Abstract
- SER 은 고정된 카테고리의 개수로 감정을 분류하기에 이는 불충분할 수 있음
- 따라서 emotion을 묘사하고자 하였으며, 이를 위해 캡셔닝 기술을 적용했음
- 텍스트 디코더 : 라마, 오디오 인코드 : 휴버트, 이 둘사이를 이어주는 것으로 QFormer 사용
- QFormer는 감정과 관련된 speech feature을 추출함.
Introduction
- frstly, how to extract the emotion-related speech features from the original speech inputs; and secondly, how to generate high-quality, human-like speech emotion descriptions
- 첫번째 챌린지를 위한 방안
- we employ QFormer as Bridge-Net to compress HuBERT features
- HuBERT만 사용하면 좀 무거우니까, Qformer을 birdge net으로 사용해서 HuBERT feature을 압축해줬음
- we employ QFormer as Bridge-Net to compress HuBERT features
- 두번째 챌린지를 위한 방안
- 잘 학습된 언어모델 사용
- 첫번째 챌린지를 위한 방안
Method
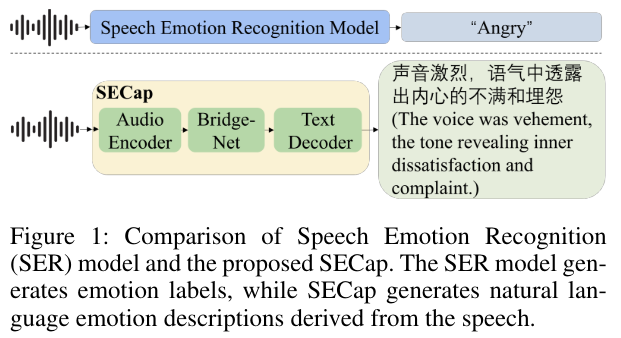
speech emotion recognition(SER)과 제안하는 SECap을 비교함.
SER은 emotion labels를 만듬.
SECap은 음성으로 부터 감정 묘사를 생성함.
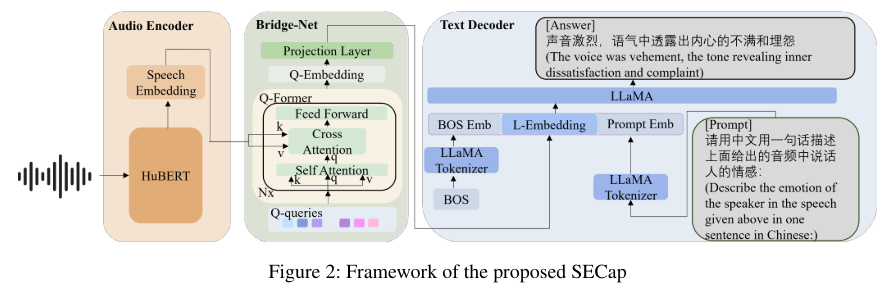
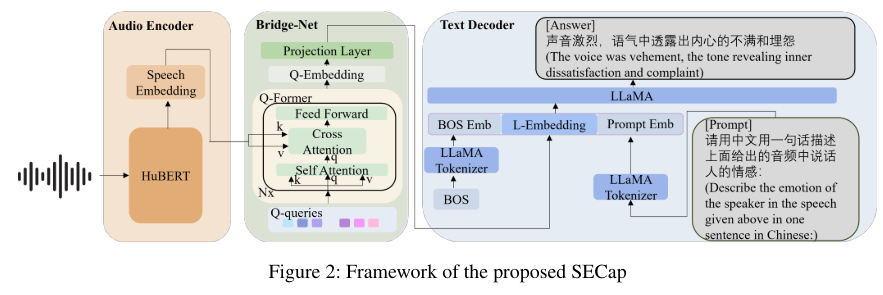
- Encoder-Decoder architecture, as illustrated in Figure 1.
- The audio encoder extracts speech features
- Bridge-Net extracts emotion-related speech features and transforms them into the text decoder’s feature space.
- audio feature을 text decoder에 넣어도 되나?→bridge net을 학습해서 text decoder에 넣을 수 있도록 학습하게 하는 것. speech representation을 text representation space에 projection 시키는 것으로 이해하면 됨
- The text decoder then generates speech emotion captions based on these features.
- emotion-related representations를 얻기 위한 Bridge-Net 구조의 2가지 핵심 포인트 설명함.
