4. The return Statement
void가 아닌 함수는 반드시 return 구문을 사용하여 어떤 값을 반환하는지 명시해주어야 한다. return 구문은 아래와 같은 형태를 따른다.
return expression ;표현식은 보통 상수나 변수이다.
return 0;
return status;더 복잡한 표현식도 가능하다. 많이 쓰진 않지만 조건 연산자(conditional operator)도 return 구문에 사용될 수 있다.
return n >= 0 ? n : 0;이 구문이 실행되었을 때, n >=0 ? n : 0이 먼저 계산된다. 계산 결과가 true면 n이 반환되고, 아니면 0이 반환될 것이다.
만약 return 구문의 표현식의 자료형이 함수의 return type과 일치하지 않는다면, 표현식은 암시적으로(implicitly) return type으로 변환될 것이다. 예를 들어 만약 함수가 int로 선언되었지만, return 구문이 double 자료형을 포함하고 있다면 표현식의 값은 int로 변환된다.
return 구문은 return type이 void인 함수에서도 나타날 수 있는데, 어떠한 표현식도 주어지지 않는다.
return; /* return in a void function */이러한 return 구문에 표현식을 넣는 것은 compile-time error를 발생시킬 수 있다. 아래의 에제에서는 부정인 argument가 주어졌을 때 즉각적으로 함수를 반환시킨다.
void print_int(int i)
{
if (i < 0)
return 0;
printf("%d", i);
}i가 0보다 작다면, print_int는 printf의 호출없이 반환된다.
return 구문은 void 함수의 끝에 나타날 수도 있다.
void print_pun(void)
{
printf("To C, or not to C: that is the question.\n");
return; /* OK, but not needed */
}함수의 마지막 구문이 실행된 이후에 자동으로 함수가 반환되기 때문에, return을 사용하는 것은 불필요하다.
void가 아닌 함수가 return 구문 실행에 실패하여 body의 끝부분에 도달했고, 이 함수에 의해 반환된 값을 사용하려고 시도한다면 이는 undefined behavior이다. 어떤 컴파일러는 void가 아닌 함수가 body의 끝까지 도달할 가능성을 발견한다면 "control reaches end of non-void function"과 같은 경고를 발생시킨다.
5. Program Termination
main이 함수이기 때문에 반드시 return type을 가져야 한다. 일반적으로 main의 return type은 int이다.
int main(void)
{
...
}오래된 C 프로그램들은 종종 전통적으로 기본값이 int라는 사실을 이용하여 main의 return type을 생략하기도 한다.
main()
{
...
}하지만 함수의 return type을 생략하는 것은 C99에서 규칙에 어긋난다. 그래서 위와 같은 습관은 피해야 한다. main의 parameter 안에 void를 생략하는 것은 규칙에 맞지만, 명시적으로 main이 parameter 를 가지지 않는다는 사실을 나타내는 것이 가장 좋다. (나중에 main이 때때로 argc와 argv라는 2개의 parameter을 가진다는 사실을 알아볼 것이다.)
main에 의해 반환되는 값은 상태 코드(status code)인데, 프로그램이 종료될 때 검사된다. main은 프로그램이 일반적으로 종료되었을 때 0을 반환해야 한다. 비정상적인 종료를 나타내기 위해서 main은 0이 아닌 다른 값을 반환해야 한다(실제로는, 다른 의도로 return 값을 사용하는 것을 방지하기 위한 규칙은 없다). 상태 코드를 쓸 일이 없더라도 모든 C 프로그램이 상태 코드를 반환하도록 하는 것은 좋은 습관이다.
