원본 논문: 논문 바로가기
논문 내용을 정리하는 글입니다. 논문 전체 내용을 담고 있지 않을 수 있습니다. 또한, 잘못된 내용이 있을 수도 있습니다. 감사합니다.
Abstract
존재하는 tabular data에 관한 deep learning 문헌은 다양한 범위의 새로운 구조를 제안하고 다양한 datasets에 대해 경쟁력있는 결과를 보고 한다. 하지만, 제안된 모델은 보통 적절하게 비교되지 못한다.
그 결과 researchers와 practitioners 모두 어느 모델이 더 좋은지 명확하게 알지 못한다.
게다가 field는 여전히 효과적인 baselines가 부족하다. 즉, 다양한 문제에 경쟁력있는 성능을 제공하는 사용하기 쉬운 모델들이 부족하다.
본 논문에서는, tabular data를 위한 DL 구조의 main families의 개요를 수행하고 간단하고 강력한 deep architectures를 구분함으로써 tabular DL에서 baseline의 기준을 제시한다.
첫번째는 ResNet-like 구조이다.
두번째는 tabular data를 위한 Transformer 구조의 간단한 변형(adaptation)이다. 이 구조는 대부분의 task에서 다른 솔루션들을 능가했다.
저자들은 또한, best DL models를 Gradient Boosted Decision Trees와 비교했다. 그리고 여전히 보편적으로 우수한 solution은 존재하지 않는다고 결론지었다.
1. Introduction
images, audio and texts와 같은 data domains에서 엄청난 deep learning의 성공 덕분에, tabular 형태로 저장된 데이터 문제로 성공을 확장하려는 연구적인 관심이 많았다. 이 문제에서 data points는 이질적인 features의 vectors로 표현되었다. 이는 산업 적용 및 ML 대회에서 일반적인 경우이다. ML 대회에서 neural networks는 non-deep competitor인 GBDT가 있다. tabular data에 deep learniang을 사용하는 것은 잠재적으로 더 높은 성능 뿐만 아니라 multimodal pipelines를 구축할 수 있기 때문에 매력적이다. 이런 파이프라인은 모든 modalirties에 대해 end-to-end로 훈련 가능하다. 이런 이유로 많은 DL solutions가 최근 제안되고 계속 등장하고 있다.
불행하게도, 구축된 benchmarks의 부족으로, 존재하는 논문들은 평가를 위해 다른 datasets를 사용하고 종종 제안된 DL models는 적절하게 비교되지 못한다. (tabular benchmark dataset의 부족으로 DL models의 비교가 적절히 이루어지고 있지 않다.) 따라서 현 논문에서부터, 어느 DL model이 일반적으로 좋은 성능을 내는지, GBDT가 DL models를 능가하는지는 알 수 없다. 추가적으로 많은 새로운 구조에도 불구하고 field에는 적당한 노력으로 경쟁력있는 성능과 다양한 tasks에서 안정적인 성능을 제공하는 간단하지만 신뢰할 수 있는 해결책이 부족하다. 위에서 언급한 문제들은 연구 과정을 방해하고 관측 결과를 충분히 결론짓지 못하게 한다.
저자들은 잘 연구된 DL 구조 블록들이 tabular data에 대해서는 덜 관측되었고 더 좋은 baseline을 구축하기 위해 사용될 수 있다고 가정한다. 따라서, 다른 분야의 잘 검증된 구조에서 영감을 받아서 tabular data를 위한 두 개의 simple model을 만들었다. 첫 번째는 ResNet-like 구조이다. 두 번째는 FT-Transformer이다. 그 후 같은 환경에서 두 모델을 많은 존재하는 solution들과 비교했다. 우선, 고려한 DL model들이 ResNet-like model을 능가하지 못한다는 것을 밝힌다. 둘째, FT-Transformer는 대부분의 tasks에서 best performance를 증명했다. FT-Transformer는 "Conventional" ResNet과 다른 DL model들 보다 더 넓은 범위의 tasks에서 잘 작동했다. 마지막으로 best DL models와 GBDT를 비교한 결과 보편적으로 우수한 solution은 없다고 결론지었다.
contribution 정리
1. 상대적인 성능 비교를 위해서 다양한 tasks에서 주요 tabular DL models를 철저히 평가함.
2. simple ResNet-like 구조가 tabular DL을 위해서 효과적인 baseline이라는 것을 증명함. 모델이 단순하기 때문에 다른 tabular DL과 비교하기 위한 baseline으로 쓸 것을 추천함.
3. FT-Transformer를 소개함.
4. GBDT와 deep models 중 보편적으로 우수한 solution은 없다는 것을 밝힘.
2. Related work
The "shallow" state-of-the-art
tabular data 문제에서 "얕은" sota는 현재 decision trees의 ensemble이다. XGBoost, LightGBM, CatBoost와 같은 여러 라이브러리들이 있다.
최근 몇 년 동안, tabular data를 위한 대형 deep learning model들이 개발되었다. 이 모델들 대부분을 대략적으로 3가지 그룹으로 나누고 밑에서 설명한다.
Differentiable trees.
decision tree ensemble이 tabular data에서 좋은 성능을 보이는 것에서 영감받았다. decision trees는 미분 불가능하고 gradient optimization이 불가능하기 때문에, end-to-end 방식으로 훈련되는 파이프라인에 사용이 불가능하다.
이 문제를 해결하기 위해서 일부 논문에서는 아래와 같은 방식을 제안함.
“smooth” decision functions in the internal tree nodes to make the overall tree function and tree routing differentiable.
이 방식을 사용한 방법들이 일부 tasks에서 GBDT를 능가할 수 있었지만, 본 논문의 실험에서는 일관적으로 ResNet을 뛰어넘지 못했다.
