본격적으로 AI공부를 시작한지 대략 5개월째 되어가고 있다. 본래 데이터 분석가, 엔지니어 취업 준비와 ADP 자격증을 준비하다보니 ML에는 어느정도 지식이 있던 터라 빠르게 지식을 습득 할 수 있던 것 같다.
처음에는 내가 많은 것을 안다고 생각하고 RNN, CNN만 알고있던 내가 AI 엔지니어 공고에 지원하고 광탈하며 좌절하던 시절도 생각나고 CV 모델과 LLM 모델들을 공부하며 내가 아직 모르는 것이 많지만 지원은 해보자 하며 서류 통과와 면접, 코딩테스트를 보며 실패를 겪고 이를 밑거름 삼아 보완해나간 지난 날을 돌이켜 보니, 벌써 LLM을 이용한 프로젝트와 관련 논문을 통해 기술을 학습할 수 있는 단계에 왔다는 것이 내심뿌듯한 나날인 것 같다.
하지만, 아직도 갈길이멀고 AI 개발자는 배움의 연속이라고 하니 앞으로는 서적이나 강의뿐만 아니라, 논문을 통한 학습도 자주 해보려고 한다! 그래도 이론 물리로 졸업 연구를 하며 여러 논문을 읽고 학습한 경험이 있어 현직 대학원생 만큼은 아니더라도 충분히 할 수 있을 것이라 믿는다.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Task
RAG(Retrieval-Augmented Generation)라는 개념을 처음 소개한 논문이다. 직역하면 "검색 증강 생성"이다. 흔히 이것을 사용하면 LLM의 환각(Hallucination)이 줄어든다고 알려져 있는 요즘 뜨고있는 기술중의 하나이다. 지금부터 이 논문을 리뷰하겠다.
논문 요약 파트
- 기존 LLM은 지식의 조작이나 접근이 굉장히 제한적이다. 그래서 출처 제공과 지식의 업데이트가 어렵다.
- 만약 주식관련 내용을 예를 들면 우리가 어떤 회사에 대한 시장의 분위기를 물어봤을때, LLM은 어떤 대답은 출력을 할 것인데 그 대답에 대한 검증을 해보았을 때 이상한 답변인 경우가 종종 있다.
- 경제 시장에서 어떤 회사에 대한 평판은 오늘 다르고 내일 다른 경우가 굉장히 많기 때문에 정보가 자주 바뀌는 도메인에서 LLM을 도입하기가 굉잫이 힘들다.
- 이를 해결하기 위해 해당 도메인에 대해 Fine-Tuning, PEFT를 할 수 있지만, 매일 정보가 업데이트되고 수정된다고 하면 이것도 굉장히 쉽지 않을 것이다.
- 그래서 파라매틱 메모리 + 넌 파리매틱 메모리를 결합한 하이브리드 모델을 도입하면 이를 해결할 수 있고 이를 RAG라고 정의한다.
- 파라매틱 메모리(parametic memory)는 Seq2Seq 모델이다.
- 넌 파라메틱 메모리(non - parametic memory)는 사전학습된 신경망 검색기로 접근되는 위키피디아의 밀집 벡터 인덱스이다.
- 쉽게 말해서 LLM이 모르는 정보는 외부 데이터를 검색을 해서 정보를 학습하여 결과를 추출하게 하는 것이다.
- Function Calling과 비슷한 것 같다. Function Calling를 사용하면 AI가 모르는 기능을 알고있는 함수를 불러와 상황에 맞는 출력을 하도록 할 수 있다.(예시: 11월 3일 기준 서울의 기온을 알려줘! > AI는 실제 서울의 기온을 모르기 때문에 사전에 등록되어있는 함수를 실행시켜 결과를 출력한다.)
- 그래서 Seq2Seq모델에 외부 정보 검색기를 더한 하이브리드 모델이 성능이 더 좋아진다.
- 실제 도메인에 RAG를 적용했더니 유의미한 결과가 있었다.
논문 소개(구조 및 실험에 따른 결과)
-
사전학습된 신경망 언어 모델은 데이터로부터 상당한 양의 지식을 학습한다.
- 외부 메모리에 대한 접근 없이도 많은 지식을 알고 있다.
- 하지만 메모리 확장이 쉽지 않고 예측에 대한 통찰을 제공할 수 없다. 추가로 환각을 일으킬 수 있다.
-
사전학습 모델의 문제점을 일반 Seq2Seq 모델과 검색기반 메모리를 결합한 하이브리드 모델을 도입하므로서 이를 해결할 수 있다.
- 이 하이브리드 모델은 지식을 직접 수정하고 확장할 수 있다.
- 추가로 지식에 대한 검증도 할 수 있다.
-
REALM, ORQA(마스크 언어모델)은 추출형(extractive) 다운 스트림 작업에 대해선만 연구가 진행되었다.(마스크 언어모델에 대해서 잘 모르지만 디코더 모델 비슷한 것 같다.)
