이 chapter에서는 3개의 새로운 자료형을 도입할 것이다. 3개의 자료형은 구조체(structures), 공용체(unions), 열거형(enumerations)이다.
구조체는 서로 다른 자료형을 가진 값(멤버)의 모음이다.
공용체는 구조체와 비슷하지만, 멤버들이 같은 공간을 공유하다는 점에서 다르다. 결과적으로 공용체는 멤버를 동시에 저장하지 못하고, 한 번에 하나씩 밖에 저장하지 못한다.
열거형은 프로그래머에 의해 이름이 지어질 수 있는 정수형 값이다.
1. Structure Variables
지금가지 다룬 유일한 데이터 구조는 배열이다. 배열은 두가지 중요한 속성을 가진다. 첫번째, 배열의 모든 요소는 같은 자료형을 가진다. 두번째, 배열의 요소를 선택하기 위해서 위치를 명시해주어야 한다(integer subscript를 통해).
구조체(structure)의 속성은 이런 배열의 속성과는 많이 다르다. 구조체의 요소(C언어로 말하면 멤버)는 같은 타입을 가져야할 필요는 없다. 그리고 구조체의 멤버는 이름을 가지는데, 특정한 멤버를 선택하기 위해 위치를 명시하는 것이 아니고 이름을 명시한다.
구조체(structure)라는 말이 친숙하게 들릴 수도 있는데, 대부분의 프로그램 언어가 비슷한 기능을 제공하기 때문일 것이다. 어떤 언어에서는, 구조체가 record로 불리고, 멤버는 field로 불린다.
Declaring Structure Variables
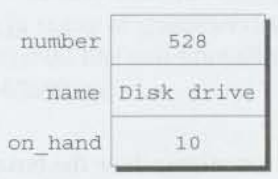
우리가 관련된 데이터 항목들의 모음을 저장할 필요가 있을 때, 구조체는 논리적인 선택이다. 예를 들어 창고 내부의 파트(part)를 추적할 필요가 있다고 생각해보자. 각각의 파트에 저장하기 위해 필요한 정보들은 파트의 넘버(정수), 파트의 이름(문자열), 보유한 파트의 개수(정수)를 포함할 수 있다. 이 3개의 모든 데이터의 항목들을 저장할 수 있는 변수를 만들기 위해, 우리는 아래와 같은 선언을 사용할 수 있다.
struct {
int number;
char name[NAME_LEN+1];
int on_hand;
} part1, part2;각각의 구조체 변수는 3개의 멤버를 가진다. number(파트 넘버), name(파트 이름), on_hand(보유량)이다. 이 선언은 C에서 다른 변수 선언들과 같은 형태를 가진다. struct { ... }은 자료형을 명시하고, part1과 part2는 그 자료형의 변수이다.
구조체의 멤버는 선언된 순서대로 메모리에 저장된다. part1 변수가 메모리에서 어떻게 보이는지 보여주기 위해 (1) part1이 주소 2000에 위치해있고, (2) 정수는 4개의 바이트를 차지하고, (3) NAME_LEN이 25의 값을 가지고, (4)멤버들간에 어떠한 틈도 없다고 가정해보자.
위의 가정들을 고려했을 때, part1은 아래와 같은 모습을 보일 것이다.

보통 구조체 내부의 세부사항을 그리는 것은 필요하지 않다. 일반적으로 더 추상적으로 보여주기 위해 일련의 박스를 사용할 것이다.

때때로는 수직이아닌 수평으로 박스를 그릴 것이다.

멤버의 값은 박스에 나중에 들어갈 것이다. 지금은 빈 상태로 놔둘 것이다.
