
지도학습, 비지도학습에 쓰이는 머신러닝 알고리즘들과 과적합 방지 방법, 평가지표에 대해 깔끔하게 정리해서 머리에 넣기 위해 만들었다!
1️⃣ 지도학습
Regression
💡 데이터를 잘 설명하는 선을 찾아 미래 결과값 예측
Loss function 최소화하는 Gradient Descent
- 단순 선형회귀, 다중 선형회귀, 다항 회귀
< Overfitting 방지 방법 >
-
Cross Validation : K-fold 교차 검증
-
Regularization : Lasso (L1, 베타 i → 0), Ridge (L2, 베타 i → 0에 가까운 값)
Elastic Net (Lasso + Ridge, 비율 조정)< 평가 지표 >
1.RSS : 단순 오차 제곱 합, 작을수록 성능 좋음, 직관적 해석 가능
2.MSE : 평균 제곱 오차, 작을수록 성능 좋음, Outlier에 민감
3.MAE : 평균 절대값 오차, 작을수록 성능 좋음, 변동성 큰, 낮은 지표 같이 예측시 유용
( 1, 2, 3 지표는 입력값 크기 의존적)4.MAPE
5.R^2 (결정 계수) : 설명력 표현, 1에 가까울 수록 성능 좋음, 크기에 의존적 X
-
Classification
💡 주어진 입력값이 어떤 클래스에 속할지에 대한 결과값 도출
-
로지스틱 회귀, Support Vector Machine, K-Nearest Neighbor, 나이브 베이즈 분류
-
Logistic regression : Sigmoid 함수 사용, Decision Boundary(결정경계)기준으로 판별
(주로 2개 값, 이진분류 위해 사용, 선형 회귀 응용한 분류 알고리즘)
-
SVM : 이진분류 문제에서 Margin을 최대화하는 최적의 결정경계 찾기
(Support Vector : 결정 경계와 가장 가까이 있는 데이터 포인트들,
Margin : 결정 경계와 서포트 벡터 사이의 거리
선형, 비선형 분류 모두 가능, 고차원 데이터에서도 높은 성능, 회귀 적용 가능)
-
나이브 베이즈 분류 : 독립 가정 설정, 베이즈 정리 활용한 확률 통계학적 분류
(각 특징들이 독립이라면 성능 좋고, 학습데이터 적게 필요) -
KNN : 기존 데이터 가운데 가장 가까운 k개 이웃의 정보로 새로운 데이터 예측
(설정된 K값 따라 가까운 거리 내의 이웃의 수에 따라 분류,
직관적, 결과 해석 쉬움, K값 결정에 따라 성능 크게 좌우, 학습 없는 Lazy Model)
-
< 평가 지표 >
- Confusion Matrix
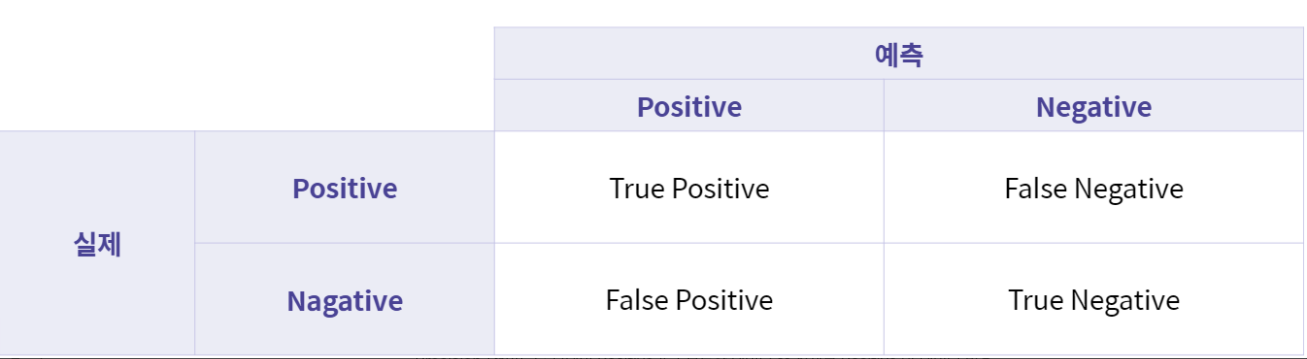
FP 1형 오류 , FN 2형 오류
Accuracy (정확도) : 전체 데이터 중 제대로 분류된 데이터 비율
Precision (정밀도) : 모델이 Positive라고 분류한 데이터 중 실제로 Positive 인 데이터 비율
Recall (재현율, TPR) : 실제로 Positive인 데이터 중 모델이 Positive로 분류한 데이터 비율
FRP (False Positive Rate) : 실제로 Negative인 데이터 중 모델이 Positive로 분류한 비율
Decision Tree
💡 특정 질문들을 통해 정답을 찾아가는 모델, 회귀/분류 에서 모두 적용 가능 의사결정 나무는 결과가 직관적, 해석하기 쉬움
-