The exit Function
main 안에서 return 구문을 실행하는 것은 프로그램을 종료하는 하나의 방법이다. 또다른 방법은 exit 함수를 호출하는 것인데, 이는 <stdlib.h> 헤더에 속해있다. exit에 전달되는 argument는 main의 반환값과 동일한 의미를 가진다. 둘다 종료에서의 프로그램 상태를 나타낸다. 일반적인 종료를 나타내기 위해선 0을 전달한다.
exit(0); /* normal termination */0을 숨기고 싶을수 있기 때문에 C언어는 EXIT_SUCCESS를 대신 지원한다(효과는 똑같다).
exit(EXIT_SUCCESS); /* normal termination */EXIT_FAILURE를 전달하는 것은 비정상적인 종료를 나타낸다.
exit(EXIT_FAILURE); /* abnormal termination */EXIT_SUCCESS와 EXIT_FAILURE는 <stdlib.h>에 정의된 매크로(macro)이다. EXIT_SUCCESS와 EXIT_FAILURE는 implementation-defined이지만, 일반적인 값은 각각 0과 1이다.
프로그램을 종료하는 방법으로써 return과 exit는 밀접하게 관계되어 있다.
return expressionexit(expression);첫번째 구문과 두번째 구문은 main내부에서 동일하다.
return과 exit의 차이점은, exit는 어떤 함수에서 호출이 되던 상관없이 프로그램을 종료시키고, return 구문은 main 함수 내부에서 나타낼 때에만 프로그램이 종료된다는 점이다. 어떤 프로그래머들은 프로그램 내부에서 모든 종료 지점을 쉽게 만들기 위해 exit를 사용한다.
6. Recursion
함수가 자기 스스로 호출한다면 함수는 재귀적이다(recursive). 예를 들어 아래의 n!을 공식 n! = n * (n - 1)!에 따라 계산하는 함수를 보자.
int fact(int n)
{
if (n <= 1)
return 1;
else
return n * fact(n - 1);
}어떠한 프로그래밍 언어는 재귀에 아주 많이 의존하기도 하지만, 어떤 프로그래밍 언어들은 재귀를 허용하지 않기도 한다. C언어는 어디에도 포함되지 않는 중간형이다. C언어는 재귀를 허용하지만, 대부분 C 프로그래머들은 재귀를 자주 이용하지는 않는다.
어떻게 재귀가 작동하는지 알아보자.
i = fact(3);fact(3)은 1보다 작거나 같지 않은 3을 발견하였고, 그래서 fact(2)를 호출한다.
fact(2)는 1보다 작거나 같지 않은 2를 발견하였고, 그래서 fact(1)을 호출한다.
fact(1)은 1보자 작거나 같은 1을 발견하였고, 그래서 1을 반환한다.
fact(2)는 2 * 1 = 2를 반환한다.
fact(3)은 3 * 2 = 6을 반환한다.fact가 최종적으로 1을 전달할 때 까지 끝나지 않은 fact의 호출이 어떻게 쌓이는지를 주목해야한다. 원래의 호출인 fact(3)이 정답인 6을 반환할 때까지 과거에 호출된 fact가 하나씩 풀리기 시작한다.
아래에 재귀에 대한 또다른 예시가 있다. x^n = x * x^(n-1)의 공식을 이용하여 x^n을 계산하는 함수이다.
int power(int x, int n)
{
if (n == 0)
return 1;
else
return x * power(x, n - 1);
}power(5, 3)의 호출은 아래와 같이 실행된다.
power(5, 3)는 0과 같지 않은 3을 발견하였고, 그래서 power(5, 2)를 호출한다.
power(5, 2)는 0과 같지 않은 2를 발견하였고, 그래서 power(5, 1)을 호출한다.
power(5, 1)은 0과 같지 않은 1을 발견하였고, 그래서 power(5, 0)을 호출한다.
power(5, 0)은 0과 같은 0을 발견하였고, 그래서 1을 반환한다.
power(5, 1)은 5 * 1 = 5를 반환한다.
power(5, 2)는 5 * 5 = 25를 반환한다.
power(5, 3)은 5 * 25 = 125를 반환한다.power 함수를 조건 표현식(conditional expression)을 return 구문에 사용하는 것으로 조금 더 압축시킬 수 있다.
int power(int x, int n)
{
return n == 0 ? 1 : x * power(x, n - 1);
}fact와 power 둘다 호출되었을 때 종료 조건을 검사하는 것에 주의해야한다. fact가 호출되었을 때, parameter가 1보다 작거나 같은지 즉각적으로 확인할 것이다. power가 호출되었을 때, 두번째 parameter가 0과 같은지 확인할 것이다. 모든 재귀 함수는 무한 재귀(infinite recursion)을 예방하기 위해 어떠한 종류의 종료 조건을 필요로 한다.
