

- 이번 강의에서는 지난시간에 배운 word2vec을 마무리하고 GloVe를 배운다.
- Manning 교수님이 진행하는 강의인데 본인이 쓴 논문이라 GloVe를 열심히 소개하는 듯.
- 클래스가 끝난 후에는 word embeddings paper를 읽을 수 있게 되는 것이 목표라고 한다. 지금까지 읽으려고 시도는 종종 했지만 100% 이해한 적은 없다.. 열심히 들어야지.
-
word2vec 돌아보기
-
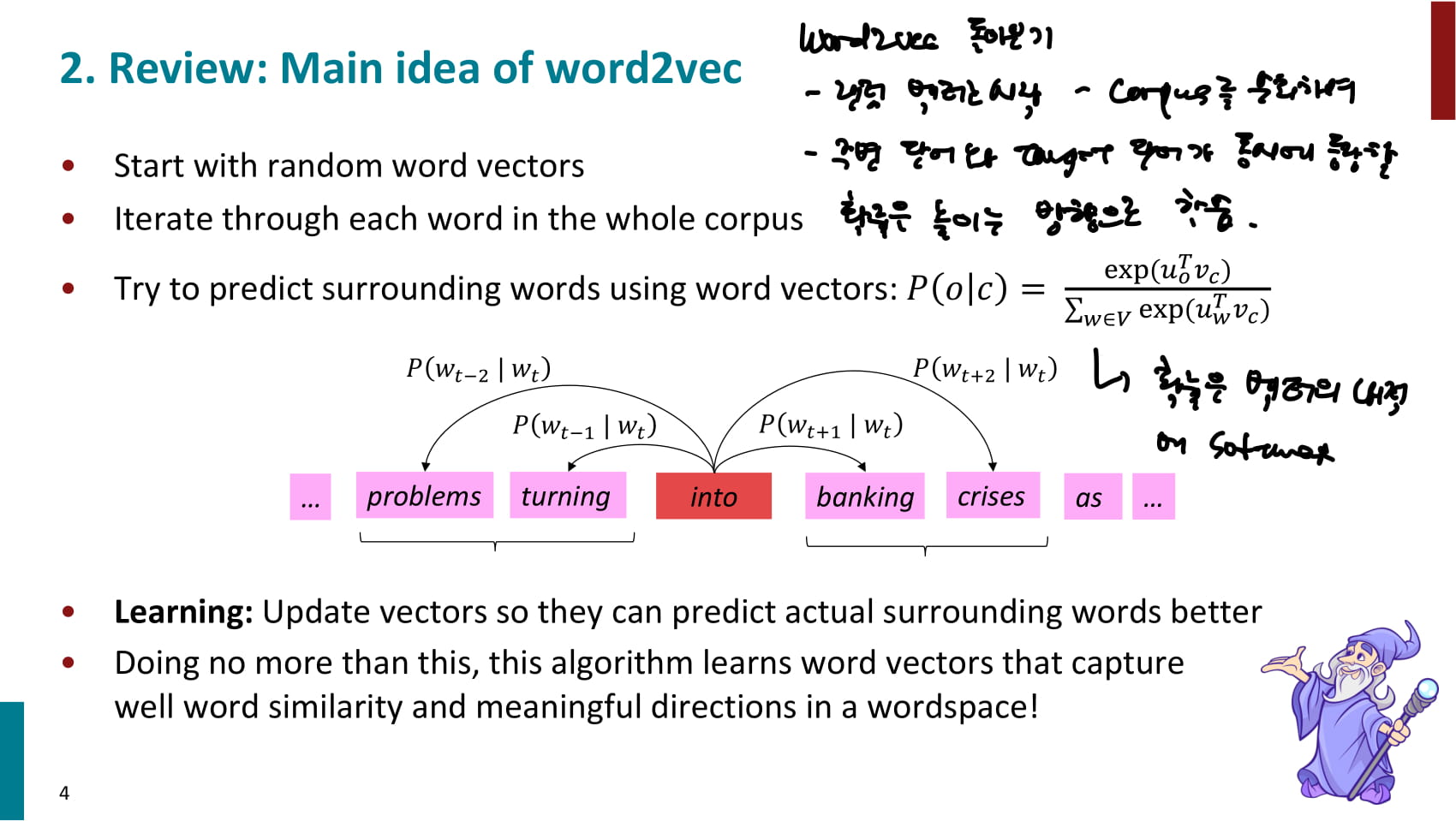
랜덤 벡터로 시작하여, corpus를 순회하며 target word가 등장했을 때 window 안에 context word가 등장할 확률을 높이는 방향으로 학습한다.
-
이 때 동시 등장 확률은 다음과 같이 계산한다.
-
: context word의 벡터를 전치한 것 과 center word의 벡터 를 내적한 후 exponential을 구한다.
-
는 배열 x의 각 요소에 대해 를 반환한다. 는 자연상수.
-
자연상수가 밑인 지수함수를 미분한 결과는 그 자신이다.
-
이런 특성으로 인해 자연상수를 밑으로 사용하면 미분 결과가 깔끔해지고 목적함수에 집어넣어도 기울기를 발생시켜 역전파가 용이해진다.
-
-
: 모든 context word에 대해 를 구하고 더해 분자 값을 나눈다.
-
벡터의 내적에 softmax 함수를 적용한 것과 같은 효과
-
-
-
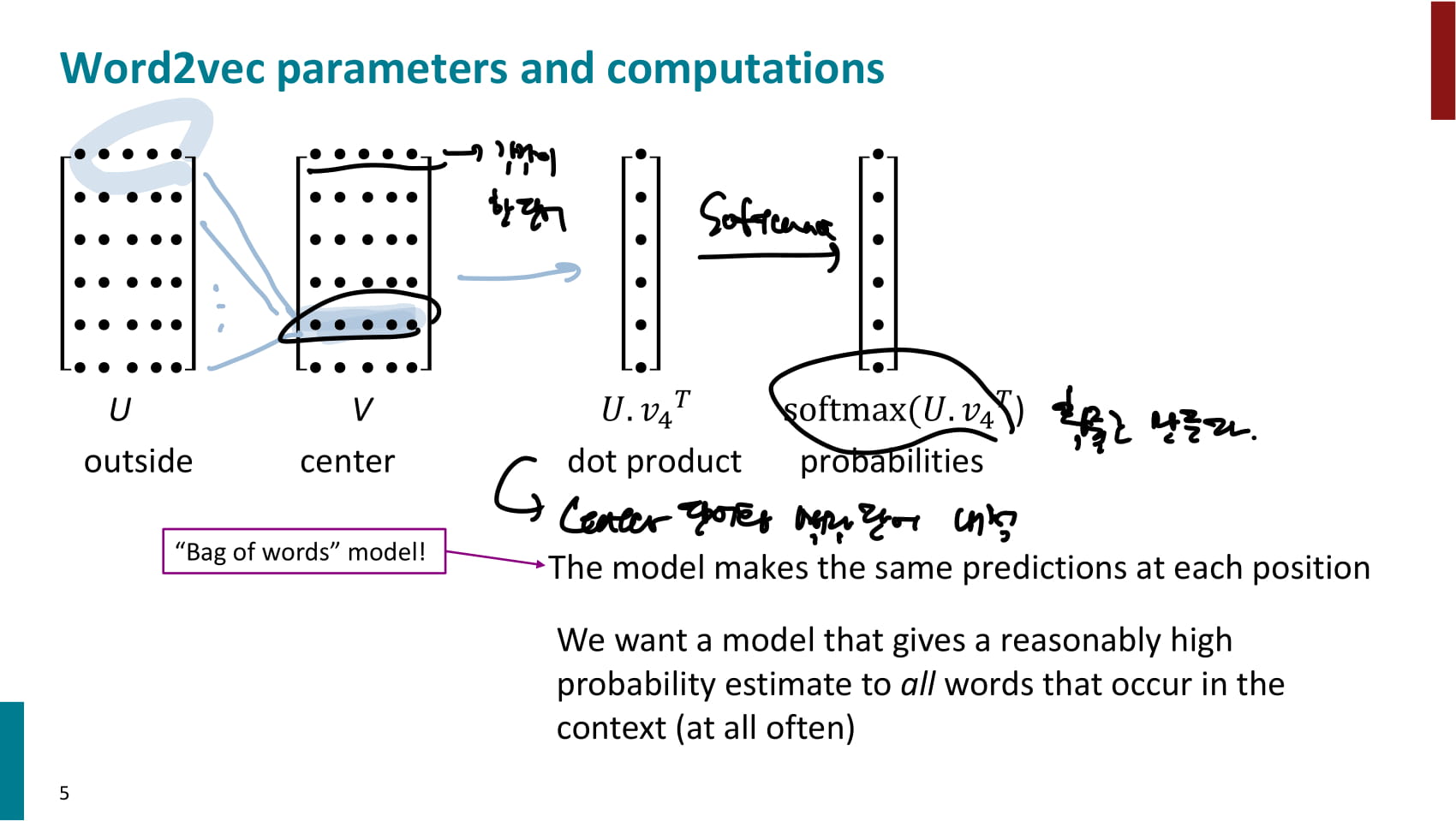
예시 시각화. center word 각각에 대해 outside word 들의 벡터를 내적하고, 내적한 결과에 softmax를 적용한다.

