Continuous batching
쉽게 비유하자면:
- Continuous Batching: 식당에서 손님이 오는 대로 바로바로 음식을 내어주는 '효율적인 서빙 시스템' (스케줄링 전략)
- Paged Attention: 주방에서 식재료(메모리)를 낭비 없이 아주 알뜰하게 관리하는 '혁신적인 냉장고 정리법' (메모리 관리 전략)
1. 전체 구조도 (Mermaid)

2. Continuous Batching (연속 배칭) 상세 설명
기존의 Static Batching(정적 배칭)은 모든 문장이 끝날 때까지 기다려야 했습니다. 하지만 Continuous Batching은 다릅니다.
(1) Static Batching vs Continuous Batching 예시
[상황] 3개의 요청이 들어왔습니다.
- 요청 A: 2단어 생성 필요
- 요청 B: 5단어 생성 필요
- 요청 C: 3단어 생성 필요
1. Static Batching (비효율적):
가장 긴 요청 B가 끝날 때까지(5단어 생성 시점) 요청 A와 C는 계산이 끝났음에도 불구하고 GPU 메모리를 점유한 채 가만히 기다려야 합니다. (이를 'Padding 낭비'라고 합니다.)
2. Continuous Batching (효율적):
- 1단계: A, B, C가 동시에 첫 단어를 만듭니다.
- 2단계: A가 2단어째를 만들고 종료됩니다. 그 즉시 대기열에 있던 새로운 요청 D를 A가 쓰던 자리에 집어넣습니다.
