
이번 프로젝트는 TIOBE라는 소프트웨어 품질 평가 전문사이트에서 주기적으로 발표하는 TIOBE INDEX 상위권 언어들의 실제 체감 인기도는 어떠한지 분석해보는 것입니다.
TIOBE INDEX는 프로그래밍 언어 커뮤니티 지수로 ,
구글, 빙, 야후, 위키피디아, 아마존, 유튜브, 바이두 등 인기 검색 엔진들 중심의 인기 지표입니다. 매월 순위가 공개되며 프로그래밍 언어의 품질 및 성능과는 무관합니다.
프로그래밍 언어들의 체감 인기도를 확인할 수 있는 지표로는 다양한 것들이 있겠지만, 이번 분석에서는 출판되는 책의 양에 초점을 맞추어보았습니다.
2020년, C와 Java의 양강체제를 무너뜨리고 TIOBE에서 올해의 프로그래밍 언어 상 을 수상한 Python의 실제 체감 인기 역시 1위일지 한번 확인해볼까요?!
I. 데이터 크롤링 및 전처리
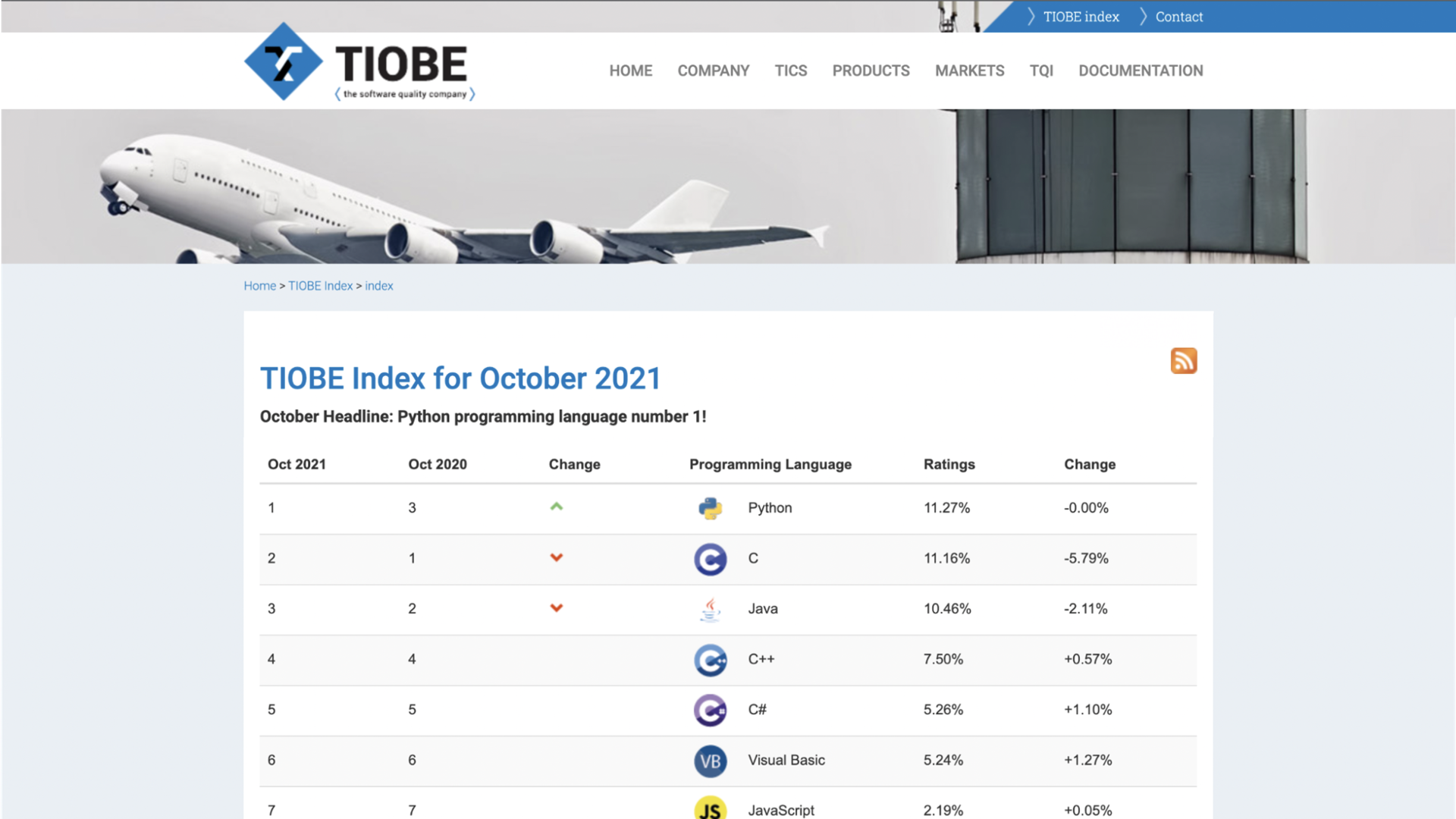
1. TIOBE INDEX 페이지 크롤링
1~9위 +
R까지 총 10개의 프로그래밍 언어 정보를 크롤링!
1) BeautifulSoup으로 순위정보 긁어오기
import pandas as pd
import numpy as np
import requests
import time
import re
from bs4 import BeautifulSoup
from urllib.request import urlopen
warnings.simplefilter(action='ignore')
>
url = 'https://www.tiobe.com/tiobe-index/'
response = urlopen(url)
# response.status
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify())
2) DataFrame 만들기
datas = []
>
for tio in tiobe_index[:14]:
r_2021 = tio.select('tr > td')[0].text # 2021 순위
r_2020 = tio.select('tr > td')[1].text # 2020 순위
name = tio.select('tr > td')[4].text # 언어 이름
rates = tio.select('tr > td')[5].text # 점유율
datas.append({