각각의 구조체는 새로운 scope를 표현한다. scope내에 선언된 어떠한 이름이든 프로그램 내부의 다른 이름과 충돌하지 않는다. (C의 용어로는, 각각의 구조체가 멤버에 대해 분리된 name space를 가진다고 말한다.) 예를 들어, 아래의 선언은 같은 프로그램에 안에서 나타날 수 있다.
struct {
int number;
char name[NAME_LEN+1];
int on_hand;
} part1, part2;
struct {
char name[NAME_LEN+1];
int number;
char sex;
} employee1, employee2;part1과 part2의 내부 멤버인 number과 name는 employee1과 employee2의 내부 멤버인 number과 name은 충돌하지 않는다.
Initializing Structure Variables
배열과 비슷하게, 구조체 변수는 선언과 동시에 초기화될 수 있다. 구조체를 초기화하기 위해서, 우리는 구조체 내부에 저장될 값의 목록을 준비해야 하고, 이를 중괄호로 감싸야한다.
struct {
int number;
char name[NAME_LEN+1];
int on_hand;
} part1 = {528, "Disk drive", 10},
part2 = {914, "Printer cable", 5};initializer 내부의 값은 반드시 구조체의 멤버의 순서와 동일하게 나타나야 한다. 우리의 예시에서는, part1의 number 멤버가 528이 될것이고, name 멤버는 "Disk drive"가 될 것이다. 그리고 이 방식으로 더 진행될 것이다. 아래의 그림은 초기화 이후에 part1이 보이는 모습이다.
구조체 initializer는 배열의 initializer와 비슷한 규칙을 따른다. 구조체 initializer에서 사용되는 표현식은 반드시 상수여야한다. 예를 들어, part1의 on_hand 멤버를 초기화하기 위해 변수를 사용할 수 없다. (이러한 제한은 C99에서는 완화되었는데, 이는 Section 18.5에서 알아볼 것이다) initializer는 초기화하는 구조체보다 더 적은 멤버를 가질 수 있다. 배열처럼, "나머지" 멤버들은 초기 값으로 0의 값이 주어진다. 특히, 남은(leftover) 문자 배열의 바이트는 0이 될 것이고, 빈 문자열을 표현하도록 할 것이다.
Designated Initializers(C99)
C99의 designated initializer는 Section 8.1의 배열에서의 맥락에서 알아본 적이 있었는데, 이는 구조체에도 동일하게 사용된다. 이전 예시의 part1에 대한 initializer를 생각해보자.
{528, "Disk drive", 10}designated initializer도 이와 비슷한데, 각각의 값이 초기화하는 멤버의 이름으로 labeled된다는 점이 다르다.
{.number = 528, .name = "Disk drive", .on_hand = 10}점(.)과 멤버의 이름을 결합한 것을 designator라고 부른다. (배열 요소에 대한 designator는 다른 형태를 가진다)
designated initializer는 여러 장점을 가진다. 그 중 하나로 더 읽기 쉽고 일치를 확인하는게 더 쉬운데, 읽는 사람이 구조체의 멤버와 initializer 내부의 값이 대응되는 것을 명확하게 확인할 수 있기 때문이다. 또다른 장점은, initializer 내부의 값은 구조체 내부의 멤버들의 목록과 같은 순서를 취할 필요가 없다.
{.on_hand = 10, .name = "Disk drive", .number = 528}순서는 문제가 되지 않기 때문에, 프로그래머는 멤버가 원래 어떤 순서로 선언되었는지 기억할 필요가 없다. 그 이상으로, 멤버의 순서가 미래에 바뀌더라도 designated intializer는 영향을 받지 않는다.
designated initializer로 사용되지 않는 모든 값이 designator에 의해 접두사가 붙을 필요는 없다. (이는 Section 8.1에서 알아본 배열에도 속한다) 아래의 예시를 보자.
{.number = 528, "Disk drive", .on_hand = 10}"Disk drive"는 designator를 가지지 않았는데, 그래서 컴파일러는 이를 구조체 내부의 number에 이은 멤버(number다음 멤버)를 초기화한다. initializer가 초기화에 실패하면 멤버의 값이 0이된다.
