
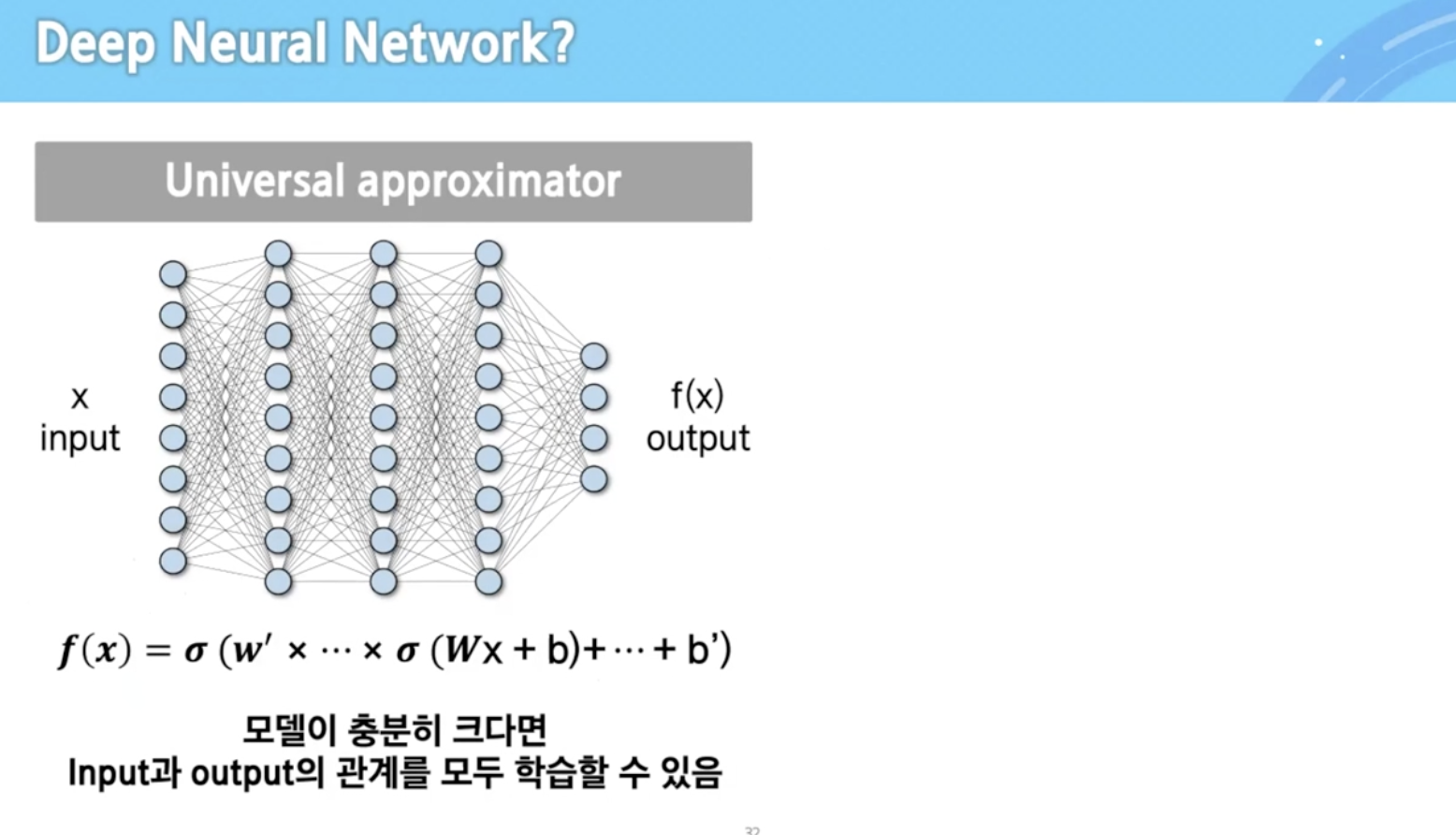
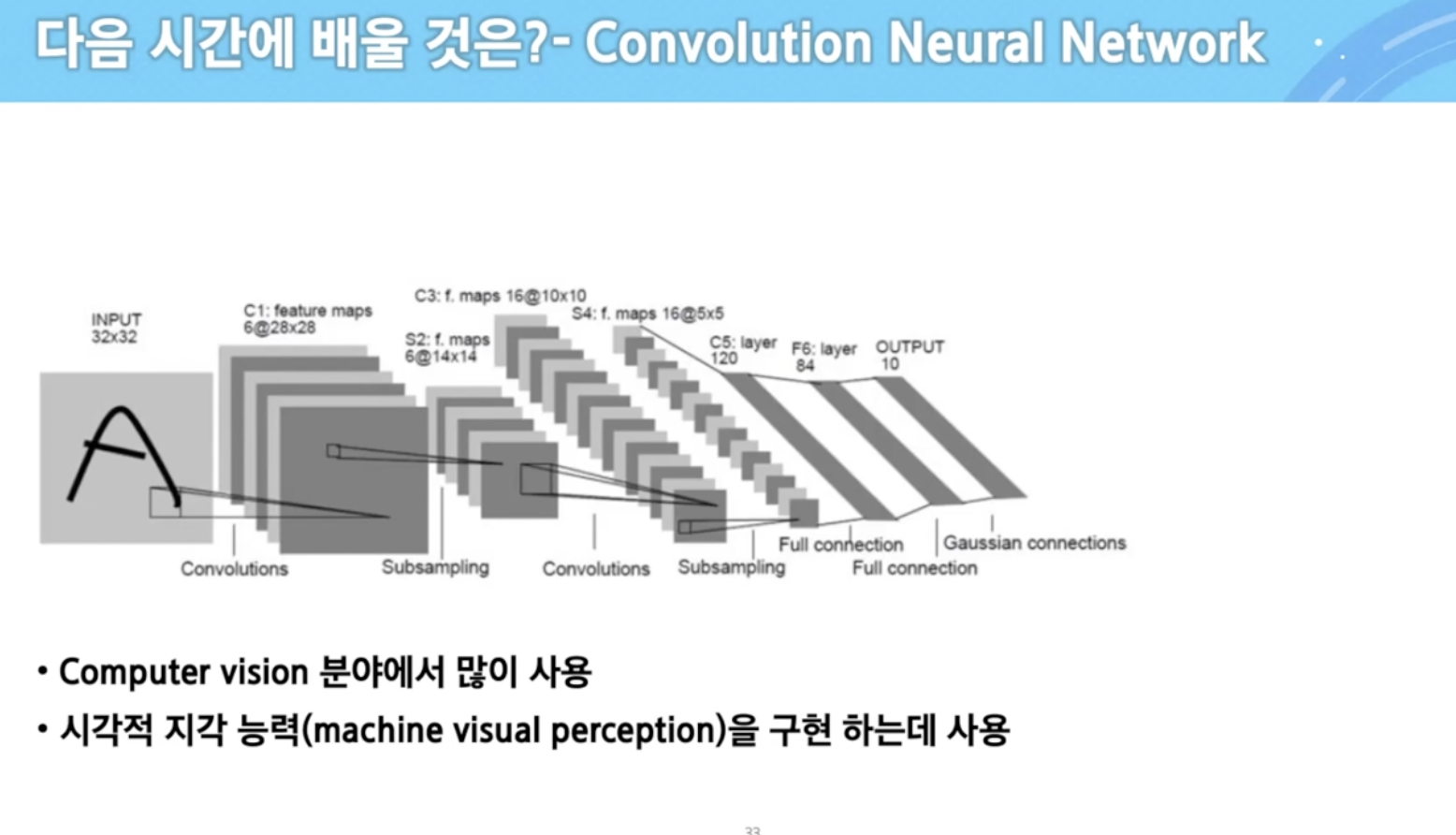
기계학습이란 무엇인가?
