5. Linked Lists
동적 공간 할당은 list, tree, graph 등의 연결된 데이터 구조(linked data structure)에 특히 유용하다. 이번 section에서는 연결 리스트(linked list)에 대해 알아볼 것이다.
연결 리스트는 nodes라고 불리는 구조체의 체인으로 이루어져있고, 각각의 노드는 체인 내부에서 다음 노드를 가리키는 포인터를 포함한다.

리스트 내부의 마지막 노드는 null pointer를 가지고, 그림에서는 이것을 대각선으로 표현했다.
이전 chapter들에서, 데이터 항목의 모음을 저장하기 위해서는 배열을 사용했었다. 연결 리스트는 배열을 사용하지 않는 다른 대안을 제공한다. 연결 리스트는 배열보다 더 유연한데, 연결 리스트 내부에서 쉽게 node를 삭제하고 삽입할 수 있으며, 필요할 때마다 리스트가 커지거나 줄어든다. 그렇지만, 우리는 배열의 "임의 접근(random access)"의 기능을 잃는다. 임의 접근 덕분에 배열의 어떤 요소에 접근하든지 같은 시간이 들었지만, 연결 리스트 내부의 node에 접근하는 것은 노드가 시작부분에 가까우면 빨라지고, 시작부분에서 멀어지면 느려진다.
이 section은 어떻게 C언어에서 연결 리스트를 설정하는지 알아볼 것이다. 또 연결 리스트에서 수행되는 일반적인 몇몇 연산에 대해 알아볼 것인데, 리스트의 시작부분에 node를 넣는 것과, node를 검색하는 것과, node를 삭제하는 것이다.
Declaring a Node Type
연결 리스트를 설정하기 위해서, 우리가 필요한 첫번째는 리스트 내부에서 단일 node를 나타낼 구조체이다. 단순하게, node가 data인 정수값과 리스트 내부의 다음 node를 가리킬 포인터만 가지고 있다고 생각해보자. 그러면 구조체는 아래와 같은 형태를 가질 것이다.
struct node {
int value; /* data stored in the node */
struct node *next; /* pointer to the next node */
};next 멤버는 struct node * 자료형을 가지고 있는데, 이것은 node 구조체에 대한 포인터를 저장할 수 있다는 것을 의미한다. node라는 이름에 딱히 특별한 것은 없고, 단지 일반적인 구조체 tag일 뿐이다.
node 구조체의 하나의 측면은 특별히 언급할만하다. Section 16.2에서 설명한 것처럼, 우리는 일반적으로 특정 종류의 구조체에 대한 이름을 정의하기 위해 tag나 typedef 이름을 사용한다. 그러나 node처럼 구조체가 같은 종류의 구조체를 가리키는 멤버를 가졌을 때, 우리는 구조체 tag를 사용할 필요가 있다. node 태그 없이는, 우리는 next의 자료형을 선언할 방법이 없다.
node 구조체가 선언되고 나면, 우리는 리스트의 시작이 어디인지 추적할 방법이 필요하다. 다른말로 말하면, 리스트 내부의 첫번째 node를 항상 가리킬 수 있는 변수가 필요하다. 이 변수를 first라고 하자.
struct node *first = NULL;리스트가 처음에는 비었다는 것을 알리기 위해 first를 NULL로 설정한다.
Creating a Node
연결 리스트를 만들었다면, 우리는 node를 하나씩 만들어서 리스트에 추가하길 원할 것이다. node를 만드는 과정은 3가지 과정이 필요하다.
1. node에 대한 메모리를 할당한다.
2. node에 데이터를 저장한다.
3. 리스트에 node를 삽입한다.
먼저 1, 2 단계를 보자.
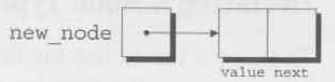
우리가 node를 만들었을 때, node를 리스트에 삽입할 때 까지 일시적으로 node를 가리킬 변수가 필요하다. 이 변수를 new_node라고 부를 것이다.
struct node *new_node;malloc을 사용하여 새로운 node에 대한 메모리를 할당하고, new_node에 반환 값을 저장할 것이다.
new_node = malloc(sizeof(struct node));new_node는 이제 node 구조체를 저장하기에 충분히 넓은 메모리의 블록을 가리킬 것이다.
자료형의 이름으로 sizeof 연산을 수행하여 할당할 때에는 포인터를 자료형으로 하지 않도록 주의를 기울여야 한다.
new_node = malloc(sizeof(new_node)); /*** WRONG ***/프로그램이 컴파일되긴하지만, malloc은 오직 node 구조체를 가리키는 포인터에 대한 충분한 메모리를 할당하기 때문이다. 나중에 new_node가 가리키고 있는 node에 데이터를 저장하려고 시도하면 충돌(crash)가 발생할 것이다.
다음으로, 우리는 새로운 node의 value 멤버에 데이터를 저장할 것이다.
(*new_node).value = 10;대입을 하고나면 아래의 그림의 모습을 보일 것이다.
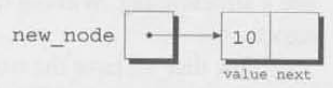
node의 value 멤버에 접근하기 위해서, 우리는 indirection operator인 *을 적용했고(new_point가 가리키는 구조체를 참조하기 위해), 그 후 selection operator인 .을 적용했다(구조체의 멤버를 선택하기 위해). *new_node 주변의 괄호는 필수적인데, 왜냐하면 . 연산자가 * 연산자보다 더 높은 우선순위를 가지기 때문이다.
The -> Operator
우리가 리스트에 새로운 node를 삽입하는 다음 단계로 넘어가기전에, 유용한 지름길(shortcut)을 사용해보자. 포인터를 사용하는 구조체의 멤버에 접근하는 것은 아주 흔하기 때문에, C언어에서는 이러한 목적으로 사용할 수 있는 특별한 연산자를 제공한다. 이 연산자는 right arrow selection으로도 알려져있는데, - 표시 이후에 >가 나타난다. -> 연산자를 사용하여 아래와 같이 작성할 수 있다.
new_node->value = 10;위의 구문은 아래의 구문 대신에 작성할 수 있다.
(*new_node).value = 10;-> 연산자는 *과 . 연산자의 조합이다. ->연산자는 new_node가 가리키는 구조체의 위치를 찾기 위해 new_node에 대해 indirection을 수행하고, 그 후 그 구조체의 멤버 value를 선택한다.
-> 연산자는 lvalue를 생성하기 때문에, 일반적인 변수가 허용되는 곳에는 이 연산자를 사용할 수 있다. new_node->value는 대입의 왼쪽 부분에 나타날 수 있다. scanf의 호출에서도 쉽게 나타날 수 있다.
scanf("%d", &new_node->value);new_node가 포인터여도 & 연산자가 여전히 필요하다는 것을 주목하자. &없이는 우리는 int 자료형을 가지는 new_node->value의 값을 scanf에 전달하게 된다.
Inserting a Node at the Beginning of a Linked List
연결 리스트의 이점 중 하나는 node가 리스트 내부의 시작부분, 끝부분, 중간부분 어디든 어떤 지점에서 추가될 수 있다는 점이다. 리스트의 시작부분이 node를 삽입하기에 가장 쉽기 때문에 이 경우에 대해 집중하여 알아볼 것이다.