- 마지막으로, 전반적인 SECap의 훈련 과정에 대해 설명함.
Model Architecture
The audio encoder extracts speech features, and Bridge-Net extracts emotion related speech features and transforms them into the text decoder’s feature space- HuBERT- based audio encoder(훈련이 된 모델임) 강력한 speech feature extraction을 통해서 speech embedding을 만둘 수 있음. 하지만, frame-level에서는 계산량이 많이 필요함.
- Q-Former-based Bridge-Net
- features를 압축함. (ex. 2048 dimension → 128 dimension)
- acoustic 정보는 speech emotion과 직접적으로 관련 있고
- content 정보는 transcriptions로 부터 얻을 수 있음.
- 결론) Bridge-Net은 감정과 관련된 음향 정보를 추출하고 맥락 정보를 제거하는데 사용됨.
- 맥락 정보 : 대화 내용. (내용 자체와 그 사람의 감정이 상반될 수 있기 때문에, 이를 제거하고 사용한다는 것)
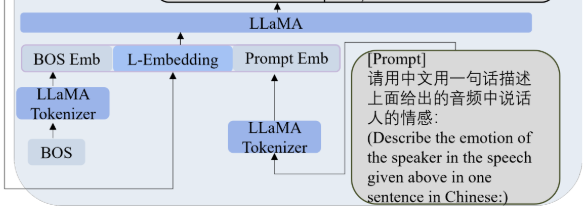
- LLaMA-based text decoder
- LLaMA를 사용함.
- LLaMA’s input format과 맞추기 위해서 we position L-Embedding between the “BOS” and a prompt.
- 이 방법은 prompt로 LLaMA의 아웃풋을 제한해서 더 정확한 speech emotion captions를 만들 수 있음.
- 시작 토큰인 BOS embedding을 붙여주는 것이 라마 모델의 필수 요건임
- L-embedding은 라마 임베딩으로, bridge model의 output이라고 보면 됨
- HuBERT- based audio encoder(훈련이 된 모델임) 강력한 speech feature extraction을 통해서 speech embedding을 만둘 수 있음. 하지만, frame-level에서는 계산량이 많이 필요함.
Q-Former
- self-attention, cross-attention, and linear layers로 이루어져 있음.
- Q-queries are learnable parameters for extracting speech embedding
- 쿼리는 학습의 대상이 됨
- 이 쿼리는 attention 이 감정에 집중할 수 있도록 learnable param을 만드는 것.
Q-qureis, q (n_q,d_q)
- n_q is the number of Q-queries
- d_q is the dimension of Q-queries
Speech embedding, S, (n_s,T_s,d_s)
- n_s is the batch size
- T_s is the number of time steps
- d_$ is the dimension of speech embedding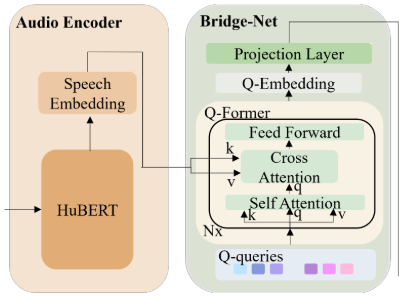
이 attention mechanism은 speech embedding안에서 Q-queries와 관련된 features를 검색하게 함.
Q-Former의 아웃풋을 Q- Embedding으로 표기함. Qe
input speech와 상관없이 고정된 길이를 갖게 함.
이 고정된 길이의 표현은 길이가 다른 다양한 발화 입력에 대한 일반화 성능을 향상시킴.