-
결과 벡터 시각화 예시
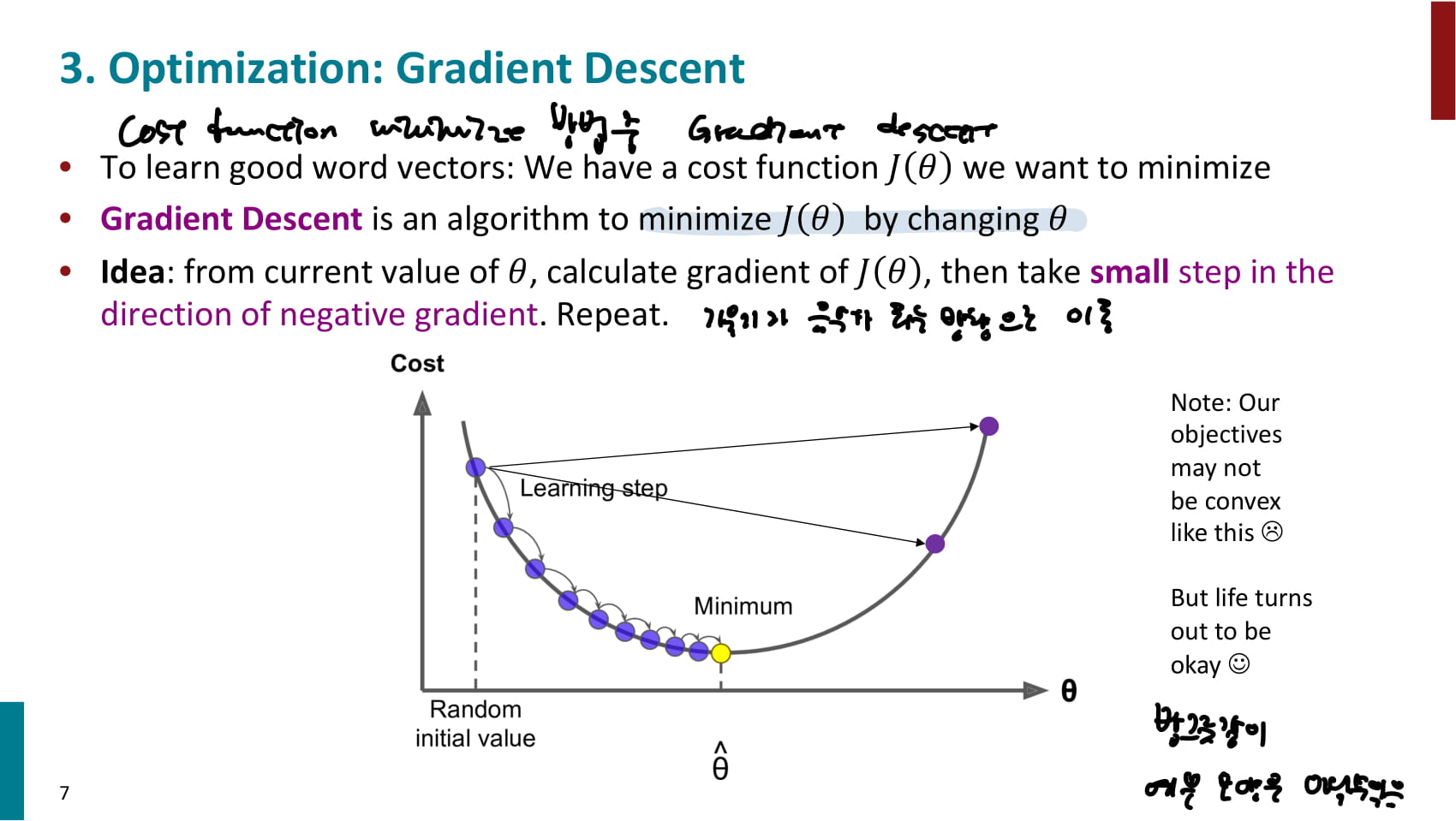
- Gradient descent에 대해서도 다시 설명한다. 목적함수를 최적화하는 여러 방법이 있는데, 그 중 하나가 Gradient descent이다.
- 현재 값 (현재 파라미터)에서 목적함수의 기울기를 계산하고, 기울기가 하강하는 방향으로 이동한다.

- 는 learning rate, 즉 gradient descent를 얼마나 강하게 반영할것인지 결정
- 목적함수를 미분한 결과가 양수인 경우 에서 양수를 빼게 되기 때문에 그래프 상에서 는 왼쪽으로 이동한다.
- 목적함수를 미분한 결과가 음수인 경우 에서 음수를 빼게 되기 때문에 그래프 상에서 는 오른쪽으로 이동한다.

-
지금까지 소개한 Gradient descent도 단점이 있다. corpus의 모든 단어에 대해 window 안의 단어들과 목적함수의 미분을 수행하기 때문에 corpus가 커질수록 비효율적이라는 것.
-
여기에서 Stochastic gradient descent (SGD)가 등장한다. SGD는 미니 배치 방식처럼 window를 샘플링하며 여러 번 Gradient descent를 수행한다.
-
앙상블처럼 여러번 GD를 수행한 결과를 평균내기 때문에 노이즈가 적으며 더 중요한 장점은 각 미니배치가 독립적으로 수행될 수 있기때문에 병렬연산이 가능하다는 점이다.

-
하지만 SGD를 사용하는 경우에도 문제가 발생하는데.. 샘플링을 하기 때문에 연산을 하는 파라미터 개수에 비해 실제 존재하는 값이 적기 때문에 연산이 비효율적이다.

-
이를 해결하기 위해서는 두 가지 방법을 사용할 수 있는데, 하나는 값이 존재하는 row의 인덱스를 저장해놨다가 해당 row만 업데이트하는 것이고, 다른 하나는 word vector를 해싱하는 방법이다.

-
기타 word2vec에 대한 부연설명
- 한 단어에 대해 두 vector(context word일때의 vector와 target word일때의 vector)를 유지하는 것은 계산하기가 더 쉬워지기 때문
- Skip-gram과 CBOW 두 가지 모델이 있다. 우리가 계속 보고있는 예시는 skip-gram임.
-
지금까지 학습한 방법은 naive softmax로 간단하지만 느린 방법이다. negative sampling을 통해 성능을 향상시킬 수 있다.

-
위에서 본 의 normalization term인 은 계산하기 매우 비싸다. vocab의 모든 단어 벡터에 대해 현재 단어의 벡터와 내적을 하고 exponential해 더해줘야 한다.
-
negative sampling의 핵심 아이디어는 이런 계산을 이진 분류 문제로 만드는 것이다. 즉, context word는 target word와 등장할 확률을 높이는 동시에 window 밖에 있는 단어는 target word와 등장할 확률을 낮춘다.


- negative sampling의 목적함수는 위와 같다.
- : context word와 target word의 내적의 합이 클수록 0에 가까워진다.
- : context 밖 word와 target word의 내적의 합이 작을수록 0에 가까워진다.
- 즉 context word와 target word는 가까울수록, outside word와 target word는 멀수록 목적함수가 작아진다.
- 여기에서 많이 등장하는 단어가 많이 샘플링될 수 있기 때문에 단어의 수를 센 후 3/4승을 해 고르게 샘플링되도록 해준다.

- word2vec 소개는 할만큼 한 것 같고, GloVe 얘기를 하기 위해 co-occurrence count 얘기를 꺼내며 시동을 건다.
- co-occurrence matrix는 두 가지 방법으로 만들 수 있다.
- window 기반: word2vec과 유사하게 각 단어 주변 단어를 window로 사용하여 동시등장 카운트
- word-documnt 기반: 같은 문서에 등장한 단어들을 동시등장 단어로 카운트한다.
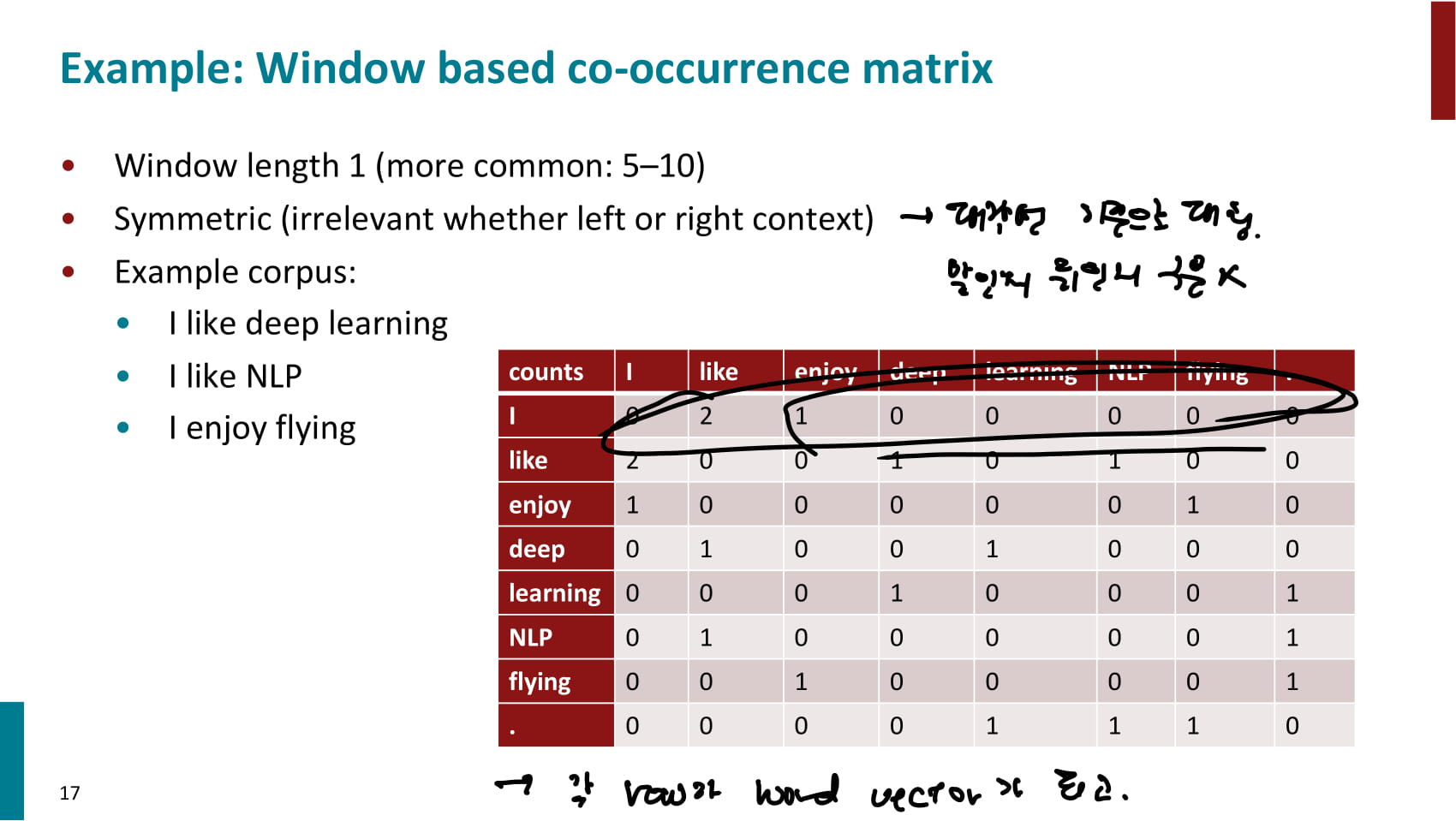
- window 기반 co-occurrence matrix 예시(window 크기 1)
- 각 row가 word vector가 되며, 유사한 단어의 vector 또한 유사할거라 가정한다.

