저번 chapter 11에서는 포인터를 도입하여 어떻게 함수 argument로써 사용되고 반환값으로써 사용되는지 알아보았다. 이번 챕터는 포인터의 또다른 적용에 대해 알아볼 것이다.
포인터가 배열 요소를 가리킬 때, C언어는 빼기와 더하기 등의 수학 연산을 포인터에 수행할 수 있도록 허용하며, array subscript를 포인터가 대체할 수 있도록 한다.
1. Pointer Arithmetic
Section 11.5에서 포인터는 배열 요소를 가리킬 수 있다는 것을 보았었다. 예를 들어 a와 p는 아래의 선언을 따른다고 생각해보자.
int a[10], *p;우리는 아래처럼 쓰는 것으로 p가 a[0]을 가리키도록 만들 수 있다.
p = &a[0];우리가 무엇을 했는지 아래에 시각적으로 표현했다.

우리는 이제 p를 통해 a[0]에 접근할 수 있다. 예를 들어 우리는 아래의 예시처럼 a[0]에 5의 값을 저장할 수 있다.
*p = 5;
포인터 p가 배열 a의 요소를 가리키도록 하는 것은 딱히 흥미로운 일은 아니다. 그러나 pointer arithmetic(address arithmetic)을 p에 수행하는 것으로, 우리는 a의 또다른 요소에 접근할 수 있다. C언어는 딱 세 가지 형태의 포인터 연산(pointer arithmetic)을 허용한다.
Adding an integer to a pointer
Subtracting an integer from a pointer
Subtracting one pointer from another각 3가지의 연산에 대해 자세하게 알아보자. 뒤에 나올 예제들은 아래의 선언을 따른다고 생각하자.
int a[10], *p, *q, i;Adding an Integer to a Pointer
정수 j를 포인터 p에 더하는 것은 p가 가리키는 요소의 뒤인 요소 j의 자리를 가리키는 포인터가 생성된다. 더 정확하게 말하면, p가 배열의 요소 a[i]를 가리킨다면, p + j는 a[i+j]를 가리키게 된다.(당연하게도 a[i+j]가 존재해야한다.)
아래의 에제는 포인터 덧셈을 표현한다. 다이어그램은 다양한 지점의 계산에서 p와 q의 값을 보여준다.
p = &a[2];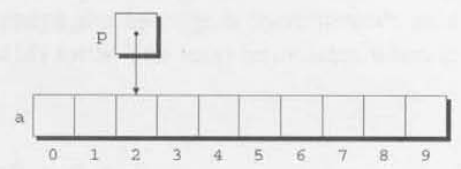
q = p + 3;
p += 6;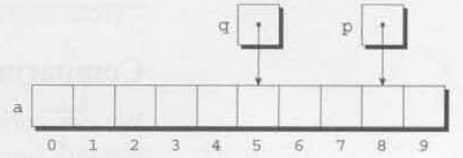
Subtracting an Integer from a Pointer
만약 p가 a[i]를 가리키면, p - j는 a[i-j]를 가리킨다.
p = &a[8];
q = p - 3;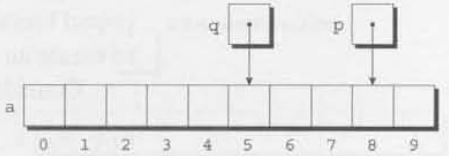
p -= 6;
Subtracting One Pointer from Another
한 포인터에서 다른 포인터를 뺄 때, 결과는 포인터 사이의 거리이다(배열 요소에서 측정됨). 그래서 만약 p가 a[i]를 가리키고 q가 a[j]를 가리킨다면 이는 i - j와 동일하다.
p = &a[5];
q = &a[1];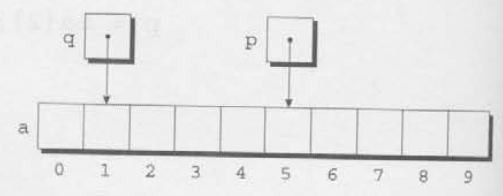
i = p - q; /* i is 4 */
i = q - p; /* i is -4 */배열 요소를 가리키고 있지 않은 포인터에 수학적 연산을 수행하는 것은 undefined behavior를 발생시킨다. 그 이상으로, 같은 배열의 요소를 가리키는게 아니라면 포인터끼리 뺄셈 연산을 하는 것은 undefined이다.
