안녕하세요!
저는 평소에 친구들사이에서 말차처돌이로 유명한데요🍵🍵🍵
그래서 "시카고 샌드위치🥪 맛집 분석" 을 하다가, 좀 더 제 삶과 밀접한 연관이 있는 프로젝트를 진행해보고 싶어졌습니다.
바로 실행에 옮기는 거 까진 쉬웠지만,,, 완성하는 데 까지는 꽤 많은 난관이 있었는데요...😂
사실 'BEST 30' 인데 더보기버튼을 눌러야 추가로 데이터가 로드되기 때문에, BeautifulSoup으로는 10개까지 밖에 긁어올 수가 없었어요😥
그래서 아직 미완성 프로젝트이긴 하지만! 그래도 1차 완성을 했다는 것에 뿌듯함을 느낍니다😎
조만간 Selenium을 익히고 나면 아마 완성할 수 있지 않을까 생각해봅니다!
1. 데이터 긁어오기
평소 유심히 봐두었던, 망고플레이트 "그린티라떼 맛집 베스트 30곳" 페이지의 html을 긁어옵니다.
https://www.mangoplate.com/top_lists/1426_greentea_latte
import pandas as pd
import numpy as np
import re # regular expression (정규표현식)사용을 위해
from bs4 import BeautifulSoup # 오늘의 핵심
from urllib.request import urlopen, Request #오늘의 핵심 2 url = 'https://www.mangoplate.com/top_lists/1426_greentea_latte'
req = Request(url, headers={'User-Agent': 'Chrome'})
# 그냥 불러오면 500 error가 납니다.
# 그래도 다행히 headers넣어주니까 잘 불러와졌습니다(안도의 한숨)
html = urlopen(req)
mang = BeautifulSoup(html, 'html.parser')