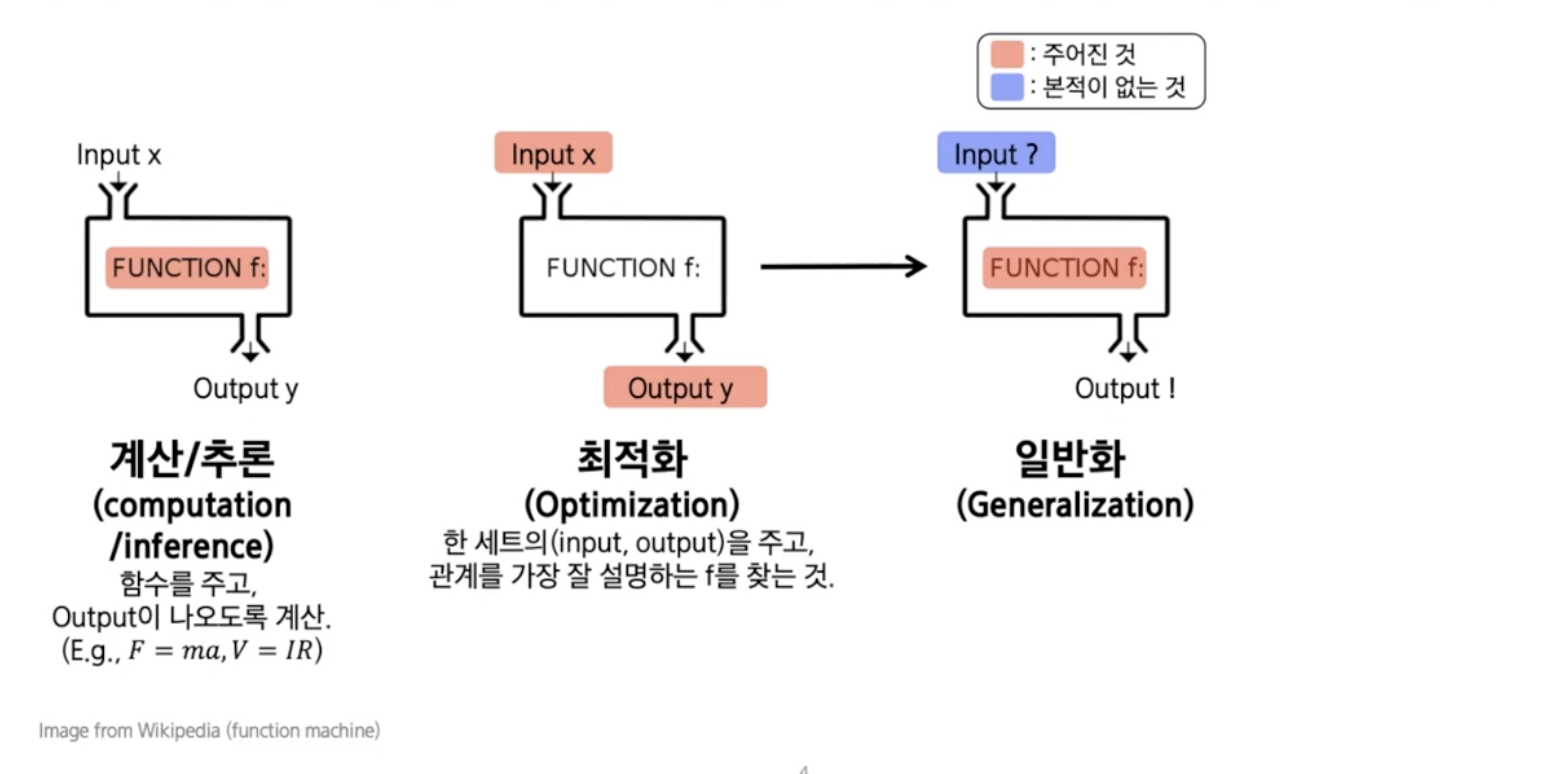
- 최적화
- 데이터를 줬을 때 그 관계를 찾는 것
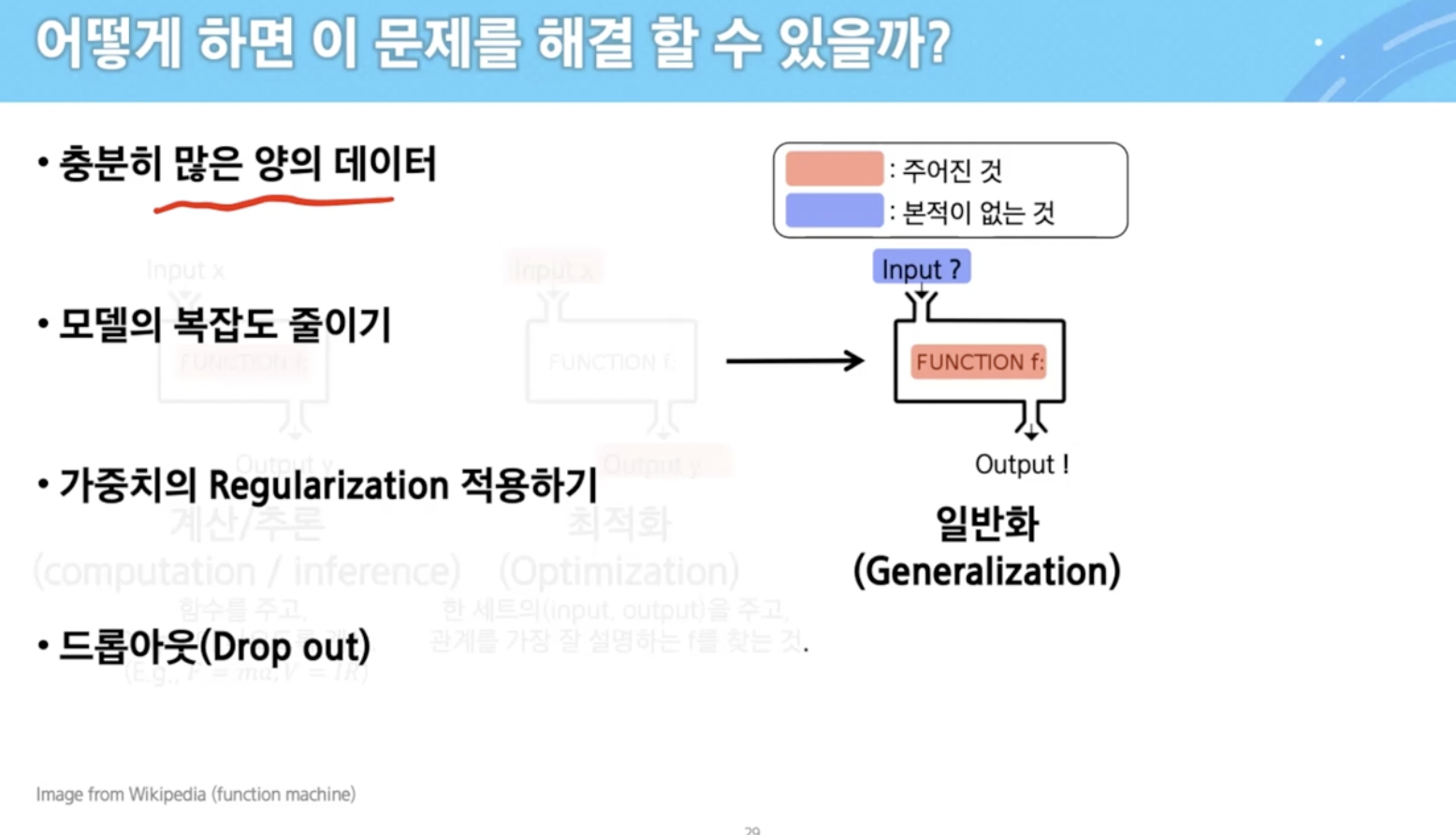
- 일반화
- 본 적이 없는 새로운 데이터가 들어와도 적절한 출력을 내보내서 정답을 맞췄으면 일반화가 잘 되었다고 표현함
