
1. 프로젝트 개요
공공데이터 포털에서 다운 받은
서울시 행정구역별 강력범죄 발생건수데이터를 활용한
데이터 분석 프로젝트❕
2. 데이터 개요
import pandas as pd import numpy as np
◾ 데이터 읽기
crime_raw_data = pd.read_csv( "../data/02.crime_in_Seoul.csv", thousands=",", # 쉼표로 구분된 숫자 데이터를 문자가 아닌 숫자 데이터로 읽어오게끔 하는 설정 encoding="euc-kr" # 공공데이터를 그냥 바로 가져오면 에러가 나는 경우가 많아 한글 인코딩 필요 ) crime_raw_data.head() # head()로 잘 불러와졌는지 확인
✔
info()로 데이터 개요 확인crime_raw_data.info() # RangeIndex가 65,534인데, 널 값이 아닌 데이터는 310개 뿐이다.
✔
unique()로 유일한 값 확인crime_raw_data["죄종"].unique() # "죄종" 컬럼의 값 중에 nan 값이 있음을 알 수 있다.
✔ null값 제외
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()] crime_raw_data.info() # 310개의 값만 존재하는 것이 확인된다.
✅ 널값을 없애서 데이터 용량이 2.0+ MB에서 12.1+KB로 줄어들었다.
✅ 나중에 딥러닝을 하게 되면 용량 관리가 중요해져서 이런거 하나하나 세팅하는게 굉장히 중요하다고 한다.✔
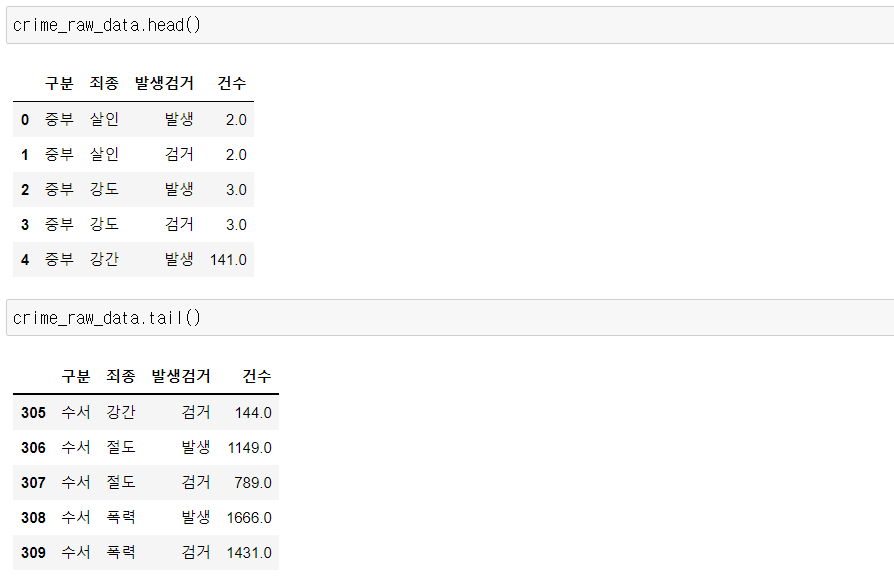
head(),tail()로 데이터가 잘 정리됐는지 확인crime_row_data.head() crime_row_data.tail()




