어떤 C 프로그램은 하나의 파일에 넣기 충분할 정도로 작지만, 대부분은 그렇지 않다. 두 개의 파일 이상으로 구성된 프로그램은 빈번하게 나타난다. 이 chpater에서는 여러개의 소스파일과 평범한 헤더파일들로 구성된 전형적인 프로그램에 대해 알아볼 것이다.
1. Source Files
지금까지, 우리는 하나의 파일로 구성된 C 프로그램만을 보았었다. 사실, 프로그램은 몇 개의 소스 파일로 나누어질 수 있다. 관습적으로, 소스파일은 .c의 확장자를 가진다. 각각의 소스파일은 프로그램의 일부를 포함하고, 주로 함수의 정의나 변수들을 포함한다. 하나의 소스파일은 반드시 main이라는 이름의 함수를 포함해야 하고, 이 main 함수는 프로그램의 시작 지점으로써의 역할을 한다.
예를 들어 연산자가 피연산자의 뒤에 잇따르는 Reverse Polish notation (RPN)의 방식으로 입력된 정수형 표현식을 계산하는 단순한 프로그램을 작성하고 싶다고 가정해보자. 사용자는 아래와 같은 표현식을 입력할 것이다.
30 5 - 7 *우리는 이것의 값을 출력하는 프로그램을 원한다(이 경우에는 175). 우리가 연산자와 피연산자를 하나씩 읽어, 스택(stack)을 사용하여 중간 결과를 추적하는 프로그램을 가지고 있다면 RPN 표현식을 계산하는 것이 쉬울 것이다. 만약 프로그램이 숫자를 읽는다면, 우리는 이 숫자를 스택에 넣는다(push). 만약 연산자를 읽는다면, 스택으로부터 두 개의 숫자를 없앤다(pop). 이 연산을 수행한 후 결과값을 다시 스택에 넣는다. 프로그램이 사용자가 입력한 input의 끝에 도달했다면, 표현식의 값은 스택에 있을 것이다. 예를 들어 프로그램이 30 5 - 7 * 표현식을 아래와 같은 방식으로 계산할 것이다.
- 30을 스택에 넣는다.
- 5를 스택에 넣는다.
- 두 개의 숫자를 스택에서 없애고, 30에서 5를 뺀 후 나온 값인 25를 다시 스택에 넣는다.
- 7을 스택에 넣는다.
- 두 개의 숫자를 스택에서 없애고, 그 두개를 곱하고 결과값을 다시 스택에 넣는다.
이러한 과정 이후에 스택은 표현식의 값인 175를 포함하고 있을 것이다.
이 전략을 프로그램으로 바꾸는 것은 어렵지 않다. 프로그램의 main 함수는 아래의 동작을 수행하는 루프를 포함할 것이다.
- "token"을 읽는다. (숫자나 연산자)
만약 token이 숫자이면, 스택에 넣는다.
만약 토큰이 연산자이면, 스택으로부터 피연산자를 없애고, 연산을 수행한 후, 연산의 결과값을 스택에 넣는다.
만약 이것과 비슷한 프로그램을 여러 개의 파일로 나눌 때에는, 관련된 함수와 변수를 같은 파일에 넣는 것이 이치에 맞다. toekn을 읽는 함수들은 token과 관련된 함수 모두와 함께 하나의 소스파일로 들어가야 한다(예를 들면 token.c). push, pop, make_empty, is_empty, is_full과 같은 스택에 관련된 함수들은 다른 파일인 stack.c에 들어가야 한다. 스택을 표현하는 변수들 또한 stack.c에 들어가야 한다. main 함수는 또다른 파일인 calc.c에 들어가야 한다.
프로그램을 여러 개의 소스파일로 나누는 것은 큰 이점을 가진다.
- 관련된 함수들과 변수들을 하나의 파일로 묶는 것은 프로그램의 구조를 명확하게 한다.
