추천 시스템 논문(with GPT)
1.Deep Neural Networks for YouTube Recommendations 2
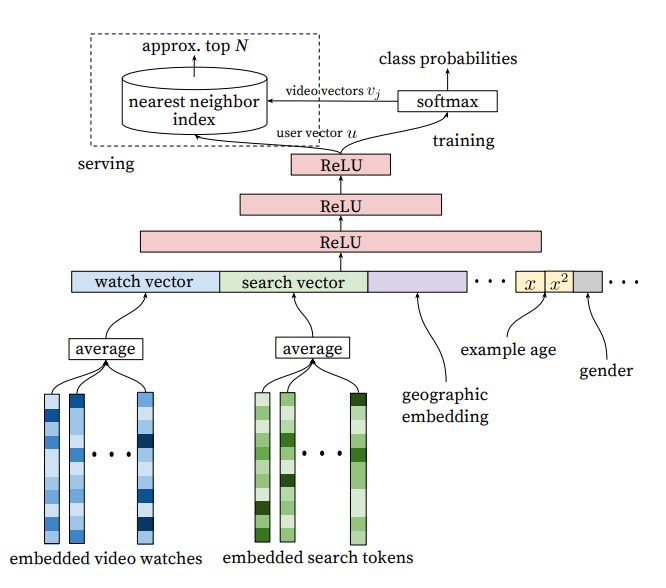
임베디드 희소 특성 (Embedded Sparse Features): 사용자 ID, 비디오 ID, 검색 토큰 등과 같은 범주형 특성들은 모델에서 사용할 수 있도록 밀집 벡터(임베딩)로 변환됩니다.밀집 특성 (Dense Features): 평균 시청 시간, 예시 나이,
2.Deep Neural Networks for YouTube Recommendations 1
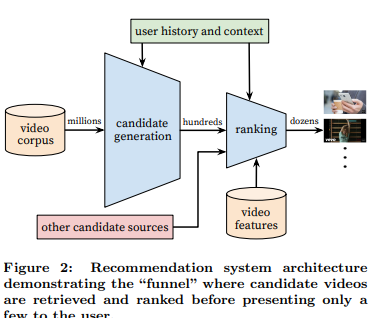
추천 시스템은 크게 두 단계로 나뉩니다:1\. 후보 생성 (Candidate Generation): 수백만 개의 비디오 중에서 사용자에게 적합한 수백 개의 비디오를 선정합니다.2\. 랭킹 (Ranking): 선정된 수백 개의 비디오를 순위화하여 최종적으로 사용자에게 몇
3.Deep Neural Networks for YouTube Recommendations 3
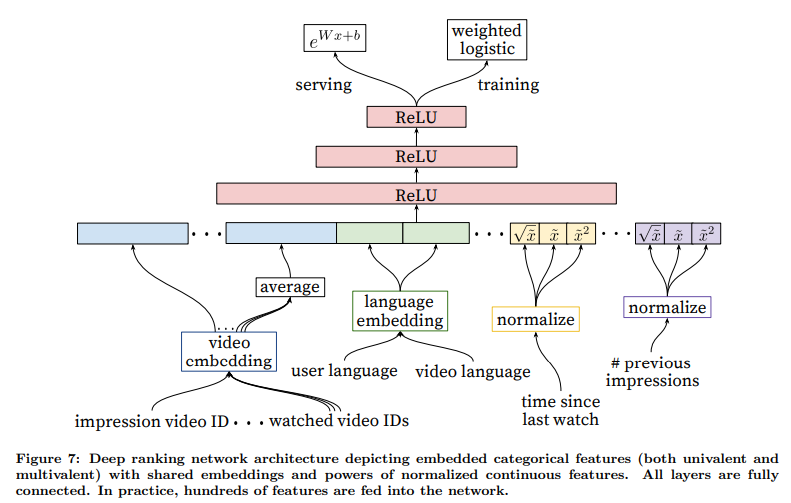
YouTube의 랭킹(Ranking) 모델 아키텍처와 특징 표현(Feature Representation)랭킹 모델은 사용자와 비디오의 다양한 특성을 입력으로 받아 비디오의 순위를 매깁니다. 이 모델은 임베딩(Embedding)된 범주형 특성과 정규화된 연속형 특성을
4.Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations 1 (전체 개요)

추천 시스템은 사용자가 관심 있는 콘텐츠를 발견하도록 돕는 시스템으로, 비디오 추천, 앱 추천, 온라인 광고 타겟팅 등 다양한 분야에서 사용됩니다. 이러한 시스템은 수백만에서 수십억 개의 아이템을 포함하는 대규모 콘텐츠 코퍼스에서 사용자에게 맞춤화된 추천을 제공해야 합
5.Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
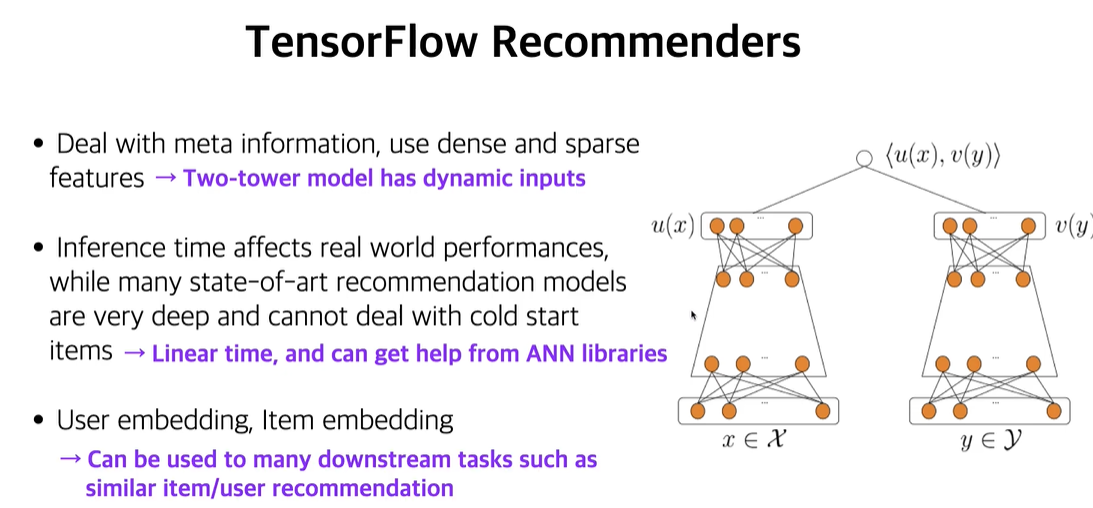
extreme classificationsample softmaxuser vector가 video vector의 임베딩 크기보다 훨씬 크다.두 벡터의 크기가 다르므로 유사도를 구할때 user의 정보에 치우친다.아이템의 다양한 정보에 대한 내용이 부족하다.NLP에서 다음
