RAG 논문 실험 내용 및 결론 정리
이번에는 RAG 소개논문의 실험들을 정리해서 포스팅할 것이다. 내가 잘 모르는 것은 AI에게 질문하였고, 이를 포스팅에도 추가해서 이해를 돕고자 노력했다. 내가 했던 질문들은 (질문1,2...) 이런식으로 추가 되어있다.
Part 1: 실험 내용 (Section 3: Experiments)
실험 공통 설정
데이터 소스 및 인덱싱 (Section 3)
- 비파라메트릭 지식 소스: Wikipedia (2018년 12월 덤프)
- 문서 분할: 각 Wikipedia 문서를 100단어씩 분할하여 총 21M 문서 생성
- 인덱싱 방법: FAISS 라이브러리 사용, Hierarchical Navigable Small World 근사로 MIPS 인덱스 구축
- 검색 문서 수: 학습 시 k ∈ {5, 10}, 테스트 시 k는 dev 데이터로 결정
💡 추가 설명: 잠재 문서(Latent Documents)란? (질문 8)
간단 정의 (2줄)
- 잠재 문서는 쿼리에 대해 검색된 상위 K개의 문서입니다
- RAG는 이 문서들을 직접 관찰하지 않고 확률적으로 주변화하여 최종 답변을 생성합니다
상세 설명
- "잠재(latent)"의 의미: 직접 보이지 않지만 내부에서 사용됨
- 작동 방식: K=5면 5개 문서를 검색해서 모두 고려하고, 각 문서의 기여도를 확률로 계산해서 합침
- 사용자 관점: 최종 답변만 보고, 어떤 문서를 썼는지 직접 보지 못함
- 실험에서의 의미: K=5로 학습하든 K=10으로 학습하든 성능 차이 미미하지만, 테스트 때 K를 늘리면 성능 향상 (대신 느려짐)
실험 1: Open-Domain Question Answering (Section 3.1)
실험 목적
- 지식 집약적 작업의 대표 사례로 Open-domain QA 평가
- 추출형(extractive) QA와 생성형(generative) QA 비교
- "Closed-Book QA"(검색 없음)와의 성능 비교
📖 추가 설명: 추출형 vs 생성형 다운스트림 작업 (질문 2)
추출형(Extractive) 다운스트림 작업
- 주어진 문서에서 정답 구간(span)을 그대로 추출하는 방식
- 예시: 문서에 "Barack Obama was born in Hawaii" → "Hawaii" 그대로 추출
- 한계: 문서에 없는 내용은 답할 수 없음
생성형(Generative) 작업
- 문서 내용을 이해하고 새로운 문장을 생성하는 방식
- 예시: 여러 문서의 정보를 종합하여 "Hawaii"라고 생성
- 장점: 문서에 정답이 정확히 없어도 관련 정보로 답변 가능
RAG의 접근: 생성형을 사용하여 추출형보다 더 유연한 답변 생성
데이터셋 (Section 3.1)
1. Natural Questions (NQ) - 구글 검색 질문
2. TriviaQA (TQA) - 트리비아 질문
3. WebQuestions (WQ) - Freebase 기반 질문
4. CuratedTrec (CT) - TREC QA 데이터
실험 설정
- CT, WQ는 작은 데이터셋이므로 NQ RAG 모델로 초기화
- 이전 연구(ORQA, DPR)와 동일한 train/dev/test 분할 사용
- 평가 지표: Exact Match (EM) 점수
- TQA는 T5와 비교하기 위해 TQA Wiki 테스트 셋에서도 평가
📊 추가 설명: Exact Match (EM) 평가 지표 (질문 1)
정의
- 모델의 답변이 정답과 정확히 일치하는 경우의 비율
- 부분 일치는 인정하지 않음
예시
- 정답: "Barack Obama"
- 모델 답변: "Barack Obama" → ✓ 1점 (정확히 일치)
- 모델 답변: "Obama" → ✗ 0점 (부분 일치도 불인정)
- 모델 답변: "President Barack Obama" → ✗ 0점 (추가 단어 있음)
특징
- 매우 엄격한 평가 기준
- Open-domain QA의 표준 평가 지표
- Table 1의 모든 점수는 EM 기준
학습 방법
- 질문-답변을 입력-출력 쌍으로 취급
- 답변의 negative log-likelihood 직접 최소화