The Quicksort Algorithm
이 시점에서, 우리가 왜 재귀를 필요로 하는지 이유가 궁금할 것이다. fact나 power 둘다 재귀를 진정으로 필요로 하지 않기 때문이다. 사실, fact나 power 둘다 재귀를 많이 사용하지는 않았는데, 왜냐하면 각각의 호출이 자기 자신을 한번만 호출하기 때문이다. 재귀는 이러한 상황보다는 함수가 스스로를 두 번, 세 번 이상씩 필요로 하는 정교하고 복잡한 알고리즘에서 더 도움이 된다.
실제로, 재귀는 분할정복(divied-and-conquer)이라고 알려진 알고리즘 디자인 기술의 결과로써 자연스럽게 떠오르게 되었다. 분할정복은 큰 문제를 작은 조각으로 나눈 다음에 동일한 알고리즘으로 해결할 수 있게 한다. 분할정복 전략의 가장 기본적인 예시는 잘 알려진 알고리즘인 Quicksort에서 발견할 수 있다. Quicksort 알고리즘은 아래의 원리로 작동한다.(정렬되는 배열이 1부터 n까지라고 가정)
- 배열의 요소
e("partitioning element")를 선택한 후, 요소1, ...,i-1이e보다 작거나 같도록 재배열되고, 요소i는e를 포함하고, 요소i+1, ...,n은e보다 크거나 같다. 1, ...,i-1을 Quicksort를 재귀적으로 사용하여 정렬한다.i+1, ...,n을 Quicksort를 재귀적으로 사용하여 정렬한다.
1단계에서 요소 e는 적절한 위치에 있다. e의 왼쪽에 있는 요소들은 e보다 작거나 같기 때문에, 요소들은 2단계에서 정렬되어 올바른 위치에 있을 것이다. 비슷한 논리가 e의 오른쪽에 있는 요소들에도 적용된다.
Quicksort 알고리즘의 1단계는 아주 중요하다. 다른 방법보다 더 좋은 배열을 나눌 수 있는 여러 방법이 있기 때문이다. 우리는 이해하기는 쉽지만 특별하게 효과적인 것은 아닌 기술을 사용할 것이다.
이 알고리즘은 2개의 "표식"에 의존하는데, 이름은 각각 low와 high이다. 이 표식들은 배열 안에서 이동한다.
처음에는 low를 첫번째 요소로 하고, high를 마지막 요소로 한다. 첫번째 요소(partitioning element)를 일시적인 위치에 복사해놓고, 배열에 구멍을 내야한다.
다음엔, high가 partitioning element보다 작은 지점을 가리킬때까지 오른쪽에서 왼쪽으로 high를 이동시킨다. 그리고 high가 가리키는 지점에 있는 요소를 low가 가리켰었던 구멍에 복사한다. 그리고 high가 가리키는 지점에 새로운 구멍을 만든다.
이제는 low를 왼쪽에서 오른쪽으로 옮길 차례인데, partitioning element보다 더 큰 요소를 찾아서 이동한다. 이를 만족하는 요소를 발견하면, 이 요소를 high 가 가리키는 구멍에 복사한다. low와 high가 번갈아가면서 이러한 과정을 반복하게 되고, 이 과정은 high와 low가 중앙에서 만날때까지 계속된다.
이 시점에서, low와 high는 둘다 구멍을 가리킬 것이다. 우리가 해야할 모든 것들은 partitioning element를 구멍으로 복사하는 것이다. 아래의 다이어그램은 Quicksort가 어떻게 정수의 배열을 정렬하는지 설명한다.