'rank_2021':r_2021,
'language':name,
'ratings':rates,
'rank_2020':r_2020
})
df = pd.DataFrame(datas)
df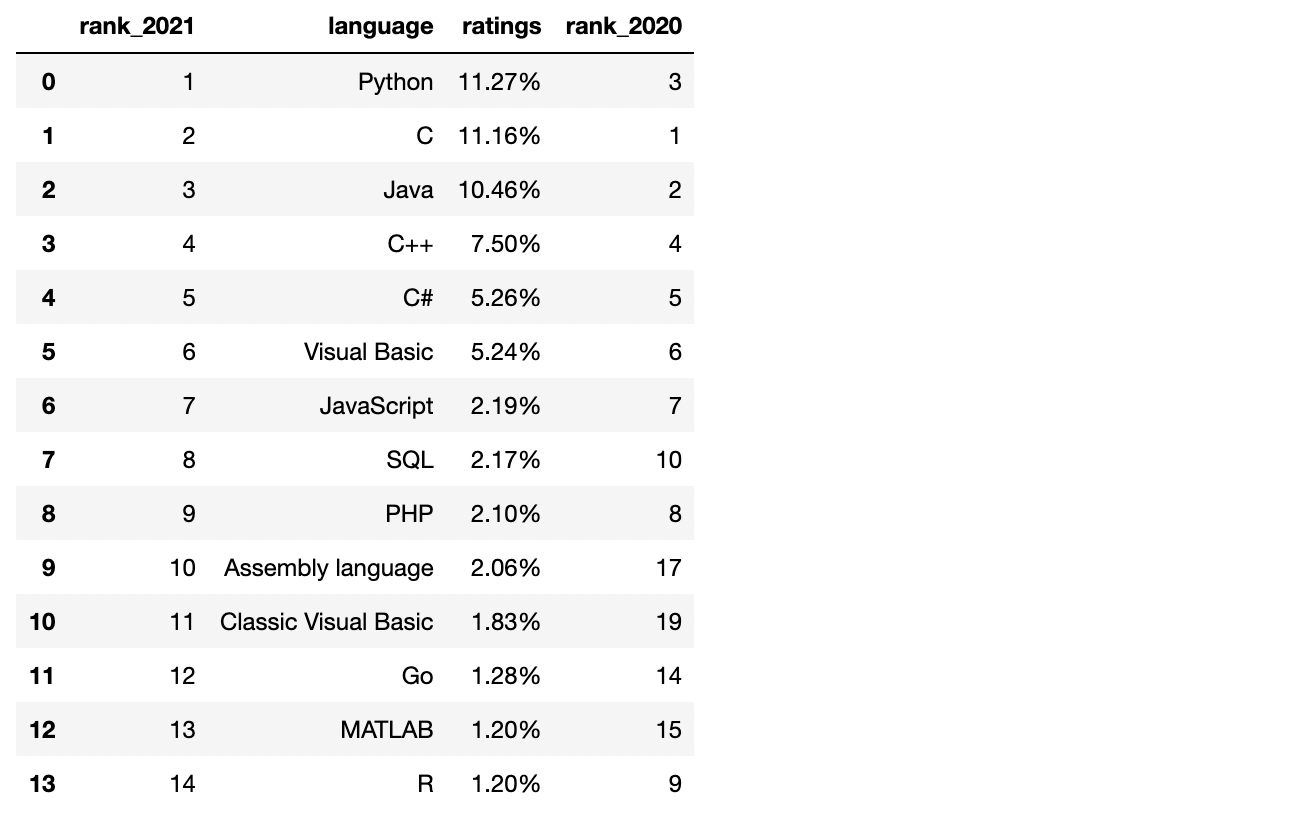
✔️ 숫자 데이터로 형 변환
df['rank_2021'] = df['rank_2021'].astype(int)
df['rank_2020'] = df['rank_2020'].astype(int)
df.info()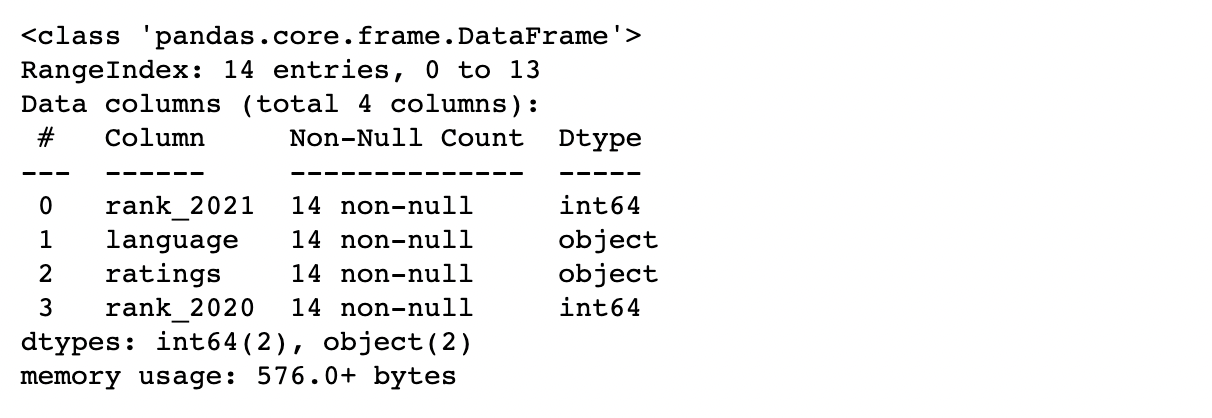
✔️ 1~9위 언어와 R만 남기기
df2 = df.copy()
df = df[df['rank_2021'] < 10]
df2 = df2[df2['rank_2021'] == 14]
tiobe = pd.concat([df,df2], ignore_index=True)
tiobe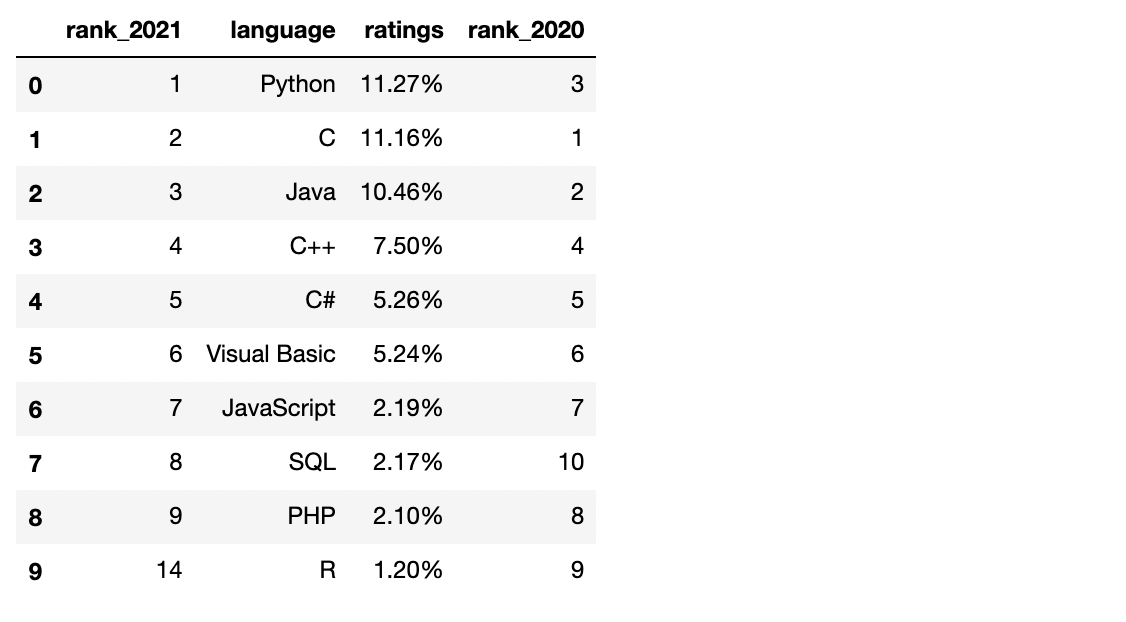
3) 언어 이름 list에 담아주기
tiobe_top10 = list(tiobe['language'])
tiobe_top10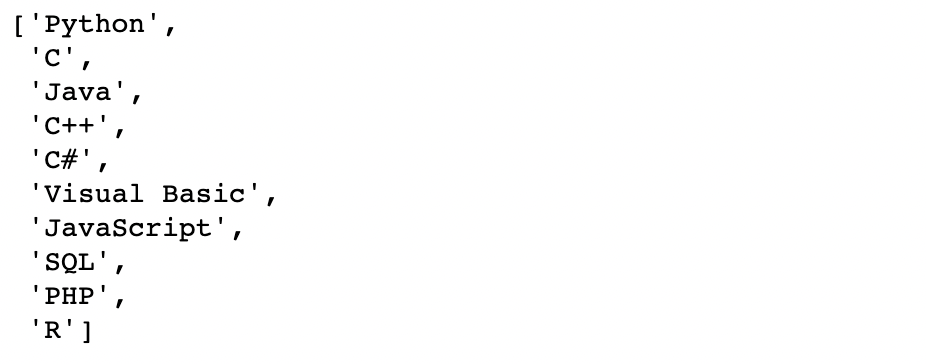
✔️ 검색어 추가해주기
tiobe_top10.insert(1,'파이썬')
tiobe_top10.insert(3,'C 언어')
tiobe_top10.insert(4,'자바')
tiobe_top10.insert(8,'비주얼 베이직')
tiobe_top10.insert(10,'자바스크립트')
tiobe_top10.insert(15,'R 언어')
tiobe_top10
2. 언어별 출판도서 정보 크롤링
네이버 검색 API 이용
C나R같은 경우는 알파벳 한 글자이기때문에, 그냥 검색하면 정확한 검색이 어렵습니다.
- 그래서 일반 검색(1), 검색어가 책 제목에 포함되는 조건(2), 책 카테고리를 'IT/전문서'로 특정하는 조건(3)을 추가하여 각각 검색해보았습니다.
➡️상세 검색by카테고리(d_catg)/책 제목(d_titl)
➡️ [IT 전문서] 카테고리 번호:280020
1) 책 정보 크롤링 함수 만들기
(1) gen_search_url
: 검색 url을 만들어주는 함수
조건별 검색량 변화를 확인하기 위해 세 가지 형태로 함수를 선언!