🔬 추가 설명: SSM (Salient Span Masking) (질문 3)
정의
- SSM = Salient Span Masking (중요 구간 마스킹)
- T5와 REALM에서 사용하는 특별한 사전학습 기법
일반 마스킹 vs SSM
- 일반 BERT 마스킹: 랜덤하게 단어를 가려서 학습
- 예: "Barack [MASK] was born in Hawaii" → "Obama" 예측
- SSM: 중요한 정보(엔티티, 날짜, 고유명사 등)를 선택적으로 가림
- 예: "[MASK] Obama was born in [MASK]" → "Barack", "Hawaii" 예측
목적 및 효과
- 모델이 중요한 지식을 더 잘 기억하게 만듦
- 지식 집약적 작업에서 성능 향상
단점 및 RAG의 장점
- SSM 단점: 계산 비용이 매우 높음 (어떤 span이 중요한지 판단 필요)
- RAG의 우위: SSM 없이도 T5+SSM보다 우수한 성능 달성
실험 2: Abstractive Question Answering (Section 3.2)
실험 목적
- RAG의 자연어 생성(NLG) 능력을 지식 집약적 환경에서 테스트
- 단순 추출을 넘어선 자유 형식 추상적 텍스트 생성 평가
데이터셋 (Section 3.2)
- MS-MARCO NLG task v2.1
- 구성: 질문 + 검색 엔진의 10개 gold passage + 전체 문장 답변
- RAG 설정: Gold passage는 사용하지 않고 질문과 답변만 사용하여 open-domain abstractive QA로 취급
주의사항
- 일부 질문은 gold passage 없이 참조 답변과 일치하는 답변 불가능 (예: "What is the weather in Volcano, CA?")
- 일부 질문은 Wikipedia만으로 답변 불가능 → RAG가 파라메트릭 지식 활용
실험 3: Jeopardy Question Generation (Section 3.3)
실험 목적
- 비-QA 설정에서 RAG의 생성 능력 평가
- 표준 open-domain QA의 짧고 단순한 질문 대신 더 어려운 작업 제안
작업 특징
- Jeopardy 형식: 엔티티에 대한 사실로부터 그 엔티티 추측
- 예시: "The World Cup" → "In 1986 Mexico scored as the first country to host this international sports competition twice"
- 정확하고 사실적인 진술 생성이 필요한 지식 집약적 생성 작업
데이터셋 (Section 3.3)
- SearchQA 분할 사용
- Train: 100K, Dev: 14K, Test: 27K 예제
평가 방법
1. 자동 평가: SQuAD-tuned Q-BLEU-1 메트릭
- Q-BLEU는 엔티티 매칭에 높은 가중치를 둔 BLEU 변형
- 질문 생성에 대해 인간 판단과 높은 상관관계
- 인간 평가: 2가지 측면
- Factuality: 신뢰할 수 있는 외부 소스로 확증 가능한지
- Specificity: 입력과 출력 간의 높은 상호 의존성
- 방법: 쌍별 비교 평가 (BART vs RAG)
🔄 추가 설명: RAG-Token vs RAG-Sequence (질문 4)
핵심 차이점
두 모델의 핵심 차이는 검색된 문서를 언제 사용하는지입니다.
RAG-Sequence
특징:
- 전체 답변 생성에 같은 문서 사용
- 한 문서를 선택하면 끝까지 그 문서만 참고
- 일관성 있는 답변에 유리
수식:
p(y|x) = Σ p(z|x) × p(y₁,y₂,...,yₙ|x,z)예시: "Who wrote 'The Sun Also Rises'?"
- 문서1 선택 → 전체 답변 생성: "Ernest Hemingway wrote it in 1926."
장점: 일관된 단일 소스 기반 답변, QA에 적합
RAG-Token
특징:
- 각 토큰마다 다른 문서 사용 가능
- 매 단어 생성할 때마다 가장 적합한 문서 선택
- 여러 정보 조합에 유리
수식:
p(y|x) = Π Σ p(z|x) × p(yᵢ|x,z,y₁:ᵢ₋₁)예시: "Who wrote 'The Sun Also Rises'?"