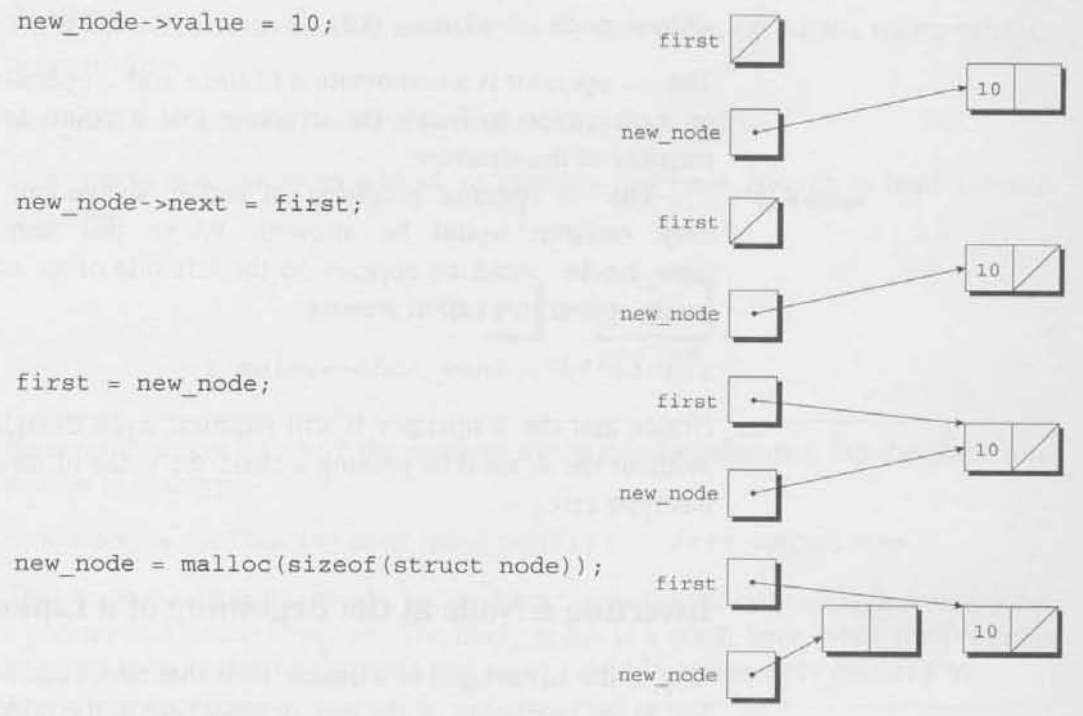
만약 new_node가 삽입된 node를 가리키고 있다면, first는 연결 리스트 내부의 첫번째 node를 가리킬 것이고, 그 후 리스트 내부로 노드를 삽입하기 위해 2개의 구문이 필요하다. 첫번째로, 새로운 node의 next 멤버가 이전에 리스트의 내부의 처음에 있던 node를 가리키도록 수정할 것이다.
new_node->next = first;두번째로, first이 새로운 node를 가리키도록 할 것이다.
first = new_node;우리가 node를 삽입할 때 리스트가 비어있다면 이 구문은 작동할까? 운좋게도 그렇다. 이게 참(true)이라는 사실을 확실하게 하기 위해, 빈 리스트에 2개의 node를 삽입하는 과정을 추적해보자. 숫자 10을 가지는 node를 먼저 삽입하고, 그 후에 20을 가지는 node를 삽입할 것이다. null pointer는 대각선으로 표현된다.

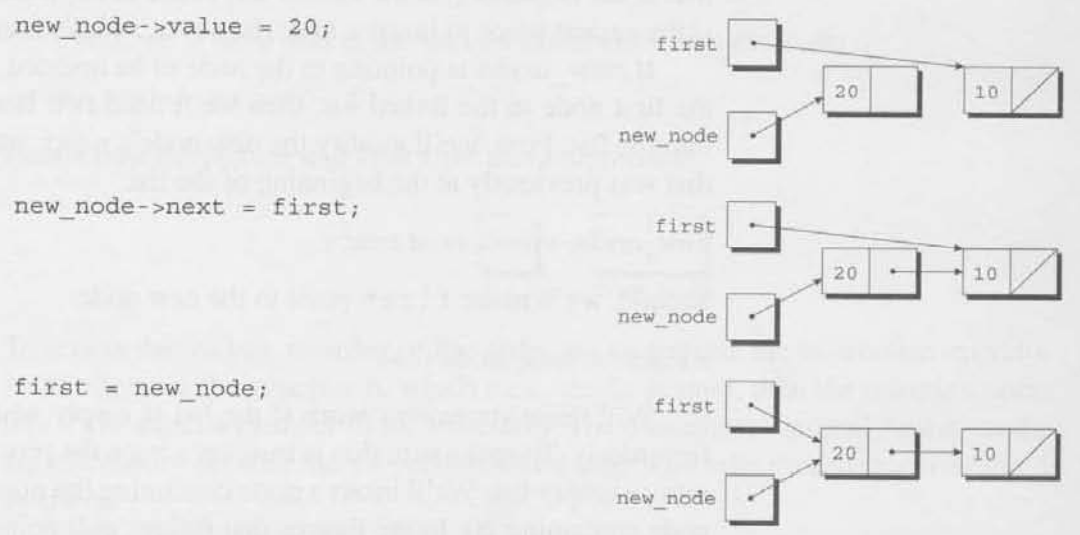
연결 리스트에 node를 삽입하는 것은 일반적인 연산이다. 함수의 이름을 add_to_list로 하자. add_to_list는 2개의 parameter를 가질 것인데, list(원래의 리스트 내부의 첫번째 node를 가리키는 포인터)와 n(새로운 node에 저장될 정수)이다.
struct node *add_to_list(struct node *list, int n)
{
struct node *new_node;
new_node = malloc(sizeof(struct node));
if (new_node == NULL)
{
printf("Error: malloc failed in add_to_list\n");
exit(EXIT_FAILURE);
}
new_node->value = n;
new_node->next = list;
return new_node;
}add_to_list는 list 포인터를 수정하지 않는다는 점에 주목하자. 대신, 새로 생성된 node를 가리키는 포인터를 반환한다(이제 이 node가 리스트의 시작이 된다). add_to_list를 호출했을 때, 우리는 반환값을 first에 저장해야 할 것이다.
first = add_to_list(first, 10);
first = add_to_list(first, 20);이 구문들은 10과 20을 가지는 node를 first에 의해 가리켜지는 리스트에 추가한다. first를 직접적으로 수정하기 위해 add_to_list를 사용하는 것은, first에 대해 새로운 값을 반환하는 것보다 더욱 까다롭다. 여기에 대해서는 Section 17.6에서 알아보겠다.
아래의 함수는 add_to_list를 사용하여 사용자에 의해 입력되는 숫자를 포함하는 연결 리스트를 만든다.
struct node *read_number(void)
{
struct node *first = NULL;
int n;
printf("Enter a series of integers (0 to terminate): ");
for (;;)
{
scanf("%d", &n);
if (n == 0)
return first;
first = add_to_list(first, n);
}
}숫자들은 리스트 내부에 거꾸로 저장될 것인데, 왜냐하면 first는 항상 입력된 마지막 숫자를 가지는 node를 가리키기 때문이다.
Searching a Linked List
연결 리스트를 만들고 나면, 특정한 데이터 조각을 검색해야할 필요가 있을 것이다. 리스트를 검색하기 위해 while 루프가 사용될 수 있지만, for 구문이 좋을때가 많다. 숫자를 세는 루프를 작성할 때 for 구문을 사용하는 것에 익숙할텐데, 여기에만 좋은 것이 아니고 for 구문의 유연성 덕분에 연결 리스트에 대한 연산을 포함하여 다른 작업에도 적합하다. 아래의 예시는 연결 리스트 내부의 node를 방문하는 관습적인 방법이다. 포인터 변수 p를 사용하여 "현재" node를 추적할 수 있도록 하였다.
idioms
for (p = first; p != NULL; p = p->next)
...p = p->next 대입은 p 포인터가 한 node에서 다음 node로 넘어갈 수 있도록 한다. 이 형태의 대입은 연결 리스트를 순회하는 루프를 작성할 때 C에서 변함없이 사용한다.
리스트(parameter list에 의해 가리켜지는)에서 정수 n을 검색하는 search_list 함수를 작성해보자. 만약 n을 찾는다면, search_list는 n을 포함한 node를 가리키는 포인터를 반환할 것이다. 그렇지 못한다면, null pointer를 반환할 것이다. 첫번째 version의 search_list는 "리스트-탐험(list-traversal)" idiom을 사용한다.
struct node *search_list(struct node *list, int n)
{
struct node *p;
for (p = list; p != NULL; p = p->next)
if (p->value == n)
return p;
return NULL;
}당연하게도, search_list를 작성하는 다른 많은 방법이 있다. 하나의 대안으로 p 변수를 제거하고, 대신 list 자체를 현재 node를 추적하는 것에 사용한다.
struct node *search_list(struct node *list, int n)
{
for (; list != NULL; list = list->next)
if (list->value ==n)
return list;
return NULL;
}list가 원래의 리스트 포인터의 복사본이기 때문에, 함수 내부에서 이 복사본을 수정하는 것은 어떠한 영향도 없다.
다른 대안은 list->value == n 검사와 list != NULL 검사를 함께 결합하는 것이다.
struct node *search_list(struct node *list, int n)
{
for (; list != NULL && list->value != n; list = list->next)
;
return list;
}만약 list의 끝에 도달했을 때 list가 NULL이기 때문에 list를 반환하는 것은 n을 찾지 못했다고 해도 올바르다. 이 version의 search_list는 while 구문을 사용한다면 조금 더 깔끔해진다.
struct node *search_list(struct node *list, int n)
{
while (list != NULL && list->value != n)
list = list->next;
return list;
}Deleting a Node from a Linked List
연결 리스트 내부에 데이터를 저장하는 것의 큰 이점은 우리가 더 이상 필요로 하지 않는 node를 쉽게 삭제할 수 있다는 것이다. node를 만드는 것과 비슷하게, node를 삭제하는 것은 3개의 단계를 필요로 한다.