Attention-based models.
attention 기반의 구조들이 다른 domain에서 널리 성공했기 때문에 일부 저자들은 tabular DL을 위한 attention-like modules를 제안했다.
본 저자들의 실험에서 적절하게 튜닝된 ResNet은 존재하는 attention-based models를 이겼다. 그렇지만, 저자들은 transformer 구조를 tabular data에 적용하는 효과적인 방법을 찾아냈다. 해당 방식은 ResNet을 대부분의 task에서 이겼다.
Explicit modeling of multiplicative interactions.
추천 시스템과 click-through-rate prediction(클릭될 확률 예측, 추천시스템과 관련된 개념)의 논문에서는, features 사이의 multiplicative interations를 modeling하는데 적합하지 않다고 MLP를 비판했다. 따라서 일부 논문들은 MLP에 feature products를 결합하는(incoporate) 다양한 방식을 제안했다.
본 논문의 실험 결과 그런 방식은 적절히 튜닝된 basellines보다 우수한 것을 발견하지 못했다.
위 그룹에 속하지 않는 다른 구조들도 많이 제안되었지만, 전반적으로 다른 benchmark를 사용하여 평가했고 서로 거의 비교도 되지 않았다.
3. Models for tabular data problems
3.1 MLP
"MLP" 구조를 공식 (1)로 규정함.
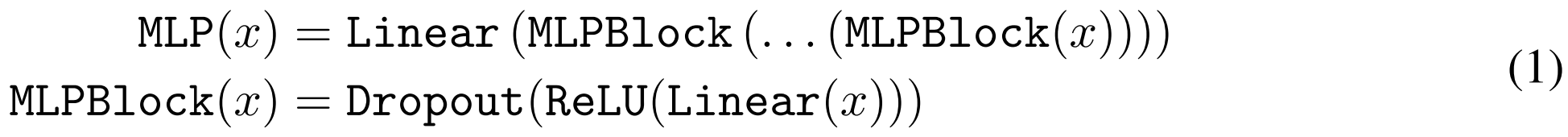
3.2 ResNet
ResNet-like baseline을 디자인하려는 시도가 좋지 않다는 결과가 있었지만 computer vision에서 NLP tasks에서 ResNet이 성공적이었다는 점을 보아 ResNet 구조를 다시 시도함. 공식 (2)에 묘사된 것과 같이 단순한 variation을 주어 만들음.

main building block은 원래 구조와 비교하여 단순화됨. 입력에서 출력까지 직접적인 경로가 있으면 이는 optimization에 유용할 것으로 판단함. 전반적으로 이 구조는 deeper representations가 유용한 작업에서 MLP를 능가할 것으로 기대함.
3.3 FT-Transformer
FT-Transformer를 소개함.(Feature Tokenizer + Transformer)
tabular data를 위한 Transformer 구조의 간단한 수정임.
Figure 1이 FT-Transformer의 main parts를 설명함.
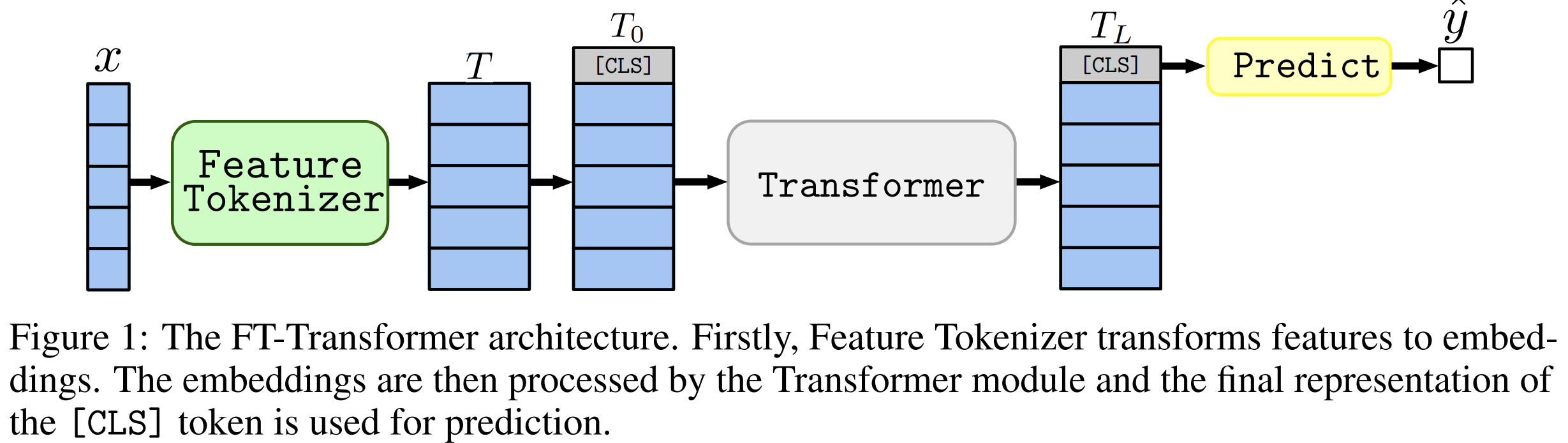
all features(categorical and numerical)를 embedding으로 변환하고 embedding에 transformer layers 스택을 적용함. 따라서 모든 transformer layer는 하나의 객체의 feature level에서 작동함. section 5.2에서 FT-Transformer를 개념적으로 비슷한 AutoInt와 비교함.
