추천 시스템
1.연관 규칙 추천(Association Rule Mining, A priori 알고리즘)

상호 배반적이란 두 상품이 동시에 발생할 수 없는 관계올바른 예시:햇반 → 김치 (가능)맥주 → 기저귀 (가능)이들은 서로 다른 카테고리의 상품이며, 독립적으로 구매 가능하기 때문입니다.잘못된 예시:햇반 → 햇반 프리미엄콜라 1.5L → 콜라 2L같은 종류의 상품이라
2.마르코프 체인
ref: https://www.youtube.com/watch?v=i3AkTO9HLXo&list=PLM8wYQRetTxBkdvBtz-gw8b9lcVkdXQKV각 포인트는 다음날 무엇을 먹을지에 대한 확률이다.ex) 햄버거를 먹고 다음날 피자를 먹을 확률: 0.
3.Page Rank
A는 인접 행렬H는 전이 행렬인접행렬과 전이행렬의 차이.예를 들어 3개의 페이지(A, B, C)가 있고 다음과 같은 링크가 있다고 해보겠습니다:인접행렬 (Adjacency Matrix)단순히 링크의 존재(1)와 부재(0)를 나타냅니다.전이행렬 (Transition Ma
4.Text rank
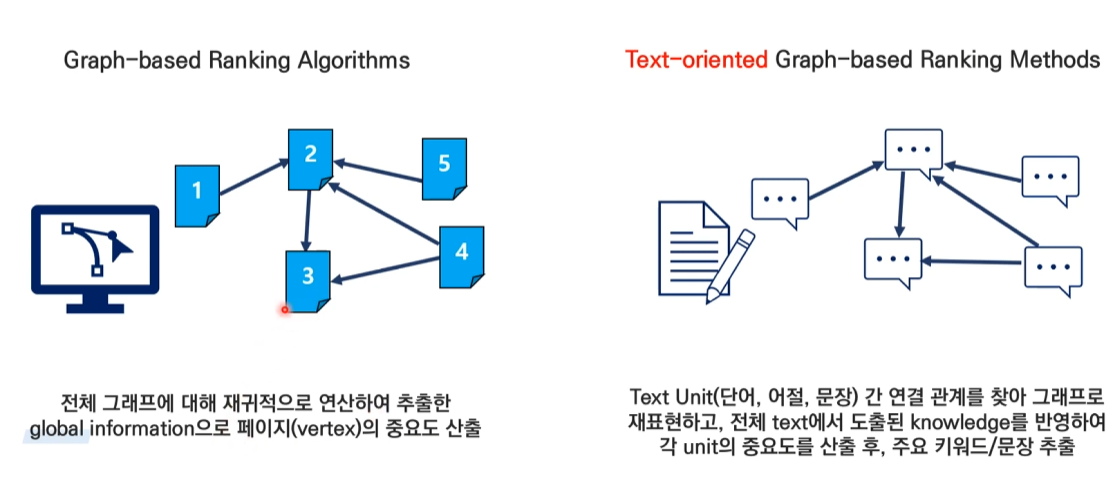
실험 결과 명사, 형용사 조합이 가장 좋은 결과.window size 2에 해당하는 단어들을 연결해 준다.위 예제는 방상형과 가중치가 없는 그래프이다.방향이 있고 가중치가 없는 그래프방향성은 window size에서 왼쪽에서 오른쪽에 있는 방향으로 정해진다.ex) li
5. 의사결정 기반의 전파 모형(linear threshold model)
Linear Threshold Model은 소셜 네트워크에서 영향력이 전파되는 과정을 수학적으로 설명하는 모델입니다.핵심 개념:1\. 임계값(θ): 각 개인이 행동을 변화시키는 기준점2\. 가중치(w): 이웃 노드들의 영향력 크기실제 예시로 설명하겠습니다:💡 대학생
6.전파 최대화 문제 1
정의한정된 예산(k명의 초기 시작점)으로 네트워크에서 최대한 많은 사람에게 영향을 미치고 싶을 때, 어떤 사람들을 선택해야 하는지를 찾는 문제입니다.실제 예시: 대학교 축제 홍보 상황상황: 축제 홍보대사 3명을 선발해야 함 (k=3)목표: 최대한 많은 학생들에게 축제
7.전파 최대화 문제 2
정점의 중심성(Node Centrality)을 이용한 휴리스틱 접근 방법기본 개념휴리스틱: 최적해를 보장하지는 않지만, 실용적이고 효율적인 해결책을 찾는 방법k개 시드 선택: 주어진 제한된 수(k)만큼 초기 전파자를 선택하는 문제주요 중심성 지표들각각의 중심성을 실제