Obtain Emotion-Related Representations
human-labeled speech emotion captions 과 the transcriptions을 함께 사용함
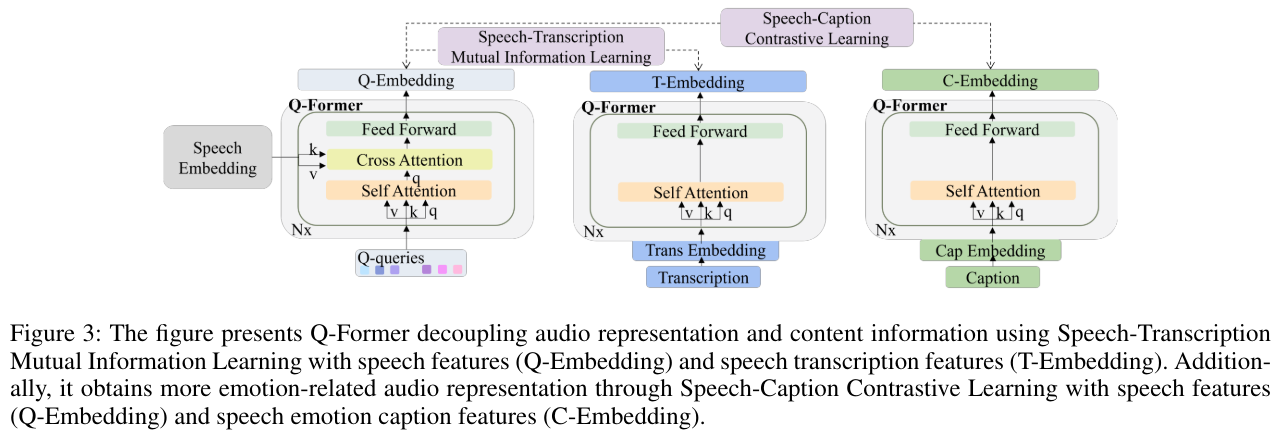
seech-Transcription Mutual Information Learning을 사용해서 speech content로 부터 speech features를 풀음(분리함.)
Speech-Caption Contrastive Learning을 사용해서 emotion-related speech features를 추출함.
- Q-former으로 학습시키고 전체 모델을 학습시키는 구조임
peech-Transcription Mutual Information Learning (STMIL)
- mutual information은 상호 정보를 의미함.
- speech content가 감정 평가에 영향을 줄 수 있음. 예를 들어, 기쁨을 표현하는 발화가 차분하게 전달될 수 있음. speech features와 contents 간의 상관 관계를 최소화하여 speech가 감정 캡션 생성에 미치는 영향을 줄이기 위해 Speech-Transcription Mutual Information Learning을 제안함.(예상과 달랐던 부분임 내 생각에는 발화 내용도 사용 할것이라고 생각했는데.. 반대였음.)
- Speech Embedding과 Trans Embedding을 Q-Former에 도입하여, Q-Embedding(Qe)과 T-Embedding(Qt)을 얻음. 이를 통해 통합된 표현 공간 내에서 음성과 그 콘텐츠를 비교할 수 있음. Qe와 Qt 사이의 상관 관계를 평가하기 위해 mutual information I (Qt;Qe )을 선택함.
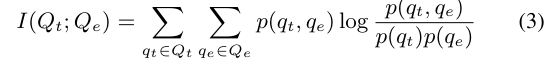
- p(qt, qe)는 Qt와 Qe의 결합 확률 분포를 나타내며, p(qt) 및 p(qe)는 각각 Qt와 Qe의 주변 확률 분포를 나타냄.
- 그러나 Qe와 Qt 사이의 matmul information을 직접 계산하는 것은 그들의 알려지지 않은 고차원적인 특성 때문에 불가능함.
- 상호 정보의 하한을 계산하는 방법:MINE (Belghazi et al. 2018) and infoNCE (Van Den Oord, Vinyals et al. 2017)
- 상호 정보의 상한을 계산하는 방법: vCLUB (Cheng et al. 2020)
- vCLUB을 사용해서 loss function으로 사용하고 speech features와 content 사이의 상관관계를 줄임(즉, speech featuresㅇ와 content사이의 관련성을 낮췄다고 보면 됨.)
- 조건부 확률인 q(yi|xi)와 q(yj|xi)
- 이는 i번째와 j번째 Qe 샘플이 주어진 i번째 Qt 샘플의 확률을 나타냄
- 로그는 Qt에 조건을 걸어 Qe의 dissimiarity을 포착하며,
- 모든 쌍 조합에 대해 합산함으로써 Qe와 Qt 사이의 상호 정보 상한을 제공함.
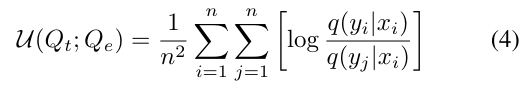
- 음성이 가지고 있는 정보와 텍스트가 가지고 있는 정보의 교집합을 계산을 함 . 교집합을 낮추는 방향으로 계산을 하는 건데,, 슬픈 노래에 기쁜 가사가 있을수있는데 슬픈 노래인것만 집중을 하기 위해서 이런 방향을 사용함. ⇒ 맥락 정보 제거
Speech-Caption Contrastive Learning (SCCL)
speech features는 content, background noise, emotion-related 등 풍부한 정보를 가지고 있음.
