트랜스포머 인코더
이번에는 트랜스포머의 인코더에대해 살펴볼 예정이다.
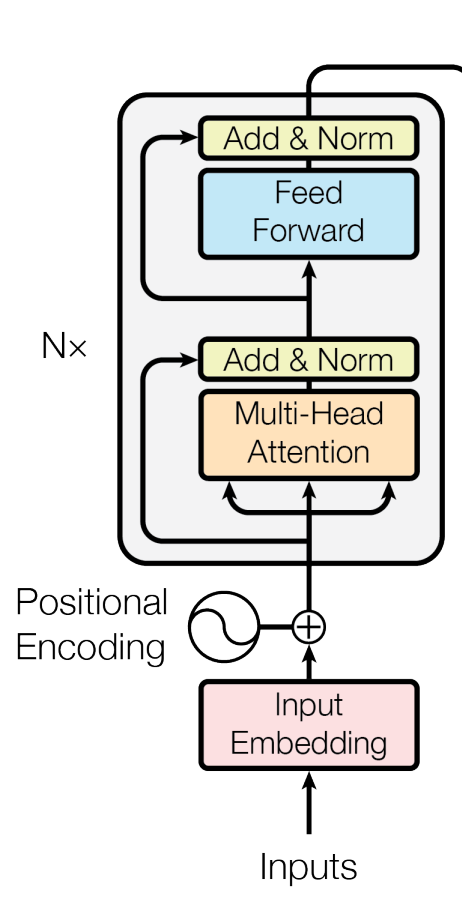
이전 까지 입력 임베딩이 어떻게 생성되고 위치 인코딩이 어떤 방식으로 진행되는지 배웠다. 입력 임베딩에는 위치 정보가 없기에 위치 인코딩을 더해준다.
멀티 헤드 어텐션
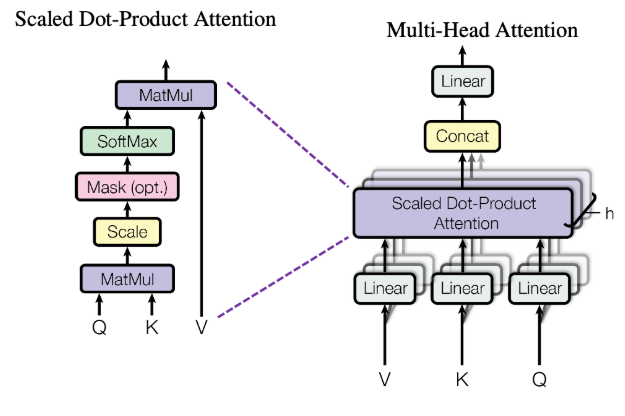
1. Q, K, V 벡터 생성
처리된 입력 텐서의 차원을 [N, S, d]라고 하면 입력 임베딩은 선형변환을 통해 3개의 임베딩 벡터로 쪼개지고 이를 쿼리(Q), 키(K), 값(V) 벡터라고 한다.
※입력 임베딩 요소: N: 배치 크기(한번에 처리하는 문장의 갯수), S: 토큰 최대 길이, d: 임베딩의 차원
-
쿼리 벡터(Q): 현재 시점에서 참조하고자 하는 정보의 위치를 나타내는 벡터로, 인코더의 각 시점마다 생성된다.
-
키 벡터(K): 쿼리 벡터와 비교되는 대상으로 쿼리 벡터를 제외한 입력 시퀀스에서 탐색되는 벡터가 된다. 각 인코더 시점에서 생성된다.
-
값 벡터(V): 쿼리 벡터와 키 벡터로 생성된 어텐션 스코어를 얼마나 반영할지를 설정하는 가중치 역할을 한다.
3개의 벡터는 각각 쿼리, 키, 값 가중치와 행렬 곱셈을 통해 얻어진다.
