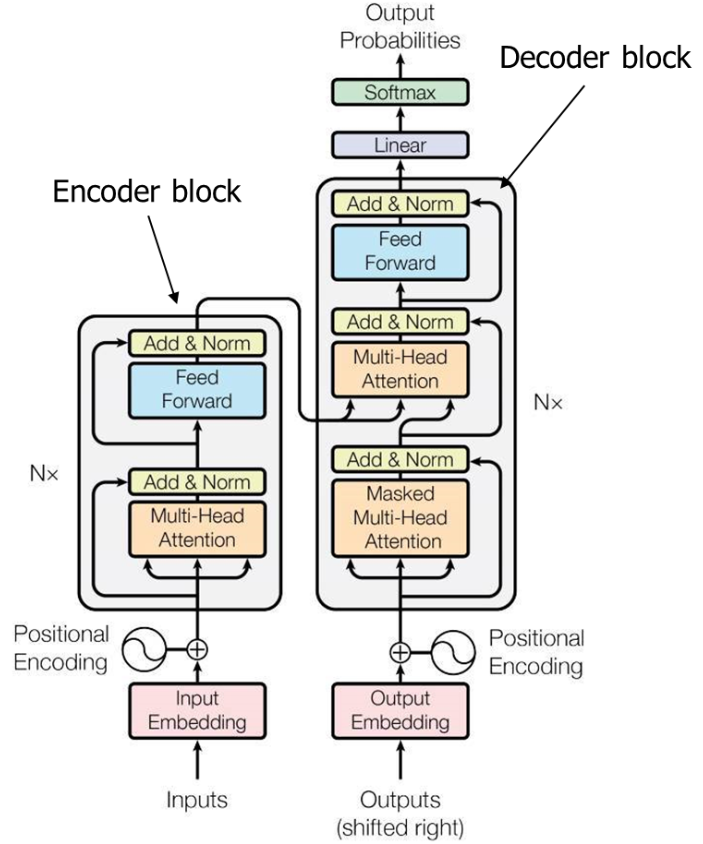
이번에는 디코더이다.
디코더
1. 쿼리(Q), 키(K), 값(V) 벡터의 이해
트랜스포머 블록에서 입력 임베딩은 각각 쿼리, 키, 값 벡터로 나눠진다고 공부하였다. 의미를 좀 더 잘 와닿도록 되짚어보자.
입력 문장: The cat ate fish를 한글로 번역해줘.
- 쿼리(Q) 벡터: 현재의 요구사항은 무엇일까?? 쿼리 벡터는 입력에 대한 요구사항에 관한 정보를 담는 벡터이다.
- 키(K) 벡터: 참조 대상은 무엇이 있을까? 키 벡터는 참조 대상의 특징에 관한 정보를 담는 벡터이다.
- 값(V) 벡터: 실제 어떤정보를 갖고 와야할까? 값 벡터는 참조 대상의 의미에 관한 정보를 담는 벡터이다.
그래서 인코더에서와 디코더(마스크 어텐션, 크로스 어텐션)에서의 쿼리, 키, 값 벡터의 의미가 조금씩 바뀐다.
1️⃣ 인코더 셀프 어텐션
Q, K, V의 출처: 모두 입력 문장
Q: 입력 문장의 요구사항 ✓
K: 입력 문장의 특징 ✓
V: 입력 문장의 의미 ✓2️⃣ 디코더 마스크드 셀프 어텐션
Q, K, V의 출처: 모두 디코더 입력
Q: 디코더 입력의 요구사항 ✓
K: 디코더 입력의 특징 ✓
V: 디코더 입력의 의미 ✓3️⃣ 디코더 크로스 어텐션
Q의 출처: 디코더 입력
K, V의 출처: 인코더 출력
Q: 디코더의 요구사항 ✓
K: 인코더 출력(소스 문장)의 특징 ✓
V: 인코더 출력(소스 문장)의 의미 ✓디코더의 경우 인코더의 출력 텐서를 크로스 어텐션(Multi-Head Attention)에서 키, 값 벡터로 사용하기 때문에 이 의미를 아는 것이 중요하다. 지금부터 디코더에 대해 설명하겠다.
2. 트랜스포머 디코더
디코더의 핵심은 인코더의 출력 벡터를 크로스 어텐션(디코더의 Multi-Head Attention)에서 키, 값 벡터로서 사용이 되고, 디코더의 입력은 Masked Multi-Head Attention에서 처리되어 크로스 어텐션의 쿼리 벡터로 이용된다.
3. Masked Multi-Head Attention
기본적으로 멀티 헤드 어텐션과 유사하다. 다만, -inf 마스크를 더해줌으로서 어텐션 스코어 값이 0이 되도록 씌워준다.
씌우는 대상은 첫번째 쿼리 벡터는 첫 번째 키 벡터를 제외한 모든 키 벡터, 두번째는 첫 번째와 두 번째 키 벡터를 제외한 모든 키 벡터에 씌운다.
마스킹 예시
스코어:
키0 키1 키2 키3
쿼리0 [ 5.2 3.1 4.0 2.5 ]
쿼리1 [ 3.5 6.8 2.9 4.1 ]
쿼리2 [ 4.1 2.7 5.5 3.2 ]
쿼리3 [ 2.8 4.3 3.6 6.0 ]
+ 마스크:
키0 키1 키2 키3
쿼리0 [ 0 -∞ -∞ -∞ ]
쿼리1 [ 0 0 -∞ -∞ ]
쿼리2 [ 0 0 0 -∞ ]
쿼리3 [ 0 0 0 0 ]
= 마스킹된 스코어:
키0 키1 키2 키3
쿼리0 [ 5.2 -∞ -∞ -∞ ]
쿼리1 [ 3.5 6.8 -∞ -∞ ]
쿼리2 [ 4.1 2.7 5.5 -∞ ]
쿼리3 [ 2.8 4.3 3.6 6.0 ]마스킹은 행렬 형태로 [seq_len,seq_len] 크기를 갖는다.
마스킹은 소프트맥스를 적용하기 전에 적용한다.
이외 과정은 인코더의 멀티 헤드 어텐션과 동일하다.
크로스 어텐션(디코더의 멀티 헤드 어텐션)
인코더와 동일하지만 소스 데이터는 인코더의 출력 텐서(키, 값 벡터)로, 타깃 데이터는 디코더의 마스크 멀티 헤드 어텐션의 출력 텐서(쿼리)로 사용 되는 것이 차이점이다.
선형 변환과 출력
디코더를 통해 출력되는 텐서는 [임베딩 차원(d), 어휘 사전의 크기(vocab_size)]차원인 행렬과 행렬곱을 하여 로짓(logit)이 생성된다. 이 로짓은 소프트맥스에 입력이되어 확률로 변환이되고 최종 가장 확률이 높은 요소가 출력된다.
요약 정리
-
디코더의 멀티 헤드 어텐션의 소스 데이터는 인코더의 출력 텐서, 타깃 데이터는 마스크 멀티 헤드 어텐션의 출력 텐서이다.
-
디코더의 출력 텐서는 선형 변환 가중치 행렬([임베딩 차원(d), 어휘 사전의 크기(vocab_size)])과 행렬 곱을 통해 소프트맥스를 거쳐 결과가 출력이 된다.