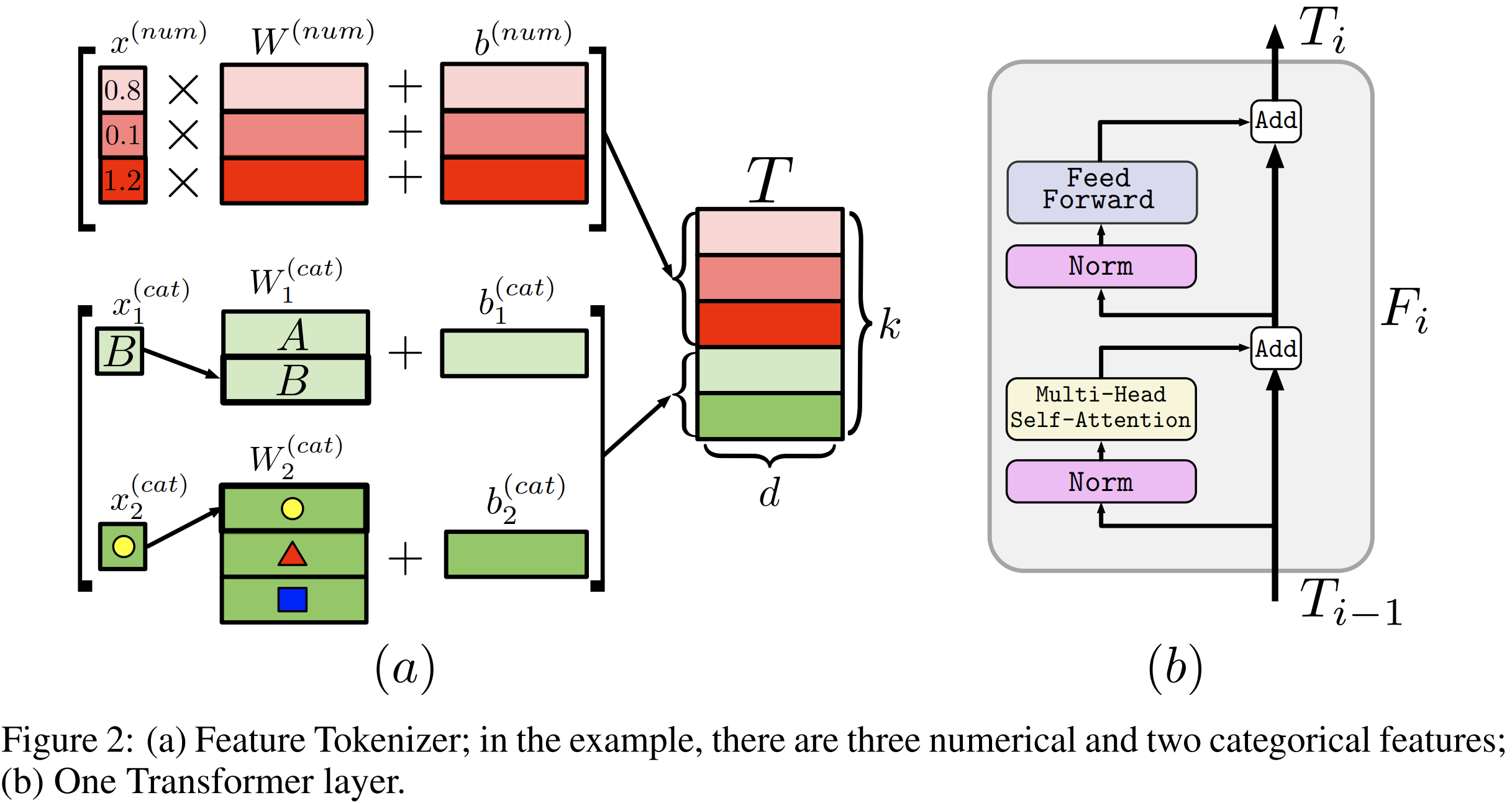
Feature Tokenizer.
input features x를 embeddings 로 변환시킴.
feature 가 주어졌을 때, embedding은 아래와 같이 계산됨.
은 vector과의 element-wise multiplication으로 만들어짐.
은 look-up table로 만들어짐.
Transformer
[CLS] token의 embedding을 T에 추가함.
L Transformer layers 이 적용됨.(transformer layer L번 적용됨.)
Limitations
FT-Transformer는 ResNet과 같이 간단한 모델에 비해서 훈련시키는데 자원(hardware and time)이 많이 필요하다. and may not be easily scaled to datasets when the number of features
is “too large” (it is determined by the available hardware and time budget). 그 결과 tabular data 문제를 해결하게 위해서 FT-Transformer를 사용하는 것은 머신러닝을 사용하는 것보다 더 많은 C02를 방출할 수 있다. 이 문제의 주된 원인은 vanilla Multi head self attention이 features의 수에 quadratic complexity를 가지고 있다는 것이다. 하지만 이 문제는 효율적인 Multi-head-self-attention 추정을 사용함으로 완화할 수 있다. 게다가 FT-Transformer를 더 간단한 구조로 distill하는 것도 가능하다.
3.4 Other models
본 논문에서 비교군으로 사용할 tabular data를 위해 디자인된 다른 모델들을 소개함.
-
SNN (Klambauer et al., 2017).
- MLP-like 구조.
- SELU activation 함수를 사용함.
- SELU activation 함수는 더 깊은 모델을 학습 가능하게 함.
-
NODE (Popov et al., 2020).
- oblivious decision trees의 미분 가능한 ensemble임.
-
TabNet (Arik and Pfister, 2020).
- dynamical reweighing of features와 conventional feed-forward modules을 번갈아 사용하는 recurrent 구조임.
-
GrowNet (Badirli et al., 2020).
- Gradient boosted weak MLPs.
- 공식 구현은 classifiacion regressoin 문제만 지원함.
-
DCN V2 (Wang et al., 2020a).
- MLP-like module과 feature crossing module로 이루어져있음.
- feature crossing module은 linear layers와 multiplications의 조합임.
-
AutoInt (Song et al., 2019).