8.전파 최대화 문제 3 (Greedy Algorithm)
탐욕 알고리즘(Greedy Algorithm)기본 개념매 단계에서 현재 상황에서 가장 좋아 보이는 선택을 함한 번 선택한 것은 번복하지 않음전체 최적해를 보장하지는 않지만, 계산이 빠르고 실용적알고리즘 진행 과정 (예: SNS 인플루언서 3명 선택하기)Step 1: 첫
9.군집 탐색
배치 모형(Configuration Model)배치 모형은 네트워크 과학에서 매우 중요한 개념으로, 네트워크의 구조를 이해하고 분석하는 데 사용되는 null 모델입니다.실제 예시를 들어보겠습니다:대학교 동아리 네트워크를 생각해봅시다.각 학생(정점)의 친구 수(연결성)를
10. Girvan-Newman 알고리즘 (하양식 방법)
매개 중심성 계산 공식 쉽게 설명Σ (시그마)는 모든 경우의 합을 구한다는 의미입니다.i<j는 모든 노드 쌍을 한 번씩만 계산한다는 뜻입니다.더 쉽게 풀어서 설명하면:이 단순화된 그래프에서 매개 중심성을 계산해보겠습니다:1️⃣ C-D 간선의 매개 중심성 계산:1단
11.유사도와 내적
내적의 수학적 의미를 수식과 함께 설명두 벡터 u와 v의 내적은 다음과 같이 정의됩니다:u·v = ||u|| ||v|| cos(θ)여기서,||u||, ||v||는 각 벡터의 크기(magnitude)θ는 두 벡터 사이의 각도cos(θ)는 두 벡터의 방향 유사도구체적인 수
12.그래프의 정점을 어떻게 백터로 표현할까?
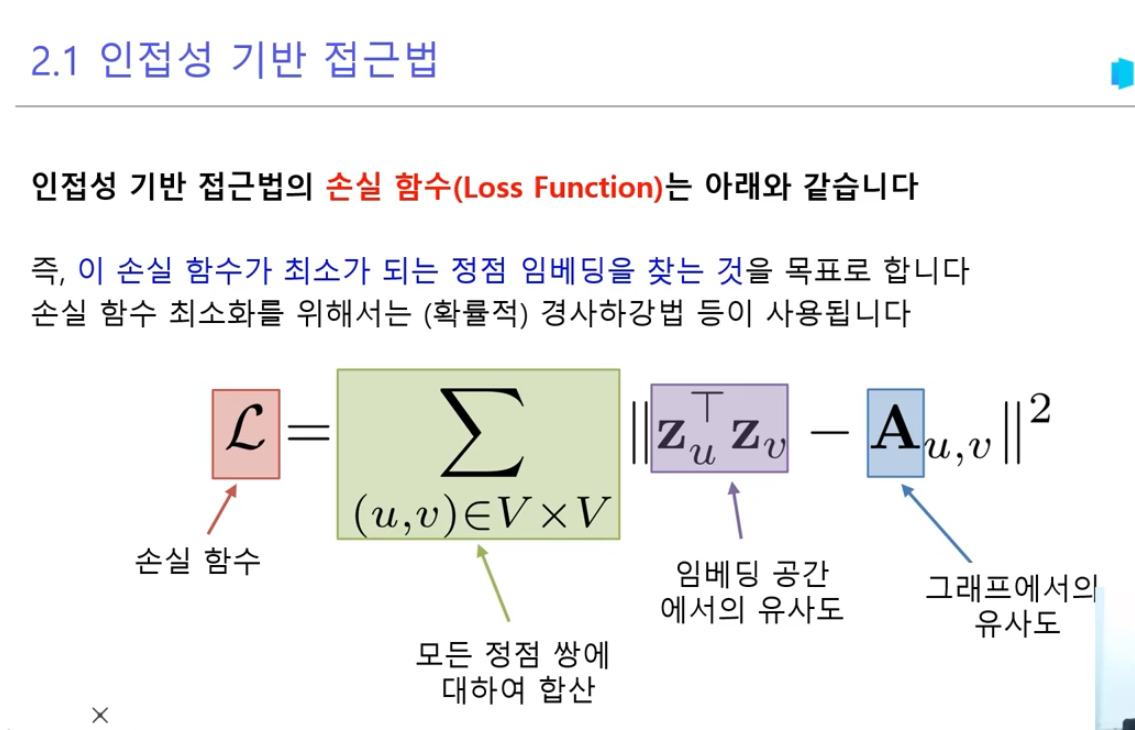
기본 개념 설명손실함수 L = Σ ||z_u^T z_v - A_u,v||²는 다음을 의미합니다:z_u, z_v: 정점 u와 v의 임베딩 벡터A_u,v: 실제 그래프에서 정점 u와 v 사이의 연결 관계||...||²: 유클리드 거리의 제곱실제 예시를 통한 설명작은 소셜
13.경로 기반 접근법
수식을 직관적으로 이해해보겠습니다:기본 개념 설명:두 정점(u,v) 사이의 경로 중 거리가 k인 것을 A^k\_{u,v}로 표현합니다예를 들어, A가 다음과 같은 소셜 네트워크를 나타낸다고 가정해봅시다:철수(1) - 영희(2) - 민수(3) - 지영(4)실제 예시로 이
14.중첩 기반 접근법

간단한 소셜 네트워크 예시:먼저 각 노드의 이웃 집합을 구합니다:공통 이웃 수 계산 (S\_{u,v}):임베딩 벡터 예시 (2차원):손실 함수 계산 예시:철수-영희 쌍에 대해:영희-지영 쌍에 대해:전체 손실 함수:최적화 목표:zu^T z_v 값이 S{u,v}에 가까워지