1. 삭제될 node를 찾는다.
2. 삭제된 node를 "건너뛰도록(bypasses)" 이전의 node를 수정한다.
3. 삭제된 노드가 차지하던 공간을 재활용하기 위해 free를 호출한다.
단계 1은 보기보다 어렵다. 만약 삭제할 node를 가리키는 포인터에서 끝난다면, 단계 2를 수행하지 못하는데 단계 2에서는 이전의 node를 바꿔야할 필요가 있기 때문이다.
이 문제를 해결하기 위해 다양한 해결책이 존재한다. 우리는 "후행 포인터(trailing pointer)" 기법을 사용할 것이다. 단계 1에서 리스트를 검색할 때, 우리는 현재 node(cur)뿐만 아니라 이전의 node(prev)또한 가지고 있어야 한다. 만약 list가 검색할 list를 가리키고, n이 삭제되어야 할 정수라면, 아래의 루프는 단계 1을 구현한 것이다.
for (cur = list, prev = NULL;
cur != NULL && cur->value != n;
prev = cur, cur = cur->next)
;이것이 C언어에서의 for 구문의 힘이다. 이 예시에서는 for 구문의 body가 비어있고, 콤마(,)연산자가 자유롭게 사용되었고, n을 검색하기 위해 필요한 모든 행동을 수행한다. 루프가 종료되었을 때, cur는 삭제되는 node를 가리킬 것이고, prev는 이전의 node를 가리킬 것이다.
이 루프가 어떻게 작동되는지 보기 위해, list가 30, 40, 20, 10을 순서대로 포함하는 리스트를 가리킨다고 생각해보자.

n이 20이라고 가정하면, 우리의 목표는 리스트 내부의 3번째 node를 삭제하는 것이다. cur = list, prev = NULL이 실행된 이후에, cur은 리스트의 첫번째 노드를 가리킨다.
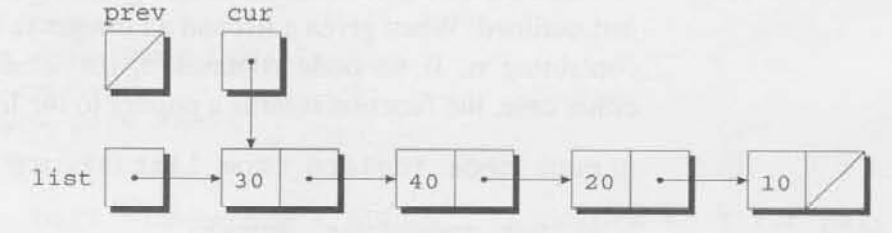
cur != NULL && cur->value != n은 참인데, cur이 node를 가리키지만 그 node가 20을 가지지 않기 때문이다. prev = cur, cur = cur->next가 실행된 이후에, prev가 어떻게 cur 뒤를 따라가는지 보자.
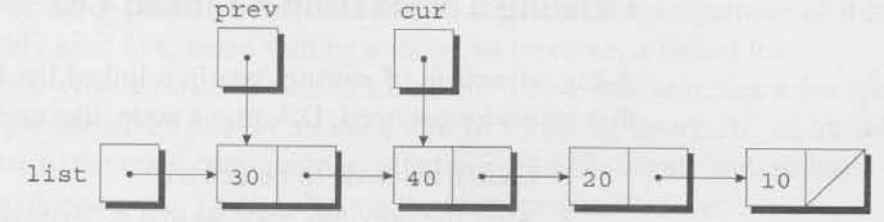
다시, cur != NULL && cur->value != n은 참이고, 그래서 prev = cur, cur = cur->next가 한 번더 실행된다.
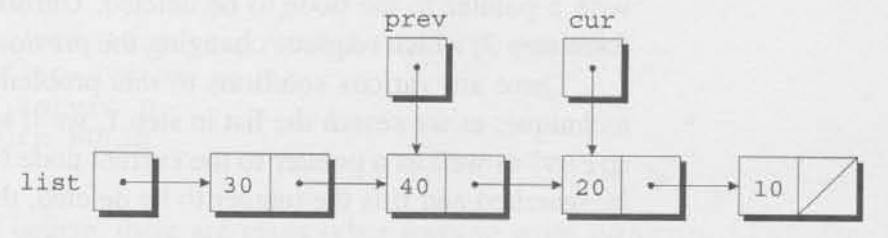
cur이 이제 20을 가진 node를 가리키기 때문에, cur->value != n은 거짓이고 루프가 종료된다.
다음으로, 우리는 단계 2에서 필요한 건너뛰기(bypass)를 수행할 것이다.
prev->next = cur->next;위의 구문은 이전의 node 내부의 포인터가 현재 노드 이후를 가리키도록 한다.
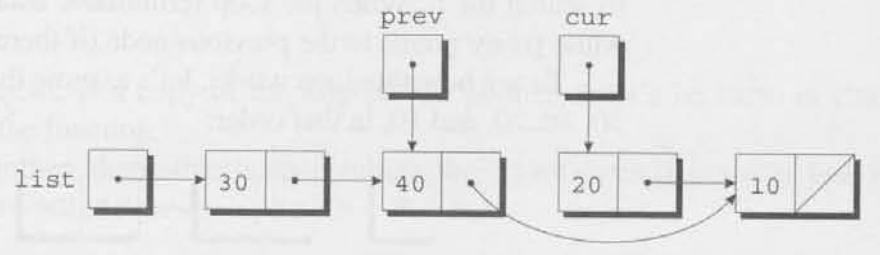
이제 단계 3에 대한 준비를 하면 되는데, 현재 노드에 의해 차지된 메모리를 해제하는 것이다.
free(cur);아래의 함수 delete_from_list는 우리가 지금까지 개략적으로 만든 전략을 사용한다. 리스트와 정수 n이 주어졌을 때, 함수는 n을 가진 첫번째 node를 제거한다. 만약 n을 가진 node가 없다면, delete_from_list는 아무것도 하지 않는다. 두 경우 모두 함수는 리스트을 가리키는 포인터를 반환한다.
struct node *delete_from_list(struct node *list, int n)
{
struct node *cur, *prev;
for (cur = list, prev = NULL;
cur != NULL && cur->value != n;
prev = cur, cur = cur->next)
;
if (cur == NULL)
return list; /* n was not found */
if (prev == NULL)
list = list->next; /* n is in the first node */
else
prev->next = cur->next; /* n is in some other node */
free(cur);
return list;
}리스트 내부의 첫번째 node를 삭제하는 것은 특별한 경우이다. prev == NULL은 이 경우에 대해 체크하고, 이는 다른 bypass 단계를 필요로 한다.
Ordered Lists
리스트의 node들이 어떠한 순서를 가질때(node 내부에 저장된 데이터에 의해 정렬된), 이를 보고 리스트가 정렬되었다(ordered)고 말한다. 정렬된 리스트에 node를 삽입하는 것은 더 어렵다(node가 항상 리스트에 시작부분에 들어가는 것이 아니기 때문). 하지만, 검색이 더 빨라진다(원하는 node가 위치한 곳에 도달하면 검색하는 것을 멈출 수 있다). 아래의 프로그램은 node의 삽입의 어려움이 늘어났지만, 검색이 빠르다.
PROGRAM : Maintaining a Parts Database(Revisited)
Section 16.3(책 참고)의 데이터베이스 프로그램을 연결 리스트로 저장된 데이터베이스를 저장하도록 해보자. 배열 대신 연결 리스트를 사용하는 것은 두개의 주요한 장점이 있다. (1) 우리는 데이터베이스의 크기를 제한하는 프리셋을 넣을 필요가 없다. parts를 저장하기 위해 필요한 메모리가 더 없을 때 까지 데이터베이스가 커질 수 있다. (2)part number에 의해 정렬된 데이터베이스를 쉽게 유지할 수 있다. 원래의 프로그램에서는 데이터베이스가 정렬되지 않았었다.
