APACHE kafka를 번역합니다.
Introduction
event streming이란?
이벤트 스트리밍이란 인체의 중추 신경계와 같다.
즉, 비즈니스가 더욱 소프트웨어화, 자동화됨에 따라 소프트웨어의 사용자가 더 많은 소프트웨어를 사용하는 '상시 가동' 세계에서의 기반 기술이다.
기술적으로 이야기하자면 이벤트 스트리밍은 데이터베이스, 센서, 모바일 장치, 클라우드 서비스, 소프트웨어 어플리케이션과 같은 이벤트 소스에서 실시간 데이터를 이벤트 스트림의 형태로 캡처하는 것이다. 이러한 이벤트 스트림은 지속적으로 저장되며 나중에 검색을 통해 가져 올 수도 있다. 또한 과거데이터부터 실시간 데이터까지 조작, 처리, 반응하며 필요에 따라 이벤트 스트림을 다른 기술로 라우팅한다.
따라서 이벤트 스트리밍은 데이터의 지속적인 흐름과 이해를 보장하며 적절한 정보가 적절한 장소에 적시 제공되도록 한다.
아파치 카프카는 분산 스트리밍 플랫폼이다.
스트리밍 플랫폼은 세 개의 주요 기능을 가지고 있다.
- 메세지 큐나 전사 메세징 시스템과 유사한 레코드 스트림의 발행과 구독
- 내결함성과 내구성이라는 두가지 방식의 장애 허용 시스템에 레코드 스트림 저장
- 자체에서 발생되는 레코드 스트림의 처리
❗️ NOTE
장애 허용 시스템 (Fault tolerance) = 결함 감내 시스템
시스템을 구성하는 부품의 일부에서 결함 또는 고장이 발생하여도 정상적 혹은 부분적으로 기능을 수행할 수 있는 시스템.
카프카는 일반적으로 두 가지 광범위한 클래스의 응용 프로그램에 사용된다.
- 시스템과 어플리케이션 사이에서 데이터를 확실히 가져오는 실시간 스트리밍 데이터 파이프라인 구축
- 데이터 스트림에 반응하거나 변환하는 실시간 스트리밍 어플리케이션 구축
어떻게 카프카가 이런 일들을 할 수 있는지 이해하기 위해 아래에서 Kafka의 기능에 대해 자세히 알아본다.
카프카가 어떻게 작동하는지 간단히 알아보자 🤔
우선 몇 가지 개념을 훑어보자 :
- 카프카는 여러 데이터 센터에 걸쳐있는 하나 이상의 서버에서 클러스터로 실행된다.
- 카프카의 클러스터는 토픽이라고 불리는 카테고리 내에 레코드 스트림을 저장한다.
- 각 레코드는 하나의 키, 값, 타임스탬프로 구성된다.
카프카는 고성능 TCP 네트워크 프로토콜로 통신하는 서버와 클라이언트로 구성된 분산 시스템이다. 클라우드 환경 뿐만아니라 on-premise(기업이 서버를 클라우드 환경이 아닌 자체 설비로 보유하고 운영한다)에서도 bare-metal 하드웨어(소프트웨어가 설치되어 있지 않은 컴퓨터 하드웨어), VM, 컨테이너에 배포할 수 있다.
📌 Servers
kafka는 여러 데이터센터나 클라우드 지역에 걸쳐있을 수 있는 하나 이상의 서버 클러스터로 실행된다. 이러한 서버 중 일부는 broker라고하는 storage 계층을 형성한다. 다른 서버는 Kafka Connect를 실행하여 데이터를 이벤트 스트림으로 지속적으로 가져오고 내보냄으로써 RDB나 다른 Kafka 클러스터와 같은 기존에 사용중이던 시스템과 이를 통합한다. 작업 수행에 필수적인 use case를 구현할 수 있도록 Kafka 클러스터는 높은 확장성과 내결함성을 가진다.: 만약 서버 중 하나에 장애가 발생하면 다른 서버가 작업을 대신함으로써 데이터 손실없이 지속적인 운영을 보장한다.
📌 Clients
네트워크 문제나 머신 장애가 발생하는 경우에도 내결함성 방식으로 대규모의 이벤트 스트림을 읽고, 쓰고, 처리하는 분산 어플리케이션과 마이크로서비스를 작성할 수 있다. kafka 커뮤니티에서 제공하는 수십 개의 클라이언트에 의해 증축된 kafka는 일부 그러한 클라이언트를 포함한다.: 클라이언트는 REST API 뿐만아니라 Go, Python, C/C++ 및 다른 프로그래밍 언어를 위한 높은 수준의 kafka 스트림 라이브러리를 포함하는 Java와 Scala에서 이용될 수 있다.