- 결과: GPU가 쉬는 시간 없이 계속해서 토큰을 찍어냅니다.
이 기술의 핵심은 "기다리지 않는다"입니다. 기존 방식이 모든 학생이 시험을 다 풀 때까지 아무도 교실 밖으로 못 나가게 하는 것이라면, Continuous Batching은 다 푼 학생은 즉시 나가고, 그 자리에 대기하던 다음 학생이 바로 들어와 시험을 치게 하는 방식입니다.
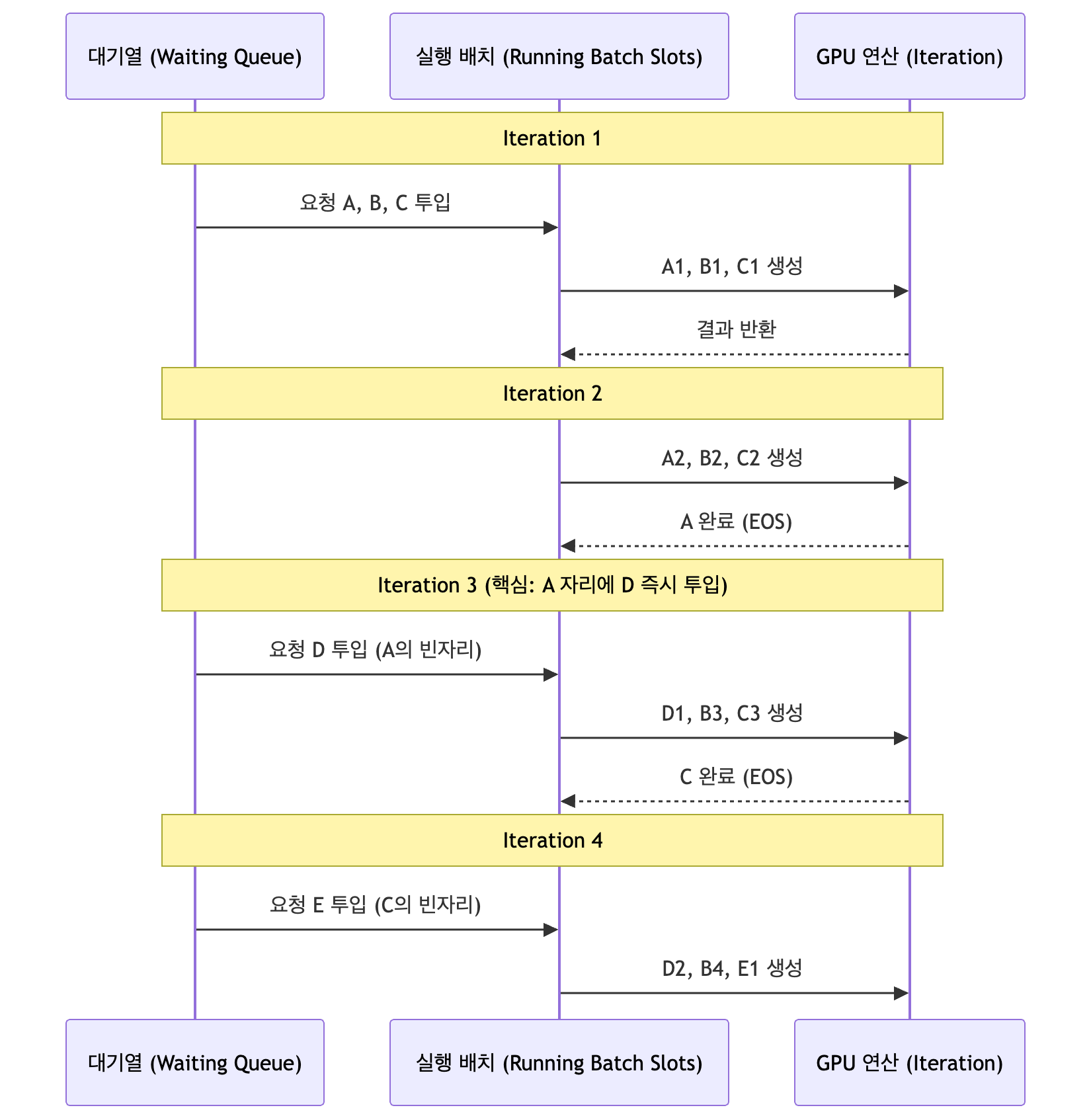
1. Continuous Batching의 전체 구조 (Mermaid)
먼저, 요청이 어떻게 스케줄링되는지 흐름도를 통해 구조를 파악해 봅시다.
2. 시각적 비교: Static vs Continuous Batching
각 칸은 GPU가 수행하는 1번의 연산(Iteration)을 의미합니다.
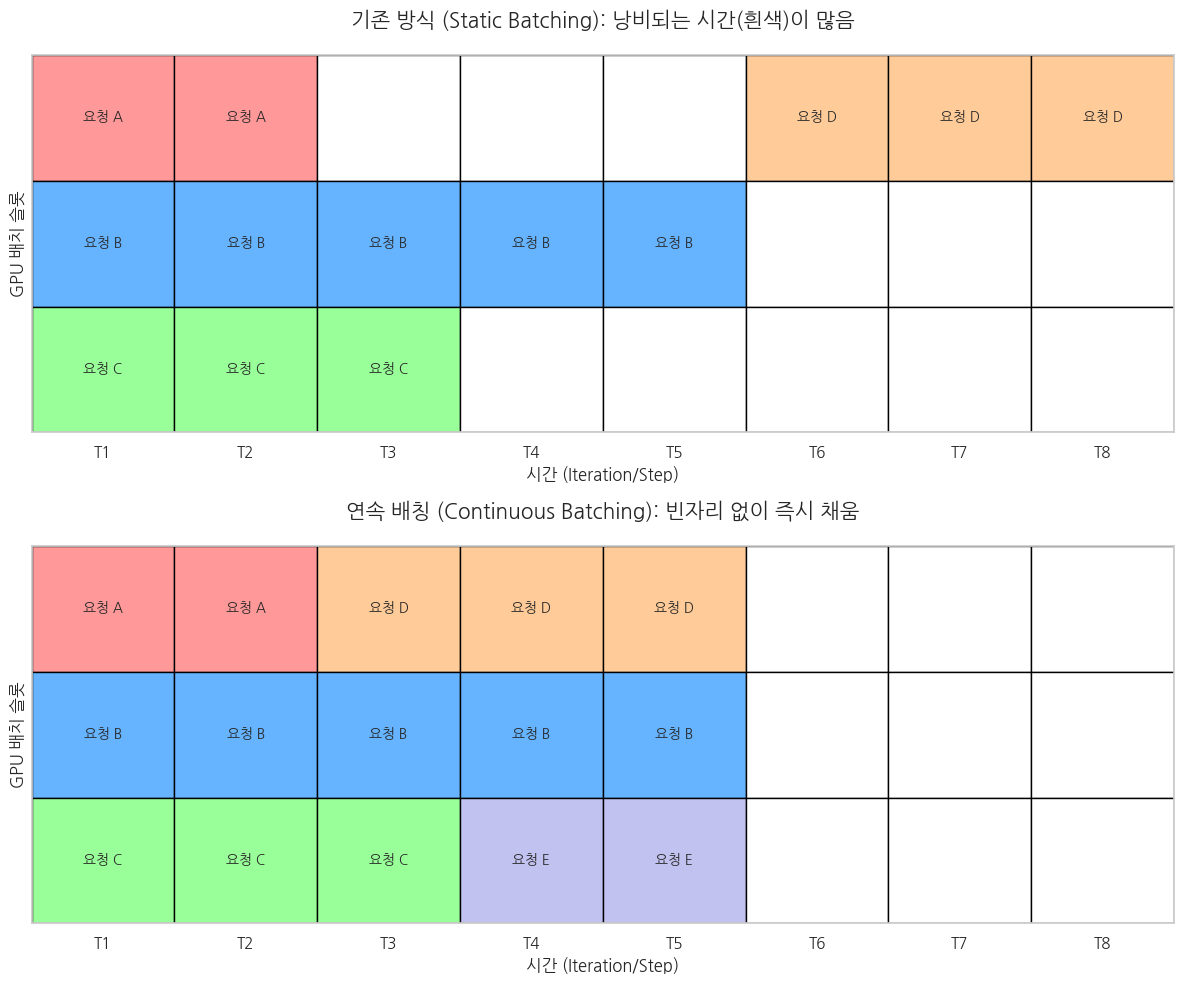
3. 단계별 상세 설명
T1 ~ T2 단계 (초기 가동)
- 상황: 요청 A(2단어), B(5단어), C(3단어)가 동시에 들어왔습니다.
- 작동: GPU는 A, B, C의 첫 번째 토큰(T1)과 두 번째 토큰(T2)을 동시에 계산합니다.
- 결과: T2가 끝나는 순간, 요청 A는 종료됩니다.
T3 단계 (교체 발생 - 핵심!)
- 기존 방식: B와 C가 끝날 때까지 A의 자리를 비워두고 기다립니다. (엄청난 낭비!)
