지금까지의 변수는 단일 data item을 가지는 scalar였다. C는 aggregate 변수도 제공하는데, aggregate 변수는 값의 집합을 저장할 수 있다. C에는 두 가지 종류의 aggregate가 있는데, 배열(array)와 구조체(structure)이다.
1. One-Dimensional Arrays
배열은 많은 값을 포함하고 있는 데이터 구조인데, 이 값들은 모두 같은 자료형을 가진다. 요소(element)라고도 알려진 이 값들은 배열 안에서 위치를 가지고, 선택될 수 있다.
가장 간단한 배열의 종류는 one dimension을 가지는 것이다. one-dimensional 배열의 요소들은 개념적으로 한 행(또는 열)으로 차례로 나열된 것이다. 아래는 one-dimensional 배열인 a를 시각화한 것이다.

배열을 선언하기 위해선 먼저 배열의 요소들의 자료형과 요소의 갯수를 명시해주어야 한다. 예를 들어 a 배열이 10개의 int형 요소를 가진다고 하면 아래와 같이 쓸 수 있다.
int a[10];배열의 요소들의 자료형은 어떤 자료형이나 될 수 있고, 배열의 길이는 어떠한 정수형 상수 표현식으로 명시될 수 있다. 나중에 프로그램이 바뀌었을 때 배열의 길이를 수정해야 할 필요가 있을 수 있기 때문에, 배열의 길이를 macro로 정의하는 것은 아주 좋은 습관이다.
#define N 10
...
int a[N];Array Subscripting
배열의 특정한 요소에 접근하기 위해서는, 우리는 대괄호(sqaure brackets)에 들어있는 정수형 값을 따르는 배열의 이름을 써야 한다(이는 배열을subscripting 또는 indexing한다고 표현하기도 함). 배열 요소들은 항상 0부터 번호가 매겨지고, 그렇기에 배열의 요소들의 길이가 n이면 0부터 n-1까지 번호가 매겨진다. 예를 들어 a가 10개의 요소를 가진 배열이라면, 이 요소들은 a[0], a[1],..., a[9]처럼 지정될 수 있다.

a[i] 형태의 표현식은 lvalue이고, 그래서 일반적인 변수들과 같은 방식으로 사용될 수 있다.
a[0] = 1;
printf("%d\n", a[5]);
++a[i];일반적으로 만약 배열이 자료형 T의 요소를 포함하고 있다면, 배열의 각각의 요소는 자료형 T의 변수인 것처럼 다루어진다.
배열과 for 루프는 서로 관계가 깊다. 많은 프로그램이 배열의 모든 요소에 어떠한 작동을 수행하는 for 루프를 포함하고 있다. 길이가 N인 배열 a의 전형적인 작동들의 예시를 아래에 서술하였다.
for (i = 0; i < N; i++)
a[i] = 0; //clears a
for (i = 0; i < N; i++)
scanf("%d", &a[i]); //reads date into a
for (i = 0; i < N; i++)
sum += a[i]; //sums the elements of a일반적인 변수처럼, scanf 호출을 이용해 배열 요소를 읽을 때에는 & 표시를 반드시 사용해야 한다.
C언어는 subscript의 경계가 확인될 필요가 없는데, 만약 subscript가 범위 바깥으로 나가면 이 행위는 undefined behavior이다. subscript가 경계 바깥을 넘어가는 것을 유발하는 하나의 상황은, 배열의 요소가 n개인 배열이 0부터 n-1까지 index된다는 것을 잊고있는 것이다. 일변적인 큰 실 수로 인해 발생될 수 있는 기괴한 현상이 아래의 예시에 있다.
int a[10], i;
for (i = 1; i <= 10; i++)
a[i] = 0;어떠한 컴파일러에서는, 이 순진해보이는 for 구문이 무한 루프를 발생시킬 수 있다.
i가 10에 도달했을 때, 프로그램은 a[10]에 0을 저장한다. 근데 a[10]은 존재하지 않고, 그래서 0은 a[9]다음의 메모리에 바로 저장된다. 만약 이 경우처럼 변수 i가 메모리에서 a[9] 바로 다음에 저장되어 있다면, i는 0으로 초기화되고, 루프가 처음부터 다시 시작된다.