- "Ernest" 생성 시 → 문서1 참고 (작가 정보)
- "Hemingway" 생성 시 → 문서2 참고 (이름 정보)
- "1926" 생성 시 → 문서3 참고 (출판 연도)
장점: 복잡한 정보 조합, Jeopardy처럼 여러 사실 필요한 경우
실험 결과 기반 선택 가이드
- RAG-Token 선택: Jeopardy 생성 (Q-BLEU-1: 22.2 > 21.4)
- RAG-Sequence 선택: Open-domain QA, MS-MARCO (더 일관된 답변)
실험 4: Fact Verification (Section 3.4)
실험 목적
- 생성이 아닌 분류 작업에서 RAG의 능력 평가
- 검색 감독 없이 팩트 검증 성능 평가
데이터셋 (Section 3.4)
- FEVER: 자연어 주장이 Wikipedia에 의해 지지/반박/판단불가 분류
- 검색 + 추론이 결합된 복잡한 작업
실험 설정
- FEVER 클래스 라벨(supports/refutes/not enough info)을 단일 출력 토큰으로 매핑
- claim-class 쌍으로 직접 학습
- 중요: 대부분의 다른 FEVER 접근법과 달리 검색 증거에 대한 감독(supervision) 사용 안 함
평가 변형
1. 3-way 분류: supports/refutes/not enough info
2. 2-way 분류: supports/refutes (Thorne and Vlachos 연구)
- 평가 지표: Label Accuracy
Part 2: 실험 결과 (Section 4: Results)
4.1 Open-Domain Question Answering 결과 (Section 4.1, Table 1)
성능 비교 (Table 1)
| 모델 유형 | Model | NQ | TQA | WQ | CT |
|---|---|---|---|---|---|
| Closed-Book | T5-11B | 34.5 | -/50.1 | 37.4 | - |
| Closed-Book | T5-11B+SSM | 36.6 | -/60.5 | 44.7 | - |
| Open-Book | REALM | 40.4 | - | 40.7 | 46.8 |
| Open-Book | DPR | 41.5 | 57.9/- | 41.1 | 50.6 |
| RAG | RAG-Token | 44.1 | 55.2/66.1 | 45.5 | 50.0 |
| RAG | RAG-Seq. | 44.5 | 56.8/68.0 | 45.2 | 52.2 |
주요 발견 (Section 4.1)
1. SOTA 달성: 4개 데이터셋 모두에서 최고 또는 최고 수준 성능
2. 효율성: REALM, T5+SSM과 달리 비싼 "salient span masking" 사전학습 불필요
3. 생성의 우위:
- DPR의 BERT 기반 cross-encoder re-ranker, extractive reader 모두 불필요
- 문서에 답변이 정확히 없어도 관련 단서로 답변 생성 가능
- 검색된 문서에 정답이 없는 경우에도 NQ에서 11.8% 정확도 달성 (추출형은 0%)
4.2 Abstractive Question Answering 결과 (Section 4.2, Table 2, Table 3)
정량적 결과 (Table 2)
| Model | MS-MARCO Bleu-1 | MS-MARCO Rouge-L |
|---|---|---|
| SOTA* | 49.9 | 49.8 |
| BART | 41.6 | 38.2 |
| RAG-Token | 41.5 | 40.1 |
| RAG-Seq. | 44.2 | 40.8 |
*gold context 사용
성과
- RAG-Sequence가 BART 대비 +2.6 Bleu, +2.6 Rouge-L 향상
- Gold passage 없이 SOTA에 근접한 성능
정성적 분석 (Table 3)
- RAG 모델이 BART보다 환각(hallucination) 적음
- 더 사실적으로 정확한 텍스트 생성
- 예시에서 BART는 논리적 모순, RAG는 정확한 정의 제공
4.3 Jeopardy Question Generation 결과 (Section 4.3, Table 2, Table 3, Table 4)
자동 평가 결과 (Table 2)
| Model | Jeopardy Q-BLEU-1 |
|---|---|
| BART | 19.7 |
| RAG-Token | 22.2 |
| RAG-Seq. | 21.4 |
인간 평가 결과 (Table 4, 452쌍 비교)
| 평가 기준 | BART better | RAG better | Both good | Both poor |
|---|---|---|---|---|
| Factuality | 7.1% | 42.7% | 11.7% | 17.7% |
| Specificity | 16.8% | 37.4% | 11.8% | 6.9% |
주요 발견
- RAG가 BART보다 6배 더 사실적 (42.7% vs 7.1%)