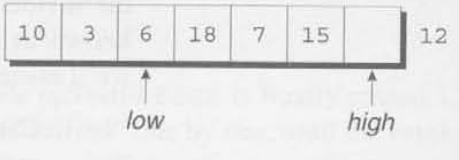
low는 첫번째 요소를, high는 마지막 요소를 가리킨다.

첫번째 요소는 12인데, 이는 partitioning element이다. 이것을 다른 어떤 곳에든지 저장해두고 배열의 시작부분에 구멍을 만든다.

우리는 이제 high가 가리키고 있는 요소인 12를 비교할 것이다. 10이 12보다 작기 때문에 10은 잘못된 자리에 있는 것이고, 그래서 10을 구멍으로 옮기고 low를 오른쪽으로 이동시킨다.
low가 3을 가리키는데, 이는 12보다 작으므로 옮길 필요가 없다. 대신 low를 오른쪽으로 이동시킨다.
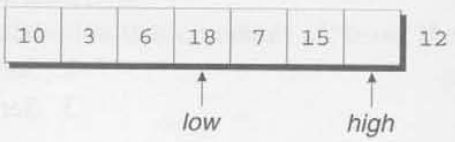
6이 12보다 작기 때문에 low를 다시 오른쪽으로 옮긴다.
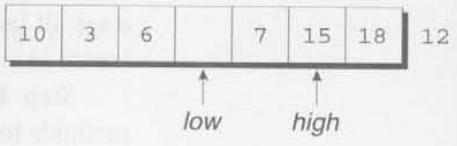
low가 이제 18을 가리키고 있는데, 18은 12보다 크므로 잘못된 자리에 있다. 18을 구멍으로 옮긴 다음에, high를 왼쪽으로 옮긴다.
high가 15를 가리키는데 15는 12보다 크므로 옮길 필요가 없다. high를 왼쪽으로 옮긴다.
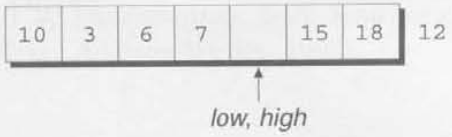
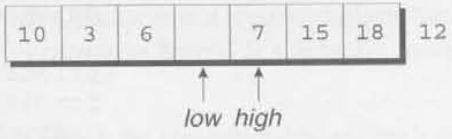
high가 7을 가리키는데 이는 12보다 작으로므로 잘못된 위치에 있다. 7을 구멍으로 옮긴 후 high를 왼쪽으로 옮긴다.

low와 high가 이제 같고, 그렇기 때문에 우리는 구멍으로 partitioning element를 옮긴다.
우리는 이 시점에서 우리의 목표를 완수했다. partitioning element의 왼쪽에 있는 모든 요소는 12보다 작거나 같고, 오른쪽에 있는 모든 요소들은 12보다 크거나 같다. 이제 배열은 나누어졌으며, 우리는 첫 4개의 요소(10, 3, 6, 7)와 마지막 2개의 요소들(15, 18)에 Quicksort를 재귀적으로 사용하면 된다.
Quicksort program
quicksort의 이름을 가진 재귀함수를 구현해보자. main 함수에서 배열에 10개의 숫자를 읽어 quicksort함수를 호출하여 배열을 정렬한 후 배열의 요소를 출력할 것이다.
Enter 10 numbers to be sorted:input
9 16 47 82 4 66 12 3 25 51
output
In sorted order: 3 4 9 12 16 25 47 51 66 82배열을 분리하는 코드가 조금 길기 때문에, split이라는 이름을 가진 함수로 분리했다.