주요 개념과 용어
이벤트는 비즈니스에서 "무언가가 일어났다"는 사실을 기록한다. 이는 도큐먼트에서 record나 message라고 불리기도 한다. Kafka에서는 이벤트의 형식으로 데이터를 읽거나 쓴다. 개념적으로 이벤트는 키, 값, 타임스탬프, 선택적 메타데이터 헤더를 가진다.
Example :
Event key: "Alice"
Event value: "Made a payment of $200 to Bob"
Event timestamp: "Jun. 25, 2020 at 2:06 p.m."producer는 kafka에 이벤트를 게시하는(작성하는) 클라이언트 어플리케이션이며, consumer는 이러한 이벤트를 구독한다(읽고 처리한다). kafka에서 producer와 consumer는 완전히 분리되며 서로를 인식할 수 없는데 이로인해 Kafka는 높은 확장성을 가질 수 있다. (예를 들어, producer는 consumer를 기다릴 필요없다.) Kafka는 이벤트를 정확하게 한 번 처리하는 것과 같은 다양한 요소를 보증한다.
이벤트는 구성되고 지속적으로 topic에 저장된다. 단순하게 말하자면 topic은 파일시스템의 폴더와 유사하며 event는 해당 폴더의 파일이다. 위의 예제에서 topic의 이름은 "payments"일 수 있다.
kafka에서 topic은 항상 multi-producer이며 multi-subscriber이다.: topic은 (이벤트를 작성하는) 0개, 1개, 혹은 그 이상의 producer와 (이벤트를 구독하는) 0개, 1개, 혹은 그 이상의 consumer를 가질 수 있다. topic 내 event는 필요에 따라 자주 읽을 수 있으며, 기존 메시징 시스템과 달리 사용 후에도 이벤트가 삭제되지 않는다. 대신 topic 별 구성에서 이벤트를 유지하는 기간을 설정할 수 있고 오래된 이벤트는 삭제될 것이다. kafka의 성능은 데이터 크기와 무관하게 효과적으로 유지되므로 장기간 데이터를 저장하기에 완벽하다.
topic은 분할되어있다. 즉, topic은 서보다른 kafka 브로커에 있는 여러 "bucket"에 분산되어 있다. 데이터의 분산 배치는 클라이언트 어플리케이션이 동시에 여러 브로커에서 데이터를 읽고 쓸 수 있도록하므로 확장성에 매우 중요하다. 새 이벤트가 topic에 게시되면 실제로 topic의 파티션 중 하나에 추가된다. 동일한 이벤트 키(e.g. 고객ID, 차량ID ..)를 가진 이벤트는 동일한 파티션에 기록된다. 또한, kafka는 어떤 topic(파티션)의 consumer가 항상 해당 파티션에 작성된 것과 동일한 순서로 이벤트를 읽을 수 있음을 보장한다.
