ML/DL
1.[ML/DL] Train/Test/Valid Dataset

모델을 학습 시킬 때 사용할 데이터는 train/test/valid(혹은 Dev) 으로 분리해서 학습에 사용된다. 이렇게 분리하는 이유와 각 데이터 셋의 용도와 데이터를 분리할 때 사용할 수 있는 모듈들을 알아보자~한 눈에 살펴보는 특징들표 출처 : https:
2.[ML/DL] 알고리즘 정리(지도/비지도학습)

지도학습, 비지도학습에 쓰이는 머신러닝 알고리즘들과 과적합 방지 방법, 평가지표에 대해 깔끔하게 정리해서 머리에 넣기 위해 만들었다!
3.[ML/DL] AI 와 ML 과 DL의 기본 개념

AI, ML, DL 의 개념들과 예시를 알아보자!인공지능은 크게 2가지로 나뉜다고 한다. strong AI (artificial general intelligence) : 사람과 구분이 안 될 정도로 강한 성능을 가진 AIweak AI (artificial narrow
4.[ML/DL] K-Fold 교차 검증

validation data set 을 k 번 바꿔가며 검증하는 K-Fold 교차 검증에 대해 공부해보고 sklearn 을 이용해서 간단한 분류 모델을 작성해봤다.사용한 데이터 : iris data set사용한 모델 : decisiontreeclassifier가장 보편
5.[ML/DL] 하이퍼파라미터를 찾는데 도움을 주는 Grid Search CV

모델의 성능을 개선하기 위해서는 만족할 만한 성능이 나올 때까지 학습, 검증 개선 작업을 반복해서 수행한다. 이를 튜닝이라고 한다. 개선 방법을 크게 두가지로 나눠보면 다음과 같다. 1\. 구조적인 변경 \- 하이퍼파라미터 : 모델을 구성하는 정보 중 데이터를 통해 학
6.[ML/DL] 모델성능평가 F1-score
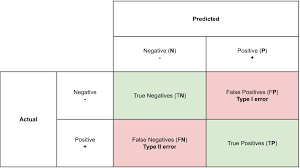
사이킷런에는 모델의 성능을 평가할 수 있는 여러 다양한 라이브러리들이 존재한다. binary classification도 가능하지만 multi class 인 경우에도 파라미터를 설정하면 평가할 수 있다.올바르게 예측된 데이터의 수를 전체 데이터의 수로 나눈 값모델이 T
7.[ML/DL] Aspect-Based Sentiment Analysis

대상의 하위 요소 및 특성과 관련된 용어를 고려하여, 각각에 대한 감정을 식별하는 기술전형적인 감성 분석은 문장/단락에 대한 감성을 긍/부정으로 분류/예측(주어진 텍스트에 하나의 측면과 하나의 극성만 있다는 가정으로진행)→ ABSA은 문장에서 언급된 양상과 각각의 as
8.argmin, argmax

논문을 읽다가 항상 까먹어서 검색해보는 argmin, argmax 에 대해 포스팅을 해야겠다. argmin 의 수식은 위에 처럼 사용하는데 의미는 함수 f(x)를 최소로 하는 x 값을 구한다는 뜻이다. 이를 만족하는 값은 하나일수도 있고 그 이상일 수도 있다. 가장 많
9. ROUGE 성능지표 (텍스트 요약 모델 평가)

Recall-Oriented Understudy for Gisting Evaluation 의 준말 텍스트 요약 모델의 성능 평가 지표텍스트 자동 요약, 기계 번역 등 자연어 생성 모델의 성능을 평가하기 위한 지표모델이 생성한 요약본 혹은 번역본을 사람이 미리 만들어 놓