REST API란 도대체 뭘까..
🤔 일반적으로..
- URI를 통해 자원을 지정(URI보다 URL이 더 큰 집합, URI는 식별하고 URL은 위치를 가르킨다)
- HTTP 메서드 자원에 대한 행위 표현
- REST 제약을 지킨 아키텍쳐
- 왜 이걸 지켜야햐는데? => 7번 항목으로
- 어케 지키는데? => 9번 항목으로
1. 하지만?
REST API 창시자는 개빡침
- 논문 어디에도 CRUD에 대한 내용은 없음
- HTTP 메서드는 REST가 아니라 웹의 아키텍쳐 스타일의 일부
- HTTP에서 정의한 방식대로만 잘 쓴다면 REST는 딱히 할말 X
2. 그렇다면?
- REST API 창시자(Roy Fielding)의 본래 뜻은?
- REST 아키텍쳐 스타일에 부합하는 API
- 진짜 REST API가 되려면?
- 여러가지 조건에 부합해야 함
- Client-Server
- Stateless
- Cache
- Uniform Interface
- Layered System
- Code-On-Demand
- 여러가지 조건에 부합해야 함
- 그 중에서도 Uniform Interface
- 자원의 식별
- representations(표현)를 통한 자원의 조작
- 자기 서술적 메세지
- Hateoas(Hypermedia As The Engine Of Application State)어플리케이션의 상태를 조작하기 위한 하이퍼 미디어
3. 자원의 식별
- 이름을 지닐 수 있는 모든 정보
- 개념적인 대상
- ex) 문서 이미지 자원집합 실존대상
- 자원은 객체이다
- 상태는 변화가능 => 변하지 않는 식별자가 필요하다 => 그러므로 서버의 개별자원을 갖고 올 수 있는 URI를 통해 자원을 식별!!해야 한다!!
4. Representations(표현)을 통한 자원에 대한 조작
- 표현: 특정한 상태의 자원에 대한 표현
- 자원을 다양한 방식으로 표현 가능
- REpresentational State Transfer
==> REST의 기본)) 표현된 상태 전송 - 메시지는 스스로에 대해 설명 해야 한다!!
5. 자기 서술적(self-descriptive) 메세지
- Host 헤더에 도메인명 기재가 필요하다!
- HTTP/1.1 부터 Host 헤더 필수화
=> IP주소로는 안되나?
=> 가상호스트 문제- 하나의 IP 주소에 복수의 도메인명 존재 가능
- IP 주소만으로는 요청대상을 찾아낼 수 없음
- 캐쉬 관련 헤더를 통한 캐쉬 전략 지정
- HTTP/1.1 : Cache-Control, Age, Etag, Vary
=> 캐시로부터 정보를 가져옴
- HTTP/1.1 : Cache-Control, Age, Etag, Vary
6. Hateoas(Hypermedia As The Engine Of Application State)
- 만약에 홈페이지에서 링크로 이동하는 것이 아닌 URI로 숨겨진 페이지를 접속 할 경우 위배사항임!!
=> 하지만 프론트엔드로 받는 JSON에 앞으로 바뀔 URI를 첨부해 보낸다면 Hateoas위배 아님
7. 왜 이걸 지켜야 하는데?
- 자신이 개발한 시스템을 완전히 통제할 수 있다고 생각한다면 REST API에 시간을 쓸 필요가 없음
- 솔직히 이 조건들 비효율적임
- 애플리케이션에 필요한 정보가 아니라 표준화된!! 방식으로 전달하는 것이 REST API
=> 때에 따라서 다를 수 있지만 표준화된 방식을 따르는 것이 옳다!!
8. HTTP통신 인터페이스를 그냥 REST API라고 부르면 개빡치는 필딩좌
- 못지킬거면 GraphQL API도 있으니 URI를 통한 자원 식별 제역조건 위배일 경우 GraphQL API로 ㄱㄱ
9. 표준화된 조건
- 자원을 이름으로 구분
=> URI를 구분 잘되게 잘 만들어라- 명사를 사용해서 자원표현
- 예외적으로 동사가능(controller)
- 자원간 계층 관계를 표현해라
=> 계층마다 슬래시 사용 ex) /crews/frontend - 마지막에는 슬래시 쓰지마
- 하이픈 기호로 중간에 둬서 URI 가독성 향상 가능
- 언더바 사용하지마
- 소문자만
- CRUD 함수 이름 쓰지마 ex) /create/crews
- 필터링을 위해선 Query String을 사용해라!