회귀 ( RSS 최소화 하는 방향으로 구역 나누기 Top-down, Greedy Approach )
겹치지 않는 구역으로 데이터 나눔, 특정 구역에 데이터가 있으면 그 데이터의 예측값은 해당 구역의 평균값
-
분류 ( 데이터의 Impurity 를 최소화하는 구역으로 나누기 )
- 불순도 : 다른 데이터가 섞여 있는 정도
- Gini Impurity (지니 계수) : 1 - (yes의 확률)^2 - (no의 확률)^2 해당 구역 안에서 특정 클래스에 속하는 데이터의 비율을 모두 제외한 값, 다양성 계산 방법 불순도를 낮춰가며 진행, 너무 나무가 깊어지면 Overfitting 문제 발생 가능성 증가
< Overfitting 방지 방법 >
앙상블 기법
💡 의사결정나무의 과적합 방지 및 더 높은 성능의 결과 도출하도록 여러 모델 활용하는 기법
- Voting / Bagging (Bootstrap Aggregating) / Boosting
-
Voting : 여러 모델의 예측 결과값을 활용하여 투표를 통해 최종 예측값 결정
( 회귀 : 예측값의 평균 / 분류 : 직접 투표-다수결 채택, 간접 투표-확률의 평균
결과가 직관적, 해석 쉽고 간단한 연산 사용)
-
Bagging : 복원 추출 통해 랜덤 추출한 데이터를 생성, 각 데이터를 모델 학습하여 결합한 후, 학습된 모델의 예측 변수를 활용하여 최종 모델을 생성하는 방법 ( 데이터 편향을 줄여줌 )
(Bootstrap : 데이터를 복원추출하는 통계학적 방법 / Pasting : 비복원 추출
Bootstrap 활용한 랜덤 샘플링으로 과적합 방지, 복원과정 있어서 불균형, 소수데이터 적용가능)
-
Boosting : 여러개의 Weak Learner 수정하여 Strong Learner 만드는 방법
(독립적인 모델을 합산하여 산출하기보다는 기존의 모델을 개선시키는 방향의 앙상블 기법
작은 decision stub 합쳐서 strong Learner 만들기)
Random Forest
💡 입력 변수에 대해서도 복원 추출, 의사결정나무 + Bagging 알고리즘 Bootstrap 데이터 생성할 때, 변수들도 임의로 샘플링 진행 (정확도 높음, SVM 유사하거나 높음)
- 데이터 셋에서 Bootstrap 을 통해 N개의 훈련데이터셋 생성, 생성한 N개의 의사결정 나무들을 학습, 학습된 나무들의 예측 결과값의 평균 또는 다수결 투표 방식 이용하여 결합 ( 변수의 중요성 파악 가능, 변수 일부를 사용하기 때문에 Overfitting 방지 가능)
Boosting Algorithm
-
Ada Boost (Adaptive Boosting, 적응 부스팅) : 이전 학습 과정에서 오분류한 데이터를 다음 학습 과정에서는 잘 분류할 수 있도록 하여 Weak Learner를 Strong learner로 수정하는 알고리즘
이전 모델이 오분류한 데이터의 가중치를 바꾸는 방식
오분류 데이터에 대해 모델을 적합할 수 있음, Overfitting 가능성 높음, 계산과정 병렬수행 불가
-
Gradient Boosting (Gradient Descent + Boosting) : Ada Boost와 동일한 원리
차이점은 가중치 업데이트 과정에서 Gradient Descent 사용 ( 오차는 손실함수로 표현되고, 이 손실 함수를 최적화 하는 데 있어 Gradient Descent 를 사용함.)
