
Spring Batch Introduction
Background
오픈 소스 소프트웨어 프로젝트와 관련 커뮤니티는 웹 기반 및 마이크로 서비스 기반 아키텍처 프레임워크에 더 많은 관심을 집중했다. 하지만 엔터프라이즈 IT 환경 내에서 프로세싱과 같은 것들을 처리하고자 하는 요구사항이 지속적으로 있었음에도 불구하고, Java 기반의 배치 프로세싱이란 요구를 수용할 수 있는 재사용 가능한 아키텍처 프레임워크에 대한 집중은 부족했다. 재사용 가능한 표준 배치 아키텍처가 없었기에 클라이언트 엔터프라이즈 IT 기능 내에서 개발된 일회성 사내 솔루션들이 확산되었다.
SpringSource(현재의 Pivotal)와 Accenture는 이를 바꾸기 위하여 협력했다. 배치 아키텍처 구현에 있어 Accenture의 산업과 기술 경험, SpringSource의 깊은 기술 경험, 스프링의 입증된 프로그래밍 모델이 함께 자연스럽고 강력한 파트너십을 만들었다. 이는 높은 수준의 시장과 밀접한 소프트웨어를 만들기 위함이었는데 이로인해 엔터프라이즈 자바가 가지는 중요한 격차를 메울 수 있었다. 두 회사는 스프링 기반의 일괄적인 아키텍처 솔루션을 개발하여 유사한 문제를 해결하고자 하고있던 다수의 고객과 협력했다. 이들은 고객이 제기하는 실제 문제에 적용가능한 해결책을 보장하는 추가 세부사항과 실질적인 제약조건을 제공했다.
Accenture는 지원과 개선, 기존의 기능셋을 다루기 위해 커밋 리소스와 함께 이전에 소유했던 배치 처리 아키텍처 프레임워크를 Spring Batch 프로젝트에 기부했다. Accenture가 기부한 것은 COBOL/Mainframe, C++/Unit 등의 마지막 몇 세대에 걸친 플랫폼을 이용해 배치 아키텍처를 구축한 수십년의 경험들이었다.
Accenture와 SpringSource는 기업이 지속적으로 활용가능한 소프트웨어 프로세싱 접근법, 프레임워크, 도구의 표준화를 촉진하는 것을 목표로 배치 어플리케이션을 만들었다. 엔터프라이즈 IT 환경에 입증된 표준 솔루션을 제공하길 원하는 기업과 정부 기관은 스프링 배치의 이점을 활용할 수 있다.
Spring Batch Introduction
엔터프라이즈 도메인 내의 많은 애플리케이션은 미션 크리티컬(사업 운영 또는 단체에 필수적인 요인) 환경에서 비즈니스 운영을 위해 대량 처리를 필요로 한다. 이러한 비즈니스 연산에는 다음과 같은 것들이 포함된다.
- 사용자와의 상호 작용없이 가장 효율적으로 처리되는 대량의 정보에 대한 자동화되고 복잡한 처리. 일반적으로 시간 기반 이벤트(월말 계산, 통지 또는 통신 등)가 포함된다.
- 매우 큰 데이터 집합에 걸쳐 반복적으로 처리되는 복잡한 비즈니스 룰의 정기적 작용(보험급여 결정 또는 요율 조정)
- 일반적으로 formatting, 유효성 검증, 트랜잭션 방식의 처리과정이 필요한 내부 및 외부 시스템에서 수신한 정보를 레코드 시스템으로 통합한다. 배치 프로세싱은 기업에서 매일 발생하는 수십억 건의 거래를 처리하는데 사용된다.
스프링 배치는 엔터프라이즈 시스템의 매일의 운영에 필수적인 강력한 배치 어플리케이션의 개발을 가능하게 하기 위해 고안된 경량적이고 포괄적인 배치 프레임워크다. 스프링 배치는 스프링 프레임워크의 특성(생산성, POJO 기반의 개발 접근법, 일반적인 사용상의 편의성)을 기반으로 구축되며, 필요로 할 때 마다 더욱 발전된 엔터프라이즈 서비스에 쉽게 접근하고 활용할 수 있도록 한다. 스프링 배치는 스케줄링 프레임워크가 아니다. 오픈 소스이며 상용으로 사용가능한 좋은 엔터프라이즈 스케줄러(Quartz, Tivoli, Control-M 등)는 많다. 스프링 배치는 스케줄러를 교체하는 것이 아니라 스케줄러와 함께 작동하는 것이다.
스프링 배치는 logging/tracing, 트랜잭션 관리, 잡 프로세싱 통계, 잡 재시작, 스킵, 리소스 관리 등 대량의 레코드 처리에 필수적이며 재사용가능한 기능을 제공한다. 또한 최적화와 파티셔닝 기법을 사용함에도 대용량 처리와 고성능의 배치 작업을 가능하게하는 고급 기술과 기능을 제공한다. 스프링 배치는 DB로부터 파일을 읽거나 저장 프로시저를 실행하는 것과 같은 단순한 사용 사례뿐만 아니라 DB간 대용량의 데이터 이동과 변환 등 복잡하고 대용량의 사용 사례에서도 모두 사용할 수 있다. 대량의 배치 작업은 상당한 양의 정보를 처리하기 위한 고도의 확장 가능한 방식으로써 프레임워크를 활용할 수 있다.
Usage Scenarios
일반적인 배치 프로그램의 종류는 다음과 같다.
