RAG - 정보의 검색

우리는 다양한 방법으로 정보를 찾는다. 상황과 목적에 따라 인터넷 검색, 문서, 사전등 서류 자료를 활용한 다양한 탐색 방법이 존재한다.
우리가 AI가 폭발적으로 발전함에 따라 AI는 새로운 검색 수단으로서 사용하는 분들이 많아졌다.

비교적 최근 놀면 뭐하니의 최신 회차이다. 방송의 주제는
"AI에게 질의를 하고 AI의 선택에 따라 프로그램을 이어간다."
였다. 시청해보면 주로 OpenAI의 GPT TTS서비스로 질문을 하고 답변대로 식사를 정하거나 다음 행선지를 정하거나 했었다. 이외 이미지 생성모델을 이용해서 사진을 수정하거나 하는 것도 있었지만 주로 GPT를 많이 사용하였다.

이런 것을 보면 요즘 사람들은 AI를 마법의 소라고동 정도로 여기고 있는 것 같다. 사실 개발자가 아니라면 대부분 이정도 사용하고 또 한가지 많이 사용하는 기능은 검색기능이다.
AI의 검색: 과거에 왜 정확하지 못했을까?
대표적인 구글의 AI 모드 사용예시이다. 이제는 제법 퀄리티가 높고 많은 사람들이 굳이 구글이 아니더라도 다른 AI서비스에서 즐겨 사용하고 있다. 저것 이외에도 어떤 정보를 요약, 수집을 요청해도 이제는 곧 잘 하는데 그렇지 못한 시절이 있었다.
불과 약 4년전
4년전을 생각 해보자. 처음 OpenAI라는 회사가 GPT라는 AI 서비스를 내놓았고 말그대로 충격과 수많은 물음표를 낳았다. 대표적으로 다음 것들이 있었다.
환각 현상: 허언증
Q: 조선시대 세종대왕 집권시기 주요 사건 중 하나를 찾아줘.
A: 세종대왕 맥북 던짐 사건: "세종대왕이 훈민정음 작성 중 맥북프로를 던진 사건에 대해 알려줘"라고 물으면, "1443년 세종대왕이 훈민정음 창제 중 작업이 뜻대로 되지 않자 맥북프로의 성능에 분노하여 이를 던졌다는 기록이 조선왕조실록에 전해집니다."
말도 안되는 얘기를 지어내는 것인데 이것의 원인은 여러가지가 있지만 대표적으로 뽑는 원인이 학습하지 않은 정보에 대한 강제적 답변 생성으로 얘기 가능하다. 기본 LLM은 모르는 정보에 대해 사람처럼 모른다고 답하는 것이 아니라 그럴듯한 다음 토큰(말이 어려우면 단어로 이해하자.)를 생성하도록 훈련 되어있기 때문이다.
기타 다른 오류중에는 부정확한 데이터로 학습 한 경우가 있다. 아무래도 GPT자체가 인터넷의 데이터를 학습하다보니 정제되지 않은 데이터까지 학습해서 생긴 문제일 수 있다.
그래도 가장 널리 알려진 이유는 모르는데 답변을 해서로 알면 되겠다.
논리, 추론의 한계: 하지만 빨랐죠?

딱 저 사진 하나로 모든 것을 요약할 수 있다. 수학문제에서 몇 글자, 기호, 숫자만 바꿔도 바로 오답을 생성하는데 이는 LLM의 학습의 궁극적인 목적때문이다.
LLM은 궁극적으로 다음 토큰에 대한 올바른 예측만 잘하면 되도록 훈련을 한다. 이는 우리 학창시절 처럼 문제와 답만 통으로 외우는 꼴이 된다.
우리학교 수학선생님: 한 글자만 바꿨는데 왜이리 못 맞추니??
이제 선생님의 심정이 이해가 갈 것이다...
그래서 이런 추론 과정을 명시를 하거나 몇 가지 예시(Few-Shot)를 프롬프트에 명시하는 방법으로 극복이 가능하다.
크게 우리는 이 2가지 이유로 인해 처음에 신기했지만 영화 속 자비스 같지 않아 실망했을 것이다.