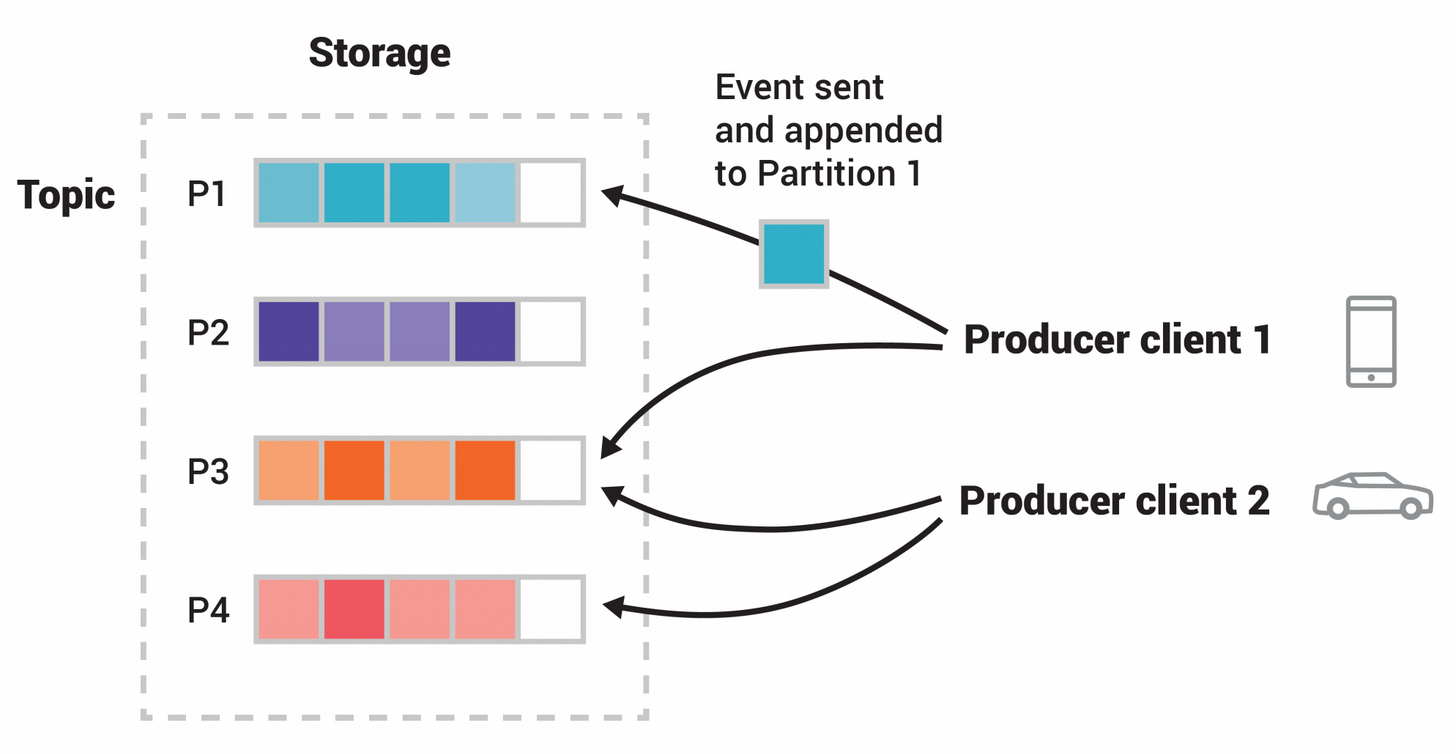
위 그림에는 4개의 파티션 P1-P4가 있다. 두 개의 다른 producer 클라이언트가 네트웍을 통해 topic의 파티션에 독립적으로 "event를 작성"하고 있다. 동일한 키(그림에서 색상으로 표시)를 가진 이벤트는 동일한 파티션에 기록된다. 두 producer는 적절한 경우에 동일한 파티션에 이벤트를 쓸 수 있다.
모든 topic은 지역적 영역이나 데이터 센터에 걸쳐 복제할 수 있으므로 문제가 발생할 경우를 대비하여 데이터 사본을 보유한 여러 broker를 유지보수하며 데이터의 내결함성과 가용성이 증대시킨다. 일반적인 프로덕션 셋팅은 3개의 데이터 사본을 유지하는 것이다. 이는 topic의 파티션 수준에서 수행된다.
Kafka API
카프카의 다섯가지 핵심 APIs :
- Producer API
어플리케이션이 하나 이상의 카프카 토픽에 대한 레코드 스트림을 발행하도록 한다. - Consumer API
어플리케이션이 하나 이상의 토픽을 구독하고 그것들에 의해 생성된 레코드 스트림을 처리하도록 한다. - Streams API
어플리케이션이 하나 이상의 토픽에서 인풋 스트림을 소비하고 하나 이상의 반환토픽으로 아웃풋 스트림을 생성하기 위해 인풋 스트림을 아웃풋 스트림으로 효과적으로 변환한다. - Connector API
카프카 토픽을 기존의 어플리케이션 혹은 데이터 시스템에 연결하는 재사용가능한 producer와 consumer를 구축하고 실행시킨다. 예를 들어, 관계형 데이터 베이스로의 커넥터가 테이블의 모든 데이터를 캡처하는 경우. - Admin API
토픽, 브로커 및 다른 카프카 오브젝트를 관리, 검사한다.
카프카에서 클라이언트와 서버 간의 커뮤니케이션은 간단하고 고성능의 언어에 구애받지 않는 (language agnostic) TCP 프로토콜로 수행된다. 이 프로토콜은 버전화 되어있고 이전 버전과 호환성을 유지한다. 카프카를 위한 자바 클라이언트를 제공하나 클라이언트는 다른 다양한 언어로도 가능하다.
사용 사례
1️⃣ 메세징
- 전통적인 메세지 브로커를 대체
- ActiveMQ나 RabbitMQ 같은 기존 메시징 시스템과 유사하다.
2️⃣ 웹 사이트 활동 추적
- 사용자 활동 추적 파이프라인을 실시간 publish-subscribe 피드 집합으로 재빌드한다.
- 사이트 활동(페이지보기, 검색 등 사용자가 취할 수 있는 작업들)을 활동 유형 당 하나의 topic으로 중앙 topic에 게시된다.
- 실시간 처리, 실시간 모니터링, 오프라인 처리 및 보고를 위해 Hadoop 또는 오프라인 데이터웨어 하우징 시스템에 로드하는 등
3️⃣ 지표
- 운영 모니터링 데이터에 사용된다.
