Spring, JAVA 최신기술정리
항상 맡은자리에서 최선을 다하다보니
우연찮게 면접제의가 들어왔다.
아직까지 모놀로직아키텍쳐밖에 다루지 못했고, noSql이라곤 redis정도로 캐싱해본 경험이 전부이며,
MSA로 구성된 쿠버네티스개발환경, ElasticSearch등에 대해서 무지한 내게 갑자기 최신기술을 사용하는 기업에서의 면접이라니...
부담스러우면서도 감격스럽다.
물론 경력기술서, 포트폴리오에 적힌것은 전부 사실이므로
이러한 환경에 대한 이해에 많은것을 바라지는 않을것 같다는 생각이 들지만,
그래도 면접인데 해당 회사가 사용하는 기술에 대해서
한줄 정도는 말 할 수는 있어야 할 것 같아서
'나중에 배워야지.'하고 미뤄놨던 최신기술들을 한번 이곳에 공유하면서 정리해보려고 한다.
모르는채로, 써보지도 않은채로 정리를 위해 함께 포스팅을 하는것으로
전반적으로 뇌피셜인 부분이 많다.
참고만 하되 너무 자료를 신뢰하진 말자!
MSA
MicroService Architecture
각각의 서비스를 독립적으로 나눠서 연결한 구조로, 이러한 특징으로 시스템 전체의 중단 없이 필요한 부분만 업데이트, 배포가 가능하다.
MSA 사용시 장점
1. 배포
- 서비스별로 개별 배포가 가능하다.
- 특정 서비스의 요구사항만을 반영하여, 빠른 배포가 가능하다.
2. 확장에 용이
- 특정 서비스에 대한 확장이 용이하다.
- 클라우드 기반 서비스 사용에 적합하다.
- 코드 변경시 사이드 이펙트가 해당 모놀로직아키텍쳐에 비해서 적다.
3. 장애대응
- 일부 서비스의 장애가 서비스의 전체 장애로 이루어지지 않는다.
- 부분적으로 장애가 발생하여 장애에 대한 격리가 수월하다.
4. 그 외
- 각각의 서비스가 독립적으로, 새로운 기술을 적용하기 유연하다.(서비스별로 다른 DB를 사용한다던지, 다른 언어를 사용할 수 있다.)
- 각각의 서비스에 대한 구조 분석이 쉽다.
MSA 사용시 단점
1. 설계의 어려움
- 분명 쉽지않다. 이견이 없을것이라 생각한다.
2. 성능
- 서비스간 호출시 API를 활용하므로, 통신비용이나 성능적인 이슈가 존재할 수 있다.
3. 테스트/데이터 트랜잭션
- MSA에서는 각각의 서비스가 가지고 있는 DB가 다르기 때문에, 한개의 요청에 대해서 트랜잭션을 유지하기 어렵다.
- 애플리케이션 통합 테스트가 어렵다
4. 데이터관리의 어려움
- 데이터가 여러 서비스에 분산되어 있어 조회하거나, 관리에 어려움이 따른다.
Kubernatis
사실 한번 찍먹해보려다가 어지러워서 포기했던 기술이다.
Kubernatis는 컨테이너화된 애플리케이션의 배포, 관리, 확장 등의 환경을 자동화 할 수 있도록 도와주는 플랫폼이다.
MSA 환경에서 자연스럽게 접하게 되는데, MSA의 특성상 작은 컨테이너들을 여러개 배포를 하게되고, 컨테이너 수가 많아지면 어떤 환경에 배포를 해야할지, 각 서비스마다 CPU나 메모리 용량은 어느정도로 잡아야 할지에 대한 고민이 생기게 된다.
쿠버네티스운영환경에서는 이러한 고민이 해결된다.
위와같은 스케쥴링 뿐만 아니라 컨테이너가 정상적으로 동작중인지 체크하고, 모니터링을 하고, 삭제, 관리등을 자동으로 최적화시켜준다.