- 각각의 소스파일은 별도로 컴파일될 수 있고, 이는 프로그램이 크고 빈번하게 수정되어야 할 때 시간을 아주 많이 절약해준다.
- 함수가 별도의 소스파일로 그룹화되어 있을 때, 함수를 다른 프로그램에서 다시 사용하기 쉽다. 우리의 예제에서는
stack.c와token.c를main함수로부터 분리시켜 스택 함수들과 token 함수들을 미래에 다시 사용하기 쉽도록 만들었다.
2. Header Files
우리가 프로그램을 몇 개의 소스파일로 분리시킬 때, 문제가 발생한다. 어떻게 하나의 파일에 있는 함수가 또다른 파일의 함수를 호출하지? 어떻게 함수가 또다른 파일에 있는 외부 변수에 접근하지? 어떻게 동일한 macro 정의나 type 정의를 두 개의 파일이 공유할 수 있도록 하지?
정답은 여러 개의 소스파일들 사이에서 함수 prototype, macro 정의, type 정의 등등의 정보를 공유하게 해주는 #include directive에 있다.
#include directive는 전처리기가 명시된 파일을 열고, 현재 파일에 명시된 파일의 내용물을 삽입하도록 한다. 그래서, 우리가 몇몇의 소스파일들이 같은 정보에 접근하기를 원한다면 한 파일에 정보를 넣고 #include를 사용해 각각의 소스파일 안으로 파일의 정보를 가져와야 한다. 이러한 의도로 included 되는 파일을 헤더파일(header files)이라고 부른다(때로는 include files). 여기에 대한 세부사항은 이 chapter의 나중에 다루겠다. 관습적으로 헤더 파일은 .h의 확장자를 가진다.
C 표준에서는 "source file"이라는 단어가 프로그래머에 의해 작성된 모든 파일을 언급하는 것에 사용하는 용어이다. 이는 .c와 .h 파일을 모두 포함한다. 하지만 이 책에서 언급하는 source file은 .c 파일만을 언급한다.
The #include Directive
#include directive는 주로 두 개의 형태를 가진다. 첫번째 형태는 C언어의 라이브러리에 속해있는 헤더파일을 사용할 때 사용된다.
#include <filename>두번째 형태는 우리가 작성한 것을 포함한 모든 다른 헤더파일에 사용된다.
#include "filename"두 개의 차이는 미묘한데 어떻게 컴파일러가 헤더파일을 찾는지와 관련이 있다. 대부분의 컴파일러가 따르는 규칙을 아래에 서술하겠다.
#include <filename>: 시스템 헤더 파일이 있는 디렉토리들을 검색한다. (예를들어 UNIX system에서는/usr/include에 시스템 헤더가 보통 들어있다.)#include "filename": 현재 디렉토리를 검색하고, 그 후 시스템 헤더 파일이 있는 디렉토리들을 검색한다.
헤더파일이 검색되어야 할 장소가 보통 바뀔 수 있기 때문에, -Ipath와 같은 커맨드라인 옵션이 자주 사용된다.
직접 작성한 헤더파일을 포함시킬때는 <나 >기호(brackets)를 사용하면 안된다.
#include <myheader.h> /*** WRONG ***/전처리기가 아마도 시스템 헤더 파일이 있는 장소에서 myheader.h를 찾으려고 할 것이다(당연하게도 찾지 못한다).
#include directive 내부의 파일 이름은 디렉토리 path나 드라이브 명시자와 같은 파일의 위치를 알아내는데에 도움을 주는 정보를 포함할 수 있다.
#include "c:\cprogs\utils.h" /* Windows path */
#include "/cprogs/utils.h" /* UNIX path */#include directive 내부의 큰따옴표 표시가 문자열 리터럴처럼 보일 수 있는데, 전처리기는 이를 문자열 리터럴과 같은 방식으로 처리하지 않는다.(Windows example에서 나타나는 것처럼 \c나 \u가 문자열 리터럴 내부의 escape sequence처럼 처리될 수 있기 때문이다)
이식성(portability)를 위해서는, #include directive 안에 경로나 드라이브 정보를 포함하지 않는 것이 일반적으로 가장 좋다. 이러한 정보는 다른 machine이나 다른 operating system으로 프로그램이 이동되었을 때 프로그램 컴파일을 더 어렵게 만든다.
