
요약
2주차의 주제는 네트워크이다. EKS에서 사용하는 CNI인 ENI의 장점과 실습을 통한 원리를 중점적으로 파악하였다. 이후 서비스, 로드밸런서, Ingress, External DNS, Istio로 이어지나 도메인을 구매하는 데 실패하여 External DNS 실습은 진행하지 못했다. (~5.8 진행예정) 화요일날 블로그 포스팅을 작성할 예정이었으나 컨디션이 안좋아서 속도가 안나와 토요일에 와서 포스팅을 했다. 한번에 진행한 실습이 아니다 보니, 자원을 재생성하는 과정에서 IP 등 여러 결과값이 앞과 뒤가 살짝 다를 수 있다.
이번 블로그에서 사용되는 용어를 정리해보면 다음과 같다.
- CNI(Container Network Interface)
- ENI(Elastic Network Interface)
: ec2 내부의 가상 네트워크 인터페이스, ec2에서 여러 개의 IP주소 사용가능 - Prefix Delegation
: 접두사 위임으로, 192.168.1.0/24와 같이 네트워크 대역을 확인하는 상위 비트 개수를 위임한다. - CIDR(Classless Inter-Domain Routing)
: 기존 클래스인 A,B,C 와 같이 고정적인 방법으로 네트워크 대역을 설정하는 것이 아닌 유연하게 네트워크 대역을 설정하는 방법
배포
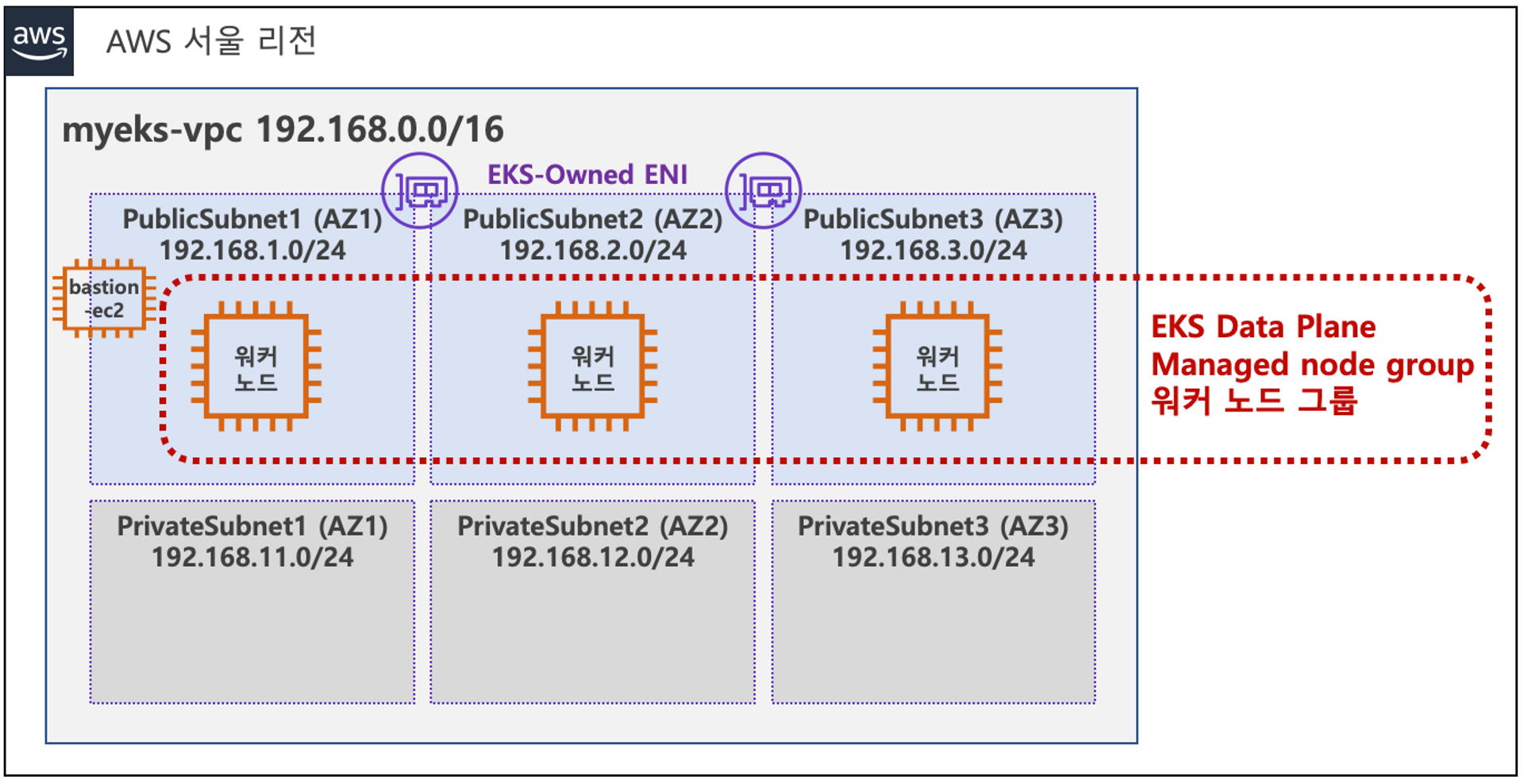
배포는 CloudNet 팀에서 준비해주신 원클릭 CloudFormation을 통해 진행했다. 관련 자료는 YAML부분을 참고하면 되고, ec2 type은 상황에 맞게 변경해주면 된다. 현재 기본값은 t3.medium 이나 추후 grafana 등 리소스가 많이 필요하면 타입을 상향하면 된다. 배포한 아키텍처는 다음과 같다. 가시다님이 친절하게 아래와 같이 설명까지 써주셨다.
사전 준비 : AWS 계정, SSH 키 페어, IAM 계정 생성 후 키
전체 구성도 : VPC 1개(퍼블릭 서브넷 3개, 프라이빗 서브넷 3개), EKS 클러스터(Control Plane), 관리형 노드 그룹(EC2 3대), Add-on
실습이 종료된 이후 아래의 명령어를 입력하면, 모든 자원을 삭제할 수 있다. EKS는 스탑기능이 없으니, 진행한 실습이 끝났다면 바로 삭제해줘야 비용을 최소화할 수 있다.
eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME
AWS VPC CNI
ENI 장점
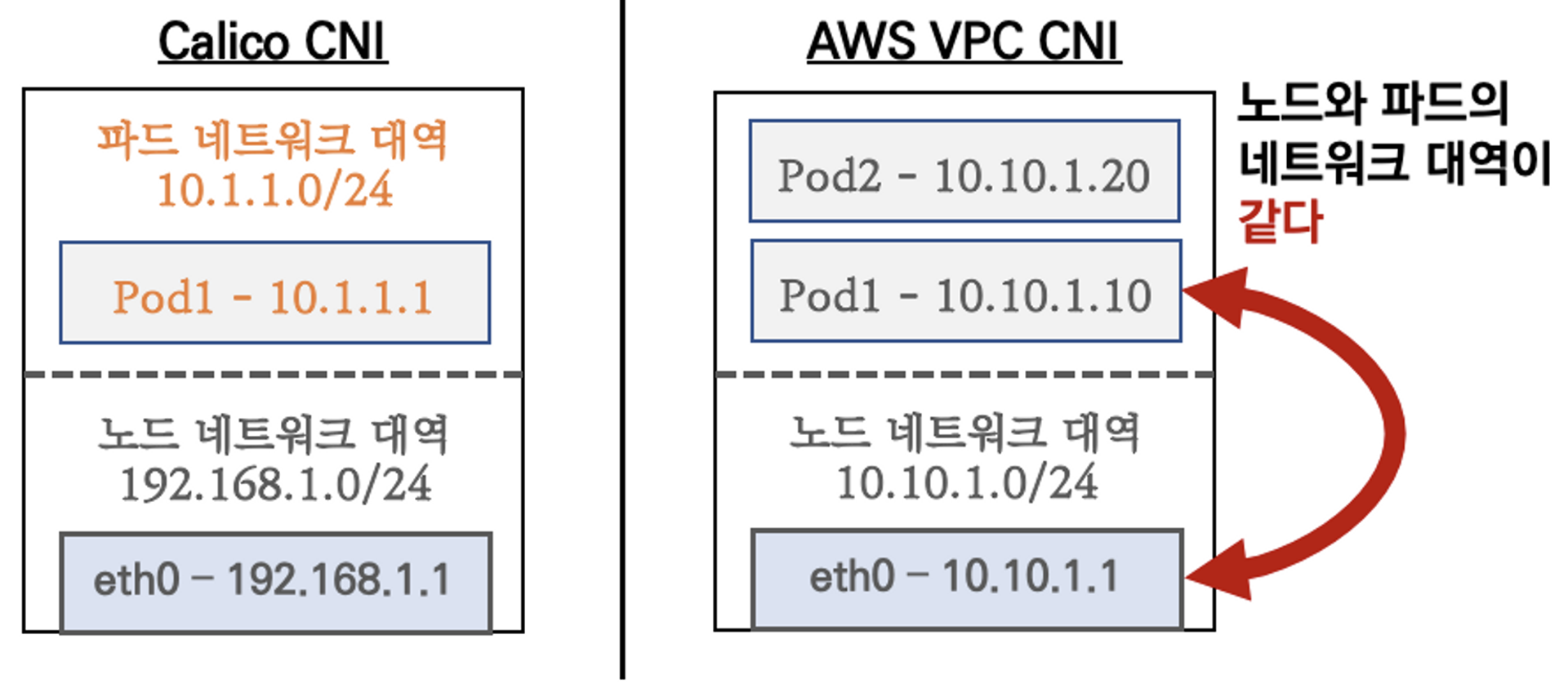
파드의 ip를 할당해준다. 해당 ip 대역은 노드의 ip 대역과 같아서 직접 통신이 가능하다는 장점이 있다. 직접 통신이 가능하다면, 중간에 IP를 적절하게 변경하는 연산이 필요없다. 이는 컴퓨팅 리소스를 아낄 수 있고 성능을 향상시킨다.