최적화를 통해 f를 잘 찾고 새로운 데이터가 들어와도 아웃풋 잘 나왔을 때(일반화) 기계학습이라고 함
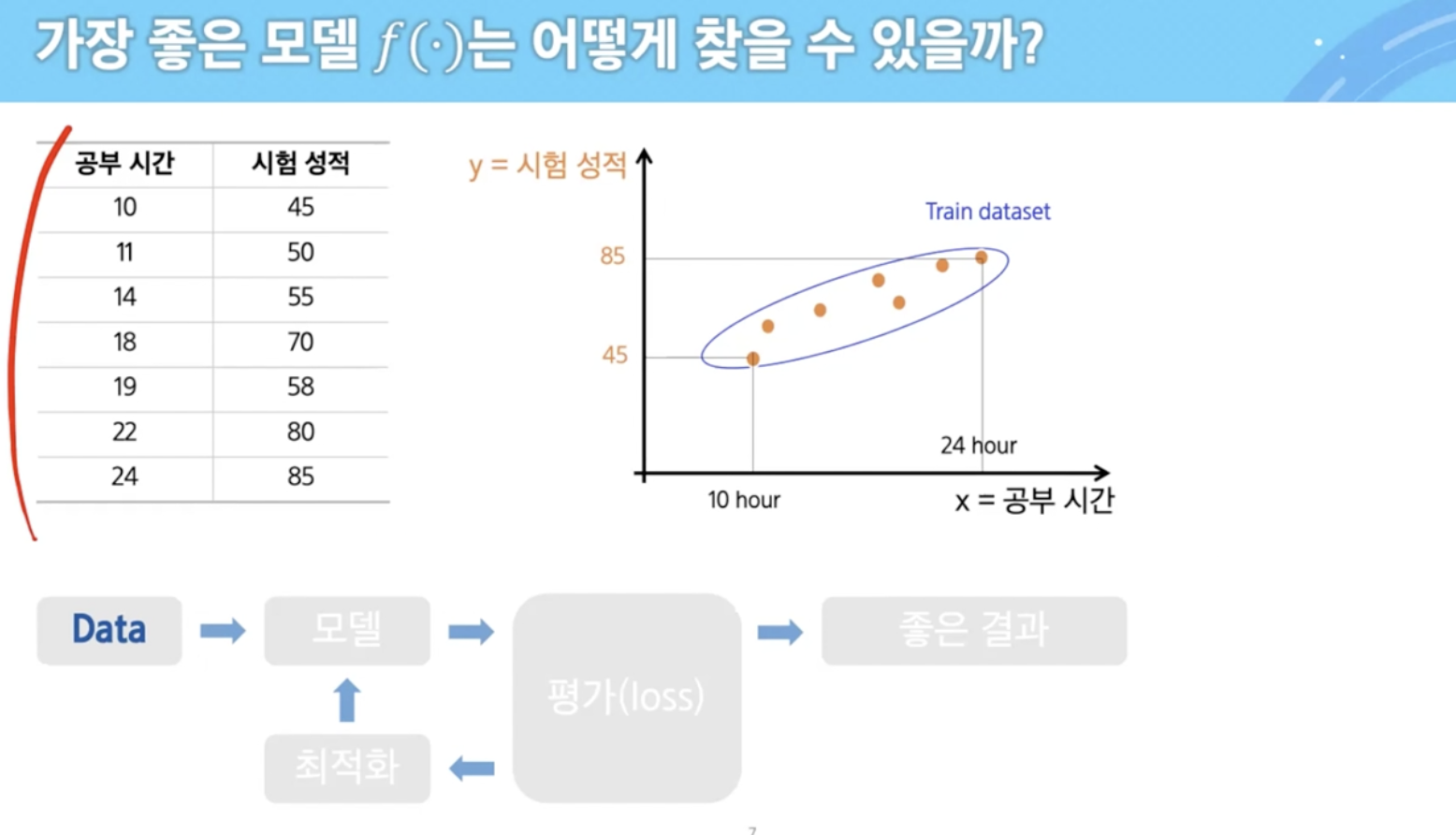
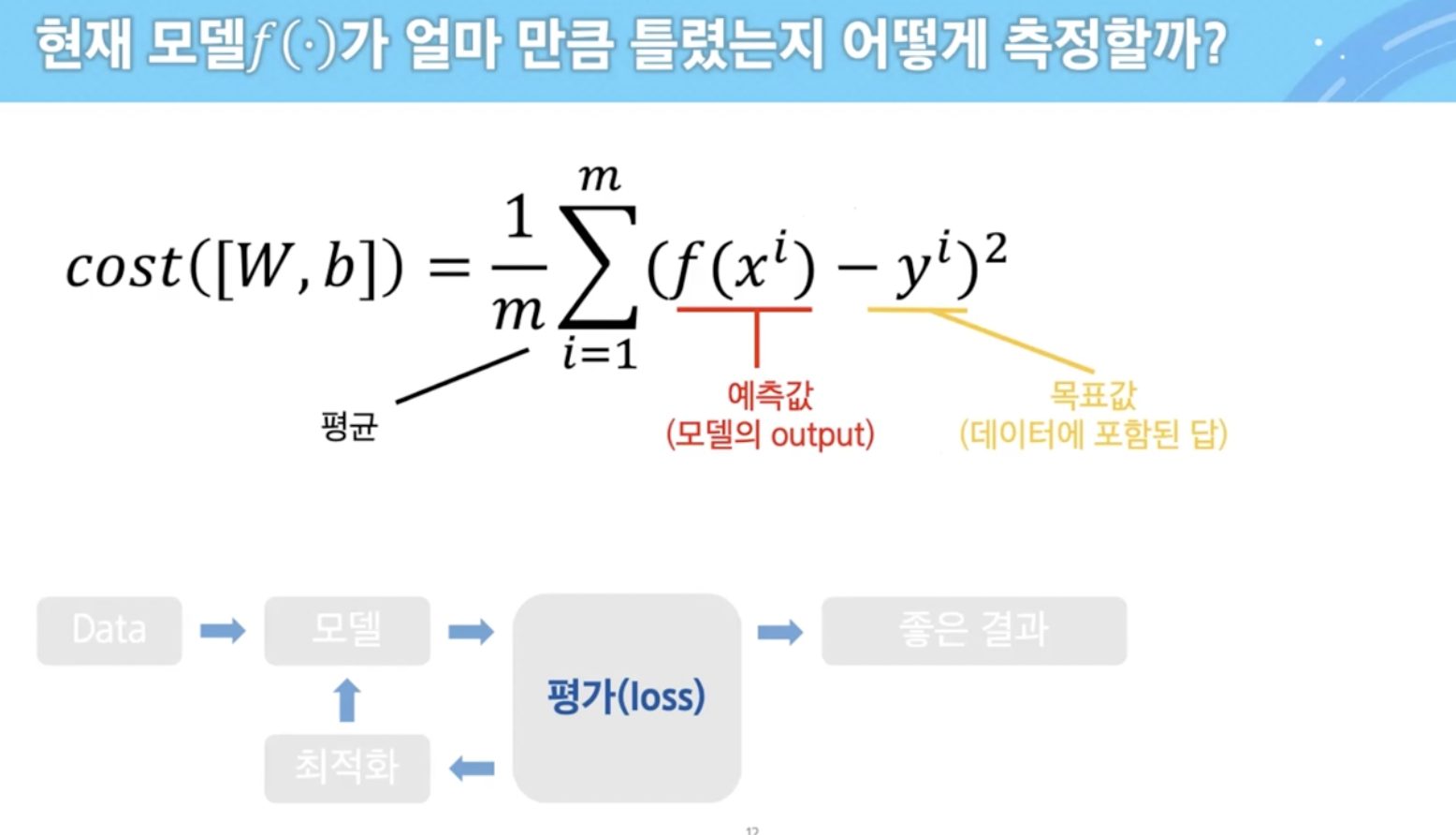