- window 기반이든 document 기반이든 단순히 동시등장 횟수를 카운트해 사용하는 방법은 비효율적이다
- vocab 사이즈에 비례하여 word vector 사이즈도 증가
- sparse한 고차원 벡터이기 때문에 많은 공간을 비효율적으로 사용한다.
- model이 덜 robust하다. 이상치에 쉽게 영향을 받을 것 같다.
- 이를 해결하기 위해 SVD, LSA 등의 기법을 통해 정보를 보존하며 co-occurrence matrix를 줄여 dense vector로 만들 수 있다.
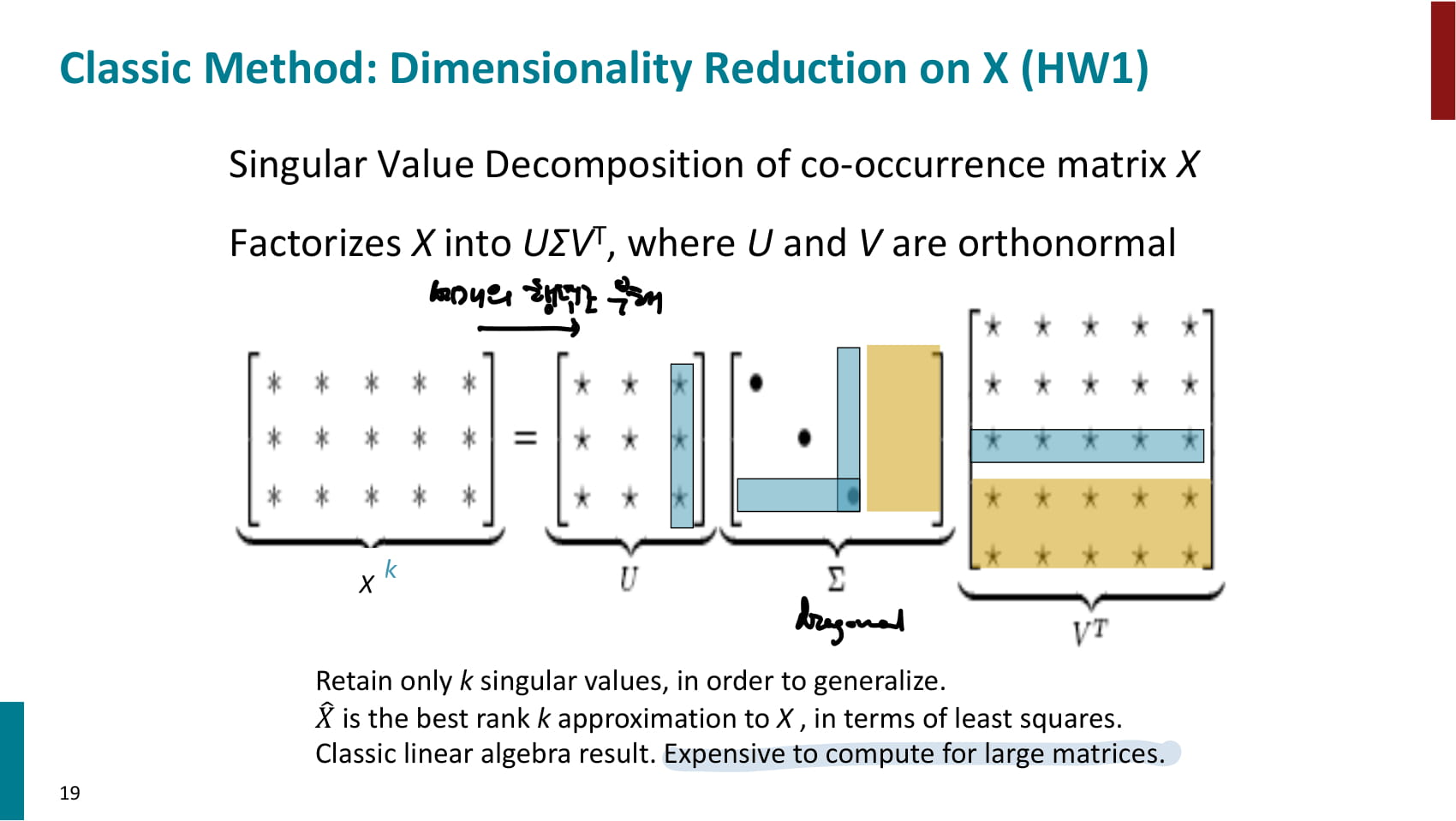

- 단순히 카운트에 SVD를 적용하는 것보다는, 여러가지 방법을 카운트를 가공해주는 것이 성능을 향상시켰다.
- the, he, has 등 너무 흔하게 등장하는 단어를 보정하기 위해 log를 취하거나, ceiling하거나, 아예 무시하는 방법 사용
- 가까운 단어에 더 많은 점수 부여
- 피어슨 상관계수 이용