배열의 subscript는 어떠한 정수 표현식이라도 될 수 있다.
a[i+j*10] = 0;표현식은 심지어 side effects를 가질 수도 있다.
i = 0;
while (i < N)
a[i++] = 0;배열 subscript가 side effect를 가질 때에는 반드시 주의해야 한다. 아래의 예시를 보면 알 수 있는데, 배열 b의 요소를 a에 복사하도록 설계된 루프는 적절하게 작동하지 않을 것이다.
i = 0;
while (i < N)
a[i] = b[i++];a[i] = b[i++]는 i의 값에 접근하면서 동시에 표현식 안에 i를 수정한다. Section 4.4에서 봤듯이 이는 undefined behavior이다. 당연하게도 우리는 subscript에 증가연산자를 제거하는 것으로 이 문제를 간단하게 피할 수 있다.
for (i = 0; i < N; i++)
a[i] = b[i];Array Initialization
다른 변수들처럼 배열도 선언될 때 같이 초기값을 가질 수 있다. 이 규칙은 어느정도는 까다로울 수 있기 때문에 일부만 알아보고 나머지는 후에 서술할 것이다.
array initializer의 가장 흔한 형태는 상수 표현식의 목록을 닫힌 중괄호 안에 넣고 콤마로 분리하는 것이다.
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};initializer가 배열보다 짧다면, 남은 배열의 요소들은 0의 값을 가지게 된다.
int a[10] = {1, 2, 3, 4, 5, 6};
/* initial value of a is {1, 2, 3, 4, 5, 6, 0, 0, 0, 0} */이 특징을 이용한다면, 우리는 간단하게 배열을 0으로 초기화할 수 있다.
int a[10] = {0};
/* initial value of a is {0, 0, 0, 0, 0, 0, 0, 0, 0, 0} */initializer를 완벽하게 빈칸으로 하는 것은 규칙에 어긋나기 때문에, 중괄호 안에 하나라도 0을 넣어야 한다. 배열보다 긴 초기화를 하는 것또한 규칙에 어긋난다.
만약 initiailizer가 존재한다면, 배열의 길이는 생략될 수 있다.
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};컴파일러는 initializer의 길이를 사용하여 얼마나 배열이 긴 지 결정한다. 마치 길이를 명시적으로(explicitly) 특정한 것처럼 배열은 여전히 고정된 요소의 개수를 가질 것이다(위의 예제에서는 10).
Designated Initializers
상대적으로 적은 배열의 요소들을 명시적으로(explicitly) 초기화해야할 필요가 있는 경우가 있다. 아래의 예시를 보자.
int a[15] = {0, 0, 29, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 48};우리는 배열의 요소 2를 29로, 요소 9를 7로, 요소 14를 48로 하면서 다른 값들은 0이 되도록 하기를 원한다. 큰 배열에서는, 이러한 방식의 initializer 작성은 지루하고 오류가 발생하기 쉽다.
C99의 designated initializers는 이 문제를 해결할 수 있게 해준다. desiganted initializer를 사용하여 이전의 예제를 고치는 방법은 아래와 같다.
int a[15] = {[2] = 29, [9] = 7, [14] = 48};대괄호 안의 각각의 숫자는 designator라고 부른다
더 짧아지고 읽기 쉬워졌을 뿐만 아니라, designated initializer는 또다른 장점을 가진다. 요소를 적을 때 요소의 순서는 문제가 되지 않는다는 점이다. 예시를 아래처럼도 쓸 수 있다.
int a[15] = {[14] = 48, [9] = 7, [2] = 29};designator는 반드시 정수형 상수 표현식이여야 한다. 만약 초기화된 배열이 n의 길이를 가지면, 각각의 designaotr는 반드시 0과 n-1 사이여야 한다. 만약 배열의 길이가 생략되었다면, designatore는 음수가 아닌 어떠한 정수라도 될 수 있다. 후자의 경우 컴파일러는 가장 큰 designator로부터 배열의 길이를 추론할 것이다. 아래의 예시를 보면, designaotr로 나타난 23이 길이를 24로 하도록 강제할 것이다.
int b[] = {[5] = 10, [23] = 13, [11] = 36, [15] = 29};initializer는 오래된 방식과 새로운 방식 둘다 사용할 수 있다.
int c[10] = {5, 1, 9, [4] = 3, 7, 2, [8] = 6};위의 initializer에서 c에 어떻게 저장될지 예측해보면, c[0]은 5, c[1]은 1, c[2]는 9, c[3]은 0, c[4]는 3, c[5]는 7, c[6]은 2, c[7]은 0, c[8]은 6, c[9]는 0이다.