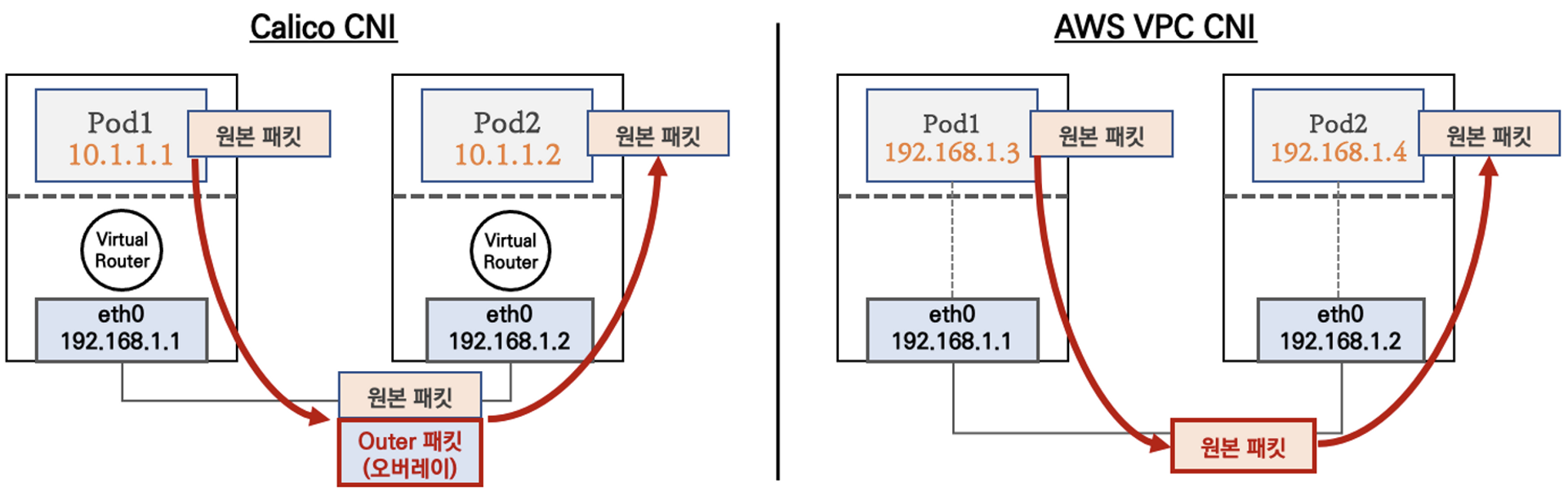
파드와 노드의 네트워크 대역이 같으면 오버레이과정을 안거쳐도 된다. 기존 패킷에 대한 업데이트 없이(연산) 그대로 전달할 수 있다.
최대 파드 개수
Amazon CNI에 대한 자세한 내용은 GitHub에서 확인할 수 있다. 문서를 확인하면 ENI의 기본주소를 노드의 IP로 설정하고, --max-pods 의 값을 the number of ENIs for the instance type × (the number of IPs per ENI - 1)) + 2 로 권장한다. 관련 이유를 살펴보면 네트워크의 안정성을 위해 제한을 두었다는 설명을 확인할 수 있고, 아래의 토글에서 각 인스턴스별 제한을 확인할 수 있다.
#현재 배포된 EKS의 max pods의 값 확인
$k describe node ip-192-168-1-139.ap-northeast-2.compute.internal
Name: ip-192-168-1-139.ap-northeast-2.compute.internal
...
Allocatable:
attachable-volumes-aws-ebs: 25
cpu: 1930m
ephemeral-storage: 27905944324
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3388364Ki
#17개임을 확인할 수 있다.
pods: 17
...현재의 인스턴스 타입은 t3.medium 이다. 연산은 3 * (6 - 1) + 2 = 17 이니 권장사항을 만족한 것을 확인할 수 있다.
최대 파드 개수
Amazon ENI에 대한 자세한 내용은 GitHub에서 확인할 수 있다. 문서를 확인하면 ENI의 기본주소를 노드의 IP로 설정하고, --max-pods 의 값을 the number of ENIs for the instance type × (the number of IPs per ENI - 1)) + 2 로 권장한다. 관련 이유를 살펴보면 네트워크의 안정성을 위해 제한을 두었다는 설명을 확인할 수 있다. 실습 코드 아래에 각 인스턴스별 제한을 확인할 수 있다.
계산식에 대해 구체적으로 알아보면, 2개의 파드를 추가하는 것은 기본적으로 node ip 와 동일한 aws-node , kube-proxy 파드를 의미한다. 또, ENI당 사용할 수 있는 IP에서 1을 빼는 것은 컨트롤플레인과 소통하기 위한 primary private IPv4 addresses 를 파드에서 사용할 수 없기 때문이다. 또한, 30vCPU미만은 110, 이외 모든 인스턴스는 250이 최대값으로 상한선이 정해져있다.
t3.medium 의 경우 ENI 마다 최대 6개의 IP를 가질 수 있다
- **"t3.medium": {ENILimit: 3, IPv4Limit: 6, HypervisorType:"nitro", IsBareMetal:false},**
현재의 인스턴스 타입은 t3.medium 이다. 연산은 3 * (6 - 1) + 2 = 17 이니 권장사항을 만족한 것을 확인할 수 있다.
직접 클러스터에서 관련된 정보를 확인해보면 다음과 같이 연산한 값과 일치하는 것을 볼 수 있다.
#현재 배포된 EKS의 max pods의 값 확인
$k describe node ip-192-168-1-139.ap-northeast-2.compute.internal
Name: ip-192-168-1-139.ap-northeast-2.compute.internal
...
Allocatable:
attachable-volumes-aws-ebs: 25
cpu: 1930m
ephemeral-storage: 27905944324
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3388364Ki
pods: 17
...
#17개임을 확인할 수 있다.아래는 AWS에서 소개한 ENI, IPv4의 최대개수와, 최대 파드의 수를 계산한 값이다.
var InstanceNetworkingLimits = map[string]InstanceTypeLimits{
...
"t1.micro": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"xen", IsBareMetal:false},
"t2.2xlarge": {ENILimit: 3, IPv4Limit: 15, HypervisorType:"xen", IsBareMetal:false},
"t2.large": {ENILimit: 3, IPv4Limit: 12, HypervisorType:"xen", IsBareMetal:false},
"t2.medium": {ENILimit: 3, IPv4Limit: 6, HypervisorType:"xen", IsBareMetal:false},
"t2.micro": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"xen", IsBareMetal:false},
"t2.nano": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"xen", IsBareMetal:false},
"t2.small": {ENILimit: 3, IPv4Limit: 4, HypervisorType:"xen", IsBareMetal:false},
"t2.xlarge": {ENILimit: 3, IPv4Limit: 15, HypervisorType:"xen", IsBareMetal:false},
"t3.2xlarge": {ENILimit: 4, IPv4Limit: 15, HypervisorType:"nitro", IsBareMetal:false},
"t3.large": {ENILimit: 3, IPv4Limit: 12, HypervisorType:"nitro", IsBareMetal:false},
"t3.medium": {ENILimit: 3, IPv4Limit: 6, HypervisorType:"nitro", IsBareMetal:false},
"t3.micro": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"nitro", IsBareMetal:false},
"t3.nano": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"nitro", IsBareMetal:false},
"t3.small": {ENILimit: 3, IPv4Limit: 4, HypervisorType:"nitro", IsBareMetal:false},
"t3.xlarge": {ENILimit: 4, IPv4Limit: 15, HypervisorType:"nitro", IsBareMetal:false},
"t3a.2xlarge": {ENILimit: 4, IPv4Limit: 15, HypervisorType:"nitro", IsBareMetal:false},
"t3a.large": {ENILimit: 3, IPv4Limit: 12, HypervisorType:"nitro", IsBareMetal:false},
"t3a.medium": {ENILimit: 3, IPv4Limit: 6, HypervisorType:"nitro", IsBareMetal:false},
"t3a.micro": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"nitro", IsBareMetal:false},
"t3a.nano": {ENILimit: 2, IPv4Limit: 2, HypervisorType:"nitro", IsBareMetal:false},
"t3a.small": {ENILimit: 2, IPv4Limit: 4, HypervisorType:"nitro", IsBareMetal:false},
"t3a.xlarge": {ENILimit: 4, IPv4Limit: 15, HypervisorType:"nitro", IsBareMetal:false},
...- 아래는 최대 파드의 개수를 계산한 결과이다.