Operations on Structures
가장 일반적인 배열의 연산은 위치에 의해 요소를 선택하는 subscripting이기 때문에, 구조체에 대한 가장 일반적인 연산이 멤버들 중 하나를 선택하는 것이라는 사실은 놀랍지 않다. 그러나 구조체 멤버는 위치에 의해 선택되는 것이 아닌 이름에 의해 선택된다.
구조체 내부의 멤버에 접근하기 위해서는, 구조체의 이름을 작성하고 그 후 점(.)을 쓰고, 그 후 멤버의 이름을 쓴다. 예를 들어 아래의 구문들은 part1의 멤버들의 값을 표시한다.
printf("Part number: %d\n", part1.number);
printf("Part name: %s\n", part1.name);
printf("Quantity on hand: %d\n", part1.on_hand);구조체의 멤버는 lvalue이고, 그래서 대입의 왼쪽에 나타나거나 증감 표현식의 피연산자로 사용될 수 있다.
part1.number = 258; /* changes part1's part number */
part1.on_hand++; /* increments part1's quantity on hand */구조체 멤버에 접근하기 위해 사용하는 점(.)은 실제로 C 연산자이다. 이는 후위(postfix) ++와 --연산자와 동일한 우선순위를 가지는데, 그래서 다른 모든 연산자들보다 거의 더 높은 우선순위를 가진다. 아래의 예시를 보자.
scanf("%d", &part1.on_hand);표현식 &part1.on_hand는 두 개의 연산자(&와 .)를 가진다. . 연산자는 & 연산자보다 높은 우선순위를 가지기 때문에, &는 우리가 원하는 의도대로 part1.on_hand의 주소를 계산할 것이다.
또 주로 사용되는 구조체 연산은 대입이다.
part2 = part1;이 구문의 효과는 part1.number를 part2.number에 복사하고, part1.name을 part2.name에 복사하는 것이다.
배열은 = 연산자를 사용하여 복사되지 않기 때문에, 구조체가 이러한 것이 가능한 게 놀라울 수 있다. 심지어 더 놀라운 것은 구조체 내부에 있는 배열은 구조체가 복사될 때 같이 복사된다. 어떤 프로그래머들은 이 특성을 이용해 나중에 배열을 복사할 때 사용할 "dummy" 구조체를 만들기도 한다.
struct { int a[10]; } a1, a2;
a1 = a2; /* legal, since a1 and a2 are structures */= 연산자는 오직 호환가능한(compatible) 자료형의 구조체에만 사용될 수 있다. 동시에 선언된 두 개의 구조체(part1과 part2처럼)는 호환가능하다. 다음 section에서 볼 것인데, 같은 "구조체 태그"나 같은 자료형의 이름을 사용하여 선언된 구조체 또한 호환가능하다.
2. Structure Types
이전 section에서 어떻게 구조체 변수를 선언하는지 보여주었지만, 중요한 이슈를 설명하는 것에 실패했다. 구조체의 자료형의 이름을 짓는것이다. 프로그램이 동일한 멤버를 가진 여러 구조체 변수를 선언할 필요가 있다고 생각해보자. 만약 모든 변수가 한번에 선언된다면 어떠한 문제도 없다. 그런데 만약 프로그램의 다른 지점에서 변수가 선언되어야 할 필요가 있다면, 삶(life)이 더 어려워질 것이다.
struct {
int number;
char name[NAME_LEN+1];
int on_hand;
} part1;
struct {
int number;
char name[NAME_LEN+1];
int on_hand;
} part2;전자의 선언과 후자의 선언이 다른 장소에서 작성된다면, 문제가 발생한다. 구조체의 정보를 반복하는 것은 프로그램이 더욱 부풀어오르게(bloat) 한다. 프로그램을 나중에 수정하는 것도 위험한데, 왜냐하면 선언이 일관성있게 유지될 것이라는 게 쉽게 보장되지 않기 때문이다.
