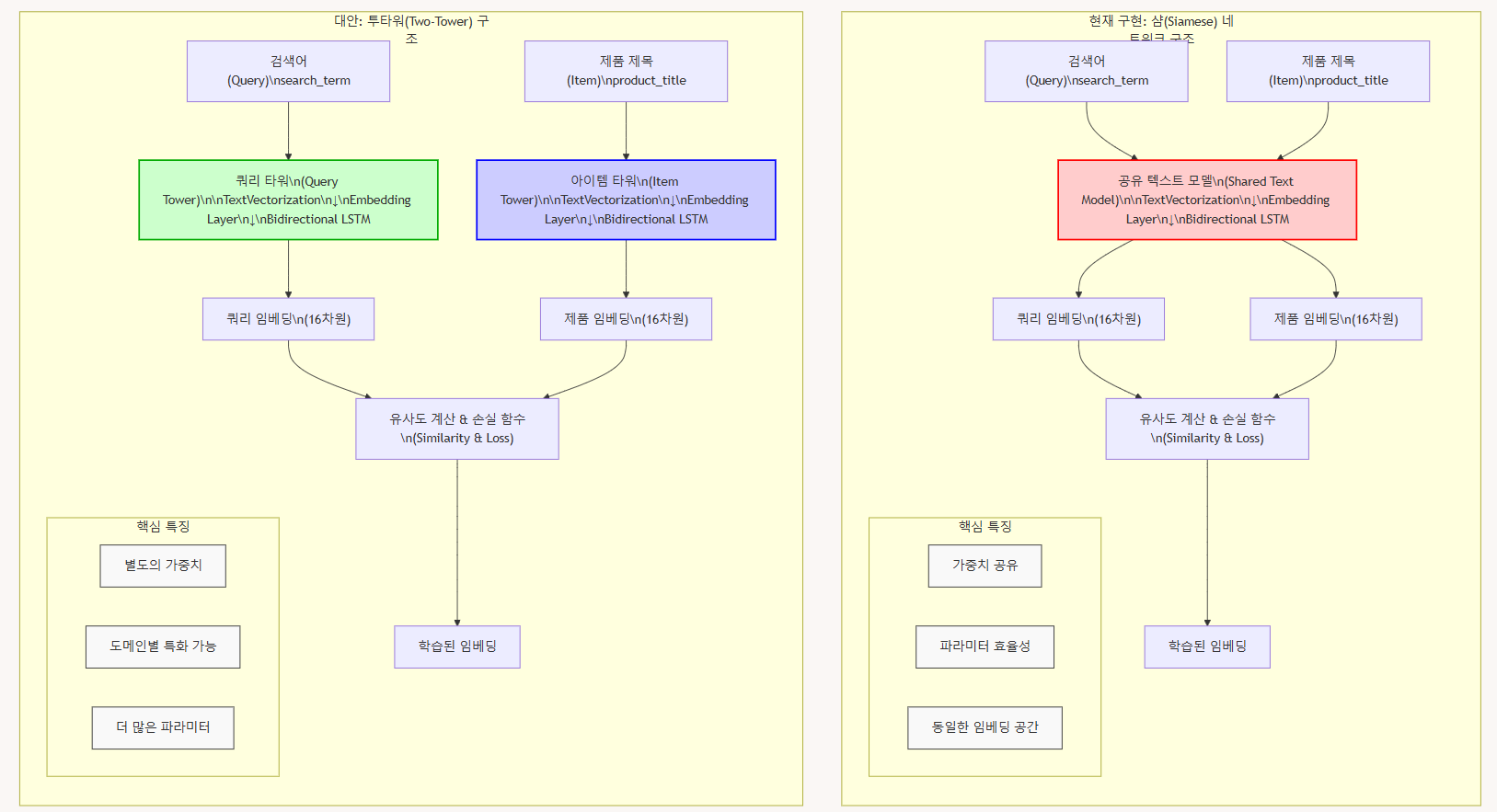
샴 네트워크 vs 투타워 구조 비교
샴 네트워크 구조
핵심 특징:
1. 가중치 공유: 쿼리와 아이템 모두 동일한 텍스트 모델을 통과합니다.
2. 파라미터 효율성: 하나의 모델만 학습하므로 파라미터 수가 더 적습니다.
3. 동일한 임베딩 공간: 쿼리와 아이템이 완전히 동일한 방식으로 처리되어 같은 임베딩 공간에 매핑됩니다.
코드 구현:
# 두개의 tower를 공유
text_model = tf.keras.Sequential([
vectorization,
tf.keras.layers.Embedding(1001, 8),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(8))
])
# 동일한 모델로 쿼리와 제품 처리
query_embedding = self.model(features['search_term'])
title_embedding = self.model(features['product_title'])투타워 구조 (대안)
핵심 특징:
1. 별도의 가중치: 쿼리와 아이템을 위한 별도의 인코더가 있으며, 각각 다른 가중치를 가집니다.
2. 도메인별 특화 가능: 쿼리와 아이템의 특성에 맞게 각 타워를 다르게 설계할 수 있습니다.
3. 더 많은 파라미터: 두 개의 독립적인 모델을 학습하므로 파라미터 수가 두 배입니다.
투타워 구현 예시:
# 별도의 타워 구현
query_tower = tf.keras.Sequential([
query_vectorization,
tf.keras.layers.Embedding(1001, 8),
tf.keras.layers.LSTM(16)
])
item_tower = tf.keras.Sequential([
item_vectorization,
tf.keras.layers.Embedding(1001, 8),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(8))
])
# 별도 모델로 쿼리와 제품 처리
query_embedding = query_tower(features['search_term'])
title_embedding = item_tower(features['product_title'])선택 기준
- 샴 네트워크: 쿼리와 아이템이 유사한 특성을 가질 때 효과적 (예: 둘 다 짧은 텍스트)
- 투타워 구조: 쿼리와 아이템이 매우 다른 특성을 가질 때 효과적 (예: 쿼리는 짧은 텍스트, 아이템은 이미지)
검색어와 제품 제목이 모두 텍스트이며 유사한 특성을 가지므로 샴 네트워크가 더 적합한 선택.

시리즈를 기반으로 작성하였습니다.