print(mang.prettify())
# prettify()는 들여쓰기를 실행해서 가독성을 높여줍니다.
Tip❕
fake_useragent로 사용하는 것도 가능합니다.# !pip install fake-useragent from fake_useragent import UserAgent ua = UserAgent() ua.ie # headers={'User-Agent': ua.ie}로 넣어서 사용하면 됩니다.
2. html코드 확인
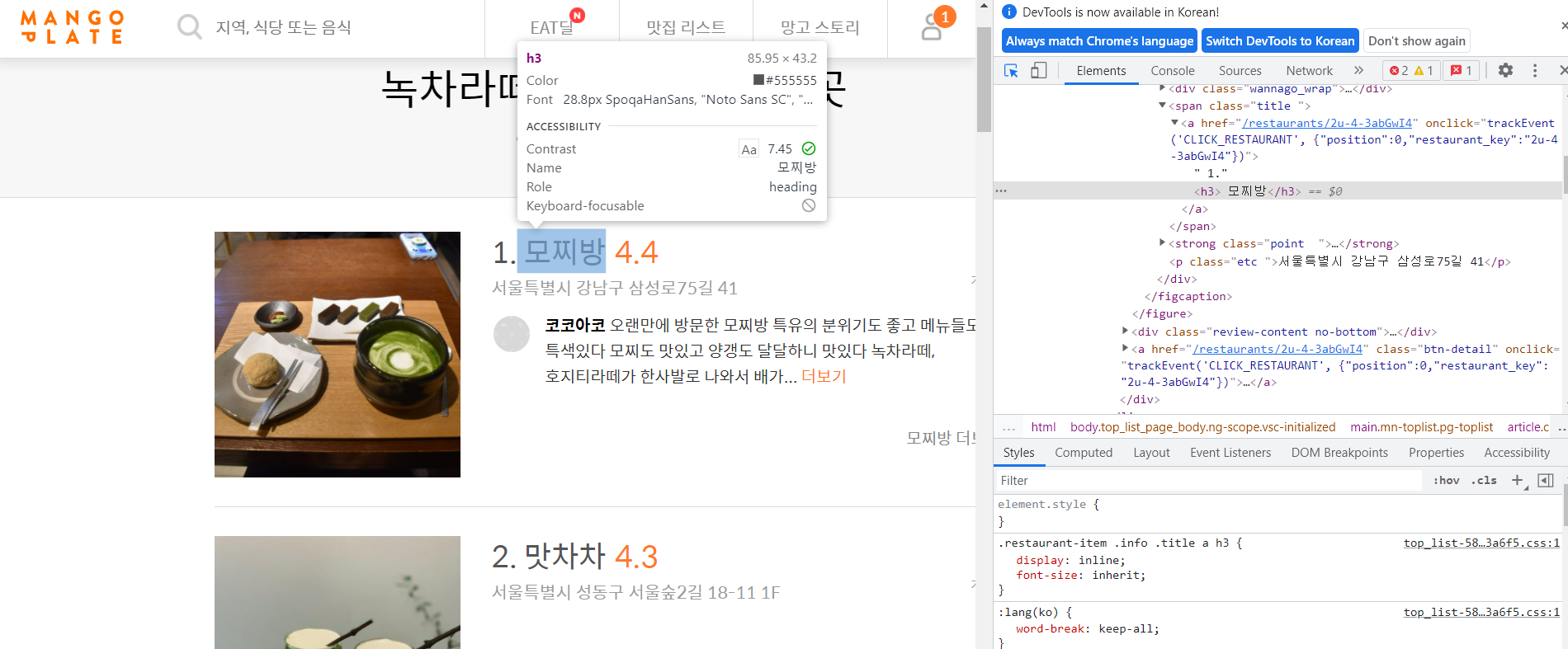
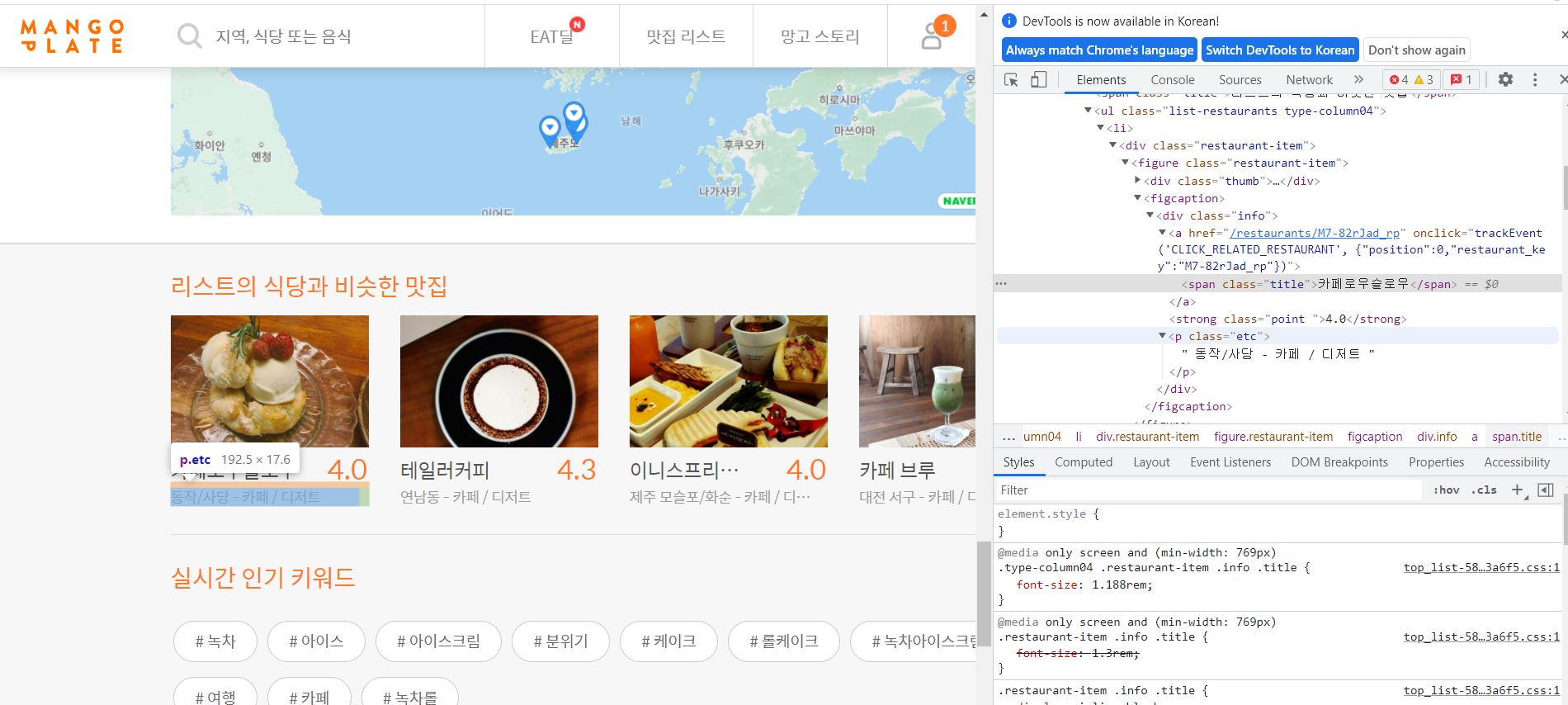
Chrome창에서 우측 상단에 점 세개 버튼을 누르면도구더보기가 있고, 거기서개발자도구를 누르면 html을 볼 수 있는 창이 뜹니다.- 커서모양이 있는 버튼을 누르면 원하는 부분의 html코드를 쉽게 찾을 수 있습니다.
- 태그와 속성, 속성값들을 확인하여 원하는 정보들을 불러올 준비를 합니다. 제가 필요한 정보는 '카페 이름', '평점', 지도시각화를 위한 '주소' 이렇게 세 가지로 일단 정해보았습니다.
3. 카페 이름, 평점, 주소 얻기
◾ 각각을
find()를 사용하여 필요한 데이터를 추출합니다.여기서부터 정말 삽질을 많이 했는데요.
결론부터 말하자면, "Simple is BEST" 입니다.
(만병통치(?)strip()짱..)
제가 삽질을 했던 이유는find()와find_all()을 혼동했기 때문입니다.find()는 제일 첫 번째 결과 하나만 불러오는 반면,find_all()은 모든 결과를 불러온다는 차이가 있습니다.
find()를 쓸 때는 바로.text를 쓸 수 있지만,find_all().text는 계속 오류가 납니다.find_all()[0].text코드는 결과가 출력됩니다.
