이 논문은 eBay와 같은 대규모 전자상거래 플랫폼에서 개인화된 추천 시스템을 구축하기 위한 방법을 제안합니다. 이 방법은 사용자와 아이템을 동일한 벡터 공간에 임베딩하는 딥러닝 모델을 사용하며, 콘텐츠 기반의 아이템 임베딩과 다중 모달 사용자 임베딩을 통해 콜드 스타트 문제를 해결합니다.
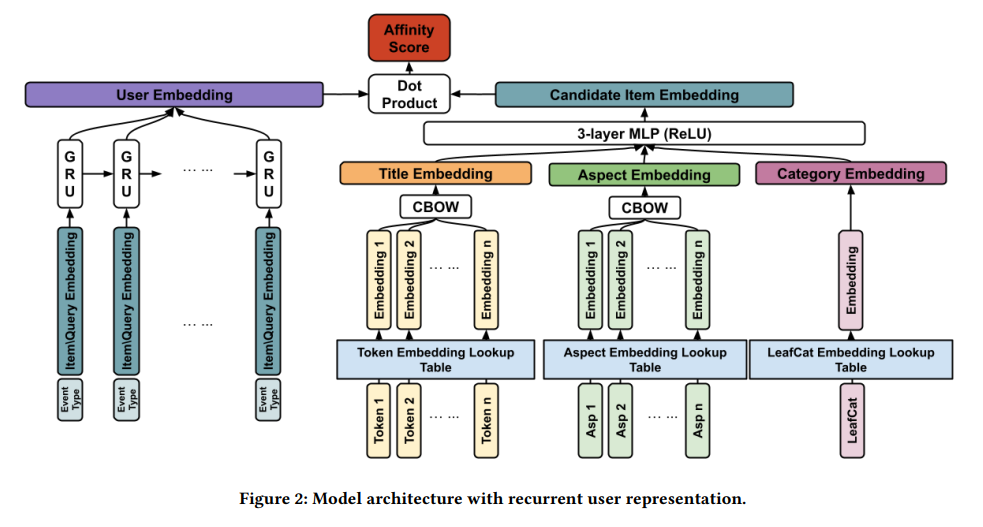
1. 아이템 임베딩 (Content-based Item Embedding)
아이템 임베딩은 아이템의 콘텐츠 정보(제목, 카테고리, 속성 등)를 기반으로 생성됩니다. 이는 콜드 스타트 문제를 해결하기 위해 아이템의 고유 ID 대신 콘텐츠 정보를 사용합니다.

- CBOW (Continuous Bag of Words): 단어들의 평균 임베딩을 계산하여 텍스트를 벡터로 변환합니다.
- MLP (Multi-Layer Perceptron): 여러 층의 신경망을 통해 아이템의 콘텐츠 정보를 임베딩으로 변환합니다.
2. 사용자 임베딩 (Multi-Modal User Embedding)
사용자 임베딩은 사용자의 온사이트 활동(아이템 클릭, 검색 쿼리 등)을 기반으로 생성됩니다. 이는 사용자의 다양한 활동을 다중 모달로 통합하여 개인화된 추천을 가능하게 합니다.
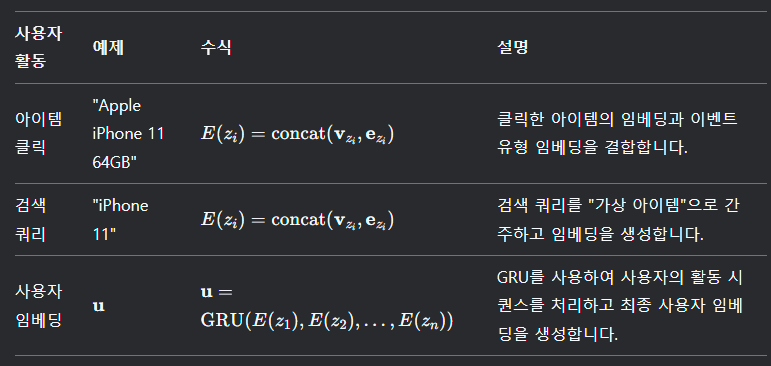
- Vzi: 아이템 벡터
- Ezi: 이벤트 벡터 (item click, search ...)
- GRU (Gated Recurrent Unit): 사용자의 활동 시퀀스를 처리하여 시간적 순서를 반영한 사용자 임베딩을 생성합니다.
- 이벤트 임베딩: 각 사용자 활동(클릭, 검색 등)을 벡터로 변환하고, 이를 GRU에 입력하여 사용자 임베딩을 생성합니다.
3. Affinity Function (유사도 함수)
사용자와 아이템 간의 유사도를 계산하기 위해 Affinity Function을 사용합니다. 이 함수는 사용자 임베딩과 아이템 임베딩의 내적을 기반으로 합니다.