- 데이터베이스, 파일, queue로부터 다량의 자료 읽기
- 어떤 방식으로 데이터를 처리하기
- 수정된 형태로 데이터를 다시 작성하기
스프링 배치는 기본 배치 반복을 자동화하여 일반적으로 사용자와 상호 작용없이 오프라인 환경에서도 유사한 트랜잭션을 세트로 처리 할 수 있는 기능을 제공한다. 배치 작업은 대부분의 IT 프로젝트의 일부이며 Spring Batch는 엔터프라이즈 규모의 강력한 솔루션을 제공하는 유일한 오픈 소스 프레임워크이다.
🔎 Business Scenarios
- 배치 프로세스를 주기적으로 커밋
- 동시적 일괄 처리 : job의 병렬 처리
- 단계적인 엔터프라이즈 message-driven 처리
- 거시적 병렬처리
- 실패 후 수동 또는 예약에 의한 재시작
- 종속 단계의 순차적 처리(워크 플로 중심의 일괄 처리로 확장)
- 부분 처리 : 레코드 스킵(e.g. 롤백)
- 배치 크기가 작거나 기존의 저장 프로시저 or 스크립트가 있는 경우에는 전체 배치를 트랜잭션
🔎 Technical Objectives
- 배치 개발자는 Spring 프로그래밍 모델을 사용하라. 비즈니스 로직에 집중하고 프레임 워크가 인프라를 관리하도록 해야한다.
- 인프라, 배치 실행 환경, 배치 어플리케이션 간의 고려사항을 명확하게 구분하라.
- 모든 프로젝트가 구현할 수 있는 인터페이스로 공통적인 핵심 실행 서비스를 제공하라.
- "즉시 사용 가능한" 핵심 실행 인터페이스의 단순하고 기본적인 구현을 제공하라.
- 모든 계층의 스프링 프레임 워크를 활용해 쉽게 서비스를 구성하고 커스텀마이징과 확장이 가능하다.
- 기존의 모든 핵심 서비스는 인프라 계층에 영향을주지 않고 쉽게 교체하거나 확장 할 수 있어야한다.
- Maven을 사용하여 빌드된 아키텍처 JAR가 애플리케이션과 완전히 분리된 간단한 배치 모델을 제공하라.
Spring Batch Architecture
스프링 배치는 확장성과 다양한 최종 사용자 그룹을 염두에 두고 설계되었다. 아래 그림은 최종 사용자인 개발자를 위한 사용 편의성과 확장성을 지원하는 계층화된 아키텍처를 보여준다.
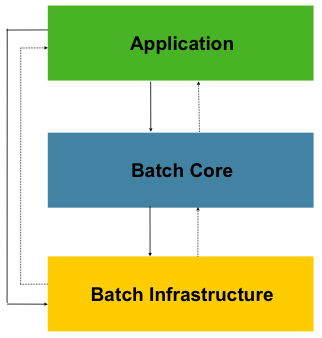
이 계층화된 아키텍처는 세 개의 주요한 구성요소인 어플리케이션, 코어, 인프라를 강조한다. 어플리케이션은 개발자가 스프링 배치를 사용하여 작성한 모든 배치 잡과 커스텀 코드를 포함하고 있다. 배치 코어는 배치 작업을 시작하고 제어하는데 필요한 코어 런타임 클래스를 포함한다(JobLauncher, Job, Step의 구현체 등). 어플리케이션과 코어는 모두 공통 인프라 위에 구축된다. 이 인프라는 어플리케이션 개발자(ItemReader, ItemWriter와 같은 reader나 writer)와 코어 프레임워크(자체 라이브러리인 재시도(retry))에 의해 사용되는 공통 reader, writer, 서비스(e.g. Retry Template)를 포함한다.
General Batch Principles and Guidelines
배치 솔루션을 구축할 때 다음과 같이 핵심 원칙과 지침, 일반적인 고려사항 등을 고려해야한다.
~추가 중~
The Domain Language of Batch
ref. https://docs.spring.io/spring-batch/docs/current/reference/html/domain.html#domainLanguageOfBatch
overall concepts
전문적인 배치 설계자에게 스프링 배치에 사용되는 배치 프로세싱의 전체 개념은 친근하고 편안해야한다. Jobs, Steps, 개발자가 제공하는 프로세싱 유닛은 ItemReader/ItemWriter이라고 불린다. 그러나 스프링 패턴, 연산, 템플릿, 콜뱃, idioms에 의해 다음과 같은 것들을 할 수 있게되었다.
- 확실한 고려사항 분리에 대한 개선
- 아키텍처 계층과 서비스를 명확하게 묘사하는 인터페이스 제공
- 간단한 기본 구현으로 신속하게 선택하고 사용
- 확장성의 향상
다음의 다이어그램은 수십 년 동안 사용된 batch reference architecture의 단순화된 버전이다. 이는 배치 프로세싱의 도메인 언어를 구성하는 컴포넌트의 전반적인 개요를 제공한다. 이 아키텍처 프레임 워크는 지난 몇 세대의 플랫폼 (COBOL/Mainframe, C/Unix, 현재의 Java/anywhere)에서 수십 년에 걸친 구현을 통해 입증된 청사진이다. JCL, COBOL 개발자는 C, C#, Java 개발자와 같은 개념에 익숙할 것이다. 스프링 배치는 매우 복잡한 프로세싱 요구사항을 해결하기 위한 인프라와 확장 기능을 통해 복잡한 배치 어플리케이션을 간단하게 생성하기 위해 사용되는, 일반적으로 강력하고 유지보수되는 시스템에서 찾을 수 있는 레이어, 컴포넌트, 기술적 서비스의 물리적인 구현을 제공한다.
너무 길어서 한국말로 써도 뭐라는지 모르겠음.. 원문은 이거임 👉 Spring Batch provides a physical implementation of the layers, components, and technical services commonly found in the robust, maintainable systems that are used to address the creation of simple to complex batch applications, with the infrastructure and extensions to address very complex processing needs.