- RAG가 BART보다 2배 이상 구체적 (37.4% vs 16.8%)
- RAG-Token이 여러 문서 정보 결합에 유리함을 보임
문서 사용 분석 (Figure 2)

- RAG-Token의 문서 posterior p(zi|x,yi,y<i) 시각화
- "The Sun Also Rises" 생성 시 문서2 활용
- "A Farewell to Arms" 생성 시 문서1 활용
- 파라메트릭과 비파라메트릭 메모리의 협력 입증
4.4 Fact Verification 결과 (Section 4.4, Table 2)
성능 결과 (Table 2)
| Model | FEVER 3-way | FEVER 2-way |
|---|---|---|
| SOTA | 76.8 | 92.2* |
| BART | 64.0 | 81.1 |
| RAG-Token | 72.5 | 89.5 |
*gold evidence 사용
주요 성과
- 3-way: SOTA 대비 4.3% 이내 (검색 감독 없이)
- 2-way: Gold evidence 모델 대비 2.7% 이내 (claim만으로)
- 복잡한 파이프라인 시스템에 근접한 성능
검색 정확도 분석 (Section 4.4)
- Top-1 문서가 gold article: 71%
- Top-10에 gold article 포함: 90%
4.5 추가 실험 결과 (Section 4.5)
4.5.1 Generation Diversity (Table 5)
Distinct Trigram Ratio (Table 5)
| Model | MS-MARCO | Jeopardy |
|---|---|---|
| Gold | 89.6% | 90.0% |
| BART | 70.7% | 32.4% |
| RAG-Token | 77.8% | 46.8% |
| RAG-Seq. | 83.5% | 53.8% |
발견
- RAG-Sequence가 RAG-Token보다 더 다양
- 둘 다 다양성 촉진 디코딩 없이 BART보다 훨씬 다양
- Jeopardy에서 RAG-Seq: 53.8% vs BART: 32.4% (+21.4%p)
📊 추가 설명: Generation Diversity의 n-gram 비교 (질문 5)
측정 방법
모델이 얼마나 다양한 표현을 사용하는지 측정합니다.
계산 공식:
다양성 = (고유한 3-gram 개수) / (전체 3-gram 개수)예시로 이해하기
BART 생성 (다양성 낮음 - 44%)
생성 결과: 1. "This is a cat" 2. "This is a dog" 3. "This is a bird" 3-gram 분석: - "This is a" (3번 반복됨!) - "is a cat" - "is a dog" - "is a bird" 계산: 고유 3-gram: 4개 전체 3-gram: 9개 다양성 = 4/9 = 44.4%RAG 생성 (다양성 높음 - 100%)
생성 결과: 1. "A feline animal" 2. "Canine species here" 3. "Bird flying overhead" 3-gram 분석: - "A feline animal" - "Canine species here" - "species here" - "Bird flying overhead" - "flying overhead" (모든 3-gram이 다름!) 계산: 고유 3-gram: 9개 전체 3-gram: 9개 다양성 = 9/9 = 100%실험 결과 해석
- MS-MARCO: RAG-Seq 83.5% vs BART 70.7%
- RAG가 12.8%p 더 다양한 표현 사용
- Jeopardy: RAG-Seq 53.8% vs BART 32.4%
- RAG가 21.4%p 더 다양한 표현 사용
의미
- RAG는 같은 표현을 반복하지 않고 더 풍부한 어휘와 구조 사용
- 외부 문서에서 다양한 표현 방식을 학습
- 다양성 촉진 디코딩 기법 없이도 자연스럽게 달성
4.5.2 Retrieval Ablations (Table 6)
실험 설계 (Section 4.5)
1. Learned vs Frozen Retrieval: 학습 중 검색기 동결 여부
2. Dense (DPR) vs BM25: 신경망 검색 vs 단어 중복 검색
Learned vs Frozen 결과 (Table 6 - Dev Set)
| Model | NQ | TQA | WQ | CT |
|---|---|---|---|---|
| RAG-Token | 43.5 | 54.8 | 46.5 | 51.9 |
| RAG-Token-Frozen | 37.8 | 50.1 | 37.1 | 51.1 |
| RAG-Seq. | 44.0 | 55.8 | 44.9 | 53.4 |
| RAG-Seq.-Frozen | 41.2 | 52.1 | 41.8 | 52.6 |
발견: 모든 작업에서 학습된 검색이 성능 향상
❄️ 추가 설명: Retrieval Ablations의 Frozen (질문 7)
Frozen이란?