...
t1.micro 4
t2.2xlarge 44
t2.large 35
t2.medium 17
t2.micro 4
t2.nano 4
t2.small 11
t2.xlarge 44
t3.2xlarge 58
t3.large 35
t3.medium 17
t3.micro 4
t3.nano 4
t3.small 11
t3.xlarge 58
t3a.2xlarge 58
t3a.large 35
t3a.medium 17
t3a.micro 4
t3a.nano 4
t3a.small 8
t3a.xlarge 58
...L-IPAM
L-IPAM은 노드별로 보조 IP 주소의 warm-pool을 유지한다. 파드를 하나 추가할 때마다, warm-pool에서 사용가능한 IP를 가져와 파드에 할당한다. GitHub에서 자세한 내용을 확인할 수 있다.
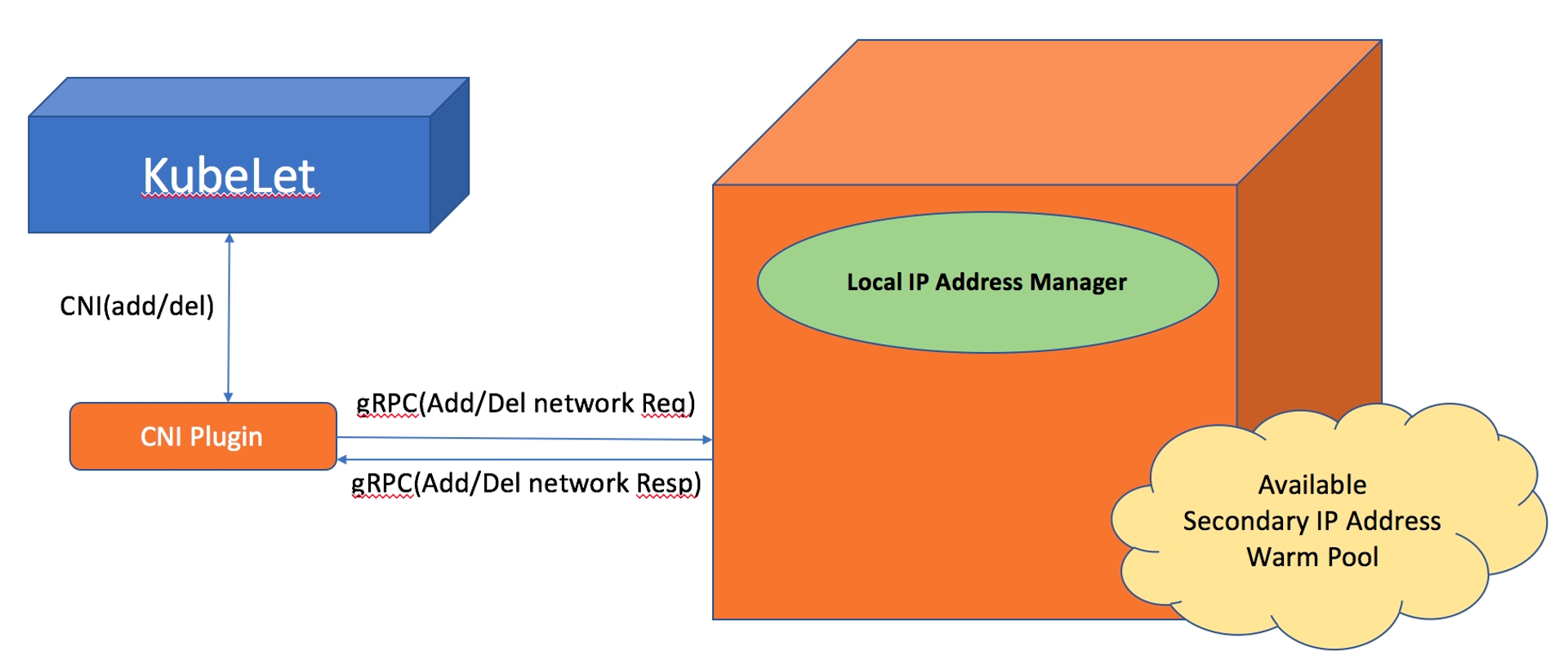
아래의 그림을 확인해보면, 파드를 생성하면 ENI의 남아있는 IP를 할당한다. 만약 IP가 부족하다면 새로운 ENI를 생성하고, IP를 부여한다. 모든 ENI와 IP를 소모하면, 파드는 생성되지 않고 Pending 상태가 된다. (아래의 실습에서 확인할 수 있다.)
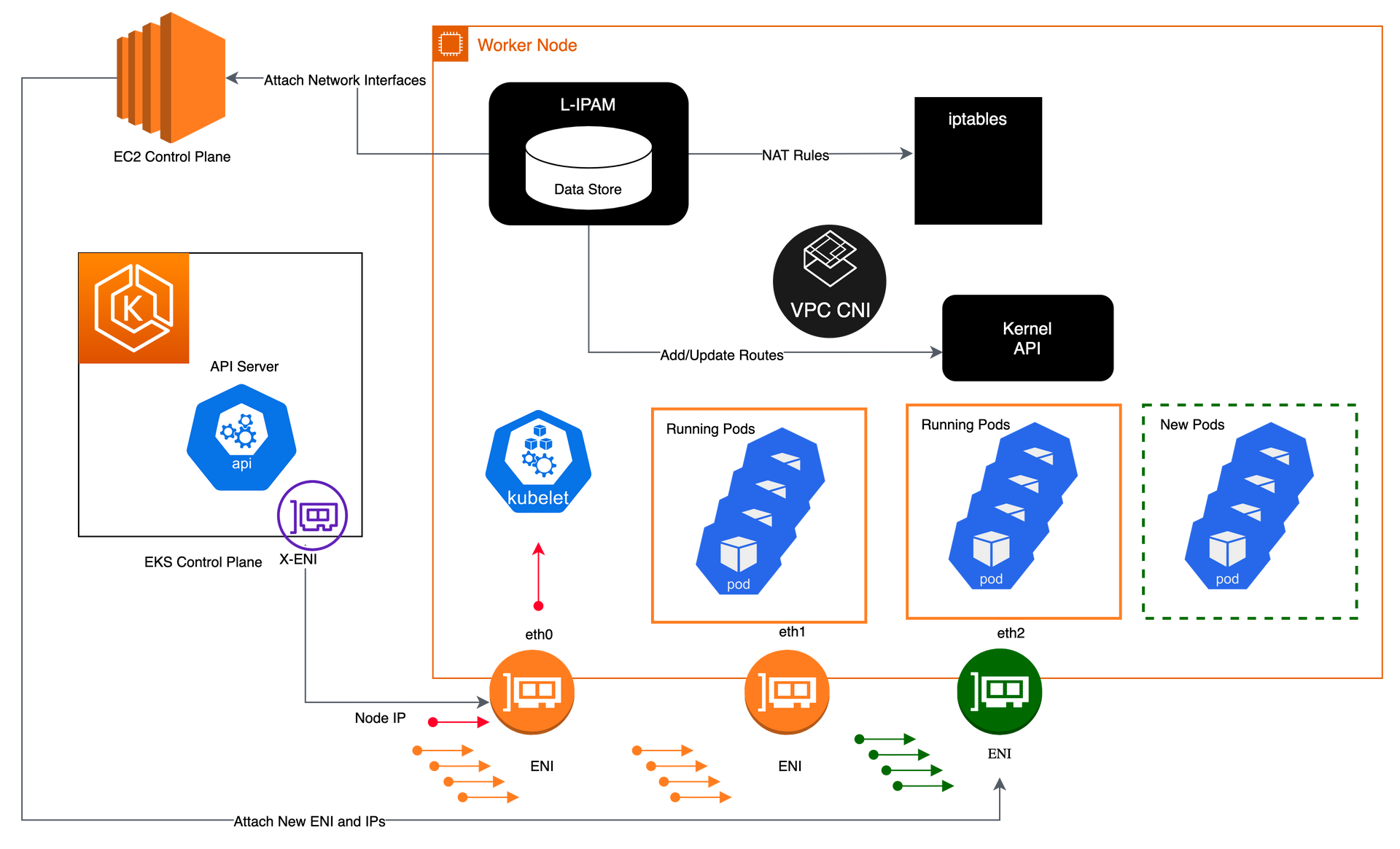
ifconfig 명령을 통해 eth(이더넷)을 확인해보면 cni는 aws-node kube-proxy 를 제외한 다른 파드를 배포하면 두번째 ENI를 생성하는 것을 확인할 수 있다. 또, 추가적으로 발생한 파드에 대해서는 모든 라이팅 테이블이 eni로 향하고 있다. 파드에 대한 접근이 들어오면 eni에게 할당되고 이를 pod에게 보낸다. 아래의 실습코드에서 coredns의 Ip : 192.168.1.29를 따라가보면 위의 내용을 확인할 수 있다.