새로운 프로그램에서, part 구조체는 추가적인 멤버를 가지고(연결 리스트 내부에서 다음 node를 가리킬 포인터), 변수 inventory는 리스트 내부의 첫번째 node를 가리키는 포인터일 것이다.
struct part {
int number;
char name[NAME_LEN+1];
int on_hand;
struct part *next;
};
struct part *inventory = NULL; /* points to first part */새로운 프로그램의 대부분의 함수는 원래의 프로그램에 대응되는 함수들과 비슷할 것이다. 그렇지만 find_part와 insert 함수는 더 복잡해질 것인데, 왜냐하면 inventory 리스트 내부의 node가 part number에 의해 정렬된 상태를 유지할 것이기 때문이다.
원래의 프로그램에서는 find_part가 inventory 배열의 index를 반환했다. 새로운 프로그램에서는 find_part가 원하는 part number를 가진 node를 가리키는 포인터를 반환할 것이다. 만약 part number를 찾을 수 없다면, find_part는 null 포인터를 반환할 것이다. inventory 리스트가 part number에 의해 정렬되었기 때문에, 새로운 version의 find_part는 원하는 part number보다 크거나 같은 part number를 포함하는 node를 찾을 때 검색을 중단하는 것으로 시간을 절약할 수 있다.
find_part의 검색 루프는 아래와 같은 형태를 가질 것이다.
for (p = inventory;
p != NULL && number > p->number;
p = p->next)
;p가 NULL(part number를 찾지 못함을 나타냄)이 되었을 때 또는 number > p->number이 거짓(우리가 찾는 part number가 node에 이미 저장된 number보다 작거나 같을 때)일 때 루프가 중단된다. 후자의 경우에, 우리는 원하는 number가 실제로 리스트 내부에 있는지 알 수 없기 때문에 추가적인 검사가 필요하다.
if (p != NULL && number == p->number)
return p;insert의 원래의 version은 다음 이용가능한 배열 요소에 새로운 part를 저장했었다. 새로운 version은 반드시 리스트 내부의 어디에 새로운 part가 속할지 결정해야 하고, 거기에 삽입해야 한다. 또, part number가 이미 리스트에 존재하는지 insert가 체크하도록 해야한다. insert는 find_part 내부의 비슷한 루프를 사용하는 것으로 두 개의 작업을 수행할 수 있다.
for (cur = inventory, prev = NULL;
cur != NULL && new_node->number > cur->number;
prev = cur, cur = cur->next)
;이 루프는 2개의 포인터에 의존하는데, 현재 node를 가리키는 cur와 이전 node를 가리키는 prev이다. 일단 루프가 종료되고 나면, insert는 cur이 NULL인지 확인하고 new_node->number가 cur->number와 같은지 확인한다. 만약 그렇다면, part number는 이미 리스트에 있다는 것이다. 그렇지 않다면, node를 삭제하기 위해 사용한 전략과 비슷하게 하여 insert는 prev와 cur이 가리키는 node들 사이에 새로운 node를 삽입할 것이다(이 전략은 새로운 part number가 리스트에 있는 어떠한 node보다 클 때 작동한다. 이 경우에 cur은 NULL이 될 것이지만 prev는 리스트의 마지막 node를 가리킬 것이다).
read_line 함수는 Section 16.3(책참조)에 서술되어있다.
inventory2.c
/* Maintains a parts database (linked list version) */
#include <stdio.h>
#include <stdlib.h>
#include "readline.h"
#define NAME_LEN 25
struct part {
int number;
char name[NAME_LEN+1];
int on_hand;
struct part *next;
};
struct part *inventory = NULL; /* points to first part */
struct part *find_part(int number);
void insert(void);
void search(void);
void update(void);
void print(void);
/*********************************************************
* main: Prompts the user to enter an operation code, *
* then calls a function to perform the requested *
* action. Repeats until the user enters the *
* command 'q'. Prints an error message if the user *
* enters an illegal code. *
**********************************************************/
int main(void)
{
char code;
for (;;)
{
printf("Enter operation code: ");
scanf(" %c", &code);
while (getchar() != '\n') /* skips to end of line */
;
swtich (code)
{
case 'i': insert();
break;
case 's': search();
break;
case 'u': update();
break;
case 'p': print();
break;
case 'q': return 0;
default: printf("Illegal code\n");
}
printf("\n");
}
}
/*********************************************************
* find_part: Looks up a part number in the inventory *
* list. Returns a pointer to the node *
* containing the part number; if the part *
* number is not found, return NULL. *
**********************************************************/
struct part *find_part(int number)
{
struct part *p;
for (p = inventory;
p != NULL && number > p->number;
p = p->next)
;
if (p != NULL && number == p->number)
return p;
return NULL;
}
/*********************************************************
* insert: Prompts the user for information about a new *
* part and then inserts the part into the *
* inventory list; the list remains sorted by *
* part number. Prints an error message and *
* returns prematurely if the part already exists *
* or space could not be allocated for the part. *
**********************************************************/
void insert(void)
{
struct part *cur, *prev, *new_node;
new_node = malloc(sizeof(struct part));
if (new_node == NULL)
{
printf("Database is full; can't add more parts.\n");
return;
}
printf("Enter part number: ");
scanf("%d", &new_node->number);
for (cur = inventory, prev = NULL;
cur != NULL && new_node->number > cur->number;
prev = cur, cur = cur->next)
;
if (cur != NULL && new_node->number == cur->number)
{
printf("Part already exists.\n");
free(new_node);
return;
}
printf("Enter part name: ");
read_line(new_node->name, NAME_LEN);
printf("Enter quantity on hand: ");
scanf("%d", &new_node->on_hand);
new_node->next = cur;
if (prev == NULL)
inventory = new_node;
else
prev->next = new_node;
}
/*********************************************************
* search: Prompts the user to enter a part number, then *
* looks up the part in the database. If the part *
* exists, prints the name and quantity on hand; *
* if not, prints an error message. *
**********************************************************/
void search(void)
{
int number;
struct part *p;
printf("Enter part number: ");
scanf("%d", &number);
p = find_part(number);
if (p != NULL)
{
printf("Part name: %s\n", p->name);
printf("Quantity on hand: %d\n", p->on_hand);
}
else
printf("Part not found.\n");
}
/*********************************************************
* update: Prompts the user to enter a part number. *
* Prints an error message if the part doesn't *
* exist; otherwise, prompts the user to enter *
* change in quantity on hand and updates the *
* database. *
**********************************************************/
void updata(void)
{
int number, change;
struct part *p;
printf("Enter part number: ");
scanf("%d", &number);
p = find_part(number);
if (p != NULL)
{
printf("Enter change in quantity on hand: ");
scanf("%d", &change);
p->on_hand += change;
}
else
printf("Part not found.\n");
}
/*********************************************************
* print: Prints a listing of all parts in the database, *
* showing the part number, part name, and *
* quantity on hand. Part numbers will appear in *
* ascending order. *
**********************************************************/
void print(void)
{
struct part *p;
printf("part Number Part Name "
"Quantity on Hand\n");
for (p = inventory; p != NULL; p = p->next)
printf("%7d %-25s%11d\n", p->number, p->name,
p->on_hand);
}6. Pointers to Pointers
Section 13.7에서, 포인터를 가리키는 포인터의 개념을 보았었다. char *자료형을 요소로 가지는 배열을 사용했었는데, 이 배열의 요소를 가리키는 포인터는 char ** 자료형을 가졌었다. 또, "포인터를 가리키는 포인터"라는 개념은 연결된 데이터 구조에서 자주 나타난다.
Section 17.5의 add_to_list 함수를 생각해보자. 우리가 add_to_list를 호출했을 때,
함수에 원래 리스트 내부의 첫번째 node를 가리키는 포인터를 전달한다. 그리고 함수는 업데이트된 리스트 내부의 첫번째 노드를 가리키는 포인터를 반환한다.
struct node *add_to_list(struct node *list, int n)
{
struct node *new_node;
new_node = malloc(sizeof(struct node));
if (new_node == NULL)
{
printf("Error: malloc failed in add_to_list\n");
exit(EXIT_FAILURE);
}
new_node->value = n;
new_node->next = list;
return new_node;
}new_node에 list를 대입하는 대신에, new_node를 반환하는 함수로 수정한다고 생각해보자. add_to_list로부터 return 구문을 제거하고, 아래의 구문으로 대체할 것이다.
list = new_node;불행하게도, 이는 작동하지 않는다. 아래와 같은 방법으로 add_to_list를 호출했다고 생각해보자.
add_to_list(first, 10);함수 호출의 시점에, first는 list로 복사된다(모든 argument처럼 pointer도 값으로써 전달된다). 함수 내부의 마지막 행은 list의 값을 바꾸고, list가 새로운 node를 가리키개 한다. 하지만 이는 first에 어떠한 영향도 미치지 않는다.
add_to_list가 first를 수정하게 하는 것은 가능하지만, first에 대한 포인터를 add_to_list에 전달해야 한다. 아래의 올바른 version의 함수를 보자.
void add_to_list(struct node **list, int n)
{
struct node *new_node;
new_node = malloc(sizeof(struct node));
if (new_node == NULL)
{
printf("Error: malloc failed in add_to_list\n");
exit(EXIT_FAILURE);
}
new_node->value = n;
new_node->next = *list;
*list = new_node;
}우리가 새로운 version의 add_to_list를 호출했을 때, 첫번째 argument는 first의 주소가 되어야 한다.
add_to_list(&first, 10);7. Pointers to Functions
변수, 배열 요소, 동적할당된 메모리 블록을 포함한 다양한 데이터를 가리키는 포인터를 알아보았었다. C언어는 오직 데이터만 가리키는 포인터만 사용할 수 있는게 아니고, 함수를 가리키는 포인터를 가지는 것 또한 가능하다. 함수를 가리키는 포인터는 생각한 것만큼 이상하지 않다. 결국, 함수도 메모리를 차지하고, 그러므로 모든 함수는 변수가 주소를 가지는 것처럼 주소를 가진다.