Frozen = 검색기를 얼려서(고정해서) 학습하지 못하게 함
비교 예시로 이해하기
시나리오: "대통령이 누구인가?" 질문에 답하기
일반 RAG 학습 (검색기 학습 O)
초기 상태: 질문: "대통령이 누구인가?" 검색: 스포츠 문서, 요리 문서 검색 (❌ 관련 없음) 학습 진행 중: 모델이 틀린 답변 → 손실 발생 → 검색기 업데이트 학습 후: 질문: "대통령이 누구인가?" 검색: 정치 문서, 정부 문서 검색 (✓ 정확함) → 검색기가 점점 똑똑해짐! 작업에 맞는 문서 찾는 법 학습Frozen RAG (검색기 학습 X)
초기 상태: 질문: "대통령이 누구인가?" 검색: 스포츠 문서, 요리 문서 검색 (❌ 관련 없음) 학습 진행 중: 모델이 틀린 답변 → 손실 발생 → 검색기는 고정되어 업데이트 안 됨 생성기만 "이상한 문서로도 답변 만들기" 학습 학습 후: 질문: "대통령이 누구인가?" 검색: 여전히 스포츠 문서, 요리 문서 (❌ 관련 없음) → 검색기는 그대로! 생성기만 필사적으로 학습실제 성능 차이 (Table 6)
모델 Natural Questions 점수 차이 RAG-Token (학습) 43.5 - RAG-Token-Frozen 37.8 -5.7점 결론
- 검색기 학습이 매우 중요함을 입증
- 작업에 맞는 문서를 찾는 능력이 성능에 큰 영향
- 엔드-투-엔드 학습의 효과를 보여줌
Dense vs BM25 결과 (Table 6 - Dev Set)
| Model | NQ | TQA | WQ | FEVER-3 |
|---|---|---|---|---|
| RAG-Token | 43.5 | 54.8 | 46.5 | 74.5 |
| RAG-Token-BM25 | 29.7 | 41.5 | 32.1 | 75.1 |
발견
- FEVER 제외 모든 작업에서 Dense Retrieval 우수
- FEVER는 엔티티 중심적이어서 BM25 유리
- Open-Domain QA에서 Dense Retrieval 특히 중요
4.5.3 Index Hot-Swapping (Section 4.5)
실험 설계
- 2016년 12월 vs 2018년 12월 Wikipedia 인덱스
- 82명의 변경된 세계 지도자 리스트
- 질문: "Who is {position}?" (예: "Who is the President of Peru?")