평가할 수 있는 기준 → loss function, cost
- 목표값과 예측값과의 오차를 제곱하고 평균 계산
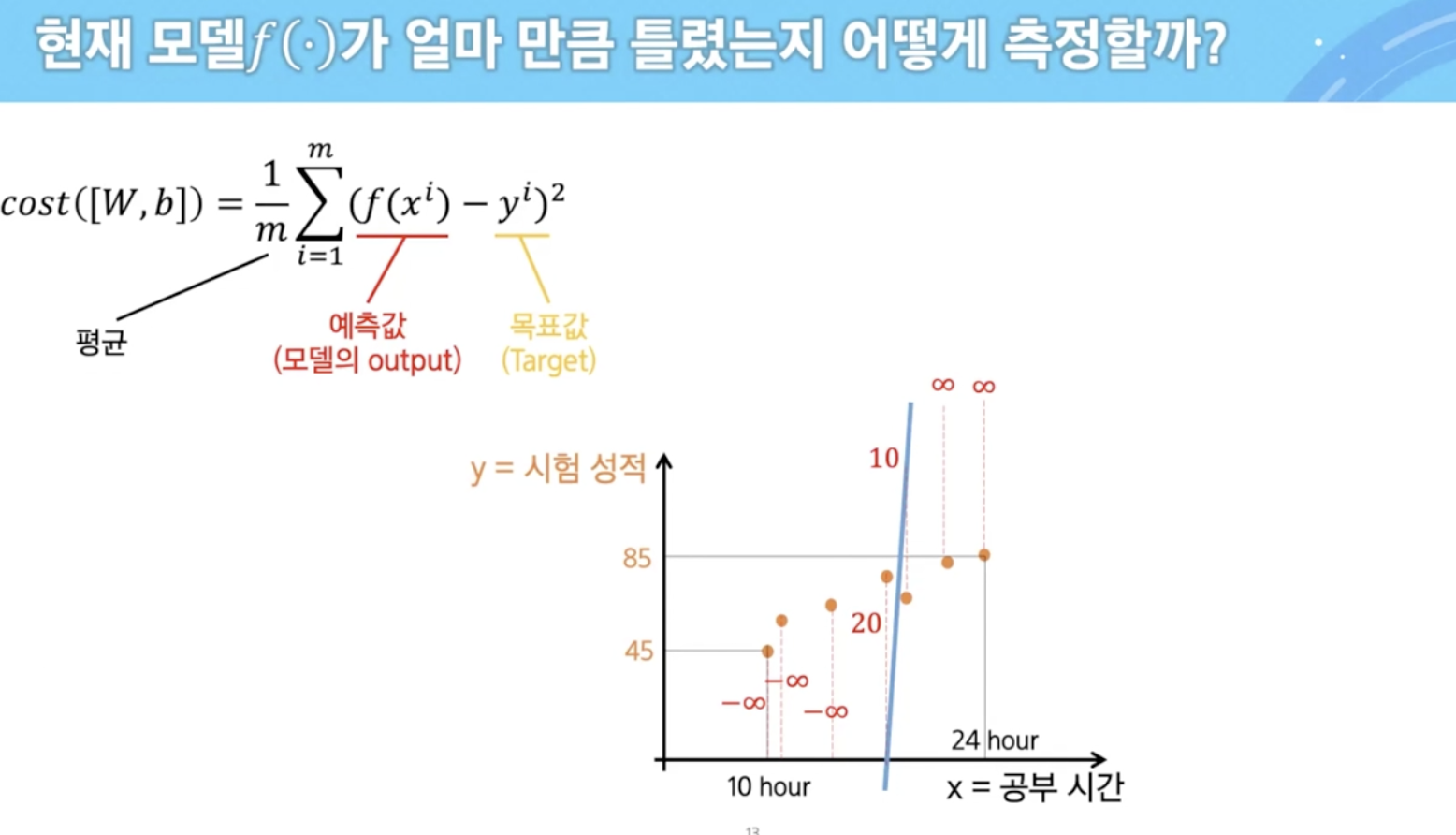
x 값을 넣어봄으로써 데이터가 얼마나 잘 맞는지 확인
각각의 데이터가 얼마나 맞는지 물어본다.