예를 들어 아래의 예시처럼 Windows #include directive가 명시하는 드라이브나 경로의 정보가 항상 유효하는 것은 아니다.
#include "d:utils.h"
#include "\cprogs\include\utils.h"
#include "d:\cprogs\include\utils.h"위의 예시보다, 아래의 예시를 사용하는 것이 더 좋다. 아래의 예시는 명시된 드라이브를 언급하지 않고, 경로를 절대경로가 아닌 상대경로를 사용하는 예시다.
#include "utils.h"
#include "..\include\utils.h"#include directive는 초반에 명시한 두 가지 형태보다 잘 사용되지 않는 세번째 형태를 가지기도 한다.
#include tokenstokens의 위치에는 어떠한 전처리 token의 연속이라도 들어갈 수 있다. 전처리기는 token을 스캔하고, 발견한 macro를 대체한다. macro 대체 이후에, 결과물인 directive는 반드시 #include의 다른 형태(초반에 명시한 두가지 형태)와 일치해야 한다.#include의 세번째 형태의 장점은 파일 이름이 directive 자체적으로 "hard-coded"되는 것이 아니고, macro를 통해 파일 이름을 정의할 수 있다는 점이다. 아래의 예시를 보자.
#if defined(IA32)
#define CPU_FILE "ia32.h"
#elif defined(IA64)
#define CPU_FILE "ia64.h"
#elif defined(AMD64)
#define CPU_FILE "amd64.h"
#endif
#include CPU_FILESharing Macro Definitions and Type Definitions
대부분의 큰 프로그램은 다양한 소스파일에서 공유되어야 하는 macro 정의와 type 정의를 가지고 있다. 이러한 정의들은 반드시 헤더파일로 가야한다.
예를 들어 우리가 BOOL, TRUE, FALSE의 이름을 가진 macro를 사용하는 프로그램을 작성한다고 생각해보자(당연히 C99에서는 이것들이 필요하지 않은데, <stdbool.h>에 비슷한게 있기 때문). 이것들을 필요로 하는 각각의 소스파일 내부에 이러한 macro의 정의를 반복하는 것 대신에, boolean.h와 같은 이름의 헤더파일 안에 정의들을 넣는 것이 이치에 맞다.
#define BOOL int
#define TRUE 1
#define FALSE 0이 macro를 필요로하는 어떤 소스파일이든 아래의 행을 포함해야 한다.
#include "boolean.h"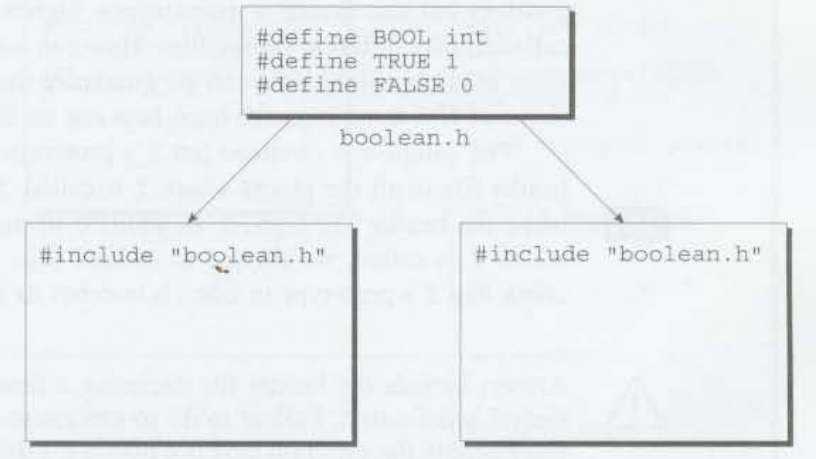
위의 그림은 두 개의 파일이 boolean.h를 포함한 것을 나타냈다.
type 정의 또한 헤더파일에서 일반적이다. 예를 들어 BOOL macro를 정의하는 것 대신에, 우리가 typedef를 통해 Bool 자료형을 만들 수 있을 것이다. 만약 우리가 그렇게 한다면, boolean.h 파일은 아래와 같은 모습을 보인다.