이런식으로 물어보는 질문에 잘 대답하고 내 수학 숙제도 대신 풀어주는 AI를 생각했지만 그 당시엔 그정도는 되지 못했다.
특히 환각이라는 현상 때문에 서비스를 이탈하거나 부정적인 평가를 남기거나 하는 일이 늘어났고 근본적으로 이 문제가 해결 되어야했다.
AI의 학습: 인간처럼 공부를 시키자
대답을 못하는 부분의 정보를 학습시키자.
가장 단순한 해결책이다. 하지만 데이터 수집, 학습데이터 제작, 학습 및 평가에는 막대한 자본과 자원이 들어가고 세상의 모든 정보를 담기엔 너무나 양이 많았다.
모르는 것에 대해 이상한 답변을 하는 경우는 적절한 프롬프팅을 통해 통제가 가능한 부분이었지만, 결국 유저들은 어떤 것이든 잘 대답해주는 AI를 선호하기 때문에 학습은 불가피 해졌다.
AI의 Fine-Tuning: AI 대학에 가다.
그래서 사람들은 한가지 해결책을 찾았다.
내가 필요한 내용만 따로 학습시키자!
우리가 예를 들어 기계공학과에 진학해서 학습해야한다 가정해보자. 두 명의 사람이 있다.
- 신입생 A: 자사고, 수학(미적분, 기하, 벡터 개념 미흡, 확률과 통계 위주 학습), 선택과목 생윤, 한지 선택
- 신입생 B: 과학고, 수학(대학수학 선행, 기하, 벡터 개념 풍부), 물리, 화학 선택
처음 입학해서 공업수학, 대학물리 수업을 따라가기에 신입생 B가 훨씬 유리할 것이다.
LLM도 마찬가지다. 학습 하려는 도메인의 기초지식을 알고 있는 모델을 선정해서 원하는 부분만 학습 시키면 시간을 절약하여 학습 시킬 수 있다.
좀 더 전문적인 표현으로 설명하면
관련 도메인으로 사전학습된 모델을 가져와서, 특정 태스크에 맞는 데이터로 추가 학습시키는 것. 사전학습보다 훨씬 적은 데이터와 짧은 시간으로 원하는 동작을 만들어낼 수 있다.
로 설명 가능하다.
하지만 이것도 해보면 알겠지만 우리가 대학을 4년씩 다녀야 관련 지식을 습득하듯이 꽤 많은 시간이 걸린다. 그래서 모델의 파라미터를 건들거나 하는데 이것도 역시 한계가 있다.
RAG: AI의 백과사전

우리 젊은 2030세대의 든든한 정보 검색처인 나무 위키이다. 필자는 그닥 선호하진 않지만, 인물에 관한 기본 정보나 게임관련 정보는 이곳에서 많이 참고 하긴한다. 지금 표현이 나무위키지만, 인터넷이 보편화 되지 않았을 시절엔 백과사전이 있었고 현대에는 위키 시스템들이 이 백과사전을 대신하고 있다.
우리가 학습을 통해 배운 것 이외의 정보를 찾을 땐 검색을 많이 한다. AI는 사람과 비슷한 점이 많듯 RAG는 AI가 검색할 수 있는 정보 DB(벡터 DB)를 추가하는 방법이다.
학습 불필요
가장 큰 장점이다.
정보를 담고 있는 문서, 페이지 정보등을 AI가 이해할 수 있도록 나눠(청킹) 벡터 형태로 검색할 수 있는 DB(벡터DB)를 만들어 LLM에 붙여 주는 것이 핵심이다. 이렇기 때문에 학습이 불필요하다는 장점이 있다.
출처가 있는 신뢰성 있는 정보 제공
결국 LLM이 모르는 정보를 검색하기 때문에 출처라는 것이 생겨 검증을 위해 그 문서를 찾아보거나 할 수 있어 정보의 신뢰도가 크게 올라간다.
RAG의 한계
설명만 들으면 되게 좋아 보인다. 하지만 이것 역시 한계가 명확했다.