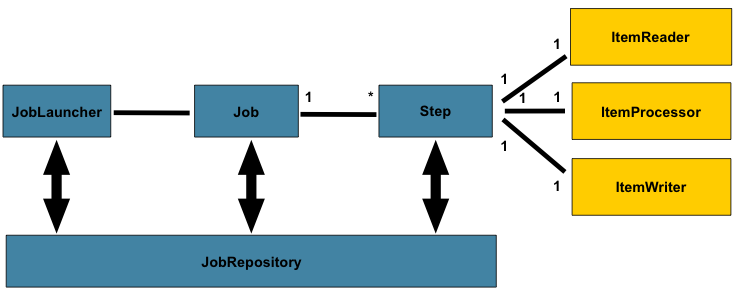
위의 다이어그램은 스프링 배치의 도메인 언어를 구성하는 주요 개념을 강조한다. ❗️하나의 Job에는 하나 혹은 여러 Step이 있으며, 각 Step에는 정확히 하나의 ItemReader, ItemProcessor, ItemWriter가 있다. job은 JobLauncher로 시작되고 현재실행 중인 프로세스에 대한 메타 데이터를 JobRepository에 저장해야한다.
Job
이 섹션에서는 배치 잡의 개념과 관련된 일반적인 종류의 정의에 대해 설명한다. 잡은 전체 배치 프로세스를 캡슐화하는 엔터티이다. 다른 스프링 프로젝트와 마찬가지로 잡은 XML 구성이나 자바 기반 구정과 함께 연결되며 이 구성을 Job configuration이라고 한다. 하지만 잡은 다음 다이어그램에 표시된 것처럼 전체 계층 구조의 최상위이다.
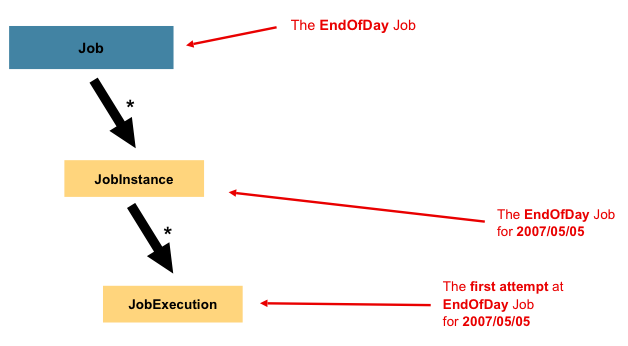
스프링 배치에서 잡은 (단순하게는) 스탭 인스턴스를 위한 컨테이너이다. 논리적으로 하나의 흐름에 속하는 여러 스탭을 결합하고 재시작 가능성과 같은 모든 단계에 걸쳐 전체 범위의 속성을 구성할 수 있다. Job configuration에는 다음이 포함된다.
- 잡의 간단한 이름
- 스탭 인스턴스의 정의 및 순서
- 잡을 다시 시작할 수 있는지에 대한 여부
잡 인터페이스의 기본적인 간단한 구현체는 SimpleJob 클래스의 형태로 제공되며 Job 위에 일부 표준 기능을 생성한다. 자바 기반 구성을 사용하는 경우, 다음 예제처럼 builders 콜렉션을 이용해 사용가능한 잡 인스턴스를 만들 수 있다.
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}JobInstance
JobInstance는 논리적인 잡 실행이다. 앞의 다이어그램에서 'EndOfDay' 잡과 같이 하루가 끝날 때 한 번 실행되어야하는 배치 작업을 생각해보라. 하나의 'EndOfDay' 잡이 있지만, 각 잡은 개별적인 실행으로 추적해야한다. 이 잡의 경우 하루에 하나의 논리적인 JobInstance가 있다. 예를 들어 1월 1일 실행, 1월 2일 실행 등이 있다. 1월 1일 실행이 처음에 실패하고 다음날 다시 실행되는 경우, 여전히 이는 1월 1일에 대한 실행이다. (일반적으로 1월 1일 실행이 1월 1일 데이터를 처리한다는 의미에서도 처리하고 있는 데이터와 일치한다.) 따라서 각 JobInstance는 여러번 실행될 수 있으며 (JobExecution은 이 장의 뒷부분에서 자세히 설명한다.) 특정 잡에 해당하고 JobParameter을 식별하는 JobInstance는 한 번에 하나만 실행될 수 있다.
JobInstance의 정의는 로드될 데이터와 전혀 관련이 없다. 어떻게 데이터를 가져오느냐는 전적으로 ItemReader의 구현에 달려있다. 예를 들어 'EndOfDay' 시나리오에서 데이터에 속하는 '유효 날짜'나 '일정 날짜'를 나타내는 컬럼이 데이터에 존재할 수 있다. 따라서 1월 1일 실행은 1일의 데이터만 로드해야하고 1월 2일 실행은 2일의 데이터만 사용해야한다. 이러한 결정은 사업상의 결정이 될 가능성이 높기 때문에, ItemReader에게 맡겨진다. 하지만 같은 JobInstance를 사용하면 이전 실행의 'state'(이 장 뒷부분에서 설명할 ExecutionContext)를 사용할지 여부를 결정한다. 새로운 JobInstance를 사용한다는 것은 '처음부터 시작함'을 의미하며 기존의 인스턴스를 사용한다는 것은 일반적으로 '끝났던 부분부터 시작'을 의미한다.
JobParameters
JobInstance와 잡이 어떻게 다른지에 대해 논의하였으니 당연히 "한 JobInstance가 다른 것들과 어떻게 구별되는가?"라는 질문을 하게 될 것이다. 이에 대한 답이 JobParameters이다. JobParameters 오브젝트는 배치 잡을 시작하는데 필요한 파라미터 셋을 가지고 있다. JobParameters는 다음 이미지와 같이 실행 중에 식별하거나 참조하는 데이터로 사용된다.