그러나 이것들은 가장 큰 문제가 아니다. C의 규칙에 따르면, part1과 part2는 호환되지 않는 자료형을 가진다. 결과적으로 part1는 part2에 대입될 수 없고, 그 반대도 가능하지 않다. 또한, part1과 part2의 자료형에 대한 이름을 가지고 있지 않기 때문에, 함수 호출에서 argument로써 사용할 수도 없다.
이러한 어려움을 피하기 위해, 우리는 구조체의 자료형을 표현하는 이름을 정의할 필요가 있는데, 이는 특정한 구조체의 변수가 아니다. C는 구조체의 이름을 짓는 두 가지 방법을 제공한다. "구조체 태그"를 선언하거나 자료형의 이름을 정의하는 것에 typedef를 사용하는 것이다.
Declaring a Structure Tag
구조체 태그는 특정 종류의 구조체를 식별하는 것에 사용되는 이름이다. 아래의 예시는 part라는 이름의 구조체 태그를 선언한다.
struct part {
int number;
char name[NAME_LEN+1];
int on_hand;
};오른쪽 중괄호에 세미콜론(;)이 들어간다는 사실을 주목해라. 선언을 종료시키기 위해 반드시 존재해야 한다.
우연히 구조체 선언의 끝에 세미콜론을 생략하는 것은 놀라운 에러를 발생시킬 수 있다. 아래의 예시를 생각해보자.
struct part {
int number;
char name[NAME_LEN+1];
int on_hand;
} /*** WRONG: semicolon missing ***/
f(void)
{
...
return 0; /* error detected at this line */
}프로그래머는 함수 f(약간 조잡한 프로그래밍)의 return type을 명시하는 것에 실패했다. 함수의 앞에 있는 구조체 선언이 적절하게 종료되지 않았기 때문에, 컴파일러는 f가 struct part라는 자료형의 값을 반환하는 것으로 생각하게 된다. 이 에러는 컴파일러가 함수 내부의 첫번째 return 구문에 도달할 때 까지 감지되지 않을 것이다. 결과적으로 해석하기 어려운 에러 메시지를 발생시킨다.
part 태그를 만들었으면, 우리는 이를 변수 선언에 사용할 수 있다.
struct part part1, part2;불행하게도, 단어 struct를 생략하는 것으로 이 선언을 축약시킬 수는 없다.
part part1, part2; /*** WRONG ***/struct없이 part는 자료형의 이름이 아니다. 이는 어떠한 의미도 가지지 못한다.
구조체 태그의 앞에 struct가 없다면 인식되지 않기 때문에 프로그램 내부에 사용된 다른 이름과 충돌하지 않는다. part라는 이름의 변수가 이미 프로그램에 있더라도 이는 완벽하게 규칙에 맞다(물론 작은 혼동이 있을 수는 있지만).
구조체 태그의 선언은 구조체 변수의 선언과 결합될 수 있다.
struct part {
int number;
char name[NAME_LEN+1];
int on_hand;
} part1, part2;part라는 이름의 구조체 태그를 선언했고(나중에 part를 사용하여 더 많은 변수를 선언할 수 있다), part1과 part2라는 이름을 가진 변수들 또한 선언했다.
struct part 자료형을 가지도록 선언된 모든 구조체는 서로 다른 것들 끼리 호환가능하다(compatible).
struct part part1 = {528, "Disk drive", 10};
struct part part2;
part2 = part1; /* legal; both parts have the same type */Defining a Structure Type
구조체 태그를 선언하는 것의 대안으로, 우리는 typedef를 사용하여 진짜 자료형을 정의할 수 있다. 예를 들어 아래의 방법으로 Part라는 자료형의 이름을 정의할 수 있다.
typedef struct {
int number;
char name[NAME_LEN+1];
int on_hand;
} Part;자료형의 이름인 Part가 단어 struct 이후가 아닌 반드시 맨끝에 와야한다.
우리는 Part를 내장된 자료형과 같은 방식으로 사용할 수 있다. 예를 들어 우리는 이를 사용하여 아래와 같이 변수를 선언할 수 있다.