qsort.c
/* Sorts an array of integers using Quicksort algorithm */
#include <stdio.h>
#define N 10
void quicksort(int a[], int low, int high);
int split(int a[], int low, int high);
int main(void)
{
int a[N], i;
printf("Enter %d numbers to be sorted: ", N);
for (i = 0; i < N; i++)
scanf("%d", &a[i]);
quicksort(a, 0, N - 1);
printf("In sorted order: ");
for (i = 0; i < N; i++)
printf("%d ", a[i]);
printf("\n");
return 0;
}
void quicksort(int a[], int low, int high)
{
int middle;
if (low >= high) return;
middle = split(a, low, high);
quicksort(a, low ,middle - 1);
quicksort(a, middle + 1, high);
}
int split(int a[], int low, int high)
{
int part_element = a[low];
for(;;) {
while (low < high && part_element <= a[high])
high--;
if (low >= high) break;
a[low++] = a[high];
while (low < high && a[low] <= part_element)
low++;
if (low >= high) break;
a[high--] = a[low];
}
a[high] = part_element;
return high;
}이러한 형태의 Quicksort가 작동하긴 하지만, 이것은 가장 좋은 방법은 아니다. 프로그램의 성능을 올릴 수 있는 여러가지 방법이 있다.
-
partitioning algorithm을 향상시켜라.
- 우리의 방법은 가장 효율적인 것이 아니다. partitioning element로 배열의 첫번째의 요소를 선택하는 대신에, 첫번째 요소, 중앙의 요소, 마지막 요소의 중간값을 선택하는 것이 더 좋다. partitioning 과정이 자체적으로 더 간단해지고 빨라진다. 특히, 두 개의
while문으로low < high의 검사를 했는데, 이를 피하는 방법이 있다.
- 우리의 방법은 가장 효율적인 것이 아니다. partitioning element로 배열의 첫번째의 요소를 선택하는 대신에, 첫번째 요소, 중앙의 요소, 마지막 요소의 중간값을 선택하는 것이 더 좋다. partitioning 과정이 자체적으로 더 간단해지고 빨라진다. 특히, 두 개의
-
작은 배열을 정렬하는 다른 방법을 사용해라.
- 하나의 요소가 있는 배열까지 Quicksort를 재귀적으로 사용하지 않고, 대신에 작은 배열(25개의 요소 이하)에 대한 더 간단한 방법을 사용하는 것이 좋다.
-
Quicksort를 재귀적이지 않게 만들어라.
- Quicksort는 기본적으로 재귀 알고리즘인데, 이는 재귀의 형태가 더 쉽게 이해할 수 있기 때문이다. 만약 재귀가 없어진다면 더 효율적일 수 있다.
Quicksort를 증진시키는 것에 대한 세부사항은 Robert Sedgewick의 Algorithms in C, Parts 1-4: Fundamentals, Data Structures, Sorting, Searching, Third Edition과 같은 알고리즘 디자인에 대한 책을 찾아보라.
Others
parameter의 목록 이후에 분리된 형태로 parameter의 선언 내에서 자료형이 명시되었는데, 이는 규칙에 맞는 것인가?
double average(a, b)
double a, b;
{
return (a + b) / 2;
}함수를 정의하는 이러한 방법은 K&R C로부터 등장했는데, 그래서 이러한 형태는 오래된 책이나 프로그램에서 발견할 수 있다. C89와 C99는 오래된 프로그램이 여전히 컴파일되게 하기 위해서 이러한 스타일을 지금도 지원한다. 그러나 이러한 형태는 새로운 프로그램에서는 피하는 것이 좋다. 2가지 이유가 있다.
첫번째, 오래된 방식으로 선언된 함수는 같은 정도의 error-checking을 따르지 않는다. 함수가 오래된 형태로 정의되었고 prototype이 존재하지 않을때, 컴파일러는 함수의 호출에 argument의 개수가 올바른지 확인하지 않을 것이고 argument가 적절한 자료형을 가졌는지 확인하지 않을 것이다. 대신에 default argument promotion을 수행한다.
두번째, C 표준은 오래된 스타일은 "시대에 뒤떨어졌다"라고 말한다. 이는 오래된 스타일의 사용은 장려되지 않고, 최종적으로는 C언어로부터 떨어져 나올 수도 있다는 것을 의미한다.
어떠한 프로그래밍 언어는 프로시저(procedure)와 함수가 서로를 중첩하는 것을 허용한다. C언어는 함수 정의가 중첩되는 것을 허용하는가?