- 본격적인 GloVe 소개 시작
- 지금까지 본 word embedding 기법에는 두 가지 방식이 있었다.
- Count based
- 훈련이 빠르다.
- 통계 정보를 효율적으로 사용한다.
- 주로 유사도 측정에 사용된다.
- 많이 등장하는 단어에 편향될 수 있다.
- direct prediction
- 다양한 과제에서 비교적 잘 동작한다.
- 유사도 이외의 복잡한 패턴을 잘 잡아낼 수 있다.
- 통계 정보를 효율적으로 사용하지 못한다. count based 기법의 경우 window 밖에 있는 단어의 통계정보도 전반적으로 사용할 수 있다.
- 두 가지를 합쳐 더 좋은 방법을 만들어보자!
- Count based
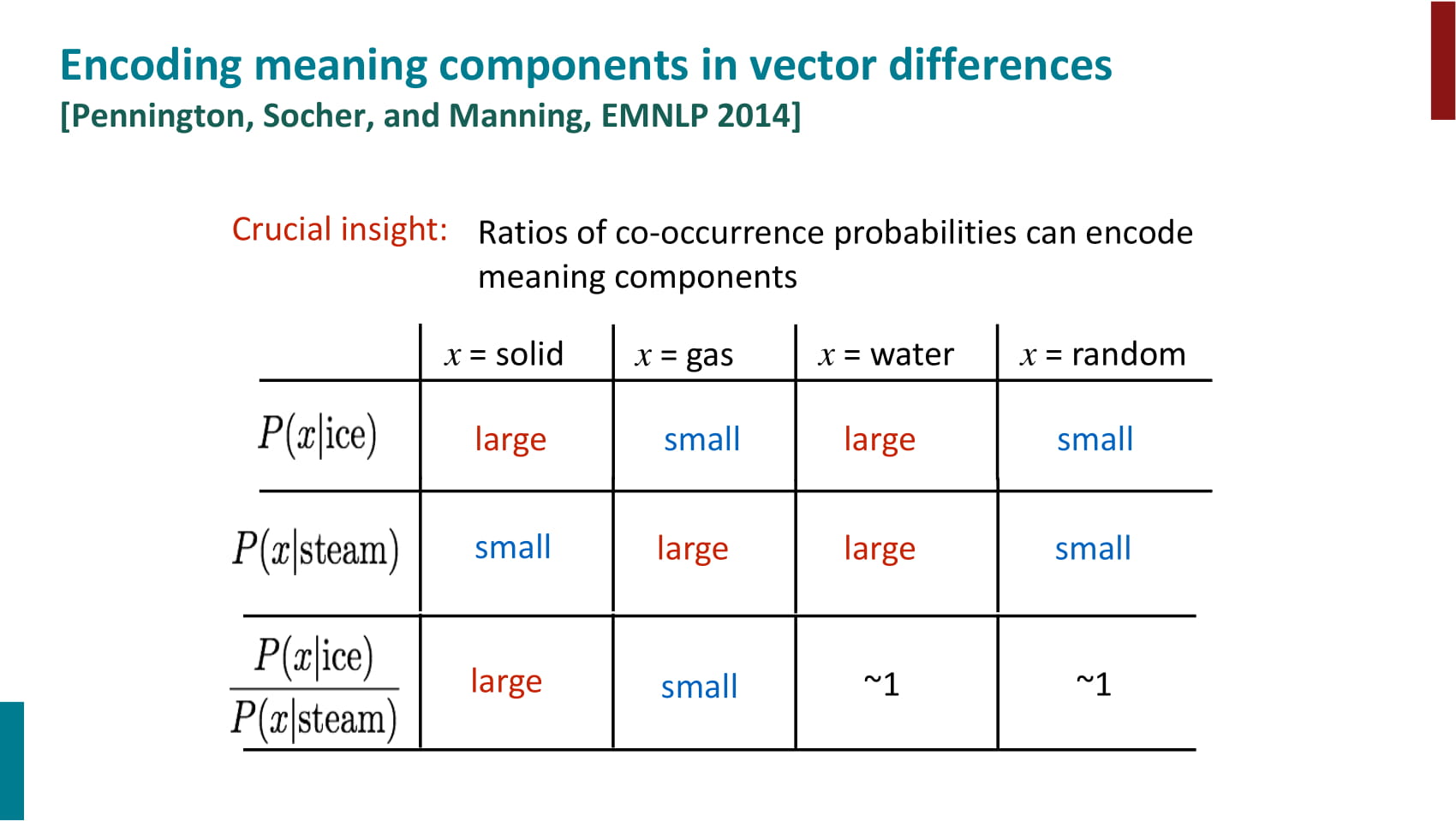
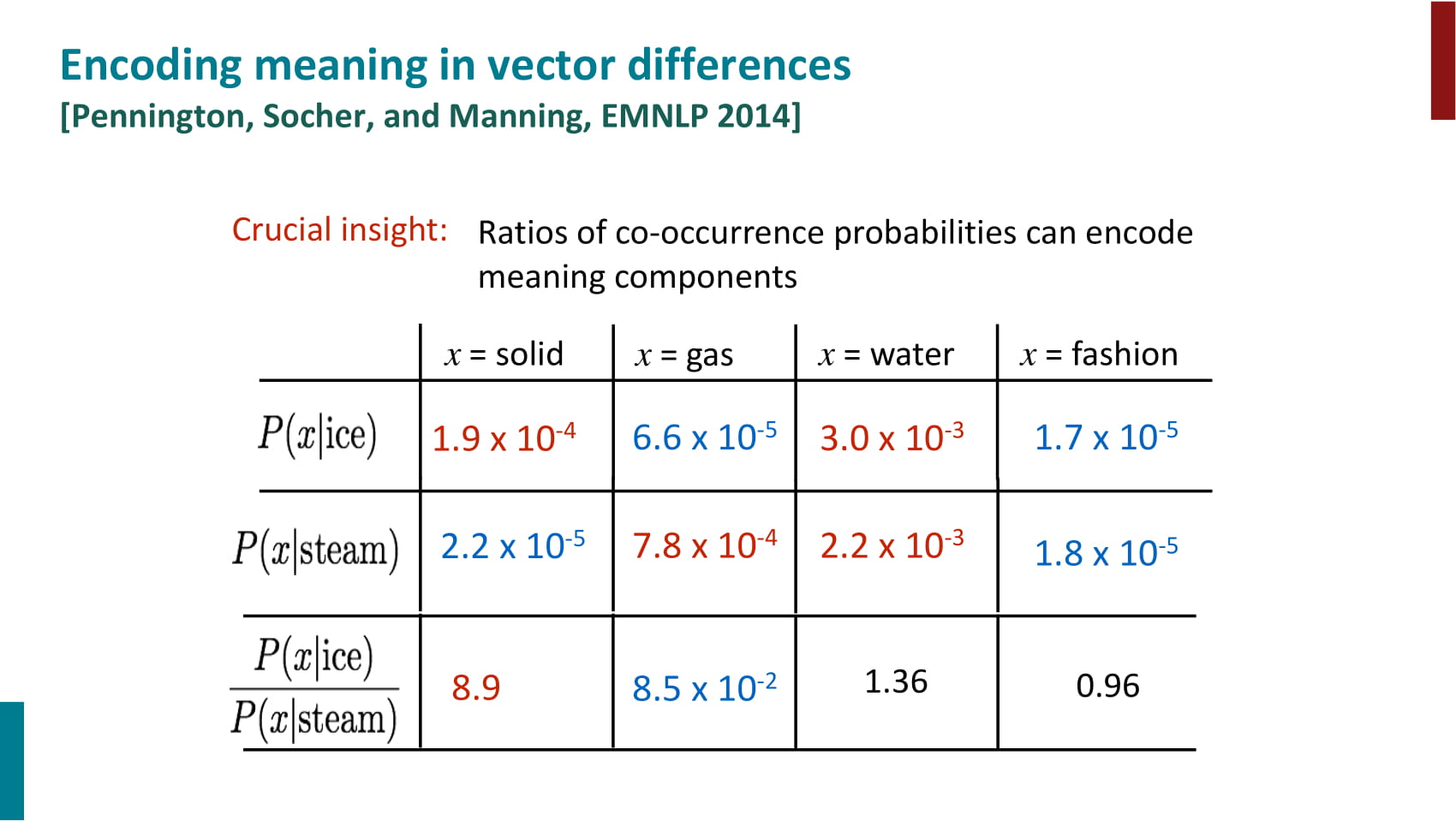


- word count를 사용하되 direct prediction처럼 iterative하게 vector를 업데이트하는 방식
- 목적함수가 복잡해보이지만, bias를 빼고 보면 context word와 target word 벡터의 내적에서 동시등장확률의 로그값을 빼는 내용
- 즉, 두 벡터의 내적을 동시등장확률의 로그값에 가깝게 만든다.