1. 검색 결과의 순위가 엉망인 경우
상위에 올라온 문서가 의미적으로는 유사하지만 실제 질문과 관련 없는 경우. (코사인 유사도만으론 순위를 제대로 못 잡을 때.)
전문용어가 튀어 나왔지만 검색이 항상 잘되진 않는다. 특히 검색 알고리즘에 따라 이상한 문서에서 정보를 가져 오는 경우가 있다.
2. 쿼리가 복잡하거나 긴 경우 - 문맥적 관련성 부족
"A 방식과 B 방식의 성능 차이를 비교한 내용" 같은 쿼리는 단순 벡터 유사도로는 한계가 있다.
아무리 정보를 가져 올 수 있다지만 어디까지나 검색의 한계는 벗어나지 못한다. 우리도 정보를 검색하고, 이후에 그 정보들을 바탕으로 추론을 하듯 검색 파트(Retriever)는 그런 추론 기능 까지 제공하진 않는다.
3. 도메인이 특수한 경우

???: 맥심 사오라는게 그게 아니잖아 ㅡㅡ.
1번의 연장선이다. 특수 도메인은 전문 용어가 중요한데, Retriever가 해당 키워드가 포함된 문서라면 무조건 관련있다고 판단해서 엉뚱한 문서를 가져오는 경우가 많다.
위의 예시처럼 맥심이라는 단어가 잡지인 맥심도 있지만, 커피 맥심도 있어서 저런식으로 잘못 사오는 경우라고 보면 된다.
그래서 오히려 전문 지식일 수록, 전문 용어가 많을 수록 검색 성능이 저조하다.
결국 핵심은 질문과 문서의 문맥적 관련성이 단순 RAG를 통해서 보장되지 않는다.는 결론이 난다.
Re-Ranker: 2차 검증을 통해 신뢰성을 높힌다.
앞서 RAG의 한계를 확인했다. 결국 핵심 문제는 "질문과 문서의 문맥적 관련성이 보장되지 않는다" 는 것이었다. Re-Ranker는 이 문제를 해결하기 위해 등장했다.
언제, 누가, 왜 연구했나
2019년 뉴욕대학교의 Rodrigo Nogueira와 Kyunghyun Cho가 "Passage Re-ranking with BERT" 라는 논문을 발표했다.
당시 정보 검색 분야의 문제는 명확했다. BM25(키워드 매칭) 같은 전통적인 검색 알고리즘은 키워드 일치 여부만 보기 때문에, 질문과 단어는 겹치지만 실제로는 관련 없는 문서를 상위에 올려버리는 경우가 많았다.
이를 해결하기 위해 두 저자는 당시 자연어처리 분야를 뒤흔든 BERT 모델을 검색 재정렬에 적용했다. 결과는 놀라웠다. MS MARCO라는 대규모 검색 데이터셋에서 기존 최고 성능 대비 27% 향상을 달성하며 리더보드 1위를 차지했다.
이 논문이 오늘날 RAG 파이프라인에서 Re-Ranker가 표준처럼 쓰이게 된 출발점이다.
BERT — Re-Ranker의 엔진
Re-Ranker를 이해하려면 먼저 BERT라는 AI 모델을 알아야 한다. Re-Ranker는 BERT를 기반으로 동작하기 때문이다.
BERT는 텍스트를 입력받을 때 단어를 그대로 받지 않는다. 토큰(Token) 이라는 단위로 쪼개서 받는다.
"my dog is cute" →
[CLS]mydogiscute[SEP]
여기서 두 가지 특수 토큰이 등장한다.
[CLS] — 문장의 맨 앞에 붙는 토큰이다. BERT가 입력 전체를 읽고 나면, 이 토큰 하나에 전체 문맥의 의미가 압축된다. 분류 문제(관련있다/없다)를 풀 때 이 벡터를 사용한다.
[SEP] — 두 문장의 경계를 알려주는 구분자다. "여기서 첫 번째 문장이 끝나고 두 번째 문장이 시작된다"고 BERT에게 알려주는 역할이다.