Comparing Pointers
관계 연산자(relational operator) (<, <=, >, >=)와 동등 연산자(equality operator) (==, !=)를 사용하여 포인터를 비교할 수 있다. 관계 연산자를 사용하여 두 포인터를 비교하는 것은 같은 배열의 요소를 가리키고 있을 때에만 의미가 있다. 비교의 결과는 배열에서 두 요소의 상대적 위치에 의존한다. 아래의 예시를 보자.
p = &a[5];
q = &a[1];p <= q의 값은 0이고, p >= q의 값은 1이다.
Pointers to Compound Literals
복합 리터럴(compound literal)로 작성된 배열의 요소를 가리키는 포인터도 규칙에 어긋나지 않는다. 복합 리터럴은 이름이 없이 배열을 만드는 것에 사용될 수 있는 C99의 특성이다. 아래의 예시를 보자.
int *p = (int []){3, 0, 3, 4, 1};p는 정수 3, 0, 3, 4, 1을 포함한 5개의 요소를 가진 배열의 첫 번째 요소를 가리킨다. 복합 리터럴을 사용하는 것은 먼저 배열을 선언하고 p가 그 배열의 첫번째 요소를 가리키도록 하는 수고를 덜어준다.
int a[] = {3, 0, 3, 4, 1};
int *p = &a[0];2. Using Pointers for Array Processing
포인터 연산은 포인터 변수를 반복적으로 증가시는 것으로 배열의 요소를 방문할 수 있도록 해준다. 배열 a의 요소의 합을 구하는 아래의 예시를 보자. 예시에서는 포인터 변수 p가 처음에 a[0]을 가리키도록 했다. 루프를 지나는 동안 p는 증가한다. 결과적으로 a[1], a[2], ...를 가리키면서 점점 앞으로 계속 증가한다. p가 a의 마지막 요소를 지나는 순간 루프는 종료된다.
#define N 10
...
int a[N], sum, *p;
...
sum = 0;
for (p = &a[0], p < &a[N]; p++)
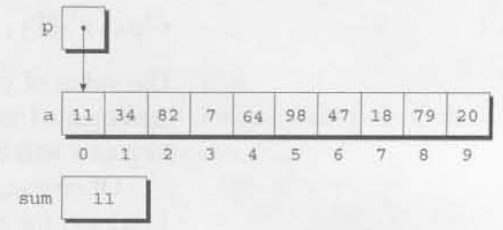
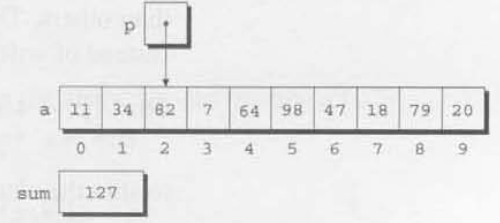
sum += *p;처음 세번의 루프 반복이 끝날 때의 a, sum, p의 내용물을 아래에 그림으로 나타냈다.
첫번째 반복이 끝날때
두번째 반복이 끝날때

세번째 반복이 끝날때
for 구문 내부의 p < &a[N]는 특별히 주목할만 하다. a[N]이라는 요소는 존재하지 않는데(a은 0부터 N - 1까지만 index되니까), a[N]에 주소 연산자를 적용하는 것은 규칙에 맞다. 이것은 조금 이상하게 보일 수 있다. a[N]을 이러한 의도로 사용하는 것은 아주 안전하다. 왜냐하면 루프는 a[N]의 값을 검사하려고 시도하지 않을 것이기 때문이다.
루프의 body는 p가 &a[0], &a[1], ..., &a[N-1]와 같아지면 실행될 것이지만, p가 &a[N]과 같을 때에는 루프가 종료된다.
우리는 subscripting을 대신 사용하는 것으로 포인터 없이 루프를 쉽게 작성해왔다. 포인터 연산은 실행 시간을 줄일 수 있다는 주장이 종종 인용된다. 그러나 이는 구현에 따르는데, 어떤 C컴파일러는 subscripting에 의존하는 루프가 더 나은 코드를 생성하기 때문이다.
Combining the * and ++ Operators
C 프로그래머들은 배열 요소를 처리하는 구문 안에서 종종 *(indirection)과 ++ 연산자를 사용한다. 배열 요소 안에 값을 저장하고 다음 요소로 나아가는 단순한 경우를 생각해보자. 배열 subscripting을 사용한다면 아래처럼 작성할 수 있을 것이다.
a[i++] = j;만약 p가 배열 요소를 가리킨다면, 대응되는 구문은 아래와 같을 것이다.