# search_text : 검색 키워드
# start_num : 검색 시작 숫자. 네이버 검색 API에서는 최대 1000
# disp_num : 한번에 표시되는 데이터 개수. 네이버 검색 API에서는 최대 100
# (1) 기본 검색 url을 만들어주는 함수
def gen_search_url(search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search/book.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + param_query + param_start + param_disp
# (2) 책 제목만 사용하는 url을 만들어주는 함수(d_titl 사용)
def gen_search_url_bookname(search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search/book_adv'
param_title = '?d_titl=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + param_title + param_start + param_disp
# (3) 책 제목과 카테고리를 사용하는 url을 만들어주는 함수(d_catg, d_titl 사용)
def gen_search_url_catg_bookname(search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search/book_adv'
param_catg = '?d_catg=280020'
param_title = '&d_titl=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + param_catg + param_title + param_start + param_disp (2) get_result_onepage()
: 한 페이지의 검색 결과를 json 형태로 가져오는 함수
import json
import datetime
def get_result_onepage(url):
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
print('[%s] Url Request Success' % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))
# 잘 실행되는지 확인
url = gen_search_url_catg_bookname('R', 1, 1)
one_result = get_result_onepage(url)
one_result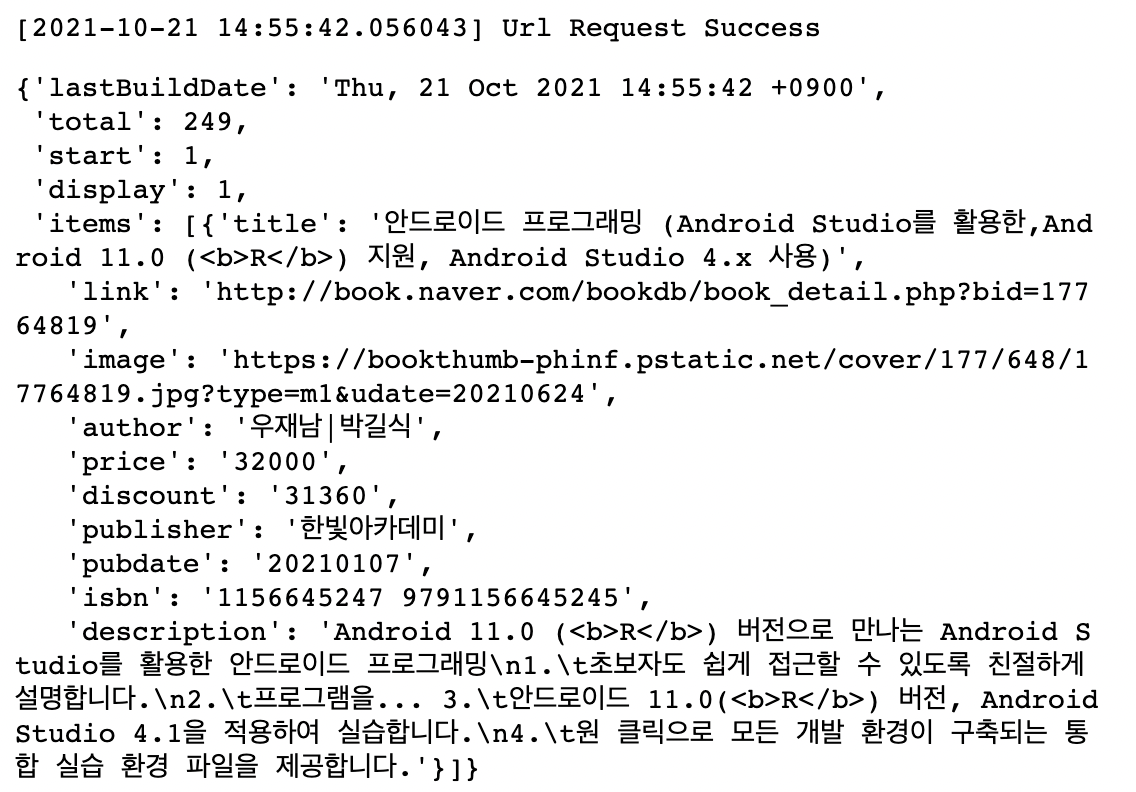
✔️ 세 가지 함수를 사용한 검색 결과 비교
# 그냥 키워드로 검색
datas1 = []
for top in tiobe_top10:
url = gen_search_url(top, 1, 1)
one_result = get_result_onepage(url)
total = one_result['total']
datas1.append({
'언어':top,
'total':total
})
datas1 = pd.DataFrame(datas1)
# 키워드가 책 제목에 들어간 책 검색
datas2 = []
for top in tiobe_top10:
url = gen_search_url_bookname(top, 1, 1)
one_result = get_result_onepage(url)
total = one_result['total']
datas2.append({
'언어':top,
'total_bookname':total
})
datas2 = pd.DataFrame(datas2)
# 책 제목 + IT 전문서 카테고리로 검색
datas3 = []
for top in tiobe_top10:
url = gen_search_url_detail_catg(top, 1, 1)
one_result = get_result_onepage(url)
total = one_result['total']
datas3.append({
'언어':top,
'total_category':total
})
datas3 = pd.DataFrame(datas3)
# 하나의 데이터프레임으로 합쳐주기
datas = pd.merge(datas1,datas2,how='left',on='언어')
datas = pd.merge(datas, datas3, how='left', on='언어')
search_total = datas
search_total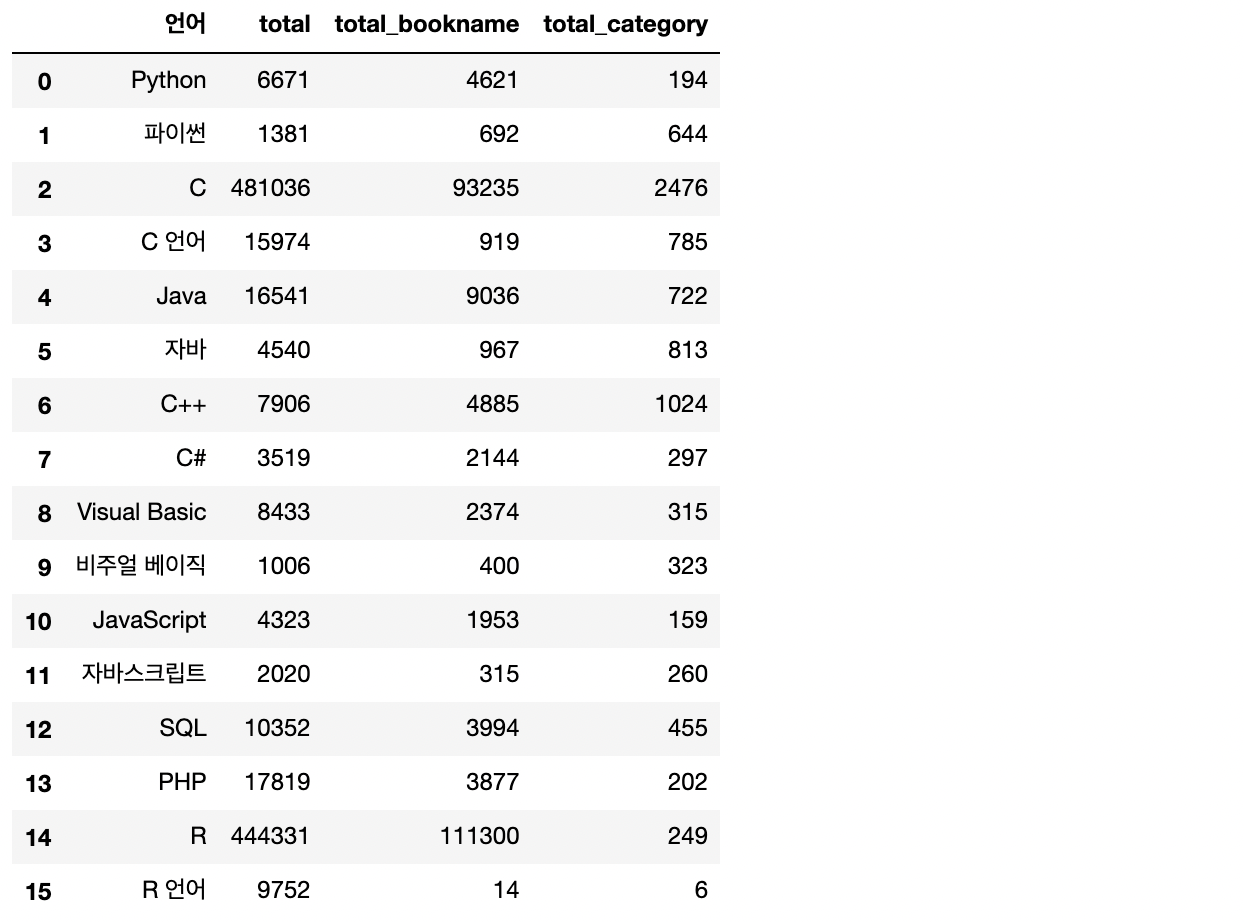
- 전체 검색 건수를 대략적으로 확인해보니, 검색어마다 편차가 큽니다.
- 카테고리까지 사용하여서 분석에 이용한다면 더욱 정확도가 높아지겠지만, 아쉬운 부분은 '해외도서' 카테고리가 따로 마련되어 있어, 해외도서 데이터가 다소 누락될 수 있다는 점입니다.
