[Paper Review] A Survey on Knowledge Graphs: Representation, Acquisition and Applications(KRL Part)

[KNOWLEDGE REPRESENTATION LEARNING]
A. Representation Space

1. Point-Wise Space
-
대표 모델 1 : TransE
h + r ≈ t:h에서r만큼 이동하면t근처에 와야 한다 -
대표 모델 2 : TransR
- TransE의 한계로 entity와 relation을 같은 공간에 넣는 것의 부족함을 지적
- entity 공간과 relation 공간을 분리
- entity
h,t는 , 관계r은 에 두고 projection matrix 로 entity를 관계 공간으로 투영
-
대표 모델 3 : NTN
- bilinear tensor neural layer를 써서 entity간의 relational interaction을 tensor로 포착
- TransE보다 더 복잡한 관계를 담고 싶을 때 쓰는 방향
head와tail의 복잡한 상호작용까지 보려는 방식
-
대표 모델 4 : HAKE
- 직교좌표계 대신 극좌표계를 사용해 semantic hierarchy를 잡음
- entity embedding을 modulus와 phase 부분으로 나눔
—
2. Complex Vector Space
- 실수 벡터 공간은 어떤 관계 성질을 표현하는데 약할 가능성이 있음
- 대표 모델 1 : ComplEx
- 복소수 공간에서
relation,head,tail를 조합해 대칭/반대칭 관계를 잡음
- 복소수 공간에서
- 대표 모델 2 : RotatE
- Euler identity를 바탕으로 ,
relation을 회전으로 보고t = h ο r처럼head를 complex space에서 회전시켜tail로 간다고 설명 - 공간이 복소수라서 회전이 가능
- inversion, composition, symmetry, antisymmetry도 잡을 수 있다고 설명
- Euler identity를 바탕으로 ,
- 대표 모델 3 : QuatE
- complex space를 더 확장한 hypercomplex / quaternion 공간으로 간다고 설명
- Hamilton product를 사용해서 더 풍부한 상호작용을 표현
—
3. Gaussian Distribution
- 불확실성을 담기 위한 공간
- KG2E가 entity와 relation을 점 하나가 아니라 다변량 Gaussian distribution으로 표현
- 평균 μ는 위치를, 공분산 ∑는 불확실성을 나타냄
- 평균 : “대략 어디 있는지”
- 공분산 : “얼마나 불확실한지?
- 불확실성, 다의성, 여러 의미 모드를 표현하고 싶을 때 쓰는 공간
- TransG
relation을 mixture of Gaussian으로 본다고 설명relation이 하나의 의미만 갖지 않고 여러 의미 모드를 가질 수 있을 때 유용
—
4. Manifold and Group
- 더 유연한 기하구조
- Point-Wise 모델이 어떤 경우엔 ill-posed이고, 빡빡한 기하구조에 갇힌다고 설명
- 해결방안으로 manifold space, Lie group, dihedral group같은 더 일반적인 공간 소개
- 공간 자체를 유연하게 바꿈
- 대표 모델 1 : ManifoldE
- point-wise embedding을 manifold-based embedding으로 확장하고 sphere와 hyperplane 두 가지 설정을 도입
- relation-specific parameter가 0이면 manifold가 다시 point로 붕괴
- 제약을 완화 → 표현력이 더 커짐
- 대표 모델 2 : Hyperbolic space / MuRP
- hyperbolic space가 hierarchical information을 잘 잡는다 설명
- MuRP가 Poincare ball 위에서 multi-relational KG를 표현
- 트리 구조, 계층 구조에 잘 맞음
- 위로 갈수록 크게 퍼지는 계층을 더 자연스럽게 담음
- 대표 모델 3 : TorusE
- n-차원 torus라는 compact Lie group 위에 임베딩해서, TransE의 regularization문제를 해결
- torus space에서도
[h] + [r] ≈ [t]같은 translation을 따름
- 대표 모델 4 : DihEdral
- DihEdral이 2차원 polygon을 보존하는 dihedral symmetry group을 제안
- 회전과 반사 같은 대칭군 구조를 이용해서 관계 패턴을 표현
B. Scoring Function
- A절에서 entity 와 relation을 어떤 공간에 놓을지 정했다면 B절에서는 어떤 triple이 맞는지 틀린지를 판단 → scoring function
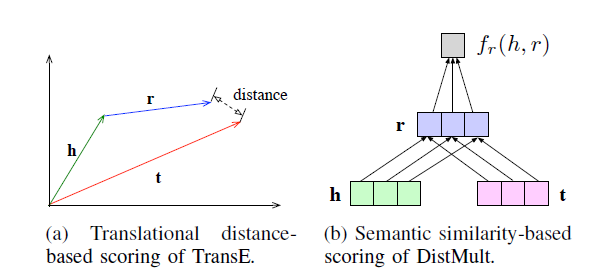
1. Distance-based Scoring Function
h에r을 적용했더니t에 가까워졌나?- 좋은 triple일수록 거리값이 작아지는 방향
- entity의 relational projection 사이 Euclidean distance를 계산하는 것
