
Apache Hive 데이터 웨어하우스 소프트웨어는 구축된 스토리지에 저장되어있는 대용량의 데이터셋을 SQL을 사용하여 읽고, 쓰고, 관리하는 것을 가능하게한다. 이미 저장되어 있는 데이터에 구조를 투영시킬 수 있다. Hive와 사용자를 연결하기 위한 커맨드 라인 툴과 JDBC 드라이버를 제공한다.
hadoop의 SQL
Hive Architecture
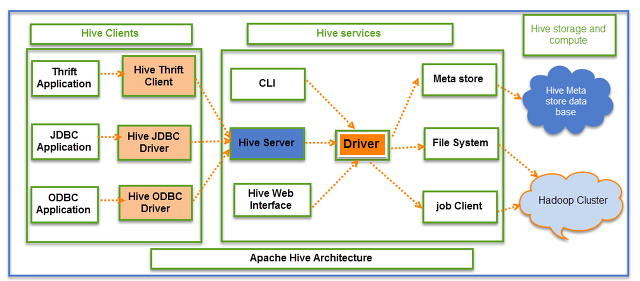
- Meta Store
- 물리적으론 MySql이나 Oracle 등의 DB로 구성
- 테이블의 스키나 구조 등 설정값 저장
- Meta Store의 장애 혹은 데이터 유실 시 Hive는 정상 구동되지않는다.
- Hive Server
- Hive에 질의하는 가장 앞단의 서버
- JDBC나 ODBC로부터 질의를 받아서 이를 Driver에 전달
- Driver
- Hive의 엔진
- 여러 질의에 대해 Optimizer를 통해 Hive SQL의 연산 방식을 계산
- MR, Spark 등의 여러 엔진 등과 연동시킴
실행 순서
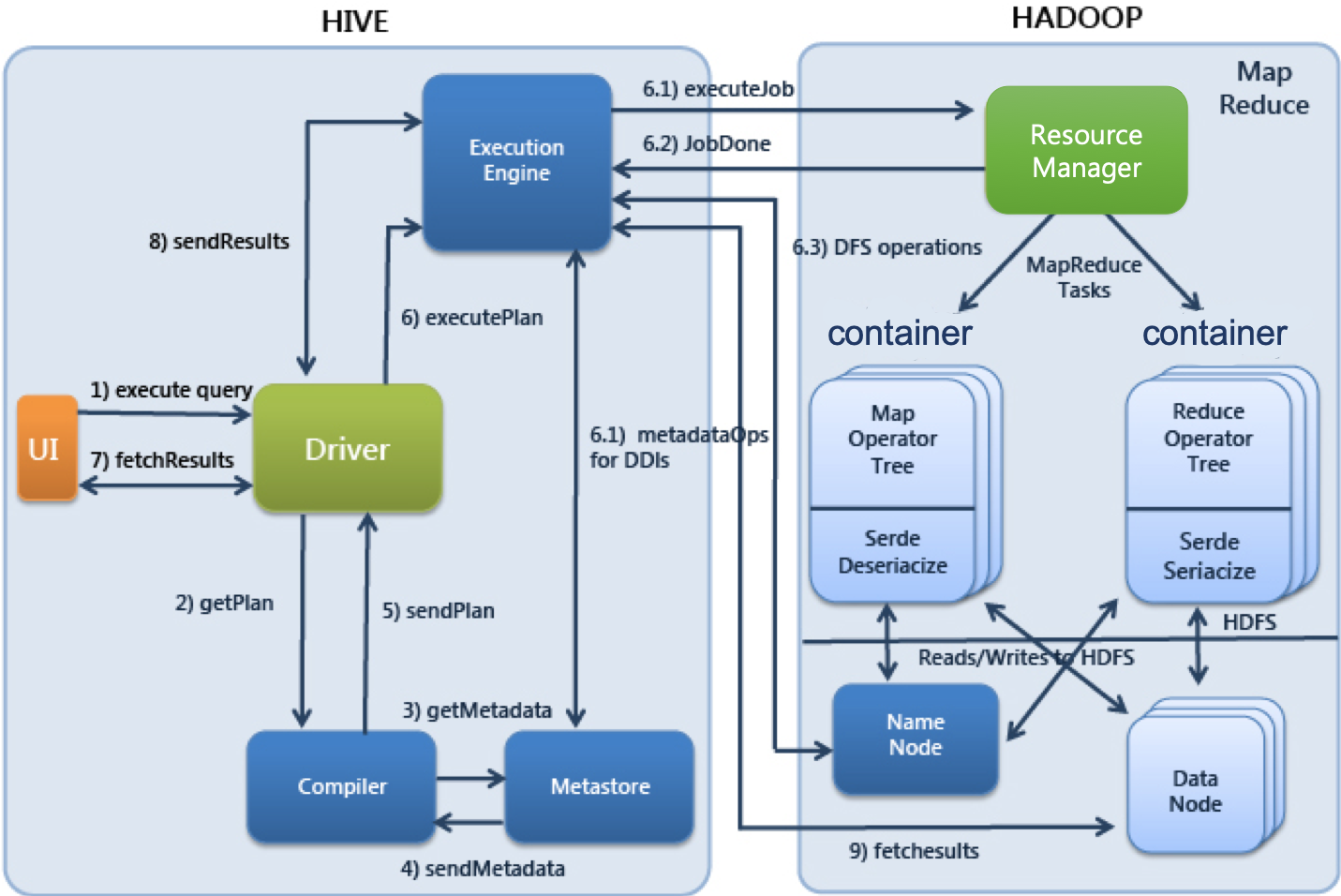
- 사용자가 제출한 SQL문을 드라이버가 컴파일러에 요청하여 메타스토어의 정보를 이용해 처리에 적합한 형태로 컴파일
- 컴파일된 SQL을 실행엔진으로 실행
- 리소스 매니저가 클러스터의 자원(저장된 데이터)을 적절히 활용하여 실행
- 실행 중 사용하는 원천데이터는 HDFS등의 저장장치를 이용
- 실행결과를 사용자에게 반환
❗️ NOTE
HDFS, Hadoop Distributed File System
범용 하드웨어에서 동작하고 장애 복구성을 가지는 분산 파일 시스템
실시간 처리보다는 배치처리를 위해 설계되었으므로 빠른 데이터 응답시간이 필요한 작업에는 적합하지 않다.
Beeline
- SQLLine 기반의 하이브서버2에 접속하여 쿼리를 실행하기 위한 도구.
- JDBC를 사용하여 하이브서버2에 접속한다.
Table
- 하이브의 Database는 테이블의 이름을 구별하기 위한 네임 스페이스 역할을 한다.
- 기본 위치 :
hive.metastore.warehouse.dir = hdfs:///user/hive/ - 데이터 베이스의 기본 위치 :
hdfs:///user/hive/{데이터베이스 명}.db - 테이블의 기본 위치 :
hdfs:///user/hive/{데이터베이스 명}.db/{테이블 명}
- 기본 위치 :
- Table은 HDFS 상에 저장된 파일과 디렉토리 구조에 대한 메타 정보라고 할 수 있다.
데이터 타입
- 기본 원시 타입
- INT, FLOAT, STRING, DATE 등을 지원