(그런데find_all()[0].text이 코드를 사용하면 나중에for문을 돌릴때 또 오류가 납니다.....ㅠㅡㅠ (끝나지 않는 삽질...))
아무튼, 본인 Case의 필요, 편리, 취향에 따라 적절히 사용하시면 되겠습니다 :)
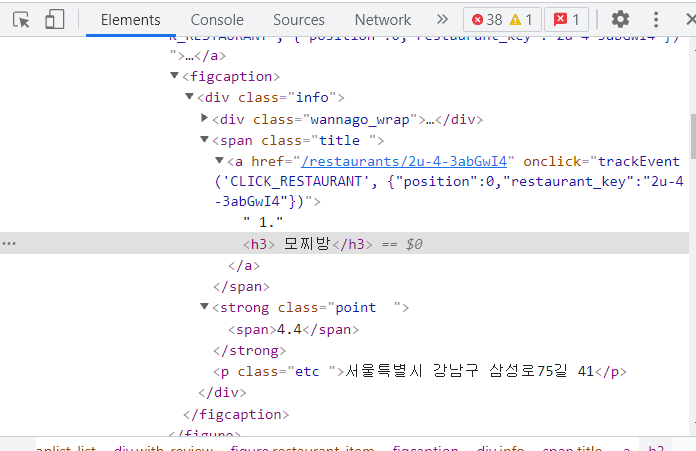
1) 카페 이름
➡ 카페이름은 span 태그의 title에 들어있습니다.
mang.find('span', 'title')
<span class="title">
<a href="/restaurants/2u-4-3abGwI4" onclick="trackEvent('CLICK_RESTAURANT', {"position":0,"restaurant_key":"2u-4-3abGwI4"})">
1.<h3> 모찌방</h3>
</a>
</span>mang.find('span', 'title').text
'\n\n 1. 모찌방\n\n'mang.find('span', 'title').text.strip()
'1. 모찌방'title = mang.find('span', 'title').text.strip() title[3:]
'모찌방'저 '모찌방' 세 글자만 떠 있는걸 보고 눈물이 날 뻔했습니다.ㅠㅠ
2) 평점
➡ 평점은 strong 태그의 point에 들어있습니다.
mang.find('strong', 'point')
<strong class="point">
<span>4.4</span>
</strong>mang.find('strong', 'point').text
'\n4.4\n'mang.find('strong', 'point').text.strip()
'4.4'+삽질의 흔적,,, (이렇게 해도 각각 '4.4'라는 결과값은 나오지만 역시나 for문에서 에러,,,,)
# 1 point_tmp = mang.find_all('strong', 'point')[0].span.text point_tmp # 2 tmp_string = mang.find(class_='point').text re.split(('\n|\r\n'), tmp_string)[1]
3) 주소
➡ 주소는 p 태그의 etc에 들어있습니다.
mang.find(class_='etc')
<p class="etc">서울특별시 강남구 삼성로75길 41</p>mang.find(class_='etc').text
'서울특별시 강남구 삼성로75길 41'주소가 가장 쉬웠습니다😂
4. for문으로 전체 데이터 추출하고 데이터프레임 만들기
이 부분에서도 정말 삽질을 많이했지만,
결국, 역시 깔끔하고 간단한 코드가 최선이었습니다. 하하하
1) for문 돌리기
# 빈 리스트들을 준비해둡니다.
name = []
point = []
address = []
# 세 가지 정보를 모두 포함하는 상위 태그로 선택하였습니다.
list_soup = mang.find_all('div', 'info')
# 각 리스트에 append()로 추가해줍니다.
for item in list_soup:
address.append(item.find('p', 'etc').text)
point.append(item.find('strong', 'point').text.strip())
title = item.find('span', 'title').text.strip()
name.append(title[3:])2) 완성된 리스트의 데이터 확인 후, 연관없는 데이터 삭제
len(name), len(point), len(address)(14, 14, 14)
❔데이터가 각각 10개여야 하는데 무언가 이상함을 감지😒
name, point, address
주소를 보면 보다 명확히 보이는데, 리스트 이외에 페이지 하단에 나오는 '리스트의 식당과 비슷한 맛집'의 정보가 같이 들어간 것으로 보입니다.
