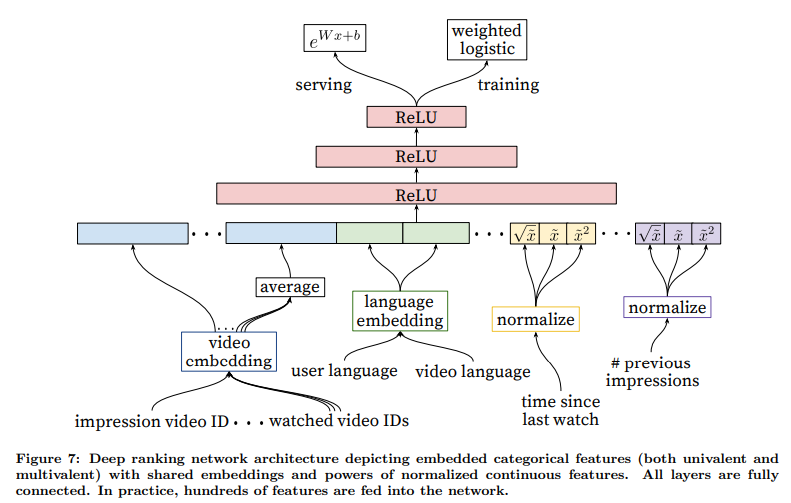
YouTube의 랭킹(Ranking) 모델 아키텍처와 특징 표현(Feature Representation)
1. 랭킹 모델 아키텍처 (Figure 7):
랭킹 모델은 사용자와 비디오의 다양한 특성을 입력으로 받아 비디오의 순위를 매깁니다. 이 모델은 임베딩(Embedding)된 범주형 특성과 정규화된 연속형 특성을 사용하며, 모든 층은 완전 연결(Fully Connected)되어 있습니다.
1.1 특성의 종류:
- 범주형 특성 (Categorical Features):
- 단일 값 (Univalent): 하나의 값만 가지는 특성 (예: 현재 평가 중인 비디오 ID).
- 다중 값 (Multivalent): 여러 값을 가지는 특성 (예: 사용자가 최근에 시청한 N개의 비디오 ID).
- 연속형/순서형 특성 (Continuous/Ordinal Features):
- 사용자의 행동 패턴을 나타내는 연속적인 값 (예: 마지막 시청 시간, 이전 노출 횟수 등).
1.2 특성 공학 (Feature Engineering):
- 수백 개의 특성을 사용하며, 범주형과 연속형 특성이 비슷한 비율로 사용됩니다.
- 사용자의 과거 행동과 비디오 간의 관계를 나타내는 특성이 가장 중요합니다.
- 예: 사용자가 특정 채널에서 시청한 비디오 수, 특정 주제의 비디오를 마지막으로 시청한 시간 등.
2. 임베딩된 범주형 특성:
범주형 특성은 희소한(one-hot encoding된) 형태이므로, 이를 밀집 벡터로 변환하기 위해 임베딩을 사용합니다.
2.1 임베딩 학습:
- 각 범주형 특성은 고유한 임베딩 벡터로 표현됩니다.
- 예: 비디오 ID, 사용자 언어, 비디오 언어 등은 각각 별도의 임베딩 벡터로 변환됩니다.
- 다중 값 특성의 경우, 임베딩 벡터를 평균화하여 고정된 크기의 벡터로 변환합니다.
2.2 임베딩 공유:
- 동일한 ID 공간의 범주형 특성은 임베딩을 공유합니다.
- 예: 비디오 ID 임베딩은 현재 평가 중인 비디오 ID, 사용자가 최근에 시청한 비디오 ID 등 여러 특성에서 공유됩니다.
- 이는 일반화 성능을 향상시키고, 학습 속도를 높이며, 메모리 사용량을 줄이는 데 도움이 됩니다.
3. 정규화된 연속형 특성:
연속형 특성은 신경망의 학습을 위해 적절히 정규화되어야 합니다.
3.1 정규화 방법:

