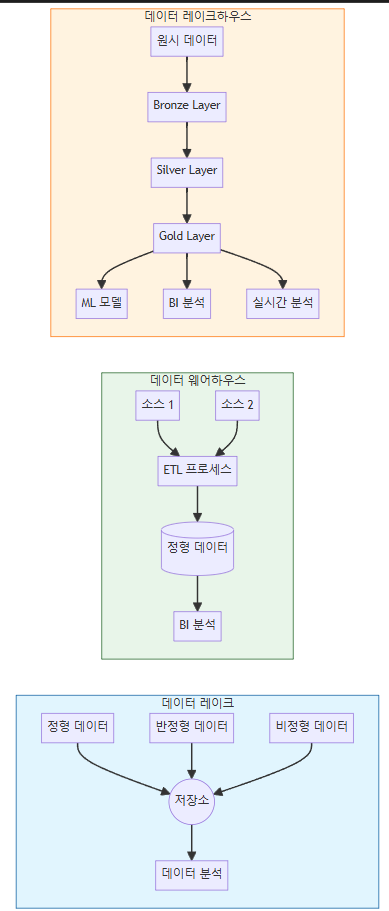

각 아키텍처의 주요 특징과 차이점
-
데이터 레이크:
- 모든 형태의 데이터를 원시 형태로 저장
- 유연한 스키마 구조
- 주로 데이터 과학자들이 사용
- 예: Amazon S3, Azure Data Lake Storage
-
데이터 웨어하우스:
- ETL을 통한 정제된 데이터 저장
- 엄격한 스키마 구조
- BI 및 리포팅에 최적화
- 예: Snowflake, Amazon Redshift
-
데이터 레이크하우스:
- 계층적 데이터 구조 (Bronze/Silver/Gold)
- 데이터 품질 관리와 메타데이터 관리
- 실시간 처리와 배치 처리 동시 지원
- 예: Databricks Delta Lake, Apache Iceberg
실제 구현 예시:
- Bronze Layer (원시 데이터):
# 원시 데이터 수집
raw_data = spark.read.format("json").load("/raw/events")
raw_data.write.format("delta").save("/bronze/events")- Silver Layer (정제 데이터):
# 데이터 정제 및 변환
cleaned_data = spark.read.format("delta").load("/bronze/events")
cleaned_data = cleaned_data.dropDuplicates()
.filter("event_type IS NOT NULL")
cleaned_data.write.format("delta").save("/silver/events")- Gold Layer (분석용 데이터):
# 분석용 데이터 준비
analytics_data = spark.read.format("delta").load("/silver/events")
daily_metrics = analytics_data.groupBy("date", "user_id")
.agg(count("*").alias("event_count"))
daily_metrics.write.format("delta").save("/gold/daily_metrics")이러한 아키텍처를 통해 기업은 데이터의 수집부터 분석까지 효율적인 파이프라인을 구축할 수 있습니다.
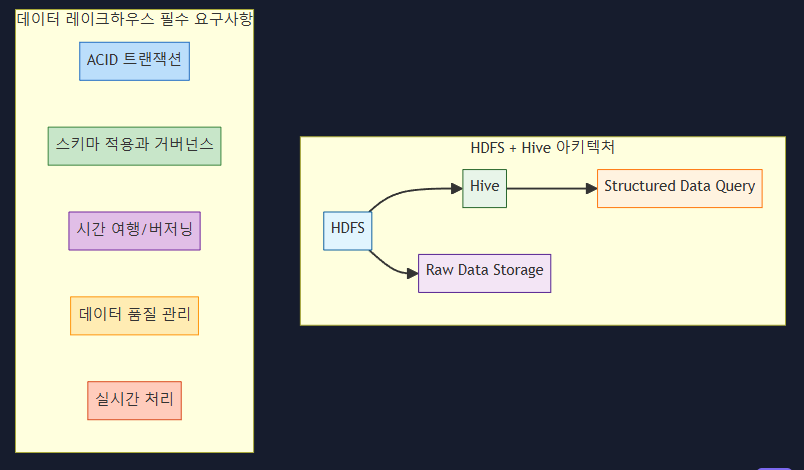
데이터 레이크 하우스
HDFS와 Hive의 조합과 데이터 레이크하우스의 주요 차이점:
-
ACID 트랜잭션 지원
- HDFS + Hive:
-- Hive의 제한된 ACID 지원 CREATE TABLE sales (id INT, amount DECIMAL) CLUSTERED BY (id) INTO 3 BUCKETS STORED AS ORC TBLPROPERTIES ('transactional'='true'); - 데이터 레이크하우스:
# Delta Lake의 완전한 ACID 트랜잭션 지원 deltaTable.update( condition = "date > '2024-01-01'", set = { "status": "processed" } )
- HDFS + Hive:
-
스키마 관리
- HDFS + Hive:
-- 스키마 변경 시 테이블 재생성 필요 ALTER TABLE sales ADD COLUMNS ( new_column STRING ); - 데이터 레이크하우스:
# 스키마 진화 자동 지원 df.write.format("delta").mode("append").save("/path/to/table")
- HDFS + Hive:
-
데이터 버저닝
- HDFS + Hive:
-- 버저닝 기능 없음, 수동으로 관리 필요 CREATE TABLE sales_backup AS SELECT * FROM sales; - 데이터 레이크하우스:
# 자동 버저닝과 시간 여행 지원 df = spark.read.format("delta").option( "versionAsOf", "5" ).load("/path/to/table")
- HDFS + Hive:
-
데이터 품질 관리
- HDFS + Hive:
-- 제한된 데이터 검증 SELECT COUNT(*) FROM sales WHERE amount IS NULL; - 데이터 레이크하우스:
# 고급 데이터 품질 관리 expectations = DeltaExpectations(spark) expectations.expect_column_values_to_not_be_null("amount") expectations.expect_column_values_to_be_between("amount", 0, 1000000)
- HDFS + Hive:
-
실시간 처리
- HDFS + Hive:
-- 배치 처리 중심 INSERT INTO sales_summary SELECT * FROM sales WHERE date = CURRENT_DATE; - 데이터 레이크하우스:
# 실시간 스트리밍 처리 streamingDF = spark.readStream.format("delta").load("/path/to/table") query = streamingDF.writeStream.format("delta").start()
- HDFS + Hive:
결론:
HDFS와 Hive의 조합은 다음과 같은 한계를 가지고 있어 완전한 데이터 레이크하우스라고 할 수 없습니다:
- 제한된 ACID 트랜잭션 지원
- 스키마 진화의 어려움
- 버저닝과 시간 여행 기능 부재
- 제한된 데이터 품질 관리
- 실시간 처리의 한계
진정한 데이터 레이크하우스가 되기 위해서는 다음과 같은 기술들을 추가로 도입해야 합니다:
- Delta Lake
- Apache Iceberg
- Apache Hudi
- 실시간 처리 엔진 (Apache Spark Streaming)
- 데이터 품질 관리 도구
- 메타데이터 관리 시스템
이러한 요소들을 통합했을 때 비로소 완전한 데이터 레이크하우스 아키텍처를 구현했다고 할 수 있습니다.

시리즈를 기반으로 작성하였습니다.