- 분산된 어플리케이션의 통계를 집계하여 운영되는 데이터의 중앙 집중식 피드를 생성한다.
4️⃣ 로그 집계
- 로그 집계 솔루션의 대용품
- 일반적으로 서버에서 물리적 로그 파일을 수집하여 처리를 위해 중앙(파일 서버나 HDFS)에 저장한다.
- kafka는 파일의 세부사항을 추상화하고 로그나 이벤트 데이터를 메세지 스트림으로 깔끔하게 추상화함으로써 처리 지연 시간을 줄이고 multiple data source와 분산된 데이터의 소비의 지원을 쉽게 만들어준다.
- 비교 대상 : Scribe나 Flume같은 로그 중심 시스템
5️⃣ 스트림 처리
- 많은 kafka 사용자는 여러 단계로 구성된 파이프라인에서 데이터를 처리하는데, kafka topic에서 원시 입력 데이터를 소비하고 다음의 소비와 후속 처리를 위해 새로운 topic으로 통합, 농축, 변환한다.
- exmaple) 뉴스 기가 추천을 위한 처리 파이프 라인
- RSS 피드에서 기사 콘텐츠를 크롤링하여 "articles" topic에 게시한다.
- 추가 처리 : 콘텐츠를 정규화 or 중복 제거 → 정리된 콘텐츠를 게시
- 최종 처리 단계에서 이 콘텐츠를 사용자에게 추천하게 한다.
- 개별 topic을 기반으로 실시간 데이터 흐름 그래프를 만들 수 있다.
- Kafka Streams 스트림 처리 라이브러리를 지원한다.
- 대체 오픈소스 스트림 도구에는 Apache Storm, Apache Samza가 있다.
6️⃣ 이벤트 소싱
- 상태의 변경이 시간 순서에 따라 기록되는 레코드 시퀀스
7️⃣ 커밋 로그
- 분산 시스템에 대한 일종의 외부 커밋 로그 역할
- 로그는 노드간 데이터를 복제하는 것을 도우며 실패한 노드가 데이터를 복원하기 위한 재동기화 메커니즘 역할을 한다.
Topics and Logs
레코드 스트림을 제공하기 위한 카프카의 주요 구현체인 topic을 알아보자.
토픽은 레코드가 발행되는 카테고리 혹은 피드 이름이다. 카프카의 토픽은 항상 다중 구독자이다. 즉, 토픽은 여기에 쓰여진 데이터를 구독하는 0개, 1개 혹은 많은 소비자를 가질 수 있음을 뜻한다.
각각의 토픽에 대해 카프카 클러스터는 아래처럼 파티셔닝된 로그를 유지하고 관리한다.
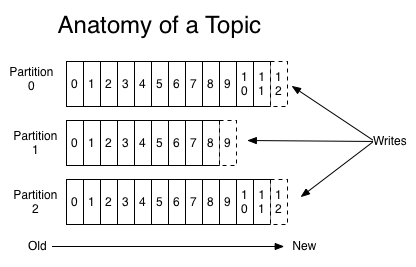
각 파티션은 구조화된 커밋 로그에 지속적으로 이어붙어지는 순서가 변하지 않는 레코드의 연속이다. 파티션 내의 레코드는 각각 파티션 내에서 각 레코드를 고유하게 식별하는 offset이라고 순차 아이디 번호가 할당된다.
카프카 클러스터는 소비되고 있는가의 여부와는 상관없이 보존 기간 구성을 사용해 모든 발행된 레코드를 지속(유지)한다. 예를 들어, 만약 기억 정책이 이틀로 셋팅되어 있다면 레코트가 발행된 후로 이틀동안 소비가 가능하며 그 후엔 공간을 확보하기 위해 제거된다. 카프카의 퍼포먼스는 실제로 데이터 사이즈에 대해 일정하기 때문에 오랜기간동안 데이터를 보관하는 것은 문제가 되지 않는다.
