
File System Implementation
- 어떻게 구현할 것인가???
- 교재에 나와있는 VSFS(Very Simple File System)을 위주로 살펴볼 예정
1. Disk Structures
- File System을 위해서 disk는 어떤 구조를 가지고 어떤 정보를 가지고 있는가?
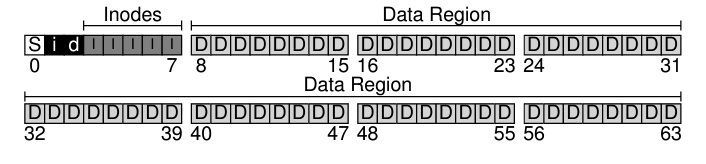
1-1. Data Blocks
- Disk는 기본적으로 Block단위로 분할되어 있다.(일반적으로는 4KB)
- File의 contents를 저장하는 disk block
- 대부분은 data를 저장하긴 하는데, File System에 따라서는 metadata의 일부를 같이 저장하는 system도 별도로 존재함
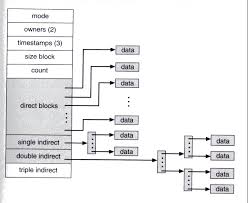
1-2. Inodes

-
Inode는 file에 대한 전체적인 metadata를 저장하는 struct
- Inode의 크기는 고정적이고, 파일의 데이터에 접근하기 위해서는 반드시 이를 거쳐야 하기 때문에...
- File system은 대부분이 고정된 위치에 이를 저장하는 공간을 미리 할당해놓는다.(Inode table)
-
Inode table은 한 블럭당 대략 16개의 inode에 대한 데이터를 저장하고 있다(256KB).
- 따라서 Inode table의 개수가 file system이 수용할 수 있는 전체 파일의 갯수를 결정하는 셈
-
Inode가 저장하는 metadata list
1-3. Bitmaps
-
우리가 모든 block을 일일이 접근하면서 이 inode가 사용중인지 저 data block이 사용중인지를 일일이 검사하는 건 너무 비효율적이니까...
-
개별적인 bit를 이용해서 해당 block, inode를 사용중인지 아닌지를 표기하는 bitmap을 할당해 놓는다.
- inode bitmap : inode에 대한 bitmap
- data bitmap : data block에 대한 bitmap
- 한개의 data bitmap block은 4096개의 data block에 대한 metadata를 표기할 수 있다.
- 어째서일까. bit단위로 표기하면 더 많이 저장할 수 있지 않을까. bit단위 접근이 안되니까?
1-4. Superblock
- 전체 파일 시스템에 대한 metadata를 저장하는 블록
- 파일 시스템 type
- 블록 사이즈(4KB가 일반적인데 16KB도 있더라...)
- 전체 block 갯수
- inode 개수(전체 파일 갯수)
- data/inode bitmap의 갯수
2. Allocation
- 디스크 안쪽의 어떤 블록에 데이터를 어떻게 저장할 것인가?
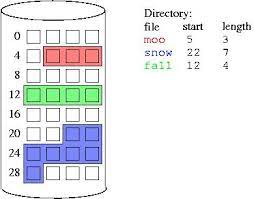
2-1. Contiguous Allocation
- Metadata:
<starting block #, length>- 시작 Block부터 #개를 연속적으로 저장
- 장점
- 순차 읽기는 정말 빠르다.(이건 뭐... 당연하지)
- random access도 빠르게 계산할 수 있다.(start block + access block #)
- metadata에도 딱 2개만 저장하면 되니까 엄청 간단해진다.
- 단점
- 끔찍한 수준의 External fragmentation
- 파일의 크기가 커지면 대응하기 매우 어려움
- 이 2개의 단점이 사실 너무 커서... 실질적으로 이걸 사용하기는 힘들다.
2-2. Linked Allocation
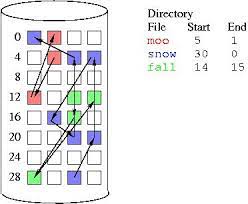
-
Metadata:
<starting block #>- 개별 block이 다음 block에 대한 pointer를 가지고 있기 때문에, linked list처럼 따라가면 된다.
-
장점: Continuous의 단점이 장점이 된다.
- External fragmentation은 없다.(linked list니까...)
- 파일의 크기가 커져도 아무런 문제가 없다.
-
단점
- sequential access는 살짝 느리다.(포인터 연산)
- Random access는 끔찍하다. linked list의 단점을 그대로 따라가는 것.