Part part1, part2;Part가 typedef 이름이기 때문에, struct Part처럼 작성하는 것이 허용되지 않는다. 모든 Part 변수는 어디서 선언되었든 상관 없이 호환된다.
구조체의 이름을 지을 때 우리는 구조체 태그를 선언하거나 typedef를 사용할 수 있다. 그러나 나중에 볼 것이지만, 구조체 태그를 선언하는 것은 연결 리스트(linked list)에서 구조체가 사용될 때 필수적이다. 대부분의 예제에서 typedef 이름이 아닌 구조체 태그를 사용할 것이다.
Structures as Argumnets and Return Values
함수는 argument와 반환값으로 구조체를 가질 수 있다. 두 개의 예시를 보자. 첫번째 함수에서는, part 구조체가 argument로써 주어지고 구조체의 멤버를 출력한다.
void print_part(struct part p)
{
printf("Part number: %d\n", p.number);
printf("Part name: %s\n", p.name);
printf("Quantity on hand: %d\n", p.on_hand);
}print_part는 아래처럼 호출된다.
print_part(part1);두번째 함수는 함수의 argument로 구성된 part 구조체를 반환하는 함수이다.
struct part build_part(int number, const char *name,
int on_hand)
{
struct part p;
p.number = number;
strcpy(p.name, name);
p.on_hand = on_hand;
return p;
}build_part의 parameter가 구조체 part의 멤버와 일치하는 이름을 가지는 것은 규칙에 어긋나지 않는다.구조체는 자신만의 name space를 가지기 때문이다. build_part가 어떻게 불리는지 아래에 예시가 있다.
part1 = build_part(528, "Disk drive", 10);구조체를 함수에 전달하고 함수로부터 구조체를 반환하는 것은 둘다 구조체 내부의 모든 멤버의 복사를 필요로 한다. 결과적으로, 이러한 연산은 프로그램에 꽤 많은 오버헤드(overhead)를 발생시키는데 특히, 구조체가 클 때 그렇다. 이 오버헤드를 피하기 위해, 구조체 자체를 전달하는 것보다는 구조체를 가리키는 포인터를 전달하는 것이 타당하다. 간단하게 말하면, 우리는 함수가 실제의 구조체를 반환하는 것이 아니라 포인터를 반환하도록 할 수 있다
이러한 효율성 말고도 구조체를 복사하는 것을 피해야 하는 이유가 있다. 예를 들어, <stdio.h> 헤더는 FILE이라는 이름의 자료형을 정의하는데, 이는 전형적으로 구조체이다. 각각의 FILE 구조체는 열린(open) 파일의 상태에 대한 정보를 저장한다. 그래서 반드시 프로그램 내에서 고유해야 한다. <stdio.h> 내부의 파일을 여는 모든 함수는 FILE 구조체에 대한 포인터를 반환하고, 그리고 열린 파일에 연산을 수행하는 모든 함수는 FILE 포인터를 argument로써 필요로 한다.
때때로, 함수에 paramater로써 전달되는 구조체와 일치하도록 함수 내부의 구조체 변수를 초기화하는 것을 원할 수 있다. 아래의 예시에서, part2에 대한 initializer는 f 함수에 전달되는 parameter이다.
void f(struct part part1)
{
struct part part2 = part1;
...
}C언어는 이런 종류의 initializer를 허용하는데, 우리가 초기화하는 구조체가 automatic storage duration을 가지도록 한다(함수에 지역적(local)이고, static으로 선언되지 않은). initializer는 적절한 자료형을 가진 어떠한 표현식이든 가능하고, 구조체를 반환하는 함수 호출 또한 가능하다.
Compound Literals(C99)
Secion 9.3에서 복합 리터럴(compound literal)로 알려진 C99의 특징을 도입했었다. 복합 리터럴이 이름없는 배열을 만드는 것에 사용되었고, 보통 함수에 배열을 전달하는 의도로 사용된다. 또 복합 리터럴은 변수 내부에 먼저 구조체를 저장하지 않고 "즉석으로(on the fly)" 구조체를 생성하는 것에도 사용된다. 결과로 나오는 구조체는 parameter로써 전달될 수 있고, 함수에 의해 반환될 수 있고, 변수에 대입될 수 있다. 2개의 예시를 보자.