그래서 10개의 데이터만 남겼습니다.name = name[:10] point = point[:10] address = address[:10]
3) DataFrame 만들기
data = {
"Cafe":name,
'Point' : point,
'Address' : address
}
df = pd.DataFrame(data)
df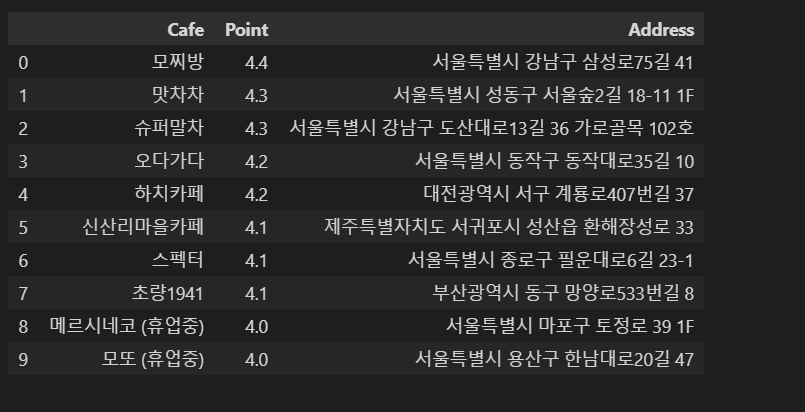
4) csv파일로 저장하고, 불러와보기
# 저장
df.to_csv(
'../hangni/best_greentea_list.csv', sep=',', encoding='utf-8'
)
# 불러오기
df = pd.read_csv('../hangni/best_greentea_list.csv', index_col=0)
df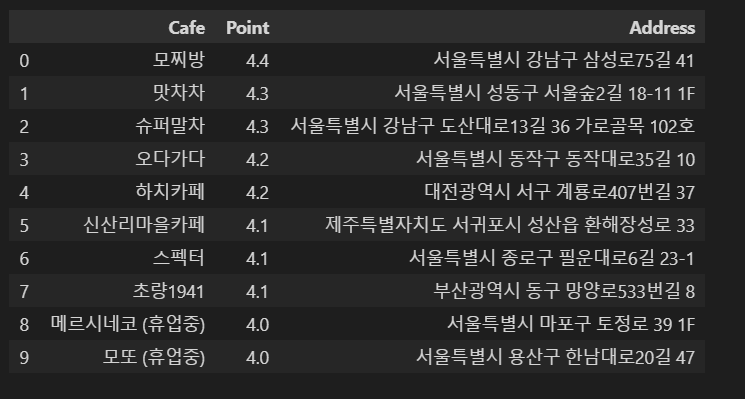
저장한 데이터프레임이 잘 불러와지네요. 이제 거의 다왔습니다!
5. googlemaps와 folium을 이용하여 지도시각화하기
1) googlemaps에서 [위도, 경도] 정보 얻어서 DataFrame에 추가하기