- 다른 단점으로... disk crash에 굉장히 취약하다.(pointer가 block안쪽에 그대로 있기 떄문에... block 한개라도 잘못되면 그 이후의 데이터는 전혀 불가능하다.)
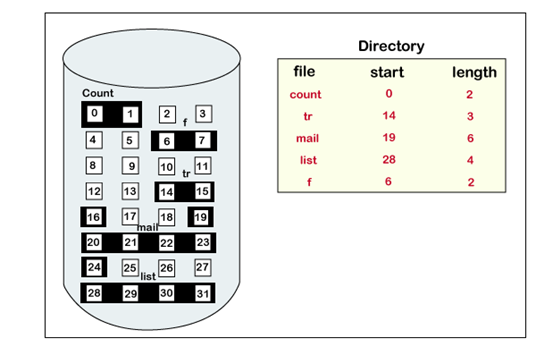
2-3. File Allocation Table(FAT)
-
Linked Allocation과 거의 유사하지만, pointer가 block 내부에 저장되어있는 방식이 아니라 FAT라는 별개의 table에 따로 저장한다.
-
윈도우에서 사용했던걸로 유명하다. e.g. FAT12, FAT16, FAT32...
- 뒤의 숫자는 pointer의 bit 개수(그렇기 때문에 이 bit가 나타낼 수 있는 숫자의 최대가 block의 최대 갯수라고 볼 수 있다.)
-
FAT를 따로 main memory에 caching할 수 있기 때문에 속도면에서는 다소 이득을 볼 수 있다.
2-4. Indexed Allocation
-
한개의 블럭을 할당하고 해당 블럭에 다른 모든 block의 포인터를 저장한다.
- Metadata:
<indexed block pointer>
- Metadata:
-
장점: 뭐 사실 전체적으로 좋다.
- External fragmentation도 없고
- 파일 크기도 쉽게 조절할 수 있고
- Random access, sequential access 성능 모두 준수하다.
-
단점
- Metadata의 크기가 커진다...
- 사실 대부분의 파일은 4KB에 해당하는 포인터 전체를 활요할 만큼 크지가 않다..
2-5. Multi-level Indexing

-
파일 시스템이 커지니까 한개의 블록으로 안되는 경우가 종종생겼다...
- 이것도 그래서 멀티레벨로 바꿨다.
- 사실 별로 설명할건 없다.
-
파일의 최대 크기:
2-6. Extent-based Allocation(ExtN)
- 모든 블록을 다 저장할 필요는 없다! sequential하게 할 수 있으면 가능한 sequential하게 저장하는게 Best다!
- Sequential하게 저장할 수 있는 구역으로 전체 파일을 분할해서 저장한다.
- Metadata:
<starting block #, extent size> - 개별 Node가 sequential하게 저장할 수 있는 구역에 대한 정보를 저장한다.
- 나머지는 이전의 multi-level indexing과 동일하기 때문에... 뭐 큰 차이는 없다.
- Multi-level에 비해서 metadata 크기도 줄어들고 sequential performance는 상승하지만, random access에서는 다소 계산이 더 필요하다.
3. Directory
- 디렉토리는 파일이긴 한데, metadata를 파일로 가지고 있는 file이다.
3-1. Directory Data

- 단순히 현재 디렉토리에 있는 파일의 list
- Metadata:
<file name, inode number> - 파일 이름으로 찾고 inode로 데이터에 접근한다.