Using the sizeof Operator with Arrays
sizeof 연산자는 배열의 크기를(byte로) 결정 할 수 있게 해준다. 만약 a가 10개의 정수 배열이라면 sizeof(a)는 전형적으로(int가 4byte를 필요로한다고 했을때) 40이다.
우리는 sizeof를 a[0]과 같은 배열 요소의 크기를 측정하는 것에도 사용할 수 있다. 배열 크기를 요소 크기로 나누면 배열의 길이를 알 수 있다.
sizeof(a) / sizeof(a[0])어떠한 프로그래머들은 배열의 길이가 필요할 때 이러한 표현식을 사용한다. 아래의 예시는 배열 a를 전부 지우는 예시이다.
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
a[i] = 0;이러한 기술로, 나중에 프로그램을 업데이트 했을 때 배열의 길이가 바뀌어도 이 루프 구문을 수정하지 않아도 된다. 당연하게도 macro를 사용하여 배열의 길이를 표현하는 것도 이와 똑같지만, sizeof를 사용하는 것이 조금더 낫다. 왜냐하면 macro의 이름을 기억할 필요가 없기 때문이다.
하나 짜증날 수 있는 것은 어떤 컴파일러들은 i < sizeof(a) / sizeof(a[0])의 표현식에 경고 메시지를 만들기도 한다. 변수 i는 아마도 int(signed 자료형)인 반면에, sizeof는 size_t(unsigned 자료형) 자료형의 값을 생성하기 때문이다. Section 7.4에서 설명했던 것처럼 signed 정수와 unsigned 정수를 비교하는 것은 아주 위험한 습관이지만, 이 경우에서는 안전하다. 왜냐하면 i와 sizeof(a) / sizeof(a[0])의 값은 음수가 아닌 값이기 때문이다. 이러한 경고를 제거하기 위해서는 sizeof(a) / sizeof(a[0])의 자료형을 cast하여 signed 정수로 바꾸어야 한다.
for (i = 0; i < (int)(sizeof(a) / sizeof(a[0])); i++)
a[i] = 0;(int)(sizeof(a) / sizeof(a[0]))는 조금 다루기 어려울 수 있다. 이때 매크로(macro)를 정의하는 것은 도움이 된다.
#define SIZE ((int)(sizeof(a) / sizeof(a[0])))
for (i = 0; i < SIZE; i++)
a[i] = 0;위에서는 분명 macro를 피하기 위해서 sizeof를 사용한 것인데, 이렇게 되면 주객전도가 된 것이 아닐까라고 생각할 수 있다. 이에 대한 대답은 나중의 chapter에서 할 것이다.
2. Multidimensional Arrays
배열은 어떤 숫자의 dimension이라도 가질 수 있다. 예를 들면, two-dimensional array또한 선언할 수 있다. 이는 수학적 용어로 matrix라고 한다.
int m[5][9];배열 m은 5개의 row과 9개의 column을 가진다. row와 column은 각각 0부터 index된다.

row i와 column j 안의 m의 요소에 접근하기 위해서는, m[i][j]를 써야한다. m[i]표현식은 m의 row i를 지정하고, m[i][j]는 그 후 이 row에서 요소 j를 선택한다.
m[i][j] 대신에 m[i,j]를 쓰는 유혹을 이겨내야 한다. C언어는 이 맥락 안에서 콤마를 하나의 연산자로써 처리하는데, 그래서 m[i,j]는 m[j]와 동일하다.
우리가 two-dimensional array를 테이블의 형태로 시각화하였지만, 이는 실제로 컴퓨터 메모리에 저장되는 방식은 아니다. C언어는 row-major order의 형태로 배열을 저장한다. 아래의 예시는 m 배열이 저장되는 방식이다.
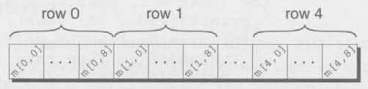
우리는 일반적으로 이 세부적인 것을 무시하지만, 때때로 코드에 영향을 미친다.
for 루프가 one-dimensional array와 관계가 깊은 것처럼, 중첩된 for 루프는 multidimensional array에 이상적이다. 단위행렬(identity matrix)로써 사용하기 위해 배열을 초기화하는 문제가 있다고 해보자. 우리는 체계적인 방식으로 배열의 각각 요소들을 방문할 필요가 있다. 모든 row index와 각각의 column index에 접근하기 위해 쌍으로 중첩된 for 루프는 매우 완벽하다.