- 그렇지만 이번 분석에서 사용하는 네이버 API의 키워드당 검색량이 1000개로 제한되어있다는 점과, IT 서적으로 범위를 한정하여도 체감 인기도 분석에는 무리가 없을 것이라 판단하여 3번 함수로 선택하였습니다.
(3) delete_tag()
: 제목에 포함된 태그를 벗기는 함수
def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>','')
return input_str
(4) get_fields()
: 각 데이터를 가져와 데이터프레임으로 만들어주는 함수
import pandas as pd
def get_fields(json_data, language):
title = [delete_tag(each['title']) for each in json_data['items']] # 책 제목
pubdate = [each['pubdate'] for each in json_data['items']] # 출판일
price = [each['price'] for each in json_data['items']] # 가격
publisher = [each['publisher'] for each in json_data['items']] # 출판사
isbn = [each['isbn'] for each in json_data['items']] # ISBN
link = [each['link'] for each in json_data['items']] # 상세링크
result_pd = pd.DataFrame({
'제목' : title,
'출판사' : publisher,
'출판일': pubdate,
'가격' : price,
'ISBN' : isbn,
'언어' : language,
'링크' : link
})
return result_pd
2) 제목, 출판사, 출판일, 가격, ISBN, 상세링크 데이터 수집
각 검색 키워드별로 1000개씩 검색!
book_final = []
for top in tiobe_top10: # 검색어를 담은 리스트
book_result = []
print(top)
for n in range(1, 1000, 100):
url = gen_search_url_catg_bookname(top, n, 100)
json_result = get_result_onepage(url)
pd_result = get_fields(json_result, top)
book_result.append(pd_result)
book_result = pd.concat(book_result,ignore_index=True)
time.sleep(3) # 혹시 몰라 타임 슬립을 걸어줌
book_final.append(book_result)
✔️ 동일 언어, 동일 검색어 상 1차 중복 제거
# 동일 언어 내에서 1차적으로 중복 데이터 제거(ISBN을 기준으로)
for i in range(len(tiobe_top10)):
book_final[i].drop_duplicates(['ISBN'],inplace=True)➡️ 7424 => 7307개로 줄어듬✔️ 각 검색키워드별 검색 결과들을 하나의 데이터프레임으로 합쳐주기
result = pd.concat(book_final,ignore_index=True)
result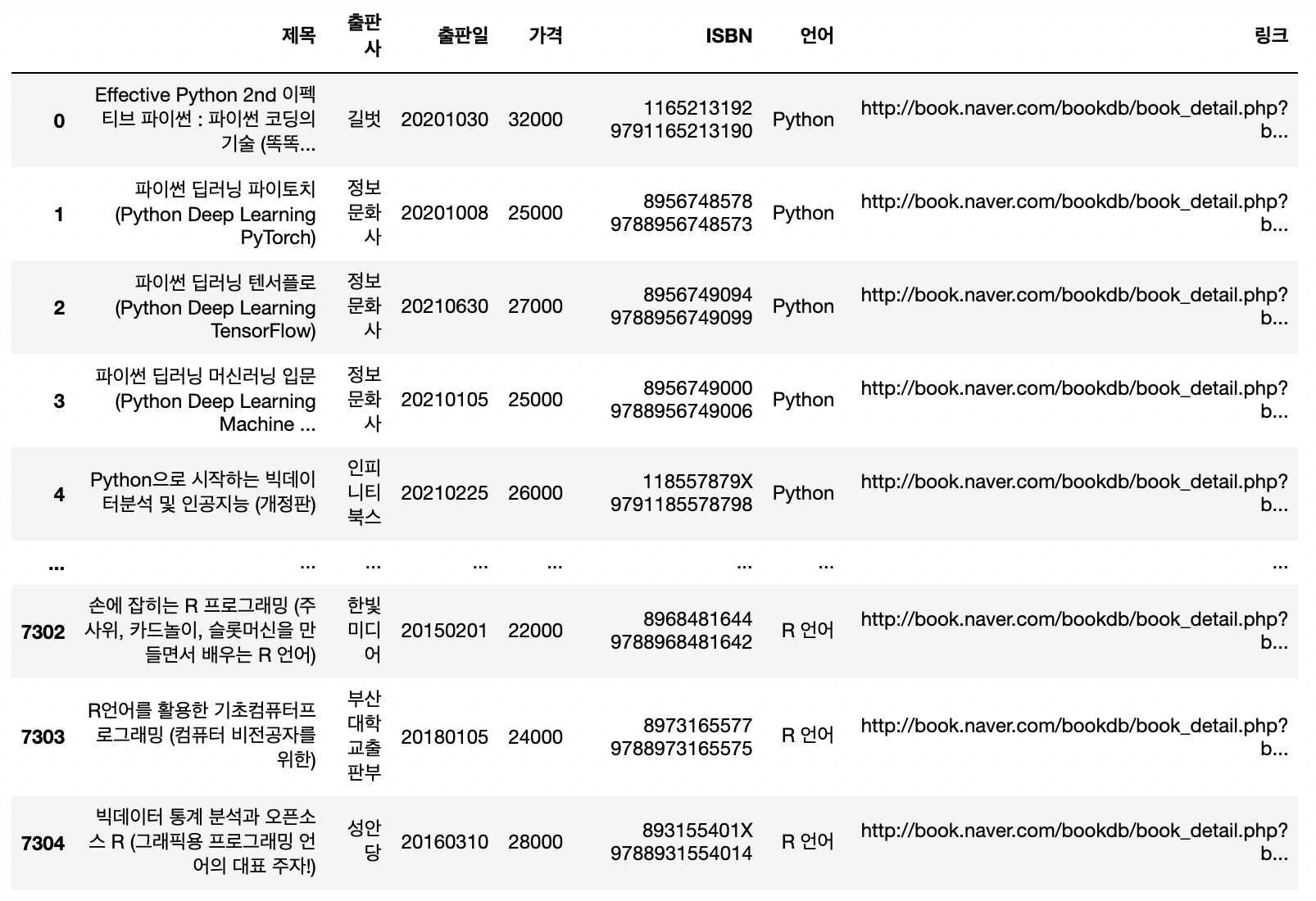
3) 데이터타입 변환
형 변환을 일단 한번 실행해보고 오류를 발생시키는 데이터들을 조회 및 삭제한 뒤 형 변환 실행!

(1) 가격 ➡️ float형으로 변환
# 조회
result.loc[result['가격']=='']
# 삭제
result.drop(index=4511,inplace=True)
# 형 변환
result['가격'] = result['가격'].astype(float)(2) 출판일 ➡️ datetime형으로 변환
# 6자리 날짜 데이터 조회
result.loc[result['출판일']=='201708']
# 삭제
result.drop(index=819,inplace=True)
# 00000000 데이터 조회 및 삭제
result.loc[result['출판일']=='00000000']
result.drop(index=3147,inplace=True)
# 7자리 날짜 데이터 조회 및 삭제
result.loc[result['출판일']=='1130717']
result.drop(index=7298,inplace=True)
# 날짜 형 변환
result['출판일'] = pd.to_datetime(result['출판일'])
# 인포 확인
result.info() 잘 변환 되었다!
잘 변환 되었다!
