1. Abstract
Diffusion models (DMs)는 이미지 생성 모델의 일종으로, 이미지 생성 과정을 denosing autoencoders의 순차적인 적용으로 분해하여 image 데이터에서 높은 성능을 보였다. 또한, DMs는 재학습을 하지 않고도 이미지 생성 과정을 제어할 수 있는 메커니즘을 제공한다. 하지만 DMs는 pixel space 상에서 동작하므로, 모델 학습 및 추론에 많은 GPU 자원을 필요로 했다. 제한된 컴퓨팅 자원으로도 DMs를 학습하기 위해 powerful pretrained autoencoders의 latent space representation을 활용한다. 이로 인해 복잡성 축소 (complexity reduction)와 디테일 보존 (detail preservation) 사이의 최적값에 도달할 수 있어, 정교하게 이미지를 표현할 수 있다. 또한, diffusion model 구조에 cross-attention layer를 도입하여, convolution 방식으로 general conditioning inputs (e.g. text, bounding boxes) 으로부터 이미지를 생성할 수 있다.
위와 같은 모델을 latent diffusion models (LDMs) 라고 한다. LDMs는 pixel-based DMs 보다 적은 컴퓨팅 자원을 사용하면서, text-to-image, unconditional image generation, super-resolution 등에서 좋은 성능을 보였다.
2. Introduction
2.1. Image synthesis
이미지 합성, Autoregressive (AR) transformers와 같은 likelihood-based models 활용
Problems:
- 많은 계산 요구
2.2. GAN
generative model과 discriminative model을 적대적으로 학습
Problems:
- multimodal distributions과 같은 복잡한 분포에 대해서는 잘 동작하지 않음
2.3. Diffusion Models (DMs)
Hierarchical denoising autoencoders, Likelihood-based models
- conditional/unconditional DMs 모두 가능
- GAN 같은 모델보다 mode-collapse나 training instabilities 문제가 적음
- parameter sharing
⇒ AR models처럼 수십 억 개의 파라미터를 사용하지 않고도 복잡한 이미지 표현 가능
Problems:
- 학습과 추론에 많은 computational resources 필요
cause: 고차원인 RGB 이미지의 representational space에서 반복된 function evaluation과 gradient computation 때문
DMs의 계산량을 줄이면서도 모델의 성능을 유지할 수 있는 방법이 필요
2.4. Latent Diffusion Models (LDMs)
Likelihood-based model의 학습을 두 단계로 나눔
- Perceptual Compression stage
lower-dimensional representational space을 생성하는 autoencoder 학습
- perceptually equivalent to the data space
- Semantic Compression stage
DMs 모델을 learned(autoencoder의) latent space에서 학습