어마어마하게 큰 오차(error) 발생
어떻게 현재 모델을 개선할 수 있을까?
W,b를 랜덤으로 바꿔볼 수도 있지만 범위가 너무 크기 때문에 못 찾을 수도 있다.
효율적으로 하려면?
현재의 위치에서 loss를 파악 → 조금 움직였을 때 loss의 변화 파악
가장 급격하게 내려갈 수 있는 부분을 찾아서 W,b를 일정 간격 변화 시켜본다.
또 다른 그래프를 통해 loss를 측정해보고 더 바뀌면 어떻게 될까… 지속적인 탐색
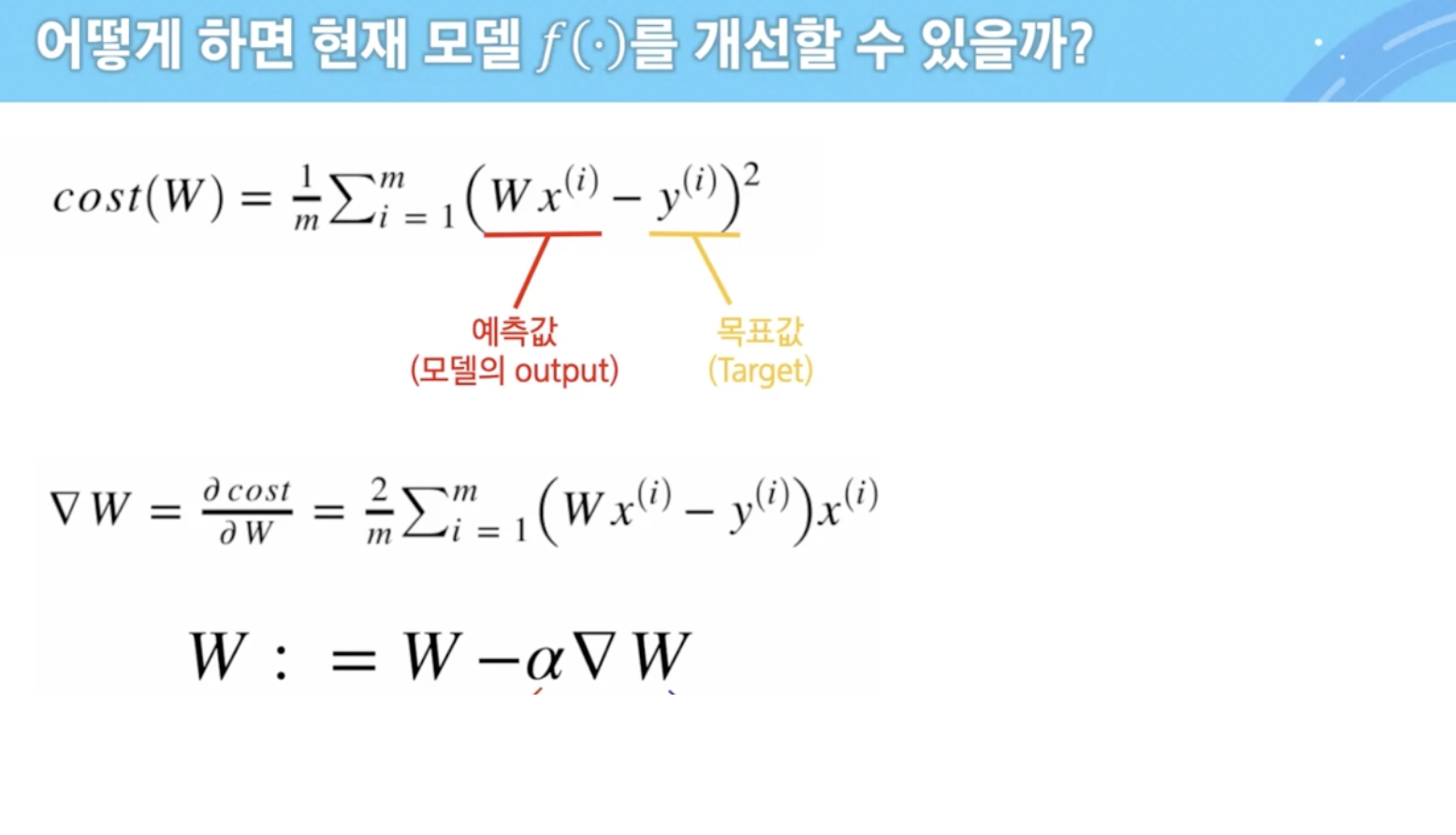
gradient direction
- 어떤 방향으로 이동했을 때 Loss가 떨어지느냐
- 많이 이동하면 좋다? → X, 꼭 그렇지 않다. 꼭 계속 감소하는 것은 아니니까
- learning rate(알파)로 step size를 결정
- gradient → 어떤 방향?