15.임의보행 기반 접근 (DeepWalk)
임의보행 기반 접근법의 손실 함수를 실제 예시와 함께 자세히 설명해드리겠습니다.네트워크 예시:임의보행 수행:시작노드 '철수'에서의 임의보행 시퀀스 예:확률 계산 P(v|z_u):손실 함수 상세 설명:여기서:V: 모든 노드 집합N_R(u): u에서 시작한 임의보행에서 방
16.임의보행 기반 접근 (Node2Vec)
DeepWalk는 자연어 처리의 Word2Vec 아이디어를 그래프에 적용한 것입니다. 그래프의 노드들을 단어처럼 생각하고, 랜덤 워크로 생성된 노드 시퀀스를 문장처럼 간주합니다.다음과 같은 소셜 네트워크가 있다고 가정해보겠습니다:이 그래프에서 가능한 랜덤 워크의 예시:
17.협업 필터링 (유저 기반, 아이템 기반)
협업 필터링의 수식과 계산 과정을 자세히 설명해드리겠습니다.먼저 유저 간 유사도를 계산하기 위해 코사인 유사도를 사용합니다.코사인 유사도 공식: 철수와 다른 사용자들의 유사도를 계산해보겠습니다:a) 철수-영희 유사도:공통 평점이 있는 영화: 어벤져스(5,4), 인셉션(
18.행렬 분해(Matrix Factorization)
다음과 같은 3명의 사용자와 4개의 영화에 대한 평점 데이터가 있다고 가정하겠습니다:3x4 행렬평점 행렬 R을 두 개의 행렬 P(사용자 특성)와 Q(영화 특성)로 분해잠재 요인의 수를 k=2로 설정 (예: 액션 선호도, 로맨스 선호도)먼저 P와 Q 행렬을 작은 난수로
19.SVD
SVD 분해 과정먼저 중심화된 행렬 R'을 다시 보겠습니다:이 행렬을 R' = U × Σ × V^T로 분해하는 과정을 설명하겠습니다.각 행렬의 의미:U (3×3): 사용자들의 잠재 특성 행렬Σ (3×3): 특이값을 대각선상에 가진 행렬V^T (3×4): 영화들의 잠재
20.MF-ALS(Alternating Least Squares, 교대 최소 제곱법)
기본 개념:ALS는 행렬 분해를 위한 반복적인 최적화 방법입니다. SVD와 비슷하지만, 결측치(missing values)가 많은 추천 시스템에 더 적합해요.실제 예시로 설명하겠습니다:(여기서 ?는 평가하지 않은 영화입니다)ALS의 목표:사용자 행렬(U)과 아이템 행렬
21.KNN(K-Nearest Neighbors)
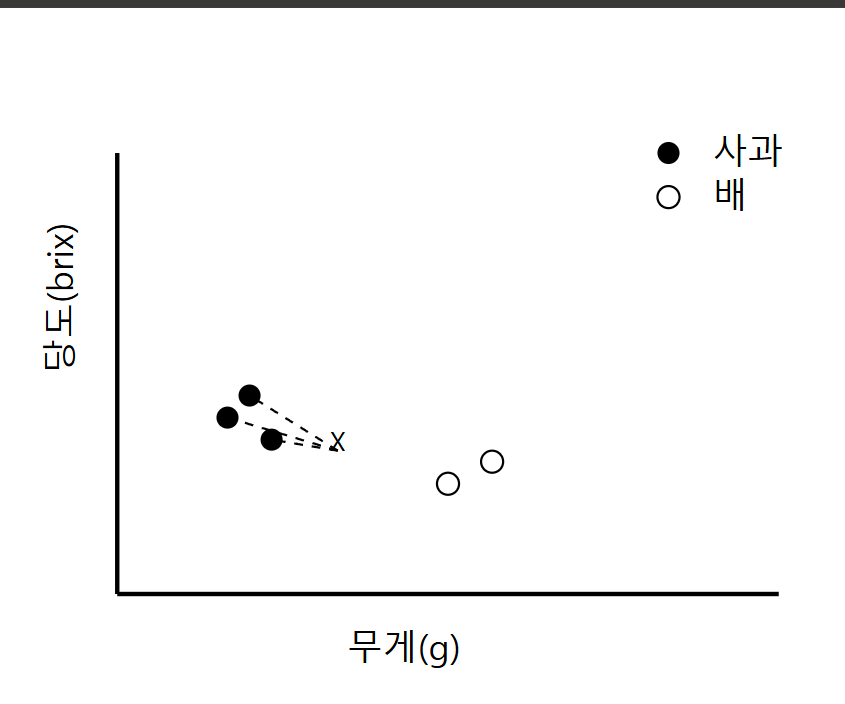