#coredns private ip 확인
$k get po -A -o wide | grep coredns
...
coredns-6777fcd775-zg7dh 1/1 Running 0 73m **192.168.1.29** ip-192-168-1-197.ap-northeast-2.compute.internal <none> <none>
#node1 route 확인 - core dns 확인
$ssh ec2-user@$N1 sudo ip -c route
default via 192.168.1.1 dev eth0
169.254.169.254 dev eth0
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.197
**192.168.1.29** dev enic94a7bde5cd scope link
#eth0, eth1 확인
$ssh ec2-user@$N1 sudo ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9001
inet 192.168.1.197 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::29:7bff:fe12:5208 prefixlen 64 scopeid 0x20<link>
ether 02:29:7b:12:52:08 txqueuelen 1000 (Ethernet)
...
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9001
inet 192.168.1.154 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::60:2fff:fe79:3eb0 prefixlen 64 scopeid 0x20<link>
ether 02:60:2f:79:3e:b0 txqueuelen 1000 (Ethernet)
...
CNI 확인 및 kube-proxy 정보 확인
(iptables vs ipvs)
kube-proxy에서 iptables 모드를 사용하고 ipvs 모드를 사용하지 않는 이유는 다음과 같다. ipvs는 일부 CNI 플러그인, 네트워크 정책과 호환되지 않는다. 또, iptables 모드는 오랜 기간 쿠버네티스에서 사용되어 안정성을 인정받았다.
- iptables 는 kube-proxy가 테이블만 관리하고, 직접 트래픽을 전달하지 않는다. 테이블을 통해 트래픽이 전달된다.
- ipvs는 table과 비슷하지만 자동으로 LB가 적용된다.
# CNI 확인
$kubectl describe daemonset aws-node --namespace kube-system | grep Image | cut -d "/" -f 2
amazon-k8s-cni-init:v1.12.6-eksbuild.1
amazon-k8s-cni:v1.12.6-eksbuild.1
# kube-proxy config 확인: iptables 모드 사용!(가장 하단 참고)
$kubectl describe cm -n kube-system kube-proxy-configData
====
config:
----
apiVersion: kubeproxy.config.k8s.io/v1alpha1
...
iptables:
masqueradeAll: false
masqueradeBit: 14
minSyncPeriod: 0s
syncPeriod: 30s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0:10249
mode: "iptables"
...ENI 통신 확인
이제 ENI의 작동방식에 대해 실습을 해봤다.
노드에 파드를 배포시키고 모니터링 해보기
#노드에 접속
$ssh ec2-user@$N1
#모니터링 시작(처음에는 2번과 route table의 첫번째줄이 없었으나 파드 배포 후 형성
$watch -d "ip link | egrep 'eth|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 02:29:7b:12:52:08 brd ff:ff:ff:ff:ff:ff
3: enic94a7bde5cd@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP mode DEFAULT group default
link/ether 9a:0f:49:8e:c9:2a brd ff:ff:ff:ff:ff:ff link-netns cni-d14dc09b-32af-693a-8b24-9cda5de41e29
4: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 02:60:2f:79:3e:b0 brd ff:ff:ff:ff:ff:ff
[ROUTE TABLE]
192.168.1.29 0.0.0.0 255.255.255.255 UH 0 0 0 enic94a7bde5cd
## ==================================배포 후============================================================================================
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 02:29:7b:12:52:08 brd ff:ff:ff:ff:ff:ff
3: enic94a7bde5cd@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP mode DEFAULT group default
link/ether 9a:0f:49:8e:c9:2a brd ff:ff:ff:ff:ff:ff link-netns cni-d14dc09b-32af-693a-8b24-9cda5de41e29
4: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 02:60:2f:79:3e:b0 brd ff:ff:ff:ff:ff:ff
5: eni49834a7b0d4@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP mode DEFAULT group default
link/ether 86:cd:5e:33:6f:52 brd ff:ff:ff:ff:ff:ff link-netns cni-9f690975-044d-b0d3-2307-1b8f380ead02
[ROUTE TABLE]
192.168.1.10 0.0.0.0 255.255.255.255 UH 0 0 0 eni49834a7b0d4
192.168.1.29 0.0.0.0 255.255.255.255 UH 0 0 0 enic94a7bde5cd
# 핑을 보낼 파드의 IP 확인
$echo $PODIP1, $PODIP2
192.168.3.186, 192.168.2.79
#파드 통신 확인(첫번째 파드에서 두번째 파드로 핑 테스트)
$kubectl exec -it $PODNAME1 -- ping -c 2 $PODIP2
PING 192.168.2.79 (192.168.2.79) 56(84) bytes of data.
64 bytes from 192.168.2.79: icmp_seq=1 ttl=62 time=1.78 ms
64 bytes from 192.168.2.79: icmp_seq=2 ttl=62 time=1.28 ms
--- 192.168.2.79 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 1.275/1.529/1.784/0.254 ms
#워커노드에 접근
$ssh ec2-user@$N2
#아래의 결과를 통해 파드끼리 통신이 잘 이뤄짐을 확인할 수 있음
$sudo tcpdump -i any -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
17:49:33.973818 IP 192.168.3.186 > 192.168.2.79: ICMP echo request, id 24336, seq 1, length 64
17:49:33.973867 IP 192.168.3.186 > 192.168.2.79: ICMP echo request, id 24336, seq 1, length 64
17:49:33.973886 IP 192.168.2.79 > 192.168.3.186: ICMP echo reply, id 24336, seq 1, length 64
17:49:33.973897 IP 192.168.2.79 > 192.168.3.186: ICMP echo reply, id 24336, seq 1, length 64
17:49:34.975715 IP 192.168.3.186 > 192.168.2.79: ICMP echo request, id 24336, seq 2, length 64
17:49:34.975755 IP 192.168.3.186 > 192.168.2.79: ICMP echo request, id 24336, seq 2, length 64
17:49:34.975775 IP 192.168.2.79 > 192.168.3.186: ICMP echo reply, id 24336, seq 2, length 64
17:49:34.975785 IP 192.168.2.79 > 192.168.3.186: ICMP echo reply, id 24336, seq 2, length 64
#아래의 명령어를 통해 나가는 패킷만 확인할 수 있다. 관련 파드는 cni1이 아니지만 eth0을 통해 빠져나간다.
$sudo tcpdump -i eth0 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
17:51:55.080619 IP 192.168.3.186 > 192.168.2.79: ICMP echo request, id 831, seq 1, length 64
17:51:55.080805 IP 192.168.2.79 > 192.168.3.186: ICMP echo reply, id 831, seq 1, length 64
17:51:56.082608 IP 192.168.3.186 > 192.168.2.79: ICMP echo request, id 831, seq 2, length 64
17:51:56.082658 IP 192.168.2.79 > 192.168.3.186: ICMP echo reply, id 831, seq 2, length 64
$ip route show table main
default via 192.168.2.1 dev eth0
169.254.169.254 dev eth0
192.168.2.0/24 dev eth0 proto kernel scope link src 192.168.2.251
192.168.2.79 dev eni96ea53d0c48 scope link
192.168.2.172 dev eni7c48f16dc91 scope link
#파드와 외부의 통신
$kubectl exec -it $PODNAME2 -- ping -c 1 www.google.com
PING www.google.com (142.250.198.4) 56(84) bytes of data.
64 bytes from nrt12s58-in-f4.1e100.net (142.250.198.4): icmp_seq=1 ttl=104 time=33.0 ms
--- www.google.com ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 32.989/32.989/32.989/0.000 ms
$sudo tcpdump -i any -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
17:56:18.262417 IP 192.168.2.79 > 142.250.198.4: ICMP echo request, id 1979, seq 1, length 64
17:56:18.262441 IP 192.168.2.251 > 142.250.198.4: ICMP echo request, id 43010, seq 1, length 64
17:56:18.295356 IP 142.250.198.4 > 192.168.2.251: ICMP echo reply, id 43010, seq 1, length 64
17:56:18.295398 IP 142.250.198.4 > 192.168.2.79: ICMP echo reply, id 1979, seq 1, length 64
#파드가 외부와의 통신에서 사용하는 IP추적
$kubectl exec -it $PODNAME2 -- curl -s ipinfo.io/ip ; echo
15.164.179.105
#아래는 워커노드에 접속하여 실행한 명령어다. 현재의 Public ip값을 받으며 위와 동일한 것을 확인할 수 있다.