#define N 10
double ident[N][N];
int row, col;
for (row = 0; row < N; row++)
for (col = 0; col < N; col++)
if (row == col)
ident[row][col] = 1.0;
else
ident[row][col] = 0.0;C언어에서 multidimensional array는 다른 많은 프로그래밍 언어보다 덜 중요한데, 왜냐하면 C언어에서는 multidimensional data를 저장하는 arrays of pointer라는 더 유연한 방법을 제공하기 때문이다.
Initializing a Multidimensional Array
one-dimensional initializer를 중첩하는 것으로 two-dimensional array에 대한 initializer를 생성할 수 있다.
int m[5][9] = {{1, 1, 1, 1, 1, 0, 1, 1, 1},
{0, 1, 0 ,1, 0, 1, 0, 1, 0},
{0, 1, 0, 1, 1, 0, 0, 1, 0},
{1, 1, 0, 1, 0, 0, 0, 1, 0},
{1, 1, 0, 1, 0, 0, 1, 1, 1}};각각 내부의 initializer는 matirx의 한 row에 대한 값을 제공한다. 더 높은 dimensional array도 비슷한 방식으로 구성할 수 있다.
C언어는 multidimensional에 대한 initializer을 축약할 수 있는 다양한 방법을 제공한다.
- 만약 initializer가 multidimensional array를 채우기에 중분히 크지 않다면, 나머지 요소들은 0의 값을 가진다. 예를 들어 아래의 initializer는 오직 첫번째
m의 3개의 row만 채우고 마지막 2개의 row는 0을 가진다.
int m[5][9] = {{1, 1, 1, 1, 1, 0, 1, 1, 1},
{0, 1, 0, 1, 0, 1, 0, 1, 0},
{0, 1, 0, 1, 1, 0, 0, 1, 0}};- 만약 내부의 목록이 row를 채우기 충분하지 않다면, row안의 남은 요소들은 0으로 초기화된다.
int m[5][9] = {{1, 1, 1, 1, 1, 0, 1, 1, 1},
{0, 1, 0, 1, 0, 1, 0, 1},
{0, 1, 0, 1, 1, 0, 0, 1},
{1, 1, 0, 1, 0, 0, 0, 1},
{1, 1, 0, 1, 0, 0, 1, 1, 1}};- 우리는 내부의 중괄호를 생략해도 된다.
int m[5][9] = {1, 1, 1, 1, 1, 0, 1, 1, 1,
0, 1, 0, 1, 0, 1, 0 ,1 ,0,
0, 1, 0, 1, 1, 0, 0, 1, 0,
1, 1, 0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 1, 0, 0, 1, 1, 1};컴파일러가 한 row를 충분히 값으로 다 채웠다고 보면, 다음부터 채우기 시작할 것이다.
multidimensional array initializer에서 내부의 중괄호를 생략하는 것은 위험한데, 추가적인 요소들(또는, 놓친 요소들)이 남은 initializer에게 영향을 주기 때문이다. 어떤 컴파일러들은 중괄호가 없으면 "missing braces around initializer"라는 오류를 발생시킨다.
C99의 designated intializer는 multidimensional array와 함께 동작한다. 예를 들어 우리가 2 x 2의 단위 행렬을 만든다고 해보자.
double ident[2][2] = {[0][0] = 1.0, [1][1] = 1.0};특정되지 않는 나머지 모든 요소들은 0이 기본값이 될 것이다.
Constant Arrays
one-dimensional이든 multidimensional이든 어떤 배열이든지 상수로 만들어 질 수 있는데, 이는 선언을 할 때 const 단어로 시작해야 한다.
const char hex_chars[] =
{'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F'};const로 선언된 배열은 프로그램에 의해 수정될 수 없다. 컴파일러는 요소를 수정하려는 직접적인 시도를 감지한다.
const로 배열을 선언하는 것은 크게 2가지 장점이 있다. 나중에 코드를 읽는 누군가에게 프로그램이 이 배열을 바꾸기를 원하지 않는다는 것을 알릴 수 있다. 또한 우리가 이 배열을 수정하기를 의도하지 않았다고 알리는 것으로 컴파일러가 에러를 발견하는 것을 도와준다.
const는 배열에 한정된 것이 아니다. 어떠한 변수에도 작동한다. 그러나 const는 특히 배열 선언에서 유용한데, 왜냐하면 배열은 프로그램 실행동안 바뀌지 말아야할 참조(reference) 정보들을 포함할 수 있기 때문이다.