- 효율적인 이미지 생성
cause: single forward pass로 이미지를 생성할 수 있기 때문
Effects:
- need to train the universal autoencoders only once
⇒ reuse it for multiple DM traings or to explore different tasks - image-to-image, text-to-image tasks을 위한 다양한 diffusion models을 탐색 할 수 있게 됨
by: Transformers와 DM UNet backbone을 연결
- token-based conditioning mechanisms
2.5. Contributions
- 이전보다 더 잘 고해상도 이미지를 다룰 수 있음
- 다양한 tasks (unconditional image synthesis, inpainting, stochastic super-resolution)에서 좋은 성능을 보이고, 자원을 덜 소모함
- 신뢰할 수 있는 reconstructions, latent space에 대한 정규화를 거의 필요로 하지 않음
- densely conditioned tasks (super resolution, inpainting, semantic synthesis) 에서 convolutional fasion을 적용할 수 있고, 1024 x 1024 크기의 고해상도 이미지를 다룰 수 있음
- Multi-modal 학습을 위하여 Cross-attention을 기반으로 하는 conditioning mechanism을 설계
- 사전학습된 latent diffusion과 autoencoders 공개 https://github.com/CompVis/latent-diffusion
3. Experiments
3.1. On Perceptual Compression Tradeoffs
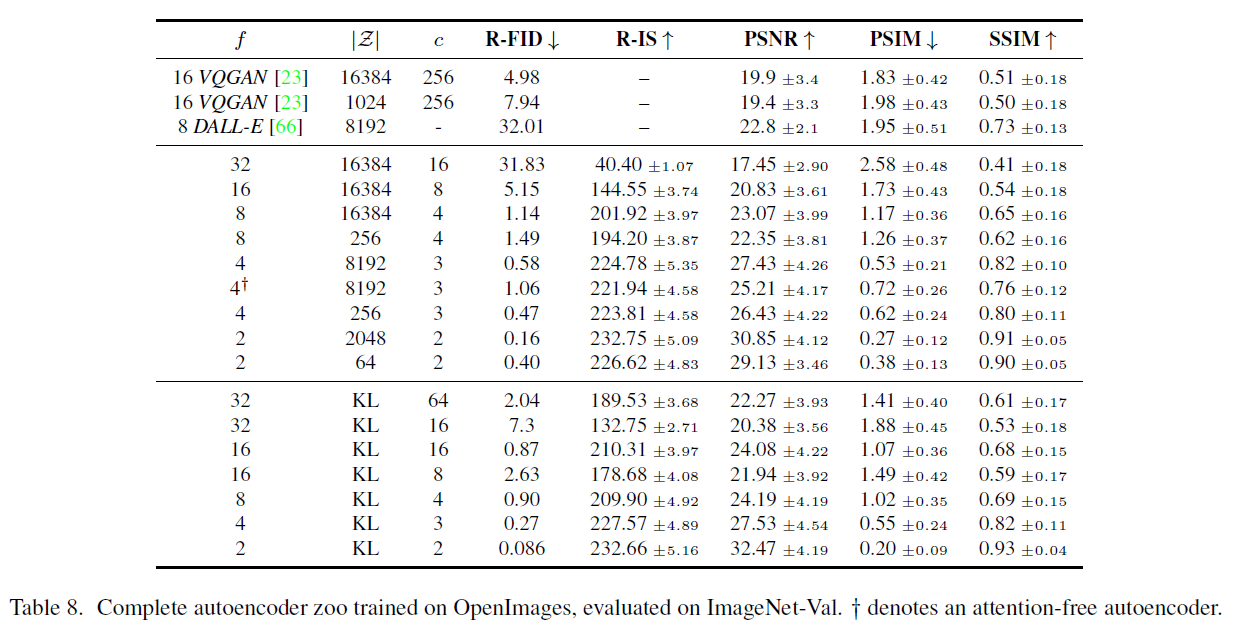
Tab 8은 hyperparameters와 LDMs 모델의 first stage 모델에 따른 reconstruction performance 지표를 나타낸다.
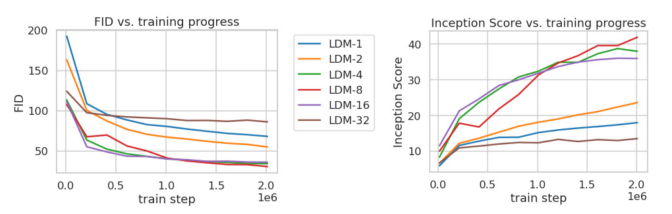
ig 6은 train step에 따른 quality를 보여준다. Downsampling이 적용되지 않은 Pixel-based LDM-1은 학습에 오랜 시간이 소요된다. 반면, perceptual compression이 과도하게 적용된 LDM-32의 경우는 정보 손실로 인해 학습이 잘 되지 않는다.
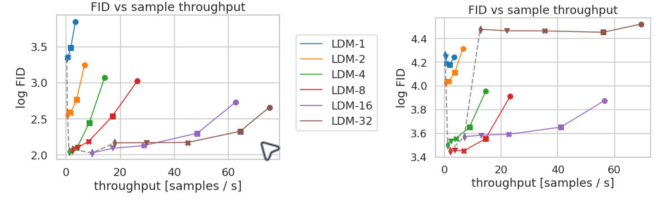
Fig 7은 CelebA-HQ (left)와 ImageNet (right) 데이터셋을 학습한 각 모델에 대하여 DDIM sampler을 사용했을 때, FID-score와 throughput (sampling speed)을 비교하였다. Pixel-based LDM-1과 비교하여 LDM-{4-8}은 throughput이 상당히 개선되었다. ImageNet과 같은 복잡한 데이터셋의 경우, 정보 손실로 인한 퀄리티 하락을 방지하기 위하여 compression rate를 낮춰야 한다.
LDM-4와 LDM-8이 일반적으로 좋은 품질의 이미지를 생성한다.
3.2. Image Generation with Latent Diffusion
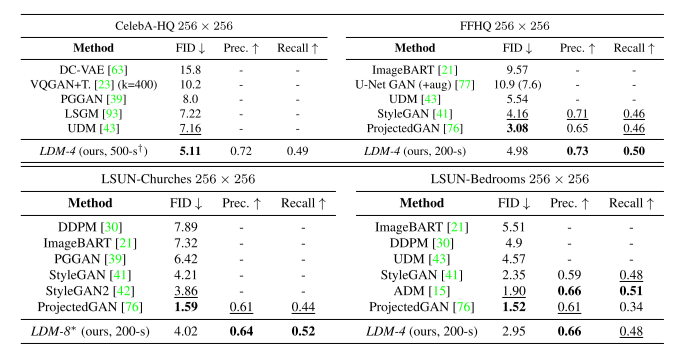
LDMs는 다른 생성 모델들과 비교하여 일반적으로 준수한 성능을 보였다.