- 성능도 괜찮은 것 같다는 자랑

- 성능이 괜찮은 것 같긴 한데, word vector의 성능은 어떻게 평가할 수 있을까?
- intrinsic 방법
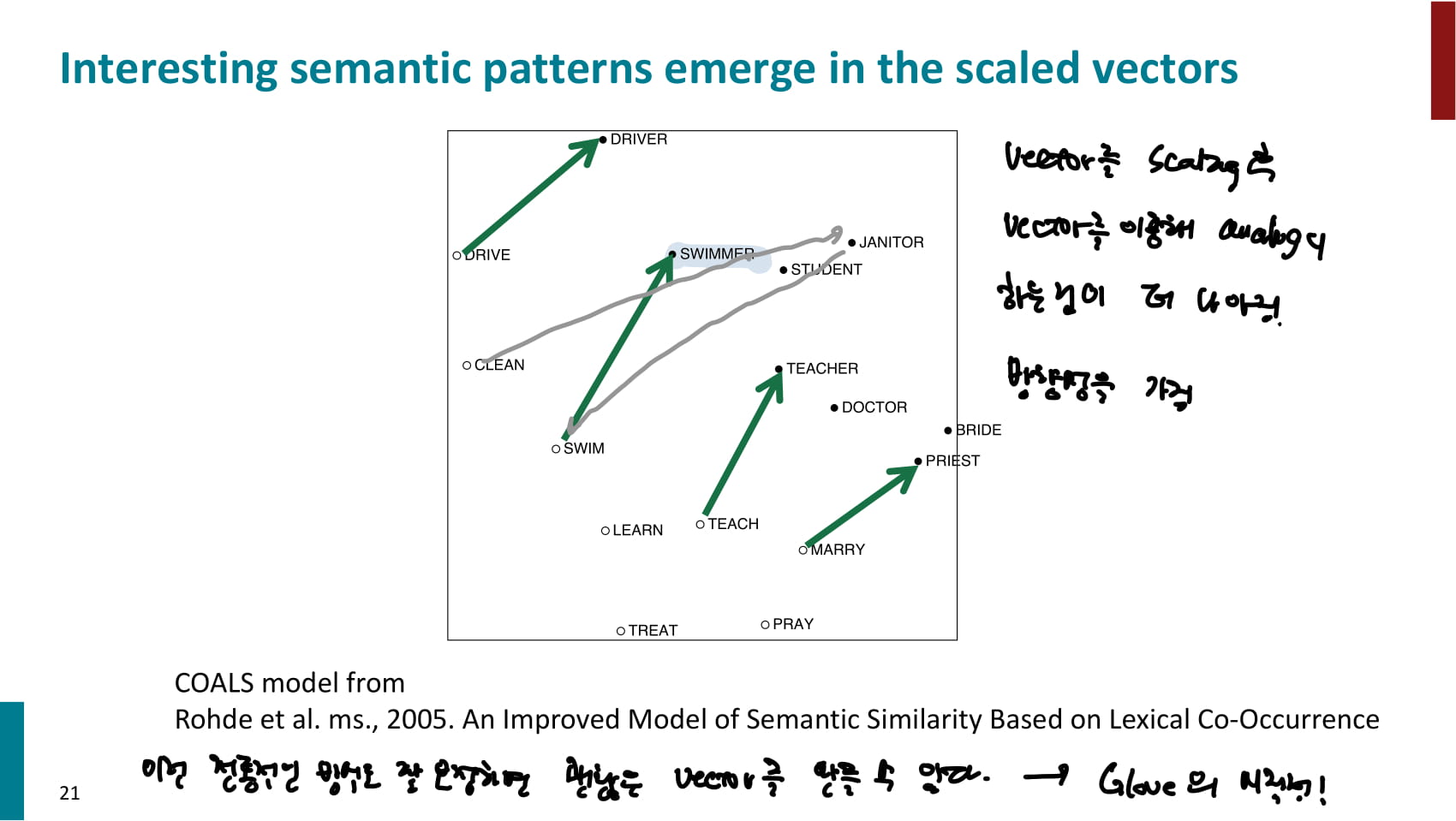
- 예시: 위 개구리 예시와 같이 유의어가 실제로 가깝게 훈련되었는지 확인한다.
- 비교적 작은 과제에 대해 수행된다.
- 빠르게 검증할 수 있다.
- 문제가 있는 경우 원인을 비교적 쉽게 파악할 수 있다.
- 실제로 적용하려는 과제에서 잘 작동할지는 알 수 없다.
- extrinsic 방법
- 검색, 질의응답 시스템 등 실제 과제에 적용한다.
- 시간이 더 오래 걸린다.
- 성능이 안나오는 경우 뭐때문에 안나오는지 알기 힘들다.
- intrinsic 방법
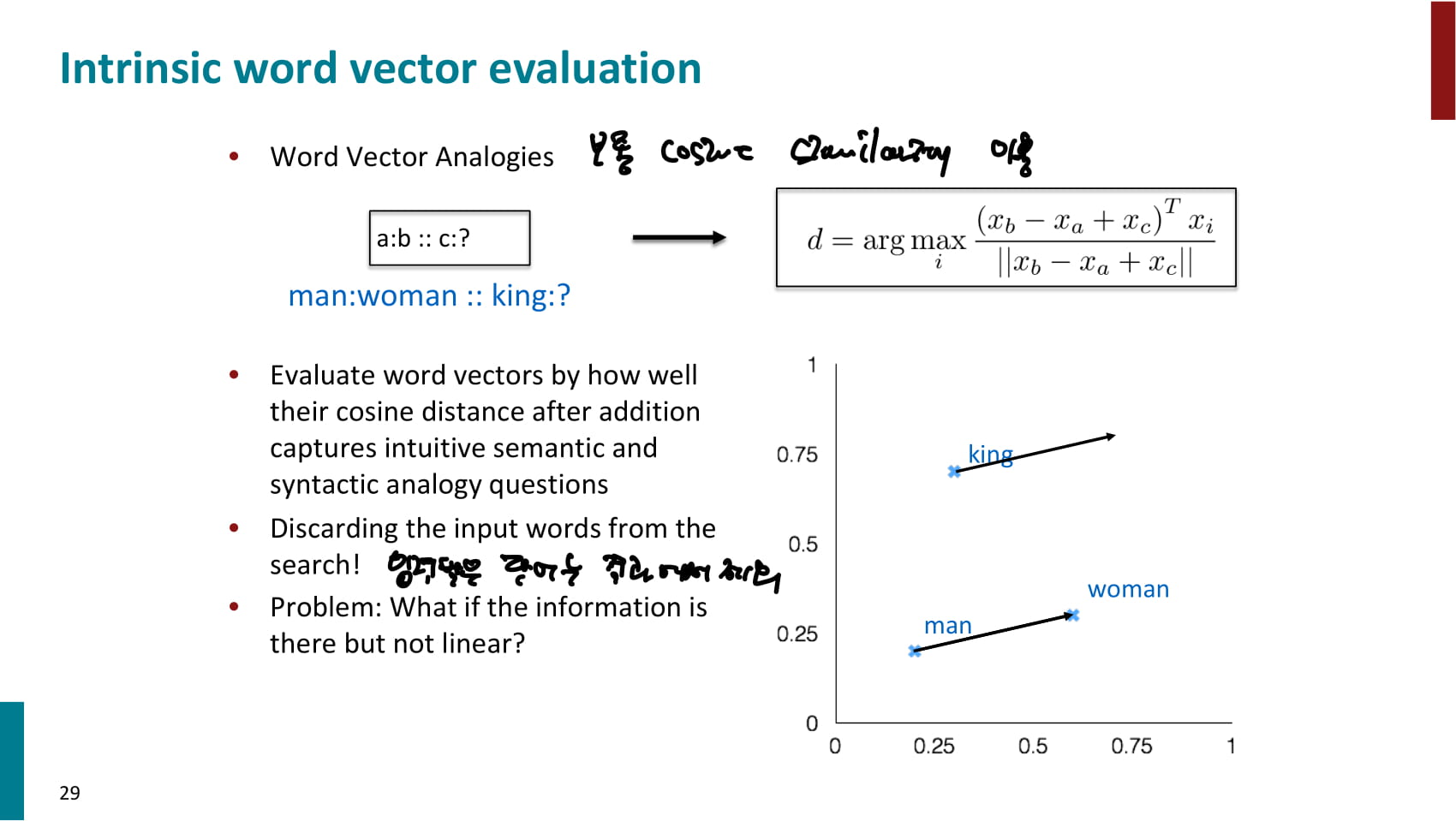