3. Variable-Length Arrays(C99)
배열 변수의 길이는 반드시 상수 표현식에 의해서 명시되어야 한다고 했었다. 하지만 C99에서는 상수가 아닌 표현식을 사용하는 것이 때때로는 가능하다. 아래의 코드를 보자.
/* reverse2.c */
#include <stdio.h>
int main(void)
{
int i, n;
printf("How many numbers do you want to reverse? ");
scanf("%d", &n")
int a[n]; /* C99 only - length of array depends on n */
printf("Enter %d nmumbers: ", n);
for (i = 0; i < n; i++)
scanf("%d", &a[i]);
printf("In reverse order:");
for (i = n - 1; i >= 0; i--)
printf(" %d", a[i]);
printf("\n");
return 0;
}이 프로그램에서의 배열 a는 variable-length array(VLA)에 대한 예시이다. VLA의 길이는 프로그램이 컴파일될 때가 아닌 시작되었을 때, 계산된다. VLA의 주요한 이점은 프로그래머가 배열을 선언할 때 자의적으로 길이를 설정할 필요가 없다는 점이다. 대신 얼마나 많은 요소들이 실제로 필요한지 프로그램이 자체적으로 계산할 수 있도록 한다. 만약 프로그래머가 결정한다면, 배열은 너무 길어질 수 있고(메모리 낭비) 너무 짧아질(프로그램이 실패하도록 하는) 수도 있다.
reverse2.c 프로그램에서 a의 길이가 사용자가 입력한 숫자의 값에 의해 결정되었다. 프로그래머는 고정된 길이를 선택할 필요가 없는 것이다.
VLA의 길이는 단일 변수로만 특정될 필요는 없다. 연산자를 포함한 자의적인(arbitrary) 표현식또한 가능하다.
int a[3*i+5];
int b[j+k];다른 배열처럼, VLA는 multidimensional일 수 있다.
int c[m][n];VLA에 대한 주요한 제한은 VLA가 static storage duration을 가질 수 없다는 것이다. 또다른 제한은 VLA는 initializer를 가질 수 없다는 것이다.
Variable-length array는 main 함수와는 다른 함수에서 자주 보인다. VLA의 큰 장점은 함수 f에 VLA가 속해있을 때인데, f가 호출 될 때마다 VLA는 다른 길이를 가질 수 있다.
Others
왜 subscript는 1이 아니라 0부터 시작하는가?
subscript를 0부터 시작하는 것은 컴파일러를 조금 더 간단하게 만든다. 또한 array subscripting을 약간 빠르게 할 수 있다.
subscript가 0에서 9까지가 아닌, 1에서 10까지 하려면 어떻게 해야하나?
일반적인 트릭으로는 10개가 아닌 11개의 요소들을 가지도록 배열을 선언한다. 그러면 subscript가 0부터 10까지 가능할 것이지만, 여기서 0은 사용하지 않는다.
array subscript로 문자를 사용하는 것도 가능한가?
당연히 가능하다. C언어는 문자를 정수로써 다루기 때문이다. 하지만 이것을 subscript로 사용하기 전에 문자에 대한 "조절"이 필요할 수 있다. 만약 단어의 알파벳을 세어 저장하는 letter_count 배열을 만들어야 한다고 해보자. 그 배열은 26개의 요소를 필요로 할 것이고, 그래서 우리는 아래와 같은 방식으로도 선언할 수 있다.
int letter_count[26];그러나 우리가 letter_count 배열의 subscript에 직접적으로 단어를 사용할 수 없는데, 그들의 정수 값은 0과 25사이에 있지 않기 때문이다. 소문자 단어를 적절한 범위로 조절하기 위해서는 우리는 간단하게 'a'를 빼는 방법이 있다. 대문자를 조절하기 위해서는 'A'를 빼면 될 것이다. 예를 들어 ch가 소문자 단어를 포함하고 있다고 생각해보자.