import folium
import googlemaps
gmaps_key = '본인의 API key number'
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode(df['Address'][0])[0].get('geometry') 시험삼아 첫 번째 행의 주소값으로
시험삼아 첫 번째 행의 주소값으로 geometry 정보를 불러와봤습니다.
geometry안에 location이 있고, 그 안에 lat(위도)값과 lng(경도)값이 있습니다. 이 값들을 불러와서 데이터프레임에 추가해줄겁니다.
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
lat.append(gmaps.geocode(row['Address'])[0].get('geometry')['location']['lat'])
lng.append(gmaps.geocode(row['Address'])[0].get('geometry')['location']['lng'])
df['lat'] = lat
df['lng'] = lng
df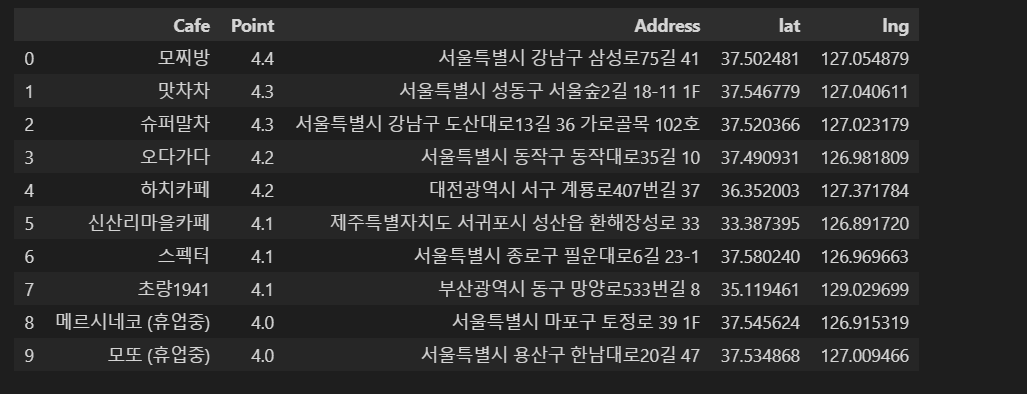 잘 들어갔네요! 이제 마지막 단계만을 놔두고 있습니다😉
잘 들어갔네요! 이제 마지막 단계만을 놔두고 있습니다😉
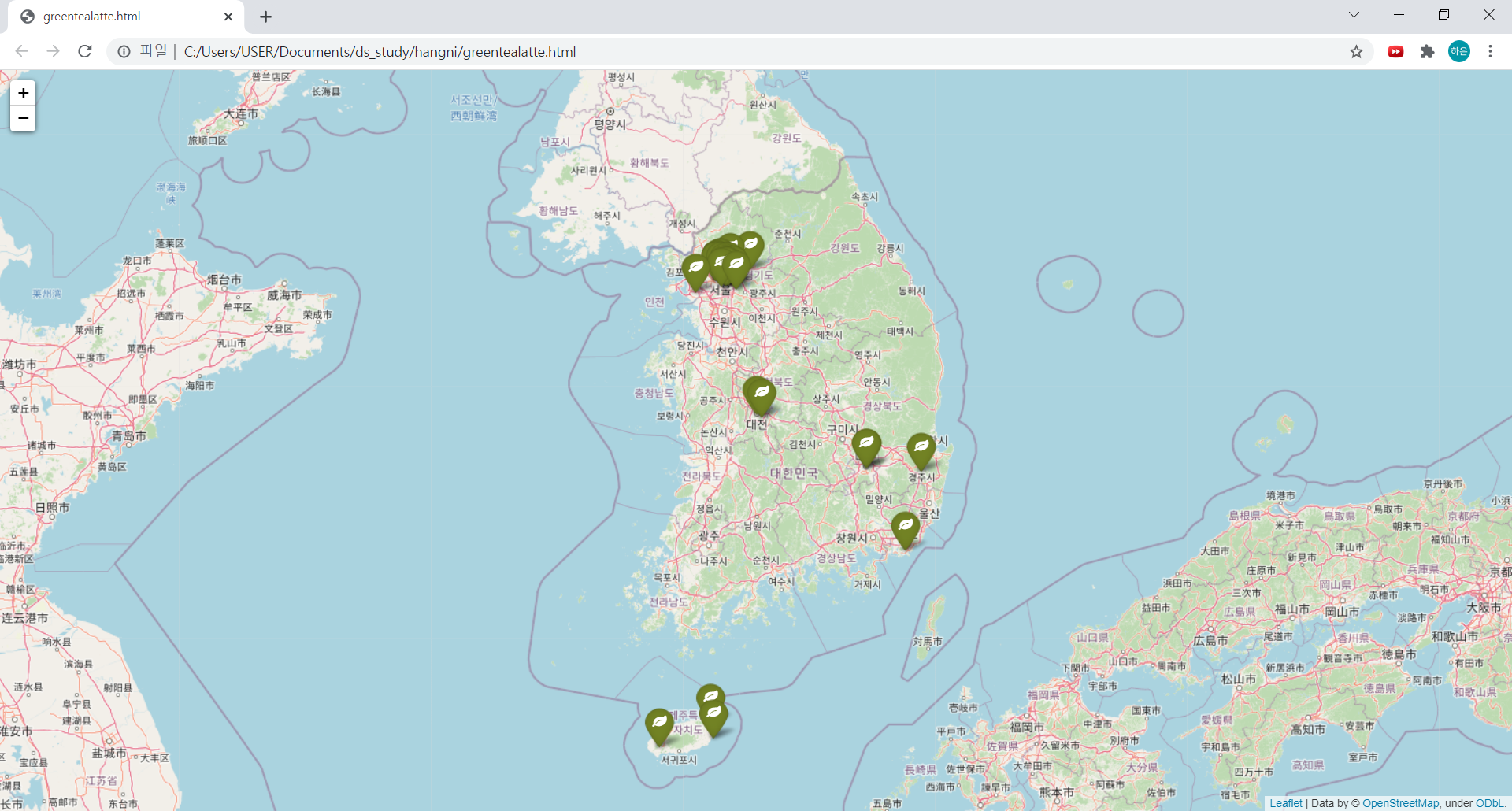
2) folium으로 지도시각화하기
# 서울 중심 좌표를 구글맵스에서 복사
mapping = folium.Map(location=[37.5330, 126.9794], zoom_start=12)
for idx, row in df.iterrows():
folium.Marker(
location=[row['lat'], row['lng']],
popup=row['Address'], # 마커 누르면 주소가 나오도록
tooltip=row['Cafe'], # 마커에 커서를 갖다대면 카페 이름이 나오도록
icon=folium.Icon(
color="darkgreen", # 녹차라떼 맛집이니까 다크그린!
icon_color='white',