결과
| 인덱스 | 질문 대상 | 정확도 |
|---|---|---|
| 2016 | 2016 지도자 | 70% |
| 2018 | 2018 지도자 | 68% |
| 2018 | 2016 지도자 | 12% |
| 2016 | 2018 지도자 | 4% |
의미: 비파라메트릭 메모리만 교체하여 RAG의 세계 지식 업데이트 가능
🔄 추가 설명: Index Hot-Swapping 이해 확인 (질문 6)
실험의 핵심 개념
RAG 구성
- RAG = 생성기(BART) + 검색 인덱스(Wikipedia)
- 이 실험은 검색 인덱스만 교체, 생성기는 재학습 없이 그대로 유지
실험 과정
1단계: 준비 - 2016년 Wikipedia → 인덱스 A 생성 - 2018년 Wikipedia → 인덱스 B 생성 - 생성기: 동일한 BART 모델 (학습 없음!) 2단계: 테스트 - 2016년 지도자 질문 + 인덱스 A → 70% 정확 - 2018년 지도자 질문 + 인덱스 B → 68% 정확 - 2016년 지도자 질문 + 인덱스 B → 12% 정확 (불일치) - 2018년 지도자 질문 + 인덱스 A → 4% 정확 (불일치)구체적 예시
질문: "Who is the President of Peru?" 2016년 인덱스 + 2016년 질문: → 검색: "Ollanta Humala is President" 문서 → 생성: "Ollanta Humala" ✓ (70% 성공률) 2018년 인덱스 + 2018년 질문: → 검색: "Martín Vizcarra is President" 문서 → 생성: "Martín Vizcarra" ✓ (68% 성공률) 2018년 인덱스 + 2016년 질문: → 검색: "Martín Vizcarra is President" 문서 (2018 정보) → 생성: "Martín Vizcarra" ✗ (2016년엔 틀림, 12% 성공률)기존 모델과의 비교
파라메트릭 모델 (T5, BART만)
- 새 지식 학습: 재학습 필요
- 시간: 수 시간 ~ 수 일
- 비용: GPU 비용 높음
- 과정: 데이터 수집 → 재학습 → 검증 → 배포
RAG (검색 인덱스 활용)
- 새 지식 업데이트: 인덱스만 교체
- 시간: 수 분 (인덱싱 시간)
- 비용: 매우 낮음
- 과정: 새 Wikipedia → 인덱싱 → 교체 완료
실용적 의미
- 마치 백과사전을 최신판으로 교체하는 것처럼 간단
- 모델 자체는 건드리지 않고 지식만 업데이트
- 실시간 정보 반영 가능 (뉴스, 최신 사건 등)
4.5.4 검색 문서 수의 영향 (Figure 3)
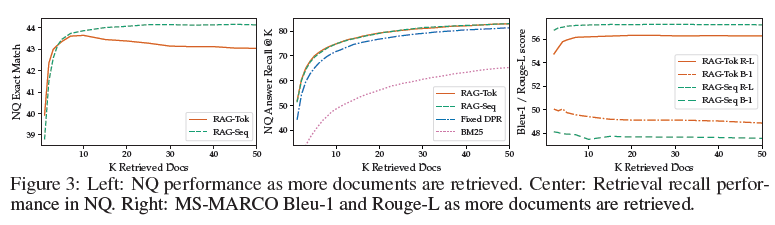
실험 설정 (Section 4.5)
- 학습: k ∈ {5, 10} (성능 차이 미미)
- 테스트: k 조정하여 성능/실행시간 트레이드오프 분석
Open-Domain QA 성능 (Figure 3 - Left)
- RAG-Sequence: k 증가 시 성능 단조 증가
- K=10: ~42점
- K=50: ~44점
- RAG-Token: k=10에서 성능 정점
- K=10: ~44점
- K>10: 성능 향상 없음
검색 Recall (Figure 3 - Center)
- k 증가 시 recall 향상 (더 많은 문서에서 정답 발견)
- RAG가 고정 DPR, BM25보다 우수한 recall
MS-MARCO 생성 품질 (Figure 3 - Right)
- RAG-Token:
- K 증가 → Rouge-L 향상, Bleu-1 감소
- 더 많은 정보 사용하지만 정확도는 trade-off
- RAG-Sequence:
- K 변화에 덜 민감
- 안정적인 성능 유지
Part 3: 결론 및 논의 (Section 6: Discussion)
주요 기여 (Section 6)
1. 하이브리드 생성 모델 제안
- 파라메트릭(모델 파라미터)과 비파라메트릭(검색) 메모리 결합
- seq2seq 아키텍처에 검색 증강 적용
2. State-of-the-Art 성능
- Open-domain QA에서 SOTA 달성
- 다양한 지식 집약적 작업에서 우수한 성능
3. 생성 품질 향상