허용하지 않는다. C언어는 함수의 정의가 또다른 함수의 body에서 나타나는 것을 허용하지 않고, 이러한 제한은 컴파일러를 간단하게 해준다.
왜 컴파일러는 괄호가 없이 함수의 이름을 사용하는 것을 허용하는가?
나중의 chapter에서 알아볼 것이지만, 컴파일러는 괄호가 붙어있지 않은 함수 이름을 함수에 대한 pointer로써 취급한다. 함수에 대한 포인터(Pointers to functions)는 정당한 사용이고, 그래서 컴파일러는 자동적으로 괄호가 없는 함수 이름을 에러라고 판단할 수 없다.
print_pun;
위의 구문은 컴파일러가 print_pun을 포인터로써 처리하고, 그러므로 표현식이 유효한(가리키는 것은 없지만) 표현식 구문을 만들기 때문에 규칙에 어긋나지 않는다.
함수 호출 f(a, b)에서, 컴파일러는 콤마(,)가 분리하는 문장부호인지 연산자인지 어떻게 아는가?
함수 호출에서의 arguments는 자의적(arbitrary) 표현식이 될 수 없다. 대신에 괄호로 둘러싸이지 않는 한, 반드시 연산자로써의 콤마를 포함하지 않는 "대입 표현식(assignment expression)"이 되어야한다. f(a, b)에서의 콤마는 문장부호이고, f((a,b))에서의 콤마는 연산자이다.
함수 prototype 안에서 parameter의 이름은 함수 정의에서 주어진 이름과 동일해야 하는가?
그렇지 않다. 어떤 프로그래머들은 이 사실을 이용하여 prototype의 parameter에 긴 이름을 붙이는데, 실제의 정의에서는 짧은 이름을 사용한다. 프랑스 프로그래머는 영어 이름을 prototype에서 사용하고, 함수 정의에서 더 익숙한 프랑스어 이름을 사용하기도 한다.
왜 함수 prototype을 신경을 써야하는지 잘 모르겠다. 그냥 모든 함수의 정의를 main 이전에 넣으면 되지 않나?
이건 틀린 말이다. 첫번째로, 이 질문은 main에서만 다른 함수를 호출한다고 가정한 것이고, 이건 비현실적이다. 실제로는 몇몇 함수끼리 서로를 호출할 것이다. 우리가 모든 함수 정의를 main 이전에 정의한다면, 우리는 이 순서를 주의깊게 봐야한다. 아직 정의되지 않은 함수를 사용하는 것은 큰 문제를 야기하기 때문이다.
이게 끝이 아니다. 두 개의 함수가 서로를 호출한다고 가정해보자. 우리가 첫번째로 정의한 함수에는 어떠한 문제가 없지만, 첫번째 함수는 아직 정의되지 않은 함수를 호출할 것이다.
또있다. 프로그램이 특정한 크기에 도달하고 나면, 하나의 파일에 모든 함수를 다 담을수가 없다. 이 지점에 도착하면, 우리는 다른 파일에 있는 함수에 대해 컴파일러에게 prototype을 알려주어야 한다.
parameters에 대한 모든 정보를 생략한 함수 선언을 본적이 있다. 이는 규칙에 맞는 것인가?
double average();규칙에 맞다. 이 선언은 컴파일러에게 average가 double 값을 반환한다는 것을 알려주지만 parameter에 대한 개수나 자료형을 알려주지 않는다.(괄호를 빈칸으로 놔두는 것이 필연적으로 average가 parameter를 가지지 않는다는 의미는 아니다.)
K&R C에서는 우리가 지금까지 사용해온 paramter 정보가 포함된 함수 prototype만을 허용한다. 여기에 대한 규칙은 C89에 도입되었다. 오래된 종류의 함수 선언은 이제 시대에 뒤쳐졌지만, 아직까지 사용이 허용되기는 한다.