4. 구체적인 예시:
시나리오:
앨리스는 YouTube에서 요리 비디오를 자주 시청합니다. 그녀의 시청 기록에는 "파스타 만드는 법", "이탈리아 요리 기술" 등이 포함되어 있습니다. 또한, 그녀는 "이탈리아 디저트"를 검색했습니다.
4.1 특성 표현:
- 범주형 특성:
- 현재 평가 중인 비디오 ID: "전통 이탈리아 디저트".
- 사용자가 최근에 시청한 비디오 ID: ["파스타 만드는 법", "이탈리아 요리 기술"].
- 연속형 특성:
- 마지막 시청 시간: 3시간 전.
- 이전 노출 횟수: 2회.
4.2 임베딩 및 정규화:
- 범주형 특성 임베딩:
- "전통 이탈리아 디저트"의 임베딩 벡터: [0.1, 0.3, 0.5, ...].
- "파스타 만드는 법"의 임베딩 벡터: [0.2, 0.4, 0.6, ...].
- "이탈리아 요리 기술"의 임베딩 벡터: [0.15, 0.35, 0.55, ...].
- 사용자가 최근에 시청한 비디오 ID의 평균 임베딩 벡터: [0.175, 0.375, 0.575, ...].
- 연속형 특성 정규화:
- 마지막 시청 시간: 3시간 전 → 정규화된 값: 0.75.
- 이전 노출 횟수: 2회 → 정규화된 값: 0.5.
4.3 모델 입력:
- 범주형 특성 임베딩과 정규화된 연속형 특성이 결합되어 모델에 입력됩니다.
- 예: [0.1, 0.3, 0.5, ..., 0.175, 0.375, 0.575, ..., 0.75, 0.5].
4.4 랭킹 결과:
- 모델은 입력 특성을 기반으로 비디오의 순위를 매깁니다.
- 예: "전통 이탈리아 디저트"가 가장 높은 순위를 받을 수 있습니다.
5. 요약:
- 특성 표현: 범주형과 연속형 특성을 사용하며, 범주형 특성은 임베딩을 통해 밀집 벡터로 변환됩니다.
- 임베딩 공유: 동일한 ID 공간의 범주형 특성은 임베딩을 공유하여 일반화 성능을 향상시킵니다.
- 정규화: 연속형 특성은 누적 분포 함수를 사용하여 정규화되며, 다항식 특성을 추가하여 모델의 표현력을 높입니다.
이 과정을 통해 YouTube는 사용자의 선호도와 비디오의 특성을 기반으로 개인화된 추천을 제공할 수 있습니다.
예제
좋습니다! YouTube의 딥 랭킹 네트워크(Deep Ranking Network)에서 사용되는 입력(Input), 출력(Output), 레이블(Label), 그리고 목적 함수(Objective Function)를 테이블 예제 데이터로 표현하고, 목적 함수에 대해 자세히 설명드리겠습니다.
1. 입력(Input), 출력(Output), 레이블(Label) 예제 데이터:
1.1 입력(Input):
입력은 사용자와 비디오의 다양한 특성으로 구성됩니다. 아래는 예시 데이터입니다.
| 사용자 ID | 현재 비디오 ID | 최근 시청 비디오 ID들 | 마지막 시청 시간 (시간 전) | 이전 노출 횟수 | 사용자 언어 | 비디오 언어 |
|---|---|---|---|---|---|---|
| 12345 | V123 | [V101, V102, V103] | 3 | 2 | 한국어 | 영어 |
| 67890 | V456 | [V201, V202, V203] | 5 | 1 | 영어 | 영어 |
- 범주형 특성: 현재 비디오 ID, 최근 시청 비디오 ID들, 사용자 언어, 비디오 언어.
- 연속형 특성: 마지막 시청 시간, 이전 노출 횟수.
1.2 출력(Output):
출력은 모델이 예측한 비디오의 순위 점수(Ranking Score)입니다. 이 점수는 비디오가 사용자에게 얼마나 적합한지를 나타냅니다.
| 사용자 ID | 현재 비디오 ID | 순위 점수 |
|---|---|---|
| 12345 | V123 | 0.85 |
| 67890 | V456 | 0.72 |
1.3 레이블(Label):
레이블은 사용자가 실제로 해당 비디오를 시청했는지 여부를 나타냅니다. 일반적으로 1(시청) 또는 0(시청하지 않음)으로 표현됩니다.
| 사용자 ID | 현재 비디오 ID | 레이블 (시청 여부) |
|---|---|---|
| 12345 | V123 | 1 |
| 67890 | V456 | 0 |
2. 목적 함수(Objective Function):
YouTube의 랭킹 모델은 이진 분류(Binary Classification) 문제로 정의되며, 목적 함수로 교차 엔트로피 손실(Cross-Entropy Loss)을 사용합니다. 이 손실 함수는 모델의 예측과 실제 레이블 간의 차이를 측정합니다.
2.1 교차 엔트로피 손실:

2.2 예시 계산:

2.3 목적:
모델은 이 손실을 최소화하기 위해 학습됩니다. 즉, 모델이 예측한 확률 ( p_i )가 실제 레이블 ( y_i )에 가까워지도록 가중치를 조정합니다.
3. 전체 과정 요약:
- 입력: 사용자와 비디오의 다양한 특성(범주형 및 연속형)이 모델에 입력됩니다.
- 출력: 모델은 각 비디오에 대한 순위 점수를 예측합니다.
- 레이블: 사용자가 실제로 비디오를 시청했는지 여부가 레이블로 사용됩니다.
- 목적 함수: 교차 엔트로피 손실을 최소화하여 모델의 예측 정확도를 높입니다.
4. 예시 데이터를 통한 전체 과정:
시나리오:
앨리스(사용자 ID: 12345)는 YouTube에서 요리 비디오를 자주 시청합니다. 그녀의 시청 기록에는 "파스타 만드는 법"(V101), "이탈리아 요리 기술"(V102), "전통 이탈리아 디저트"(V103) 등이 포함되어 있습니다. 현재 평가 중인 비디오는 "빠른 이탈리아 전채 요리"(V123)입니다.
4.1 입력 데이터:
| 사용자 ID | 현재 비디오 ID | 최근 시청 비디오 ID들 | 마지막 시청 시간 (시간 전) | 이전 노출 횟수 | 사용자 언어 | 비디오 언어 |
|---|---|---|---|---|---|---|
| 12345 | V123 | [V101, V102, V103] | 3 | 2 | 한국어 | 영어 |
4.2 모델 예측:
- 모델은 "빠른 이탈리아 전채 요리"(V123)에 대한 순위 점수를 0.85로 예측합니다.
4.3 레이블:
- 앨리스가 실제로 "빠른 이탈리아 전채 요리"(V123)를 시청했다면, 레이블은 1입니다.
4.4 손실 계산:

4.5 모델 학습:
- 모델은 이 손실을 최소화하기 위해 가중치를 조정합니다.
이 과정을 통해 YouTube는 사용자의 선호도와 비디오의 특성을 기반으로 개인화된 추천을 제공할 수 있습니다.