$curl -s ipinfo.io/ip ; echo
15.164.179.105
# 핑을 외부로 보낼 때는 아래와 같은 룰에 의해 SNAT 192.168.2.143(Worker node IP)변경되어 나간다!
sudo iptables -t nat -S | grep 'A AWS-SNAT-CHAIN'
#첫번째 규칙은 목적지 주소가 192.168.0.0/16 : 즉 같은 VPC가 아닌경우 AWS-SNAT-CHAIN-1로 점프하도록 한다.
-A AWS-SNAT-CHAIN-0 ! -d 192.168.0.0/16 -m comment --comment "AWS SNAT CHAIN" -j AWS-SNAT-CHAIN-1
#두번째 규칙은 외부로 향하는 트래픽을 노드의 IP로 변경시키는 것이다.
-A AWS-SNAT-CHAIN-1 ! -o vlan+ -m comment --comment "AWS, SNAT" -m addrtype ! --dst-type LOCAL -j SNAT --to-source **192.168.2.143** --random-fully
노드의 최대 파드개수 생성
해당 실습은 이전에 계산한 최대 파드의 수보다 많은 파드를 배포했을 때, 클러스터 내부에서 어떤 일이 발생하는 지 확인해봤다.
#파드모니터링
$watch -d 'kubectl get pods -o wide'
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6fb79bc456-4sjqf 1/1 Running 0 47s 192.168.1.238 ip-192-168-1-197.ap-northeast-2.compute.internal <none> <none>
nginx-deployment-6fb79bc456-wq4qc 1/1 Running 0 47s 192.168.3.122 ip-192-168-3-163.ap-northeast-2.compute.internal <none> <none>
#파드의 개수를 50개로 늘리자. 생성되지 못하는 파드가 보인다.(최대 개수 초과)
$kubectl get pods | grep Pending
nginx-deployment-6fb79bc456-2lvh9 0/1 Pending 0 8s
nginx-deployment-6fb79bc456-6sdq8 0/1 Pending 0 8s
nginx-deployment-6fb79bc456-9ctj5 0/1 Pending 0 8s
nginx-deployment-6fb79bc456-jcqvg 0/1 Pending 0 8s
nginx-deployment-6fb79bc456-lr7sl 0/1 Pending 0 8s
nginx-deployment-6fb79bc456-rmnw7 0/1 Pending 0 8s
nginx-deployment-6fb79bc456-xsfpx 0/1 Pending 0 8s관련 워커노드의 ip addr 모니터링한 결과는 아래와 같다. 15개의 eni가 존재하는 것을 확인할 수 있다. aws-node, kube-proxy를 포함하면 총 17개의 파드이며 이는 최대 개수와 동일함을 확인할 수 있다.
$while true; do ip -br -c addr show && echo "--------------" ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; done
2023-05-05 18:09:01
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.1.197/24 fe80::29:7bff:fe12:5208/64
enic94a7bde5cd@if3 UP fe80::980f:49ff:fe8e:c92a/64
eth1 UP 192.168.1.154/24 fe80::60:2fff:fe79:3eb0/64
enib263aee3e3a@if3 UP fe80::9801:86ff:fee0:94fe/64
enid3487d875d4@if3 UP fe80::c889:d4ff:fe33:a24d/64
eni9030418a3ff@if3 UP fe80::249c:ceff:fe41:3180/64
enib68b149b26a@if3 UP fe80::689b:ecff:fee3:8f58/64
enie5050516bf9@if3 UP fe80::98f2:83ff:fe1d:33ea/64
eth2 UP 192.168.1.84/24 fe80::d6:b0ff:fe9f:74e/64
eni161f9a2e0c7@if3 UP fe80::cc2d:24ff:fe37:aa90/64
eni70a8a75bf6a@if3 UP fe80::6084:5ff:fe5a:5bd6/64
eni34a852be90e@if3 UP fe80::40d9:f6ff:fe23:3635/64
eni04149b80833@if3 UP fe80::283f:6eff:feb3:3c8f/64
eni36442fb5871@if3 UP fe80::4c83:fdff:fe07:621e/64
enia7a957f74d7@if3 UP fe80::98c1:4ff:fe7b:c1/64
eni4952364d6e6@if3 UP fe80::b81a:ecff:fe34:9a01/64
enid486e2f5d72@if3 UP fe80::acf4:5dff:fe1a:a6b9/64
enib05a29aaa90@if3 UP fe80::3055:93ff:feb4:ae3a/64
#파드의 오류 메세지 ( Too many pods.) 를 확인할 수 있다.
$k describe po nginx-deployment-6fb79bc456-2lvh9
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 4m20s default-scheduler 0/3 nodes are available: 3 Too many pods. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.추가적으로 최대 파드 허용
네트워크 인터페이스에 접두사 할당 기능이 생김으로, 더 많은 IP주소를 활용하여 최대 파드의 개수를 늘릴 수 있다. 관련된 내용은 YongTrans에서 확인할 수 있다.
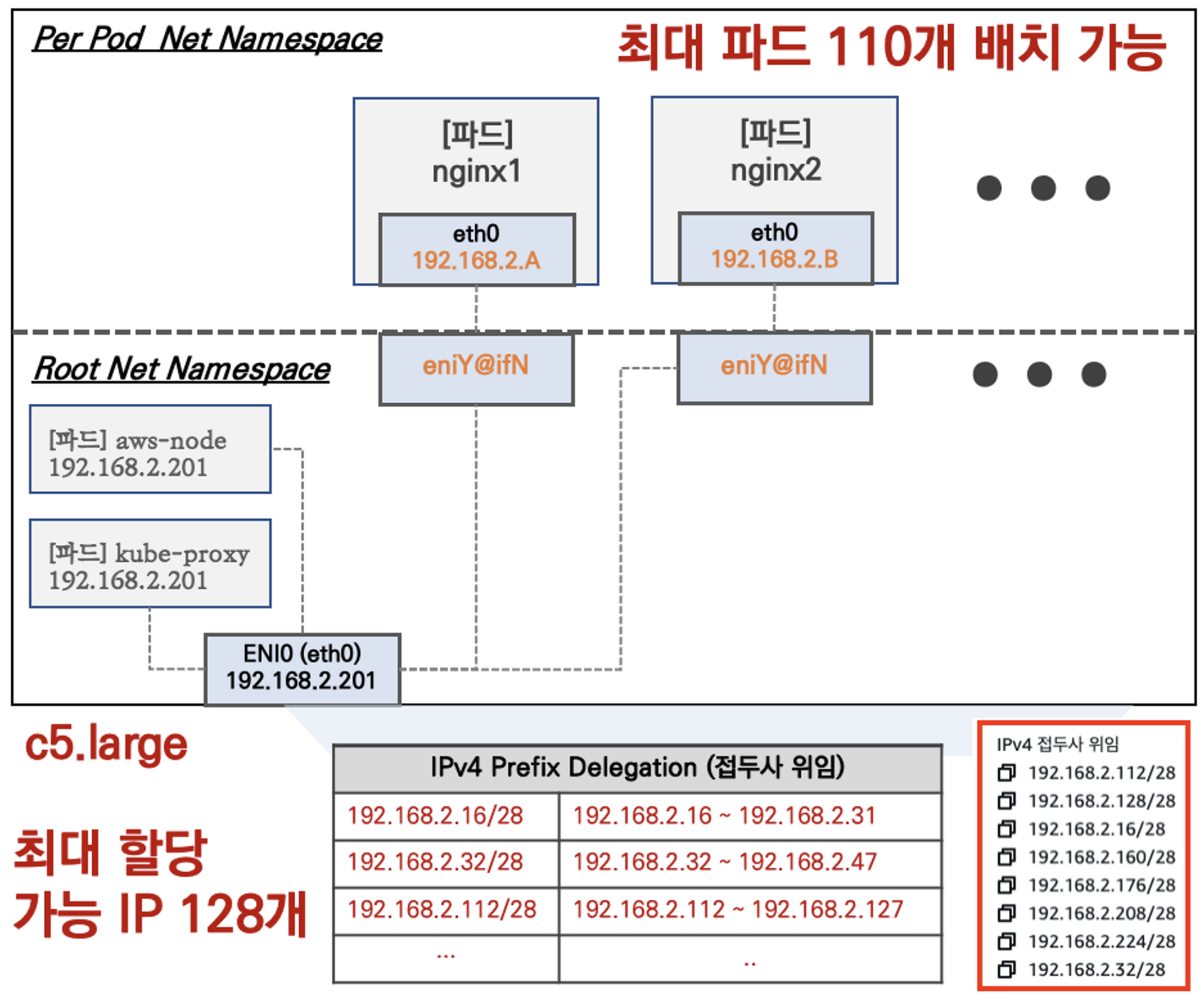
관련 내용 또한 추후에 실습할 예정이다..