왜 프로그래머들은 함수 prototype에서 의도적으로 parameter의 이름을 생략하는가? 그냥 이름을 남기는 것이 쉽지 않은가?
prototype안에서 parameter의 이름을 생략하는 것은 전형적으로 방어적인 의도로 행해진다. 만약 매크로(macro)가 parameter의 이름과 동일한 이름을 가지고 있다면, parameter의 이름은 전처리(preprocessing)과정에서 대체될 것이고, 그러므로 prototype이 피해를 입게된다. 이는 한 사람이 만드는 작은 프로그램에서는 자주 나타나지는 않지만, 여러 사람이 만드는 큰 응용프로그램에서는 나타날 수 있다.
몇몇의 함수가 같은 return type을 가지고 있다면, 그들의 선언은 결합될 수 있는가? 예를 들어 print_pun과 print_count가 void로써 return type이 같아서 결합을 한다면 이는 규칙에 어긋나는가?
void print_pun(void), print_count(int n);규칙에 맞다. 사실 C언어는 함수 선언을 변수 선언과 결합하는 것을 허용한다.
double x, y, average(double a, double b);이러한 방법으로 선언들을 결합하는 것은 좋은 생각이 아니다. 쉽게 혼란을 야기하기 때문이다.
만약에 one-dimensional array parameter의 길이를 명시하면 어떻게 되는가?
컴파일러는 그것을 무시할 것이다. 아래의 예시를 보자.
double inner_product(double v[3], double w[3]);inner_product의 argument가 길이가 3인 배열이여야 한다는 정보전달(documenting) 외에는 길이를 명시하는 것은 받아들여지지 않는다. 컴파일러는 arguement가 3의 길이를 가지는지 체크하지 않을 것이다. 사실 inner_product가 자의적인(arbitrary) 길이의 배열을 전달할 수 있지만, 3의 길이의 배열만 전달할 수 있다고 보여주는 것은 오해의 소지를 만든다.
첫번째 dimension 내부의 array parameter는 명시되지 않은채로 있을 수 있는데, 다른 dimension은 왜 안되는가?
첫번째로, 우리는 C언어에서 배열이 어떻게 전달되는지에 논의해볼 필요가 있다. 12.3에서 설명하겠지만, 배열이 함수로 전달되었을 때, 함수는 배열의 첫번째 요소에 pointer를 부여한다.
다음은, subscripting 연산자(operator)가 어떻게 작동하는지 알아야할 필요가 있다. a가 함수에 전달된 one-dimensional 배열이라고 가정해보자.
a[i] = 0;우리가 위의 구문을 썼을 때, 컴파일러는 i에 배열의 한 요소의 크기를 곱하고, 그 결과를 a가 나타내는 주소(pointer가 함수에 전달한)에 더하는 것으로 a[i]의 주소를 계산한다. 이 계산은 a의 길이에 의존하지 않는데, 이 사실은 왜 우리가 함수의 정의에서 이를 생략할 수 있는지 설명해준다.
그러면 multidimensional array에 대해선 어떨까? C언어는 배열을 row-major order로 저장한다는 점을 기억해보자. row 0에 있는 요소가 처음에 저장되고, 그 후 row 1, ... 계속 진행된다.
a[i][j] = 0; a가 two-dimensional array parameter이고, 우리가 위의 구문을 썼다고 가정해보자.
컴파일러는 아래의 지침을 따른다.
1. a의 하나의 row의 크기에 i를 곱한다.
2. a가 나타내는 주소에 (1)의 결과값을 더한다.
3. 배열 요소의 크기를 j에 곱한다.
4. (3)의 결과를 (2)의 결과값에 더한다.
이러한 지침을 따르기 위해, 컴파일러는 반드시 배열 안의 row의 크기를 알아야 하는데, 이 크기는 column의 개수에 따라 결정된다.
결론은 프로그래머가 반드시 a 안에 column의 개수를 선언해야 한다는 것이다.
왜 일부 프로그래머들은 return 구문의 표현식에 괄호를 사용하는가?