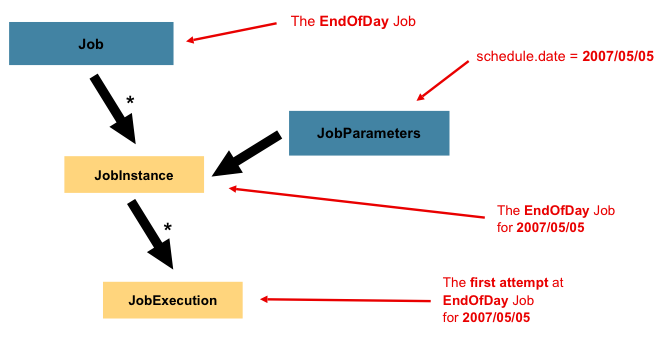
앞의 예에서 1월 1일과 1월 2일을 위한 두 개의 인스턴스가 있는 경우, 실제로는 하나의 잡만 있지만 두 개의 JobParameters가 존재한다. 하나는 '01-01-2017' JobParameters로 시작할 것이며 또 다른 하나는 '01-02-2017'로 시작할 것이다. 따라서 계약은 다음처럼 정의될 수 있다.
JobInstance = Job + 고유한 JobParameters
이를 통해 개발자는 어떤 매개 변수를 전달할지 제어함으로써 JobInstance가 정의되는 방법을 효과적으로 제어할 수 있다.
❗️ NOTE
모든 JobParameters가 JobInstance를 식별하는데 필수적인 것은 아니다. 디폴트가 그렇다. 프레임워크는 JobInstance의 식별에 기여하지 않는 매개변수를 Job에 전달할 수도 있다.
JobExecution
JobExecution은 잡을 한 번 실행한다는 "기술적인 개념"을 나타낸다. 실행은 실패하거나 성공할 수 있지만, 해당 실행의 JobInstance는 성공하지 못한 실행은 완료된 것으로 간주하지 않는다. 이전에 예로 들었던 'EndOfDay' 잡을 생각해보자. 처음 시도에 실패한 '01-01-2017'에 대한 JobInstance가 있다. 첫 번째 실행과 동일한 job parameters를 사용해 다시 실행하면 새로운 JobExecution가 만들어지지만, JobInstance는 여전히 하나이다.
1️⃣ 잡은 잡의 정의와 실행 방법을 정의한다. 2️⃣ JobInstance는 주로 올바른 재시작 시맨틱을 활성화하기 위해 실행을 그룹화하는 순수하게 조직적인 개체다. 하지만 3️⃣ JobExecution는 실행 중에 실제로 발생한 일에 대한 기본적인 저장 메커니즘이며 다음 표와 같이 제어하고 유지해야하는 더 많은 프로퍼티들을 포함하고 있다.
| Property | Definition |
|---|---|
| Status | A BatchStatus object that indicates the status of the execution. While running, it is BatchStatus#STARTED. If it fails, it is BatchStatus#FAILED. If it finishes successfully, it is BatchStatus#COMPLETED |
| startTime | A java.util.Date representing the current system time when the execution was started. This field is empty if the job has yet to start. |
| endTime | A java.util.Date representing the current system time when the execution finished, regardless of whether or not it was successful. The field is empty if the job has yet to finish. |
| exitStatus | The ExitStatus, indicating the result of the run. It is most important, because it contains an exit code that is returned to the caller. See chapter 5 for more details. The field is empty if the job has yet to finish. |
| createTime | A java.util.Date representing the current system time when the JobExecution was first persisted. The job may not have been started yet (and thus has no start time), but it always has a createTime, which is required by the framework for managing job level ExecutionContexts. |
| lastUpdated | A java.util.Date representing the last time a JobExecution was persisted. This field is empty if the job has yet to start. |
| executionContext | The "property bag" containing any user data that needs to be persisted between executions. |
| failureExceptions | The list of exceptions encountered during the execution of a Job. These can be useful if more than one exception is encountered during the failure of a Job. |
이러한 프로퍼티는 영속적이며 실행 상태를 완전히 결정하는 데 사용될 수 있다. 예를 들어 01-01에 대한 EndOfDay 작업이 오후 9:00에 실행되어 9:30에 실패하면 배치 메타데이터 테이블에 다음과 같은 항목이 입력된다.