*p++ = j;*의 우선순위보다 후위 ++의 우선순위가 더 높기 때문에 컴파일러는 이를 아래처럼 해석한다.
*(p++) = j;p++의 값은 p이다.(후위 ++를 사용하면, p는 표현식이 전부 평가될 때까지 증가되지 않는다.) 그래서 *(p++)의 값은 *p가 될 것인데, 이는 p가 가리키는 object이다.
당연하게도, *p++는 *과 ++를 사용할 수 있는 경우에 수에 불과하다. (*p)++처럼도 쓸 수 있는데, 이는 p가 가리키는 object의 값을 반환하고, 그 후 object를 증가시킨다(p 자체는 변화하지 않음). 만약 이게 혼란스럽다면 아래의 테이블이 도움을 줄 수 있다.
Expression Meaning
*p++ or *(p++) Value of expression is *p before increment; increment p later
(*p)++ Value of expression is *p before increment; increment *p later
*++p or *(++p) Increment p first; value of expression is *p after increment
++*p or ++(*p) Increment *p first; value of expression is *p after increment이 4가지 조합이 프로그램 내에서 나타날 수 있는 전부이다. 우리가 가장 자주 볼 것은 *p++인데, 이는 루프에서 편리하다.
for (p = &a[0]; p < &a[N]; p++)
sum += *p;배열 a의 요소의 합을 구하기 위해 위의 예시처럼 쓰는 대신에 아래처럼도 쓸 수 있다.
p = &a[0];
while (p < &a[N])
sum += *p++;*와 --연산자는 *과 ++연산자와 같은 방법으로 혼합할 수 있다. Section 10.2의 stack 예시를 다시 가져와보자. 맨 처음 stack은 top이라는 이름을 가진 정수형 변수에 의존하여 contents 배열의 "top-of-stack" 위치를 추적했다. 처음에 contents 배열의 요소 0을 가리키는top을 포인터 변수로 대체할 수 있다.
아래에 새로운 push와 pop함수가 있다.
void push(int i)
{
if (is_full())
stack_overflow();
else
*top_ptr++ = i;
}
int pop(void)
{
if (is_empty())
stack_underflow();
else
return *--top_ptr;
}*top_ptr--가 아니고 *--top_ptr을 사용한 이유는 pop이 top_ptr이 이전에 가리키던 값을 가져오기 전에 top_ptr을 감소시키길 원하기 때문이다.
3. Using an Array Name as a Pointer
포인터 연산은 배열과 포인터가 관계되어 있는 하나의 방법이지만, 이것만이 두 개를 이어주는 것은 아니다. 또다른 핵심 관계가 있는데, 배열의 이름이 배열의 첫번째 요소를 가리키는 포인터로 사용될 수 있따는 것이다. 이 관계는 포인터 연산을 더 간단하게 만들고, 배열과 포인터를 더 다용도로 만든다.
a가 아래처럼 선언되었다고 생각해보자.
int a[10];배열의 첫번째 요소를 가리키는 포인터로 a를 사용하는 것으로 a[0]을 수정할 수 있다.
*a = 7; /* stores 7 in a[0] */우리는 a + 1을 통해 a[1]을 수정할 수 있다.
*(a+1) = 12; /* stores 12 in a[1] */일반적으로 a + i는 &a[i]와 동일하고(둘다 a의 요소 i를 가리키는 포인터를 표현한다), *(a+i)는 a[i]와 동일하다(요소 i 자체를 표현한다). 다른 말로 말하면, 배열 subscripting은 포인터 연산의 하나의 형태로써 볼 수 있다는 것이다.
배열의 이름이 포인터의 역할을 할 수 있따는 사실은 배열을 단계적으로 통과하는 루프를 작성하는 것이 더 쉽게 된다는 것이다. Section 12.2로부터의 루프를 생각해보자.
for (p = &a[0]; p < &a[N]; p++)
sum += *p;루프를 더 간단하게 만들면, 우리는 a와 &a[N]으로 부터 나온 &a[0]을 a + N으로 대체할 수 있다.
for (p = a; p < a + N; p++)
sum += *p;비록 배열의 이름이 포인터로 사용될 수 있지만, 새로운 값을 거기에 할당하는 것은 불가능하다. 어디를 가리키게 하든지 이 시도는 에러를 발생시킨다.