Kafka
카프카는 스트리밍 데이터를 다루기 위한 미들웨어와 그 주변 생태계를 의미하는
분산 이벤트 스트리밍 플랫폼 이다.
순간적으로 요청이 몰려서 애플리케이션에 부하가 크게 올때
Kafka를 도입하지 않은경우에는 요청을 견디지 못하고 서버가 죽어버릴 수 있으나,
Kafka를 이용하면 이러한 요청을 우선 메세지Queue에 담고, 애플리케이션에 부담이 안가는 선에서 요청을 수행하므로
애플리케이션의 안정성을 한층 강화해 줄 수 있다.
메세지Queue 방식으로 동작하며
토픽을 생성하고,
Producer는 topic에 정보를 입력, Consumer는 topic을 가져오는 식으로 작동한다.
ElasticSearch
엘라스틱서치는 분산형 RESTful 검색 엔진으로
검색,분석,데이터저장소 역할을 하는 엘라스틱서치(ElasticSearch)
데이터 수집을 담당하는 비츠(Beats)
정제, 전처리를 수행하는 로그스태치(Logstash)
시각화,관리 기능을 제공하는 키바나(Kibana)로 구성된다.
더불어 여러 개발자들과 이야기를 해본결과 국내에서 제법 많이 사용하는듯하다.
RBD와의 차이
행을 기반으로 데이터를 저장하는 RDB와 달리, 엘라스틱서치는 단어를 기반으로 저장한다.
이를 역인덱스라고 표현하는데,
아래의 그림에 좋은 예시가 있어서 공유해본다.
참고자료
https://www.samsungsds.com/kr/insights/elastic_data_modeling.html
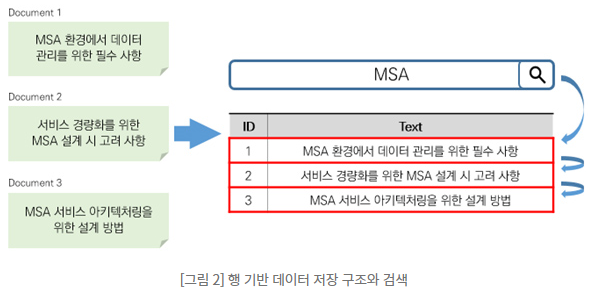
'MSA'라는 키워드로 검색을 실행하는경우
RDB는 MSA라는 키워드가 있는 행을 전부 반환한다.
데이터의 양도 (상대적으로)크고, 검색된 행 수가 있으면 그만큼 검색하는데 시간이 걸리게 된다.
그에비해 ElasticSerarch는 역인덱스 방식으로
'MSA'라는 단어가 저장된 도큐멘트를 알고 있기 때문에 그 수와 상관없이 한번의 조회로 검색을 끝낼 수 있다.
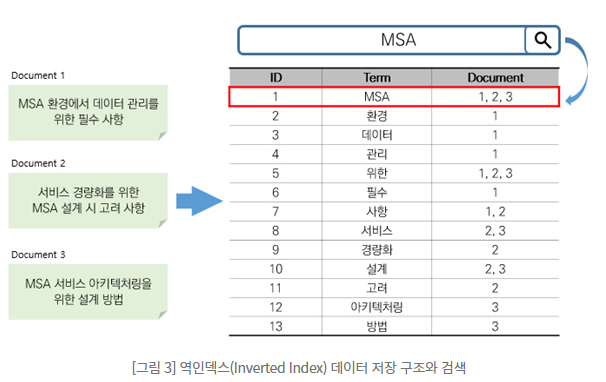
이로인해 검색성능은 RDB에 비해서 매우 뛰어나나
수정과 삭제에는 상당한 리소스가 소요된다고 한다.
Cassnadra
Cassnadra는 nosql의 한 종류로
FaceBook에서 개발하여 현재 아파치 오픈소스로 공개된 분산형 DB이다.
key-value 혹은 key-cloumn형으로 이루어져 있다.