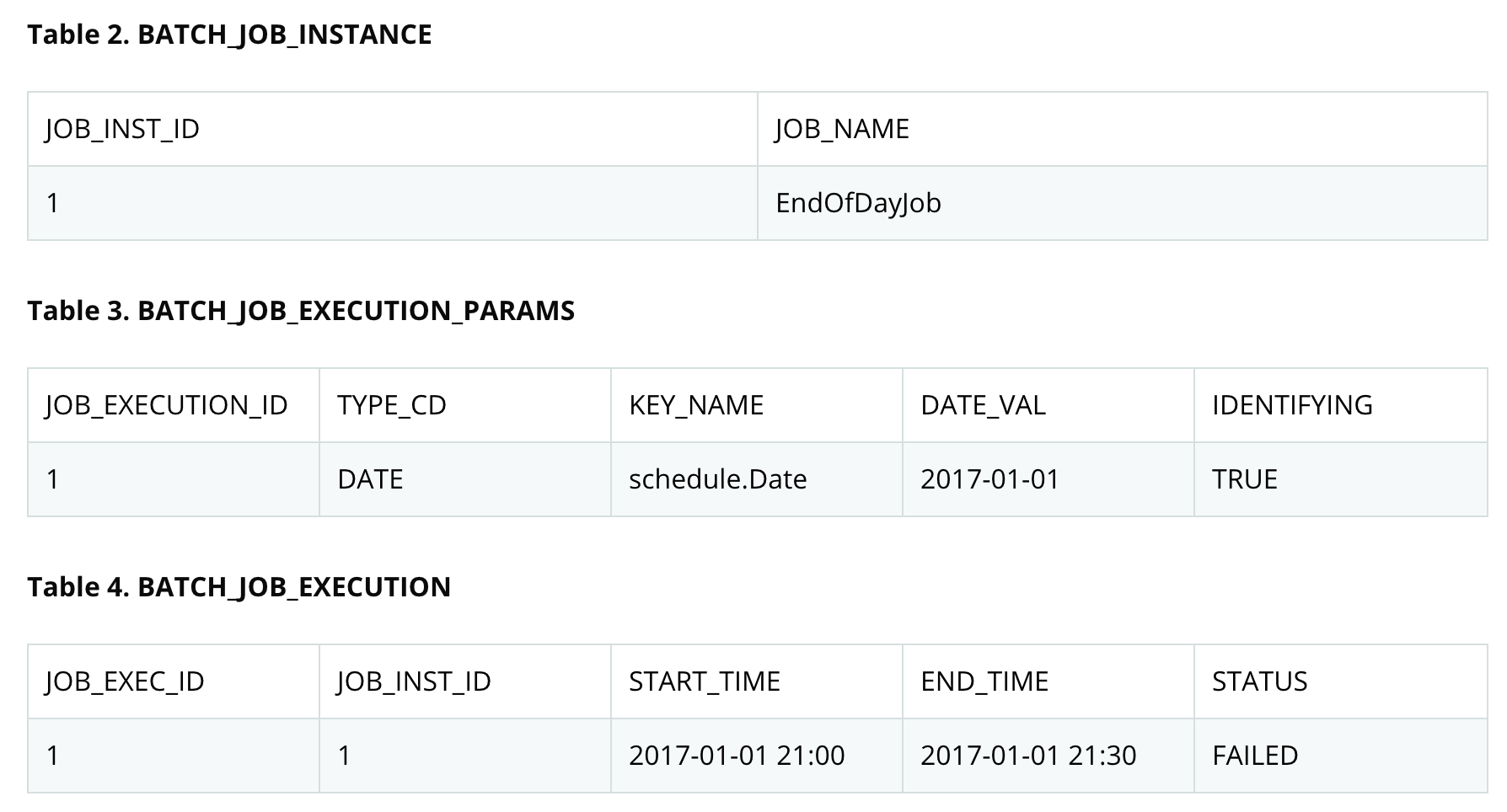
컬럼 이름은 명확성과 포맷을 위해 축약하거나 제거되었을 수 있다.
작업이 실패하고 문제를 알아내는데 밤새 걸렸기에 배치 창은 닫혔다고 가정하자. 윈도우가 오후 9시에 시작한다고 가정하면 작업은 01-01에 대해 중단된 위치에서 다시 시작하여 9시 30분에 성공적으로 완료된다. 지금은 다음날이므로 01-02 작업이 9시 31분에 시작하여 10시 31분에 (정상적인 실행시간인 1시간이 걸려서) 완료된다.
두 작업이 동일한 데이터에 액세스 할 가능성이 없으면 데이터베이스 레벨에서 lock에 문제가 발생하지 않는 한 하나의 JobInstance를 차례대로 시작할 필요가 없다. 작업 실행시기를 결정하는 것은 전적으로 스케줄러의 책임이다. Spring Batch는 별도의 JobInstance가 동시에 실행되는 것을 중지하지 않는다. (다른 Job이 이미 실행중인 동안 동일한 JobInstance를 실행하려고하면 JobExecutionAlreadyRunningException이 발생한다).
결과적으로 다음 표와 같이 현재 JobInstance 및 JobParameters 테이블에 추가 항목이 있고 JobExecution 테이블에 추가 항목이 두 개 있어야한다.