- 복합 타입
- array, map, struct, union 지원
- array : 배열 타입, 인덱스로 접근 가능
- map : key-value 사전 타입, 키로 접근 가능
- struct : 자바의 클래스와 유사, 주어진 칼럼의 정보에 필드명으로 접근
- uniontype : 저장한 데이터 타입중 하나를 저장, 출력시에는
{데이터 타입번호:데이터}와 같은 형태로 보여진다.
📌 uniontype
CREATE TABLE union_test(
foo UNIONTYPE<int, double, array<string>, struct<a:int,b:string>>
);
-- 0: int
-- 1: double
-- 2: array<string>
-- 3: struct<a:int, b:string>
SELECT foo FROM union_test;
{0:1}
{1:2.0}
{2:["three","four"]}
{3:{"a":5,"b":"five"}}
{2:["six","seven"]}
{3:{"a":8,"b":"eight"}}
{0:9}
{1:10.0}Insert, Select
- 테이블의 메타 정보에 실제 파일의 로케이션과 데이터 포맷이 저장되어 있다.
테이블 to 디렉토리
테이블 데이터를 조회하여 디렉토리에 파일로 생성하는 방법.
👉 INSERT DIRECTORY : 테이블의 데이터를 읽어서 지정한 위치에 파일을 출력한다.
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
### EXAMPLE
# /user/ 디렉토리에 source 테이블을 읽어서 저장
INSERT OVERWRITE DIRECTORY 'hdfs://1.0.0.1:8020/user/'
SELECT *
FROM source
;
# /user/ 디렉토리에 source 테이블을 읽어서 칼럼 구분을 탭으로 저장
INSERT OVERWRITE DIRECTORY 'hdfs://1.0.0.1:8020/user/'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT *
FROM source
;
# /user/ 디렉토리에 source 테이블을 읽어서 칼럼 구분을 콤마으로 저장하면서 Gzip으로 압축
# 파일을 CSV 형태로 압축하여 저장
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
INSERT OVERWRITE DIRECTORY 'hdfs://1.0.0.1:8020/user/'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT *
FROM source
;
🌱 😈💻 🌱