4) 중복데이터 삭제
ISBN을 기준으로 중복되는 데이터를 삭제
# 중복데이터 개수 확인
dup = result.duplicated(['ISBN'])
dup.value_counts()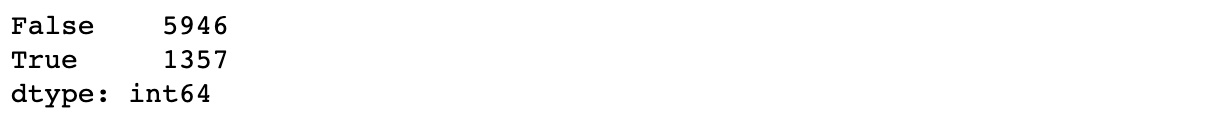
# 언어별 확보한 책 데이터 개수를 데이터 프레임으로 만들기
get_data = result['언어'].value_counts()
get_data = pd.DataFrame(get_data)
get_data.rename(columns={'언어':'get_data'},inplace=True)
get_data.reset_index(inplace=True)# 컬럼명 변경
get_data.rename(columns={'index':'언어'},inplace=True)
get_data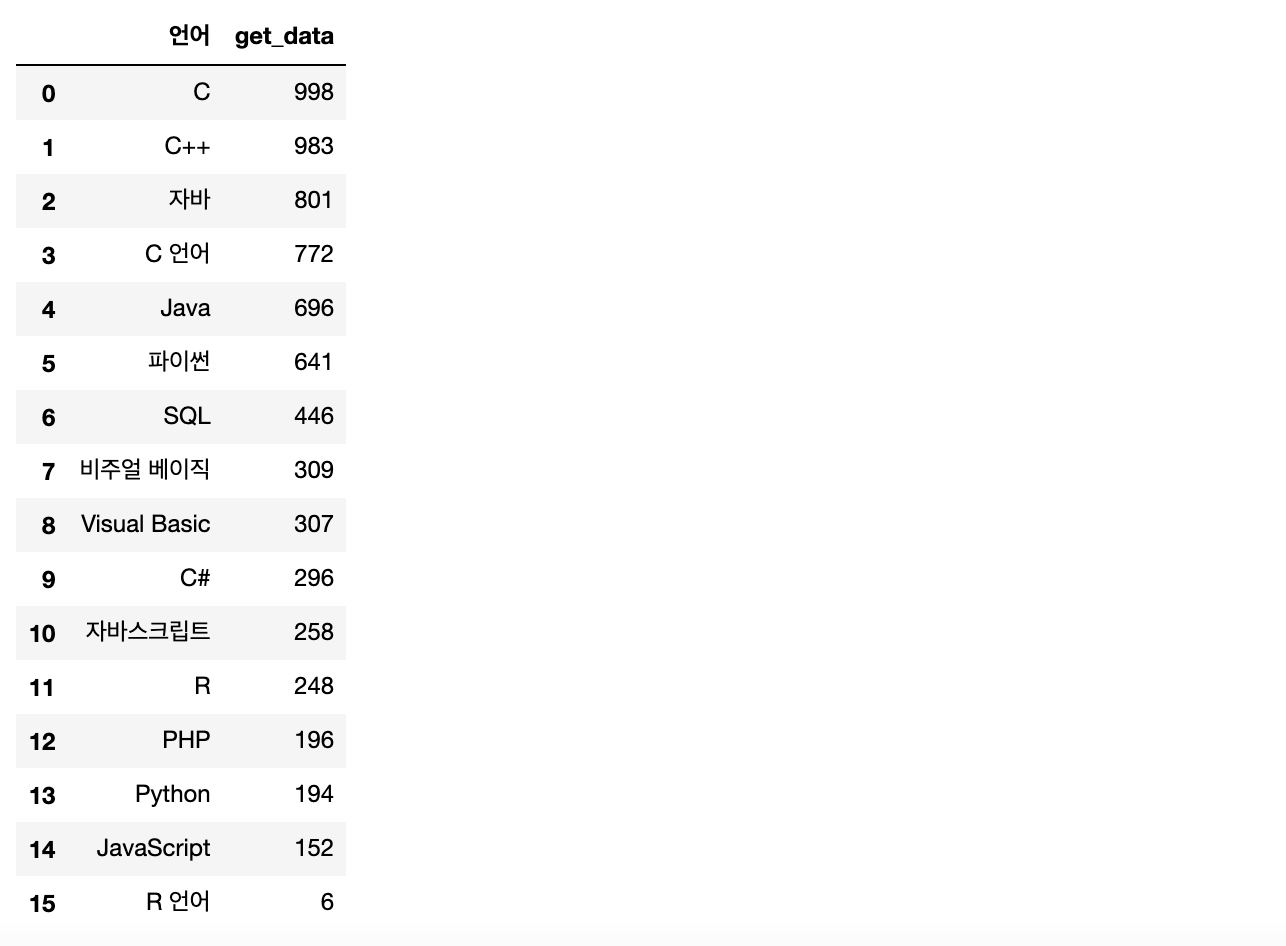
# 아까 함수 세 가지 종류별 검색결과 df에 합쳐주기
pd.merge(search_total,get_data,how='left',on='언어')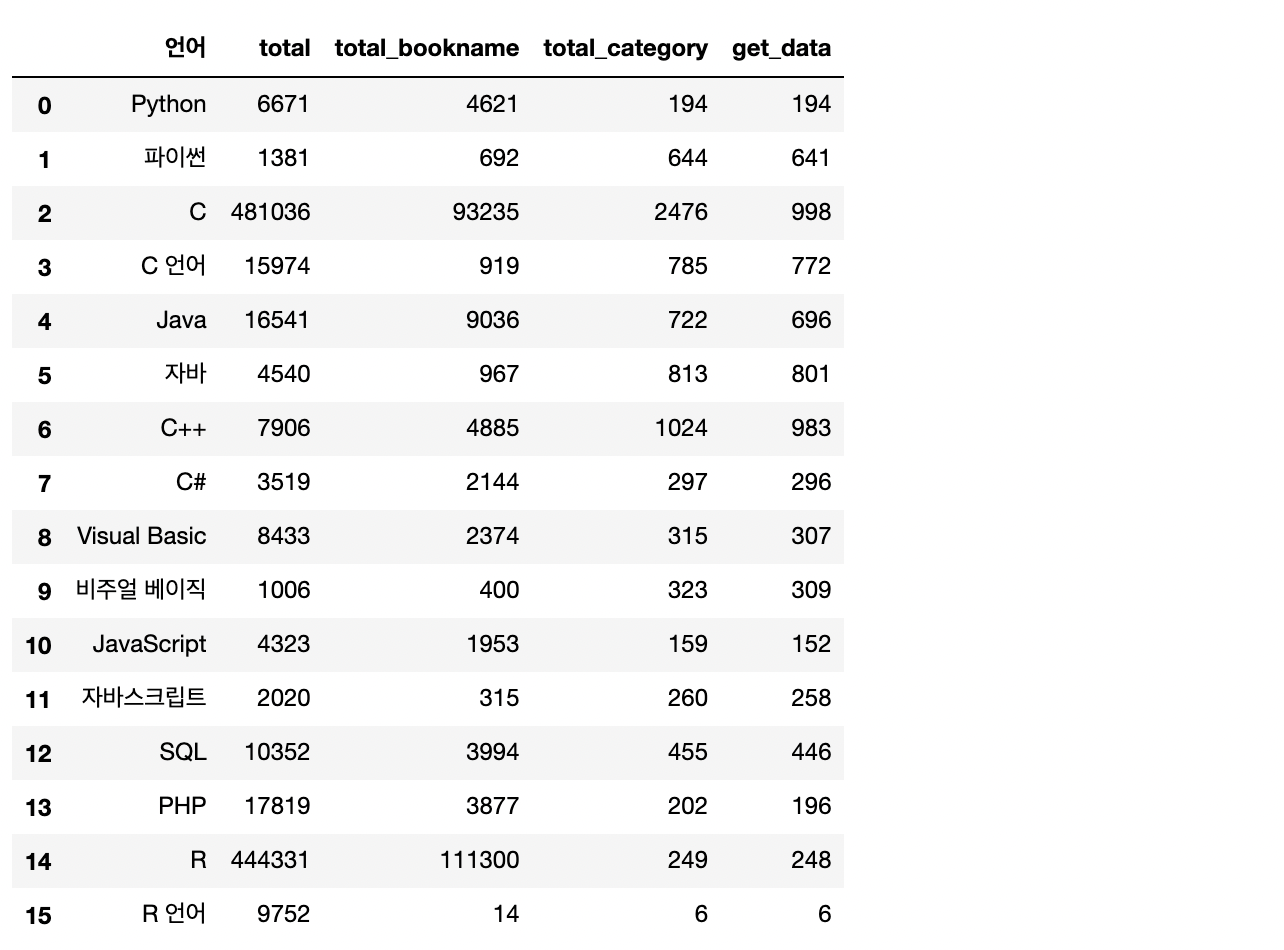
# 중복 데이터 조회 해보기
result['ISBN'].value_counts().head(5) ➡️ 중복
➡️ 중복 ISBN으로 조회된 데이터를 확인해보니
동일한 언어지만 다른 검색어(한글/영어)로 검색하여 발생한 중복 발견
(1) 동일 언어의 다른 검색어 통합 후 2차 중복 제거
# 검색어 통합
result.loc[result['언어']=='자바스크립트','언어'] = 'JavaScript'
result.loc[result['언어']=='파이썬','언어'] = 'Python'
result.loc[result['언어']=='C 언어','언어'] = 'C'
result.loc[result['언어']=='자바','언어'] = 'Java'
result.loc[result['언어']=='R 언어','언어'] = 'R'
result.loc[result['언어']=='비주얼 베이직','언어'] = 'Visual Basic'
# 수정 후 동일 언어 내에서 중복 ISBN 제거
result.drop_duplicates(['ISBN','언어'],inplace=True)➡️ 6843 개로 줄어듬
# 인포 확인
result.info()
result.loc[result['ISBN']=='8979141939 9788979141931']