- features를 embeddings로 변환함.
- embeddings에 a series of attention-based transformation을 적용함.
-
XGBoost (Chen and Guestrin, 2016).
- 가장 유명한 GBDT 구현 중 하나임.
-
CatBoost (Prokhorenkova et al., 2018).
- oblivious decision trees를 weak learners로 사용하는 GBDT 구현임.
4. Experiments
DL models를 서로 비교하고 DL model와 GBDT를 비교함. main text에서는 key results만 보고함. 추가적으로 아래 3가지 정보를 제공함.
1) 모든 models의 모든 datasets에서 성능
2) 하드웨어에 대한 정보
3) ResNet과 FT-Transformer의 훈련 시간
4.1 Scope of the comparison
본 논문에서는 다양한 구조에 따른 상대적인 성능에 초점을 두고 pretraining, additional loss function 등 model-agnostic DL 기법은 사용하지 않음. 위와 같은 방법들은 잠재적으로 성능을 향상시킬 수 잇지만, 본 논문의 목표는 다양한 모델 구조에 의한 inductive biases의 영향을 평가하는 것이다.
4.2 Datasets
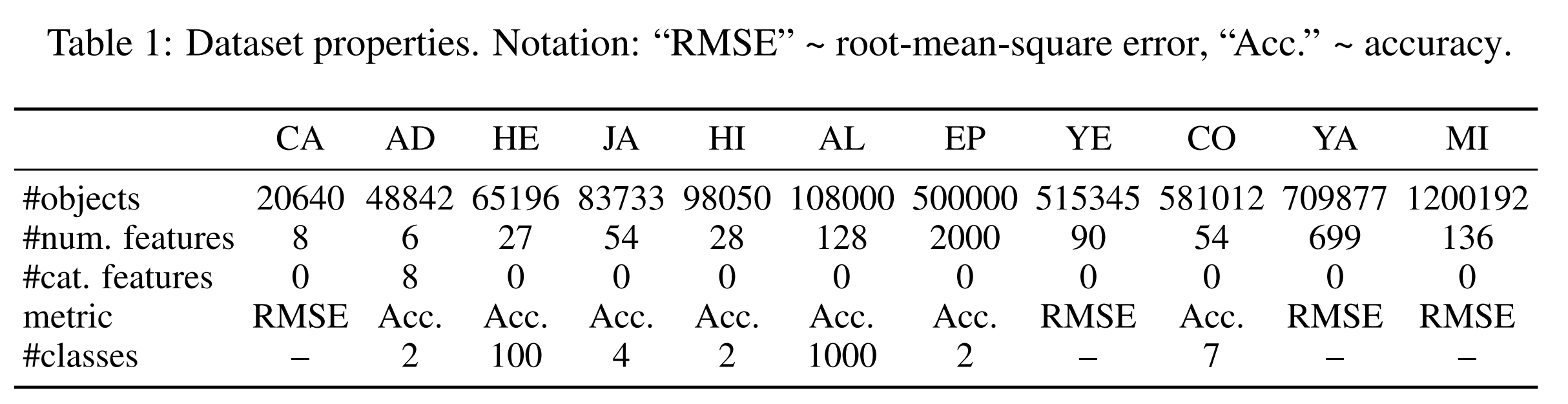
11개의 public datasets를 사용함.
data properties는 Table 1에 요약되어 있음.
4.3 Implementation details
(생략)
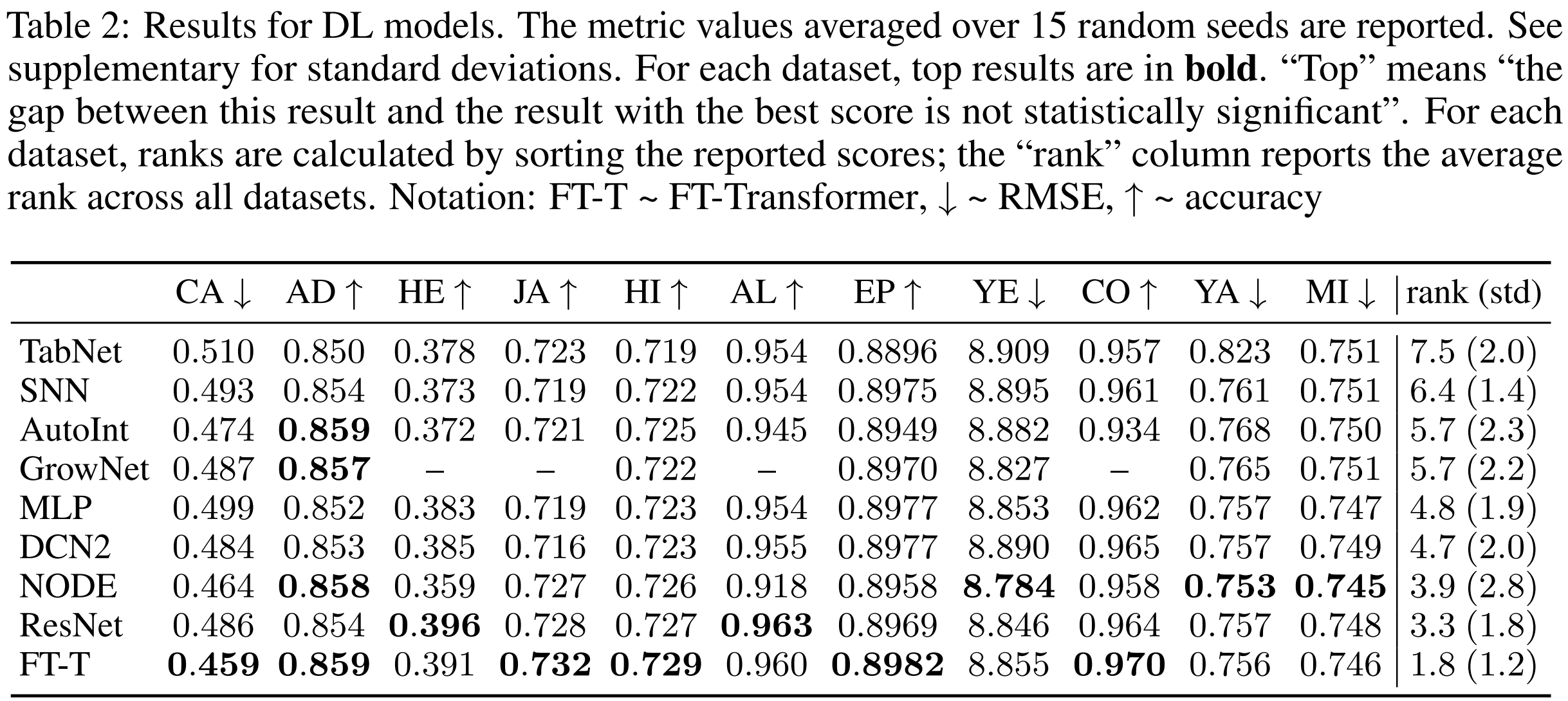
4.4 Comparing DL models
The main takeaways:
- MLP는 좋은 초기 점검 기준이다.
