
Barebones PyTorch
PyTorch는 모델 아키텍처를 편리하게 정의할 수 있도록 high-level API와 함께 제공합니다. 본 파트에서는 high-level API를 다루기 전에 barebone PyTorch 부터 시작하여 autograd 엔진을 더 잘 이해할 수 있도록 합니다.
우리는 CIFAR-10 분류를 위해 두 개의 레이어와 ReLU로 구성된 간단한 fully-connected 네트워크로 시작합니다. 본 실습에서는 PyTorch Tensor의 연산을 사용하여 forward 패스를 계산하고 PyTorch autograd를 사용하여 backward 패스의 그레이디언트를 계산합니다.
requires_grad=True로 PyTorch Tensor를 생성하면 해당 텐서는 단순히 값을 계산하는 연산만 하는 것이 아니라 백그라운드에서 계산 그래프를 구축하여 loss와 관련된 텐서의 그레이디언트 계산합니다. 구체적으로, 만약 x가 x.requires_grad == True인 Tensor라면, 역전파 후 x.grad는 마지막에 스칼라 loss값과 관련하여 x의 그레디언트를 기록하는 또 다른 Tensor가 됩니다.
PyTorch Tensors: Flatten 함수
PyTorch Tensor는 numpy array와 유사합니다. numpy와 마찬가지로 PyTorch에서도 효율적인 Tensor 연산을 위해 많은 함수들을 제공합니다. 간단한 예로, fully-connected 네트워크에 이미지 입력을 위하여 이미지 데이터를 reshape하는 flatten 함수를 제공합니다.
이미지 데이터는 일반적으로 N x C x H x W 형태의 Tensor로 저장됩니다. 여기서,
N is the number of datapoints
C is the number of channels
H is the height of the intermediate feature map in pixels
W is the width of the intermediate feature map in pixels
위의 Tensor 형태의 경우, 2D 컨볼루션과 같은 공간적 이해를 필요로 하는 레이어를 적용할때 적절한 데이터 형태 입니다. 그러나 fully-connected 네트워크를 사용하여 이미지 데이터를 처리할 때 각 데이터가 단일 벡터로 표현되어야 합니다. 따라서 데이터 당 C x H x W값을 하나의 긴 벡터 형태로 변환해주기 위해 "flatten" 연산을 사용합니다. "flatten" 함수는 먼저 주어진 데이터 배치에서 N, C, H 및 W 값을 읽은 다음 해당 데이터의 "view"를 반환합니다. "view"는 numpy의 "reshape" 방법과 유사합니다.
def flatten(x):
N = x.shape[0] # read in N, C, H, W
return x.view(N, -1) # "flatten" the C * H * W values into a single vector per image
def test_flatten():
x = torch.arange(12).view(2, 1, 3, 2)
print('Before flattening: ', x)
print('After flattening: ', flatten(x))
test_flatten()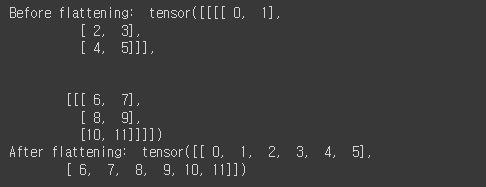
Barebones PyTorch: Two-Layer Network
Forward 패스를 수행하는 두개의 레이어를 가진 fully-connected ReLU 모델을 two_layer_fc의 이름으로 정의합니다. 정의한 이후 모델이 잘 동작하는지 확인하기 위해 zeros 값을 넣어봅니다. 본 실습에서는 별도로 코드를 작성하진 않지만, 구현된 코드를 자세히 읽어보고 다 이해하도록 합니다.
import torch.nn.functional as F # useful stateless functions
def two_layer_fc(x, params):
"""
Fully-connected 네트워크는 다음과 같이 구성되어 있습니다:
fully connected -> ReLU -> fully connected layer.
위의 정의는 forward 패스만 구현한 것이고, backward 패스는 PyTorch가 자동으로 구현합니다.
Inputs:
- x: A PyTorch Tensor of shape (N, d1, ..., dM) giving a minibatch of
input data.
- params: A list [w1, w2] of PyTorch Tensors giving weights for the network;
w1 has shape (D, H) and w2 has shape (H, C).
Returns:
- scores: A PyTorch Tensor of shape (N, C) giving classification scores for
the input data x.