실습을 진행하기 위해 관련 예제를 물어봤다. chat gpt의 답변이다. CIDR과 다른 네트워크 대역을 추가로 할당하여 노드에게 더 많은 IP주소를 부여하는 방식이다. 위의 사이트에서는 네트워크 인터페이스에 할당하지만, 여기서는 CIDR의 범위자체를 늘리는 방법을 소개해준다.

서비스
이제 ENI가 아닌 서비스에 대한 내용을 진행한다. 서비스는 파드의 IP가 바뀔 확률이 높기 때문에 고정적인 virtual IP를 만들어주는 역할을 한다. Clutser IP, Node Port 등 다양한 종류가 있지만 여기서는 로드밸런서에 대해 구체적으로 알아봤다.
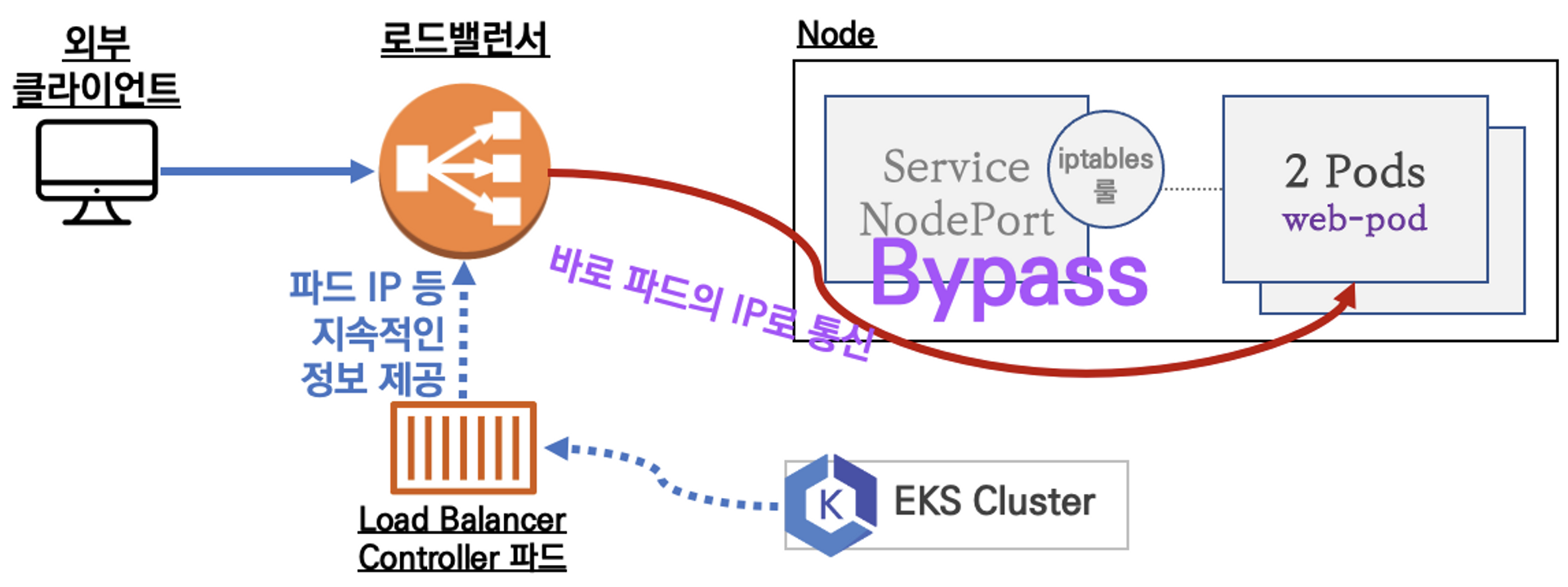
그림과 같이 EKS에서는 바로 연결이 가능하다.contrack & iptable 등 여러 작업을 건너뛸 수 있다. 이제 관련 실습을 통해 더 자세히 알아보자.
Load Balancer Controller
먼저 LB 연결하는 방법은 다음과 같다. 자세한 내용은 Docs에서 확인할 수 있다.
방법은 다음과 같은 순서로 이뤄진다.
1. IAM
- 정책 생성 : AWS Load Balancer Controller에 대한 IAM 정책 다운로드
- 역할 생성 : eksctl create iamserviceaccount ~
2. 배포
- helm 차트 : public.ecr.aws/eks/aws-load-balancer-controller:v2.4.7 ecr 이용
#OIDC(OpenID Connect) 이슈어 정보를 가져오는 명령어로, 얻은 URL을 통해 클러스터 인증 및 권한 부여,
#AWS IAM에 대한 제어를 할 수 있다.
$aws eks describe-cluster --name $CLUSTER_NAME --query "cluster.identity.oidc.issuer" --output text
https://oidc.eks.ap-northeast-2.amazonaws.com/id/73F304C1D2..F6B0692B444F
#로브드밸런서 컨트롤러에 대한 IAM 정책을 다운받는다.
$curl -o iam_policy.json https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.4.7/docs/install/iam_policy.json
#정책 생성 및 연결
$eksctl create iamserviceaccount --cluster=$CLUSTER_NAME --namespace=kube-system --name=aws-load-balancer-controller \
> --attach-policy-arn=arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --override-existing-serviceaccounts --approve
...
2023-05-06 11:33:48 [ℹ] 1 task: {
2 sequential sub-tasks: {
create IAM role for serviceaccount "kube-system/aws-load-balancer-controller",
create serviceaccount "kube-system/aws-load-balancer-controller",
} }2023-05-06 11:33:48 [ℹ] building iamserviceaccount stack "eksctl-myeks-addon-iamserviceaccount-kube-system-aws-load-balancer-controller"
...
#생성 결과 확인
$eksctl get iamserviceaccount --cluster $CLUSTER_NAME
NAMESPACE NAME ROLE ARN
kube-system aws-load-balancer-controller arn:aws:iam::1234567890:role/eksctl-myeks-addon-iamserviceaccount-kube-sy-Role1-RZW
# EKS LB helm 차트 배포
$helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
> --set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
NAME: aws-load-balancer-controller
LAST DEPLOYED: Sat May 6 11:34:52 2023
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
AWS Load Balancer controller installed!
#CustomResourceDefinition CRD 조회
$k get crd
NAME CREATED AT
eniconfigs.crd.k8s.amazonaws.com 2023-05-06T01:24:19Z
ingressclassparams.elbv2.k8s.aws 2023-05-06T02:34:50Z
securitygrouppolicies.vpcresources.k8s.aws 2023-05-06T01:24:22Z
targetgroupbindings.elbv2.k8s.aws 2023-05-06T02:34:50Z
# SA(service account) 조회
$k get sa -A | grep load-balancer
kube-system aws-load-balancer-controller 0 42m
이제 관련 서비스를 배포하고 이를 모니터링하는 과정을 진행했다. yaml 파일 등은 모두 스터디에서 제공해주었다. 먼저, 배포를 진행하고, 로드밸런서의 호스트네임을 파악하여 접근해본다. 또 노드의 tcp dump 를 확인하여 통신방식을 점검한다.
# LB 서비스를 배포
$cat echo-service-nlb.yaml | yh
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-echo
spec:
replicas: 2
selector:
matchLabels:
app: deploy-websrv
template:
metadata:
labels:
app: deploy-websrv
spec:
terminationGracePeriodSeconds: 0
containers:
- name: akos-websrv
image: k8s.gcr.io/echoserver:1.5
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: svc-nlb-ip-type
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8080"
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: "true"
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
type: LoadBalancer
loadBalancerClass: service.k8s.aws/nlb
selector:
app: deploy-websrv
#모니터링 결과 배포된 것을 확인할 수 있음.