2. 여러 개의 헤드로 분할
멀티 헤드 어텐션이기때문에 여러개의 헤드로 분할을 해야한다. 분할 후에 각 헤드에서 셀프 어텐션을 거치고 임베딩 차원 축으로 다시 병합 되는 형태로 출력이 된다. 예를 들어 [N, s, d] 입력텐서에 k(헤드의 개수)개의 셀프 어텐션벡터를 생성한다고 하면, 헤드에 대한 차원 축을 생성해 [N, s, d/k]텐서로 분할이되는 것이다.
이후, 병합이 되면 다시 [N, s, d]의 형태로 변환되어 출력이 되는 것이다.
3. 각 헤드에서 어텐션 계산(Self-Attention)
각 헤드로 연결된 벡터는 헤드에서 어텐션을 거친다(Self-Attention)
이때 수식은 다음과 같다.
식의 대한 설명은 다음과 같다.
- 쿼리 벡터, 키벡터의 전치(임베딩 차원, 토큰 최대 길이 전치)를 행렬 곱셈한다.(쿼리벡터를 전치 하게 되면 행렬 곱셈에 따라 [d, d]행렬이 된다. 단어간의 관계를 파악하기 위해 키벡터를 전치해야 한다.)
- 로 나눈다.(학습 안정화 목적)
- 소프트맥스에 대입하여 어텐션 스코어를 얻는다.
이후 값 벡터(V)와 행렬 곱셈을 하여 어텐션 벡터를 얻는다.
4. 출력 텐서와 입력 텐서의 덧셈&정규화
각 헤드에서 생성된 어텐션 벡터들은 덧셈을 통해 출력 텐서로 바뀐다. 이에 출력 가중치 행렬([d,d])을 곱해 선형 변환을 해준다.
선형 변환을 한 출력 텐서는 입력 텐서는 더해준다.(잔차 연결 - Residual Connection)
잔차 연결이 된 결과물은 레이어 정규화(Layer Normalization)을 해준다.
레이어 정규화 공식
세부적인 파라미터는 'Layer Normalization'논문을 참고하기 바란다.
5. 순방향 신경망
순방향 신경망은 선형 임베딩+ReLU로 이뤄진 ANN이나 1차원 합성곱이 사용된다.
인코더는 하나의 트랜스포머 인코더 블록만 갖고 있는 것이 아니라 여러개로 구성되어있다. 이전 불록에서 출력된 벡터는 다음블록으로 전달이 되며 점점 입력 시퀀스 정보가 추상화된다.
마지막 인코더 블록에서 출력된 벡터는 디코더에서 사용되며, 디코더의 멀티 헤드 어텐션 모듈에서 참조되는 키, 값 벡터로 활용된다. 이런 방식으로 인코더와 디코더가 서로 정보를 공유한다.
요약 정리
-
인코더에서 입력 임베딩이 멀티 헤드 어텐션을 거치면 쿼리(Q), 키(K), 값(V) 벡터로 나눠지며 이는 각각 쿼리, 키, 값 가중치와의 행렬 곱셈으로 생성된다.
-
3개의 벡터는 헤드의 갯수만큼 분할되며 그 벡터의 차원은 (임베딩 차원/헤드의 개수)차원이 된다.
-
각 헤드에서 어텐션 벡터를 구하는 것을 셀프 어텐션(Self-Attention)이라고 한다.
-
어텐션 스코어 계산할 때, 키벡터의 전치와 쿼리 벡터를 행렬곱하고 차원의 제곱근만큼 나눠 값을 보정해야한다.
-
최종 소프트맥스를 거쳐 얻은 어텐션 스코어와 값 벡터를 행렬 곱하여 어텐션 벡터를 얻고 병합을 해야한다.
-
출력 텐서를 가중치 행렬에 곱하여 선형 변환을 해주고 입력 텐서와 더하여 잔차 연결을 해준다. 이후 레이어 정규화를 해준다.(각 샘플의 모든 feature를 정규화)
-
어텐션은 각 단어가 서로 얼마나 주목하고 있는지 확률 적으로 계산하는 행위이다. 그 확률은 출력 텐서에 나타나게 되고 소프트맥스를 사용해 확률을 계산하는 것이다.
-
인코더의 출력 텐서는 디코더의 키, 값 벡터로서 활용이 된다.