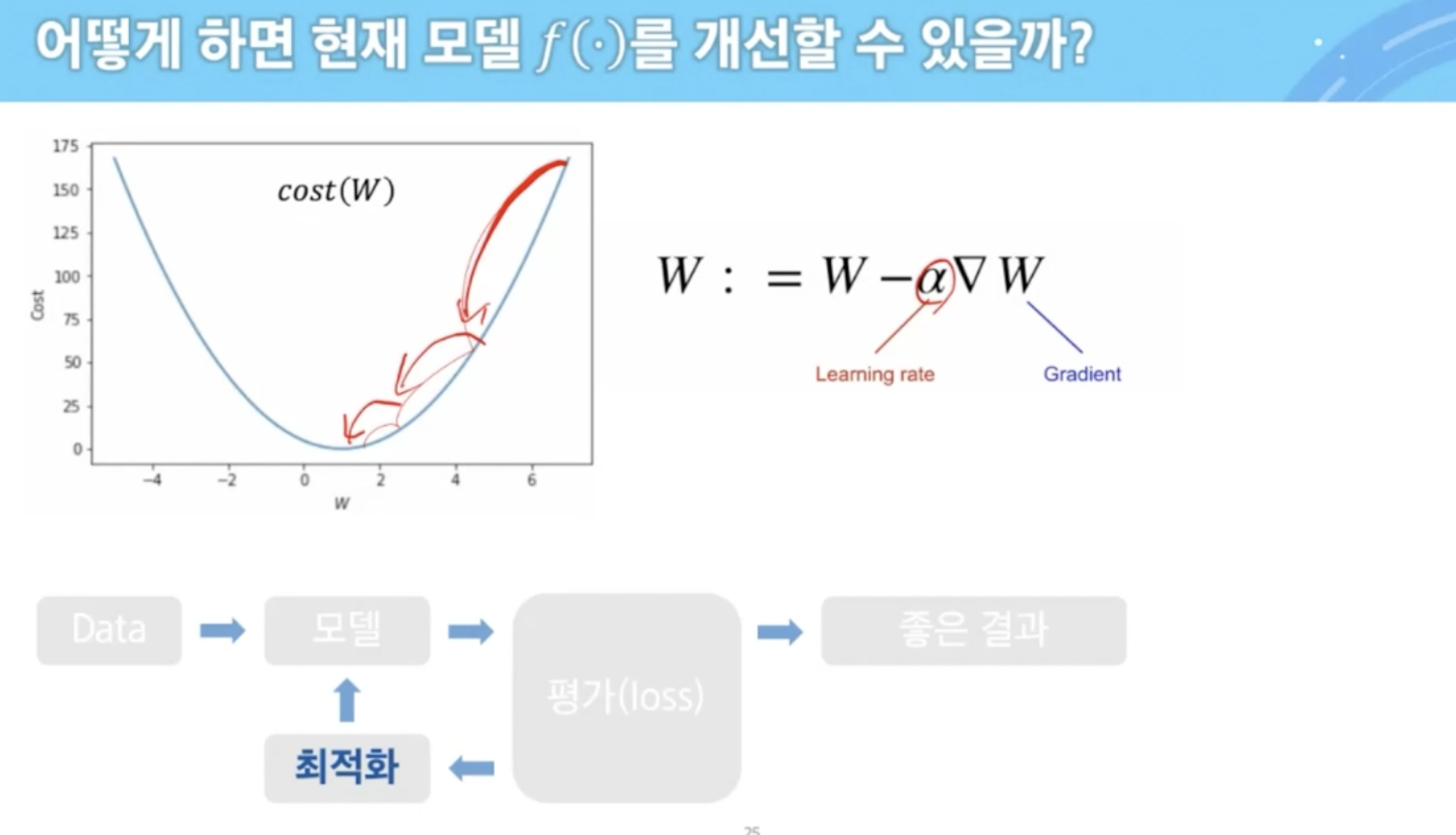
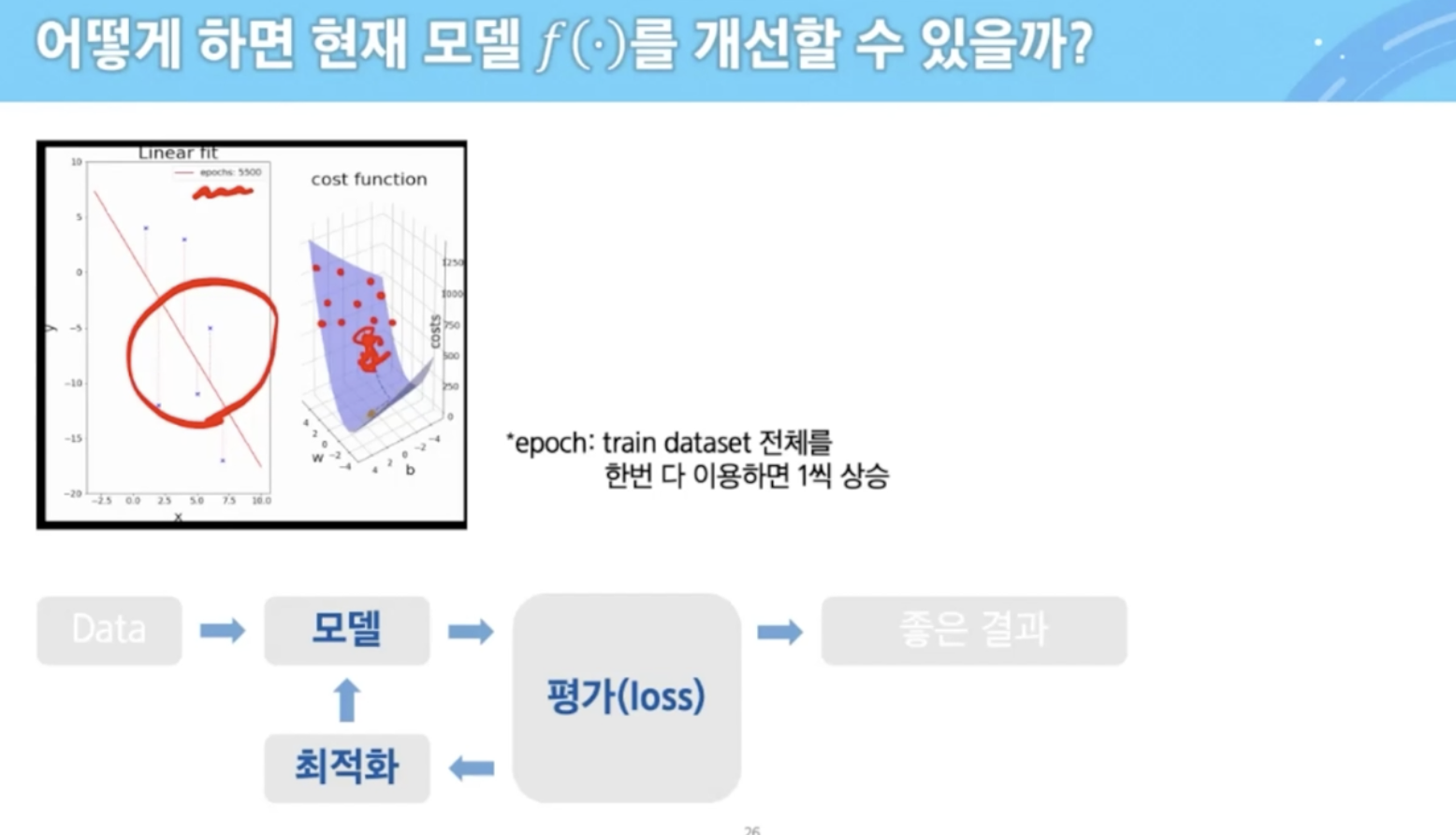
epoch : train dataset 전체를 한번 다 이용하면 1씩 상승