- Continuous Batching: A가 나간 그 슬롯(Slot)이 비었다는 것을 스케줄러가 감지합니다. 대기열에 있던 요청 D를 즉시 그 자리에 끼워 넣습니다.
- 작동: 이제 GPU는 [D의 1번째 토큰, B의 3번째 토큰, C의 3번째 토큰]을 한꺼번에 계산합니다.
T4 단계 (연쇄 반응)
- 상황: T3가 끝나면서 요청 C도 3단어를 다 채우고 종료되었습니다.
- 작동: C가 나간 자리에 또 다른 대기 요청 E를 즉시 투입합니다.
- 결과: GPU는 단 한 순간도 쉬지 않고 풀가동됩니다.
4. 왜 이게 어려웠을까요? (Paged Attention과의 연결고리)
이렇게 좋은 Continuous Batching을 과거에는 왜 못 했을까요? 바로 메모리 관리 때문입니다.
- 메모리 파편화: 요청 D가 A의 자리에 들어오려고 보니, A가 쓰던 메모리 공간이 D가 필요한 공간보다 작거나, 메모리 위치가 뒤죽박죽 섞여 있어서 할당하기가 매우 까다로웠습니다.
- 미리 알 수 없는 길이: LLM은 답변이 몇 글자가 될지 미리 알 수 없습니다. 그래서 메모리를 미리 얼마나 잡아놔야 할지 정하기가 어렵습니다.
이 문제를 해결해 준 구원자가 바로 Paged Attention입니다. 메모리를 물리적으로 붙여서 관리하지 않고, '페이지' 단위로 쪼개서 가상으로 연결해 주기 때문에, Continuous Batching이 마음 놓고 요청을 갈아 끼울 수 있게 된 것입니다.

시리즈를 기반으로 작성하였습니다.