대량의 데이터를 다수의 분산된 서버에서 관리해야할 경우에 적합하고,
사용자가 많고 다량의 wirte작업이 발생할 때 적합하다.
REDIS
포스팅중 유일하게 실제 애플리케이션에 적용하여 성능향상을 이끌어낸 Nosql이다.
마찬가지로 key-value형태로 구분하여
인메모리 DB라는 특성으로 휘발성이라는 특징이 있고, 데이터 처리속도가 매우 빠르다.
메모리에 있는 disk에 저장하는 snapshot기능을 제공하며,
key-value 형식의 value에 다양한 값을 지정할 수 있다.
다른 Nosql도 어떨진 모르겠는데
그리고 직접 사용해본 특성상 docker를 이용하여 매우 간편하게 사용할 수 있었으며
스프링 웹 어플리케이션에 도입하는데 있어서 설정이 간편했던 기억이 있다.
Prometheus와 Grafana
아 영한님 강의 듣고 정리하는 습관을 진작에 들일껄
유일하게 강의를 듣고 개인프로젝트로 따라하지 않은 기술이다.
어떻게 다루는지 알았으니까.
나중에 이러한 기능이 필요해지면 하면 주말에 잠깐 영한님강의듣고 바로 적용할 수 있을것 같아서....
이렇게 면접대비를 위해서 정리를 하게될 줄은 몰랐다....
액츄에어터를 이용하면 api의 endPoint등에 대한 모니터링이 가능하다.
정상적인 상태인지, 몇번의 호출이 있었는지 등
액츄에이터를 통해서 수많은 지표를 자동으로 만들 수 있다.
그러나, 애플리케이션에서 발생한 그 순간의 메트릭만을 확인하는것에서 멈추는것이 아니라 과거 이력까지 확인하고 싶다.
프로메테우스는 이러한 메트릭을 보관하는 DB역할을 담당한다.
그라파나는 프로메테우스에 있는 데이터를 사용자가 보기 편하게 보여주는 대시보드 툴이다.
이러한 모니터링툴을 이용한 모니터링은 값의 정확한 검증보다는 대략적인 값, 추세를 확인하는 용도로 사용하는것이 적합하며
정확한 값을 위해서는 실제 테스트환경에서 실행을 해보거나 하는등의 검증이 필요하다.
조급해 하지 않고 꾸준히 노력을 해오니
어떻게 좋은 기회가 온 것 같다.
결과가 좋을지 나쁠지는 모르겠다.
그러나 현재회사에서도 충분히 재밌게 다니고 있고
어느순간 초보개발자가 넘쳐나서.. 일을 하고있는것 만으로도 진심으로 감사하게 생각한다.
결과가 어찌되었든
나중에는 꼭 한번씩 써봐야지 하는 기술들을 이렇게 한번 먼저 프리뷰하며 정리하는 시간을 가지게 되었고,
노력의 방향을 조금 더 찾은 느낌이다.
'우대조건에 대용량처리 있던데, 이거하려면 kafka를 써야한대. 그러니까 배워야지'
하는 막연히 공부하는것과
이론상으로나마
'대용량 상황에서 부하를 처리하기 위해 kafka가 메세지큐를 통해 적절히 이벤트를 분산하고, 이로인해 안정성이 올라가고, 이렇기 때문에 트래픽이 몰리는 서비스에서는 kafka를 사용한다.'
이렇기 때문에 이러한 환경에 대응하기 위해서 배워보자. 라고 접근하면 어느부분에 더 집중해서 공부를 해야하는지 알기 쉬울것이라는 생각이 든다.
좋은 결과가 있기를 바라며,
좋은결과가 아니더라도
현재에 최선을 다하보면 더 나은 기회가 올 수 도 있을테니
너무 낙담하지않고 계속 현재에 노력을 더하고 싶다.

Kubernatis 오타 있어요 ㅎㅎ...