while (*a != 0)
a++; /*** WRONG ***/우리는 항상 a를 포인터 변수에 복사할 수 있고, 포인터 변수를 변화시킬 수 있다.
p = a;
while (*p != 0)
p++;Array Argument (Revisited)
함수로 전달 되었을 때, 배열의 이름은 항상 포인터로써 다루어진다. 아래의 함수는 정수의 배열에서 가장 큰 요소를 반환하는 예시이다.
int find_largest(int a[], int n)
{
int i, max;
max = a[0];
for (i = 1; i < n; i++)
if (a[i] > max)
max = a[i];
return max;
}find_largest를 아래처럼 호출한다고 생각해보자.
largest = find_largest(b, N);이 호출은 b의 첫번째 요소를 가리키는 포인터가 a에 대입되도록 하고, 배열 자체가 복사되지는 않는다.
배열 argument가 포인터로써 다루어진다는 사실은 중요한 결과이다.
- 일반적인 변수가 함수에 전달되었을 때, 값이 복사된다. parameter에 대응되는 어떤 변화도 변수에 영향을 미치지 않는다. 하지만, argument로써 사용되는 배열은 변화에 보호받지 못하는데, 배열 자체가 복사본이 아니기 때문이다. 예를 들어 아래의 함수(Section 9.3에서 본)는 배열의 각각의 요소들을 0으로 수정한다.
void store_zeros(int a[], int n)
{
int i;
for (i = 0; i < n; i++)
a[i] = 0;
}배열 parameter가 변하지 않게 하는 것을 나타내기 위해서 우리는 선언 앞에 const를 포함해야 한다.
int find_largest(const int a[], int n)
{
...
}만약 const가 존재한다면, 컴파일러는 find_largest의 body 안에서 a의 요소에 대입이 있는지 확인할 것이다.
-
배열을 함수에 전달하는 것에 걸리는 시간은 배열의 크기에 의존하지 않는다. 큰 배열을 전달하는 것에 대해서 어떠한 페널티도 존재하지 않는데, 이는 배열의 복사본으로 만들어지는 것이 아니기 때문이다.
-
배열 parameter는 원한다면 포인터로써 선언될 수 있다. 예를 들면
find_largest는 아래와 같이 정의될 수 있다.
int find_largest(int *a, int n)
{
...
}a를 포인터로 선언하는 것은 배열로 선언하는 것과 동일하다. 컴파일러는 포인터와 배열을 동일한 것처럼 선언하도록 처리할 것이다.
배열에 대한 parameter를 선언하는 것은 parameter를 포인터로 선언하는 것과 동일하지만, 변수에 대해서는 아니다.
int a[10];위의 선언은 컴파일러가 10개의 정수에 대한 공간을 설정한다.
int *a;위의 선언은 컴파일러가 포인터 변수에 대한 공간을 할당하도록 한다. 후자의 경우 a는 배열이 아니다. 이를 배열처럼 사용하려고 한다면 재앙적인 결과를 발생시킬 수 있다.
*a = 0; /*** WRONG ***/위의 대입은 a가 가리키는 곳에 0을 대입할 것이다. a가 가리키는 곳이 어디인지 모르기 때문에, 프로그램에 대한 효과는 undefined이다.
- 배열 parameter가 사용되는 함수는 배열의 연속적인 요소인 "조각"을 전달받을 수 있다.
find_largest가 배열b의 어떤 부분에, 예를 들면b[5],...,b[14]와 같은 요소들 중 가장 큰 요소를 확인하도록 하고 싶다고 가정해보자. 우리는b[5]의 주소를 함수로 전달할 것이고, 10개의 요소를 확인할 것이다.find_largest는 10개의 배열 요소를 검사해야 하고,b[5]에서 시작해야 한다.
largest = find_largest(&b[5], 10);Using a Pointer as an Array Name
만약 우리가 포인터로써 배열의 이름을 사용한다면, C언어는 subscript를 하기 위해 포인터를 배열의 이름처럼 사용하도록 허용할까? 가능하다. 아래의 예시를 보자.
#define N 10
...
int a[N], i, sum = 0, *p = a;
...
for (i = 0; i < N; i++)
sum += p[i];컴파일러는 p[i]를 *(p+i)처럼 다룰 것이다. 그리고 이는 완벽하게 포인터 연산의 규칙에 맞는다. 비록 포인터를 통해 subscript하는 능력은 별것아닌 것처럼 보일 수 있지만, Section 17.3에서 이에 대해 실질적인 사용방법을 알아볼 것이다.