#define TRUE 1
#define FALSE 0
typedef int Bool;macro와 type의 정의를 헤더파일에 넣는 것은 명확한 이점이 있다. 첫번째, 우리가 이 정의를 필요로 하는 소스파일에 정의를 복사하는 것으로 인한 시간을 절약할 수 있다. 두번째, 프로그램이 더욱 수정하기 쉬워진다. macro나 type의 정의를 바꾸는 것은 단지 하다의 헤더파일에서만 이루어지면 된다. macro나 type이 정의된 많은 소스파일에 일일이 수정할 필요가 없어진다는 것이다. 세번째, 같은 macro나 type의 정의가 다르도록 소스파일에 정의하여 불일치가 일어나는 것에 대한 걱정을 하지 않아도 된다는 것이다.
Sharing Function Prototypes
또다른 파일인 foo.c에 정의된 함수 f의 호출을 포함하고 있는 소스파일이 있다고 생각해보자. f를 선언하지 않고 호출하는 것은 위험하다. 의존하는 prototype이 없기때문에, 컴파일러는 f의 return type이 int라고 생각할 것이고, f의 호출 내부의 argument의 숫자가 parameter의 개수와 일치한다고 생각할 것이다. argument들은 default argument promotions에 의해 "표준의 형태(standard form)"로 자동적으로 변환될 것이다. 이러한 컴파일러의 예상은 틀릴 수 있지만, 컴파일러가 한 번에 하나의 파일만 컴파일하기 때문에 이를 체크할 수 있는 방법이 없다. 만약 컴파일러의 예상이 틀렸다면 프로그램은 아마도 작동하지 않을 것이고, 왜 작동하지 않은지에 대한 단서를 얻을 수가 없다.(이러한 이유로, C99에서는 컴파일러가 선언이나 정의가 아직 발견하지 못한 함수를 호출하는 것을 금지한다)
다른 파일에 정의된 함수 f를 호출할 때, f의 호출 이후에 컴파일러가 prototype을 항상 찾을 수 있도록 해야한다.
우리의 첫번째 생각(impulse)은 f가 호출된 파일에서 f를 선언하는 것이다. 이는 문제를 해결하지만, 유지보수의 악몽(maintenance nightmare)을 만들어낼 수 있다. 50개의 다른 소스파일에서 f가 호출되었다고 생각해보자. 모든 파일에 있는 f의 prototype이 동일한지 어떻게 확신할 수 있겠는가? foo.c에 있는 f의 정의와 prototype들이 전부 일치한다고 어떻게 보장하는가? f가 나중에 바뀐다면, 어떻게 f가 사용된 모든 파일을 찾아낼 수 있을까?
해결책은 명확하다. f의 prototype을 헤더파일에 넣는 것이다. 그 후 f가 호출된 모든 장소에 헤더파일을 포함하는 것이다. f가 foo.c에 정의되었기 때문에, 헤더파일의 이름은 foo.h로 하자. 추가로 f가 호출된 소스파일 안에 foo.h를 포함했으면, 우리는 여기에 foo.c 또한 포함할 필요가 있는데 컴파일러가 foo.h에서 f의 prototype을 확인하고 foo.c에서 함수의 정의가 일치하는지 확인하도록 하기 위해서이다.
f의 정의를 포함하는 소스파일 안에 f를 선언하는 헤더파일을 항상 포함시켜야 한다. 이렇게 하지 않는다면 버그를 찾는 것이 어려워지는데, 프로그램 내부의 어딘가에 있는 f의 호출이 f의 정의와 일치하지 않을 수 있기 때문이다.