- 자원의 상태를 주고 받음
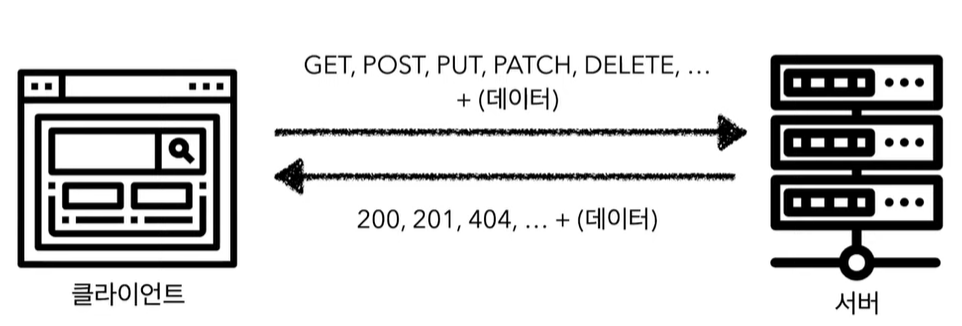


- GET
- 자원을 검색할 때 사용
- /getCrews/5 안됨, /crews/5 +GET 요청 굿
- POST
- 자원을 생성할 때 사용
- /register_crew 안됨, /crews +POST body:{"name":"하머", "type":"백수"} 요청 굿
- PUT
- 자원을 업데이트할 때 사용
- /crews/1 +PUT body:{"type": "backend"} 이렇게 보내면 name은 null로 들어옴
=> 즉 모든 Property를 가지고 있어야함
- PATCH
- 보내지 않은 데이터는 기존 데이터를 유지하고 업데이트
- /crews/1 +PATCH body:{"type": "backend"} 이렇게 보내면 name은 데이터베이스의 값을 유지한다
- DELETE
- URI의 해당하는 값의 데이터를 지웁니다.
- GET
번외 GET과 POST의 차이
- HTTP란 요청과 응답으로 나뉘어 어떠한 서버의 "액션"이 일어나게 끔 하는 메세지
- GET이란
- 서버가 가진 자원을 클라이언트로 가져다 달라는 것을 의미
- 요청을 전송할 때 body를 주지않고 쿼리스트링을 사용해 가져올 데이터를 필터링한다.
- 쿼리스트링으로 데이터가 노출되기 때문에 중요 데이터의 경우 GET을 사용해서는 안된다.
- 헤더를 통해 데이터를 전송하기에 데이터 전송량 한계 있음
- POST란
- 서버가 가진 자원(리소스)를 생성/변경 하기 위한 메서드
- 클라이언트가 전송한 데이터(ex body)가 서버로 들어가야 함
- 전송 데이터는 HTTP의 Body에 담아 전송하고 Body는 대용량 데이터 전송에 적합하며 GET과는 쿼리스트링으로 드러나지않는 차이점이 있어 보안적인 면에서 비교적 괜찮다,
- 헤더에 Content-Type에 요청 데이터의 타입을 표시해줘야 서버가 처리하기가 편하다.
});``` return axios.post(serverUrl + endpoint, bodyData, { headers: { 'Content-Type': 'application/json', Authorization: `Bearer ${getCookie('access_token')}`, },
}```
그래서 뭐가 다른데?
1. 멱등성. [ GET은 멱등성을 가지고 POST는 가지지 않는다. ]
GET은 자원에 대한 요청을 보내는 것이기에 서버에 영향을 주지 않는다.. 그저 자원의 존재 유무만 체크하면 되고
그에 맞는 응답을 받으면 된다. 그러기에 멱등성을 보장받을 수 있고 이를 기반으로 웹 브라우저는 캐시 데이터에
요청에 대한 응답(자원)을 미리 기록해둔다. [ 정적인 자원들(이미지, js, css, html 등등) ]
POST의 경우 데이터를 서버에 전송해서 특정 작업을 처리하기에 서버에서의 결과가 POST 요청마다 달라질 수 있다.
그래서 멱등성을 완전히 보장한다고 할 수는 없다. 그래서 별도의 캐시 데이터가 POST 요청을 효율적으로 처리하기
위해서 사용되지는 않는다.
2. 데이터가 어디에 실리는가
GET은 쿼리스트링에 데이터가 드러나기 때문에 보안에 취약하다. HTTP의 헤더에 데이터가 드러난다.
반면 POST의 경우 HTTP 헤더가 아닌 바디에 데이터를 실어 보내기에 외적으로 데이터가 드러나지 않는다. 하지만
그렇다고 보안에 취약한 것은 아니다. 네트워크를 스니핑할 수 있으면 해당 HTTP 메시지를 룩업 하면 암호화되지 않은 경우 바디를 그대로 확인해볼 수 있기에 중요한 데이터는 암호화 과정을 거쳐야 한다.
3. 데이터의 양
GET은 서버에 자원을 위한 키워드들을 보내거나 경로와 관련된 정보를 전송하면 된다. [EX. 검색어를 위한 키워드]
반면 POST는 서버에서 작업하는데 필요한 데이터들을 보내줘야 하기 때문에 상대적으로 보내야 하는 데이터가 많다.
[ 동영상이나 이미지.. 개인 정보 등등 ] 그래서 전송되는 데이터의 양에서 다르다고 볼 수 있다.
4. 정리
-
데이터가 어디로 저장되는지(헤더인지 바디인지)
-
GET과 POST의 주 목적이 무엇인지.
-
GET과 POST의 멱등성의 차이. 멱등성을 얻는 경우 얻을 수 있는 이점(캐싱)에 대해서 추가 답변.
-
데이터 전송양의 차이점.
정리
- REST API란 REST 아키텍쳐 스타일에 부합하는 API임
- REST API의 구현은 SSAP가능하지만..
=> 굳이 필요한가.. 어떠한 효과가 있는가.. - REST API가 만만하니?
=> 아무렇게나 HTTP 통신쓰고 나 REST API썼다고 하지말자 - REST API 지키기 쉬운데 어려움
- GET POST차이 꽤 큼
참고자료
정님 - (테코톡) REST API
naverD2 - 그런 REST API로 괜찮은가
민초님 - (테코톡) RESTful
Murphy님 - HTTP의 GET과 POST 메서드 비교