4. Pointers and Multidimensional Arrays
포인터가 one-dimensional 배열의 요소를 가리킬 수 있는 것처럼, multidimensional 배열의 요소를 가리키는 것 또한 가능하다. two-dimensional array를 사용하여 알아볼 것인데, 더 높은 dimensional array에도 똑같이 적용이 가능하다.
Processing the Elements of a Multidimensional Array
Section 8.2에서 봤던 것처럼, C언어는 two-dimensional array를 row-major order로 저장한다. 다른말로 말하면, row 0의 요소가 처음에 오고, 그 뒤에 row 1의 요소가 오고 이런 방식으로 계속 진행된다. r row의 배열은 아래와 같은 모습을 보인다.
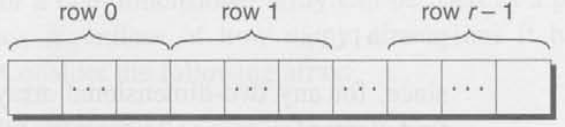
우리는 포인터를 통해 작업할 때 이러한 레이아웃의 장점을 이용할 수 있다. 만약 포인터 p가 two-dimensional array 안의 첫번째 요소를 가리킨다면(row 0, column 0), 우리는 p를 반복적으로 증가시키는 것으로 배열 내부의 모든 요소를 방문할 수 있다.
예를 들어, two-dimensional array의 모든 요소를 초기화하는 문제가 있다고 생각해보자.
int a[NUM_ROWS][NUM_COLS];중첩된 for 루프문이 사용되는 것이 명백하다.
int row, col;
...
for (row = 0; row < NUM_ROWS; row++)
for (col = 0; col < NUM_COLS; col++)
a[row][col] = 0;그러나 a를 정수의 one-dimensional array로써 본다면(배열이 저장되는 방식), 우리는 한 쌍의 루프를 단일 루프로 대체할 수 있다.
int *p;
...
for (p = &a[0][0]; p <= &a[NUM_ROWS-1][NUM_COLS-1]; p++)
*p = 0;이 루프는 p가 a[0][0]을 가리키는 것으로 시작한다. p의 연속적인 증가는 p가 a[0][1], a[0][2], a[0][3],...순으로 가리키도록 한다. p가 a[0][NUM_COLS-1]에 도달하면(row 0의 마지막요소), p가 또 증가해 p 는 a[1][0](row 1의 첫번째요소)을 가리키게 된다. 이러한 과정은 p가 배열의 마지막 요소인 a[NUM_ROWS-1][NUM_COLS-1]을 지나갈 때까지 이어진다.
two-dimensional array를 one-dimensional처럼 다루는 것은 치트(cheating)처럼 보일 수 있지만, 대부분의 C 컴파일러에서 작동한다. 이렇게 하는 것이 좋은 생각인지는 또다른 문제이다. 이러한 기술은 명백하게 프로그램의 가독성을 안좋게 하겠지만, 최소한 오래된 컴파일러에서는 효율성을 제공한다. 그렇지만 많은 현대의 컴파일러는 조금의 속도의 이점도 없다.
Processing the Rows of a Multidimensional Array
two-dimensional array의 하나의 row안에서의 요소를 처리하는 과정은 어떻게 될까?
우리는 포인터 변수 p를 사용할 선택지를 가지고 있다. row i의 요소들을 방문하기 위해서는, 우리는 p가 배열 a의 row i에 있는 요소 0을 가리키도록 초기화해야 한다.
p = &a[i][0];또는 아래와 같이 간단하게 쓸 수도 있다.
p = a[i];어떤 two-dimensional array a에 대해, 표현식 a[i]는 row i 안의 첫번째 요소를 가리킨다. 왜 이렇게 작동하는지 보기 위해, 우리는 배열 subscripting을 포인터 연산에 관계시키는 마법의 공식(magic formula)을 떠올려보자. 어떤 배열 a에 대해, 표현식 a[i]는 *(a + i)와 같다. 그래서 &a[i][0]는 &(*(a[i] + 0))과 같고, 이는 &*a[i]와 같고, 이는 a[i]와 같다. 아래의 루프문에서 이 간단한 식을 이용하여 배열 a의 row i를 모두 지운다.
int a[NUM_ROWS][NUM_COLS], *p, i;
...