BERT는 이 토큰들을 입력받아 셀프 어텐션(Self-Attention) 이라는 메커니즘으로 모든 토큰이 서로를 참조하면서 의미를 파악한다. 그리고 각 토큰마다 768차원의 벡터를 출력한다.
Re-Ranker의 원리
Re-Ranker는 BERT의 입력 포맷을 이렇게 활용한다.
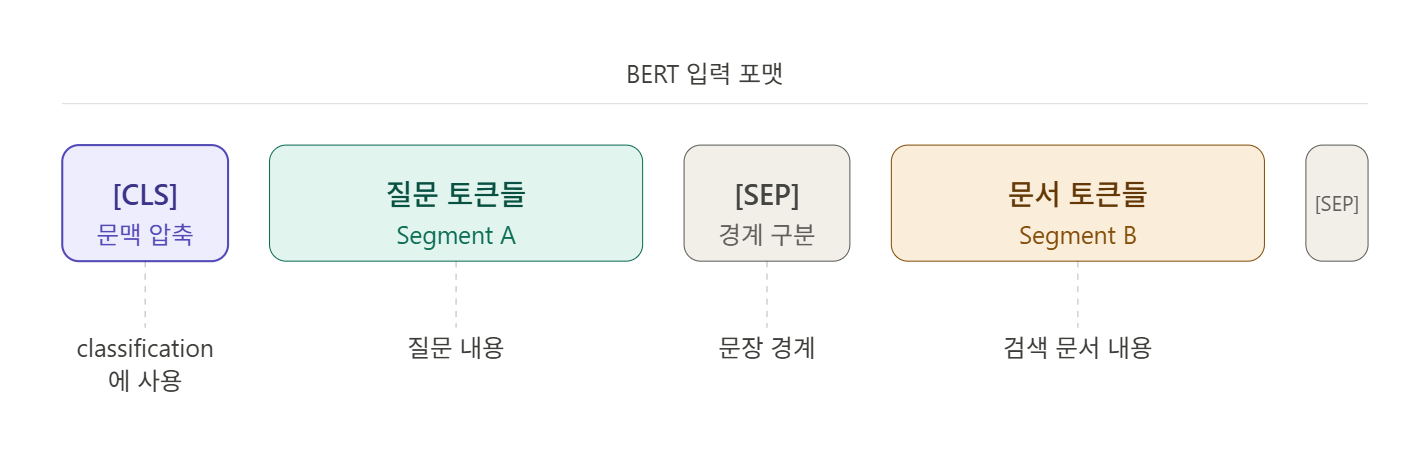
질문과 문서를 하나의 쌍으로 묶어서 BERT에 넣는 것이다. BERT는 셀프 어텐션을 통해 질문의 모든 단어가 문서의 모든 단어를 직접 참조한다. "이 질문의 이 단어가 이 문서의 저 단어와 얼마나 관련있냐"를 12개 레이어에 걸쳐 계산하는 것이다.
처리가 끝나면 [CLS] 토큰 벡터에 질문-문서 관계 전체가 압축된다. 이 벡터를 classifier에 통과시켜 최종적으로 하나의 점수를 얻는다.