icon='leaf', # 녹차 이파리
prefix='fa' # 아이콘 모양 옵션값
)
).add_to(mapping) # 지도에 마커 저장
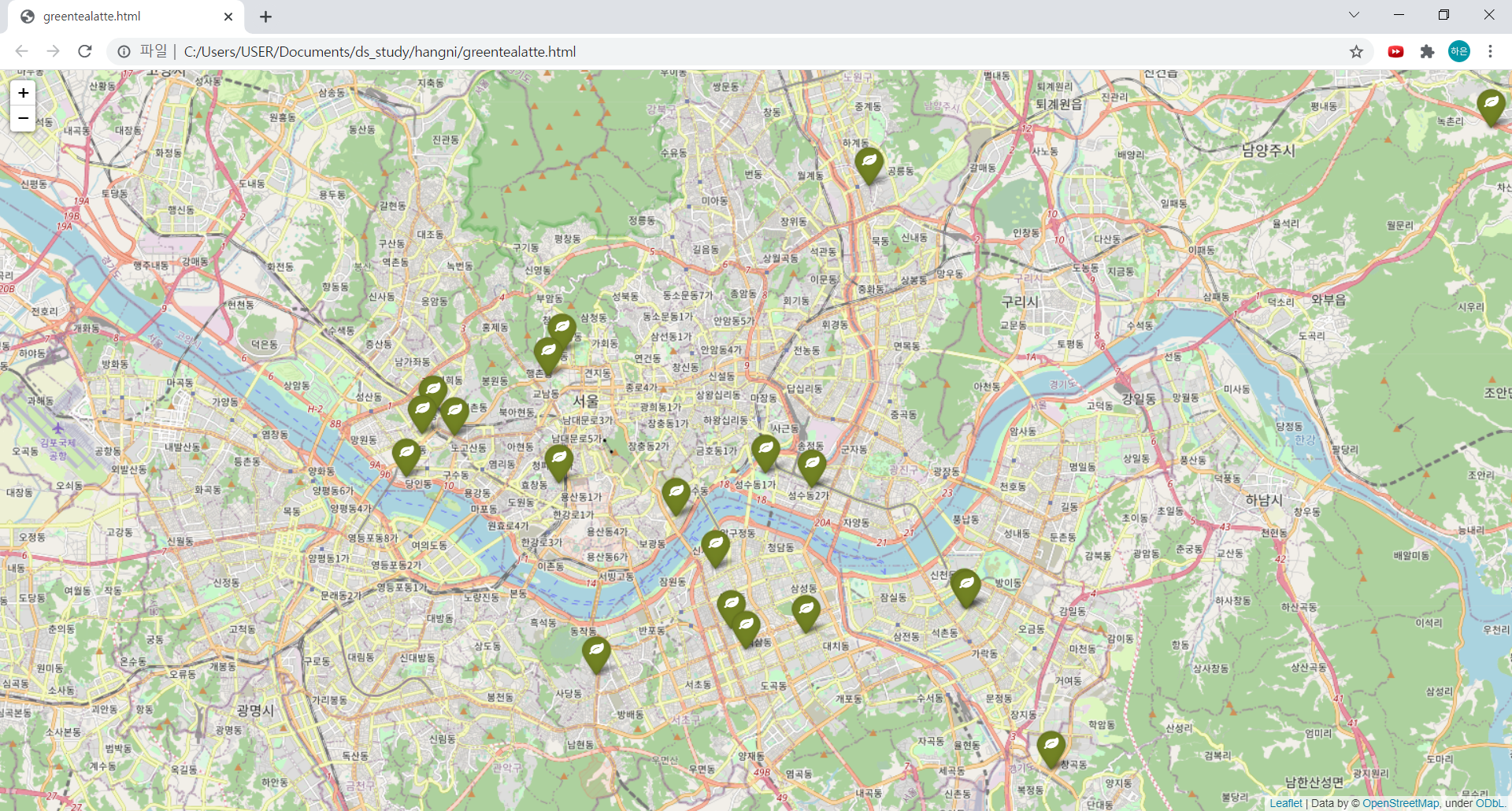
mapping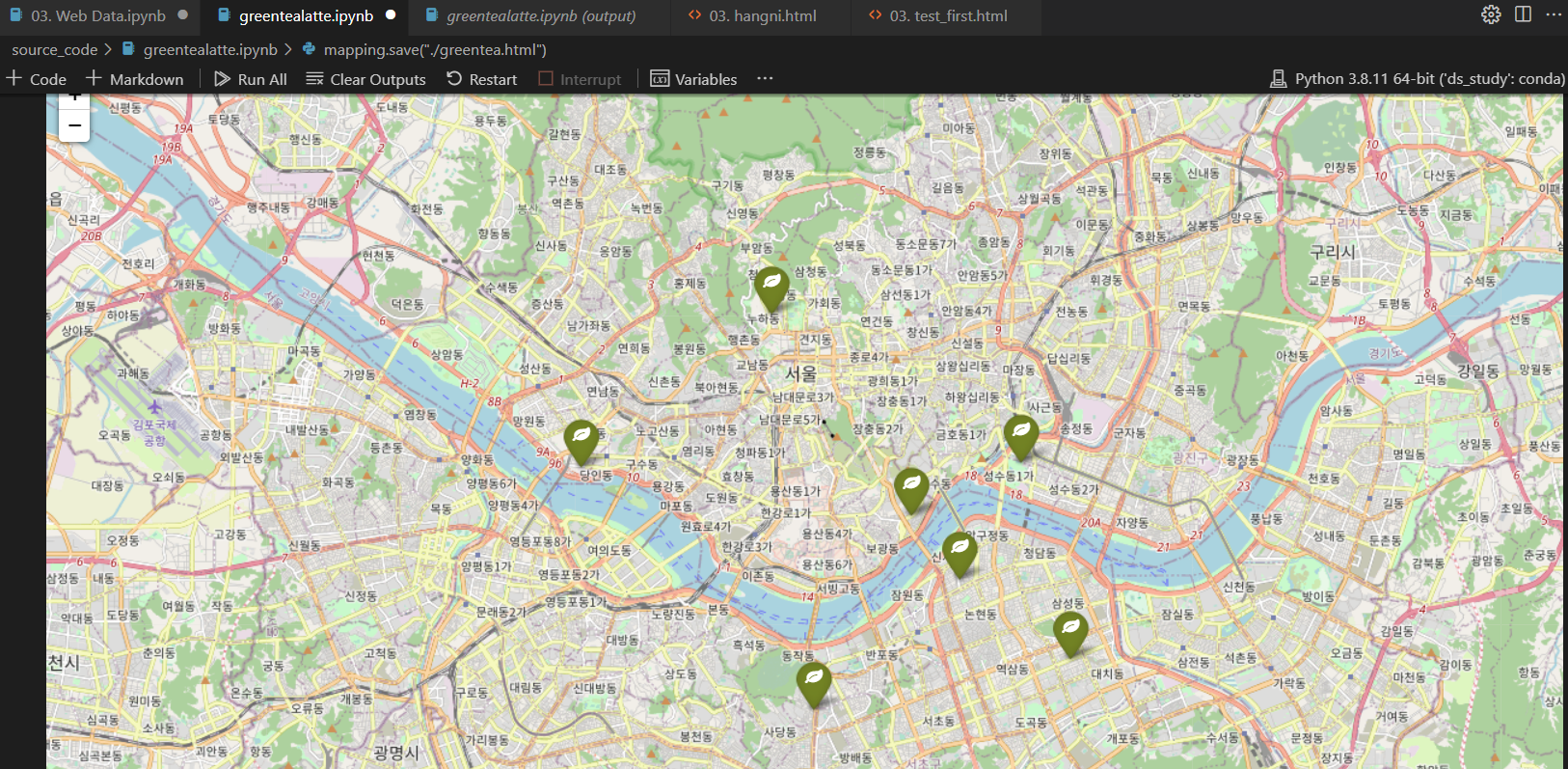
3) 지도 html로 저장하기
mapping.save("./greentea.html")저장된 파일을 크롬에서 열면 이렇게 창이 뜬답니다! 신기해...🤤
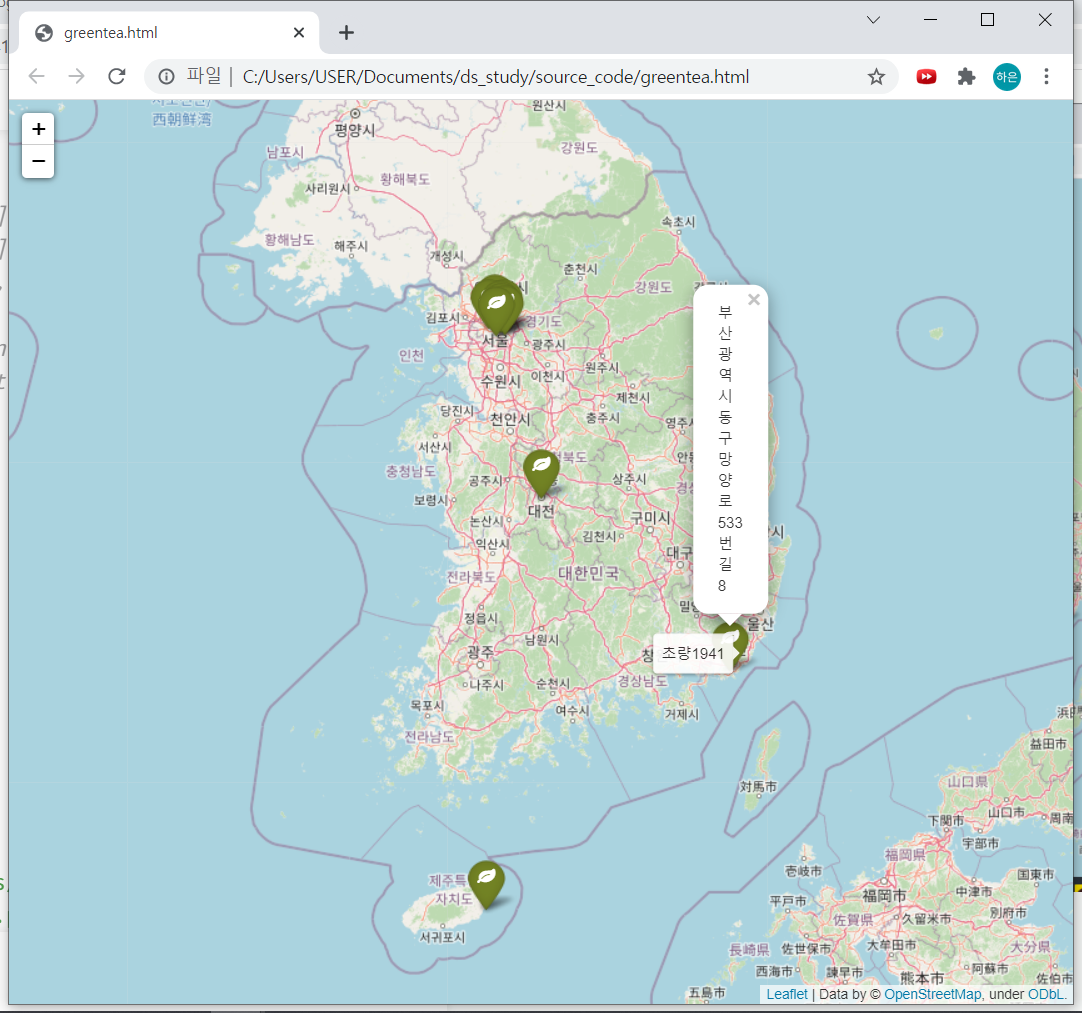
끝!
+개인적인 욕심으로는 popup에 이미지가 들어가면 더 좋을거같아서 그것도 한번 찾아봐야겠습니다😁
-------------------------------------- (2021.10.17 추가!) --------------------------------------
<말차🍵 프로젝트> 상위호환 버전을 완성해서 들고왔습니다!
달라진 부분은 처음에 html 코드를 바로 긁어오는 것이 아니라
selenium을 활용한 동적페이지 크롤링이 추가된 것입니다.