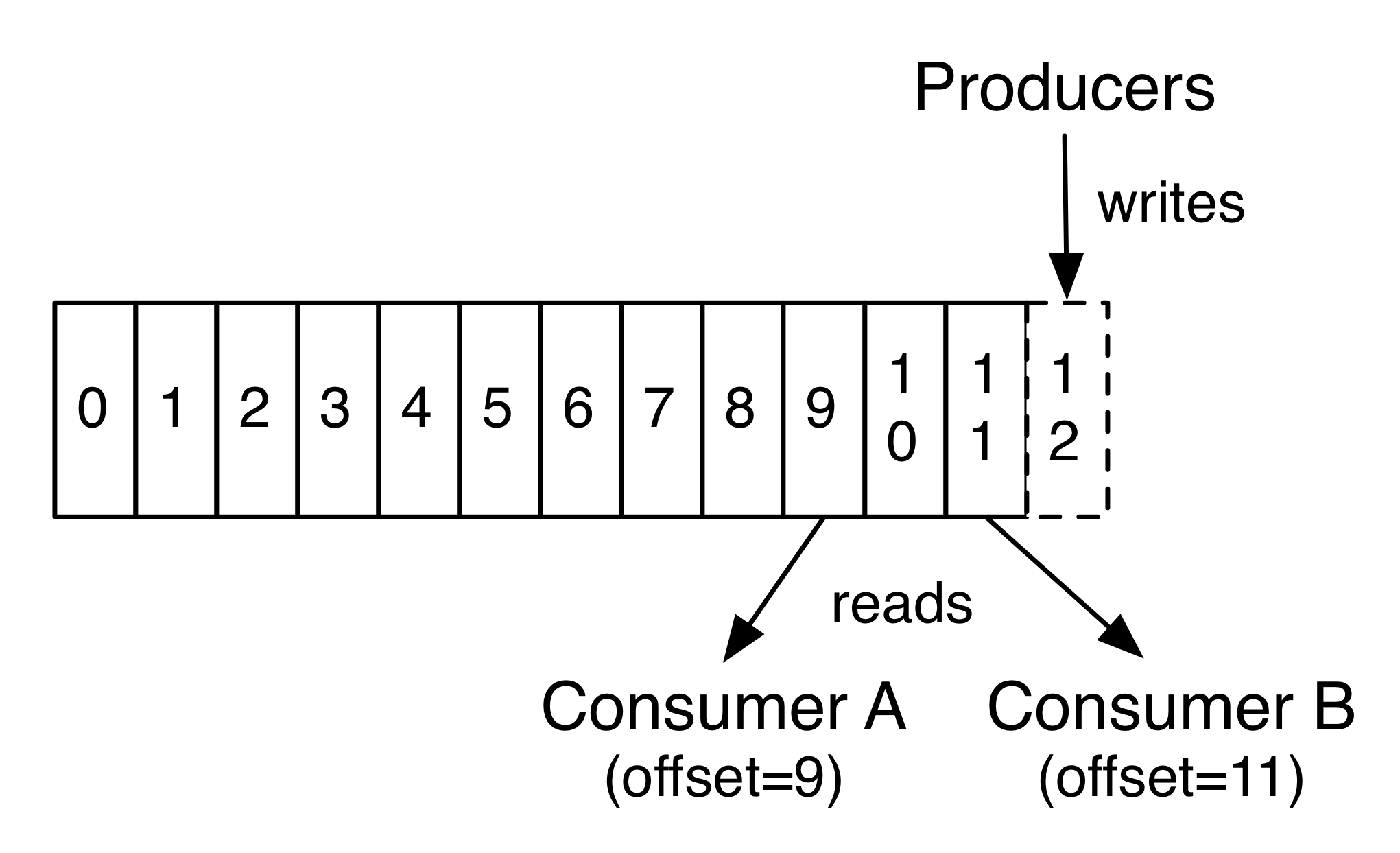
사실, 컨슈머 별로 유지되는 유일한 메타데이터는 로그에서 해당 소비자의 오프셋 또는 위치이다. 이 오프셋은 컨슈머가 제어한다. 일반적으로 컨슈머는 선형적으로 오프셋을 사용하고자 하는데 사실 위치가 컨슈머에 의해 작동되기 때문에 원하는 순서대로 레코드를 사용할 수 있다. 예를 들어 컨슈머는 이전 데이터를 다시 처리하기 위해 이전 오프셋으로 재설정하거나, 가장 최근 레코드로 건너 뛰어 현재부터 소비 할 수 있다.
이러한 기능의 조합은 클러스터나 다른 컨슈머에 영향을 끼치지 않고 오갈 수 있기 때문에 카프카의 컨슈머의 사용이 저비용이란 것을 의미한다. 예를 들어, 커맨드 라인 툴을 사용하여 현재의 어떤 컨슈머에 의해 소비되고 있는 내용을 변경하지 않고 토픽의 내용을 "쫒을 수" 있다.
로그 내 파티션은 여러가지 용도로 사용된다. 우선, 하나의 서버에 적합한 크기를 넘어서 로그를 확장 할 수 있다. 각각 개인적인 파티션은 해당 파티션을 제공하는 서버에 딱 맞아야하지만 토픽은 여러 파티션을 가지기 때문에 임의의 양의 데이터를 처리할 수 있다. 두번째로 이것들은 하나의 비트를 넘어 병렬 유닛으로 작동한다.