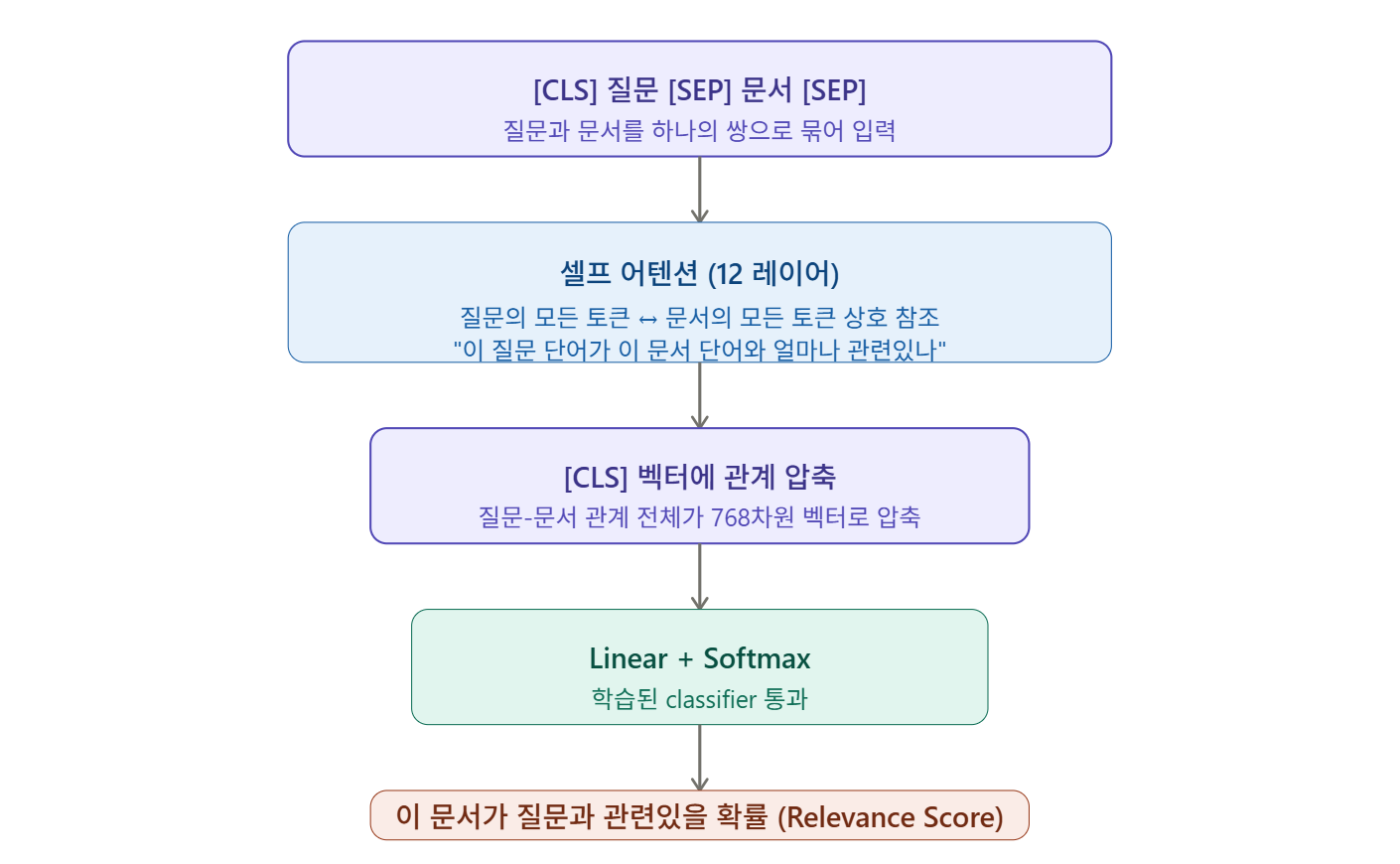
이 점수를 Relevance Score 라고 부른다. 단순한 수학 공식이 아니라, 실제 검색 데이터로 학습된 관련성 판단이라는 점이 중요하다.
Bi-Encoder와 Cross-Encoder의 역할
Re-Ranker를 실제 서비스에 쓰려면 한 가지 문제가 생긴다. 문서가 100만 개라면 질문 하나에 BERT를 100만 번 돌려야 한다. 현실적으로 불가능한 시간이다.
그래서 두 단계로 나눠서 처리한다.
1단계 — Bi-Encoder (빠른 후보 추출)
질문과 문서를 따로따로 BERT에 넣어서 각각 벡터로 만든다. 문서 벡터는 서비스 오픈 전에 미리 만들어서 저장해둔다. 질문이 들어오면 질문 벡터 하나만 만들고, 저장된 문서 벡터들과 코사인 유사도를 계산해서 상위 100~1000개를 추린다.
코사인 유사도는 두 벡터가 얼마나 같은 방향을 가리키는지를 재는 수학 공식이다. 의미적으로 비슷한 문서를 빠르게 걸러내는 데 적합하다.