256 x 256 size의 이미지로 구성된 각 데이터셋으로 학습한 LDMs의 sampling 결과이다.
4.3. Conditional Latent Diffusion
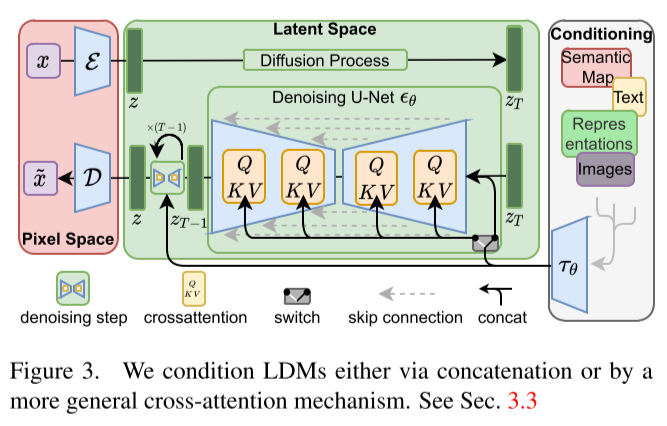
4.3.1. Transformer Encoders for LDMs

text-to-image를 위하여, LAION-400 language prompts에서 LDM를 학습하였다. BERT-tokenizer와 transformer를 활용하여 를 구현하였다. 그리고 를 (multi-head) cross-attention을 통해 UNet에 mapping 하였다.

layout-to-image를 위하여 semantic layouts을 OpenImages 데이터로 학습하고, COCO 데이터로 finetuning 하였다.
4.3.2. Convolutional Sampling Beyond
Conditioning information을 UNet의 input 에 concate 했을 때, LDMs을 image-to-image translation model을 위하여 사용할 수 있다. 본 논문에서는 semantic synthesis, super-resolution, inpainting을 위하여 사용했다.
4.4. Super-Resolution with Latent Diffusion

LDM-SR은 OpenImages로 사전학습된 autoencoding model을 conditioning 를 만들기 위하여 사용하고, 이를 UNet의 입력인 와 concatenate 하였다.
4.5. Inpainting with Latent Diffusion

4. Limitations and Societal Impact
4.1. Limitations
- pixel-based 방법론보다는 적은 자원을 요구하지만, 여전히 sampling process의 속도가 GANs 보다 느림
- 복잡하고 정밀한 이미지를 다루는 경우, LDMs-4 일지라도 pixel-space 상에서는 이미지 생성 과정에서 정보 손실이 발생할 수 있음
4.2. Societal Impact
- 창의적인 애플리케이션을 만들 수 있지만, 딥페이크와 같은 바람직하지 않은 정보를 생성할 수 있음
- 데이터에 존재하는 bias가 결과물에 나타날 수 있음
5. Conclusion
Latent Diffusion Models (LDMs)는 이미지 생성 모델 중 하나로, autoencoder의 latent space representation에 DMs를 적용하여, 샘플링 품질을 높이면서 계산 비용을 줄일 수 있다. 또한, Diffusion Models (DMs) 모델 구조에 cross-attention conditioning mechanism을 도입하여 다양한 conditional image synthesis task에서 좋은 성능을 보였다.