첫번째로, 우리는 함수에 전달될 구조체를 생성하는 복합 리터럴을 사용할 것이다. 예를 들어 print_part 함수를 호출하는 것은 아래의 모습을 보인다.
print_part((struct part) {528, "Disk drive", 10});복합 리터럴은 멤버로 528, "Disk drive", 10을 순서대로 가지는 part 구조체를 생성한다. 이 구조체는 print_part에 전달되고, 출력될 것이다.
복합 리터럴이 어떻게 변수에 대입되는지 아래에 예시가 있다.
part1 = (struct part) {528, "Disk drive", 10};이 구문은 initializer를 포함한 선언과 비슷하지만, 같지는 않다. initializer는 오직 선언에서만 나타날 수 있고, 이러한 구문에서는 나타날 수 없기 때문이다.
일반적으로, 복합 리터럴은 괄호로 둘러싸인 자료형과, 이후에 중괄호로 둘러싸인 값들의 집합으로 구성된다. 구조체를 나타내는 복합 리터럴의 경우, 자료형의 이름은 단어 struct가 앞에 붙은 구조체 태그일 수 있거나, typedef 이름일 수 있다. 복합 리터럴은 designated initializer처럼 designators를 가질 수 있다.
print_part((struct part) {.on_hand = 10,
.name = "Disk drive",
.number = 528});복합 리터럴의 내부를 전부 초기화하는 시도가 실패할 수도 있는데, 이런 경우에 초기화되지 않은 멤버의 기본 값은 0이다.
3. Nested Arrays and Structures
구조체와 배열은 제한없이 결합될 수 있다. 배열은 요소로써 구조체를 가질 수 있고, 구조체는 멤버로써 배열과 구조체를 가질 수 있다. 우리는 이미 구조체 내부의 변수의 예시를 보았다.(part 구조체의 name멤버) 다른 가능성인 멤버가 구조체인 구조체와, 배열의 요소가 구조체인 배열을 보자.
Nested Structures
한 종류의 구조체를 또다른 구조체와 중첩시키는건 종종 유용하다. 예를 들어, 우리가 사람의 성, 중간 이니셜, 이름을 저장할 수 있는 아래의 구조체를 선언했다고 생각해보자.
struct person_name {
char first[FIRST_NAME_LEN+1];
char middle_initial;
char last[LAST_NAME_LEN+1];
};person_name 구조체를 더 큰 구조체의 일부로써 사용할 수 있다.
struct student {
struct person_name name;
int id, age;
char sex;
} student1, student2;students1의 성, 중간 이니셜, 이름에 접근하기 위해서는 두 개의 . 연산자의 적용을 필요로 한다.
strcpy(student1.name.first, "Fred");name을 구조체로 만드는 것의 이점 중 하나는 (first, middle_initial, last가 멤버인 student 구조체 대신) 우리가 데이터의 단위로써 이름을 쉽게 처리할 수 있다는 것이다. 예를 들어, 우리가 이름을 출력하는 함수를 작성한다면, 우리는 3개의 argument 대신 하나의 person_name 구조체 만 argument로써 전달하면 된다.
display_name(student1.name);비슷하게, person_name 구조체로부터 student의 멤버인 name으로 정보를 복사하는 것은 3번의 대입 대신 한번의 대입만으로 이루어진다.
struct person_name new_name;
...
student1.name = new_name;Arrays of Structures
가장 흔한 배열과 구조체의 결합 중 하나는 요소로 구조체를 가지는 배열이다. 이러한 종류의 배열은 간단한 데이터베이스로써의 역할을 할 수 있다. 예를 들어, 아래의 part 구조체의 배열은 100 parts에 대한 정보를 저장할 수 있다.