- ResNet은 경쟁 모델이 일관되게 뛰어넘지 못하는 효과적인 baseline 이다.
- FT-Transformer는 대부분의 tasks에서 좋은 성능을 보이고 tabular data 문제에서 새로운 좋은 solution이 되었다.
- Tuning은 MLP와 ResNet과 같은 간단한 모델을 경쟁적으로 만단다. 따라서 가능하면 baseline을 튜닝하는 것을 추천한다. 다행히도 요즘은 Optuna와 같은 라이브러리들이 매우 접근하기 쉽다.
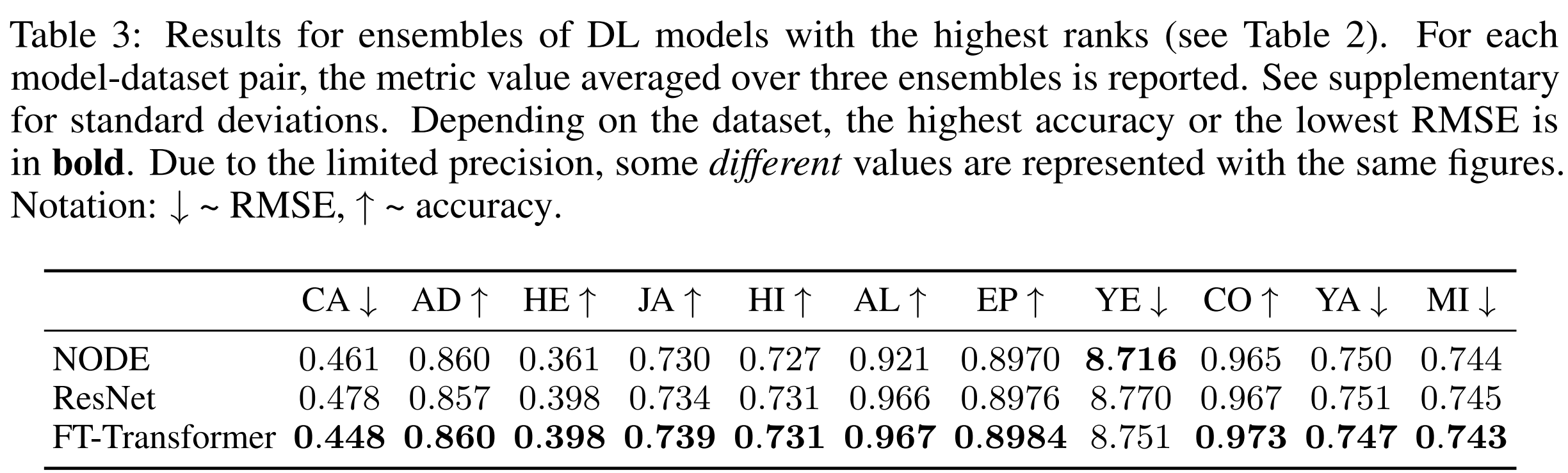
다른 모델들 중에서, NODE는 몇 tasks에서 높은 성능을 증명한 단 하나의 모델이다. 하지만, ResNet 보다 복잡함에도 불구하고 6가지 datasets에서 ResNet보다 좋지 않다. 게다가 사실 "single" 모델도 아니다. 때때로 ResNet과 FT-Transformer보다 상당히 더 많은 파라미터를 가지고 있으며 ensemble-like 구조를 가지고 있다. ensembles에 대해 Table 3에서 설명하고 있다. 결과는 ResNet과 Transformer가 ensembleing보다 더 많은 장점을 가지고 있다고 보여준다. FT-Transformer는 NODE보다 성능이 좋고, ResNet과 NODE의 차이는 줄어든다. 하지만, NODE는 tree-based 접근법들 사이에서 우수한 solution으로 남아있다.
4.5 Comparing DL models and GBDT
이 섹션의 목표는 DL model가 "개념적"으로 GBDT를 이길 준비가 되었는지 보는 것이다. 이를 위해서 speed와 하드웨어 요구사항을 고려하지 않고 GBDT 또는 DL 모델들의 가장 좋은 값을 비교한다.

Default hyperparameters.
California Housing, Adult datasets을 제외한 모든 datasets에서 FT-Transformers의 ensemble이 GBDT의 ensemble을 능가한다. 흥미로운 사실은 default FT-Transformers의 ensemble 성능이 tuned FT-Transformers의 ensemble 성능에 버금간다.