KNN의 기본 개념KNN은 새로운 데이터 포인트가 들어왔을 때, 가장 가까운 K개의 이웃들의 다수결로 분류하는 알고리즘입니다. 마치 "새로운 동네로 이사왔을 때, 가장 가까운 이웃 K명의 성향을 보고 그 동네의 특성을 파악하는 것"과 같습니다.거리 계산 방법가장 일반적
22.내적(Dot product) vs 요소별 곱(Hadamard product)
Hadamard product는 단순히 두 벡터의 대응되는 요소들을 곱한 결과 벡터를 만드는 연산입니다:이는 각 차원에서의 "상호작용(interaction)"을 표현합니다.0.56: 첫 번째 차원에서의 사용자-아이템 상호작용 강도0.12: 두 번째 차원에서의 상호작용
23.NCF
초기 잠재 벡터는 랜덤(정규 분포 사용)데이터셋 크기별 권장 차원:작은 데이터셋 (<10K users/items): 8~16 차원중간 데이터셋 (10K~100K): 16~32 차원큰 데이터셋 (>100K): 32~256 차원예시) MovieLens 데이터셋:Mov
24.베타 분포
많은 성공 (Beta(9,3) - 8성공, 2실패)그래프가 오른쪽(0.7~0.8 부근)으로 치우침뾰족한 모양은 "이 동전은 앞면이 나올 확률이 약 75%다"라는 강한 확신을 보여줌하지만 여전히 약간의 불확실성(곡선의 폭)이 존재많은 실패 (Beta(3,9) - 2성공,
25.MAB-1
1\. MAB의 기본 개념카지노의 슬롯머신을 생각해보세요. 여러 대의 슬롯머신이 있고, 각각의 슬롯머신은 서로 다른 당첨 확률을 가지고 있습니다. 하지만 우리는 그 확률을 모릅니다. 제한된 동전으로 최대한 많은 당첨금을 얻으려면 어떻게 해야 할까요?이것이 바로 MAB
26.MAB-2
문맥 정보(Contextual Information)를 MAB에 적용하는 방법1\. 시간대를 활용한 Thompson Sampling 예시저녁 8시, 넷플릭스를 켠 사용자 김철수 님의 케이스로 설명해보겠습니다.기본 데이터:시간대별 데이터를 보니:이때 우리는 베타 분포를
27.feature store
이커머스 추천에 사용되는 feature 예시사용자 관련 피처기본적인 사용자 정보:사용자의 쇼핑 행동 관련 피처:상품 관련 피처상품의 기본 정보:상품의 성과 지표:협업 필터링 관련 피처사용자-사용자 협업 필터링 점수:상품-상품 협업 필터링 점수:상호작용 관련 피처사용자와
28.협업 필터링 vs 내용기반 추천 시스템
협업 필터링과 내용기반 추천 시스템의 구조A. 사용자 기반 협업 필터링(User-based CF)핵심 구조:사용자-아이템 평가 행렬 생성사용자 간 유사도 계산 (코사인 유사도, 피어슨 상관계수 등 사용)가장 유사한 이웃 사용자 그룹 선정이웃 사용자들의 평가를 기반으로