Function Pointers as Arguments
우리가 데이터를 가리키는 포인터를 사용하는 것과 같은 방법으로 함수 포인터를 사용할 수 있다. 특히, 함수 포인터를 argument로써 전달하는 것은 C언어에서 일반적이다. 함수 f를 a와 b사이에서 수학적으로 적분하는 integrate라는 이름의 함수를 작성한다고 생각해보자. f를 argument로써 전달하는 것으로, 가능한 일반적인 integrate 함수를 만들고 싶을 수 있다. C언어에서 이것을 성취하기 위해, f가 함수를 가리키는 포인터가 되도록 선언할 것이다. double parameter를 가지고, double을 결과로 반환하는 적분 함수를 원한다고 가정해보자. 여기에 대한 prototype은 아래와 같다.
double integrate(double (*f)(double), double a, double b);*f를 둘러싼 괄호는 f가 포인터를 반환하는 함수가 아니라, f가 함수를 가리키는 포인터라는 것을 나타낸다. f가 함수인것 처럼 선언하는 것 또한 규칙에 어긋나지 않는다.
double interate(double f(double), double a, double b);컴파일러의 관점에서는, 위의 prototype이 이전의 prototype과 동일하다.
integrate를 호출할 때, 첫번째 argument로 함수 이름을 전달해야 한다. 예를 들어, 아래의 호출은 0 부터 π/2인 sin 함수를 적분할 것이다.
result = integrate(sin, 0.0, PI / 2);sin 이후에 괄호가 없다는 것을 주목하자. 함수의 이름 뒤에 괄호가 따라오지 않았을 때, C 컴파일러는 함수의 호출에 대한 코드를 생성하는 것이 아닌 함수를 가리키는 포인터를 생성한다. 이 예시에서는 sin을 호출한 것이 아니고, sin을 가리키는 포인터를 integrate에 전달한 것이다. 만약 이것이 혼란스럽다면, C언어가 배열을 어떻게 조작하는지 생각해보자. 배열의 이름이 a라면, a[i]는 배열의 하나의 요소를 나타내지만 a 자체는 배열을 가리키는 포인터로써의 역할을 한다. 비슷한 방법으로 f가 함수라면, C언어는 f(x)를 함수의 호출로써 처리할 것이지만 f 자체는 함수를 가리키는 포인터로써 처리한다.
integrate의 body 내부에서, f를 가리키는 함수를 호출할 수 있다.
y = (*f)(x);*f는 f가 가리키는 함수를 나타낸다. x는 호출에 대한 argument이다. 그래서, integrate(sin,. 0.0., PI / 2)의 실행 도중에, *f의 호출은 실질적으로는 sin의 호출이다. (*f)(x)에 대한 대안으로, C는 f가 가리키는 함수를 호출하는 것에 f(x)라고 작성하는 것을 허용한다. f(x)가 더욱 자연스럽지만, f가 함수를 가리키는 포인터라는 것을 계속 떠오르게 하기 위해 (*f)(x)를 사용할 것이다.
The qsort Function
사실, C 라이브러리의 대부분의 유용한 함수 중 어떤 것들은 argument로써 함수 포인터를 요구한다. 이것중 하나가 qsort인데, 이는 <stdlib.h> 헤더에 속해있다. qsort는 우리가 선택한 어떠한 기준에 의거하여, 어떠한 배열이든 정렬할 수 있는 능력을 가진 일반적인 정렬 함수이다.
qsort가 정렬하는 배열의 요소는 구조체, 공용체 등 어떠한 자료형이여도 가능하다. qsort는 반드시 두 개의 배열 중 어떤 것이 작다고 결정할지에 대해 알아야한다. 이 정보를 전달하기 위해 비교 함수(comparison function)를 작성해야 한다. 비교함수는 배열의 요소를 가리키는 두 개의 포인터 p와 q가 주어졌을 때, 만약 *p가 *q보다 "작다면" 음수이고, *p와 *q가 "같다면" 0이고, *p가 *q보다 "크다면" 양수를 반환하는 함수여야 한다. qsort를 사용하기 위해, *p와 *q가 어떻게 비교될 것인지에 대해 결정할 책임이 있다.
qsort는 아래의 prototype을 가진다.
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *));base는 반드시 배열의 첫번째 요소를 가리켜야 한다. (배열의 일부만 정렬할 것이라면, base가 그 일부의 첫번째 요소를 가리키도록 만들어야 한다) 가장 간단한 경우는, base가 배열의 이름인 것이다. nmemb는 정렬될 요소의 갯수이다(반드시 배열의 요소 갯수일 필요는 없다). size는 byte로 측정되는 각 배열 요소의 크기이다. compar는 비교 함수를 가리키는 포인터이다. qsort가 호출되었을 때, qsort는 오름차순으로 배열을 정렬하고 배열의 요소를 비교할 필요가 있을때마다 비교 함수를 호출한다.
Section 16.3의 inventory 배열을 정렬하기 위해 qsort를 아래와 같이 호출할 수 있다.
qsort(inventory, num_parts, sizeof(struct part), compare_parts);두번째 argument가 MAX_PARTS가 아니고 num_parts임을 주목하자. 우리는 전체의 inventory 배열을 정렬하기를 원하는 것이 아니고, 현재 저장된 parts만 정렬하기를 원한다. 마지막 argument인 compare_parts는 두 part 구조체를 비교하는 함수이다.
compare_parts 함수를 작성하는 것은 생각보다 어렵다. qsort는 비교함수의 parameter가 void *자료형을 가지는 것을 필요로 하는데, 우리는 void * 포인터를 통해 part 구조체의 멤버에 접근할 수 없기 때문이다. 대신 struct part * 자료형의 포인터가 필요하다. 이 분제를 해결하기 위해, compare_parts가 parameter인 p와 q에 struct part *의 자료형을 가진 변수를 대입하도록 하고, 원하는 자료형으로 변환되도록 해야 한다. compare_parts는 이제 p와 q가 가리키는 구조체의 멤버에 접근하기 위해 이 변수들을 사용할 수 있다. inventory 배열을 part number에 의해 오름차순으로 정렬하고 싶다면, compare_parts 함수는 아래와 같은 모습을 보여야 한다.
int compare_parts(const void *p, const void *q)
{
const struct part *p1 = p;
const struct part *q1 = q;
if (p1->number < q1->number)
return -1;
else if (p1->number == q1->number)
return 0;
else
return 1;
}p1과 q1의 선언은 const를 포함하는데, 이는 컴파일러로부터 나오는 경고를 피하기 위해서이다. p와 q가 const 포인터(p와 q가 가리키는 object가 수정되지 않도록 나타내는)이기 때문에, const로 선언된 포인터 변수에 대입되어야 한다.