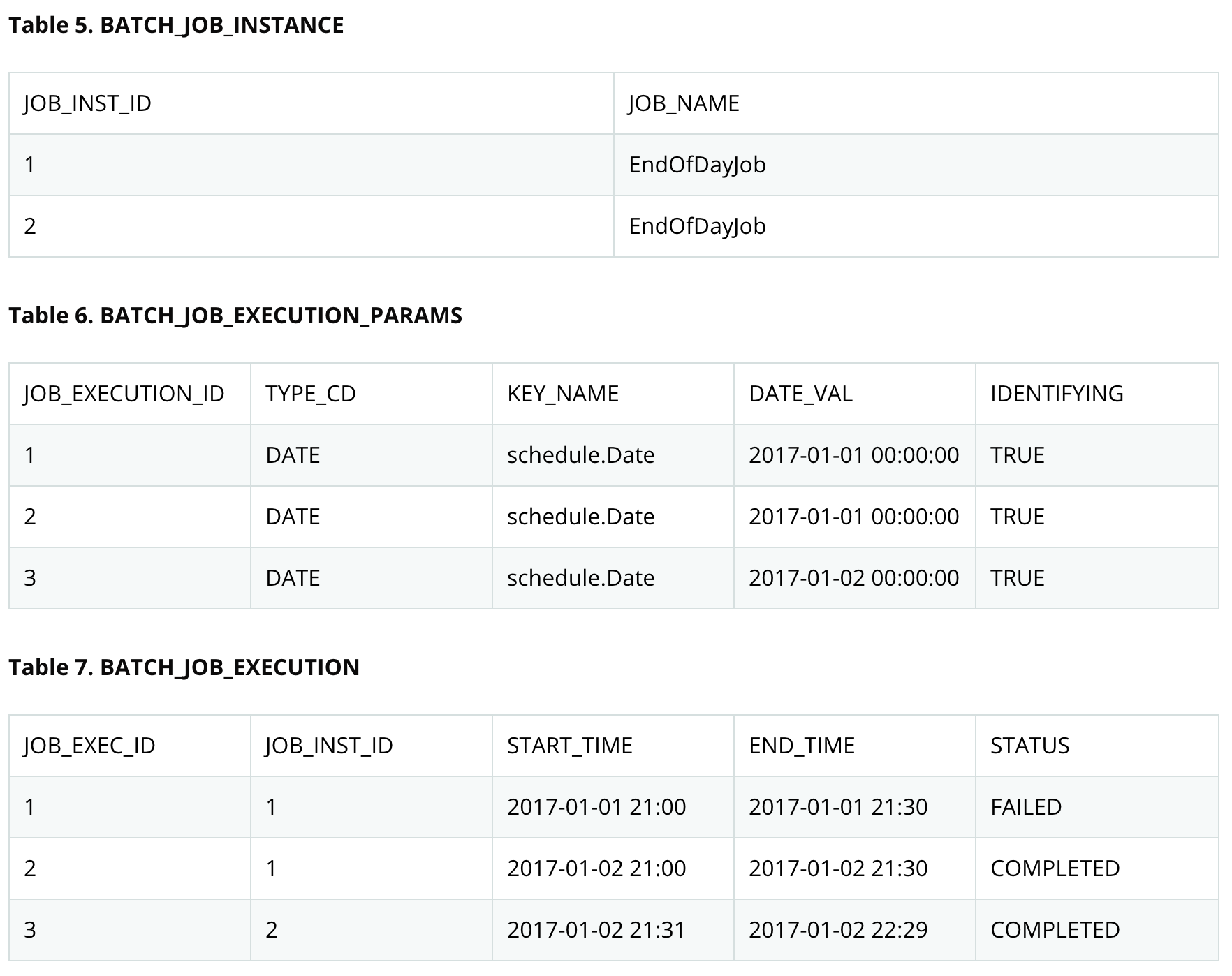
2020.06.27 추가
Step
스탭은 배치 잡의 독립적인 순차 phase를 캡슐화하는 도메인 오브젝트이다. 따라서 모든 잡은 하나 혹은 그 이상의 스탭으로 구성된다. 스탭은 실제 배치 프로세싱을 정의하고 제어하는데 필요한 모든 정보를 가지고 있다. 주어진 스탭의 내용은 Job을 작성하는 개발자의 재량에 달려있기 때문에 이것은 필연적으로 모호한 설명이다. 스탭은 개발자가 원하는만큼 간단 할 수도, 복잡 할 수도 있다. 간단한 스탭은 아마 최소한이나 아예 없는 코드로(사용된 구현체에 의존하여) 파일로부터 데이터 베이스에 데이터를 로드할 것이다. 좀 더 복잡한 스탭은 아마 처리시에 일부로 사용되는 복잡한 비즈니스 룰을 가질 것이다. Job과 마찬가지로 Step에는 고유한 JobExecution과 상관관계가 있는 개별 StepExecution이 있다.
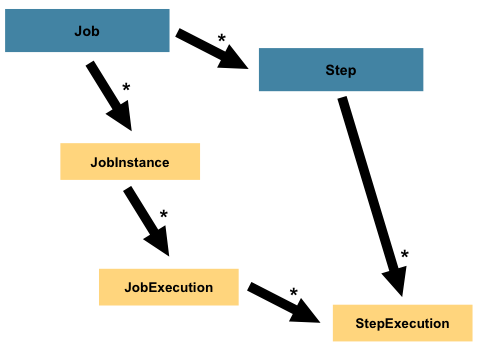
StepExecution
StepExecution는 스탭을 실행하기 위한 한 번의 시도를 나타낸다.* 새로운 StepExecution는 JobExecution와 유사하게 스탭이 실행되는 각각의 시점에 만들어진다. 만약 스탭이 실패하여 실행이 실패한다면 이는 지속되지 않는다. 즉, StepExecution는 스탭이 실제로 시작된 경우에만 만들어진다.
스탭의 실행은 StepExecution 클래스의 오브젝트로 표현된다. 각 실행에는 해당 스탭, JobExecution, 관련 데이터의 트랜젝션(커밋 및 롤백 카운트, 시작 및 종료 시간)에 대한 참조가 포함된다. 추가적으로 각 StepExecution은 ExecutionContext를 포함하는데 여기에는 개발자가 필요로하는 배치 실행 전반에 걸쳐 지속돼야하는 모든 데이터 (e.g. 통계 또는 다시 시작하는데 필요한 상태 정보)가 포함된다. 다음 표는 StepExecution의 프로퍼티에 대한 목록이다.