The main takeaway: FT-Transformersms는 있는 그래도 powerful ensembles를 만들 수 있다.
Tuned hyperparameters.
하이퍼파리미터가 적절하게 튜닝되자마자 GBDT가 일부 데이터에서 더 좋은 성능을 보였다. 이 경우들은 차이가 상당하기 때문에 DL models가 항상 GBDT를 능가하진 못한다는 결론을 내린다. DL models가 GBDT를 대부분의 tasks에서 능가한다는 것이 DL solution이 어느 경우든 더 좋다는 의미는 아니라는 것에 주의해야 한다. DL models가 GBDT보다 성능이 좋다는 것은 오직 구축된 benchmark가 "DL-friendly" 문제로 약간 치우쳐저 있다는 것을 의미한다. GBDT는 여전히 많은 수의 classes를 가진 multiclass 문제에 적합하지 않다. classes의 수에 따라 GBDT는 만족스럽지 않은 성능을 보였다.(Helena) 혹은 심지어 매우 느린 학습 때문에 튜닝할 수 없었다.(ALOI).
The main takeaways:
- DL models와 GBDT 중에서 보편적인 solution은 여전히 존재하지 않음.
- GBDT를 능가하려는 DL 연구의 노력은 GBDT 성능이 SOTA DL Solutions를 뛰어넘는 데이터셋에 집중되어야 한다. 뿐만 아니라 "DL-friendly" 문제에서의 (성능)하락을 피하기 위해선 "DL-friendly"문제를 포함하는 것도 여전히 중요하다.
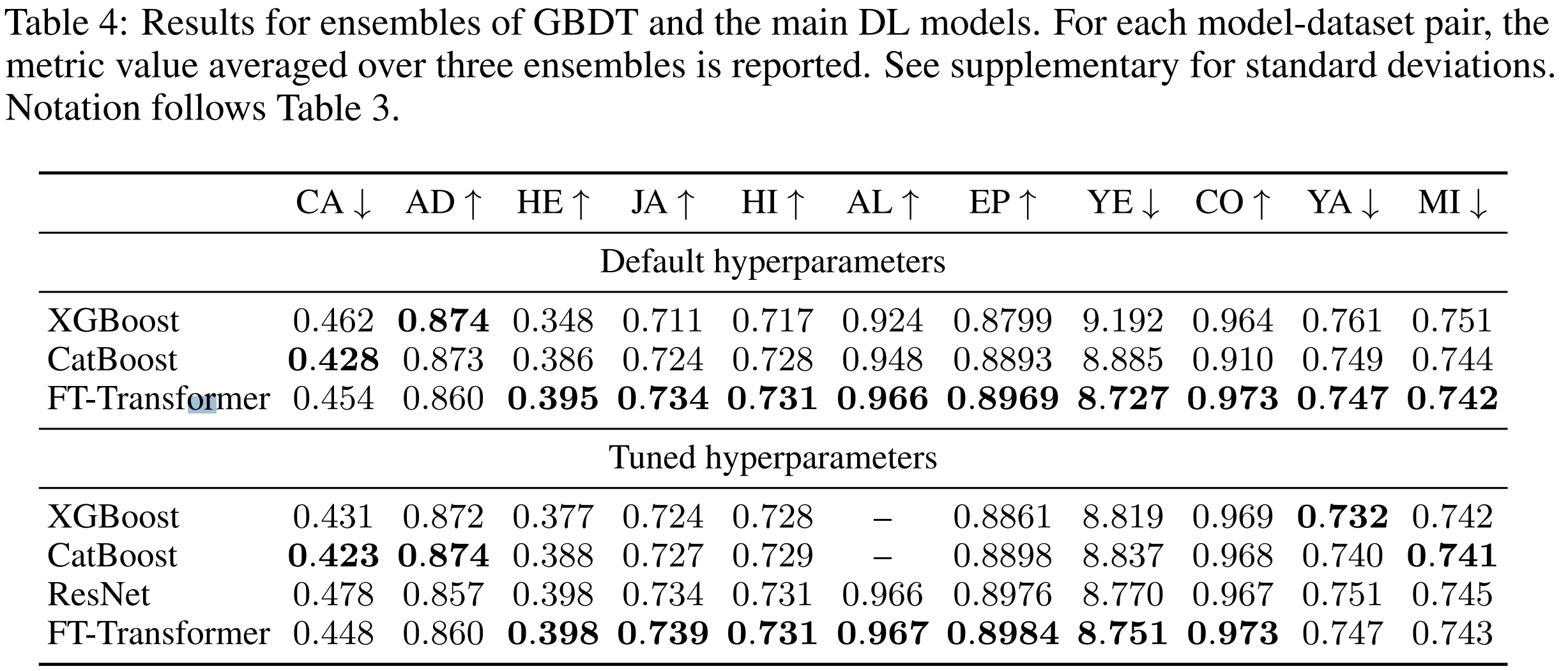
4.6 An intriguing property of FT-Transformer
Table 4에는 더 중요한 이야기가 담겨있다.
FT-Transformer는 모든 tasks에서 경쟁력있는 성능을 보인다. 반면에 GBDT와 ResNet은 일부 taks에서만 잘 작동한다. 이 관찰은 tabular data 문제에서 FT-Transformer가 보다 더 "보편적"인 model이라는 증거이다. 이 직관을 section 5.1에서 발전시킨다. 이 현상은 앙상블과는 관련이 없으면 단일 모델에서도 관찰된다.