- intrinsic 방법 중 하나 - word vector analogies
- 단어의 관계를 word vector가 잘 나타내는지를 평가할 수 있다.
- 쿼리로 사용된 단어는 결과에서 제외해야 한다.
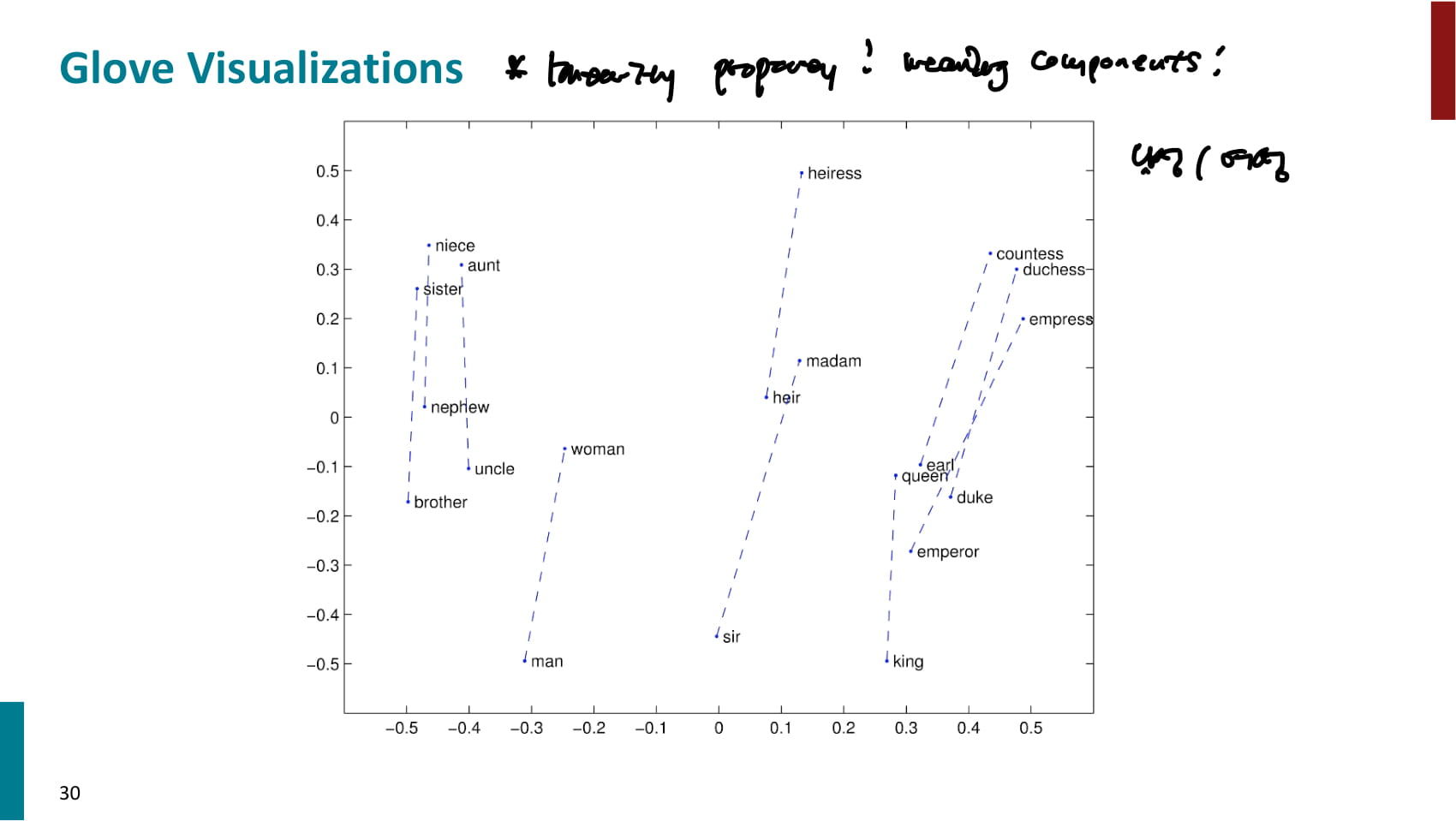
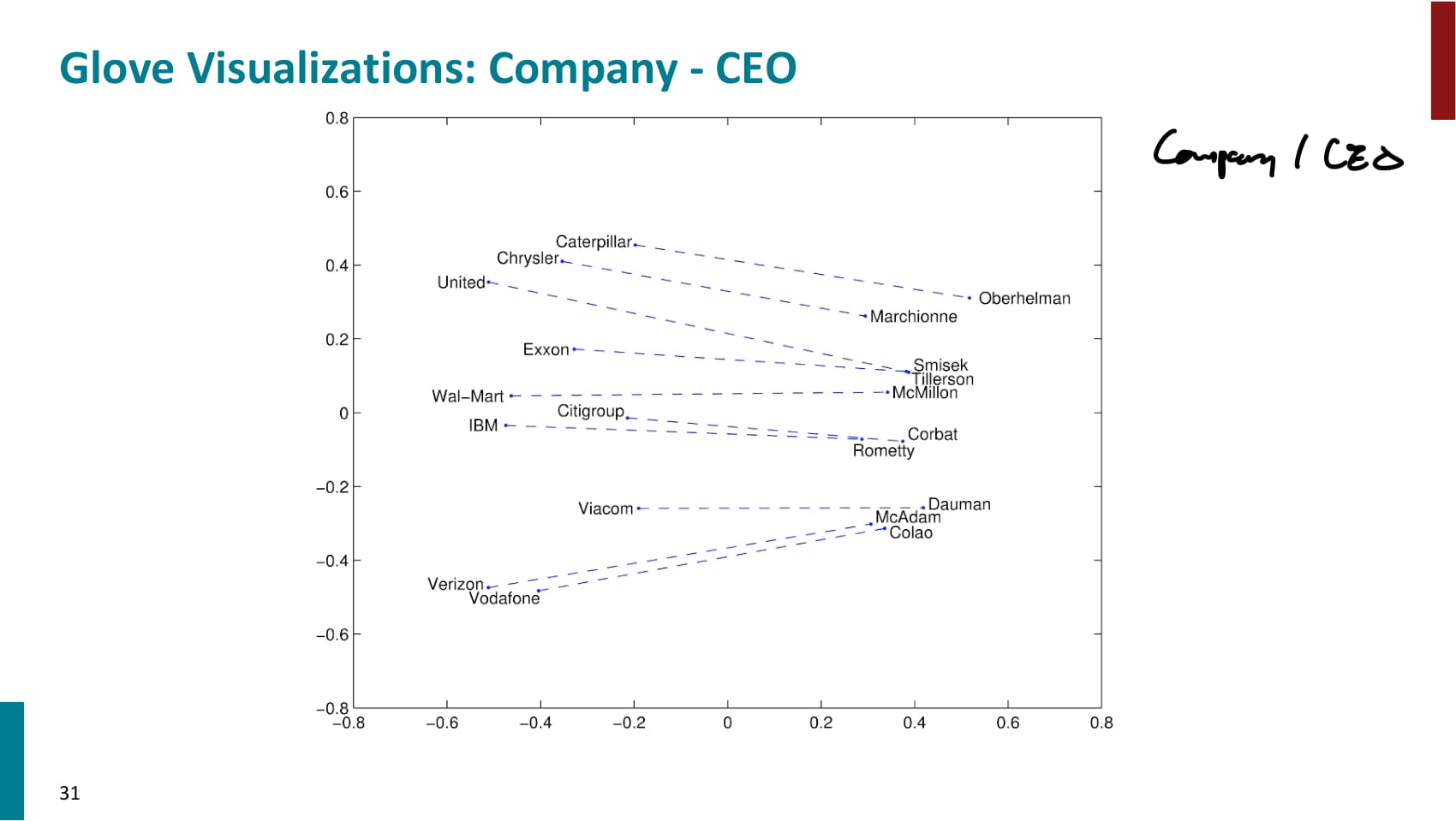
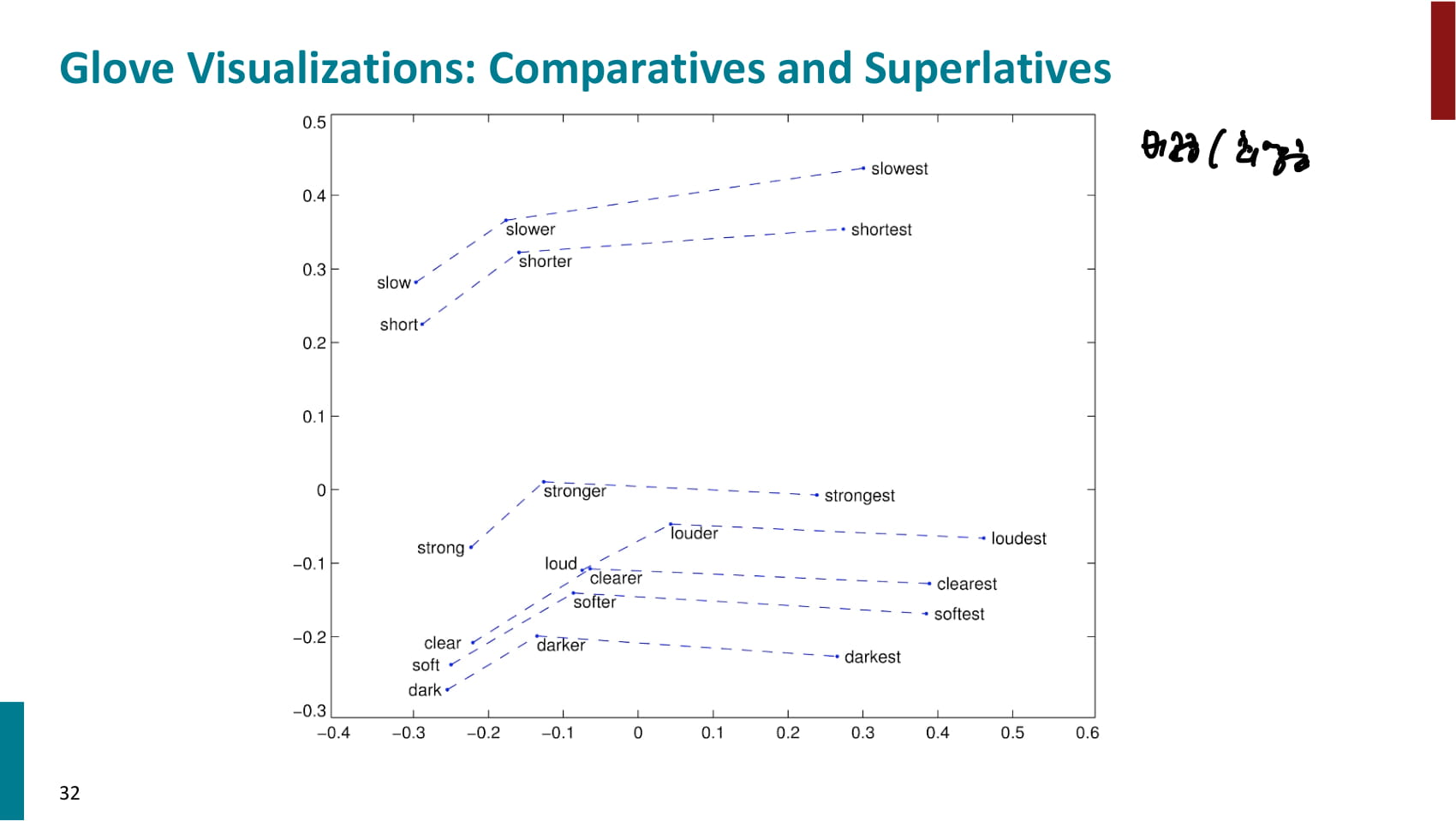
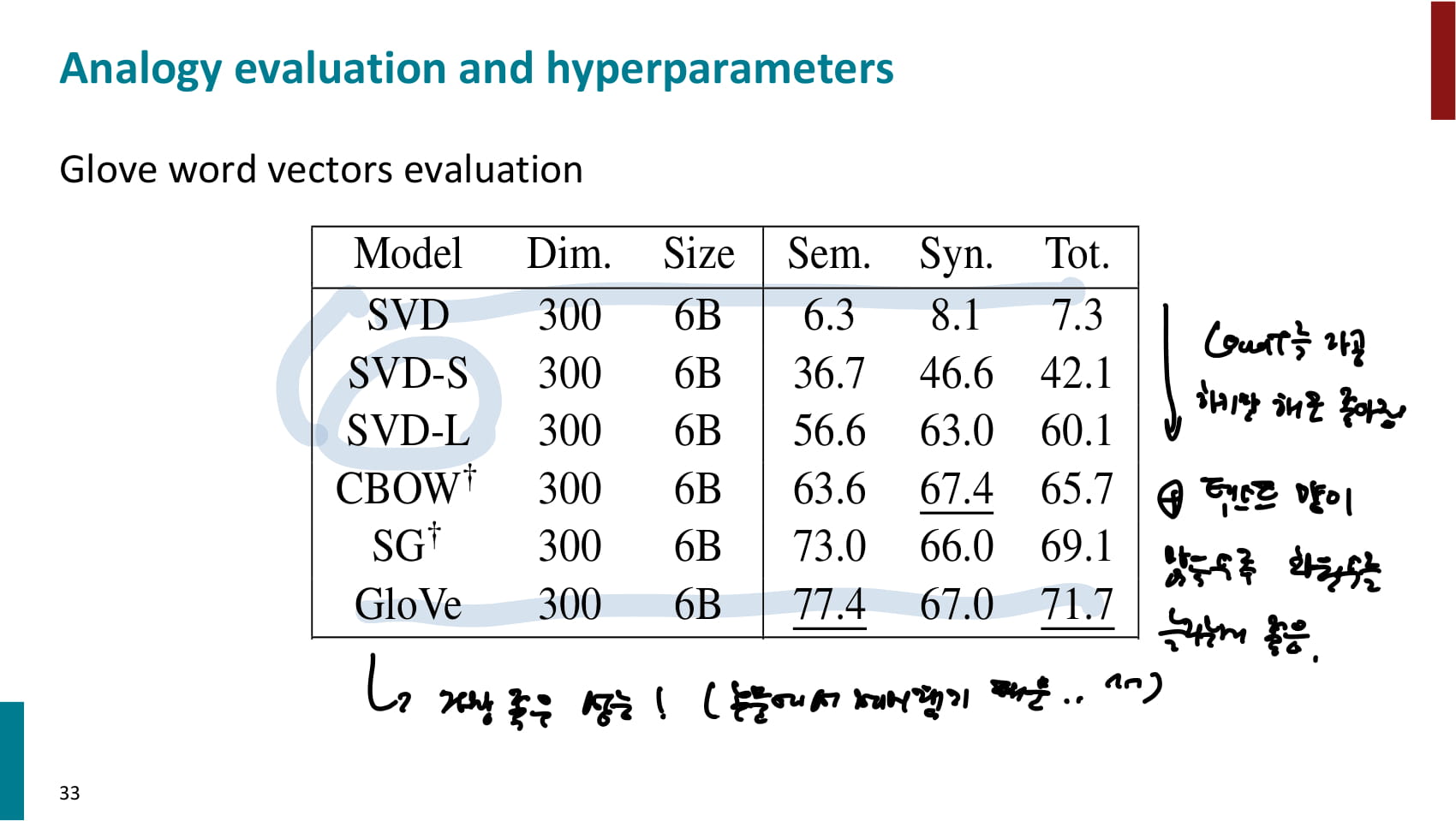
- 교수님이 만든 GloVe가 가장 좋은 성능을 냈다는 자랑. 물론 해당 논문에서 제시한 결과니까 당연하다.
- 흥미로운 것은 순수 SVD의 성능은 안좋았지만, 동시 등장 횟수를 가공하기만 해도 성능이 꽤 좋아졌다는 점.