| Property | Definition |
|---|---|
| Status | A BatchStatus object that indicates the status of the execution. While running, the status is BatchStatus.STARTED. If it fails, the status is BatchStatus.FAILED. If it finishes successfully, the status is BatchStatus.COMPLETED. |
| startTime | A java.util.Date representing the current system time when the execution was started. This field is empty if the step has yet to start. |
| endTime | A java.util.Date representing the current system time when the execution finished, regardless of whether or not it was successful. This field is empty if the step has yet to exit. |
| exitStatus | The ExitStatus indicating the result of the execution. It is most important, because it contains an exit code that is returned to the caller. See chapter 5 for more details. This field is empty if the job has yet to exit. |
| executionContext | The "property bag" containing any user data that needs to be persisted between executions. |
| readCount | The number of items that have been successfully read. |
| writeCount | The number of items that have been successfully written. |
| commitCount | The number of transactions that have been committed for this execution. |
| rollbackCount | The number of times the business transaction controlled by the Step has been rolled back. |
| readSkipCount | The number of times read has failed, resulting in a skipped item. |
| processSkipCount | The number of times process has failed, resulting in a skipped item. |
| filterCount | The number of items that have been 'filtered' by the ItemProcessor. |
| writeSkipCount | The number of times write has failed, resulting in a skipped item. |
ExecutionContext
ExecutionContext은 개발자가 StepExecution 오브젝트 또는 JobExecution 오브젝트로 범위가 지정된 영속 상태를 저장하기 위해서 프레임워크에 의해 유지되고 제어되는 키/값 쌍 컬렉션을 나타낸다. (Quartz의 JobDataMap과 매우 유사하다.) 가장 좋은 사용 예는 재시작을 용이하게 하는 것이다. 예를 들어 플랫 파일을 추가하는 경우에 개별 라인을 처리하는 동안 프레임워크는 커밋 지점에서 주기적으로 ExecutionContext를 유지한다. 이렇게 하면 ItemReader는 실행 중에 치명적인 오류가 발생하거나 전원이 꺼진 경우에도 상태를 저장할 수 있다. 다음 예제처럼 현재 읽은 라인을 컨텍스트에 넣으면 프레임워크가 나머지를 수행한다.
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());Job Stereotypes 섹션의 예인 EndOfDay 예제를 사용했을 때, 파일을 데이터베이스에 로드하는 'loadData' 단계가 있다고 가정해보자. 첫번째 실행 실패 후 메타 데이터 테이블은 다음과 같다.
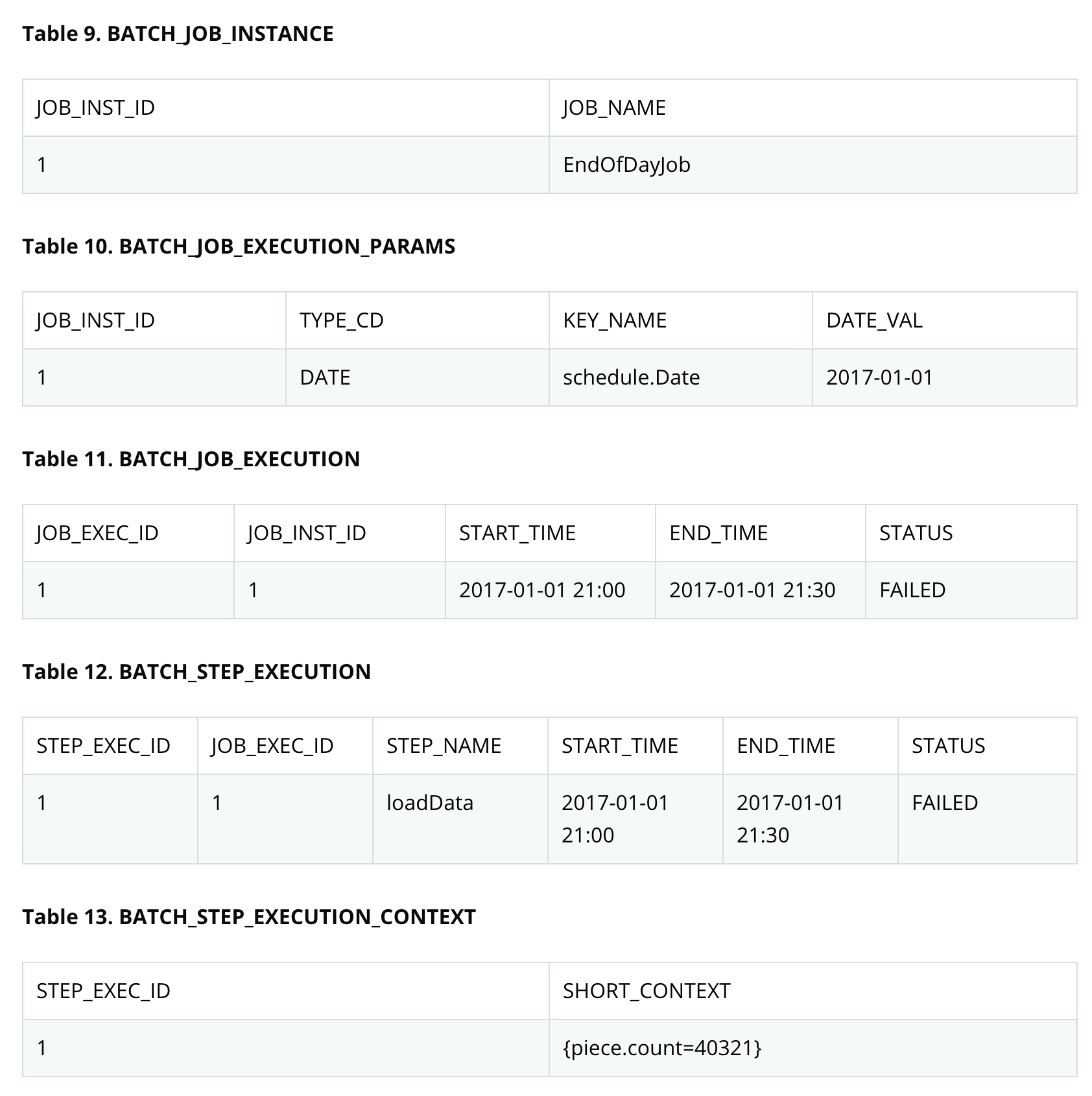
이 때 스탭은 30분 동안 40,321개의 'pieces'를 처리했는데 이는 시나리오 내 파일에서의 각 라인을 나타낸다. 이 값은 프레임워크에 의해 각 커밋 직전에 업데이트되며 ExecutionContext 내의 항목에 해당하는 여러 행을 포함할 수 있다. 커밋 전에 알림을 받으려면 다양한 StepListener 구현체 중 하나(또는 ItemStream)가 필요하며 이는 가이드의 뒷부분에서 자세히 설명한다. 이전 예제와 마찬가지로 잡은 다음 날에 재시작되는 것으로 가정한다. 재시작되면 마지막으로 실행된 ExecutionContext의 값이 데이터 베이스에서 재구성된다. ItemReader가 열리면 컨텍스트에서 모든 저장된 상태를 가지고 있는지 확인할 수 있고, 다음 예처럼 자신을 초기화한다.