Distribution
로그의 파티션은 각 서버가 데이터를 공유하고 파티션 공유를 요청하는 카프카 클러스터의 서버에 걸쳐 분산되어 있다. 각 파티션은 결함을 허용할 수 있도록 구성 가능한 수의 서버에 복제된다.
각 파티션에는 "leader" 역할을 하는 하나의 서버와 "followers" 역할을 하는 0개 이상의 서버가 있다. 리더는 파티션에 대한 모든 읽기 및 쓰기 요청을 처리하는 반면 팔로어는 리더를 수동으로 복제한다. 리더가 실패하면 팔로워 중 하나가 자동으로 새로운 리더가 된다. 각 서버는 일부 파티션의 리더가 되고 다른 파티션의 팔로워 역할을 하므로 클러스터 내에서 로드 균형이 잘 조정된다.
Geo-Replication
Kafka MirrorMaker는 클러스터를 지원하기 위한 지역 복제를 제공한다. MirrorMaker에서 메세지는 다중 데이터 센터나 클라우드 장소에 걸쳐 복제된다. 이는 백업과 덮기를 위한 active/passice 시나리오 혹은 데이터를 유저 가까이에 위치 시키거나 지역적으로 필수로 요구되는 데이터를 지원하기 위해 active/active 시나리오를 사용할 수 있다.
Producers
프로듀서는 선택한 토픽에 데이터를 발행한다. 프로듀서는 토픽 내의 어떤 파티션에 할당할 레코드를 선택할 책임이 있다. 이것은 균형잡힌 로드를 위한 round-robin 방식에 의해 가능하며, 같은 문법의 (레코드 내의 어떤 키에 기반한) 파티션 함수에 의해 가능하다. 또한 1초 내에 파티셔닝을 사용할 수 있다.
Consumers
컨슈머는 컨슈머 그룹 이름으로 라벨링되고 토픽으로 발행된 각 레코드는 각 구독하는 컨슈머 그룹 내 하나의 컨슈머 인스턴스에 전달된다. 컨슈머 인스턴스는 별도의 프로세스 혹은 별도의 시스템에 있을 수 있다.
모든 컨슈머 인스턴스가 동일한 컨슈머 그룹에 있는 경우, 레코드는 컨슈머 인스턴스에 효과적으로 군형잡힌 로드가 가능하다.
모든 컨슈머 인스턴스가 다른 컨슈머 그룹에 있는 경우, 레코드는 모든 컨슈머 프로세스에 대해 브로드 캐스트된다.
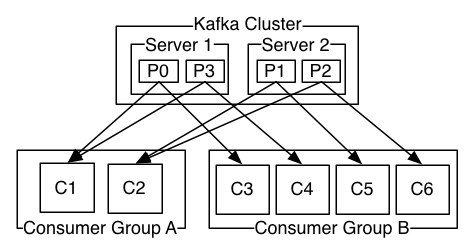
두 개의 컨슈머 그룹이 있는 네 개의 파티션(p0-p3)을 호스팅하는 두 개의 서버 카프카 클러스터가 있다. 컨슈머 그룹 A는 두 개의 컨슈머 인스턴스를 가지고 그룹 B는 네 개를 가진다.
그러나 일반적으로 토픽에 각 "논리적 구독자"마다 하나씩 소수의 컨슈머 그룹이 있는 것을 알아냈다. 각 그룹은 확장성과 내결함성을 위해 여러 컨슈머 인스턴스로 구성된다. 이는 구독자는 단일 프로세스 대신 컨슈머 클러스터인 publish-subscribe 의미론에 지나지 않는다.
카프카에서 소비가 구현되는 방식은 각 인스턴스가 특정 시점에서 파티션의 "공정한 공유"의 독점 컨슈머가 되도록 컨슈머 인스턴스를 통해 로그의 파티션을 분할하는 것이다. 그룹 내 구성원을 유지하는 프로세스는 카프카 프로토콜에 의해 동적으로 처리된다. 새 인스턴스가 그룹에 가입하면 그룹의 다른 구성원에서 일부 파티션을 인계받는다. 인스턴스가 종료되면 해당 파티션이 나머지 인스턴스에 배포된다.
카프카는 토픽 내 다른 파티션 사이가 아니라 파티션 내의 레코드에 대해서만 총 순서를 제공한다. 키 별로 데이터를 분할하는 기능과 결합된 파티션 별 순서는 대부분의 응용 프로그램에서 충분하다. 그러나 레코드에 대한 총 순서가 필요한 경우 파티션이 하나인 토픽을 사용해 이를 충족할 수는 있으나 컨슈머 그룹 당 하나의 컨슈머 프로세스만을 의미한다.