for (p = a[i]; p < a[i] + NUM_COLS; p++)
*p = 0;a[i]가 배열 a의 row i를 가리키는 포인터이기 때문에, 우리는 argument로써의 one-dimensional array를 요구하는 함수에 a[i]를 전달할 수 있다. 다른 말로 말하면, one-dimensional array로 작동하도록 설계된 함수는 two-dimenional array에 속해있는 row로도 작동할 것이다. 결과적으로 find_largest나 store_zeros와 같은 함수는 생각했던 것보다 더 다목적으로 쓸 수 있다는 것이다. 우리가 one-dimensional array에서 가장 큰 요소를 찾게 설계한 함수 find_largest를 생각해보자. 우리는 two-dimensional array a의 row i에서 가장 큰 요소를 결정하는 것에 find_largest를 쉽게 사용할 수 있다.
largest = find_largest(a[i], NUM_COLS);Processing the Columns of a Multidimensional Array
two-dimensional array의 column 안의 요소를 처리하는 것은 쉽지 않은데, 왜냐하면 배열이 column이 아닌 row로 저장되기 때문이다. 배열 a의 column을 지우는 루프를 보자.
int a[NUM_ROWS][NUM_COLS], (*p)[NUM_COLS], i;
...
for (p = &a[0]; p < &a[NUM_ROWS]; p++)
(*p)[i] = 0;요소들이 정수이고 NUM_COLS의 길이를 가지는 배열의 포인터인 p를 선언했다. (*p)[NUM_COLS]안에서 *p를 둘러싸는 괄호는 필요하다. 만약 이 괄호가 없다면 컴파일러는 p를 포인터의 배열이 아닌 배열을 가리키는 포인터로 처리하기 때문이다. 표현식 p++는 다음 row의 시작부분으로 p를 진행시킨다. 표현식 (*p)[i]에서 *p는 a의 row 전체를 표현하는데, 그래서 (*p)[i]는 row에서 column i의 요소를 선택할 수 있다. (*p)[i]의 괄호는 필수적인데, 왜냐하면 컴파일러가 *p[i]를 *(p[i])로 해석할 수 있기 때문이다.
Using the Name of a Multidimensional Array as a Pointer
one-dimensional 배열의 이름은 포인터로써 사용될 수 있는 것처럼, 어떤 배열이 얼마나 많은 dimensional을 가지고 있는지 상관없이 배열의 이름은 포인터로 사용될 수 있다. 그러나 주의가 필요한데, 아래의 배열을 보자.
int a[NUM_ROWS][NUM_COLS];a는 a[0][0]을 가리키는 포인터가 아니다. 대신에 a는 a[0]을 가리키는 포인터이다.
이는 C언어의 관점에서 본다면 배열 a를 two-dimensional array가 아닌, 요소가 one-dimensional array인 one-dimensional array로써 취급하기 때문에 더욱 의미가 있다. 포인터로써 사용할 때, a는 자료형 int (*) [NUM_COLS]를 가지게 된다(길이가 NUM_COLS인 정수형 배열을 가리킨다).
a가 a[0]을 가리킨다는 것을 알고 있는 것은, two-dimensional array의 요소를 처리하는 루프를 간단하게 하는 것에 도움이 된다.
for (p = &a[0]; p < &a[NUM_ROWS]; p++)
(*p)[i] = 0;위 처럼 쓰는 것보다, 배열 a의 column i를 명확하게 하기 위해서 아래처럼 쓸 수도 있다.
for (p = a; p < a + NUM_ROWS; p++)
(*p)[i] = 0;이 지식이 유용하게 사용될 수 있는 또다른 상황은, 우리가 multidimensional array를 진짜 one-dimensional처럼 생각하는 함수에 대한 "트릭"을 원할 때이다. 예를 들어 우리가 배열 a에서 가장큰 요소를 찾기 위해 find_largest를 어떻게 사용하는지 생각해보자. find_largest의 첫번째 argument로 a(배열의 주소)를 전달하려고 할 것이고, 두번째로는 NUM_ROWS * NUM_COLS(a안의 요소의 전체 개수)를 전달하려고 할 것이다.
largest = find_largest(a, NUM_ROWS * NUM_COLS); /*** WRONG ***/불행하게도, 컴파일러는 이 구문에 반대하는데, 왜냐하면 a의 자료형이 int (*)[NUM_COLS]이고, find_largset는 자료형 int *를 원하기 때문이다. 올바른 호출은 아래와 같다.
largest = find_largest(a[0], NUM_ROWS * NUM_COLS);a[0]이 row 0의 요소 0을 가리키고, int *(컴파일러에 의해 변환된 뒤)의 자료형을 가지는데, 그래서 후자의 호출이 올바르게 작동할 것이다.