"""
# 먼저 이미지를 flatten 합니다.
x = flatten(x) # shape: [batch_size, C x H x W]
w1, w2 = params
# Forward 패스: Tensor에 정의된 operation을 활용하여 y값을 예측합니다.
# w1과 w2는 requires_grad=True로 되어 있기 때문에 자동으로 계산 그래프를 구축하여
# 자동으로 gradient값을 계산할 수 있습니다.
# 따라서 수동으로 backward 패스를 구현하지 않아도 됩니다.
x = F.relu(x.mm(w1))
x = x.mm(w2)
return x
def two_layer_fc_test():
hidden_layer_size = 42
x = torch.zeros((64, 50), dtype=dtype) # minibatch size 64, feature dimension 50
# weight값 초기화
w1 = torch.zeros((50, hidden_layer_size), dtype=dtype, requires_grad=True)
w2 = torch.zeros((hidden_layer_size, 10), dtype=dtype, requires_grad=True)
scores = two_layer_fc(x, [w1, w2])
print(scores.size()) # you should see [64, 10]
two_layer_fc_test()Barebones PyTorch: Three-Layer ConvNet
Forward 패스를 수행하는 세개의 컨볼루션 레이어를 가진 모델을 three_layer_convnet의 이름으로 정의합니다. 앞선 실습과 마찬가지로 정의한 모델이 잘 동작하는 지 확인하기 위해 zero 값을 넣어봅니다. 네트워크 아키텍쳐는 다음과 같아야 합니다.
A convolutional layer (with bias) with channel_1 filters, each with shape KW1 x KH1, and zero-padding of two ReLU nonlinearity
A convolutional layer (with bias) with channel_2 filters, each with shape KW2 x KH2, and zero-padding of one ReLU nonlinearity
Fully-connected layer with bias, producing scores for C classes.
본 실습에서는 마지막 fully-connected layer 이후에 softmax activation이 없습니다. 이는 PyTorch의 cross entropy loss가 자동으로 softmax activation을 연산해주기 때문입니다.
HINT: For convolutions: http://pytorch.org/docs/stable/nn.html#torch.nn.functional.conv2d; pay attention to the shapes of convolutional filters!
# Req. 1-2 Three-Layer ConvNet 의 forward 패스 Tensor 연산으로 설계하기
def three_layer_convnet(x, params):
"""
아래 정의된 모델은 3개의 컨볼루션 레이어를 갖는 네트워크의 forward 패스를 수행합니다.
Inputs:
- x: 이미지의 minibatch로 구성된 (N, 3, H, W) shape의 PyTorch 텐서
- params: 네트워크의 weights와 biases를 담은 PyTorch 텐서의 리스트, 아래 내용들 포함
- conv_w1: PyTorch Tensor of shape (channel_1, 3, KH1, KW1) giving weights
for the first convolutional layer
- conv_b1: PyTorch Tensor of shape (channel_1,) giving biases for the first
convolutional layer
- conv_w2: PyTorch Tensor of shape (channel_2, channel_1, KH2, KW2) giving
weights for the second convolutional layer
- conv_b2: PyTorch Tensor of shape (channel_2,) giving biases for the second
convolutional layer
- fc_w: PyTorch Tensor giving weights for the fully-connected layer.
- fc_b: PyTorch Tensor giving biases for the fully-connected layer.
Returns:
- scores: PyTorch Tensor of shape (N, C) giving classification scores for x
"""
conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b = params
scores = None
################################################################################
# TODO: Implement the forward pass for the three-layer ConvNet. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
F=torch.nn.functional.conv2d
x1=torch.nn.functional.conv2d(x,conv_w1,padding=2)+conv_b1.view(1,-1,1,1)
x2=torch.nn.functional.conv2d(x1.clamp(min=0),conv_w2,padding=1)+conv_b2.view(1,-1,1,1)
x3=x2.view(x1.shape[0],-1).clamp(min=0).mm(fc_w)+fc_b
scores=x3
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
################################################################################
# END OF YOUR CODE #
################################################################################
return scoresForward 패스에 해당하는 ConvNet을 정의한 이후 다음 cell을 실행하여 구현한 코드를 확인해봅니다.