Multi-tenancy
카프카를 multi-tenant 솔루션으로 배포 할 수 있다. 데이터를 생성하거나 사용할 수 있는 토픽을 구성함으로써 multi-tenant를 사용할 수 있따. 또한 할당량에 대한 작업 지원도 있다. 관리자는 요청에 대한 할당량을 정의하여 정용하여 클라이언트가 사용하는 브로커 리소스를 제어 할 수 있다. 자세한 것은 보안 설명서를 참조하라.
Guarantees
고급 카프카에서는 다음을 보장한다.
- 프로듀서가 특정 토픽의 파티션으로 보낸 메세지는 전송된 순서대로 추가된다. 즉 레코드 M1이 레코드 M2와 동일한 생산자에 의해 전송되고 M1이 먼저 전송되면 M1은 M2보다 낮은 오프셋을 가지며 로그의 초기에 나타난다.
- 컨슈머 인스턴스는 로그에 저장된 순서대로 레코드를 바라본다.
- 복제된 팩터 N이 토픽인 경우, 로그에 커밋된 레코드를 잃지 않고 (최대로) N-1 서버 오류를 허용한다.
이런 보장에 대한 자세한 내용은 도큐먼트의 디자인 섹션에 나와있다.
Kafka as a Messaging System
카프카의 스트림 개념은 기존 엔터프라이즈 메세징 시스템과 어떻게 다를까?
메세징에는 전통적으로 "queuing"과 "publish-subscribe" 두 가지 모델이 있다. queue에서 컨슈머 풀은 서버에서 읽어들이며 각 레코드는 그 중 하나로 이동한다. publish-subscribe에서 레코드는 모든 소비자에게 브로드 캐스트된다. 이 두 모델은 각각 장단점이 존재한다. queuing의 장점은 여러 컨슈머 인스턴스에 걸쳐 데이터 처리를 분할함으로써 처리 규모를 조정 할 수 있다는 것이다. 불행하게도 queue는 다중 구독자가 아니므로 한 번의 처리과정에서 데이터가 읽힘과 동시에 사라진다. Publish-subscribe를 사용하면 데이터를 여러 프로세스로 브로드 캐스팅 할 수 있으나 모든 메세지가 모든 구독자에게 전달되므로 처리 규모를 조정할 방법이 없다.
카프카의 컨슈머 그룹이란 개념은 위의 두 개념을 일반화한다. 컨슈머 그룹을 사용하면 queue와 마찬가지로 프로세스 모음(컨슈머 그룹의 구성원)에 걸쳐 처리를 나눌 수 있다. 또한, publish-subscribe과 마찬가지로 여러 컨슈머 그룹에게 메세지를 브로드 캐스팅 할 수도 있다.
카프카 모델의 장점은 모든 토픽에 이러한 속성(처리 범위를 조정할 수 있고 다중 구독자임)이 모두 있으며 둘 중 하나를 선택할 필요가 없다는 것이다.
카프카는 기존 메세징 시스템보다 강력한 정렬을 보장한다.
기존의 큐는 서버에서 레코드를 순서대로 유지하며 여러 컨슈머가 큐를 소비하는 경우 서버는 저장된 순서대로 레코드를 전달한다. 서버가 레코드를 순서대로 전달하는 것과 별개로 레코드는 비동기적으로 컨슈머에 전달되기 때문에 다른 컨슈머에서는 순서가 맞지 않을 수 있다. 즉, 이는 병렬 소비가 있을 경우 레코드의 순서가 손실됨을 의미한다. 메세징 시스템은 종종 하나의 프로세스만 대기열에서 소비할 수 있는 "독점 컨슈머"라는 개념을 이용해 이 문제를 해결하지만 이는 곧 처리 과정에 병렬 처리가 없음을 의미한다.
카프카는 이보다 훨씬 났다. 토픽 내에서 병렬처리(파티션)라는 개념을 가짐으로써 kafka는 소비자 프로세스 풀에서 정렬 보장과 로드 밸런싱을 모두 제공할 수 있다. 이는 토픽의 파티션을 컨슈머 그룹의 컨슈머에게 할당하여 각 파티션이 정확히 그룹 내 하나의 컨슈머에 의해 소비되도록함으로써 가능하다. 이를 통해 컨슈머는 해당 파티션의 유일한 구독자이며 데이터를 순서대로 사용할 수 있다. 파티션이 많으므로 여전히 많은 컨슈머 인스턴스에 대한 로드 밸런스를 유지한다. 하지만 컨슈머 그룹에는 파티션 수보다 더 많은 컨슈머 인스턴스가 있을 수 없다.
Kafka as a Storage System
메시지를 사용하지 못하도록 차단된 메시지를 발행 할 수 있는 모든 메시지 큐는 기내 메시지의 효과적인 저장 시스템 역할을 하고 있다. 카프카의 다른 점은 매우 좋은 저장 시스템이라는 것이다.