# 조회해보면 모두 다른 언어이다. 즉 여러 언어를 다루고 있는 책.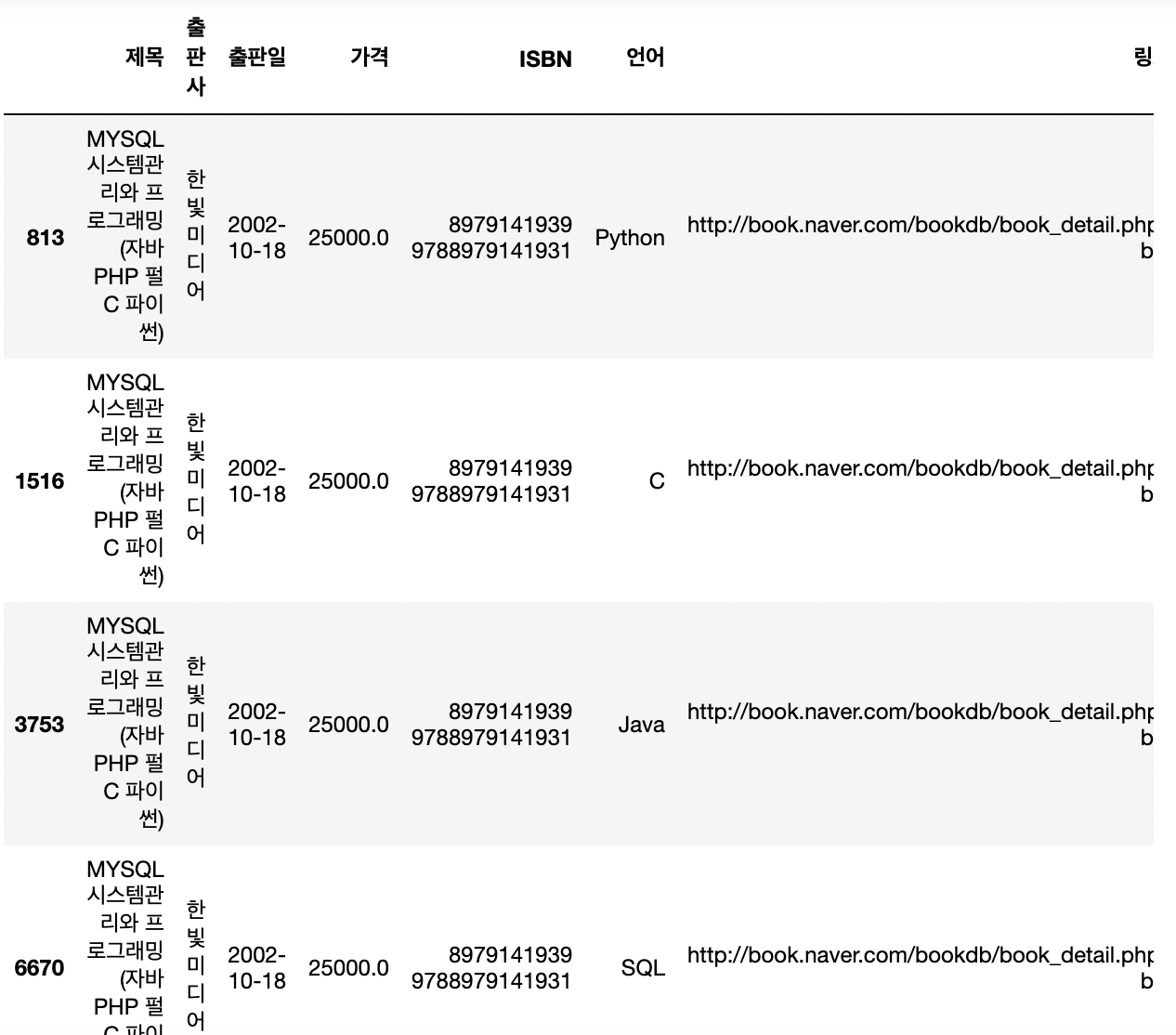
# 언어 고유값 확인
len(result['언어'].unique()) 10언어 개수가 10개로 돌아온 것을 보아
동일언어의 다른 검색어의 결과들이 잘 합쳐진 것 같다.
# 언어별 데이터 개수 확인
result['언어'].value_counts()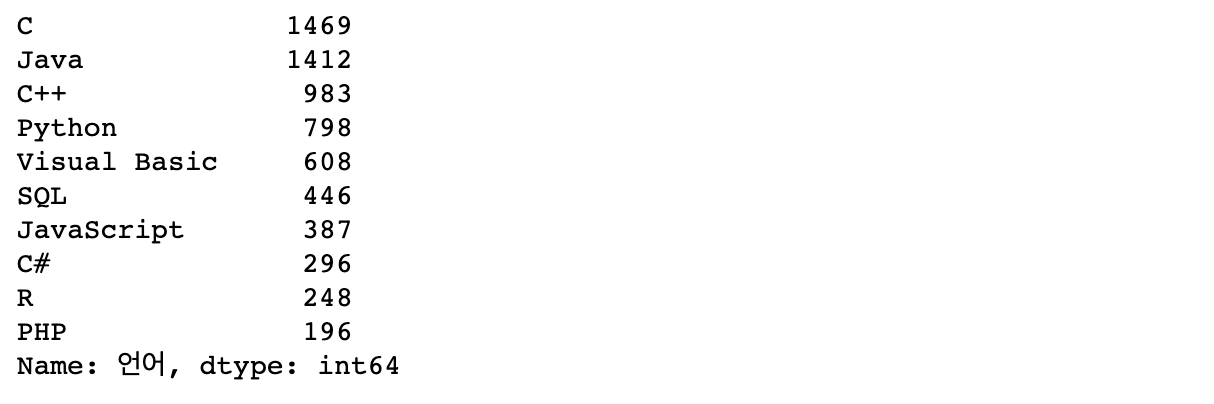
자바가 너무 많은 것이 뭔가 수상해 생각을 해봤더니,
'자바'라는 단어 자체가 '자바스크립트'에 포함되기 때문에 다시 중복처리를 해줘야한다고 판단하였다.
(2) Java와 JavaScript 차집합 검증 후 JavaScript 쪽에만 남기고 제거
# 각각 데이터 추출
java = result.loc[result['언어']=='Java']
javascript = result.loc[result['언어'] == 'JavaScript']
# 하나로 합치기
java_tonghap = pd.concat([java,javascript])# 자바스크립트 - 자바
len(set(javascript['ISBN']) - set(java['ISBN']))0# 자바 - 자바스크립트
len(set(java['ISBN']) - set(javascript['ISBN']))1025# 자바스크립트쪽 데이터를 남기고 제거(자바스크립트가 뒤쪽이라 keep='last'옵션)
java_tonghap.drop_duplicates(['ISBN'],keep='last',inplace=True)# 자바 데이터 인덱스 저장
idx_java = result[result['언어']=='Java'].index
# 자바 데이터 제거
result_final = result.drop(idx_java)
# 자바스크립트 데이터 인덱스 저장
idx_javascript = result[result['언어']=='JavaScript'].index
# 자바스크립트 데이터 제거
result_final = result_final.drop(idx_javascript)
# 중복제거된 자바, 자바스크립트 데이터 다시 합쳐주기
result_final = pd.concat([result_final,java_tonghap],ignore_index=True)
# 언어별 최종 데이터 개수 확인
result_final.value_counts()자바가 1025인걸 보니 잘 제거되었다.