이 version의 compare_parts가 작동하긴 하지만, 대부분의 C 프로그래머들은 함수를 더 간결하게 작성한다. 첫번째로, p1과 q1을 표현식 cast를 통해 대체할 수 있다.
int compare_parts(const void *p, const void *q)
{
if (((struct part *) p)->number <
((struct part *) q)->number)
return -1;
else if (((struct part *) p)->number ==
((struct part *) q)->number)
return 0;
else
return 1;
}((struct part *) p)의 괄호는 필요하다. 이 괄호가 없다면, 컴파일러는 p->number를 struct part *로 cast하려고 시도할 것이다.
if구문을 제거하는 것으로 compare_parts를 더 짧게 할 수 있다.
int compare_parts(const void *p, const void *q)
{
return ((struct part *) p)->number -
((struct part *) q)->number;
}p의 part number에서 q의 part number를 빼는 것으로, 만약 p가 더 작다면 음수, p와 q가 같다면 0, 0가 더 크다면 양수가 나오는 결과가 나오게 된다. (두 정수를 빼는 것은 잠재적으로 위험성이 있는데, overflow의 위험때문이다. part number가 양의 정수라고 가정했기 때문에 여기서는 overflow가 나타나지는 않는다)
inventory배열을 part number가 아닌 part name으로 정렬하기 위해, 우리는 아래의 version의 compare_parts를 사용할 수 있다.
int compare_parts(const void *p, const void *q)
{
return strcmp(((struct part *) p) ->name,
((struct part *) q) ->name);
}compare_parts는 하는 것은 음수, 0, 양수의 결과를 편리하게 반환해주는 strcmp를 호출하는 것이다.
Others Uses of Function Pointers
다른 함수에 대한 argument로써의 함수 포인터가 유용하지만, 항상 좋은 것은 아니다. C언어는 함수를 가리키는 포인터를 단지 데이터를 가리키는 포인터처럼 처리한다. 우리는 변수에 함수 포인터를 저장하거나, 배열의 요소나 구조체나 공용체의 멤버로써 사용할 수 있다. 심지어, 함수 포인터를 반환하는 함수를 작성할 수도 있다.
아래의 에시는 함수를 가리키는 포인터를 저장하는 변수이다.
void (*pf)(int);pf는 int parameter를 가지고, void return type을 가지는 어떠한 함수든지 가리킬 수 있다. 만약 f가 이러한 함수라면, 우리는 아래와 같은 방법으로 pf가 f를 가리키도록 할 수 있다.
pf = f;f 앞에 & 기호가 없다는 것을 주목하자. pf가 f를 가리키고 나면, 아래의 2개의 구문 중 하나를 사용하는 것으로 f를 호출할 수 있다.
(*pf)(i);
pf(i);요소가 함수 포인터인 배열은 많은 곳에 응용하여 사용할 수 있다. 예를 들어, 사용자가 선택할 수 있는 메뉴에 대한 커맨드를 출력하는 프로그램을 작성한다고 생각해보자. 이 커맨드를 구현하고 배열에 함수를 가리키는 포인터를 저장하는 함수를 작성할 수 있다.
void (*file_cmd[])(void) = {new_cmd,
open_cmd,
close_cmd,
close_all_cmd,
save_cmd,
save_as_cmd,
save_all_cmd,
print_cmd,
exit_cmd,
};사용자가 0~8의 값을 입력할 수 있는 커맨드 n을 선택한다면, 우리는 file_cmd 배열을 subscript하고 대응되는 함수를 호출할 수 있다.
(*file_cmd[n])(); /* or file_cmd[n](); */당연하게도, switch 구문을 통해 비슷한 효과를 얻을 수 있다. 그러나 함수 포인터의 배열을 사용하는 것은 더 유연함을 제공하는데, 배열의 요소들은 프로그램이 실행중일 때 변경될 수 있기 때문이다.
8. Restricted Pointers (C99)
C99에서는, 키워드 restrict가 포인터의 선언에서 나타날 수 있다.
int * restrict p;restrict를 사용하여 선언된 포인터는 restricted pointer라고 부른다. 이 의도는, 만약 p가 마지막으로 수정된 object를 가리킨다면, p를 통해 접근하는 것이 아닌 다른 방법으로는 접근할 수 없다는 의미이다. object에 대해 2개 이상의 접근 방식을 가지면 aliasing이라고도 부른다.
restricted pointer가 막아야할 행동을 알아보자. p와 q가 아래처럼 선언되었다고 생각해보자.
int * restrict p;
int * restrict q;p가 동적으로 할당된 메모리 블록을 가리키도록 하자.
p = malloc(sizeof(int));(만약 p에 변수의 주소나 배열 요소의 주소가 대입되었다면 비슷한 상황이 나타날 것이다.) 일반적으로, p를 q에 복사하고 q를 통해 정수를 수정하는 것은 규칙에 어긋나지 않는다.
q = p;
*q = 0; /* causes undefined behavior */그러나 p 가 restricted pointer이기 때문에, *q = 0 구문을 실행하는 것은 undefined이다. p와 q가 같은 object를 가리키도록 하는 것은, *p와 *q가 alias되도록 한다.
만약 restricted pointer p가 extern storage class 없이 지역 변수로 선언되었다면, restrict는 p가 선언된 블록이 실행 중일 때에만 p에 적용된다.(함수의 body는 블록임에 주목하자) restrict는 함수가 실행중일 때에만 포인터 자료형의 함수 parameter에 사용될 수 있다. 그러나 restrict가 file scope의 포인터 변수에 적용될 때, 프로그램의 전체 실행동안 restriction이 지속된다.
세부사항에 대한 C99 표준을 보면 restrict을 사용하는 것에 대한 실질적인 규칙은 다소 복잡하다. restricted pointer로부터 만들어진 alias가 생성되는 상황도 있다. 예를 들어, restricted pointer 변수 p가 규칙에 어긋나지 않게 또다른 restricted pointer 변수 q로 복사될 수 있는데, 이는 p가 함수에 지역적(local)이고, q가 함수 body내부에서 중첩된 블록 내부에서 정의되었을 때이다.
restrict의 사용을 설명하기 위해, <string.h> 헤더에 속해있는 memcpy와 memmove 함수를 알아보자. memcpy는 C99에서 아래의 prototype을 가진다.
void *memcpy(void * restrict s1, const void * restrict s2,
size_t n);memcpy는 strcpy와 비슷한데, 하나의 object로부터 또다른 object로 byte를 복사한다는 점이 다르다(strcpy는 한 문자열에서 다른 문자열로 문자를 복사한다). s2는 복사될 데이터를 가리키고, s1은 복사의 목적지를 가리키고, n은 복사될 byte수를 나타낸다. s1과 s2에 restrict를 사용하는 것은 복사되는 것과 복사의 목적지가 겹치지(overlap) 않아야한다는 것을 나타낸다(그렇지만 이것들이 겹치지 않는다는 보장은 하지 않는다).
반대로 restrict는 memmove에 대한 prototype에서 나타나지는 않는다.
void *memmove(void *s1, const void *s2, size_t n);memmove는 memcpy와 같은 것을 한다. 한 장소에서 다른 장소로 byte를 복사한다. 차이점은 memmove가 복사되는 것과 복사의 목적지가 겹치더라도 작동한다는 것을 보장한다는 점이다. 예를 들어, 우리는 memmove를 통해 배열의 요소를 다른 위치로 전환시킬 수 있다.
int a[100];
...
memmove(&a[0], &a[1], 99 * sizeof(int));C99 이전에는, memcpy와 memmove 사이에 차이점을 설명할 방법이 없었다. 두 개의 함수에 대한 prototype이 거의 동일했기 때문이다.
void *memcpy(void *s1, const void *s2, size_t n);
void *memmove(void *s1, const void *s2, size_t n);C99 version의 memcpy의 prototype에서의 restrict의 사용은 프로그래머에게 s1과 s2가 가리키는 object가 겹치지 않아야한다는 것을 알게 한다. 만약 겹친다면 함수가 작동하는 것을 보장할 수 없다는 것을 알린다.
함수 prototype에서 restrict를 사용하는 것은 설명에 유용하지만, 이것은 restrict의 존재의 주요한 이유는 아니다. restrict는 컴파일러가 최적화(optimization)라고 알려진 더 효율적인 코드를 생성하는 것을 가능하도록 하는 정보를 제공한다. (register storage class도 동일한 의도이다) 그렇지만 모든 컴파일러가 최적화를 시도하는 것이 아니고, 프로그래머가 최적화 기능을 비활성화할 수 있는 컴파일러도 있다. 결과적으로, C99 표준은 restrict가 표준에 준수하는 프로그램의 행동에 영향을 미치지 않는다는 것을 보장한다. 이러한 프로그램으로부터 restrict의 모든 사용을 제거한다고 해도, 프로그램이 동일하게 작동해야 한다.
대부분의 프로그래머들은 가능한 최고의 성능을 달성하기 위한 프로그램을 미세 조정(fine-tuning)하는 것이 아니라면, restrict를 사용하지 않는다. 그래도 restrict에 대해 알만한 가치가 있는데, 왜냐하면 많은 C99 표준 라이브러리의 함수에서 나타나기 때문이다.