Kernighan and Ritchie의 The C Programming Language(first edition)의 예시에서는 괄호가 필요하지 않더라도 항상 return 구문에 괄호가 있다. 프로그래머들은 k&R로부터의 관습을 습득한 것이다. 괄호가 필요하지도 않고, 가독성에 어떠한 기여도 하지 못하기 때문에 이러한 괄호를 사용하지 않아도 된다(The C Programming Language(second edition)의 예시에서는 괄호가 사용되지 않기 때문에 Kernighan과 Ritchie도 명확히 동의할 것이다).
만약 void가 아닌 함수가 아무 표현식도 가지지 않은 return 구문을 실행하려고 한다면 어떤 일이 일어나는가?
이는 C언어의 버전에 의존한다. C89에서는 void가 아닌 함수에서 표현식이 없는 return 구문을 실행하는 것은 undefined behavior를 야기한다(하지만 함수가 반환한 값을 프로그램이 사용하려고 했을때만 발생한다). C99에서는 이러한 구문은 규칙에 어긋나고, 컴파일러에 의해 에러로써 발견되어야 한다.
프로그램이 일반적으로 종료되었는지 확인하기 위해 main의 반환값을 어떻게하면 볼 수 있나?
이는 사용자의 운영체제(operating system)에 따라 다르다. 많은 운영체제는 몇몇 프로그램을 실행시키는 커맨드를 포함한 batch file또는shell script내부에서 이 값을 검사할 수 있도록 허용한다.
if errorlevel 1 command예를 들어, Windows batch file 안의 위의 행은 마지막 프로그램이 종료되었을 때 상태 코드(status code)가 1과 같거나 1보다 크다면 command를 실행시킬 것이다.
UNIX에서는, 각각 shell마다 상태 코드를 검사하는 방법을 따로 가지고 있다. Bourne shell에서는 $? 변수는 마지막 프로그램의 실행 상태를 포함한다. C shell도 비슷한 변수를 가지고 있지만, 이것의 이름은 $status이다.
왜 내 컴파일러는 main을 컴파일 했을 때 "control reaches end of non-void function"라는 경고 메시지를 출력하는가?
main의 return type이 int임에도 불구하고, main이 return 구문을 가지고 있지 않아 컴파일러가 이를 알아챘기 때문이다.
return 0;위의 구문을 main의 끝부분에 넣으면 컴파일러가 행복할(happy) 것이다. 컴파일러가 return 구문이 없는 것에 대해 거부(object)하지 않을 수도 있기 때문에 이는 좋은 습관이다.
C99 컴파일러를 사용하여 프로그램이 컴파일되었을 때, 이러한 경고는 발생하지 않을 것이다. C99에서는 main의 끝에서 값을 반환하지 않은 채로 놔두어도 괜찮다. 이러한 상황에서는, 표준(the standard)은 main이 자동적으로 0을 반환하도록 한다고 서술한다.
이전의 질문과 관계가 있는데, 왜 main의 반환 자료형을 void로 정의하지 않는가?
비록 이러한 관행이 꽤 일반적이더라도, C89 표준에 따르면 이는 규칙에 어긋난다. 만약 이것이 규칙에 어긋나지 않더라도 이는 좋은 생각이 아닌데, 프로그램의 종료 상태를 검사할 수 있는 사람이 아무도 없을 것으로 추정되기 때문이다.
C99는 이 관행을 표준화할 여지를 만들어놓았는데, main이 "다른 implementation-defined manner(int나 표준에서 명시하지 않은 그밖의 parameter를 반환하는 것)"로 선언되는 것을 허용하기 때문이다. 그러나, 이러한 사용은 이식성(portable)이 좋지 않은데, 그래서 main의 reurn type을 int로 선언하는 것이 가장 좋다.
함수 f1의 호출에서 f1이 함수 f2를 호출하는 것은 규칙에 맞는가?
규칙에 맞다. 이는 f1의 호출이 다른 함수의 호출을 이끌어내는 간접적인 재귀의 형태이다.(그러나 f1과 f2는 최종적으로는 종료하는 것이 확실해야 한다)