29.추천 시스템 평가
가상의 '패션 이커머스' 데이터를 기반a) Precision@K (정밀도)시스템 추천 결과:Precision@5 계산:상위 5개 중 실제 구매 상품 수: 3개Precision@5 = 3/5 = 0.6 = 60%b) 평균 정밀도(Average Precision, AP)c
30.GNN 1
시점 t=0 (초기 상태):사용자 정보:A: 운동 선호 사용자 1,0,0B: 캐주얼 선호 사용자 0,1,0C: 골프 선호 사용자 0,0,1상품 정보:운동화: 0.9,0.1,0 (운동 성향 강함)트레이닝복: 0.8,0.1,0.1골프공: 0.1,0,0.9상호작용:클릭 가중
31.GNN 2
유저끼리의 간선을 포함하여 계산해 보자시점 t=0 (초기 상태):사용자 정보:A: 운동 선호 사용자 1,0,0B: 캐주얼 선호 사용자 0,1,0C: 골프 선호 사용자 0,0,1상품 정보:운동화: 0.9,0.1,0 (운동 성향 강함)트레이닝복: 0.8,0.1,0.1골프공
32.GNN 3
이웃의 이웃까지 적용해 보자초기 상태 (Step 0)1-hop 계산 (Step 1)2-hop 계산 (Step 2)실제 적용 예시:"A 사용자가 운동화를 클릭했을 때:1\. 직접 상품 상호작용으로 운동 선호도 강화2\. B의 캐주얼 선호도 일부 반영3\. C의 골프 선호
33.Cosine Similarity와 Dot Product의 관계
Cosine Similarity와 Dot Product의 관계s(q,x) = ||x|| ||q|| cos(q,x)여기서 s(q,x)는 두 벡터 q와 x 사이의 유사도를 나타냅니다||x||는 벡터 x의 norm(길이)||q||는 벡터 q의 norm(길이)cos(q,x)는
34.l2 norm, 점곱 과 코사인 유사도의 관계
코사인 유사도와 벡터의 내적(dot product)은 밀접하게 관련되어 있습니다. 하지만, 정확히 동일한 값이 나오는 것은 아닙니다.코사인 유사도는 벡터의 방향이 얼마나 유사한지를 측정하는 반면, 단순한 내적은 벡터의 크기와 방향 모두를 고려합니다.따라서, 벡터 내적에
35.two-tower 알고리즘-1
유튜브 추천 시스템을 예시로 Two Tower 알고리즘의 전체 과정입력 데이터 구성사용자 임베딩 과정비디오 임베딩 과정유사도 계산학습과 업데이트최종 추천이런 과정을 통해 모델은:사용자의 관심사를 학습콘텐츠의 특성을 파악개인화된 추천을 제공하게 됩니다.