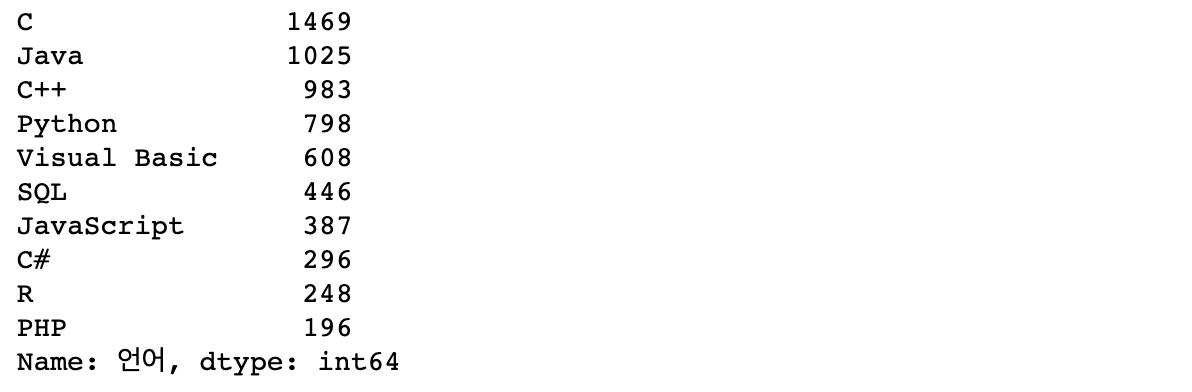
- 자바와 자바스크립트 중복 교차검증까지 끝낸 최종 데이터셋!(
result_final)
5) 페이지 수 데이터 수집
페이지 수 정보는 네이버 API 상에서 바로 불러와지는 정보가 아니라,
책 상세 페이지에 들어가야 나오는 정보이기 때문에 수집한 링크를 통해 반복문을 사용하여 다시 BeautifulSoup으로 각 책의 페이지 정보들을 불러왔습니다,,,,
(가장 애먹고(a.k.a 삽질), 시간이 많이 걸린 부분 중 하나,,,인건 안비밀,,,)
(1) BeautifulSoup으로 '페이지 수' 데이터 수집
가장 골 때렸던(?) 부분은, 책 마다 페이지 수가 들어가 있는 부분이 미묘하게 달랐다는 것입니다. 어떤 책은 3번째 div태그에 들어가있고, 어떤 책은 4번째 div태그에 들어가있으며, 심지어 어떤 책은 페이지 정보가 누락돼 있었습니다.
규칙을 찾아보니, 보통 3번째 태그에 들어있는 것이 일반적이나,
원제가 붙어있는 번역본들은 정보 한 줄이 더 추가되어 페이지 수가 4번째 태그에 들어가 있었습니다.
따라서 이 경우에는 isalpha() 조건과, 상식적으로 10000페이지가 넘는 책은 없을 것이라 생각하여 len() > 4 조건으로 골라내어 4번째 태그에서 페이지 수 데이터를 가져오도록 지정해주었습니다.
추가로, 페이지 수 정보가 누락되었을 경우, 세번째 태그에 책의 가격 정보가 들어간다는 사실도 발견하였습니다.
저의 고뇌가 담긴,,, 수많은 시행착오를 거친 코드입니다,,,
이 코드 완성하는데 3시간이 걸렸네요,,,, 코린이는 웁니다,,,😂
page_soup = []
for i in range(6456): # 6456==len(result_final['링크'])
if i == 800:
page_num = '664'
elif i == 4814:
page_num = '1252'
else:
url = result_final['링크'][i]
response = urlopen(url)
page = BeautifulSoup(response, 'html.parser')
page_raw = page.select_one('#container > div.spot > div.book_info > div.book_info_inner > div:nth-child(3)').text
if len(page_raw.split()) >= 2:
page_num = page.select_one('#container > div.spot > div.book_info > div.book_info_inner > div:nth-child(3)').text.split()[1].split('|')[0]
# 원제가 있는 번역본은 4번째 div태그에서 페이지수를 가져와야한다
if page_num.isalpha() == True:
page_num = page.select_one('#container > div.spot > div.book_info > div.book_info_inner > div:nth-child(4)').text.split()[1].split('|')[0]
if len(page_num) > 4:
page_num = page.select_one('#container > div.spot > div.book_info > div.book_info_inner > div:nth-child(4)').text.split()[1].split('|')[0]
else:
page_num = ''
page_soup.append(page_num)
print(i, page_num, url)코드를 보시면 아시겠지만,,,
알 수 없는 오류가 800번과 4814번에서 두 번 발생하였습니다.
확인해보니 Nonetype은 text()를 가져올 수 없어 그런 것이었는데,
각각 상세링크에 직접 들어가 확인해보았지만 html도 멀쩡하고, copy해봐도 다른 데이터들과 똑같은 형태로 복사가 되는데, 아무 데이터도 긁어올 수 없었습니다,,, (마치,,, "있었는데요,,,없었습니다,,,") 그래서 직접 상세페이지에 나와있는 데이터로 각각 지정해주었습니다.
약 6500여개의 데이터를 불러오는데 대충 50분 정도 걸린 거 같습니다...
(사실 저렇게 돌리면 한번에 수집이 가능하긴 하지만, 중간에 오류가 나기도 하고, 컴퓨터가 잠들기도 하는 등 애로사항도 많고, 워낙 시간이 좀 걸리는 코드이다 보니 사실 1000~2000단위씩 쪼개서 돌리고 합쳤습니다,, 모로가도 서울만 가면 되니까요,,,)
(2) '페이지 수' 컬럼 추가
result_final['페이지수'] = page_soup
result_final.tail()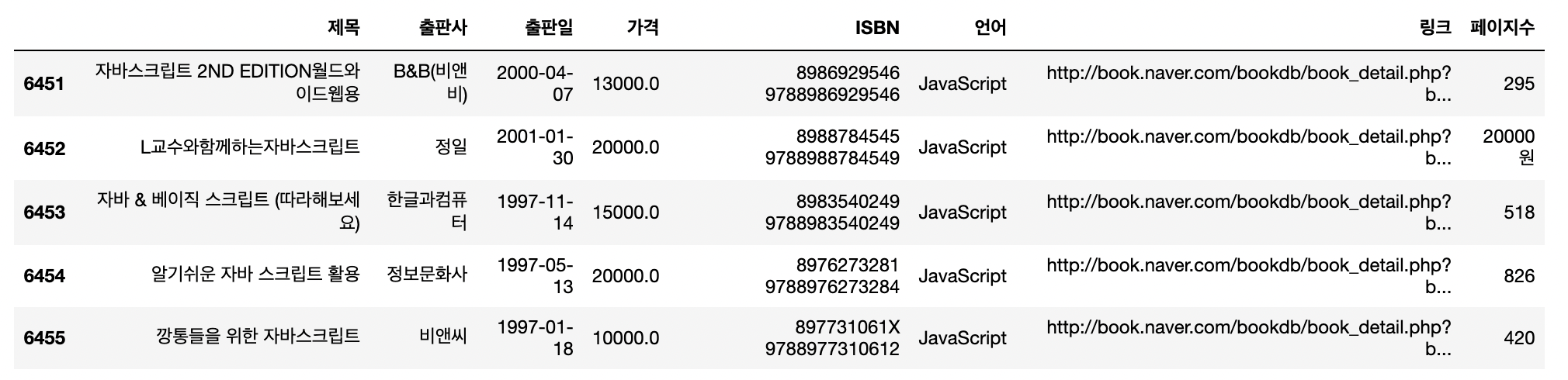 우여곡절 끝에 드디어 수집을 완료하고 데이터프레임에 추가해주었습니다!!!
우여곡절 끝에 드디어 수집을 완료하고 데이터프레임에 추가해주었습니다!!!
하지만 곧바로 2차전이 시작되었죠,,
6) 페이지 수 데이터 정제
페이지 수를
float데이터 타입으로 변환해주기 위해 정제과정이 필요했습니다.
문자가 포함된 데이터와 숫자이지만 가격, ISBN 코드가 들어간 데이터들을 처리해주어야합니다.
우리는 수집보다 정제가 더 오래걸린다는 사실을 간과해서는 안됩니다..!😂
(1) 페이지수가 '원'으로 끝나는 데이터(가격) 정제
- 가격은 원래 페이지수 다음 줄(다음 'div'태그)에 들어있기 때문에, 이 데이터들은 페이지수가 없다고 볼 수 있습니다. 따라서 nan값을 넣어주었습니다.
# 페이지수가 '원'으로 끝나는 데이터의 인덱스번호 리스트에 담아주기
won_idx = []
for idx, row in result_final.iterrows():
if row['페이지수'][-1:] == '원':
won_idx.append(idx)
# 해당 인덱스 페이지수에 nan값 넣어주기
for i in won_idx:
result_final['페이지수'][i] = np.nan(2) 페이지 수에 '원제'가 들어간 데이터 다시 크롤링
- 앞선 for문에서 번역본을 위한 isalpha() 조건과 5글자 이상 조건에 해당하지 않아 걸러내지 못한 경우가 있었습니다. 바로 'C#, 'C#', 'C#:', 'C#', 'C++', 'C++:', 'GDI+' 괄호로 시작하는 경우 등,,,, 알파벳으로만 이루어져있지도 않고, 5글자 이상이 아니기 때문이죠.