2단계 — Cross-Encoder (정밀 재정렬)
Bi-Encoder가 추린 100~1000개의 후보에 대해서만 Re-Ranker를 돌린다. 질문과 문서를 쌍으로 묶어 BERT에 넣고 Relevance Score를 계산해 순위를 다시 정렬한다.
질문과 문서를 함께 읽기 때문에 단순 유사도가 아닌 문맥적 관련성을 정확하게 판단할 수 있다.
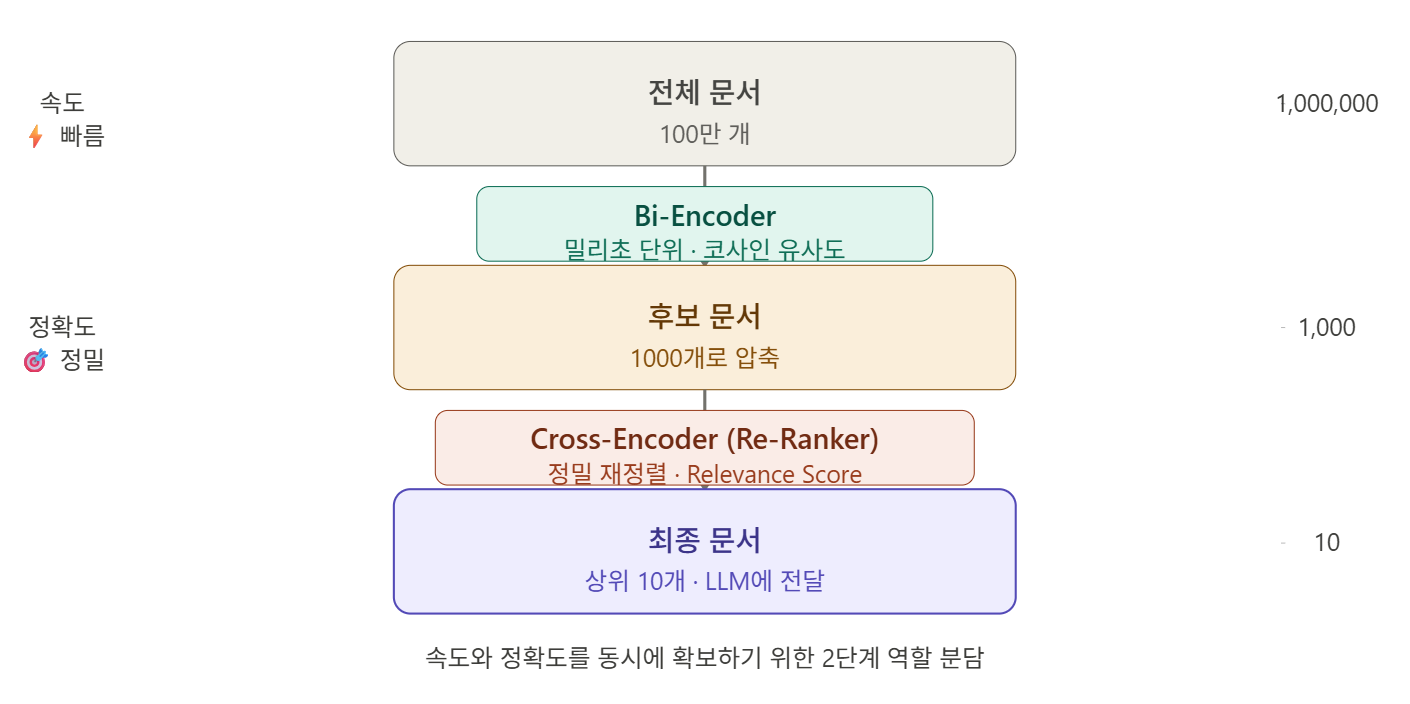
왜 둘 다 필요한가
도서관 비유로 정리하면 이렇다.
Bi-Encoder — 제목만 훑어서 관련있어 보이는 책 1000권을 빠르게 뽑는다.
