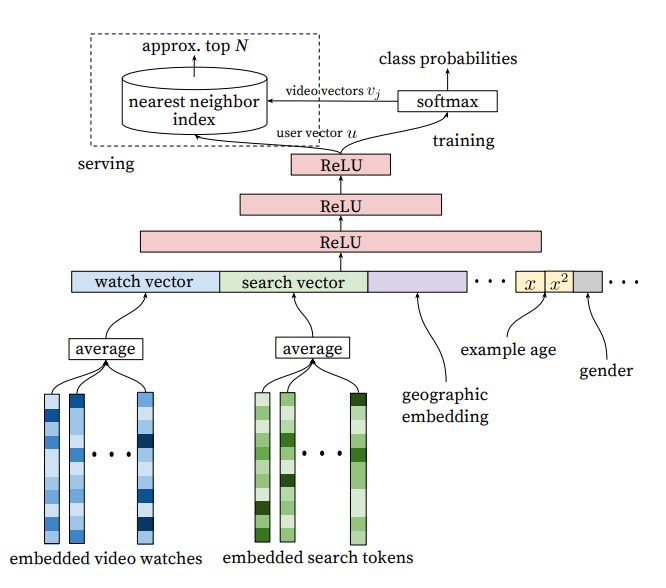
1. 모델 아키텍처 (그림 3):
- 임베디드 희소 특성 (Embedded Sparse Features): 사용자 ID, 비디오 ID, 검색 토큰 등과 같은 범주형 특성들은 모델에서 사용할 수 있도록 밀집 벡터(임베딩)로 변환됩니다.
- 밀집 특성 (Dense Features): 평균 시청 시간, 예시 나이, 성별, 지리적 위치 등과 같은 연속적인 특성들입니다.
- 결합 (Concatenation): 희소 특성의 임베딩은 평균화되어 고정된 크기의 벡터로 변환된 후, 밀집 특성과 결합됩니다.
- 은닉층 (Hidden Layers): 모델은 ReLU 활성화 함수를 사용한 완전 연결 층을 사용합니다.
- 학습 (Training): 모델은 경사 하강법을 사용하여 교차 엔트로피 손실을 최소화합니다. 출력은 샘플링된 소프트맥스 함수를 통과합니다.
- 서빙 (Serving): 서빙 시, 근사 최근접 이웃 탐색을 수행하여 수백 개의 후보 비디오 추천을 생성합니다.
2. 레이블 및 컨텍스트 선택:
- 대리 문제 (Surrogate Problem): 모델은 사용자가 다음에 시청할 비디오를 예측하도록 학습되며, 이는 효과적인 추천을 제공하는 실제 목표를 위한 대리 문제입니다.
- 학습 데이터: 학습 예제는 추천에서 생성된 시청 기록뿐만 아니라 모든 YouTube 시청 기록에서 생성됩니다. 이는 새로운 콘텐츠가 표면화되도록 하고 기존 인기 콘텐츠에 대한 편향을 방지합니다.
- 균등 가중치 (Equal Weighting): 사용자당 고정된 수의 학습 예제를 생성하여 모델이 매우 활동적인 소수의 사용자에 의해 지배되지 않도록 합니다.
- 정보 제한 (Information Withholding): 과적합을 방지하기 위해 사용자 행동의 순서와 같은 특정 정보를 모델에서 제외합니다. 예를 들어, 검색 쿼리는 순서 없는 토큰의 집합으로 표현되어 모델이 검색 결과를 단순히 재현하지 않도록 합니다.
3. 예시를 통한 설명:
앨리스라는 사용자가 YouTube에서 요리 비디오를 자주 시청한다고 가정해 보겠습니다. 이제 모델이 어떻게 작동하는지 자세히 설명하겠습니다:
-
임베디드 희소 특성: 모델은 앨리스가 시청한 비디오(예: "파스타 만드는 법," "이탈리아 요리 기술")와 사용한 검색 토큰(예: "쉬운 저녁 요리 레시피")에 대한 임베딩을 생성합니다.
-
밀집 특성: 모델은 앨리스가 요리 비디오를 시청하는 평균 시간, 지리적 위치(예: 이탈리아), 인구 통계 정보(예: 여성, 30세)와 같은 연속적인 특성도 고려합니다.
-
학습: 모델은 앨리스의 시청 기록을 기반으로 그녀가 다음에 시청할 비디오를 예측하도록 학습됩니다. 예를 들어, 앨리스가 "파스타 만드는 법"을 시청한 후 "이탈리아 요리 기술"을 시청했다면, 모델은 그녀가 다음에 "전통 이탈리아 디저트"를 시청할 가능성이 높다고 예측합니다.
-
서빙: 앨리스가 로그인하면, 모델은 그녀의 시청 기록과 유사한 비디오를 추천하기 위해 근사 최근접 이웃 탐색을 수행합니다. 예를 들어, "진짜 이탈리아 피자 레시피"나 "빠른 이탈리아 전채 요리"와 같은 비디오를 추천할 수 있습니다.
-
과적합 방지: 앨리스가 "이탈리아 디저트"를 검색하면, 모델은 단순히 상위 검색 결과를 추천하지 않습니다. 대신, 그녀의 검색 토큰과 시청 기록의 임베딩을 사용하여 이탈리아 요리에 대한 그녀의 관심사와 일치하는 비디오를 추천합니다.
-
균등 가중치: 앨리스가 다른 사용자인 밥보다 더 많은 비디오를 시청하더라도, 모델은 사용자당 학습 예제 수를 제한하여 앨리스와 밥이 학습 과정에 동등한 영향을 미치도록 합니다.
이 접근 방식은 개인화되고 다양한 추천을 제공하며, 새로운 콘텐츠가 추천될 기회를 제공하고 모델이 가장 인기 있거나 최근에 시청된 비디오에 과적합되지 않도록 합니다.
- 단점: 유저 벡터의 정보가 비디오 벡터보다 훨씬 많지만 비디오 벡터와 ANN을 하기위헤 벡터의 크기를 맞춰줘야함.