다음 함수를 실행하면, (64,10) shape을 갖는 score값을 출력하게 됩니다.
def three_layer_convnet_test():
x = torch.zeros((64, 3, 32, 32), dtype=dtype) # minibatch size 64, image size [3, 32, 32]
conv_w1 = torch.zeros((6, 3, 5, 5), dtype=dtype, requires_grad=True) # [out_channel, in_channel, kernel_H, kernel_W]
conv_b1 = torch.zeros((6,), requires_grad=True) # out_channel
conv_w2 = torch.zeros((9, 6, 3, 3), dtype=dtype, requires_grad=True) # [out_channel, in_channel, kernel_H, kernel_W]
conv_b2 = torch.zeros((9,), requires_grad=True) # out_channel
# you must calculate the shape of the tensor after two conv layers, before the fully-connected layer
fc_w = torch.zeros((9 * 32 * 32, 10), requires_grad=True)
fc_b = torch.zeros(10, requires_grad=True)
scores = three_layer_convnet(x, [conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b])
print(scores.size()) # you should see [64, 10]
three_layer_convnet_test()Barebones PyTorch: Initialization
몇가지 utility 메소드를 활용하여 모델의 weight matrices를 초기화해봅니다.
random_weight(shape) 은 weight값을 Kaiming normalization method로 초기화 합니다.
zero_weight(shape) 은 wieght값을 0으로 초기화 합니다.
random_weight 함수는 Kaiming normal initialization method로, 아래의 논문을 참고하면 됩니다:
He et al, Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, ICCV 2015, https://arxiv.org/abs/1502.01852
def random_weight(shape):
"""
Weight을 위한 랜덤 텐서를 생성합니다. 이때 requires_grad=True로 세팅해주어야
추후에 backward 패스에서 사용할 gradient를 자동으로 계산할 수 있습니다.
여기서 Kaiming normalization을 사용합니다: sqrt(2 / fan_in)
"""
if len(shape) == 2: # FC weight
fan_in = shape[0]
else:
fan_in = np.prod(shape[1:]) # conv weight [out_channel, in_channel, kH, kW]
# randn is standard normal distribution generator.
w = torch.randn(shape, device=device, dtype=dtype) * np.sqrt(2. / fan_in)
w.requires_grad = True
return w
def zero_weight(shape):
return torch.zeros(shape, device=device, dtype=dtype, requires_grad=True)
# create a weight of shape [3 x 5]
# you should see the type `torch.cuda.FloatTensor` if you use GPU.
# Otherwise it should be `torch.FloatTensor`
random_weight((3, 5))
Barebones PyTorch: Check Accuracy
모델을 학습할 때 다음의 함수를 활용하여 모델의 정확성을 확인합니다. 정확도를 확인할 때에는 gradient를 계산할 필요가 없습니다. 따라서 torch.no_grad()를 입력하여 계산 그래프의 gradient 계산을 막습니다.
def check_accuracy_part2(loader, model_fn, params):
"""
분류 모델의 정확성 측정
Inputs:
- loader: A DataLoader for the data split we want to check
- model_fn: A function that performs the forward pass of the model,
with the signature scores = model_fn(x, params)
- params: List of PyTorch Tensors giving parameters of the model
Returns: Nothing, but prints the accuracy of the model
"""
split = 'val' if loader.dataset.train else 'test'
print('Checking accuracy on the %s set' % split)
num_correct, num_samples = 0, 0
with torch.no_grad(): # gradient 계산할 필요가 없어, computational graph 를 그리지 않게 하기위해 with torch.no_grad() 사용
for x, y in loader:
x = x.to(device=device, dtype=dtype) # move to device, e.g. GPU
y = y.to(device=device, dtype=torch.int64)
scores = model_fn(x, params)
_, preds = scores.max(1)
num_correct += (preds == y).sum()
num_samples += preds.size(0)
acc = float(num_correct) / num_samples
print('Got %d / %d correct (%.2f%%)' % (num_correct, num_samples, 100 * acc))BareBones PyTorch: Training Loop
이제 학습 loop를 작성하여 네트워크를 학습합니다. 학습은 stochastic gradient descent를 사용합니다. 또한 torch.functional.cross_entropy 를 사용하여 loss를 측정합니다 read about it here.
학습 loop는 네트워크 함수와 초기화된 weight 파라미터 ([w1, w2] in our example), 그리고 learning rate을 입력으로 받습니다.
def train_part2(model_fn, params, learning_rate):
"""
CIFAR-10에 대하여 모델 학습하기.
Inputs:
- model_fn: 모델의 forward 패스를 수행하는 PyTorch 함수.