36.Deep Neural Networks for YouTube Recommendations
넷플릭스 시청 데이터를 통한 예시사용자 A의 넷플릭스 시청 기록Training 데이터 (1월~11월):1월: "킹덤", "D.P"5월: "종이의 집", "마블 시리즈" 8월: "오징어 게임", "수리남"Test 데이터 (12월):"더 글로리", "환혼"일반 사용자 김철
37.Expected Calibration Error (ECE)
Expected Calibration Error (ECE)는 머신 러닝 모델, 특히 확률을 출력하는 분류 모델의 신뢰도(calibration)를 평가하기 위한 지표입니다. ECE는 모델이 예측한 확률과 실제 정답 간의 불일치를 측정합니다. 모델이 잘 캘리브레이션(cal
38.교차 네트워크(Cross Network)
교차 네트워크(Cross Network)의 수식:교차 피쳐는 두 개 이상의 입력 특성(feature)을 조합하여 생성된 새로운 특성입니다. 예를 들어:country \* bananas: 국가와 바나나 소비량의 상호작용bananas \* cookbooks: 바나나 소비량
39.PairwiseHingeLoss
y_true: 실제 레이블. 두 번째 항목(인덱스 1)이 관련성이 높고(1), 나머지는 관련성이 낮음(0).y_pred: 모델이 예측한 점수. 두 번째 항목(0.8)과 네 번째 항목(0.8)이 가장 높은 점수를 받음.loss(y_true, y_pred).numpy()는
40.Retrieval, Ranking 입력 데이터 예시
Retrieval 단계에서는 사용자와 아이템의 기본 정보를 사용해 후보 아이템을 선정합니다. 입력 데이터는 일반적으로 다음과 같습니다.사용자 ID: user_123사용자 프로필:연령: 30성별: 남성지역: 서울사용자 행동 데이터:최근 클릭한 아이템 ID: \[item_
41.Retrieval과 Ranking

Retrieval 단계에서 선정된 후보 아이템들 중에서 클릭(Click)이 발생한 아이템은 True(1), 클릭이 발생하지 않은 아이템은 False(0)로 라벨링하여 이진 분류(Binary Classification) 문제로 접근합니다. 이는 랭킹 모델이 사용자가 특정
42.In-batch negative sampling
Q: u1가 i2나 i3와 상호작용이 있는 경우는 없는지?In-batch negative sampling에서 ( u1 )가 ( i2 )나 ( i3 )와 상호작용이 있는 경우는 포지티브 샘플로 간주되지 않습니다. In-batch negative sampling은 미니배치
43.TFRS 입력,출력,라벨 구조
각 행(row)은 (user_id, movie_title) 쌍으로 구성됩니다.예: \[user_123, "인셉션"] → 사용자 123이 "인셉션"을 시청했다는 기록.Positive Label:데이터셋에 명시된 (user_id, movie_title) 쌍은 자동으로 po
44.In-Batch Negative Sampling 한계
In-Batch Negative Sampling은 인기 있는 아이템(상품/영화)이 상대적으로 더 자주 네거티브 샘플로 선택될 가능성이 높습니다.이 현상은 데이터 분포의 편향성에서 비롯되며, 추천 시스템의 성능에 영향을 미칠 수 있습니다.인기 아이템의 빈도 수:인기 있
45.in-batch negative
이커머스에서의 In-Batch NegativesIn-batch negative는 학습 배치 내에서 negative sample을 구성하는 방법입니다. 이커머스 환경에서는 한 배치 내의 다른 사용자가 상호작용한 상품을 현재 사용자의 negative sample로 사용합니
46.DNC와 Cross Network 개요
DNC(Deep & Cross Network)는 추천 시스템에서 사용자와 아이템 간의 상호작용을 예측하는 데 사용되는 딥러닝 모델로, 특히 이커머스 데이터에서 사용자 행동을 예측하는 데 유용합니다. DNC는 Cross Network와 Deep Network 두 부분으로
47.Retrieval Task에 특화된 메트릭
FactorizedTopK는 TFRS 라이브러리에서 추천 시스템의 검색(retrieval) 작업을 평가하기 위해 설계된 메트릭입니다. 추천 시스템에서는 사용자가 좋아하는 아이템(예: 영화, 상품 등)을 대규모 카탈로그에서 찾아 상위 K개의 추천 목록으로 제시하는 것이
48.Siamese Network vs Two-Tower Architecture Comparison
핵심 특징:1\. 가중치 공유: 쿼리와 아이템 모두 동일한 텍스트 모델을 통과합니다.2\. 파라미터 효율성: 하나의 모델만 학습하므로 파라미터 수가 더 적습니다.3\. 동일한 임베딩 공간: 쿼리와 아이템이 완전히 동일한 방식으로 처리되어 같은 임베딩 공간에 매핑됩니다.
49.딥러닝 학습 속도 개선 방법
https://docs.google.com/document/d/1Bd35n0Xxe-lr6HVxDl9Dy8Rst_O5fNJSGxlTdCUKOio/edit?usp=sharing