예시

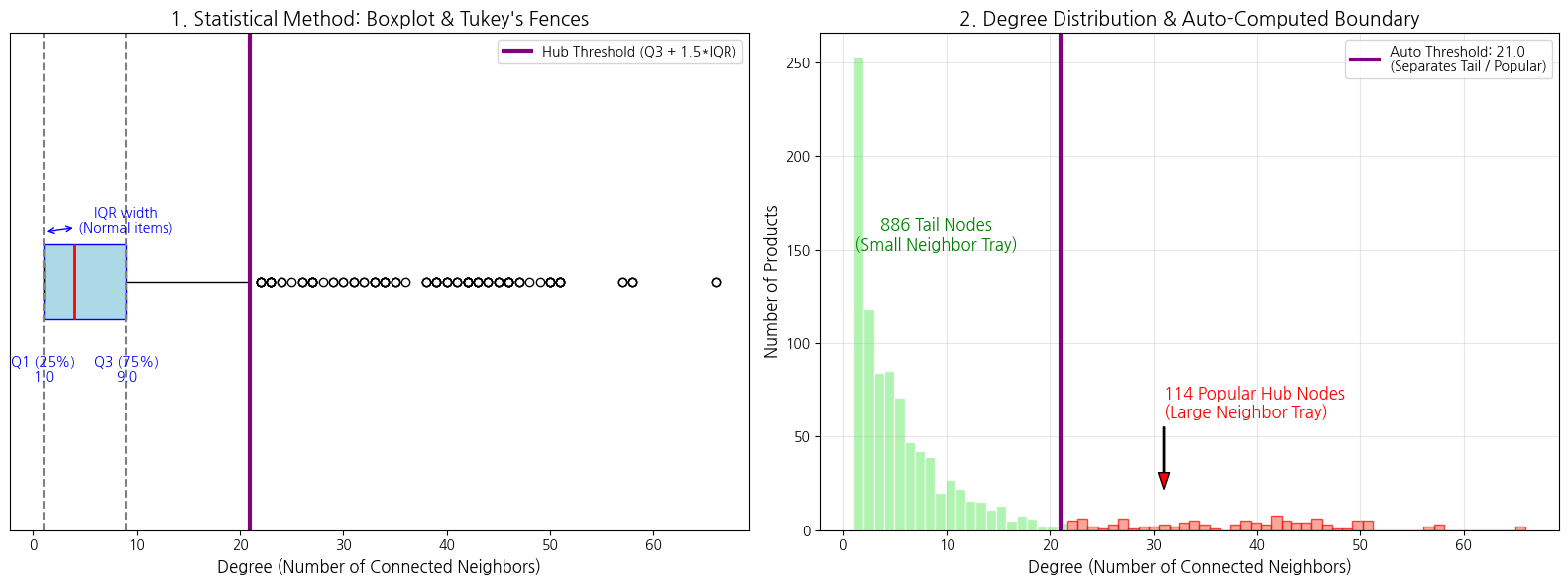
1단계: 통계적 기준 세우기 (하늘색 마름모 부분)
[흐름도] 그래프 데이터 입력 노드 차수 분포 계산 IQR Rule 적용 () 자동 티어 경계 결정
원리 예시: 쇼핑몰에 상품이 100만 개 들어왔습니다(그래프 데이터 입력). 상품마다 '함께 본 상품'이 몇 개 연결되어 있는지 세어봅니다(노드 차수 분포 계산). 이때 "어디서부터 인기 상품(Head)으로 쳐야 할까?"를 정할 때, 사람의 감으로 "상위 10%!"라고 정하지 않고, 데이터 통계(IQR)를 바탕으로 수학적인 커트라인을 긋습니다.



2단계: 티어 분리 및 맞춤형 훈련 준비 (보라색 박스 상단)
[흐름도] 인기/롱테일 티어 분리 티어별 이웃 샘플링 계획 수립 NeighborLoader 생성
원리 예시: 커트라인을 넘은 '인싸 상품'은 힌트(이웃)를 50개씩 넉넉히 주기로 하고, 커트라인 아래의 '평범한 롱테일 상품'들은 힌트를 5개만 주기로 계획을 땁니다(티어별 계획 수립). 그리고 이 계획대로 데이터를 모델에게 먹여줄 '급식 판(NeighborLoader)'을 두 종류로 나누어 만듭니다.