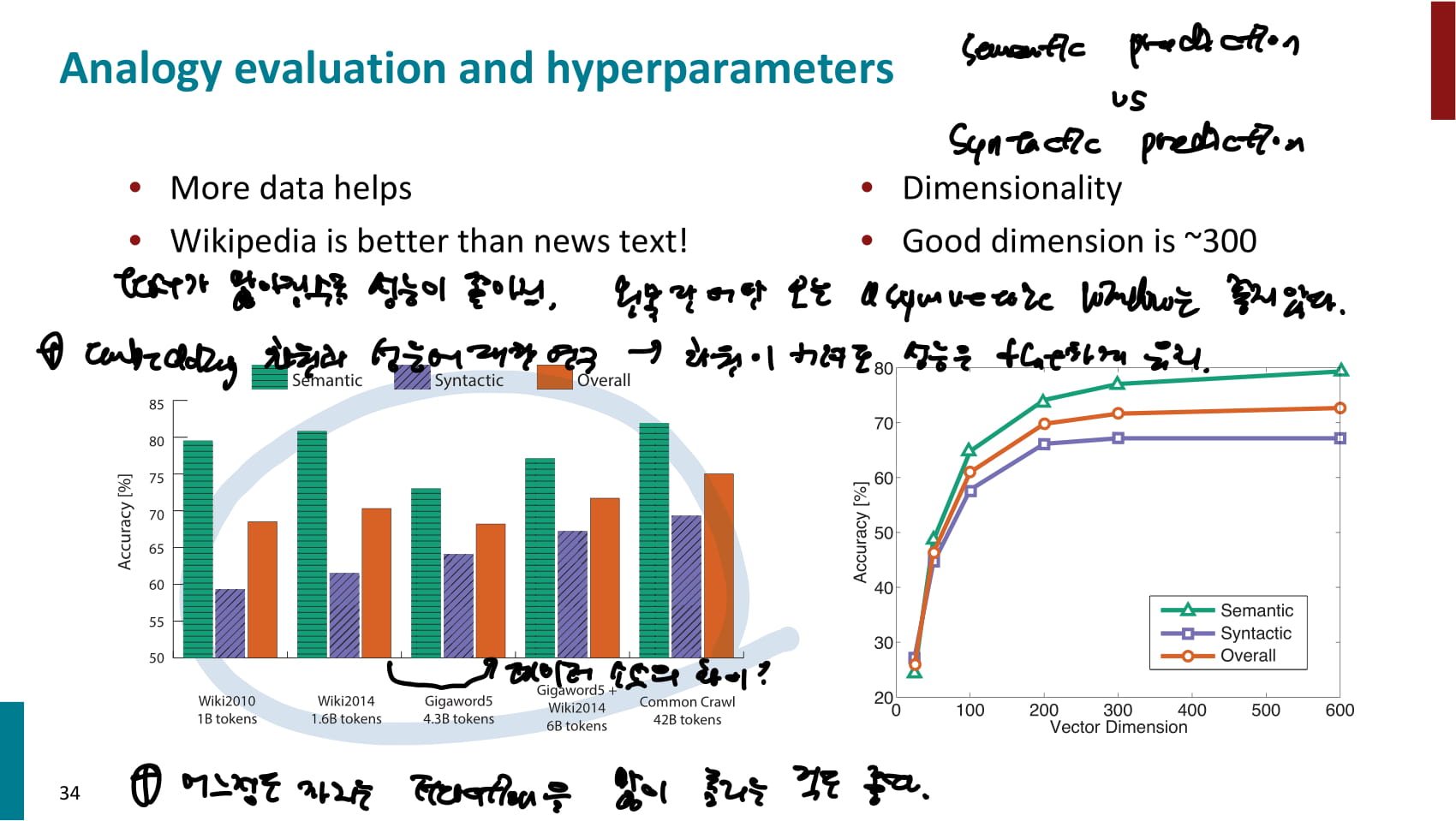
- 기타 연구내용들
- 훈련 대상 corpus가 커질수록 대체적으로 성능이 좋아지지만, 데이터 출처가 무엇인지도 영향을 준다.
- 한쪽단어만 보는 asymmetric window는 성능이 별로다.
- embedding 차원이 300정도일때까진 성능이 눈에 띄게 증가하지만, 그 후로는 별 차이 없다. 이건 최근 연구된 모델에선 다를것같기도 하다.
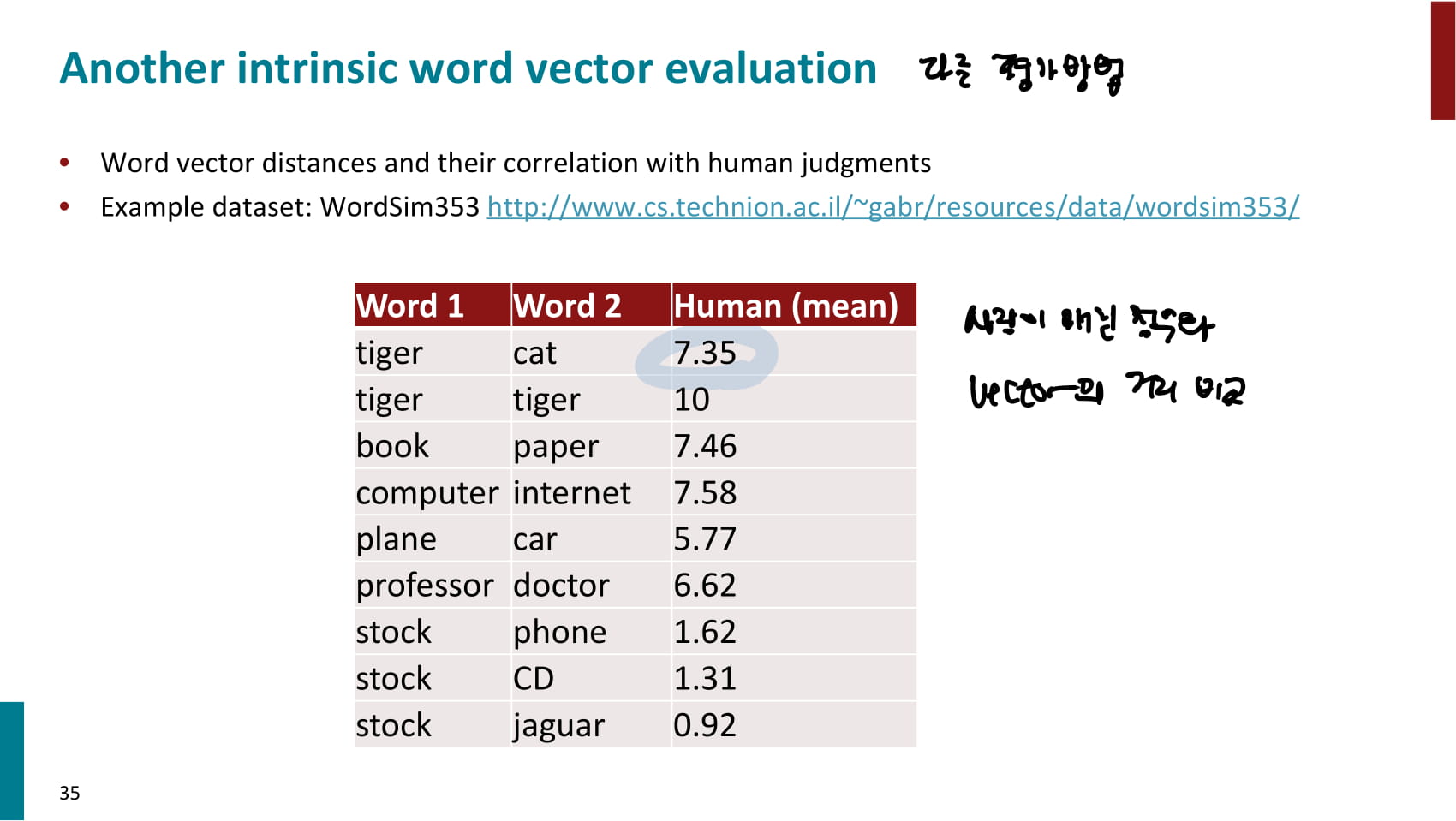
- 다른 intrinsic 평가방법으로는, 사람이 매긴 유사도 점수와 vector의 유사도를 비교하는 방법이 있다.
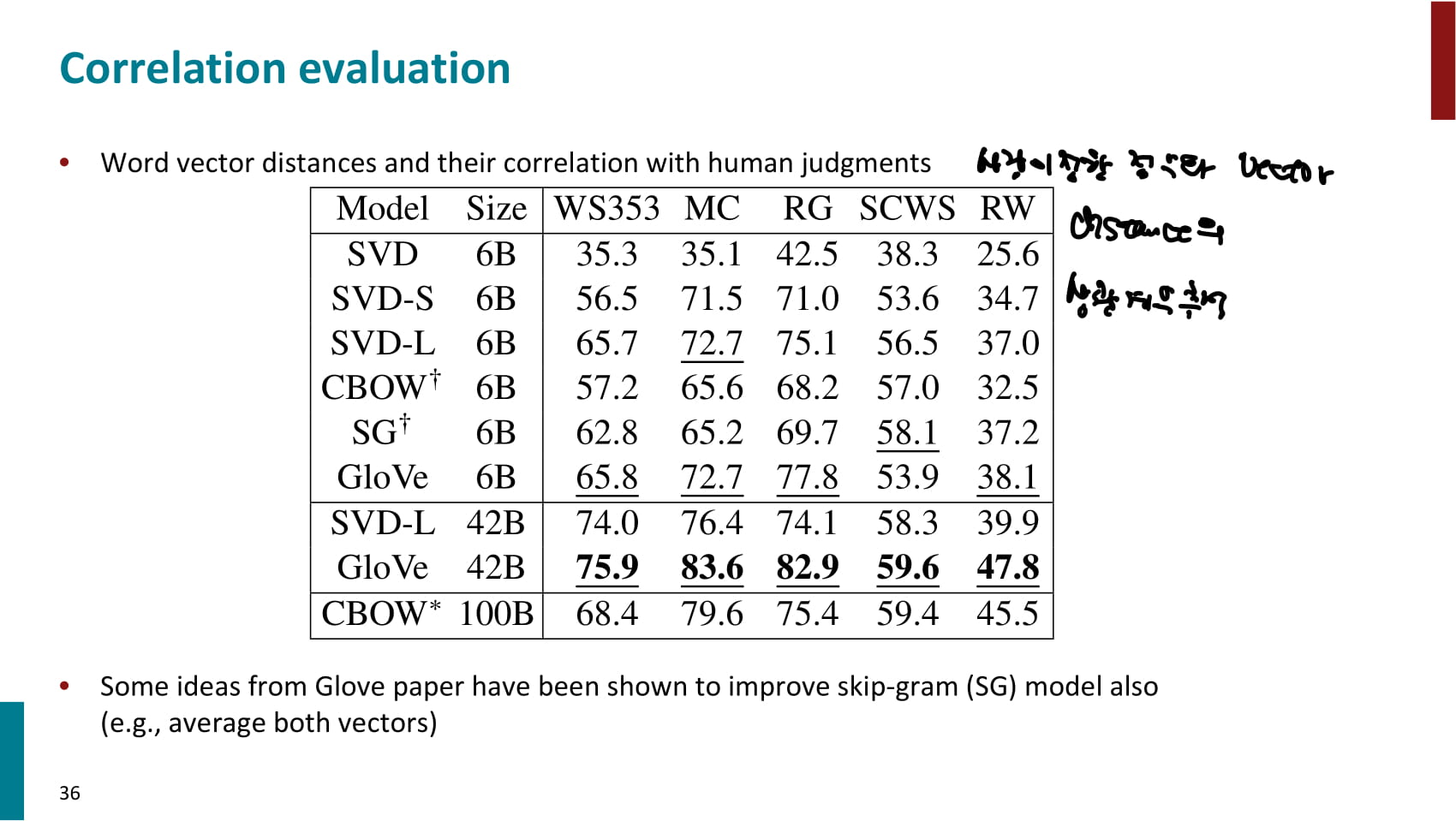