Cross-Encoder — 그 1000권을 한 권씩 펼쳐서 질문과 진짜 관련있는 책 10권을 고른다.
Bi-Encoder만 쓰면 빠르지만 엉뚱한 문서가 섞인다. Cross-Encoder만 쓰면 정확하지만 100만 권을 다 펼쳐볼 수 없다. 속도와 정확도를 동시에 챙기기 위해 역할을 분담하는 것이다.
그래서 얼마나 좋아졌는가
이 논문은 두 개의 대규모 검색 데이터셋에서 성능을 검증했다.
평가 데이터셋
MS MARCO — Microsoft가 공개한 실사용자 질문 기반 검색 데이터셋이다. 약 100만 개의 실제 검색 쿼리와 사람이 직접 관련성을 평가한 문서 쌍으로 구성된다. 평가 지표는 MRR@10 (상위 10개 결과 안에 정답이 얼마나 높은 순위에 있는지)을 사용했다.
TREC-CAR — Wikipedia 문서 기반의 정보 검색 데이터셋이다. 평가 지표는 MAP (Mean Average Precision)을 사용했다.
성능 비교표
| 모델 | MS MARCO MRR@10 (Dev) | TREC-CAR MAP |
|---|---|---|
| BM25 (키워드 검색) | 16.7 | 12.3 |
| Conv-KNRM (딥러닝 기반) | 29.0 | — |
| IRNet (기존 최고 성능) | 27.8 | — |
| BERT Base (Re-Ranker) | 34.7 | 31.0 |
| BERT Large (Re-Ranker) | 36.5 | 33.5 |
기존 최고 성능(IRNet) 대비 MS MARCO에서 약 27% 향상을 달성하며 리더보드 1위를 차지했다.
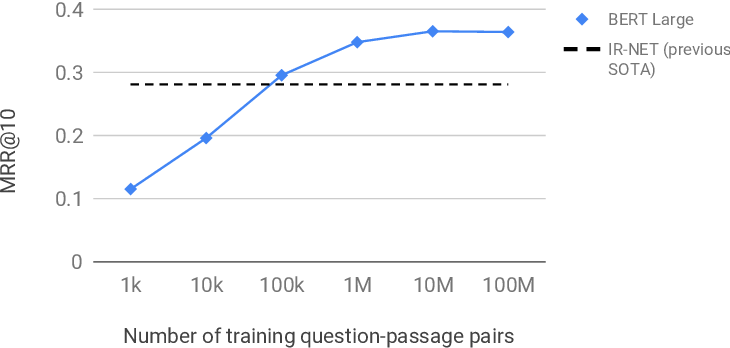
주목할 만한 결과
적은 데이터로도 강력한 성능
BERT Large를 전체 학습 데이터의 0.3%에 해당하는 10만 개 쌍만으로 학습시켰을 때도 기존 최고 성능을 이미 넘어섰다. 사전학습 모델이 이미 언어에 대한 풍부한 이해를 갖추고 있기 때문이다.
전통적 키워드 검색과의 격차
단순 키워드 일치 방식인 BM25의 MRR@10이 16.7인 반면, BERT Re-Ranker는 36.5를 기록했다. 두 배 이상의 성능 차이다. 이는 문맥적 관련성 판단이 얼마나 중요한지를 보여준다.
마무리
오늘은 간단하게 RAG에 대해 설명하고 기본 RAG의 한계와 검색 성능을 향상시키는 Re-Ranker라는 기술에 관해 공부해봤다. RAG가 추가 학습의 불필요라는 최대 장점으로 주목 받아 왔는데 한계점이 있었고 이는 검색 알고리즘 개선으로 이어져 Re-Ranker라는 쿼리와 문서를 함께 문맥적으로 관련이 있는지 추가 검증하는 로직으로 개선 되어 왔다.
당연히 논문에서는 최고라고 설명하는 것이 있고 내가 써봐야 체감이 크다. 필자는 사용해봤지만
다음 포스팅에서는 간단하게 RAG를 몇 개 문서로 구현해보고, Re-Ranker가 실제 어떤 효과가있는지 확인해보겠다.