3. Pandas pivot_table
- index, values, columns, aggfunc
✔ 엑셀파일을 읽기 위한 보조 프로그램 설치
!pip install openpyxl # 엑셀파일을 읽을 때 발생하는 오류 방지✔ 불러온 엑셀 파일 확인
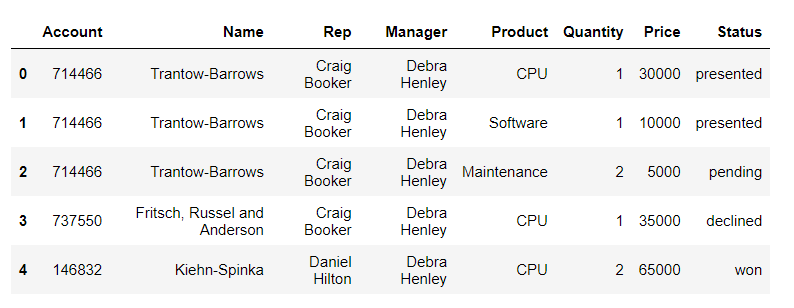
df = pd.read_excel("../data/02.sales.xlsx") df.head()
◾ index 설정
✔ Name 컬럼을 인덱스로 설정
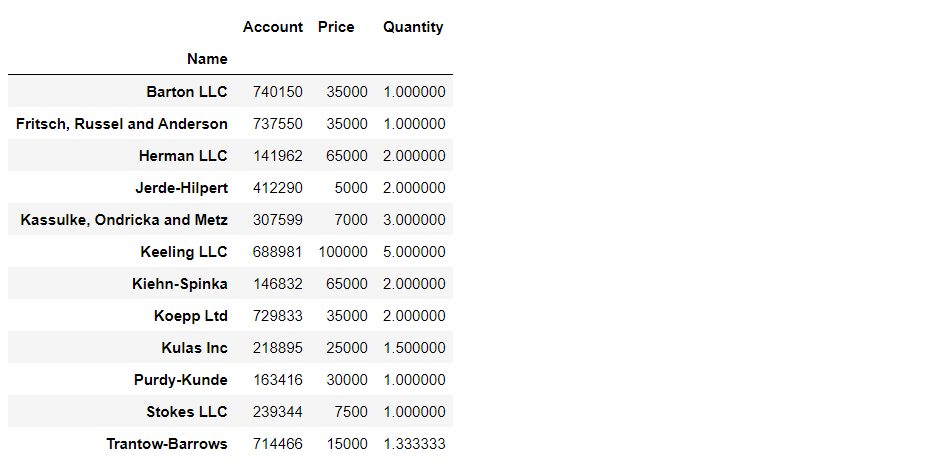
df.pivot_table(index="Name")
✔ 멀티 인덱스(다중 컬럼) 설정
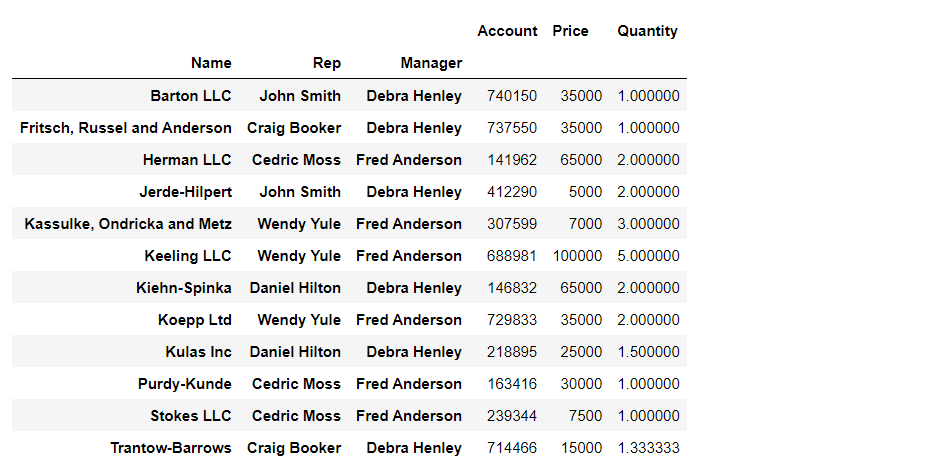
df.pivot_table(index=["Name", "Rep", "Manager"])
◾ values 설정
✅ index만 설정하면, value는 평균값으로 표현
✅ values를 지정하면, value값 그대로 표현df.pivot_table( index=["Manager", "Rep"], values="Price", aggfunc=[np.sum] )✅
np.sum연산 기능을 쓰는 이유는 그냥 파이썬sum기능을 쓰는 것과
약 5배의 속도 차이가 나기 때문이다.

◾ columns 설정
df.pivot_table( index=["Manager", "Rep"], values=["Price", "Quantity"], columns="Product", aggfunc=np.sum, fill_value=0, #Nan 값 0으로 채우기 margins=True # 총계(All) 나타내기 )
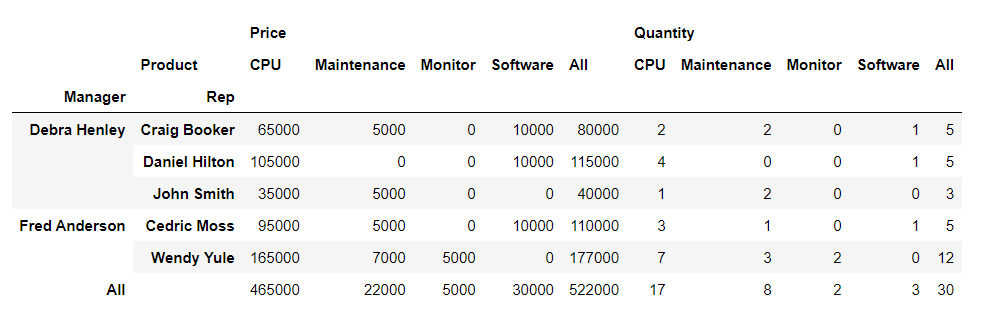
4. 서울시 범죄 현황 데이터 정리
✔ 데이터 구성 다시 확인
crime_raw_data.head(1)