LLaMA가 처리하는 speech features의 복잡성을 완화하기 위해서,
Q-Former가 speech emotion caption과 관련성이 높은 features만 추출하게 하는 것을 목표로 함.
따라서, speech features와 text modality사이의 gap을 연결함.
- 수식 정리
- 는 음성 특징을 나타내며, 로 참조됩니다.
- 는 캡션 특징을 나타내며, 로 참조됩니다.
- 의 거리를 측정하기 위해서 cosine similarity를 사용함.
- 와 사이의 사이의 거리를 최소화하는 것을 목표로 함.
- Q-Former에게 더 많은 감정 관련 특징을 추출하도록 유도하여 점진적으로 텍스트 형식에 접근함.
- CLAP 논문에서 영감을 받아서 contrastive learning 접근법을 사용함.
- 이를 통해 다른 발화 샘플의 Qe 간의 거리를 정확하게 나타내어, 유사한 감정을 가진 발화가 더 가까운 Qe 거리를 유지하고, 비슷하지 않은 감정을 가진 발화가 더 멀리 떨어진 Qe 거리를 유지하도록함.
- To mitigate the influence of similar emotions in negaㄴtive samples during contrastive learning, we partition the dataset into N distinct categories based on human-labeled speech emotion labels.
- 이것은 speech emotion captions에서 categories간의 상당한 차이를 보장함. 따라서 모델의 구별하는 능력을 향상시킴.
- 훈련 단계 정리
- 각각의 N개의 세트에서 K개의 speech-caption pair를 선택함.
- 이때, 개별 ()에 대해서 1개의 해당하는 (), (K - 1)개의 유사한 감정을 가진 (로 참조됨), 그리고 (NK - K)개의 다른 감정을 가진 (로 참조됨)가 있도록 함
- 발전된 contrastive learning을 위해서, 훈련 방식을 아래와 같이 고안함.
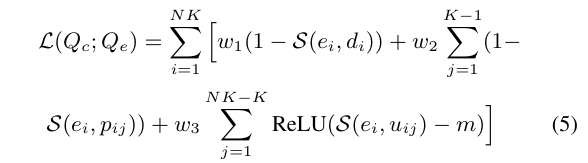
- 위 식에서 w1,w2 w3는 가중치 상관계수로 loss 함수에서 각 term의 기여를 통제함.
- threshold 값 m은 speech feature 와 관련 없는 speech emotion caption feature 의 거리를 통제하는 margin임.
- speech의 feature만 뽑았고, CL을 통해서 먼거는 멀게 가까운건 가깝게 처리해준것
Training process
두 단계의 학습 과정
- HuBERT에서 추출한 음성 특징을 압축하여 감정과 관련된 속성을 얻는 것
- 이러한 특징을 LLaMA의 표현 공간에 정렬하는 것
First trining stage
STMIL과 SCCL를 결합하여 그림 3처럼 학습시킴.
HuBERT 모델은 고정된 상태(훈련되지 않음)
BLIP-2에서 영감받아서, Bert_base의 사전 훈련된 파라미터를 사용해서 Q-Former를 초기화함.
training loss
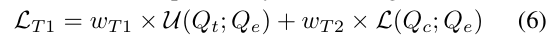
wT 1 and wT 2 control the contribution of STMIL and SCCL.
Second Stage
Q-Former와 projection layer를 fine-tune하여 Q-Former 결과를 효과적으로 LLaMA에 결합함.
LLaMA와 HuBERT의 파라미터는 여전히 고정된 상태로 훈련되지 않음.
We insert a “BOS” token before the L-Embedding to align with the in- ference format.
SECap의 일반화 능력을 향상시키기 위해, "화자의 감정을 단일한 중국어 문장으로 표현하라"는 지시에 따라 30개의 의미론적으로 유사한 문장을 만듬. 훈련 과정에서 30개 중 임의로 선택하여 L-Embedding 뒤에 연결해서 붙였음.
그 다음으로는 인간이 라벨링한 speech caption C를 지시에 추가하고, LLaMA가 캡션 를 생성할 수 있도록 teacher-forcing 방식을 사용함.
그런 다음 Cross-entropy loss (CELoss)를 학습 목적 함수로 채택함.