논문
1.BioBERT : a pre-trained biomedical language representation model for biomedical text mining
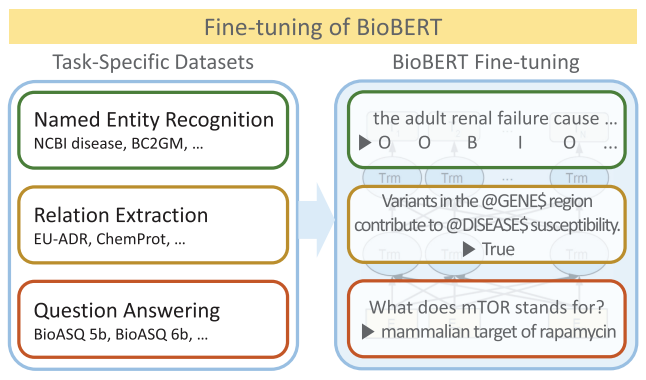
Abstract BERT는 범용학습 모델로 Biomedical 텍스트를 분석하면 성능이 떨어지는 경우가 있다. 이 논문에서는 Biomedical 텍스트를 분석하기 위해 BERT를 biomedical corpora로 Pretrain한 방법과 모델 BioBERT를 소개한
2.Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
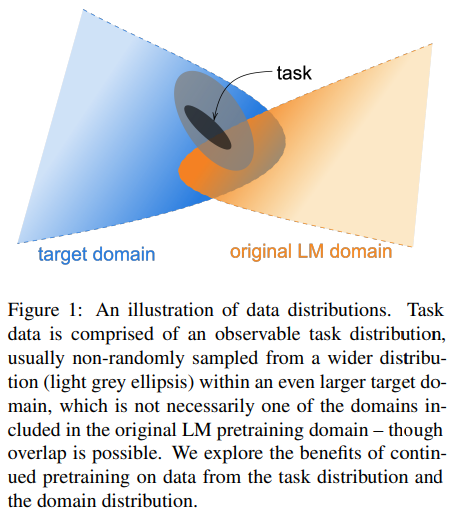
Pretrain 된 Language model을 domain corpus로 pretrain (domain-adaptive pretraining) 하였을 때 자원의 크기와 무관하게 모델의 성능이 향상되었다. 또한, domain-adaptive pretraining 이후에
3.Graph Based Network with Contextualized Representations of Turns in Dialogue
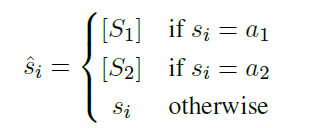
Abstract Dialogue-based relation extraction (RE)는 대화에 나타난 두 arguments 간의 관계를 추출하는 것을 목표로 한다. 대화에서는 정보가 여러 시점에 거쳐서 나타난다. Dialogue-based relation extrac
4.The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset

Abstract 이미지를 잘 분류할 수 있는 Robust한 CNN 모델을 만들기 위해서 많은 hyper-pameter에 대한 tuning이 필요하다. 그 중에서 가장 중요한 것 중 하나는 batch size로, 이는 모델이 forward와 backward를 통해 한번
5.Improving BERT Fine-Tuning via Self-Ensemble and Self-Distillation
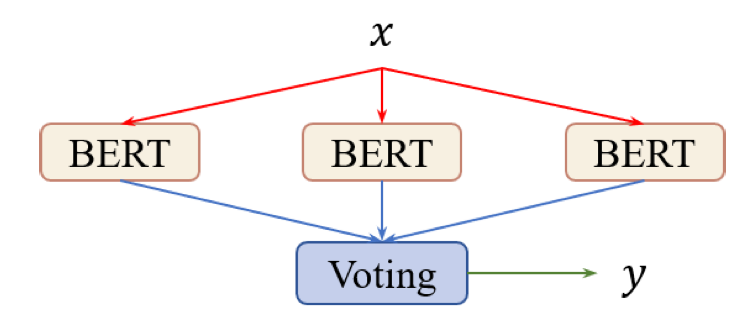
이 논문에서는 _self-ensemble_ 과 _self-distillation_ 이라는 효과적인 메커니즘을 통해 fine-tuning을 개선하고자 합니다. 텍스트 분류와 자연어 추론 task에서 위 방법이 외부 데이터나 지식을 활용하지 않고도 높은 성능을 보이는 것을
6.Few-shot Learning for Multi-label Intent Detection
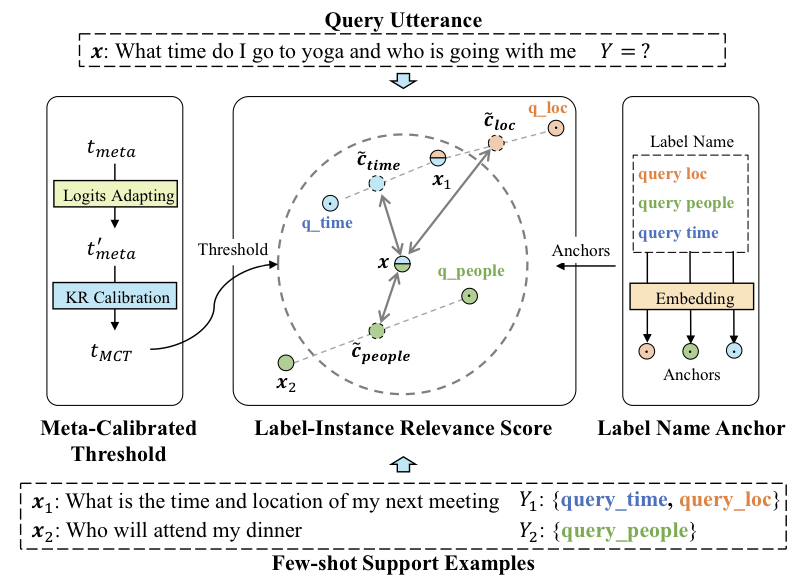
논문에서는 사용자의 발화 의도(intent detection)를 예측하기 위하여 few-shot multi-label classification을 연구하였습니다. 기존 SOTA 모델은 label과 instance 사이의 연관성을 예측하고, thresho
7.GraphSAGE : Inductive Representation Learning on Large Graphs

Large Graph에서 node에 대한 low-dimensional vector embedding(저차원 벡터 임베딩)은 다양한 예측 및 그래프 분석 과제에서 feature inputs으로 유용하다. 그러나 이전의 연구들은 고정된 단일 그래프에 대하여 embeddin
8.High-Resolution Image Synthesis with Latent Diffusion Models
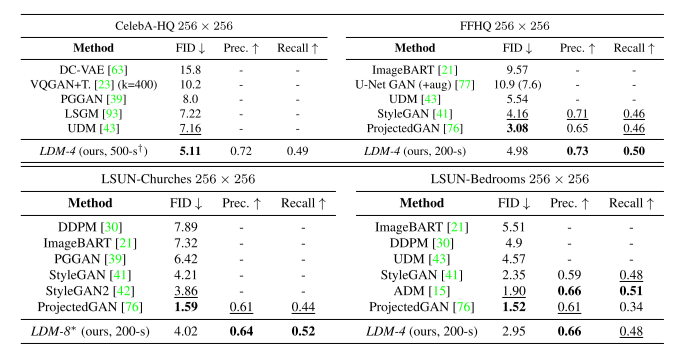
Latent Diffusion Models (LDMs)는 이미지 생성 모델 중 하나로, autoencoder의 latent space representation에 DMs를 적용하여, 샘플링 품질을 높이면서 계산 비용을 줄일 수 있다. 또한, Diffusion Model