Every 2.0s: kubectl get pod,svc,ep Sat May 6 12:21:46 2023
NAME READY STATUS RESTARTS AGE
pod/deploy-echo-5c4856dfd6-jg9hp 1/1 Running 0 4m4s
pod/deploy-echo-5c4856dfd6-pq889 1/1 Running 0 4m4s
NAME TYPE CLUSTER-IP EXTERNAL-IP
PORT(S) AGE
service/kubernetes ClusterIP 10.100.0.1 <none>
443/TCP 117m
service/svc-nlb-ip-type LoadBalancer 10.100.75.117 k8s-default-svcnlbip-2a2f74cdb7-c4a4d94160e4fb86.elb.ap-northeast-2.amazonaw
s.com 80:30432/TCP 4m4s
NAME ENDPOINTS AGE
endpoints/kubernetes 192.168.2.54:443,192.168.3.42:443 117m
endpoints/svc-nlb-ip-type 192.168.1.175:8080,192.168.2.212:8080 4m4s
#LB 서비스 호스트 네임 파악
$kubectl get svc svc-nlb-ip-type -o jsonpath={.status.loadBalancer.ingress[0].hostname} | awk '{ print "Pod Web URL = http://"$1 }'
Pod Web URL = http://k8s-default-svcnlbip-2a2f74cdb7-c4a4d94160e4fb86.elb.ap-northeast-2.amazonaws.com
#로드 밸런싱이 정상적으로 이뤄지고 있는 지 확인
$for i in {1..100}; do curl -s $NLB | grep Hostname ; done | sort | uniq -c | sort -nr
51 Hostname: deploy-echo-5c4856dfd6-jg9hp
49 Hostname: deploy-echo-5c4856dfd6-pq889
#노드의 TCP dump 에는 기록이 안나옴 : NLB에서 파드로 직접 통신하기 때문에
$sudo tcpdump -i any -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes아래는 LB Hostname으로 접근한 결과이다. 보는 것과 같이, 로드밸런싱이 잘 이뤄지는 것을 확인할 수 있고, 파드의 개수를 늘리거나 줄여도 스스로 잘 찾아서 이뤄진다. 트래픽이 들어오면 가용영역에 있는 파드 중에 이용가능한 파드를 찾아 부하를 분산한다.
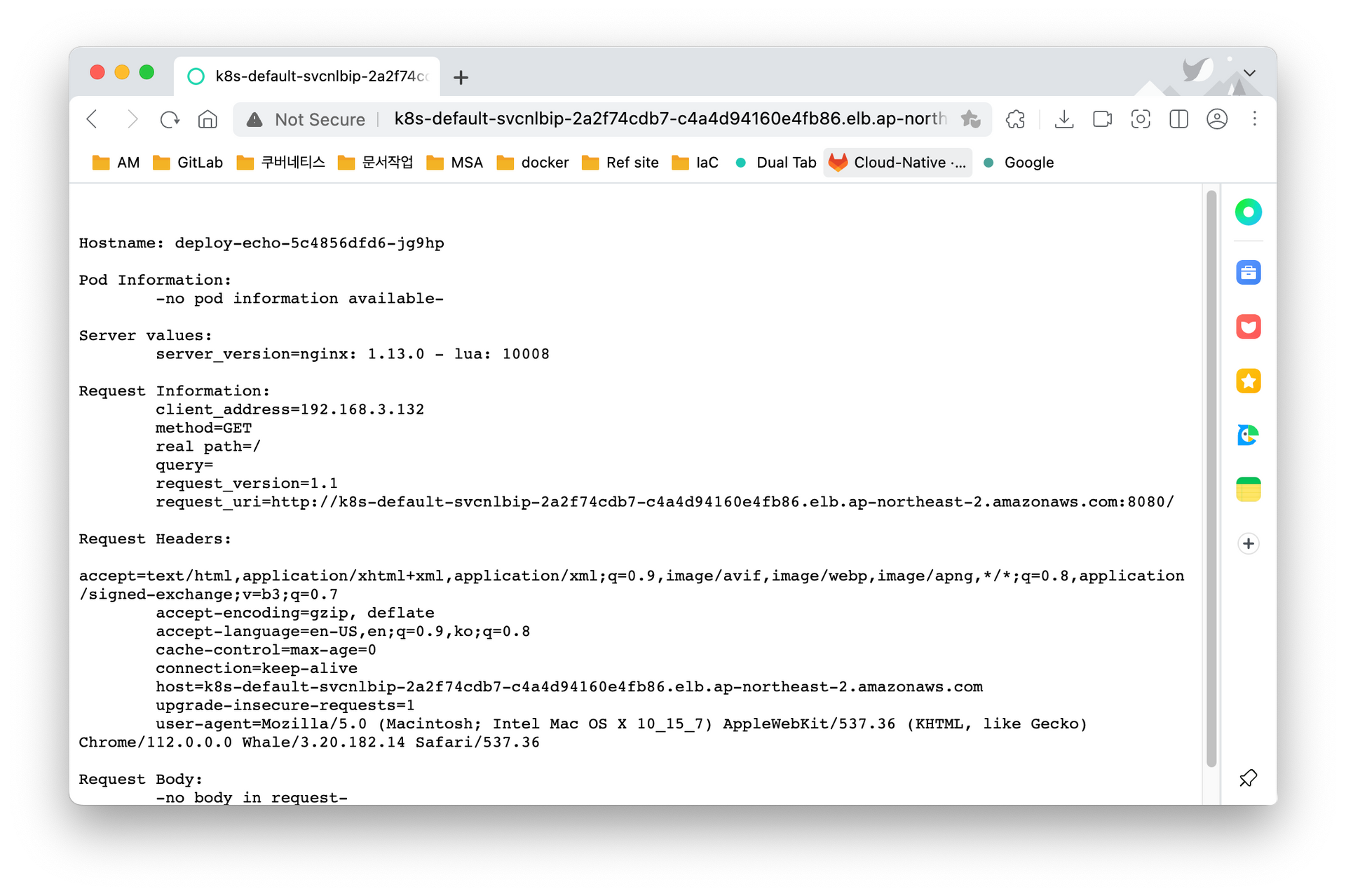
아래의 그림에서 가용영역을 확인해볼 수 있다. 1개의 파드만 존재해도 아래의 로그와 같이, 지속적으로 가능한 가용영역에서 가능한 파드가 있는 지 찾는 것을 확인할 수 있었다.
----------
2023-05-06 12:50:39
Hostname: deploy-echo-5c4856dfd6-jg9hp
client_address=192.168.1.95
----------
2023-05-06 12:50:40
Hostname: deploy-echo-5c4856dfd6-jg9hp
client_address=192.168.3.132
----------
2023-05-06 12:50:41
Hostname: deploy-echo-5c4856dfd6-jg9hp
client_address=192.168.2.61
이제 관련 룰을 확인해보자. 어떤 리소스를 접근할 수 있는 지, verbs를 통해 허락된 연산을 확인할 수 있다.
##롤 확인
$kubectl describe clusterroles.rbac.authorization.k8s.io aws-load-balancer-controller-role
Name: aws-load-balancer-controller-role
Labels: app.kubernetes.io/instance=aws-load-balancer-controller
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=aws-load-balancer-controller
app.kubernetes.io/version=v2.5.1
helm.sh/chart=aws-load-balancer-controller-1.5.2
Annotations: meta.helm.sh/release-name: aws-load-balancer-controller
meta.helm.sh/release-namespace: kube-system
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
targetgroupbindings.elbv2.k8s.aws [] [] [create delete get list patch update watch]
events [] [] [create patch]
ingresses [] [] [get list patch update watch]
services [] [] [get list patch update watch]
ingresses.extensions [] [] [get list patch update watch]
services.extensions [] [] [get list patch update watch]
ingresses.networking.k8s.io [] [] [get list patch update watch]
services.networking.k8s.io [] [] [get list patch update watch]
endpoints [] [] [get list watch]
namespaces [] [] [get list watch]
nodes [] [] [get list watch]
pods [] [] [get list watch]
endpointslices.discovery.k8s.io [] [] [get list watch]
ingressclassparams.elbv2.k8s.aws [] [] [get list watch]
ingressclasses.networking.k8s.io [] [] [get list watch]
ingresses/status [] [] [update patch]
pods/status [] [] [update patch]
services/status [] [] [update patch]
targetgroupbindings/status [] [] [update patch]
ingresses.elbv2.k8s.aws/status [] [] [update patch]
pods.elbv2.k8s.aws/status [] [] [update patch]
services.elbv2.k8s.aws/status [] [] [update patch]
targetgroupbindings.elbv2.k8s.aws/status [] [] [update patch]
ingresses.extensions/status [] [] [update patch]
pods.extensions/status [] [] [update patch]
services.extensions/status [] [] [update patch]
targetgroupbindings.extensions/status [] [] [update patch]
ingresses.networking.k8s.io/status [] [] [update patch]
pods.networking.k8s.io/status [] [] [update patch]
services.networking.k8s.io/status [] [] [update patch]
targetgroupbindings.networking.k8s.io/status [] [] [update patch]
#롤 바인딩 확인
$kubectl describe clusterrolebindings.rbac.authorization.k8s.io aws-load-balancer-controller-rolebinding
Name: aws-load-balancer-controller-rolebinding
Labels: app.kubernetes.io/instance=aws-load-balancer-controller
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=aws-load-balancer-controller
app.kubernetes.io/version=v2.5.1
helm.sh/chart=aws-load-balancer-controller-1.5.2
Annotations: meta.helm.sh/release-name: aws-load-balancer-controller
meta.helm.sh/release-namespace: kube-system
Role:
Kind: ClusterRole
Name: aws-load-balancer-controller-role
Subjects:
Kind Name Namespace
---- ---- ---------
ServiceAccount aws-load-balancer-controller kube-systemIngress
이제 Ingress를 통한 게임배포를 진행한다. Ingress는 클러스터 내부의 서비스(ClusterIP, NodePort, Loadbalancer)를 외부로 노출(HTTP/HTTPS) - Web Proxy 역할이다.