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}이 경우 위의 코드가 실행된 후 현재 행은 (이전에 40,321까지 처리했기에) 40,322이 되므로 중단된 위치부터 스탭을 시작할 수 있다. 또한 ExecutionContext는 지속할 필요가 있는 실행 통계로 이용될 수 있다. 예를 들어, 플랫 파일에 여러 줄에 걸쳐 존재하는 처리 명령이 포함된 경우 처리된 주문 수(읽은 행 수와 다름)를 저장해 본문에서 처리된 총 주문 개수를 스탭이 종료될 때 email로 보내도록 할 수 있다. 프레임워크는 이를 올바르게 적용하기 위해 개별 JobInstance를 사용하여 ExecutionContext를 저장하는 작업을 처리한다.
존재하는 ExecutionContext의 사용 여부를 아는 것은 매우 어려울 수 있다. 예를 들어 위의 'EndOfDay' 예제에서 01-01 실행이 두 번째로 다시 시작되면 프레임 워크는 동일한 JobInstance 및 개별 스탭을 인식하고 데이터베이스에서 ExecutionContext를 가져온다. 그리고 (StepExecution의 일부로써) Step 자체에 전달한다. 반대로 01-02 실행의 경우 프레임워크는 다른 인스턴스임을 인식하므로 빈 컨텍스트를 스탭으로 전달해야한다.
프레임워크에는 개발자에게 정확한 시간에 상태가 제공되도록 하기 위해 만드는 여러 유형의 결정들이 많다. 주어진 시간의 StepExecution마다 정확히 하나의 ExecutionContext가 존재한다는 점도 중요하다. ExecutionContext의 클라이언트는 공유 키 공간을 생성하므로 주의해야한다. 결과적으로 데이터를 덮어 쓰지 않도록 값을 넣을 때 주의를 기울여야한다. 하지만 스탭은 컨텍스트에 데이터를 전혀 저장하지 않으므로 프레임 워크에 부정적인 영향을 줄 수 없다.
또한 각 JobExecution와 모든 StepExecution당 하나 이상의 ExecutionContext가 있다는 점을 유념해야 한다. 예를 들어, 다음 코드를 고려해보라.
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob코멘트에 언급된 바와 같이 ecStep은 ecJob과 같지 않다. 이들은 서로 다른 실행 컨텍스트들이다. "Step"에 대한 범위 지정은 Step의 모든 "커밋 지점"에 저장되고 "Job"에 대한 범위 지정은 Step "실행 시마다" 저장된다.
JobRepository
JobRepository는 위에서 언급한 모든 스테레오 타입들을 지속하는 메커니즘이다. JobRepository는 JobLauncher, Job, Step 구현을 위한 CRUD 작업을 제공한다. Job이 처음 실행되면 레파지토리에서 JobExecution을 획득하고, 실행 과정에서 StepExecution 및 JobExecution 구현체를 저장소에 전달함으로써 이들을 지속한다.
자바 구성을 사용할 때 @EnableBatchProcessing 어노테이션은 자동으로 구성된 구성 요소 중 하나로써 기본적으로 JobRepository를 제공한다.
JobLauncher
JobLauncher는 주어진 JobParameter 세트로 Job을 시작하기 위한 간단한 인터페이스를 나타낸다.
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}구현체는 JobRepository에서 유효한 JobExecution을 얻고 잡을 실행할 것이다.
Item Reader
ItemReader는 한 번에 하나씩 스탭에 대한 입력의 반환값을 보여주는 추상체이다. ItemReader가 제공할 수 있는 것이 더이상 없으면 Null을 반환하여 이를 표시한다. ItemReader 인터페이스와 다양한 구현에 대한 자세한 내용은 Readers and Writers에서 확인할 수 있다.
Item Writer
ItemWriter는 한 번에 하나의 배치 또는 여러 아이템의 스탭의 output을 나타내는 추상체다. 일반적으로 ItemWriter는 다음에 받아야 할 입력에 대한 지식이 없으며 현재 호출에서 전달된 항목만 알고 있다. ItemWriter 인터페이스와 다양한 구현에 대한 자세한 내용은 Readers and Writers에서 확인할 수 있다.
Item Processor
ItemProcessor는 아이템의 비즈니스 처리를 나타내는 추상체다. ItemReader가 한 항목을 읽고 ItemWriter가 이를 작성하는 동안, ItemProcessor는 다른 비즈니스 프로세싱를 변환하거나 적용할 수 있는 액세스 포인트를 제공한다. 아이템을 처리하는 동안 해당 아이템이 유효하지 않다고 판단되는 경우, null을 반환하고 이는 해당 항목이 기록되지 않아야 함을 나타낸다. ItemProcessor 인터페이스에 대한 자세한 내용은 Readers and Writers에서 확인할 수 있다.