만약 foo.c가 다른 함수를 포함한다면, 다른 함수들도 f처럼 같은 헤더파일 안에 선언되어야 한다. 결국 foo.c 내부의 다른 함수는 아마도 f와 관계가 있을 것이다. f의 호출을 포함하고 있는 어떤 파일이든 foo.c안에 있는 다른 함수를 필요로 할 수 있다. 그러나, foo.c의 내부에서만 사용되도록 의도된 함수들은 헤더파일에 선언되어선 안된다. 이렇게 하는 것은 오해의 소지를 만든다.
헤더 파일 내부의 함수 prototype의 사용을 설명하기 위해서 Section 15.1의 RPN 계산기로 돌아가보자. stack.c 파일은 make_empty, is_empty, is_full, push, pop 함수의 정의를 포함할 것이다. 아래에 있는 이 함수들의 prototype은 stack.h 헤더파일에 들어가야 할 것이다.
void make_empty(void);
int is_empty(void);
int is_full(void);
void push(int i);
int pop(void);(예시가 복잡해지는 것을 피하려면 is_empty와 is_full은 int 값이 아닌 Boolean 값을 반환하도록 하는게 좋다.) calc.c 내부에 stack.h을 포함시켜 컴파일러가 cal.c에 나타나는 스택 함수의 호출을 확인할 수 있도록 한다. 또, stack.c에 stack.h를 포함시켜 컴파일러가 stack.c의 정의에 일치하는 prototype을 stack.h 내부에서 검증하도록 한다. 아래의 그림은 stack.h, stack.c, calc.c의 형태를 나타낸다.

Sharing Variable Declarations
외부 변수(external variables)는 함수와 같은 방식으로 많은 파일들 사이에서 공유될 수 있다. 함수를 공유하기 위해서 하나의 소스파일에 함수의 정의를 넣었고, 그 후 함수 호출이 필요한 다른 파일에 함수의 선언을 넣었다. 외부 변수를 공유하는 것도 같은 방식이다.
지금까지는 변수의 선언과 정의를 구분할 필요가 없었다. 변수 i를 선언하기 위해 아래의 구문을 작성했을 것이다.
int i; /* declares i and defines it as well */i가 int 자료형의 변수로 선언될 뿐만 아니라 동시에 컴파일러가 i를 위한 공간을 설정하면서 i가 정의된다. i를 정의하지 않고 선언하기 위해서는 우리는 반드시 extern 키워드를 선언부 앞에 넣어줘야 한다.
extern int i; /* declares i without defining it */extern은 컴파일러에게 i가 프로그램의 어딘가에 정의되어있다고 알려준다. 그래서 i에 대한 공간을 할당할 필요가 없다.
extern은 모든 자료형의 변수에 작동한다. 배열의 선언에 extern을 사용할 때, 우리는 배열의 길이를 생략할 수 있다.
extern int a[];위의 경우에는 컴파일러가 a의 공간을 할당할 필요가 없기 때문에 a의 길이를 컴파일러가 알 필요가 없다.
여러 소스파일 사이에서 변수 i가 공유되기 위해, 우리는 i의 정의를 하나의 파일에 넣어줘야 한다.
int i;i가 초기화될 필요가 있다면, initializer가 들어갈 수도 있다. 이 파일이 컴파일될 때, 컴파일러는 i에 대한 공간을 할당할 것이다. 그리고 다른 파일들은 i의 선언을 포함할 것이다.
extern int i;각각의 파일에 i를 선언하는 것으로, i를 선언한 파일에서 i에 접근하거나 수정할 수 있게된다. 하지만 extern 때문에, 파일 중 하나가 컴파일 될 때마다 추가적인 공간을 할당하지 않는다.