- SE(Structural Embedding) : 가장 기본적인 거리 기반 아이디어
head를relation용 행렬로 변환,tail도relation용 행렬로 변환 → L1 거리를 잰다
- TransE : 직관적
- translation-based scoring
relation을head에서tail로 가는 translation으로 봄h에서r만큼 이동하면t근처에 와야한다
- TransH
- hyperplane 위로 투영
- TransR
- entity 공간과
relation공간 분리
- entity 공간과
- TransD
- 동적 mapping matrix 사용
- TransA
- Euclidean distance 대신 Mahalanobis distance 사용
- TransF
- strict translation을 완화하고 dot product 사용
- ITransF
relation과 concept 사이 연관을 sparse attention으로 학습
- TransAt
relationattention 통합
- TransMS
- 다방향 semantics를 비선형 함수와 bias로 반영
- Distance-based의 단점
- 모든 관계를 이동으로 표현하는 게 충분하지 않을 수 있다
- 복잡한 의미적 상호작용은 잘 안잡힐 수 있다
—
2. Semantic Matching
h, r, t가 서로 잘 어울리는 조합인가?
- SME(Semantic Matching Energy)
(h,r)조합을 하나 만들고(r,t)조합을 하나 만든 뒤 둘이 얼마나 잘 맞는지 보는 방식
- DistMult
r아래서h와t가 차원별로 잘 맞는가?relation행렬을 대각행렬로 제한해서 단순화
- HolE
- circular correlation을 도입해 compressed tensor product처럼 해석
- circular correlation : 두 벡터를 합쳐서 새 벡터를 만듦
- full tensor는 무거워서 정보는 많이 담되 계산은 효율적으로 함
- circular correlation을 도입해 compressed tensor product처럼 해석
- ANALOGY
- multi-relational inference에 초점을 두고 relation matrix를 normal matrix로 제한
- 관계들 사이에 유추 가능한 패턴이 있다고 봄
- knowledge graph 안에도 비슷한 relational structure가 반복된다고 봄
- CrossE
- interaction matrix C를 사용해 entity와 relation 사이의 bi-directional interaction을 시뮬레이션
- relation에 따라 entity표현이 달라지고, entity에 따라 relation 효과도 달라짐
C. Encoding Models
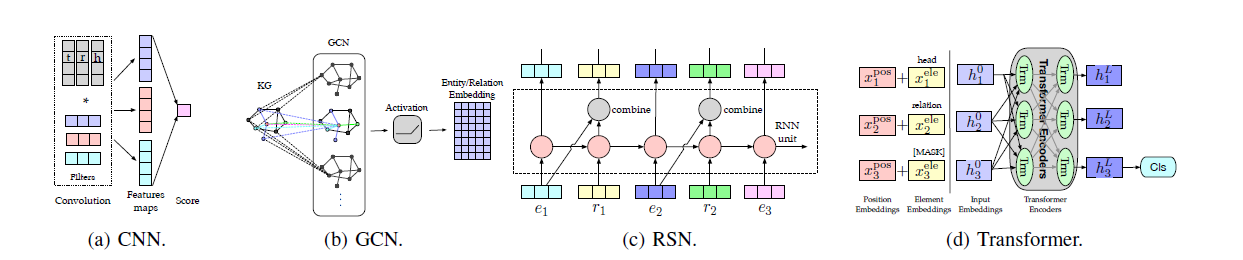
1. Linear/Bilinear Models
- entity와 relation의 상호작용을 선형 연산 또는 쌍선형 연산으로 encode한다고 설명
- relation이 head를 선형적으로 변환
- head와 tail사이 상호작용을 bilinear하게 계산
- linear(변환) : relation이 일종의 변환기 역할을 해서 head를 tail쪽으로 옮기거나 바꿈
- bilinear(궁합계산) : head와 tail이 relation 아래에서 얼마나 잘 맞는지 곱 형태로 계산
- 해석이 쉽고 계산이 비교적 안정적
- bilinear family 안에서 여러 모델들이 서로 제약조건에 따라 변환될 수 있다고 설명
- SimpIE : inverse relation을 도입해서 entity embedding 독립성 문제를 완화
—
2. Factorization Models
- 지식그래프를 텐서 분해 문제로 봄
- KRL을 three-way tensor decomposition으로 공식화
- knowledge graph를 triple목록으로 보지 말고, 거대한 3차원 배열(tensor)로 봄 ⇒ 큰 tensor를 더 작은 저차원 구조로 잘 분해해서, 숨어 있는 패턴을 찾음
- 구조가 수학적으로 깔끔하고 관계 데이터를 분해새서 해석하기 좋고 bilinear 계열과 연결되어 중요
- RESCAL
- relation마다 하나의 slice를 두고 분해하는 아주 대표적인 tensor factorization 모델
- TuckER
- 더 일반적인 tensor decomposition을 써서 entity와 relation을 더 유연하게 결합하는 모델
- LowFER
- TuckER을 일반화하면서도 low-rank approximation으로 계산 효율을 높이려는 방향
—
3. Neural Networks
- 신경망으로 semantic matching을 encode
- 비선형 활성화, 여러 층, 더 복잡한 feature 조합을 이용해서 entity와 relation의 관계를 더 풍부하게 학습
- 비선형 신경망을 이용해 entity와 relation의 복잡한 의미 상호작용을 직접 학습하는 방식
- MLP
- head, relation, tail을 이어 붙여서 fully connected layer에 넣고 점수를 계산