5. Analysis
5.1 When FT-Transformer is better than ResNet?
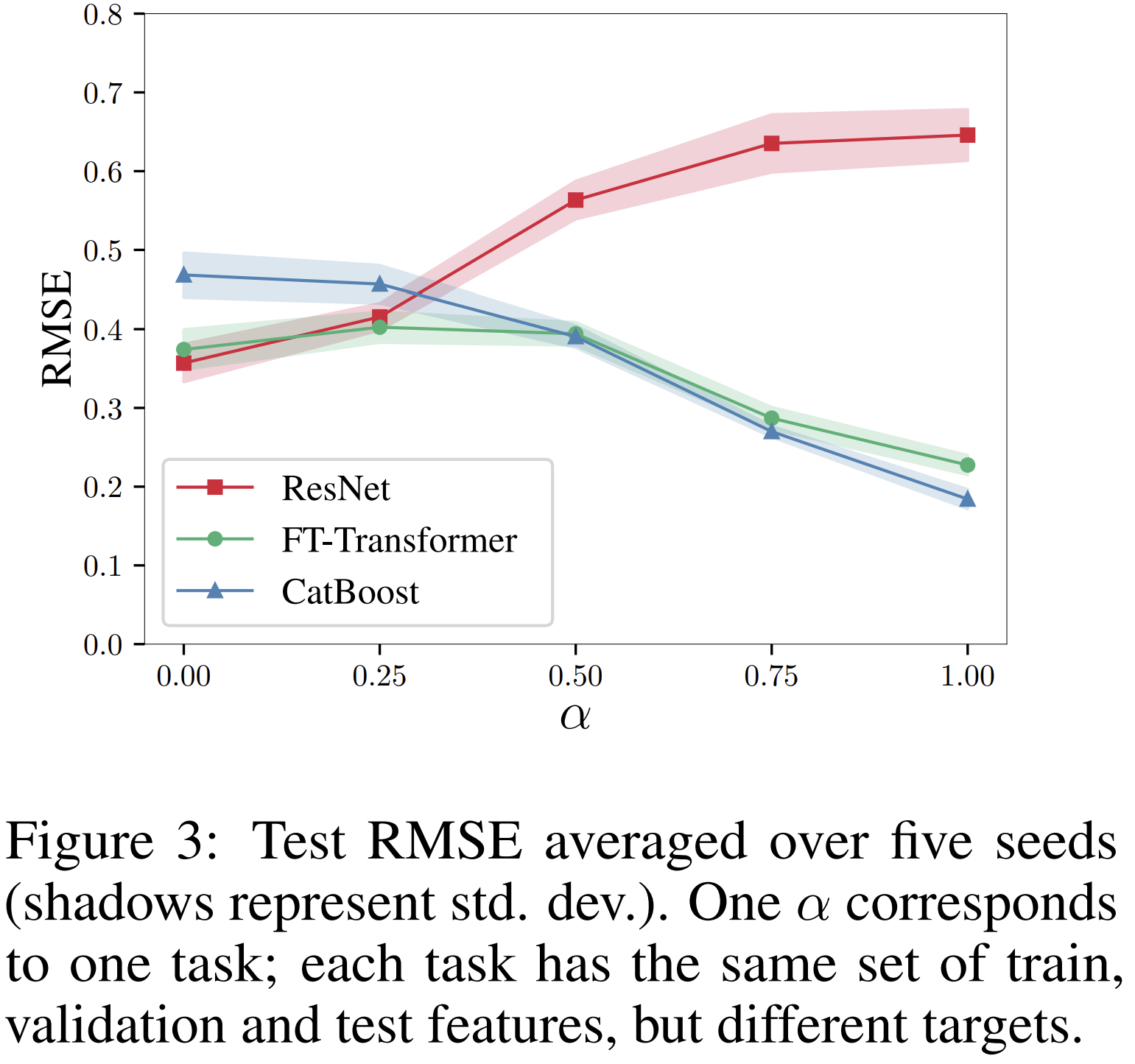
section 5.1에서는 FT-Transformer와 ResNet의 차이(section 4.6에서 관찰된 사실)를 알아 볼 것이다. 이를 위해서 두 모델의 성능 차이를 무시할 수 있는 수준에서 극적인 수준으로 점차적으로 변화시키는 tasks의 sequence를 설계함.
- object: 을 생성하여 고정함.
- train-val-test split을 한 번 실행함.
- 2개의 regression targets를 보간함.
- 이때, 는 GBDT에 쉬운 것이고 은 ResNet에 쉬운 것이다.
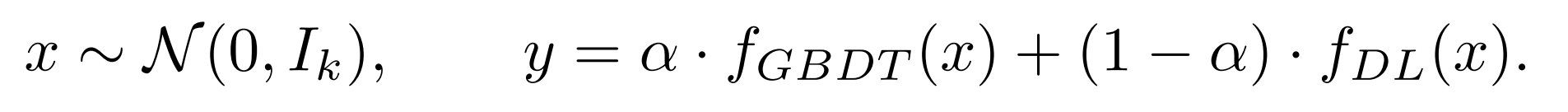 는 30개의 임의로 만들어진 decision trees의 평균 예측이다.
는 30개의 임의로 만들어진 decision trees의 평균 예측이다.
은 3개의 randomly initialized hidden layers를 가진 MLP이다.
resulting targets는 훈련 전에 standardized 된다.
- 이때, 는 GBDT에 쉬운 것이고 은 ResNet에 쉬운 것이다.
결과는 Figure 3에 시각화 되었다.
ResNet-friendly task에서 ResNet과 FT-Transformer의 성능은 비슷하게 좋고 CatBoost를 뛰어넘음. 하지만, Resnet은 GBDT-friendly task에서 상당히 성능이 떨어짐. 반면에 FT-Transfomrer는 모든 tasks에서 경쟁력있는 성능을 보임.