5. Pointers and Variable-Length Arrays(C99)
포인터는 variable-length arrays(VLAs)의 요소를 가리키는 것 또한 허용된다. 이는 C99의 특성이다. 일반적인 포인터 변수는 one-dimensional VLA의 요소를 가리키는 것에 사용된다.
void f(int n)
{
int a[n], *p;
p = a;
...
}VLA가 one dimension 이상을 가질 때, 포인터의 자료형은 첫번째 dimension을 제외한 각각의 dimension의 길이에 의존한다. two-dimensional의 경우를 보자.
void f(int m, int n)
{
int a[m][n], (*p)[n];
p = a;
...
}p의 자료형이 상수가 아닌 n에 의존하기 때문에, p는 variably modified type을 가진다고 말한다.p =a와 같은 대입의 유효성은 항상 컴파일러에 의해서 결정되는 것은 아니다. 예를 들면 아래의 코드는 m과 n이 동일할 때에만 올바르게 컴파일된다.
int a[m][n], (*p)[m];
p = a;만약 m과 n이 같지 않다면, p를 사용한 어떤 결과라도 undefined behavior를 유발할 수 있다.
varialby modified 자료형은 variable length array처럼 특정한 제한에 영향을 받는다. 가장 중요한 제한은 variably modified 자료형의 선언은 반드시 함수의 body나 함수의 prototype안에서만 나타나야 한다는 것이다.
일반적인 배열들에 작동하는 것처럼 VLA에 포인터 연산이 작동한다. two-dimensional arraya의 단일 column을 비우는 Section 12.4의 예제를 생각해보자. 이번엔 a를 VLA로 선언해보자.
int a[m][n];a의 row를 가리킬 수 있는 포인터는 아래와 같이 선언한다.
int (*p)[n];column i를 비우는 루프는 Secition 12.4에서 사용된 것과 거의 동일하다.
for (p = a; p < a + m; p++)
(*p)[i] = 0;Others
포인터 연산을 이해하지 못하겠다. 만약 포인터가 주소라면, p + j와 같은 표현식은 p에 저장된 주소에 j를 더하는 것인가?
아니다. 포인터 연산에서 사용되는 정수는 포인터의 자료형에 따라 크기가 조정된다. 만약 p가 int * 자료형이라면, p + j는 전형적으로 4 * j를 p에 더한것이 되는데, 이는 int 값이 4바이트를 사용하여 저장된다는 가정하이다. 그러나 p가 double *의 자료형을 가진다면, p + j는 8 * j를 p에 더할 것인데, 왜냐하면 double 값은 보통 8바이트의 길이이기 때문이다.
배열을 처리하는 루프를 작성할 때, 배열 subscripting이나 포인터 연산을 사용하는 것이 더 좋은가?
이 질문에는 대답하기 쉽지 않은데, 왜냐하면 이는 사용하는 machine과 컴파일러에 영향을 많이 받기 때문이다. 옛날 PDP-11에서 사용되는 C언어에서는, 포인터 연산은 더 빠른 프로그램을 만들었다. 현대의 컴파일러를 사용하는 현대의 machine은 배열 subscripting이 종종 더 빠르고, 훨씬 더 빠를 때도 있다. 중요한 것은 두 가지 방법을 모두 배우고, 작성하는 프로그램의 종류에 더 자연스러운 방법을 사용하는 것이다.
i[a]가 a[i]와 같다는 것을 어디선가 읽었다. 이건 맞는 말인가?
충분히 이상할 수 있는데, 맞는 말이긴 하다. 컴파일러는 i[a]를 *(i + a)로 처리하는데, 이는 *(a + i)와 동일하다. (일반적인 덧셈과 같이 포인터 덧셈도 교환이 가능하다) *(a + i)는 a[i]와 같다. 즉 다음에 C언어 난독화 대회(Obfuscated C contest)에 참여할 예정이 아니라면 i[a]는 프로그램에서 사용하지 마라.
왜 *a가 parameter 선언에서 a[]와 동일한가?
*a와 a[]모두 포인터가 argument로써 사용되기를 예상한다. a에 대해서도 두가지 경우에 대한 같은 작업이 가능하다.(포인터 연산과 array subscripting). 그리고 두 가지 경우에서, a는 자체적으로 함수안에서 새로운 값이 대입될 수 있다.(비록 C언어가 array 변수의 이름을 "상수 포인터"로써 사용을 허용하지만, array parameter의 이름에 대한 제한은 없다.)