먼저 페이지에 접속하여 '더보기' 버튼을 selenium을 통해 눌러준다음, 속도가 빠른 BeautifulSoup으로 정적페이지 html을 긁어오면 된답니다!
selenium설치!pip install selenium import warnings from selenium import webdriver from selenium.webdriver import ActionChains warnings.simplefilter(action='ignore')
망고플레이트 페이지 접속
driver = webdriver.Chrome('../driver/chromedriver.exe') driver.get('https://www.mangoplate.com/top_lists/1426_greentea_latte') time.sleep(10)제 컴퓨터는 너무 느리게 창이 로드되어서 타임슬립을 10으로 넉넉히 주었습니다.
더보기버튼 클릭 2번 반복for i in range(2): some_tag = driver.find_element_by_css_selector('#contents_list > div > button') action = ActionChains(driver) action.move_to_element(some_tag).perform() # 더보기버튼 위치로 이동 some_tag.click() # 버튼 클릭 time.sleep(2)
현재 페이지 소스
BeautifulSoup으로 긁어오기from bs4 import BeautifulSoup req = driver.page_source # 현재 페이지 소스 변수에 저장 soup = BeautifulSoup(req, 'html.parser') print(soup.prettify())
이후 과정은 앞의 3번 이후 과정과 동일하니 생략하도록 할게요!ㅎㅎ
완성된 지도!
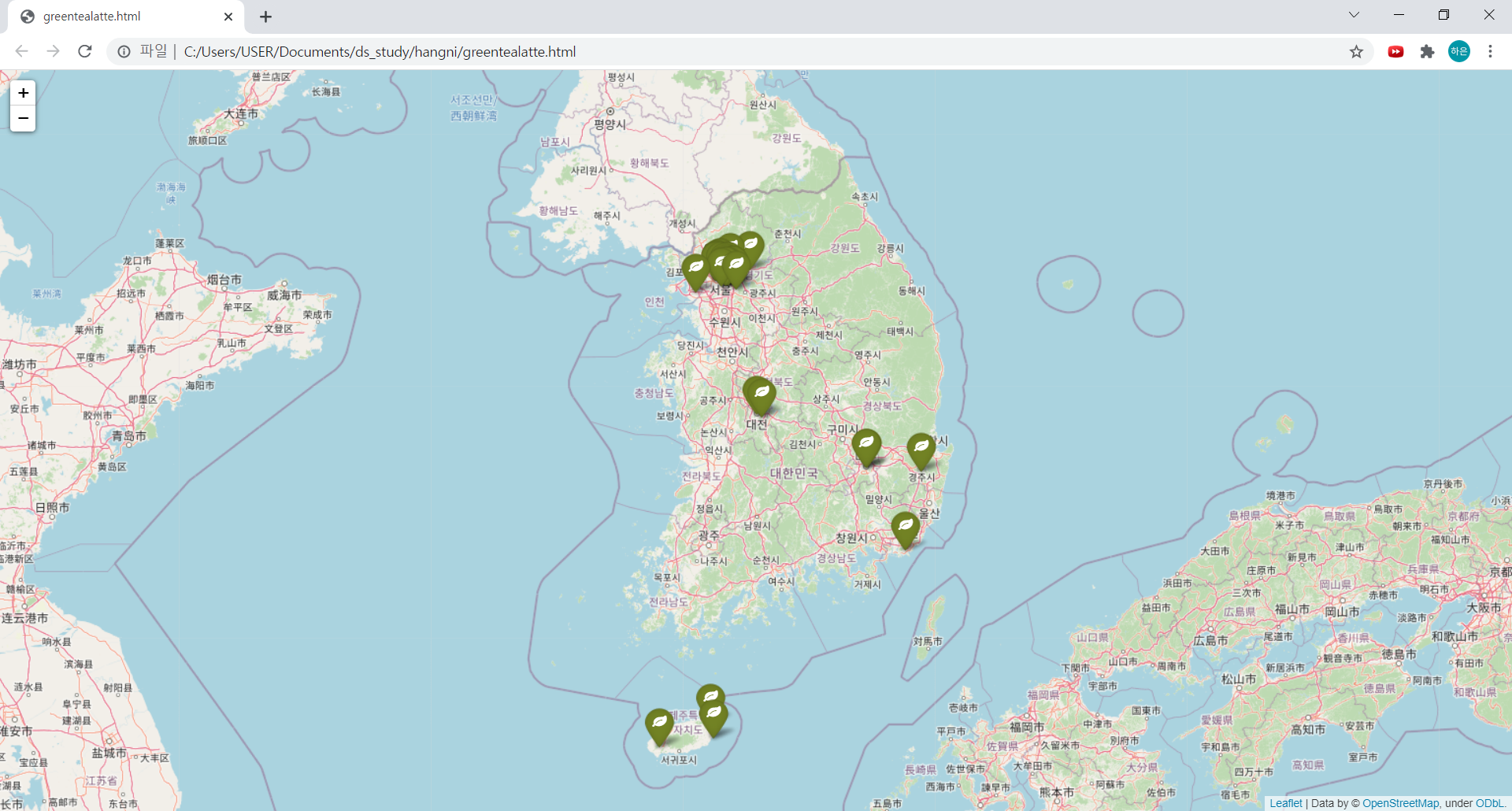

똑같은 결과만 두번 출력되는데 어떻게 해결하나요?