이 실험은 FT-Transformer가 더 잘 근사할 수 있는 함수의 유형을 보여준다. Additionally,the fact that these functions are based on decision trees correlates with the observations in section 4.6 and the results in Table 4, where FT-Transformer shows the most convincing improvements over
ResNet exactly on those datasets where GBDT outperforms ResNet.
5.2 Ablation study
FT-Transformer의 디자인 선택을 위함 실험을 함.
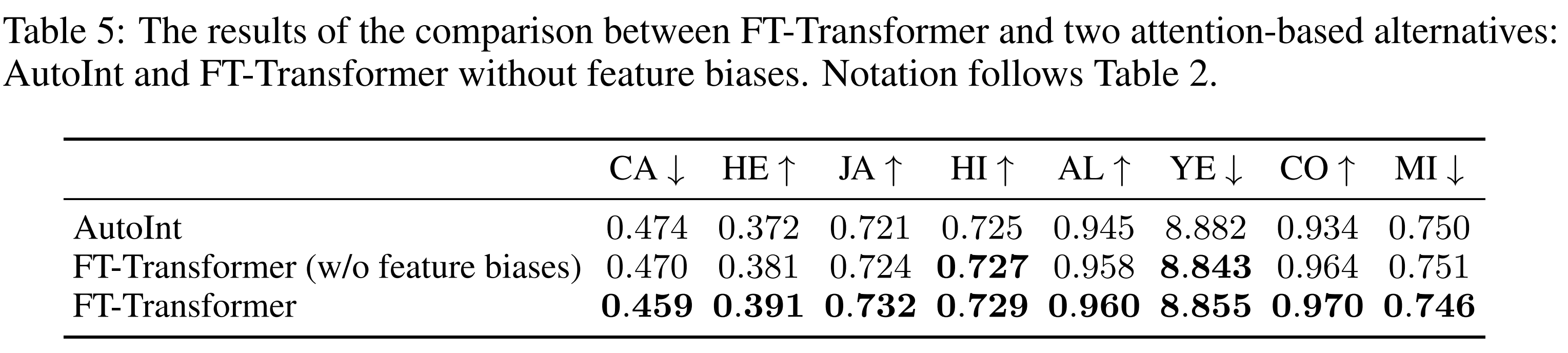
1. AutoInt가 FT-Transformer와 가장 비슷하기 때문에 FT-Transformer를 AutoInt와 비교함.
AutoInt는 all features를 embedding로 변환하고 그 위에 self-attention을 적용함. 하지만, details를 살펴보면 AutoInt는 FT-Transformer와 매우 다름. AutoInt embedding layer는 feature biases를 포함하지 않고 backbone은 vanilla Transformer와 매우 다름. 그리고 inference 과정에 [CLS] token을 사용하지 않음.
2. 좋은 성능을 위해서 Feature Tokenizer에 있는 feature biases가 필수적인지 확인함.
Transformer's backbone의 우수성과 feature biases의 필요성을 확인함.
5.3 Obtaining feature importances from attention maps
attention maps가 샘플 집합에 대해 FT-Transformer의 feature importance 원천으로 적합한지 평가함.
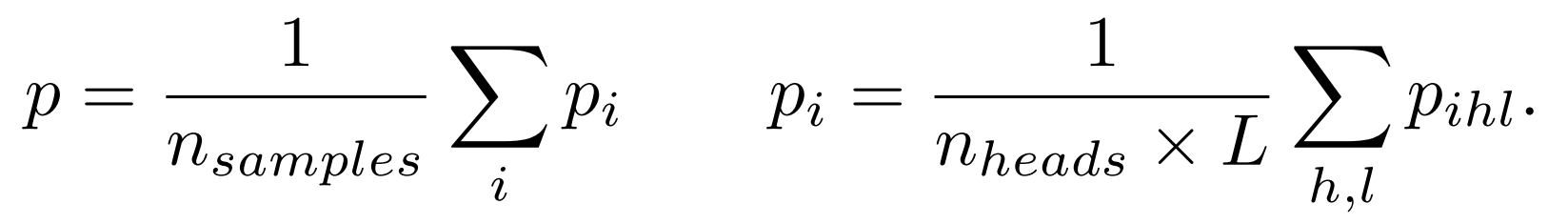
i번째 sample에 대해, [CLS] token에 대한 average attention map 를 계산함. 를 평균내서 feature importance를 나타내는 하나의 분포 p를 만듬. 수식에서 은 i번째 sample의 [CLS] token에 대한 l번째 layer의 forward pass로 부터 만들어진 h번째 head's attention map이다. 이 방식은 하나의 샘플에 하나의 forward가 필요하기 때문에 효율적이다.
위 접근 방식을 평가하기 위해서, Intergrated Gradients(IG)와 비교했다. IG는 미분 가능한 어느 모델에나 적용 가능한 일반적인 기술이다. permutation test(PT)를 사용했다. 제안한 방식은 reasonable한 feature importances를 생산하고 IG와 비슷한 성능을 보였다. (IG의 feature importance와 비슷하다는 것은 아님) IG는 크기의 정도가 더 느리게 할 수 있고 PT 형태의 baseline은 의 forward pass를 요구한다는 점을 감안하면, 단순한 averaging of attention maps는 비용 효율적인면에서 좋은 선택이 될 수 있다.

6. Conclusion
본 논문에서 저자들은 tabular data를 위한 현재 상황을 조사하고 tabular DL의 baseline 상태를 향상시켰다. 첫째, simple ResNet-like architecture가 효과적인 baseline의 역할을 할 수 있음을 증명했다. 둘째, FT-Transformer를 제안했다. FT-Transformer는 transformer의 간단한 변형이지만, 대부분의 tasks에서 다른 DL 솔루션을 능가한다. 저자들은 new baselines를 GBDT와 비교했다. GBDT는 일부 tasks에서 여전히 우수하다.