이는 이미지 데이터 x와 모델 weight의 list를 입력으로 받아 score를 출력하는 함수이다.
scores = model_fn(x, params)
- params: 모델 weight의 list
- learning_rate: scalar 값
Returns: Nothing
"""
for t, (x, y) in enumerate(loader_train):
# 데이터를 적절한 device에 올리기
x = x.to(device=device, dtype=dtype)
y = y.to(device=device, dtype=torch.long)
# Forward 패스를 수행하고, loss 계산하기
scores = model_fn(x, params)
loss = F.cross_entropy(scores, y)
# Backward 패스 수행
loss.backward()
# 모델의 weight 업데이트하기. wieght 업데이트 시에는 gradient 계산은
# torch.no_grad()를 사용하여 막는다
with torch.no_grad():
for w in params:
w -= learning_rate * w.grad
# Backward 패스를 마친 이후 수동으로 gradient 값을 0으로 초기화
w.grad.zero_()
if t % print_every == 0:
print('Iteration %d, loss = %.4f' % (t, loss.item()))
check_accuracy_part2(loader_val, model_fn, params)
print()BareBones PyTorch: Train a Two-Layer Network
이제 학습 loop 실행을 시작합니다. 먼저 앞서 정의한 weight 초기화 함수를 활용하여 w1와 w2를 정의합니다.
CIFAR-10의 각 미니배치의 Tensor shape은 [64, 3, 32, 32] 입니다.
이미지 데이터 x를 flatten한 뒤에 shape은 [64, 3 32 32]가 되어야 합니다. 이는 w1의 첫 dimension의 사이즈와 동일합니다. w1의 두번째 dimension의 사이즈는 hidden 레이어의 사이즈와 동일하고, 이는 동시에 w2의 첫 dimension의 사이즈와 동일합니다.
마지막으로, 네트워크의 출력은 10-dimensional vector이고, 이는 10개 클래스에 대한 확률을 나타냅니다.
별도로 hyperparameters를 수정하지 않고도 한 에폭 이후 40% 이상의 분류 정확도를 보이면 성공입니다.
hidden_layer_size = 4000
learning_rate = 1e-2
w1 = random_weight((3 * 32 * 32, hidden_layer_size))
w2 = random_weight((hidden_layer_size, 10))
train_part2(two_layer_fc, [w1, w2], learning_rate)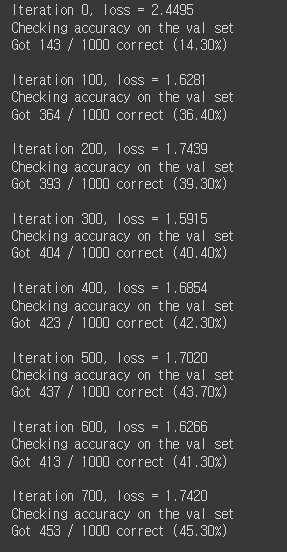
BareBones PyTorch: Training a ConvNet
Two-layer 네트워크 학습이 마쳤다면, 여기에서는 ConvNet을 학습시켜 봅니다. 여기서 정의해야할 네트워크는 다음과 같은 구조를 가져야 합니다.
Convolutional layer (with bias) with 32 5x5 filters, with zero-padding of 2
ReLU
Convolutional layer (with bias) with 16 3x3 filters, with zero-padding of 1
ReLU
Fully-connected layer (with bias) to compute scores for 10 classes
모든 weight matrices는 앞서 정의한 random_weight 함수를 사용하여 초기화 시켜 주어야 하고, bias vector는 zero_weight 함수로 초기화 시켜 줍니다.
별도로 hyperparameters를 수정하지 않고도 한 에폭 이후 42% 이상의 분류 정확도를 보이면 성공입니다.
# Req. 1-3 Three-Layer ConvNet의 weight 파라미터를 Tensor 형태로 초기화
learning_rate = 3e-3
channel_1 = 32
channel_2 = 16
conv_w1 = None
conv_b1 = None
conv_w2 = None
conv_b2 = None
fc_w = None
fc_b = None
################################################################################
# TODO: Initialize the parameters of a three-layer ConvNet. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
conv_w1=random_weight([32,3,5,5])
conv_b1=zero_weight(32)
conv_w2=random_weight([16,32,3,3])
conv_b2=zero_weight(16)
fc_w=random_weight([16*32*32,10])
fc_b=zero_weight(10)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
################################################################################
# END OF YOUR CODE #
################################################################################
params = [conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b]
train_part2(three_layer_convnet, params, learning_rate)