- NTN(Neural Tensor Network)
- relation tensor와 relation-specific weight matrix, bias를 같이 사용
- MLP와 bilinear model의 결합으로 볼 수 있음
- NAM
- hidden encoding을 tail embedding과 연결해서 관계 조절형 신경망(RMNN)을 제안한 모델
—
4. Convolutional Neural Networks(CNN)
- deep expressive features를 학습하는데 쓰임
- CNN이 원래 이미지에서 가까운 위치끼리의 패턴과 local feature를 잘 잡는 것을 활용해서 embedding안의 국소적인 상호작용 패턴을 잡음
- ConvE
- head와 relation을 2D로 reshape해서 convolution
- embedding을 이미지처럼 다룸
- h와 r을 나란히 붙이고 convolution filter로 훑으면서 의미 있는 local interaction feature를 뽑는 방식
- ConvKB
- reshape없이
[h, r, t]를 그대로 convolution - ConvE보다 local relation을 덜 강조하고, transitional characteristic을 유지하며 실험 성능이 좋음
- reshape없이
- HypER
- relation-specific 1D convolution filter를 hypernetwork로 생성
- tensor factorization 모델로도 해석 가능
—
5. Recurrent Neural Networks
- triple이 하나가 아니라, 경로(path)를 봄
- long-term relational dependencies를 포착
- entity와 relation을 번갈아 포함하는 path sequence를 random walk로 만들고, recurrent skip mechamism으로 relation과 entity를 구분해 semantic representation을 강화
- 순서가 있는 entity-relation sequence를 읽으면서 장기 의존성을 학습
- entity와 relation이 sequence 안에서 번갈아 등장한다는 KG 특성을 반영
- hidden state를 일반 RNN처럼 계사한 뒤, relation일 때는 skip mechanism을 적용
—
6. Transformers
- 텍스트 쪽에서 성공한 Transformers를 KG에 가져옴
- Transformers 기반 모델이 contextualized representation learning을 크게 끌어올림
- KG의 contextual information을 활용하기 위해 CoKE와 KG-BERT 같은 모델이 등장
- CoKE는 edge와 path sequence를 transformer로 encode하고, KG-BERT는 BERT를 entity와 relation의 encoder로 사용
- attention으로 전체 문맥을 한 번에 봄
- triple, path, edge sequence를 일종의 sequence처럼 보고, 그 안에서 각 요소가 서로 얼마나 중요한지 attention으로 학습
- 긴 문맥도 잘 보고 attention으로 중요 관계를 잡고 path/sequence 정보를 유연하게 인코딩
- CoKE
- triple을 sequence처럼 두고 한 entity를 [MASK]로 바꿔서 encode
- KG-BERT
- BERT를 그대로 entity/relation encoder 처럼 쓰는 방식
—
7. Graph Neural Networks(GNNs)
- 그래프 구조를 직접 쓰는 방식
- encoder-decoder framework 아래에서 connectivity structure를 학습하기 위해 도입
- 각 entity가 자기 이웃 entity와 relation로부터 메시지를 받아 표현을 업데이트
- 주변 이웃, relation 방향성, multi-hop neighborhood를 자연스럽게 반
- R-GCN
- propagation식을 제시하고 relation별 이웃 집합, relation별 weight matrix, self-loop weight. normalization을 사용
- relation type이 중요해서 어떤 relation으로 연결된 이웃인지에 따라 다른 변환을 적용해서 메시지를 모음
- SACN
- weighted GCN을 relation type이 같은 인전 노드 사이 강도를 정의하고, decoder로 Conv-TransE를 사용
- translational property도 유지
- 구조 정보와 translational decoder를 결합한 형태
- GAT / CompGCN
- GAT 기반 모델 : multi-head attention으로 multi-hop neighborhood를 더 잘 반영
- CompGCN : edge마다 entity-relation composition operation을 적용해서 더 일반적인 GCN 기반 모델로 확장
D. Embedding with Auxiliary Information
- 그래프 외부의 의미 단서를 KG 임베딩 안에 어떻게 섞을 것인가?