◾ pivot_table
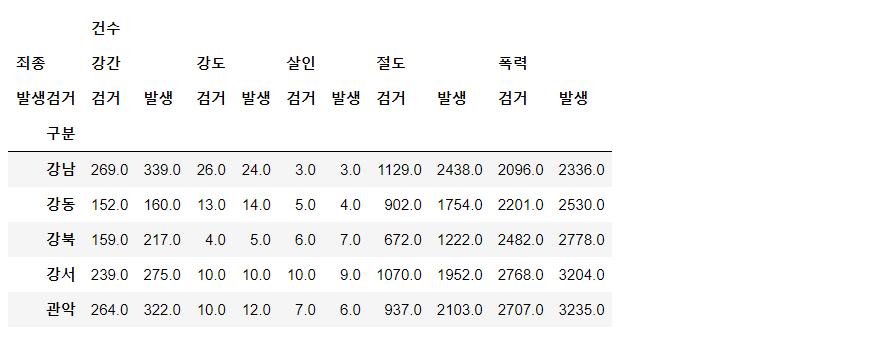
crime_station = crime_raw_data.pivot_table( crime_raw_data, index="구분", columns=["죄종", "발생검거"], aggfunc=np.sum ) crime_station.head() # 구분별 죄종-발생검거별 건수의 합계
✔ 컬럼 확인
crime_station.columns # 멀티인덱스로 나타난다.
✔ 다중 컬럼 정리
crime_station.columns = crime_station.columns.droplevel([0,1]) # 다중 컬럼에서 특정 컬럼 제거 crime_station.columns
✔ 확인
crime_station.head(1)



5. Google Maps API 설치
◾ 위도, 경도 데이터 가져오기
👉 Google Cloud에 가입한 뒤, Geocoding API 키 받기
✔
gmaps_keys변수에 복사한 API 키 저장gmaps_keys = "복사한 Geocoding API 키"✔
googlemaps다운받기# Windows, mac(intel) conda install -c conda-forge googlemaps # mac(m1) pip install googlemaps # !pip install googlemaps 도 가능import googlemaps #`Tab`키를 쳤을 때 자동완성되면 잘 다운로드 된 것✔
gmaps변수로 구글맵스 사용gmaps = googlemaps.Client(key=gmaps_keys)✔
geocode가 불러오는 데이터 형태 확인tmp = gmaps.geocode("서울영등포경찰서", language="ko") tmp # list안에 dictionary 형태
✔ 위도, 경도 데이터 추출 과정
tmp[0]
tmp[0].get("geometry")
tmp[0].get("geometry")["location"]
tmp[0].get("geometry")["location"]["lat"]
tmp[0].get("geometry")["location"]["lng"]
✔ 경찰서 이름에서 얻은 정보로 소속된 구이름 얻기
tmp[0].get("formatted_address")
tmp[0].get("formatted_address").split()[2] # Space(공백)를 기준으로 나눈 것 중 3번째 데이터








◾ 구별, lat, lng 컬럼 추가하기
👉 구이름, 위도, 경도 정보를 저장할 준비
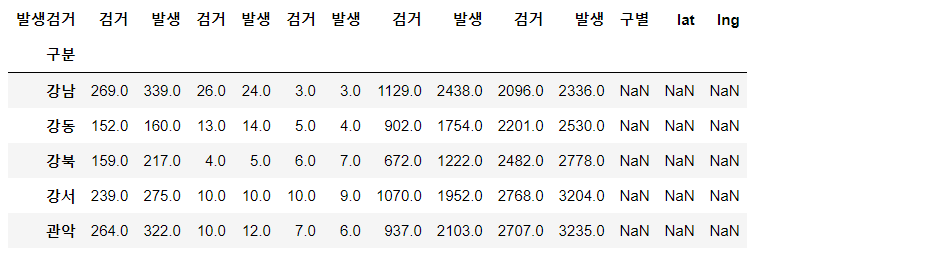
✔ nan값으로 채워진 컬럼들 추가
crime_station["구별"] = np.nan crime_station["lat"] = np.nan crime_station["lng"] = np.nan crime_station.head()
✔ 데이터 개수 확인
len(crime_station)
✔
tqdm설치 - 코드 수행 정도 파악 (필수X)!pip install tqdm from tqdm import tqdm_notebook

✔
for반복문 -iterrows()익히기for idx, rows in crime_station.iterrows(): print(idx, rows) print("==" * 100) # 가독성을 위한 구분선 출력
✔
station_name변수에 경찰서 이름 조합을 저장for idx, rows in crime_station.iterrows(): station_name = "서울" + str(idx) + "경찰서" # 문자 데이터는 `+`로 연결 print(station_name) # print()는 실제로 실행할 필요는 없지만 이해를 돕기 위해 실행 결과를 첨부
✔
station_name변수를 통해 얻은geocode데이터를tmp라는 새로운 변수에 저장tmp = gmaps.geocode(station_name, language="ko")✔
tmp에서 구 정보를 추출해tmp_gu변수에 저장tmp[0].get("formatted_address") tmp_gu = tmp[0].get("formatted_address")✔
lat,lng변수에 각각 위도, 경도 정보 저장lat = tmp[0].get("geometry")["location"]["lat"] lng = tmp[0].get("geometry")["location"]["lng"] # print(tmp_gu, lat, lng) # print("==" * 100) # 확인차 실행해 봄
✔ 각 컬럼에 정보 넣기 (여기까지 for문)
crime_station.loc[idx, "lat"] = lat crime_station.loc[idx, "lng"] = lng crime_station.loc[idx, "구별"] = tmp_gu.split()[2]✔ 잘 들어갔는지 확인!
crime_station.head()



✅ 주석처리/해제 단축키는 블록설정한 뒤 Ctrl + /
오늘은 여기까지~.~

3D 모델 플랫폼에서 데이터 분석을 하고 있습니다