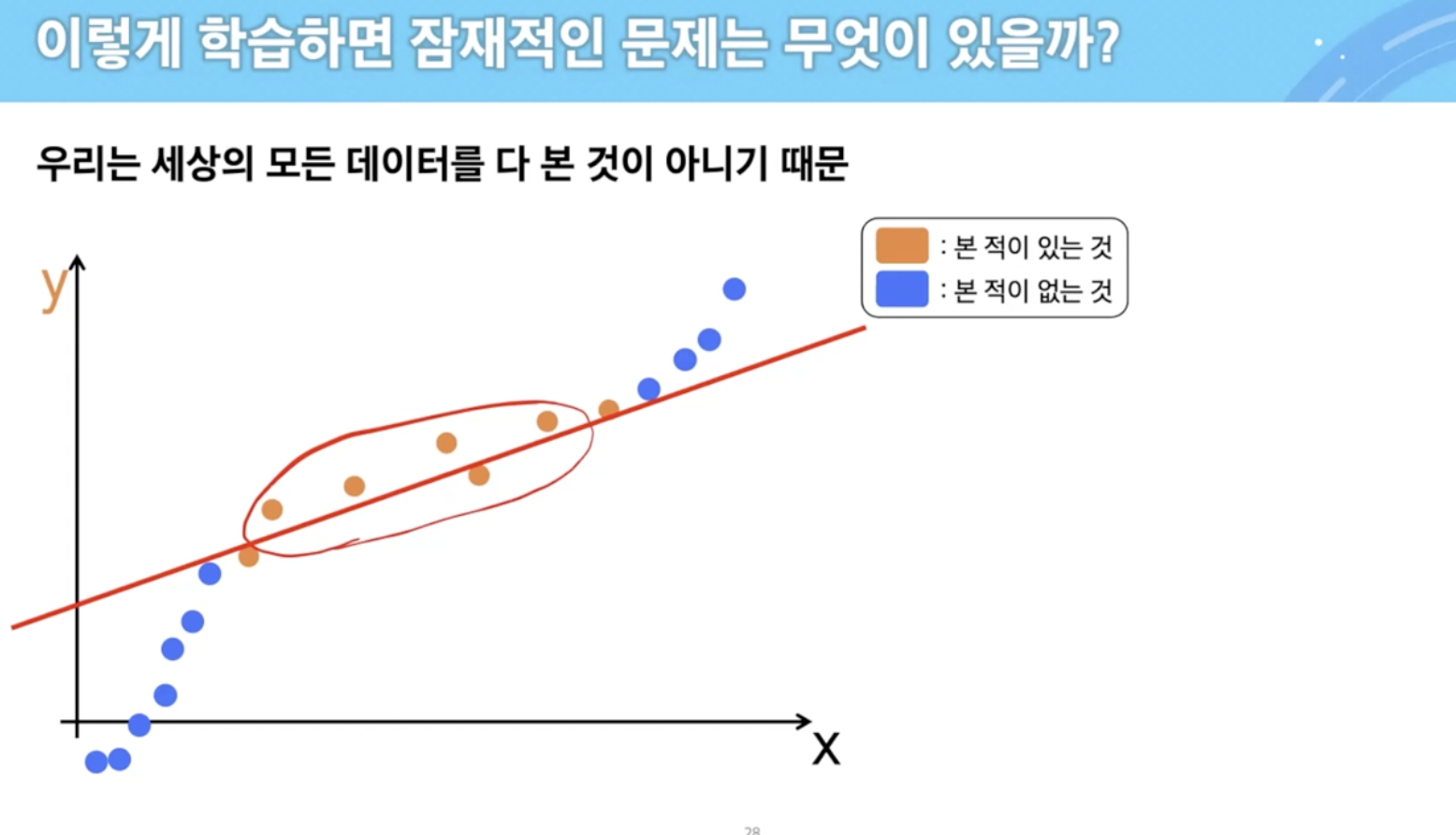
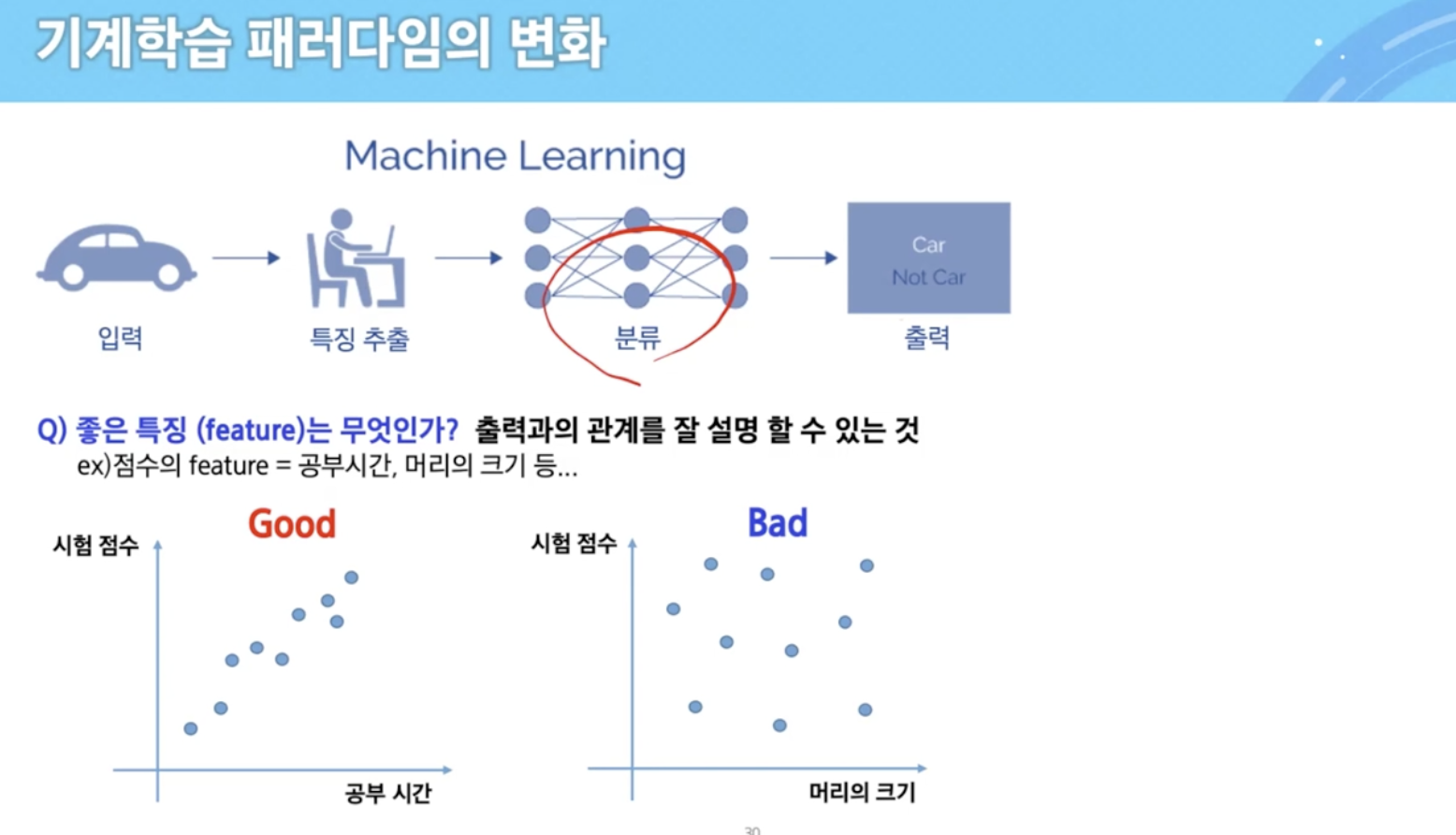
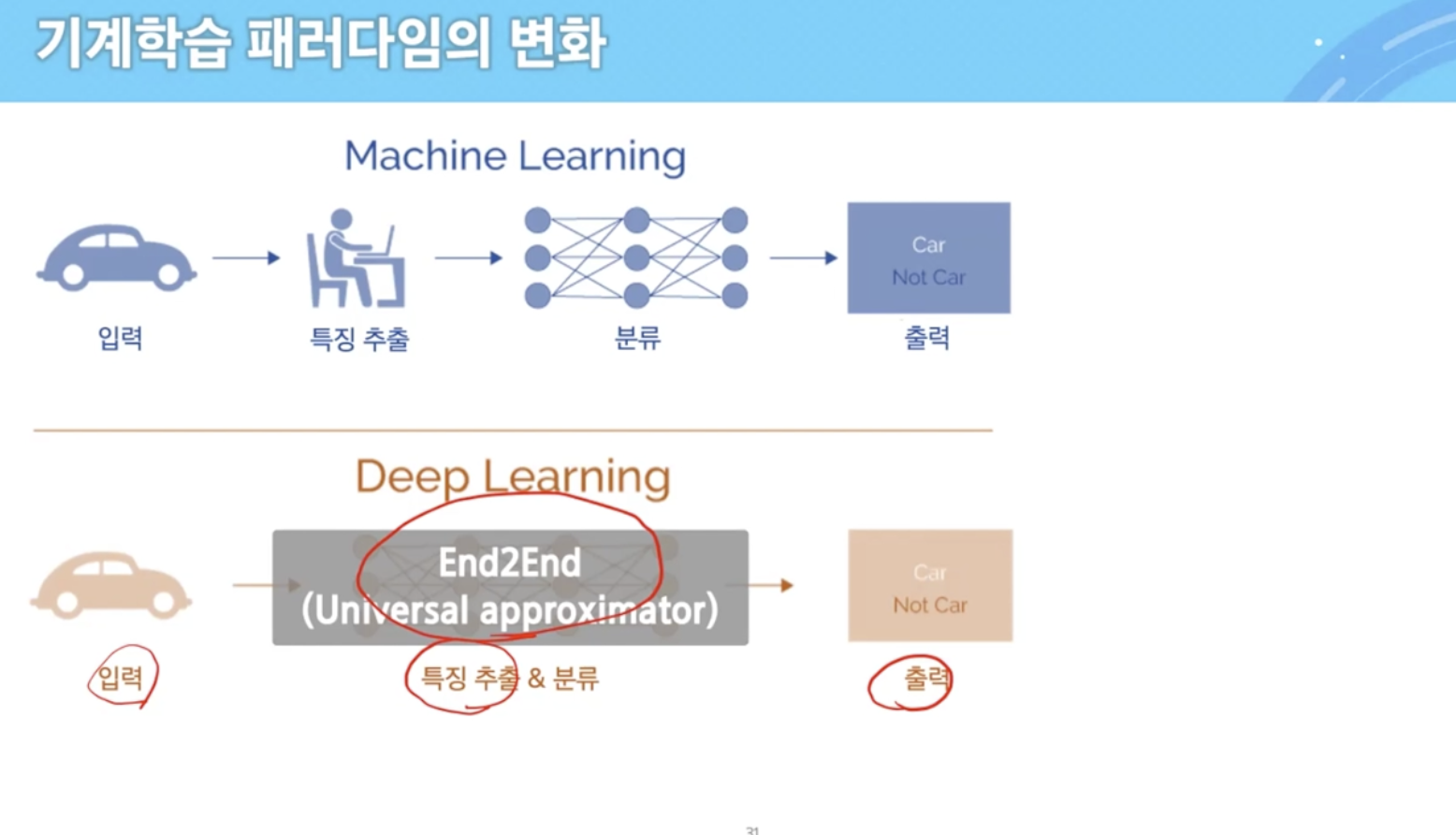
underfitting vs overfitting
- 그나마 overfitting이 낫다.
- underfitting은 학습 데이터 자체도 fitting이 잘 안 됨
- 모델 설정부터 잘못 되었다.
- 둘 다 model의 mismatch

매일 조금씩 성장하는 개발자