# 배포
$kubectl apply -f ingress1.yaml
namespace/game-2048 created
deployment.apps/deployment-2048 created
service/service-2048 created
ingress.networking.k8s.io/ingress-2048 created
#관련 yaml 파일의 내용을 확인하면
cat ingress1.yaml | yh
...
---
apiVersion: apps/v1
kind: Deployment
...
spec:
containers:
# 2048에 대한 이미지로 파드를 생성한다.
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
...
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
**type: NodePort**
selector:
app.kubernetes.io/name: **app-2048**
#기본 path = "/", LB 관련 도메인에 접속하면 `service-2048`에 연결한다.
#이 서비스는 노드 포트로, 2048게임이 있는 파드에 연결해준다. 그렇게 2048게임의 화면이 뜨게된다.
apiVersion: networking.k8s.io/v1
kind: Ingress
...
spec:
ingressClassName: alb
rules:
- http:
paths:
**- path: /**
pathType: Prefix
backend:
service:
**name: service-2048**
port:
number: 80아래의 그림은 로드밸런서 호스트네임으로 접근한 결과이다. Ingress를 통해 서비스로 연결되고, 이후 서비스를 통해 파드에게 연결되어 파드의 이미지인 2048게임 화면을 볼 수 있다.
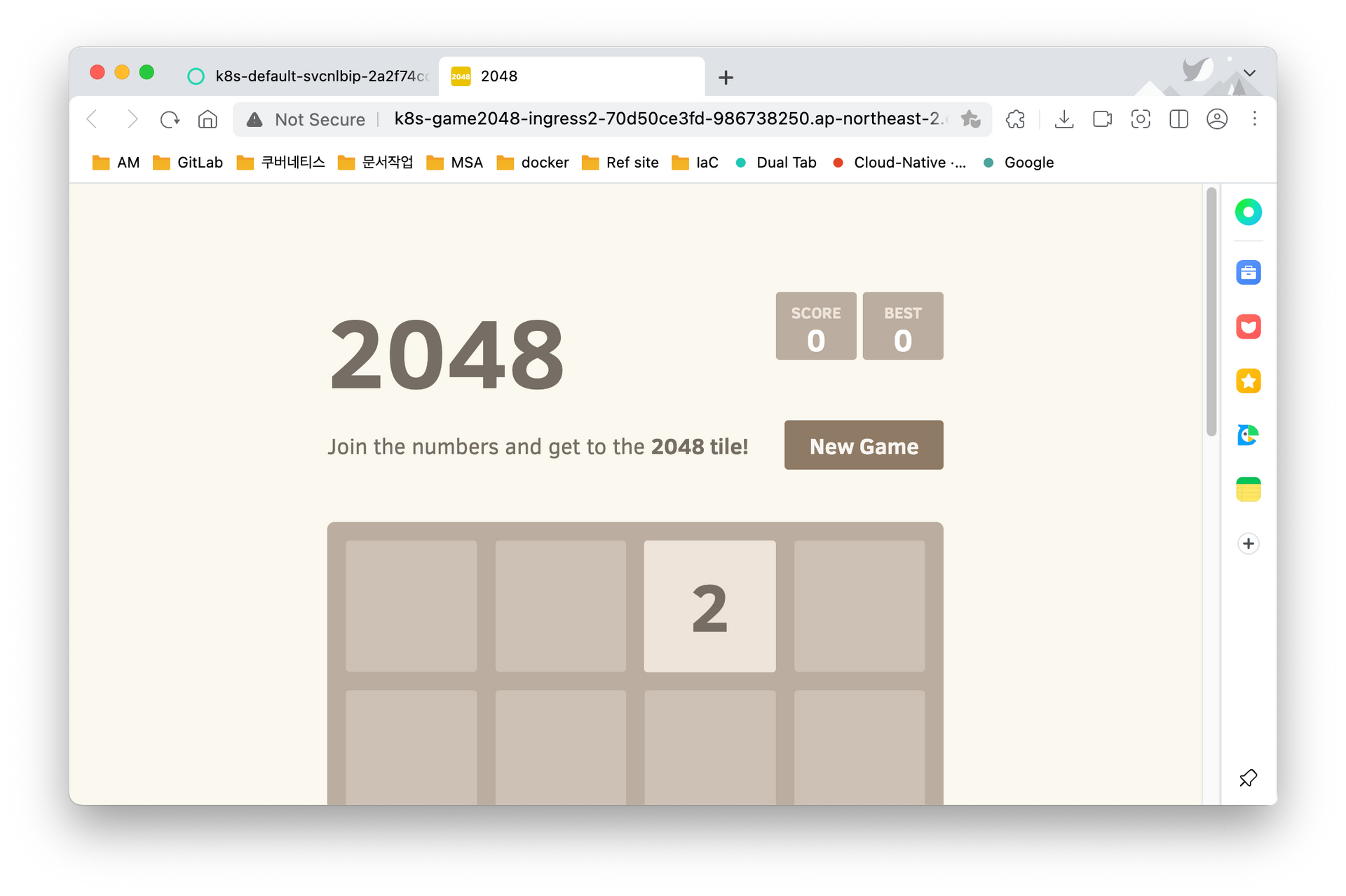
- 도메인과 관련된 부분은 추후 업데이트 예정..!
- 스터디 시작전에 관련 도메인을 미리 등록해뒀는데 결제가 안된모양이다. 아마 일전에 재발급을 받은 적이 있는 데, 업데이트를 안했나보다..

경험 발표
경험발표는 두 분이 진행해주셨다. 한분은 테라폼과 관련된 경험을 발표해주셨고, 한분은 VPC Lattice + EKS에 대해 알려주셨다. 관련 자료중에 공개해주신 자료 중 해당 WorkShop을 따라가면 데모로 보여주신 실습을 진행할 수 있다고 한다.
추가
파드의 노드와 같은 네트워크 대역대를 부여해서 오버레이 연산이 없어지기에 성능이 향상된다. ENI와 다른 CNI에 대해 눈으로 시간차이를 확인하고 싶어 관련 내용을 찾아봤다.
2개의 클러스터를 준비하고 각각 다른 CNI(ENI, 그 외)를 설치한 뒤 아래와 같이 네트워크 밴치마킹 테스트를 통해 확인해볼 수 있다. (이것도.. 추후 진행 예정)
직접 시간차이를 측정하고 싶다면 아래와 같은 과정을 따라가면 된다. 아래의 자료는 ChatGPT, 구글링을 통해 얻었다.
iperf3을 이용한 성능비교
- 2개의 EKS 클러스터를 준비하고 하나는 Calico, 하나는 ENI 사용
iperf3배포iperf3테스트 진행(서버와 클라이언트), 관련 내용 기록- 테스트 결과 비교
간단한 iperf3 deployment YAML 파일
apiVersion: apps/v1
kind: Deployment
metadata:
name: iperf3-server
spec:
selector:
matchLabels:
app: iperf3-server
replicas: 1
template:
metadata:
labels:
app: iperf3-server
spec:
containers:
- name: iperf3-server
image: networkstatic/iperf3
args: ["-s"]
ports:
- containerPort: 5201
---
apiVersion: v1
kind: Service
metadata:
name: iperf3-server
spec:
selector:
app: iperf3-server
ports:
- protocol: TCP
port: 5201
targetPort: 5201
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: iperf3-client
spec:
selector:
matchLabels:
app: iperf3-client
replicas: 1
template:
metadata:
labels:
app: iperf3-client
spec:
containers:
- name: iperf3-client
image: networkstatic/iperf3
command: ["sleep"]
args: ["infinity"]배포 후 아래의 명령어를 통해 실행하면 된다.
kubectl exec -it [iperf3-client-pod-name] -- iperf3 -c iperf3-server -t 30마치며
2주차 블로그 포스팅을 완료했다. 목표는 화, 수요일날 포스팅을 할 계획이었으나 예비군이후로 비염과 함께 컨디션이 좋지 않아 결국 토요일날 마무리?지었다. 한번에 전체적인 실습을 하는 것이 좋은 데, 그렇지 못해 실습 결과(Node Ip 등)들이 조금씩은 다르고 계속 끊기다보니 시간이 더 소요된 것 같다.! 이번주 연휴동안 푹쉬고 조금씩 보완하려한다. EKS는 중지기능이 없어서 게속 생성하고 제거하는 것했는데 조금 아쉬운 것 같다...!