*a와 a[]중 어떤 것을 array parameter로 선언하는게 더 좋은 스타일인가?
이것은 대답하기 어렵다. 어떤 관점에서는 a[]가 명확한 선택인데, *a가 모호하기 때문이다(함수가 단일 object에 대한 포인터를 원하는지, object의 배열을 원하는가). 또 다른 반대의 관점에서는 많은 프로그램들이 parameter를 *a로 선언하는 것이 더 정확하다고 주장하는데, 배열의 복사본이 아니라 포인터가 전달되기 때문이다. 또다른 관점으로는 함수가 포인터 연산을 사용하는가, 아니면 배열의 요소에 접근하기 위해 subscripting을 사용하는가에 따라 *a와 a[]를 바꿔가며 사용한다는 것이다(King이 사용하는 방법). 실제로는, *a가 a[]보다 더 일반적이고 그래서 여기에 익숙해지는 것이 더 좋다. 이게 도움이 될지는 모르겠지만, Dennis Ritchie의 말에 따르면 이제 "a[] 표기법은 사람들에게 혼란을 주는 역할을 하는 "살아있는 화석(a living fossil)"이다"라고 언급한다.
C언어에서 포인터와 배열은 밀접하게 관련되어있다는 것을 보았다. 이를 정확하게 말하면 배열과 포인터는 상호교환적(interchangeable)이라고 말해야되는 것이 아닌가?
아니다. array parameter가 pointer parameter와 상호교환적인 것은 사실이지만, 배열 변수는 포인터 변수와 같지 않다. 기술적으로, 배열의 이름은 포인터가 아니다. 오히려 C 컴파일러는 필요할 때만 이것을 포인터로 변환한다. 여기에 대한 차이점을 더 명확하게 알기 위해서, 우리가 sizeof 연산자를 배열 a에 적용할 때 무슨 일이 일어나는지를 생각해보아야 한다. sizeof(a)의 값은 배열 안의 모든 바이트의 개수이다. 각각의 요소의 크기에 요소의 개수가 곱해진다. 그러나 p는 포인터 변수이고, sizeof(p)는 포인터 값을 저장하는 것에 필요한 바이트의 개수이다.
"대부분의" C 컴파일러가 two-dimensional array를 one-dimensional이 작동하는 것처럼 처리한다고 책에 나왔다. 모든 컴파일러에서 이런 식으로 작동하는 것이 아닌가?
모든 컴파일러에서 이렇게 작동하는 것은 아니다. 몇몇의 현대 "bounds-checking" 컴파일러들은 포인터의 자료형 뿐만 아니라 포인터가 배열을 가리킬 때, 그리고 그 배열의 길이까지 추적한다. 예를 들어 p에 a[0][0]을 가리키는 포인터가 대입되었다고 생각해보자. 기술적으로 p는 one-dimensional array인 a[0]의 첫번째 요소를 가리킬 것이다. 만약 우리가 a의 모든 요소들을 방문하기 위한 노력으로 p를 반복적으로 증가시킨다면, p가 a[0]의 마지막 요소를 지나게 된다면 범위를 벗어나게 된다. 경계확인(bounds-checking)을 수행하는 컴파일러는 p가 오직 a[0]에 의해 가리켜진 배열의 요소들에 접근할 때만 사용되는지 확인하는 코드를 삽입할 것이다. 배열의 끝 부분에서 p를 지나 증가시키려는 시도는 에러로써 감지된다.
만약 a가 two-dimensional array라면, 왜 우린 a 자체가 아니고 a[0]을 find_larest에 전달해야 하는가? a와 a[0] 둘다 같은 장소(배열의 시작부분)를 가리키는 것이 아닌가?
a와 a[0]둘다 a[0][0]을 가리키고 있는 것은 사실이다. 문제는 a가 잘못된 자료형을 가진다는 것이다. a는 argument로써 사용되었을 때 배열을 가리키는 포인터지만, find_largest는 정수를 가리키는 포인터를 요구한다. 그러나 a[0]은 int *의 자료형을 가지는데, 그래서 find_largest에 적합한 argument이다. 자료형에 대한 우려는 좋은 것이다. 만약 C언어가 까다롭지 않다면, 우리는 컴파일러가 깨닫지 못하는 많은 종류의 끔찍한 포인터들을 만들 수 있었을 것이다.