변수가 파일들 간에 공유될 때, 함수를 공유하는 것과 비슷한 문제에 직면하게 되는데 모든 변수의 선언이 변수의 정의와 일치하는지 확인해야 한다는 점이다.
다른 파일에서 같은 변수의 선언이 나타날 때, 컴파일러는 변수의 선언이 변수의 정의와 일치하는지 체크할 수 없다. 예를 들어, 한 파일이 아래의 정의를 가지고 있다고 생각해보자.
int i;그리고 또다른 파일이 아래의 선언을 가지고 있다고 생각해보자.
extern long i;이러한 종류의 오류는 프로그램이 예측할 수 없는 행동을 하게 한다.
불일치를 피하기 위해 공유된 변수들의 선언이 보통 헤더파일 내부에 들어간다. 특정한 변수에 접근할 필요가 있는 소스파일은 적절한 헤더파일을 포함할 수 있다. 그리고 변수 선언을 가지고 있는 각각의 헤더파일은 변수의 정의를 가지고 있는 소스파일에 포함되는데, 이를 통해 컴파일러는 선언과 정의가 일치하는지 확인할 수 있게 된다.
파일들간에 공유된 변수들이 C의 세계에서 오랫동안 존재한 관습이라도, 이는 아주 큰 단점을 가진다. Section 19.2에서 문제가 무엇이고 공유된 변수가 필요하지 않은 프로그램을 디자인하는 방법을 알아볼 것이다.
Nested Includes
헤더파일은 #include directive를 가질 수 있다. 이 행동이 조금 이상해보일 수 있는데, 실제로는 꽤 유용할 수 있다. 아래의 prototype을 가지는 stack.h 파일을 생각해보자.
int is_empty(void);
int is_full(void);이 함수들이 오직 0이나 1의 값을 가지기 때문에, int 대신에 이 Section의 처음부분에 우리가 정의한 Bool의 return type을 선언하는 것이 좋을 것이다.
Bool is_empty(void);
Bool is_full(void);당연하게도 우리는 stack.h에 boolean.h를 포함할 필요가 있는데, stack.h가 컴파일 될 때 Bool의 정의를 사용하기 때문이다. (C99에서는, boolean.h 대신 <stdbool.h>를 포함하고, Bool이 아닌 bool로 return type을 선언할 것이다.)
전통적으로, C 프로그래머들은 중첩된 include를 피한다. (C의 초기 version은 이를 모두 허용하지 않았다) 그러나 C++에서는 중첩된 include가 일반적인 관습이기 때문에, 중첩된 include에 대한 편견이 많이 사라졌다.
Protecting Header Files
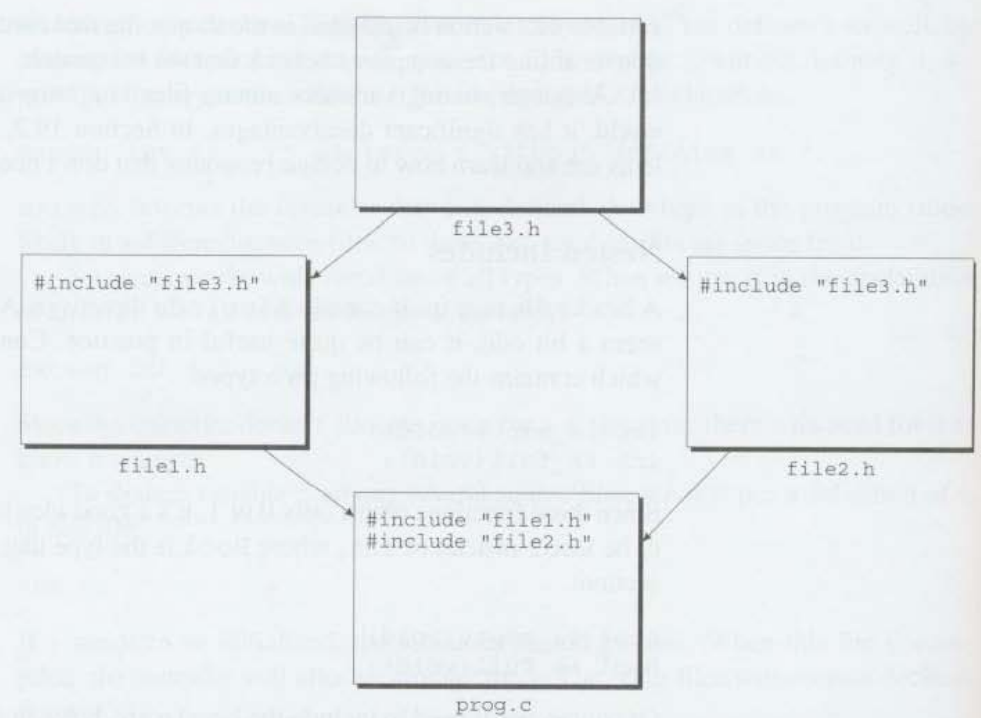