6.Personalized E-commerce Recommendation System Analysis at ebay
이 논문은 eBay와 같은 대규모 전자상거래 플랫폼에서 개인화된 추천 시스템을 구축하기 위한 방법을 제안합니다. 이 방법은 사용자와 아이템을 동일한 벡터 공간에 임베딩하는 딥러닝 모델을 사용하며, 콘텐츠 기반의 아이템 임베딩과 다중 모달 사용자 임베딩을 통해 콜드 스타
7.Negative Log Likelihood Loss (NLL Loss)
Negative Log Likelihood Loss는 모델이 예측한 확률 분포와 실제 레이블 간의 차이를 측정하는 손실 함수입니다. 이 손실 함수는 모델이 올바른 클래스를 높은 확률로 예측할수록 작아지고, 잘못된 클래스를 높은 확률로 예측할수록 커집니다.목적: 모델이
8.LLM for recommendation
M6-Rec 이후에 발표된 LLM 기반 추천 시스템 분야의 발전된 논문 및 실제 적용 사례특징: M6-Rec의 한계를 보완한 효율적인 모델로, In-Context Learning을 활용해 추천 성능을 최적화했습니다. M6-Rec 대비 추론 속도 30% 개선 및 메모리
9.Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
이 논문은 대규모 언어 모델(LLM)과 협업 필터링(Collaborative Filtering) 기술을 결합한 새로운 추천 시스템인 A-LLMRec(All-round LLM-based Recommender system)을 소개합니다. 이 시스템의 핵심 아이디어는 이미
10.멀티모달 LLM/SLM의 임베딩을 사용한 추천시스템 리서치
멀티모달 LLM/SLM 임베딩 활용의 장점:풍부한 정보 활용: 텍스트(상품 설명, 리뷰), 이미지(상품 사진), 때로는 오디오나 비디오까지 다양한 형태의 데이터를 이해하고 임베딩으로 변환하여 활용할 수 있습니다. 이를 통해 상품과 사용자의 특성을 더 깊이 있게 파악할
11.Two-Stage Recommendation System)
이커머스에서 비슷한 상품을 추천할 때 리트리버(Retriever) 모델과 랭킹(Ranking) 모델을 함께 사용하는 것은 매우 일반적이고 효과적인 접근 방식입니다. 이를 2단계 추천 시스템(Two-Stage Recommendation System)이라고 부르기도 합니다