struct part inventory[100];배열 내부의 parts 중 하나에 접근하기 위해, 우리는 subscripting을 사용할 수 있다. 위치 i에 저장된 part를 출력하기 위해, 우리는 아래와 같이 작성할 수 있다.
print_part(inventory[i]);part 구조체 내부의 멤버에 접근하는 것은 subscripting과 멤버 선택의 결합을 필요로 한다. inventory[i]의 number 멤버에 883을 대입하기 위해 아래처럼 작성할 수 있다.
inventory[i].number = 883;part name 내부의 단일 문자에 접근하기 위해 subscripting(특정한 part를 선택하는)이후에 선택(name 멤버를 선택)하고, 그 이후 subscripting(part name 내부의 문자 선택)을 필요로 한다. inventory[i]에 저장된 name을 빈 문자열로 만들기 위해 아래처럼 작성할 수 있다.
inventory[i].name[0] = '\0';Initializing an Array of Structures
구조체의 배열을 초기화하는 것은 multidimentional 배열을 초기화하는 것과 같은 방식으로 이이루어진다. 각각 구조체는 중괄호로 둘러싸인 initializer를 가진다.
구조체의 배열을 초기화하는 한 가지 이유는, 프로그램 실행 도중에 바뀌지 않을 정보의 데이터베이스로써 처리하려고 계획하려고 할 수도 있기 때문이다. 예를 들어 국제 전화 번호를 만들 때 도시 코드에 접근해야할 필요가 있는 프로그램을 작업하고 있다고 생각해보자. 첫번째로, 우리는 도시의 코드와 함께 도시의 이름을 저장할 수 있는 구조체를 정해야 한다.
struct dialing_code {
char *country;
int code;
};문자의 배열이 아닌 country가 포인터임을 주목하자. 우리가 dialing_code 구조체를 변수로써 사용하려고 한다면 문제가 생길 수도 있지만, 그렇게 하지 않을 것이다. dialing_code 구조체를 초기화할 때, country는 문자열 리터럴을 가리킬 것이다.
다음으로, 구조체의 배열을 선언하고 세계의 유명한 국가들의 코드를 포함하도록 하기 위해 초기화할 것이다.
const struct dialing_code country_codes[] =
{{"Argentina", 54}, {"Bangladesh", 880},
{"Brazil", 55}, {"Burma (Myanmar)", 95},
{"China", 86}, {"Colombia", 57},
{"Congo, Dem. Rep. of", 243}, {"Egypt", 20},
{"Ethiopia", 251}, {"France", 33},
{"Germany", 49}, {"India", 91},
{"Indonesia", 62}, {"Iran", 98},
{"Italy", 39}, {"Japan", 81},
{"Mexico", 52}, {"Nigeria", 234},
...
{"United States", 1}, {"Vietnam", 84}};각각의 구조체 값을 감싸고 있는 중괄호는 선택이다. 그렇지만, 스타일에 대한 신념때문에 난(king) 중괄호를 생략하지 않는다.
구조체의 배열(그리고 배열을 포함한 구조체)이 많이 일반적이기 때문에, C99의 desingated initializer는 항목에 하나보다 더 많은 designator를 가지는 것을 허용한다. 단일 part를 가지는 inventory 배열을 초기화한다고 생각해보자. part 개수 숫자가 528이고, 보관량이 10이지만 이름은 아직 빈 상태로 놔둘 수 있다.
strcut part inventory[100] =
{[0].number = 528, [0].on_hand = 10, [0].name[0] = '\0'};첫번째와 두번째 항목은 두 개의 designator를 사용했다(배열의 요소가 0인 part 구조체를 선택하기 위해, 그리고 구조체 내부의 멤버를 선택하기 위해). 마지막 항목은 세 개의 designator를 사용했다. 하나는 배열의 요소를 선택하고, 하나는 그 요소 내부의 name 멤버를 선택하고, 하나는 name의 요소 0을 선택했다.