RAG 모델의 구조
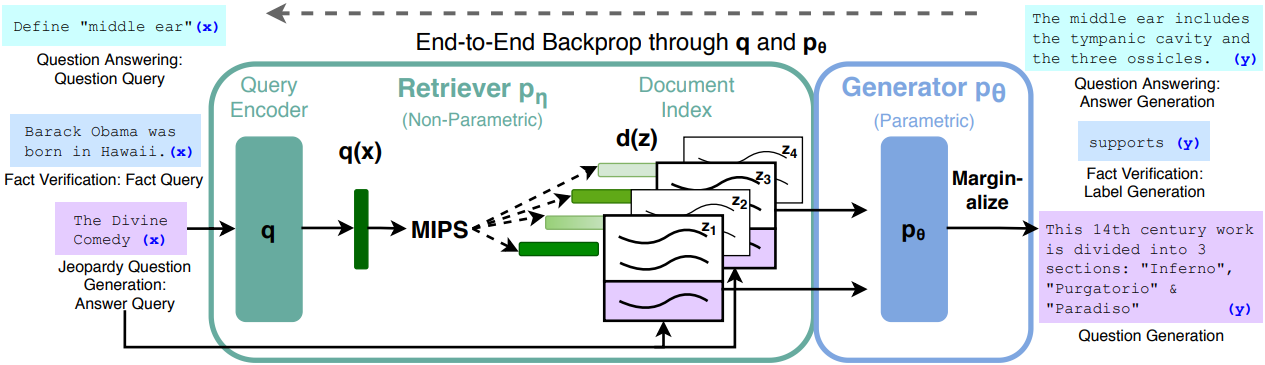
논문에서 RAG를 적용한 LLM 모델은 Seq2Seq모델이다. RAG 모델은 위키피디아의 밀집 벡터 인덱스에 접근 되는 사전학습 신경망 검색기이다.
위 그림에서 초록부분이 검색기 파트이고 파란색 부분이 언어모델 파트 이다. 논문에서는 BART로 구헌한듯하다.
사전학습된 검색기(Retriever)는 쿼리 인코더(Query Encoder)와 문서 인덱스(Document Index)가 결합된 형태이다. 쿼리 x 에대해 최대 내적 검색(Maximum Inner Product Search MIPS)를 사용하여 상위 k개의 문서()를 찾는다. 최종 예측 y를 위해 z를 잠재 변수로 취급하고 서로 다른 문서가 주어졌을 때의 seq2seq 예측들을 주변화한다.
자세한 구조 설명은 다음과 같다.
구조 상세 설명
- 입력 단계 (Input x)
그림 왼쪽에 세 가지 예시 쿼리가 표시됩니다:
- "Barack Obama was born in Hawaii." - 팩트 검증용
- "Define 'middle ear'" - 질문 응답용
- Jeopardy 질문 생성 - 생성 작업용
- 검색 컴포넌트 (Retriever) - 비파라메트릭 메모리
Query Encoder (pη):
- 입력 x를 벡터 표현 q(x)로 인코딩
Document Index:
- 21M개의 위키피디아 문서를 밀집 벡터로 인덱싱
- 각 문서 z는 d(z)로 표현됨
MIPS (Maximum Inner Product Search): 쿼리 x에 대해 MIPS를 사용하여 상위 K개 문서 zi를 검색합니다.
- 그림에서는 가 검색된 상위 문서들
- 각 문서에는 검색 확률 가 할당됨
- 생성 컴포넌트 (Generator) - 파라메트릭 메모리
Generator (pθ):
- BART 기반 seq2seq 모델
- 입력 x와 검색된 문서 z를 결합하여 출력 y 생성
- 각 검색된 문서에 대해 별도의 생성 확률 pθ(y|x,z) 계산
- Marginalize (주변화)
그림 중앙의 핵심 부분:
- 여러 검색된 문서들에 대한 예측을 결합
- 각 문서의 검색 확률과 생성 확률을 곱한 후 합산
- 최종 출력:
- 출력 단계 (Output y)
그림 오른쪽에 각 작업별 출력이 표시됩니다:
- 팩트 검증: "SUPPORTS" (라벨 생성)
- 질문 응답: "The middle ear includes the tympanic cavity and the three ossicles." (답변 생성)
- Jeopardy 질문 생성: 질문 텍스트 생성
- End-to-End Backprop
그림 하단에 "End-to-End Backprop through pη and pθ"라고 표시되어 있습니다. 이는 검색기와 생성기를 함께 엔드-투-엔드로 학습한다는 의미입니다
작동 흐름
1. 입력 쿼리 x 받음
↓
2. Query Encoder가 x를 벡터로 인코딩
↓
3. MIPS를 사용하여 Document Index에서 상위 K개 문서 검색
↓
4. 각 검색된 문서 zi에 대해:
- 검색 확률 pη(zi|x) 계산
- 생성기가 (x, zi)를 입력받아 출력 y 생성
- 생성 확률 pθ(y|x,zi) 계산
↓
5. Marginalization:
모든 문서에 대한 확률을 가중 합산
p(y|x) = Σ pη(zi|x) × pθ(y|x,zi)
↓
6. 최종 출력 y 생성본 연구의 장점과 차별점
RAG 이외에도 비메모리파라메트릭 메모리로 시스템을 강화하려는 시도는 여럿 있었다고 한다(ex. 메모리 네트워크, 스택 증강 네트워크 등). 다른 연구와 드른 것은 파라메트릭 및 비파라메트릭 메모리 구성요소 모두 사전학습이 되었다는 점, 특히 사전학습된 메커니즘을 사용하므로써 추가 학습 없이 지식에 접근이 가능하다는 장점이 차별점 이라고 소개한다.