9. Flexible Array Members(C99)
가끔, 우리는 알 수 없는 크기의 배열을 가지는 구조체를 정의해야할 필요가 있다. 예를 들어, 평범한 형태의 문자열의 형태가 아닌 문자열을 저장하는 것을 원할 수도 있다. 일반적으로 문자열은 문자의 배열이고, 마지막에 null 문자가 있다. 그렇지만 다른 방법으로 문자열을 저장하는 것의 이점이 있다. 문자열의 문자들과 함께 문자열의 길이를 저장하는 것이다(null 문자 없이). 길이와 문자들은 아래의 구조체에 저장될 수 있다.
struct vstring {
int len;
char chars[N];
};N은 문자열의 최대 길이를 나타내는 macro이다. 그러나 고정된 길이의 배열은 바람직하지 않는데, 문자열의 길이를 강제하고 메모리를 낭비시키기 때문이다(대부분의 문자열이 N개의 문자가 필요하지 않다).
C 프로그래머들은 전통적으로 이 문제를 chars의 길이가 1(dummy value)이 되도록 선언하고 동적으로 각각의 문자열을 할당하는 것으로 해결했다.
struct vstring {
int len;
char chars[1];
};
...
struct vstring *str = malloc(sizeof(struct vstring) + n - 1);
str->len = n;구조체가 선언된 것보다 더 많은 메모리를 가지도록 할당하고(이 경우에는 n - 1 문자), chars 배열의 추가적인 요소를 저장하기 위해 메모리를 사용하는 것으로 "cheating"을 했다. 이 기법은 몇년동안 일반적이었고, "struct hack"이라는 이름을 가졌다.
struct hack은 문자 배열에만 한정된 것이 아니다. 다양한 사용이 가능하다. 시간이 지나면서, 많은 컴파일러에서 지원될 정도로 충분히 유명해졌다. GCC를 포함한 몇몇 컴파일러는 심지어 chars가 0의 길이를 가지도록 하여 더 명시적으로 이 트릭을 사용하도록 허용했다. 불행하게도, C89 표준에서는 struct hack이 작동하는 것을 보장하지 않았을 뿐더러 0의 길이를 가지는 배열(zero-length array) 또한 허용하지 않았다.
struct hack이 유용하다는 것을 인지하고 나서 C99는 struct hack과 동일한 효과를 내는 flexible array member라고 알려진 기능을 가지게 되었다. 구조체의 마지막 멤버가 배열이라면, 배열의 길이가 생략될 수 있다.
struct vstring {
int len;
char chars[]; /* flexible array member - C99 only */
};chars의 길이는 vstring 구조체에 메모리가 할당될 때까지 결정되지 않기때문에 일반적으로 malloc의 호출을 사용한다.
struct vstring *str = malloc(sizeof(struct vstring) + n);
str->len = n;이 예시에서, str은 n 문자만큼 차지하는 chars 배열을 내부에 가진 vstring 구조체를 가리킨다. sizeof 연산자는 구조체의 크기를 계산할 때 chars 멤버를 무시한다. (flexible array member은 구조체 내부에서 어떠한 공간도 차지하지 않기 때문에 일반적이지 않다.)
flexible array 멤버를 가진 구조체에 적용되는 몇 가지 특별한 규칙이 있다. flexible array 멤버는 반드시 구조체의 마지막에 나타나야 하고, 구조체는 최소 하나의 다른 멤버를 가져야 한다. flexible array 멤버를 가지는 구조체를 복사하는 것은 다른 멤버는 복사하지만 flexible array 자체는 복사하지 않는다.
flexible array 멤버를 가지는 구조체는 incomplete type이다. incomplete type은 메모리가 얼마나 필요한지 결정할 필요가 있는 정보가 없다. Section 19.3의 Q&A에서 더 논의할 incomplete type은 다양한 제한의 영향을 받는다. 특히, incomplete type(flexible array 멤버를 가지는 구조체)은 또다른 구조체의 멤버나 배열의 요소가 되지 못한다. 그러나 배열은 flexible array 멤버를 가지는 구조체를 가리키는 포인터를 가질 수 있다.
Others
NULL macro는 무엇을 나타내는가?
NULL은 실질적으로 0을 나타낸다. 포인터에 0을 사용한다면, C 컴파일러는 정수 0이 아닌 null 포인터로써 처리할 것이다. NULl macro는 혼란을 피하는 것에 도움을 준다.
아래 대입은 숫자형 변수에 0을 대입하거나 포인터 변수를 null 포인터가 되도록 할 것이다. 이는 p가 포인터인지 숫자형 변수인지 바로 구분되지 않는다.
p = 0;하지만 아래의 대입은 p가 포인터라는 것을 명확하게 해준다.
p = NULL;나의 컴파일러와 함께 제공되는 헤더파일에는 NULL이 아래와 같이 정의되어 있다. 0을 void *로 cast하는 것의 이점이 무엇인가?
#define NULL (void *) 0이는 C표준에 의해 허용되는 트릭인데, 이 트릭은 컴파일러가 null 포인터의 잘못된 사용을 찾도록 만들어준다. 예를 들어, 우리가 NULL을 정수형 변수에 대입한다고 생각해보자.
i = NULL;NULL이 0으로 정의되었다면, 이 대입은 완벽하게 규칙에 어긋나지 않는다. 하지만 만약 NULL이 (void*) 0으로 정의되었다면, 컴파일러는 포인터를 정수형 변수에 대입했다는 경고를 할 수 있다.
NULL을 (void*) 0으로 정의하는 것은 더 중요한 두번째 이점이 있다. 가변 길이 인자(variable-length argument) 리스트와 그 argument들 중 하나로 NULL이 전달되어 호출되는 함수를 생각해보자. 만약 NULL이 0으로 정의되어 있다면, 컴파일러는 잘못된 0의 정수 값을 전달할 것이다. (일반적인 함수 호출에서, NULL은 잘 작동하는데 왜냐하면 컴파일러는 포인터를 예상하는 함수 prototype을 알고 있기 때문이다. 그렇지만 함수가 가변 길이 인자 리스트를 가진다면, 컴파일러는 여기에 대한 정보를 알지 못한다.) 만약 NULL이 (void *) 0으로 정의되었다면, 컴파일러는 null 포인터를 전달할 것이다.
더 혼란스럽게 하는 것은, 어떤 헤더파일은 NULL을 0L(0의 long version)으로 정의한다는 것이다. NULL을 0으로 정의하는 것과 비슷한 이 정의는, 포인터와 정수가 호환 가능했던 C언어의 초창기때 있었던 것이다. 그러나 대부분의 목적은 단순히 null 포인터에 대한 이름이라고 생각하는 것이기 때문에 어떻게 NULL이 정의되어있는지는 문제가 되지 않았다.
0이 null 포인터를 나타내는 것에 사용되기 때문에, null 포인터는 모두 0비트로 된 주소라고 생각하는데 이 생각은 맞는것인가?
반드시 그렇지는 않다. 다른 방법으로 null 포인터를 나타내는 것이 허용된 컴파일러와 모든 컴파일러가 0의 주소를 사용하는 것은 아니다. 예를 들어, 어떤 컴파일러는 null 포인터에 대해 존제하지 않는 메모리 주소를 사용한다. 이 방법으로, null 포인터를 통해 메모리에 접근하는 시도는 하드웨어에 의해 감지될 수 있다.
null 포인터가 컴퓨터에 어떻게 저장되는지는 우리와 관련이 없어야 한다. 이는 컴파일러 전문가(expert)들이 걱정해야할 세부사항이다. 중요한 것은, 포인터의 맥락에서 사용되었을 때 0은 컴파일러에 의해 적절한 내형(internal form)을 가져야 한다는 것이다.
null 문자로써 NULL을 사용하는 것은 가능한가?
확실하게 아니다. NULL은 null 포인터를 나타내는 macro이지, null 문자를 나타내는 macro가 아니다. null문자로써 NULL을 사용하는 것은 어떤 컴파일러에서 작동할 수는 있지만 모든 컴파일러에서 작동하는 것은 아니다(NULL이 (void*)0으로 정의되었기 때문에). 포인터가 아닌 다른것으로 NULL을 사용하는 것은 아주 큰 혼란을 야기할 수 있다. 만약 null 문자에 대한 이름을 원한다면, 아래의 macro를 정의하는 것이 좋다.
#define NUL '\0'내 프로그램이 종료되었을 때, "Null pointer assignment."라는 메시지가 나왔다. 이것은 무엇을 의미하는가?