만약 소스파일이 같은 헤더파일을 두 번 포함한다면, 컴파일 에러가 발생할 수 있다. 이 문제는 헤더파일이 다른 헤더파일을 포함할 때 보통 발생한다. 예를 들어, file1.h이 file3.h를 포함하고, file2.h가 file3.h를 포함한다고 생각해보자. 그리고 prog.c가 file1.h와 file2.h를 둘다 포함한다. prog.c가 컴파일될 때, file3.h가 두 번 컴파일될 것이다.
같은 헤더파일을 두 번 포함한다고 항상 컴파일 에러가 발생하지는 않는다. 만약 파일이 오직 macro 정의, 함수 prototype, 변수 선언만 포함한다면 어떠한 어려운 문제도 발생하지 않을 것이다. 하지만 만약 파일이 type 정의를 포함한다면 컴파일 에러가 발생할 것이다.
안전성을 위해, 다중 포함(multiple inclusion)으로부터 모든 헤더파일을 보호하는 것이 좋다. 이 방법을 통해 우리는 파일을 보호하는 것을 잊어버리는 리스크없이 type 정의를 추가할 수 있다. 그리고 같은 헤더파일을 불필요하게 다시 컴파일하는 것을 피하는 것으로 프로그램 개발 시간을 절약할 수 있다.
헤더파일을 보호하기 위해, 우리는 #ifndef-#endif 쌍으로 파일의 내용물을 둘러싸주어야 한다. 예를 들어, boolean.h 파일은 아래와 같은 방법으로 보호될 수 있다.
#ifndef BOOLEAN_H
#define BOOLEAN_H
#define TRUE 1
#define FALSE 0
typedef int Bool;
#endif이 파일이 처음 포함될 때, BOOLEAN_H macro가 정의되어있지 않을 것이기에 전처리기는 #ifndef와 #endif 사이에 있는 행들을 그대로 둘 것이다. 그러나 이 파일이 두 번 포함되었다면 전처리기는 #ifndef와 #endif 사이의 행들을 제거할 것이다.
macro 이름(BOOLEAN_H)은 상관이 없지만, 헤더파일의 이름과 macro의 이름을 비슷하게 만드는 것은 다른 macro와 충돌을 막는 좋은 방법이다. BOOLEAN.h를 macro 이름으로 사용할 수 없다면(identifier가 점(.)을 가질 수 없다면), BOOLEAN_H와 같은 이름이 좋은 대안이 될 것이다.
#error Directives in Header Files
#error directive는 헤더파일이 포함되지 않아야 하는 조건을 확인하기 위해 헤더파일에 사용된다. 예를 들어 헤더파일이 원래의 C89 표준 이전에 존재하지 않았던 특징을 사용한다고 생각해보자. 오래된 비표준 컴파일러에 헤더파일이 사용되는 것을 막기 위해, 헤더파일은 __STDC__ macro의 존재를 검사하는 #ifndef를 가져야 한다.
#ifndef __STDC__
#error This header requires a Standard C compiler
#endif