letter_count[ch-'a'] = 0;작은 주의사항이 있는데 이 기술은 완벽하게 portable하지 않다. 단어가 연속적인 코드라는 가정이 있기 때문이다. 그래도 ASCII를 포함한 대부분의 문자 집합에는 작동할 것이다.
designated initializer이 배열의 요소를 한번보다 더 많이 초기화할 수 있는 것처럼 보이는데, 그러면 아래와 같은 배열 선언은 규칙에 어긋나지 않을 것이다. 그러면 이 배열의 길이는 얼마나 되나?
int a[] = {4, 9, 1, 8, [0] = 5, 7};이 선언은 규칙에 잘 따르고 있다. initializer list를 처리할 때, 컴파일러는 배열의 어떤 요소가 다음에 초기화되어야 하는지 추적한다. 일반적으로 다음 요소는 마지막으로 초기화 된 요소의 다음이다. 그러나 designator가 list에서 나타난다면, designator가 표현하는 요소의 다음 요소를 강제하게 된다. 그 요소가 이미 초기화되었더라도 말이다.
컴파일러가 배열 a에 대한 initializer를 어떻게 처리하는지 차례로 나타내 보겠다.
- 요소 0(
a[0])은 4로 초기화된다. 초기화되는 다음 요소는 1(a[1])이다. - 요소 1(
a[1])은 9로 초기화된다. 초기화되는 다음 요소는 2(a[2])이다. - 요소 2(
a[2])은 1로 초기화된다. 초기화되는 다음 요소는 3(a[3])이다. - 요소 3(
a[3])은 8로 초기화된다. 초기화되는 다음 요소는 4(a[4])이다. [0]designator는 다음 요소가 0(a[0])이 되게 하고, 그래서 요소 0(a[0])이 5로 초기화된다. 초기화되는 다음 요소는 1(a[1])이다.- 요소 1(이미 9가 저장된
a[1])은 7로 초기화된다. 초기화되는 다음 요소는 2(a[2])이다.
결론은 list의 끝이 요소 2(a[2])였는데, 이는 길이와 관련이 없다.
최종 결과는 아래에 쓴 것과 동일하다.
int a[] = {5, 7, 1, 8};그래서 배열의 길이는 4이다.
대입(assignment) 연산자를 사용하여 배열을 복사하려고 했는데 컴파일러가 에러 메시지를 만들었다. 무엇이 문제인가?
충분히 그럴싸하게 보이지만, 배열의 대입 연산은 규칙에 어긋난다.
a = b; /* a and b are arrays */위의 표현식은 규칙에 어긋난다. 이 위법성(illegality)는 지금 명확하지 않다. C언어의 배열과 포인터 사이의 독특한 관계와 관련이 있어서, 이 주제는 나중의 chapter에서 알아볼 것이다.
하나의 배열을 다른 배열로 복사하는 가장 간단한 방법은 요소(element)를 복사하는 루프를 사용하는 것이다.
for (i = 0; i < N; i++)
a[i] = b[i];다른 방법은 <string.h> 헤더의 memcpy(memory copy) 함수를 사용하는 것이다. memcpy는 low-level 함수이고, 한 위치로부터 다른 위치로 byte를 간단하게 복사한다. 배열 b에 a를 복사하기 위해서는 아래와 같은 방법으로 memcpy를 사용하면 된다.
memcpy(a, b, sizeof(a));많은 프로그래머들이 memcpy를 선호하며 특히 큰 배열에서 많이 선호하는데, 왜냐하면 일반적인 루프보다 잠재적으로 더 빠르기 때문이다.
Section 6.4에서 C99는 goto 구문을 variable-length array의 선언을 우회하는 것에 사용할 수 없다고 했다. 이 제한의 이유는 무엇인가?
variable-length array를 저장하기 위한 메모리는 보통 프로그램 실행중에 배열의 선언부에 도착했을 때 할당된다. goto를 사용하여 선언을 우회하는 것은 프로그램이 할당된 적이 없는 배열의 요소에 접근하는 결과를 일으킬 수 있다.

row-major order 는
cache friendly코드 (cache miss&hit) 와,false sharing문제 (cache coherencyproblem) 와 관련하여 자주 이슈가 됩니다. 잘 알아두시면 나중에 도움이 되리라 생각합니다 : )