- 이 경우도 페이지수가 4번째 div태그에 들어있기 때문에 해당 데이터 페이지수를 다시 크롤링해주었습니다.
# 'C#, 'C#', 'C#:', 'C#', 'C++', 'C++:', 'GDI+', '('로 시작, 'XML', 일본어포함 변경
for idx, row in result_final.iterrows():
if row['페이지수'] == 'XML,': # 이 부분을 바꿔가며 코드 실행 반복
url = row['링크']
response = urlopen(url)
page = BeautifulSoup(response, 'html.parser')
page_num = page.select_one('#container > div.spot > div.book_info > div.book_info_inner > div:nth-child(4)').text.split()[1].split('|')[0]
# row['페이지수'] = page_num
print(idx, page_num, url)
# for i in cpound_idx:
result_final['페이지수'][idx] = page_num(3) 페이지 수가 '소장'인 데이터 6건 확인 후 하나씩 변경
# 확인
for idx, row in result_final.iterrows():
if row['페이지수'] == '소장':
print(idx, row['페이지수'], row['링크'])
# 변경
result_final.iloc[2041,7] = np.nan # 정보 없음
result_final.iloc[3442,7] = '424' # 알라딘
result_final.iloc[3650,7] = np.nan # 정보 없음
result_final.iloc[5031,7] = np.nan # 정보 없음
result_final.iloc[6069,7] = '600' # 예스24
result_final.iloc[6423,7] = np.nan # 정보 없음(4) 페이지 수가 0 또는 1인 데이터 확인 후 하나씩 변경
- ebook의 경우 페이지가 없거나, 0 또는 1로 나타나는 경우가 있어 직접 확인 후 변경해주었습니다.
- 페이지 수가 0,1로 나오지만, 목차를 보아 0, 1일리가 없어보이는 데이터는 nan값으로 처리해주었습니다.
# 확인 - 0
for idx, row in result_final.iterrows():
if row['페이지수'] in ['0','1']:
print(idx, row['페이지수'], row['링크'])
# 변경
result_final.iloc[4861,7] = '410'
result_final.iloc[772,7] = np.nan
result_final.iloc[4026,7] = np.nan
result_final.iloc[6052,7] = np.nan
result_final.iloc[2827,7] = '364'
result_final.iloc[6272,7] ='57'(5) len(result_final['페이지수']) > 4 조건 데이터 조회
for idx, row in result_final.iterrows():
if len(row['페이지수']) > 4:
print(idx, row['페이지수'], row['링크'])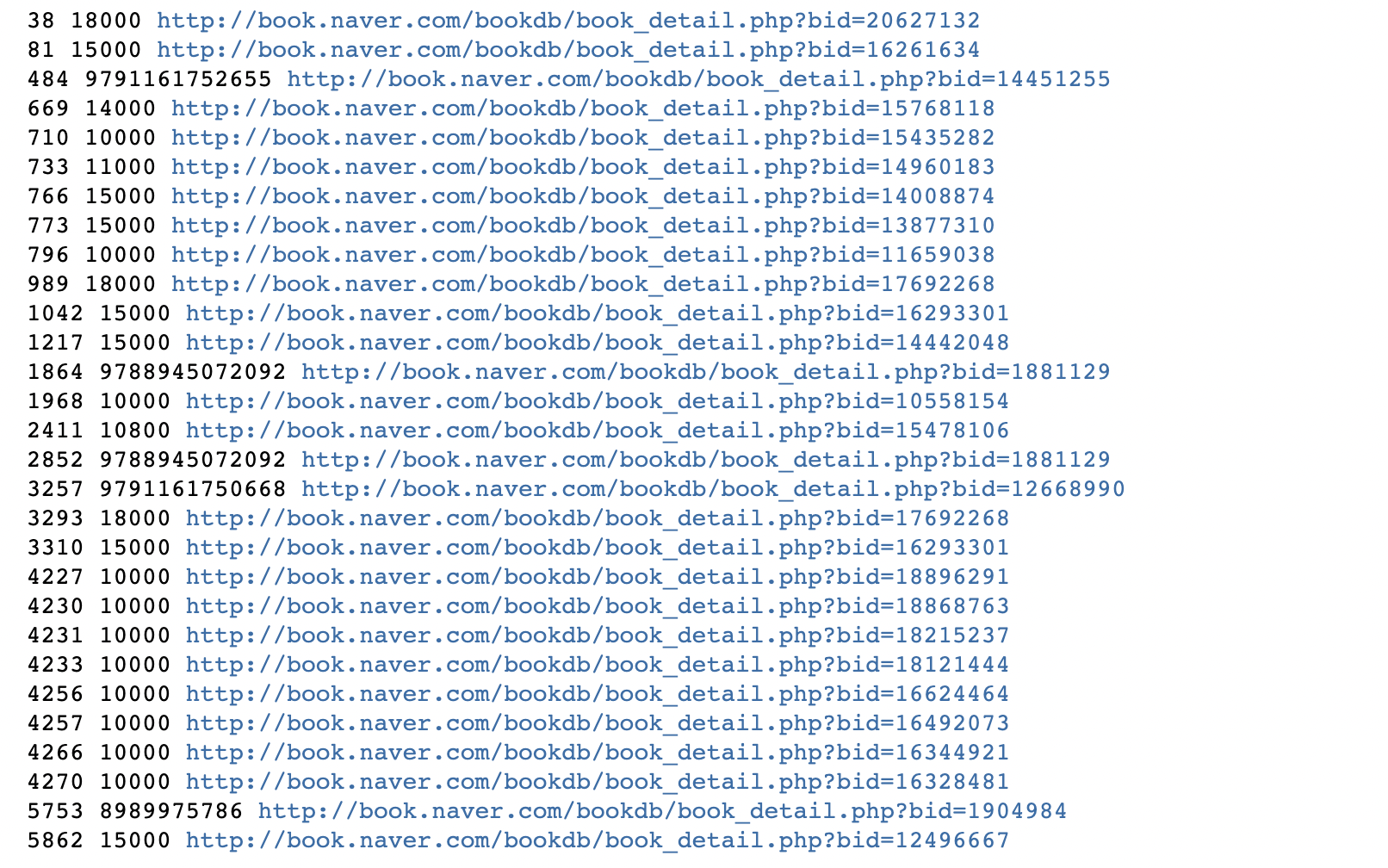
- 1000 단위로 딱 떨어져 가격으로 추정되는 데이터와, ISBN코드로 보이는 데이터들만 존재합니다.
- 따라서 역시 페이지수가 없는 데이터로 판단하여 np.nan으로 처리해주었습니다.
# 데이터 인덱스번호 리스트에 담아주기
len4plus_idx = []
for idx, row in result_final.iterrows():
if len(row['페이지수']) > 4:
len4plus_idx.append(idx)
# 해당 인덱스 페이지수에 nan값 넣어주기
for i in len4plus_idx:
result_final['페이지수'][i] = np.nan(6) nan 값을 0으로 변환
# 데이터 인덱스번호 리스트에 담아주기
nan_idx = []
for idx, row in result_final.iterrows():
if row['페이지수'] == 'nan':
nan_idx.append(idx)
len(nan_idx)
for i in nan_idx:
result_final['페이지수'][i] = 0(7) 페이지 수 float 형 변환
result_final['페이지수'] = result_final['페이지수'].astype(float)(8) 페이지 수가 너무 많은 데이터 처리
- 상세 페이지에 책 페이지 수가 누락되어 가격이 잘못 들어간 데이터로 판단하였습니다.
- 2500페이지를 넘는 책은 발견하지 못했으므로 2500을 기준으로 변경하였습니다.
# 조회
for idx, row in result_final.iterrows():
if row['Pages'] == 0:
print(idx, row['Pages'], row['언어'], row['링크'])
# 리스트에 인덱스 담기
toomuch_idx = []
for idx, row in result_final.iterrows():
if row['페이지수'] > 2500:
toomuch_idx.append(idx)
len(toomuch_idx)
# 0으로 변경
for i in toomuch_idx:
result_final['페이지수'][i] = 0
# 최대값 확인
result_final['페이지수'].unique().max()2456.06) excel파일로 저장
데이터는 소중하니까,,, 내 마음(아니고 드라이브) 속에 저장ㄴㄱㄴㄱ
result_final.to_excel('../hangnii/tiobe_project_raw.xlsx',encoding='utf-8')오늘은 여기까지!!
다음 글에서는 화려한 시각화가 여러분을 감쌀 것이니 마음의 준비를 하고 오세요😎