계산량이 많이 필요하나 높은 성능 도출
<Gradient Boosting 기반 모델들>
-
XGBoost (eXtreme Gradient Boosting)
일반 Gradient Boosting 모델과 작동원리는 동일, Overfitting 방지 위해 정규화 추가
분산/병렬 처리를 통해 실행 속도를 보완, 대부분 문제에서 양호한 예측 성능 보임
다양한 하이퍼 파라미터 지원 및 조절을 통해 과적합 방지에 효율적
-
LGBM (Light Gradient Boosting Model)
XGBoost 에 비해 더 가볍과 빠른 실행 속도 가진 모델, 범주형 변수 처리 지원 기능 추가
배타적인 범주 변수에 적합
대용량 데이터에서의 실행 속도 개선, XGBoost 대비 적은 메모리 사용
적은 수의 데이터 적용 시 과적합 문제 발생 가능성
-
CatBoost (Categorical Boosting)
범주형 변수를 위해 다양한 기능을 지원하는 부스팅 모델
Category 변수에 대한 전처리 문제 해결, 범주형 변수를 자동으로 처리, 타입변환오류 피함
범주형과 수치형 변수들의 combination 을 처리
변수 간의 상관관계를 계산함과 동시에 속도 새건, Multiple-category 데이터를 다룰 때 유용
-
2️⃣ 비지도학습
Clustering
💡 각 개체의 그룹 정보(정답) 없이 유사한 특성을 가진 개체끼리 군집화하는 것 (1) 군집 간 유사성 최소화 (2) 군집 내 유사성 최대화
- Hard Clustering : K-means / Soft Clustering : Gaussian Mixture Model Algorithm
-
K-means : 제공된 데이터를 K개로 군집화하는 알고리즘 ( K : 직접 설정, 하이퍼 파라미터)
(최적의 군집 개수 K 구하기 : Elbow Method 사용, 랜덤 초기값 설정으로 인해 데이터 분포가 독특할 경우 원하는 결과 나오지 않을 가능성 있음, 대용량 데이터에 적합)
-
GMM : 전체 데이터의 확률분포가 여러 개의 정규분포의 조합으로 이루어져있다고 가정
(확률을 통해 데이터 유사성 측정, EM 알고리즘 사용)< 평가 지표 >
-
Dunn Index : (군집 간 거리의 최소값) / (군집 내 요소 간 거리의 최대값)
분자값이 클수록 군집 간 거리 크고, 분모값 작을수록 군집내의 데이터 모여있음
-
Silhouette Index : 얼마나 잘 군집화 되었는지에 대한 정량적 평가, 클러스터의 밀집정도계산
-1부터 1 사이의 값 가짐, 1에 가까울 수록 높은 성능
-

Dimensionality Reduction
💡 고차원 데이터의 차원을 축소하여 데이터를 더욱 잘 설명할 수 있도록 함
- Principle Component Analysis (PCA, 주성분 분석) / t-Stochastic Neighborhood Embedding
- 차원의 저주 : 차원이 높을 수록 학습에 요구되는 데이터의 개수 증가, Overfitting 발생 가능
-
PCA : 고차원 데이터를 가장 잘 설명할 수 있는 주성분 찾는 방법 ( 원본 데이터의 특징 유지)
(원본 데이터와의 차이 최소화 = 차이를 최소화 하는 축(주성분) 찾아야 함,
각 점들과 축의 오차가 가장 작은 축을 중심으로 데이터 모음
고차원 데이터 함축적 표현 → 직관적 해석 어려움, 대용량 고차원 데이터 압축 시 유용)
-
t-SNE : 고차원의 공감에 존재하는 데이터 간의 거리를 최대한 유지하며 차원 축소
( 각 데이터마다 자기 이외의 데이터와 유사도 확률 계산 → 저차원으로 축소 → 초기 계산 했던 유사도 확률분포를 바탕으로 각 데이터를 이동, 데이터 간 거리 유지 통해 차원 축소 후에도 객체 간 구별 가능, 예측을 위한 학습 데이터로 이용 불가, 시각화를 위해 활용 됨)
-