- 인간 평가: BART 대비 더 사실적이고 구체적
- 환각 감소, 사실성 증가
4. 학습된 검색 컴포넌트 검증
- 검색 메커니즘의 효과 입증
- 엔드-투-엔드 학습의 중요성 확인
5. 지식 업데이트 메커니즘
- Hot-swapping을 통한 재학습 없는 지식 업데이트
- 파라메트릭 모델 대비 유연성
파라메트릭 vs 비파라메트릭 메모리 (Section 1, Section 6)
파라메트릭 메모리 (BART-400M)
- 장점: 빠른 추론, 통합된 지식
- 단점: 업데이트 어려움, 환각 발생, 해석 불가
비파라메트릭 메모리 (Wikipedia 인덱스 21M)
- 장점: 쉬운 업데이트, 해석 가능, 확장 가능
- 단점: 검색 시간 필요
RAG의 결합 효과
- 두 메모리의 장점 활용
- 상호 보완적 작동 (Figure 2 예시)
- 비파라메트릭이 가이드, 파라메트릭이 완성
한계 및 향후 연구 방향 (Section 6)
향후 연구 과제
1. Joint Pre-training: 두 컴포넌트를 처음부터 함께 사전학습
- BART의 denoising objective 또는 다른 objective 사용
-
메모리 상호작용 연구: 파라메트릭과 비파라메트릭 메모리가 어떻게 상호작용하는지
-
효과적 결합 방법: 두 메모리를 가장 효과적으로 결합하는 방법 탐구
-
다양한 NLP 작업 적용: 더 넓은 범위의 NLP 작업에 적용 가능성
사회적 영향 (Broader Impact Section)
긍정적 영향
1. 사실성 향상: 실제 지식(Wikipedia)에 강하게 근거하여 환각 감소
2. 제어 및 해석성: 더 많은 제어와 해석 가능성 제공
3. 실용적 응용: 의료 인덱스 등 다양한 도메인에 적용 가능
잠재적 위험
1. 지식 소스의 편향: Wikipedia도 완전히 사실적이거나 편향이 없지 않음
2. 언어 모델 일반 위험:
- 악용, 가짜/오해 유도 콘텐츠 생성
- 타인 사칭, 스팸/피싱 콘텐츠 자동화
- 일자리 자동화: 향후 다양한 직업 자동화 가능성
완화 방안
- AI 시스템을 통한 오해 유도 콘텐츠 및 스팸/피싱 대응
실험 결과 종합 정리
성능 지표 요약
| 작업 | 주요 성과 | 개선 폭 |
|---|---|---|
| Natural Questions | 44.5% EM | +4.0%p (vs REALM) |
| TriviaQA | 68.0% EM | +7.5%p (vs T5-SSM) |
| MS-MARCO | 44.2 Bleu-1 | +2.6 (vs BART) |
| Jeopardy (인간평가) | 42.7% better | 6배 (vs BART 7.1%) |
| FEVER 3-way | 72.5% Acc | -4.3%p (vs SOTA) |
| Generation Diversity | 83.5% (trigram) | +12.8%p (vs BART) |
핵심 실험적 발견
1. 생성형 접근이 추출형보다 유연하고 효과적
2. 학습된 검색이 고정 검색보다 5.7%p 향상 (NQ)
3. Dense retrieval이 BM25보다 대부분 작업에서 우수
4. 인덱스 교체만으로 지식 업데이트 가능 (70% → 4% 정확도 변화)
5. RAG-Token vs RAG-Sequence는 작업 특성에 따라 선택
부록: 질문 요약
본 문서에 포함된 추가 설명들:
- 질문 1: Table 1의 평가 지표 (Exact Match) → Section 3.1
- 질문 2: 추출형 vs 생성형 다운스트림 작업 → Section 3.1
- 질문 3: SSM (Salient Span Masking) → Section 3.1
- 질문 4: RAG-Token vs RAG-Sequence 차이 → Section 3.3
- 질문 5: Generation Diversity n-gram 비교 → Section 4.5.1
- 질문 6: Index Hot-Swapping 이해 → Section 4.5.3
- 질문 7: Retrieval Ablations의 Frozen → Section 4.5.2
- 질문 8: 잠재 문서(Latent Documents) → Section 3 (실험 공통 설정)