3단계: 학습과 반성 (보라색 박스 중단)
[흐름도] 학습 시작 배치별 손실 계산 노드별 손실 누적 에폭 종료?
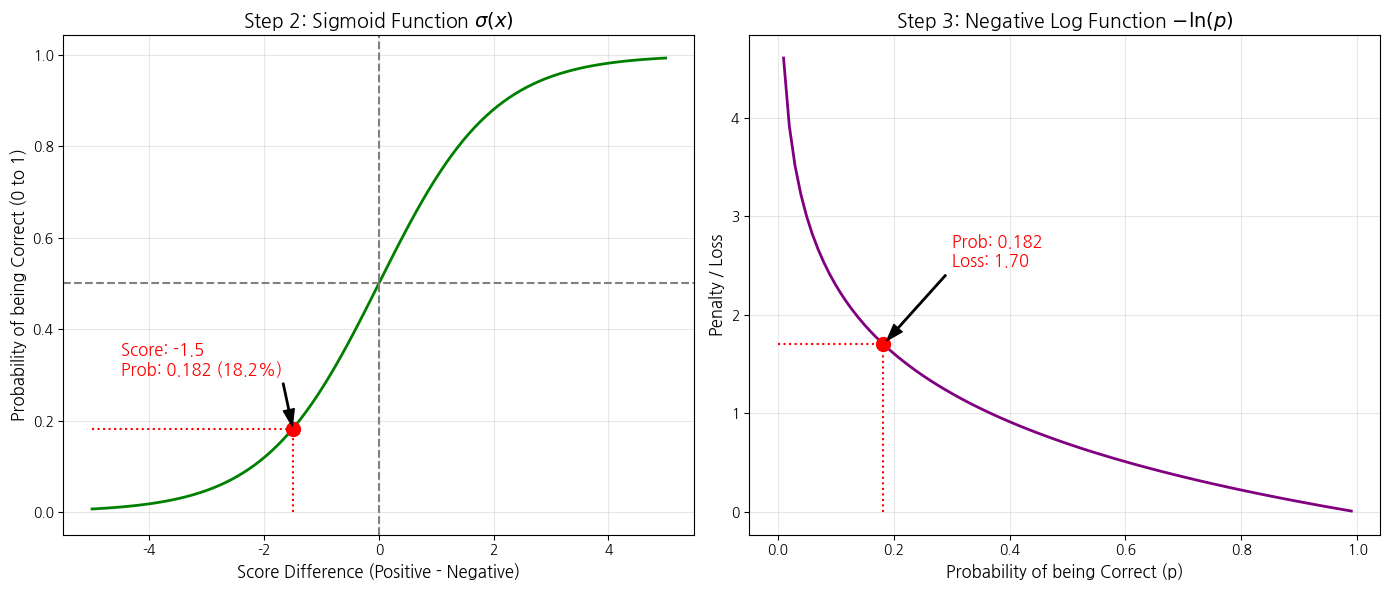
원리 예시: 드디어 1단원(1 에폭) 학습을 시작합니다. 학생(모델)이 문제를 풀면서 틀릴 때마다 "아, 수제 가죽 케이스 상품은 힌트 5개만으로는 도저히 뭔지 모르겠어!"라며 오답 노트에 스트레스 지수(손실, Loss)를 꾹꾹 적어둡니다(노드별 손실 누적).



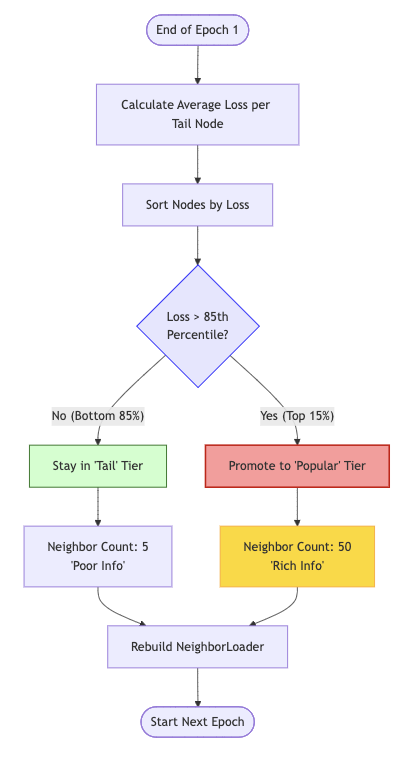
4단계: 특허의 핵심! 구제와 승격 (주황색 박스)
[흐름도] 동적 조정 주기? (예) [손실 상위 백분위 계산] [롱테일 → 인기 티어 승격] 이웃 샘플링 재구성 NeighborLoader 재생성
원리 예시: 1단원(에폭)이 끝났습니다. 선생님(시스템)이 오답 노트를 봅니다. 롱테일 상품들 중에서 유독 스트레스 지수(손실)가 상위권인 불쌍한 상품들을 찾아냅니다(손실 상위 백분위 계산). 선생님은 "너네는 안 되겠다. 2단원부터는 인싸들처럼 힌트 50개씩 줄게!"라며 인기 티어로 신분 상승(승격)을 시켜줍니다. 그리고 급식 판을 새로 짭니다(NeighborLoader 재생성).