카프카에서는 데이터가 디스크에 기록되고 내결함성을 위해 복제된다. 카프카를 사용하면 프로듀서가 승인을 기다릴 수 있으므로 쓰기가 완전히 복제될 때까지는 완전한 것으로 간주하지 않으며 쓰기가 실패하더라도 지속되도록 보장한다.
카프카는 확장성이 우수한 디스크 구조를 가진다. 서버의 영구 데이터가 50KB이든, 50TB이든 지에 상관없이 동일한 성능을 발휘한다.
스토리지를 진지하게 받아들이고 클라이언트가 읽기 위치를 제어할 수 있게 함으로써 카프카는 고성능, 짧은 대기시간의 커밋 로그 스토리지, 복제 및 전파를 전용으로하는 일종의 특수 목적 분산 파일 시스템으로 생각할 수 있다.
카프카의 커밋 로그 저장소 및 복제 설계에 대한 자세한 내용은 이 페이지를 참조하라.
Kafka for Stream Processing
단순히 데이터 스트림을 읽고 쓰고 저장하는 것만으로는 충분하지 않으며, 스트림의 실시간 처리를 가능하게 하는 것이 목적이다.
카프카에서 스트림 프로세서는 입력 토픽에서 지속적인 데이터 스트림을 가져와 이 입력에 대해 일부 처리를 수행하며 지속적으로 데이터 스트림을 생성하여 주제를 출력한다.
예를 들어, 쇼핑몰 애플리케이션은 판매와 발송의 입력 스트림을 받아들이고, 이 데이터에서 계산된 일련의 재주문 및 가격 조정 스트림을 출력할 수 있다.
프로듀서 및 컨슈머 API를 사용해 직접 간단한 처리를 수행할 수 있다. 그러나 보다 복잡한 변환을 위해 카프카는 완전히 통합된 스트림 API 또한 제공한다. 따라서 스트림에서 집계를 계산하거나 스트림을 결합하는 등의 비독점 처리를 수행하는 응용 프로그램을 만들 수 있다.
이 기능은 비순차적 데이터 처리, 코드 변경을 통한 입력 재처리, stateful computations의 수행 등 어플리케이션이 직면하는 어려운 문제를 해결하는데에 도움이 된다.
카프카가 제공하는 핵심 요소를 기반으로하는 스트림 API는 입력에 프로듀서 및 컨슈머 API를 사용하고 상태 저장에 카프카를 사용하며 스트림 프로세서 인스턴스 간의 내결함성을 위해 동일한 그룹 메커니즘을 사용한다.
Putting the Pieces Together
메세징, 스토리지 및 스트림 처리의 조합은 비정상적으로 보일 수 있지만 스트리밍 플랫폼으로서 카프카의 역할에 필수적이다.
HDFS와 같은 분산 파일 시스템을 사용하면 배치 처리를 위해 정적 파일을 저장할 수 있다. 이와 같은 시스템을 통해 효과적으로 과거의 기록 데이터를 저장하고 처리할 수 있다.
기존의 엔터프라이즈 메세징 시스템에서는 구독 후 도착할 향후 메세지를 처리 할 수 있다. 이러한 방식으로 구축된 응용 프로그램은 데이터가 도착한 후에 처리한다.
카프카는 이 두 가지 기능을 모두 갖추고 있으며 스트리밍 데이터 파이프 라인 뿐만 아니라 스트리밍 응용 프로그램을 위한 플랫폼으로 카프카를 사용하는데 있어서 모두 중요하다.
저장소와 지연 시간이 짧은 구독을 결합하여 스트리밍 어플리케이션이 과거와 미래 데이터를 동일한 방식으로 처리하도록 할 수 있다. 즉, 단일 응용 프로그램은 과거에 저장된 데이터를 처리할 수 있으면서 마지막 레코드에 도달했을 때 끝나지 않고 향후 데이터가 도착할 때 계속 처리 할 수 있다. 이것은 메세지 기반 응용 프로그램 뿐만 아니라 일괄 처리도 포함하는 스트림 처리의 일반화된 개념이다.
스트리밍 데이터 파이프 라인과 마찬가지로 실시간 이벤트에 구독을 결합하면 대기 시간이 짧은 파이프 라인에 카프카를 사용할 수 있다. 그러나 전달이 보장되어야하는 중요한 데이터나 주기적으로 데이터를 로드하거나 유지 보수를 위해 장기간 다운 될 수 있는 오프라인 시스템과의 통합 시 중요한 데이터를 위한 안정적인 저장 기능을 수행 할 수 있다. 스트림 처리 기능은 데이터가 도착함에 따라 변환 할 수 있게 한다.