1. Textual Description → entity 설명 문장 활용
- textual descriptions ⇒ 단어열로 씀
- text는 entity의 supplementary semantic information을 줌
- 핵심 도전과제는 structured knowledge와 unstructured text를 같은 공간에 임베딩 하는 것
- text는 그래프가 말하지 못하는 의미를 보충해주는 정보
- entity 설명 문장을 이용해, 그래프 구조만으로 부족한 의미를 보완하고 text와 KG를 같은 임베딩 공간에 정렬
- Wang et al.
- entity space와 word space를 정렬하려고 함
- entity names와 Wikipedia anchors를 이용해 entity space와 word space를 맞추는 두 alignment model을 제안
- entity 임베딩 공간과 단어 임베딩 공간이 따로 놀지 않게 연결
- DKRL
- TransE를 확장해서 entity descriptions로 부터 직접 representation을 학습, convolutional encoder를 씀
- 텍스트 설명 문장을 CNN 같은 인코더에 넣어서 엔티티의 임베딩을 직접 만들거나 보완하는 방식
- SSP
- triple과 textual description 사이의 강한 상관을 포착하기 위해 둘을 semantic subspace에 투영
- triple과 text가 서로 의미적으로 잘 맞는 공간을 만듦
—
2. Type Information → 클래스/타입/계층 정보 활용
- entity가 보통 hierarchical classes or types로 표현됨
- relations도 따라서 semantic types를 가짐
- 의미적 제약 조건을 제공
- entity와 relation의 타입•계층 구조를 이용해, 더 의미적으로 일관된 임베딩과 타입 제약을 반영한 학습을 하려는 방법
- SSE
- semantic categories를 활용해서, 같은 category에 속한 entity들이 semantic space 안에서 부드럽게 임베딩되도록 만듦
- 의미적으로 정돈된 배치를 하도록 유도
- TKRL
- type encoder model을 제안해서 entity projection matrix가 type hierarchy를 포착
- 상위-하위 타입 구조까지 반영
- KR-EAR
- relation types를 attributes와 relations로 나누고, entity descriptions와의 상관을 모델링
- 어떤 relation은 진짜 관계이고, 어떤 건 속성처럼 볼 수 있음
- Zhang et al.
- relation clusters, relations, sub-relations의 hierarchical relation structure를 기존 임베딩 방법에 확장
- 관계 자체에도 계층이 있음
- ontology 감각과 아주 가까움
- entity type
- class hierarchy
- relation type
- sub-relation ⇒ ontology/schema 정보
- ontology적 구조를 임베딩에 녹이는 방향
—
3. Visual Information → entity 이미지 활용
- multi-modal
- entity image를 활용해, 그래프 구조만으로 부족한 시각적 의미를 임베딩에 추가하는 방법
- IKRL
- structure-based representation과 image-based representation을 함께 가지며, 이미지를 entity space로 인코딩하고 translation principle도 따름
- cross-modal representations가 구조 기반 표현과 이미지 기반 표현이 같은 representation space 안에 있도록 보장
- triple에서 온 임베딩과 image encoder에서 온 임베딩이 서로 같은 의미 공간에서 만나게 함
—
4. Uncertain Information → fact의 confidence, uncertainty 활용
- confidence score가 fact마다 붙어 있는 uncertain information이 있음
- uncertain embedding model은 relational facts의 likehood를 표현하는 uncertainty를 포착
- 사실의 진실값이 0/1로 딱 떨어지지 않고, 확률이나 신뢰도로 붙어 있음
- triple마다 붙은 confidence나 uncertainty를 함께 학습해서, 단순한 참/거짓이 아니라 사실의 신뢰도까지 반영하려는 방법
- Chen et al.
- structural information과 uncertainty information을 동시에 보존하고, probabilistic soft logic을 이용해 confidence score를 추론
- triple 구조는 그대로 보면서, 각 사실의 신뢰도까지 함께 임베딩
- Probability Calibration
- 예측 확률을 사후적으로 조정해서 확률적으로 말이 되게 만드는 후처리
- calibration은 모델 점수를 더 확률다운 값으로 보정하는 과정

감자애오