이 메시지는 오래된 DOS 기반의 C 컴파일러에서 프로그램이 컴파일될 때 생성된다. 이 메시지는 프로그램이 잘못된 포인터(반드시 null 포인터는 아니다)를 사용한 메모리에 데이터가 저장되어있음을 나타낸다. 불행하게도, 이 메시지는 프로그램이 종료될 때까지 출력되지 않으며 어떤 구문에서 에러가 발생하는지 알아낼 단서가 없다. "Null pointer assignment" 메시지는 scanf에 &을 빠뜨렸을 때 발생하기도 한다.
scanf("%d", i); /* should have been scanf("%d", &i); */또다른 가능성은 대입이 초기화되지 않았거나 null인 포인터를 수반했을 때이다.
*p = i; /* p is uninitialized or null */어떻게 프로그램이 "null pointer assignment"가 발생했는지 아는것인가?
주소가 0으로 시작하는 단일 세그먼트(single segment)에 데이터가 저장되는 소형, 중형 메모리 모델에서 메시지가 발생한다. 컴파일러가 데이터 세그먼트의 시작부분에 "구멍(hole)"을 남긴다. 이 구멍은 0으로 초기화되는 메모리의 작은 블록인데, 프로그램에 의해 사용되지 않는다. 프로그램이 종료될 때, "구멍" 영역에 있는 데이터 중 0이 아닌 데이터가 있는지 확인한다. 만일 그렇다면, 이것은 반드시 bad 포인터를 통해 수정된 것이다.
malloc이나 다른 메모리 할당 함수의 반환값을 cast하는 것의 이점이 있는가?
보통은 없다. 이 함수들이 반환하는 포인터를 void* 포인터로 cast하는 것은 불필요하다. 왜냐하면 void* 자료형의 pointer는 자동적으로 대입하는 다른 포인터 자료형으로 변환되기 때문이다. 반환값을 cast하는 습관은 C의 오래된 version에서 있었던 것인데, 메모리 할당 함수들이 char* 값을 반환하여 반드시 cast가 필요했을 때이다. C++코드로써 컴파일되도록 설계된 프로그램은 이 cast로부터 이점이 있지만, cast의 이유는 오직 이것때문이다.
C89에서는, cast를 수행하지 않는 것으로 얻는 실질적인 작은 이점이 있다. 프로그램에서 <stdlib.h>를 포함하는 것을 잊어버렸다고 생각해보자. 우리가 malloc을 호출했을 때, 컴파일러는 자료형이 int(모든 C 함수의 기본 반환값)라고 생각한다. 만약 malloc의 반환값이 cast되지 않았다면, C89 컴파일러는 에러를 발생시킨다(아니면 최소한 오류라도). 왜냐하면 포인터 변수에 정수형 값을 대입했기 때문이다. 반대로, 우리가 포인터에 대한 반환값을 cast했다면 프로그램이 컴파일될 수는 있지만 적절하게 작동하지 않을 것이다. <stdlib.h> 헤더를 포함하는 것을 잊어버렸다면 malloc이 호출되었을 때 에러를 발생시킬 것인데, 왜냐하면 C99는 함수가 호출되기 전에 선언되는 것을 요구하기 때문이다.
calloc 함수는 메모리 블록의 bits를 0으로 초기화한다. 이는 블록 내부의 모든 데이터 항목이 0이 된다는 것을 의미하는 것인가?
보통은 그렇지만 항상 그런것은 아니다. 정수를 0bits로 설정하는 것은 항상 정수 0을 만들어낸다. 부동소수점 숫자를 0 bits로 설정하는 것은 보통 숫자 0을 만들지만, 이것이 보장된 것은 아니다. 부동소수점 숫자가 어떻게 저장되느냐에 따라 다르다. 이것은 포인터에도 마찬가지이다. bits가 0인 포인터가 반드시 null 포인터는 아니다.
구조체 태그 메커니즘이 어떻게 구조체가 자기자신을 가리키는 포인터를 가지도록 허용하는지 보았다. 그런데 두 개의 구조체가 각각의 멤버로 서로 다른 구조체를 가리키는 포인터를 가졌으면 어떻게 되는가?
아래에 어떻게 우리가 이 상황을 조작하는지 예시가 있다.
struct s1; /* incomplete declaration of s1 */
struct s2{
...
struct s1 *p;
...
};
struct s1 {
...
struct s2 *q;
...
};s1의 첫번째 정의는 완성되지 않은(incomplete) 구조체 자료형을 생성한다. 왜냐하면 s1의 멤버를 명시하지 않았기 때문이다. s1의 두번째 정의는 구조체의 멤버를 설명하는 것으로 자료형을 "완성"하였다. 구조체 자료형의 완성되지 않은 선언은 C에서 허용되는데, 이 사용은 제한적이다. 이러한 자료형(p를 선언할 때 한것처럼)을 가리키는 포인터를 생성하는 것도 이러한 사용 중 하나이다.
malloc을 잘못된 argument로 호출하는 것(더 적거나 더 많은 메모리를 할당하는 것)은 일반적인 오류인것 같다. malloc을 안전하게 사용하는 방법이 있는가?
있다. 어떤 프로그래머들은 단일 object에 대한 메모리를 할당하기 위해 malloc을 사용할 때 아래의 관용구(idiom)을 사용한다.
p = malloc(sizeof(*p));sizeof(*p)는 p가 가리키는 object의 크기이기 때문에, 이 구문은 할당되어야 할 메모리의 총량이 올바르다는 것을 보장해준다. 딱 보기에는 이 관용구는 수상해보인다. p가 초기화되지 않았고, 이 때문에 *p의 값이 undefined인 것같기 때문이다. 그렇지만 sizefo는 *p를 계산하지 않고, 단순히 크기만을 계산하기 때문에 이 관용구는 만약 p가 초기화되지 않았거나 null 포인터를 가졌어도 작동한다.
n개의 요소를 가진 배열에 대한 메모리를 할당하기 위해, 우리는 이 관용구를 조금 수정한 version을 사용할 수 있다.
p = malloc(n * sizeof(*p));왜 qsort의 이름을 qsort라고 했는가? sort를 쓰면 더 간단한게 아닌가?
qsort는 Quicksort 알고리즘으로부터 온 이름이다(Section 9.6). 모순적이게도, C 표준에서는 qsort가 Quicksort 알고리즘을 사용하지 않아도 되고, 많은 version의 qsort가 Quicksort를 사용하지 않는다.
아래의 예시처럼 qsort의 첫번째 argument가 void * 자료형이 되도록 cast하는 것은 필수적인가?
qsort((void *) inventory, num_parts, sizeof(struct part),
compare_parts);필수적이지 않다. 어떤 자료형의 포인터든지 상관없이 자동적으로 void *로 변환될 것이다.
qsort가 정수의 배열을 정렬하도록 하고 싶다. 그런데 비교 함수를 작성하는 것에서 문제가 생겼다. 어떻게 해야하는가?(what's the secret?)
아래의 예시는 작동하는 비교함수이다.
int compare_ints(const void *p, const void *q)
{
return *(int *)p - *(int *)q;
}기괴하지 않은가? (int *)p는 p를 int * 자료형으로 cast하고, 그래서 *(int *)p는 p가 가리키는 정수이다. 그러나 두 정수를 빼는 것은 overflow를 야기할 수 있다. 만약 정수가 완벽하게 임의로(arbitrary) 정렬된다면, *(int *)p와 *(int *)q를 비교하는 것에 if구문을 사용하는 것이 더 안전하다.
문자열의 배열을 정렬하고 싶다. 그래서 비교함수로써 strcmp를 사용했다. 그런데 이 비교함수를 qsort에 전달했을 때, 컴파일러가 경고 메시지를 발생시켰다. 나는 이 문제를 해결하기 위해 비교 함수에 strcmp를 넣었다. 그 후 프로그램을 컴파일했는데 qsort가 배열을 정렬하는 것처럼 보이지 않는다. 내가 무엇을 잘못한걸까?
첫번째로 ,qsort 에 strcmp자체를 전달할 수 없는데, 왜냐하면 qsort는 두 개의 const void * parameter를 가지는 비교함수를 요구하기 때문이다. compare_strings 함수는 제대로 작동하지 않는데 왜냐하면 p와 q가 문자열(char*포인터)이라고 잘못 가정하기 때문이다. 사실, p와 q는 char * 포인터를 가진 배열 요소를 가리킨다. compare_string을 고치기 위해서는,p와 q를 char **자료형으로 cast하고 * 연산자를 통해 한 수준의 indirection을 제거하면 된다.
int compare_string(const void *p, const void *q)
{
return strcmp(*(char **)p, *(char **)q);
}