이 논문에 따르면 RAG 생태계는 검색기가 사용하는 데이터는 미리 구축을 해야하는 것 같다. 그래서 관련 정보를 수집하고 벡터 DB를 구축해야한다는 것 같다.
실험 결과(Result)
실험을 통해 3가지 분야(open Natural Questions, WebQuestions, CuratedTrec)에서 뛰어난 성능을 보이는 것을 확인했고 다양한 데이터셋(MS-MARCO, Jeopardy, FEVER)과 SSM, 생성기 교체, 동결(ablation)등 여러 환경에서 실험한 결과를 여러 지표(EM, Bleu, Generation Diversity)로 확인했다. 세부 사항은 실험에 관한 내용만 따로 정리한 포스트를 확인 바란다.
RAG의 핵심 성과
-
성능 (Performance)
- 여러 지식 집약적 작업에서 SOTA 또는 근접 성능
- Natural Questions: 44.5% (이전 SOTA 대비 +4%)
- 특별한 사전학습 없이도 우수한 성능
-
사실성 (Factuality)
- 환각(hallucination) 현상 감소
- 인간 평가에서 BART 대비 6배 더 사실적 (42.7% vs 7.1%)
- 더 정확하고 신뢰할 수 있는 생성
-
구체성 (Specificity)
- 더 상세하고 정보가 풍부한 응답
- 인간 평가에서 BART 대비 2배 이상 구체적 (37.4% vs 16.8%)
-
다양성 (Diversity)
- 더 다양한 표현 생성
- RAG-Sequence: 83.5% vs BART: 70.7% (MS-MARCO)
- 다양성 촉진 디코딩 없이도 달성
-
유연성 (Flexibility)
- 재학습 없이 지식 업데이트 가능
- 인덱스만 교체하면 즉시 최신 정보 반영
- 파라메트릭 모델 대비 유지보수 용이
-
학습 가능성 (Learnability)
- 엔드-투-엔드 학습을 통한 검색 개선
- 작업에 특화된 검색 패턴 학습
- Frozen 대비 5.7점 향상 (NQ)
파라메트릭 vs 비파라메트릭 메모리 결합의 효과
| 특성 | Parametric (BART) | Non-Parametric (Index) | RAG (결합) |
|---|---|---|---|
| 지식 저장 | 모델 파라미터 | 외부 문서 | 둘 다 활용 |
| 업데이트 | 재학습 필요 | 인덱스 교체 | 인덱스 교체 |
| 해석성 | 낮음 | 높음 | 높음 |
| 환각 | 많음 | 없음 | 적음 |
| 생성 품질 | 보통 | N/A | 우수 |
| 추론 속도 | 빠름 | 느림 | 중간 |
실무 적용 시사점
-
지식 집약적 작업에 최적
- QA, 팩트 체킹, 질문 생성 등
- 정확성과 사실성이 중요한 도메인
-
유지보수 용이성
- 지식 베이스만 업데이트
- 모델 재학습 불필요
-
확장 가능성
- 문서 추가/제거로 지식 확장
- 도메인 특화 인덱스 구축 가능
-
해석 가능성
- 어떤 문서를 참고했는지 추적 가능
- 답변의 근거 제시 가능
마무리
RAG의 기본을 RAG 소개 논문을 통해 공부해봤다. 결국 RAG는 기존 LM들의 단점인 메모리 업데이트가 힘든점, LM이 모르는 내용에 대한 잘못된 답변(환각)을 해결할 한가지 방법론이다. RAG는 주식이나 기상정보와 같이 수시로 업데이트 되는 도메인에서 각광받을 것이다. 자주 업데이트가 되지 않는다면 Fine-Tuning으로 어느정도 해결이 가능할 것이기 때문이다. 다만, 많은 시간을 들이지 않아도, 별도 학습 없이도 모델의 정확도를 높힐 수 있고 다양한 답변을 출력 할 수 있다는 것은 굉장히 큰 메리트인 것은 부정할 수 없다. 적절한 상황에서 다양한 방법으로 모델의 성능을 높힐 수 있게 많은 고민을 해야할 것 같다.