4. KNN 검색 및 클러스터링 (KNN Search & Clustering)
추천 시스템에서 사용자에게 적합한 아이템을 찾기 위해 KNN (K-Nearest Neighbors) 검색을 사용합니다. 또한, 아이템의 다양성을 보장하기 위해 클러스터링 기법을 적용합니다.

- 클러스터링: 아이템을 클러스터로 그룹화하여 유사한 아이템들이 동일한 클러스터에 속하도록 합니다. 이를 통해 추천 아이템의 다양성을 높입니다.
5. 오프라인 평가 (Offline Evaluation)
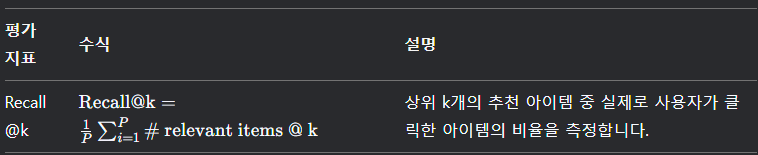
모델의 성능을 평가하기 위해 오프라인 평가를 수행합니다. 주요 평가 지표로는 Recall@k를 사용합니다.
6. 온라인 A/B 테스트 (Online A/B Testing)
모델의 실제 성능을 평가하기 위해 온라인 A/B 테스트를 수행합니다. 기존의 RVI (Recently Viewed Items) 방법과 비교하여 추천 시스템의 성능을 평가합니다.
| A/B 테스트 결과 | 결과 | 설명 |
|---|---|---|
| Surface Rate 증가 | ~6% 증가 | 추천 시스템이 사용자에게 더 많은 아이템을 노출시킬 수 있음을 의미합니다. |
- Surface Rate: 추천 시스템이 사용자에게 아이템을 노출시키는 비율로, 모델이 더 많은 아이템을 추천할 수 있음을 의미합니다.
7. 데이터 어블레이션 분석 (Data Ablation Analysis)
모델의 안정성을 높이기 위해 사용자 데이터의 일부를 제거하면서 모델을 학습시킵니다. 이를 통해 모델이 부분적인 데이터에서도 강건하게 동작하도록 합니다.
| 어블레이션 분석 | 결과 | 설명 |
|---|---|---|
| 최근 60분 데이터 제거 | Recall@20 50% 감소 | 최근 데이터가 모델 성능에 큰 영향을 미침을 보여줍니다. |
| 학습 시 데이터 제거 | 모델 강건성 증가 | 학습 시 데이터를 제거함으로써 모델이 부분적인 데이터에서도 잘 동작하도록 합니다. |
- 어블레이션 분석: 모델이 부분적인 데이터에서도 잘 동작하도록 하기 위해 학습 데이터의 일부를 의도적으로 제거하는 방법입니다.
8. 프로덕션 엔지니어링 아키텍처 (Production Engineering Architecture)
모델을 실제 프로덕션 환경에 배포하기 위한 엔지니어링 아키텍처를 설명합니다. 이는 대규모 사용자와 아이템을 처리하기 위해 설계되었습니다.
| 프로덕션 아키텍처 | 설명 |
|---|---|
| Spark ETL 작업 | 사용자 활동 데이터와 아이템 메타데이터를 처리 |
| GPU 클러스터 (Krylov) | 아이템 및 사용자 임베딩 생성 |
| KNN 검색 (FAISS) | 사용자 임베딩과 아이템 임베딩 간의 유사도 계산 |
| Couchbase 캐싱 | 빠른 런타임 추천을 위한 캐싱 시스템 |
- FAISS: 대규모 벡터 검색을 위한 라이브러리로, 빠른 KNN 검색을 가능하게 합니다.
- Couchbase: 추천 결과를 빠르게 제공하기 위한 캐싱 시스템입니다.
9. 향후 작업 (Future Work)
향후 모델의 개선을 위해 다양한 사용자 피드백(예: 장바구니 추가, 관심 목록 추가)을 통합하고, 사용자의 다양한 관심사를 반영할 수 있는 다중 임베딩 기법을 연구 중입니다.
| 향후 작업 | 설명 |
|---|---|
| 다중 사용자 임베딩 | 사용자의 다양한 관심사를 반영 |
| 실시간 추천 시스템 | 실시간 사용자 활동을 반영한 추천 |
이 테이블들은 논문에서 제안된 방법론을 실제 예제와 수식을 통해 더 자세히 설명한 것입니다. 이를 통해 개인화된 추천 시스템이 어떻게 동작하는지 이해할 수 있습니다.