- Metadata:
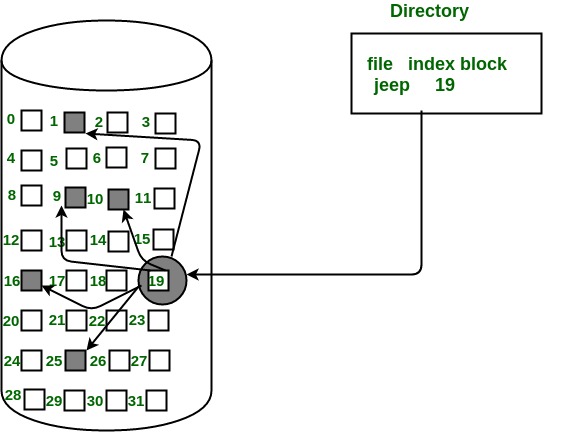
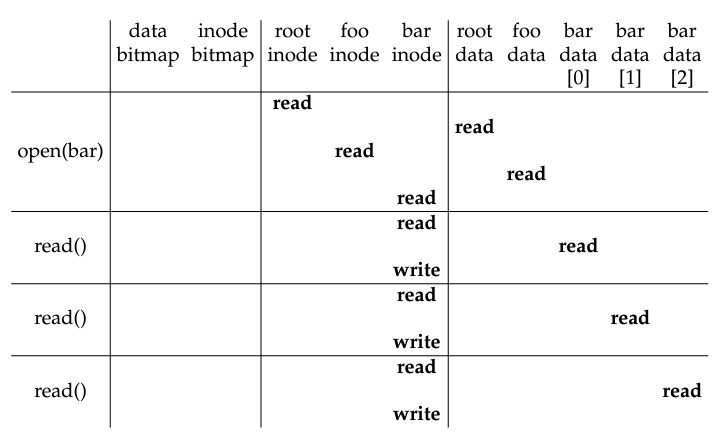
3-2. Reading a File
-
e.g. read 3 block from /foo/bar
-
root에서 부터 차례대로 읽어간다...(이건 18장에서 path에서 이미 설명했으니까...)
- root inode 열어서 data block 위치 찾고, data block에서 foo inode # 찾고...
- 이 과정에서 permission 검사를 포함한 open 과정의 검사를 전부 수행한다.
-
그렇게 최종적으로 bar의 위치를 찾으면 bar의 inode로 부터 block의 위치를 찾고 data block에서 실재로 읽어온다.
-
write는 무엇인가?: access time(필요할 떄도 있지만, 실재로 필요한가는 잘 모르겠다...)
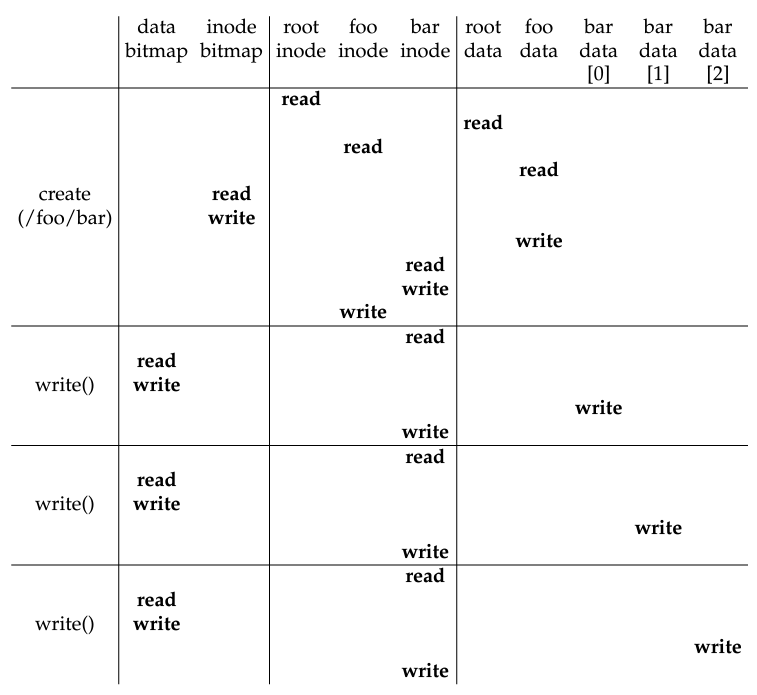
3-3. Writing a File
-
e.g. create and write 3 block at /foo/bar
-
path를 찾아가는 과정은 동일하니까 skip.
-
일단 foo data에서 bar라는 이름이 있는지를 검사해야해서... data를 read한다.
-
이제 bar 파일을 생성하기 위해서는 총 4개의 data에 write를 해야한다.
- inode bitmap: bar inode를 할당해야 하므로, 이를 확인하고 마크한다.
- foo data: foo directory 내부에 bar에 대한
<filename, inode #>data를 기록해야 한다. - bar inode: bar라는 파일에 대한 metadata를 만들어야 함
- foo inode: foo 역시 access time, modified time, size등 여러가지의 metadata를 변경해야할 가능성이 높다.
-
이제 bar 내부에 data를 쓰는 과정을 보면 마찬가지로 파일 찾는 건 동일하므로 skip.
-
bar 내부에 쓰기 위해서는 3개를 변경해야한다.
- bar inode: bar metadata가 변경됨(각종 time, block index, size, etc...)
- bar data block: dat
- data bitmap: 만일 크기가 커져서 bitmap이 추가로 필요하다면 이 역시 allocate 해야함