- 두 점수의 상관계수를 측정해 성능을 평가할 수 있다.
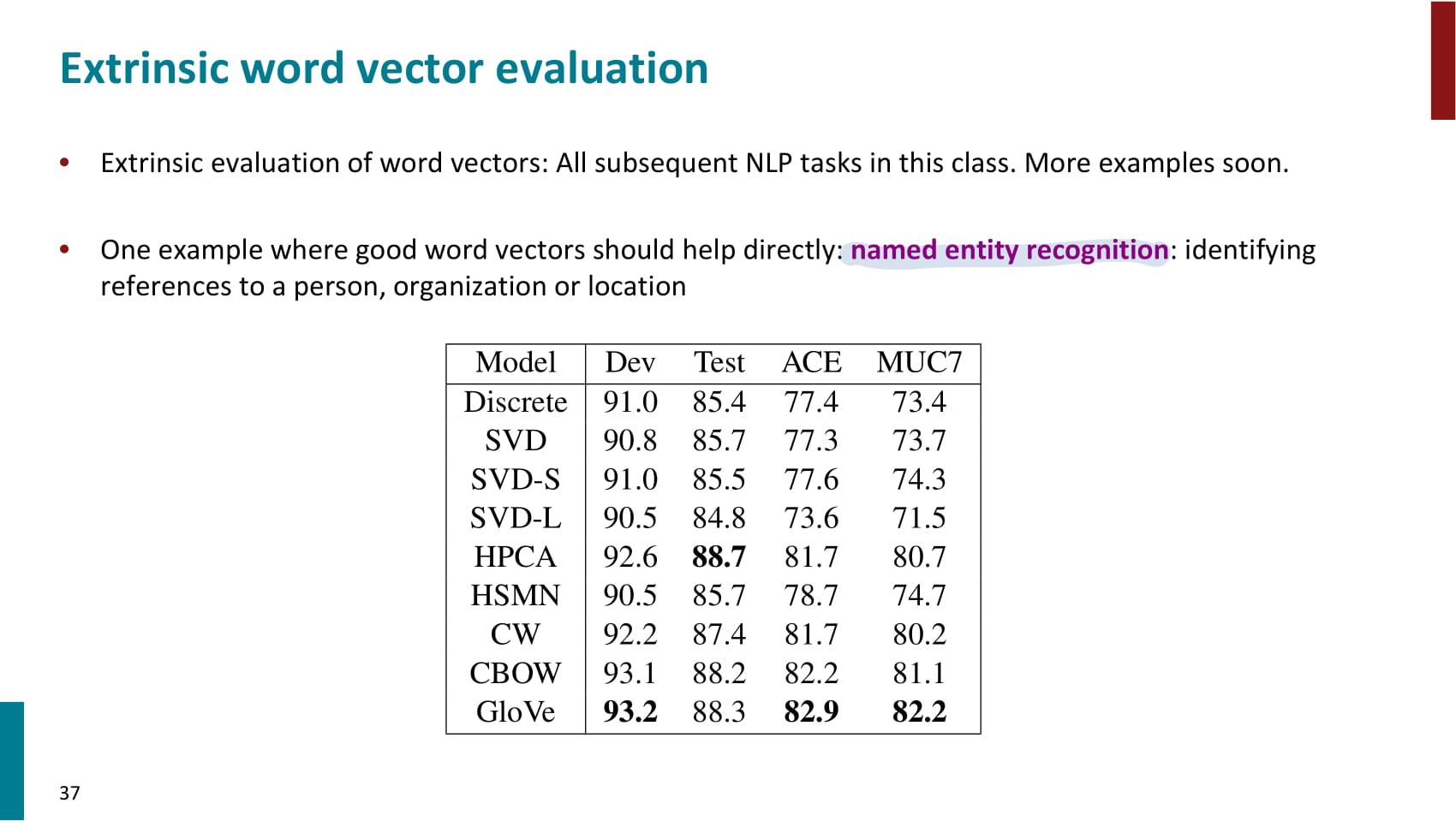
- NER 을 통해 extrinsic 평가를 수행할 수도 있다.

- 한 단어가 여러 의미를 가질 경우 모든 의미가 한 vector에 섞여 불분명해질 수 있는 문제.

- pike라는 단어는 위와 같이 여러 의미를 가진다.

- 이를 해결하기 위해 word window를 클러스터링하고, 클러스터 수만큼 단어를 pike_1, pike_2와 같이 여러 단어로 만들어 embeding을 학습할 수 있다.
- 이런 방법은 오래 걸리고, 각기 다른 의미의 클러스터가 겹칠 수도 있다.

- 위 예시와 같이 클러스터링한 후, 등장 빈도에 따라 가중합을 수행할 수도 있다.
- 의미가 꽤 잘 분리되는 결과를 보인다.
참고
