질의답
1.
"의미론적 정합성 게이트" 거리 측정 피쳐에 맨해튼거리 방식(절대값)을 사용한 이유.
딥러닝 모델의 내부 피처(Feature)로 사용할 때는 제곱보다 절댓값이 더 유리한 경우가 있습니다.

-
이상치(Outlier)에 대한 민감도 문제
- 제곱(Squared, L2): 차이가 조금만 커져도 결과값이 기하급수적으로 커집니다.
- 예: 차이가 0.1이면 제곱은 0.01이지만, 차이가 10이면 제곱은 100이 됩니다.
임베딩 벡터의 특정 차원에 노이즈가 껴서 값이 튀면, 제곱 방식은 그 값을 너무 과하게 반영하여 전체 거리를 왜곡시킬 수 있습니다.
-
절댓값(Absolute, L1): 차이가 커지는 만큼만 비례해서 커집니다.
-
특정 차원이 튀더라도 전체 결과에 미치는 영향이 제곱 방식보다 덜합니다. 즉, 노이즈에 더 강건(Robust)합니다.
-
또한 너무 들쑥날쑥하게 큰 것(제곱)보다, 선형적으로 증가하는 값(절댓값)이 학습할 때 가중치(Weight)를 조절하기가 더 편안합니다(Gradient가 안정적임).
-
2.
힌지 마진 손실 0.15가 왜 객관적으로 타당한 수치인가?
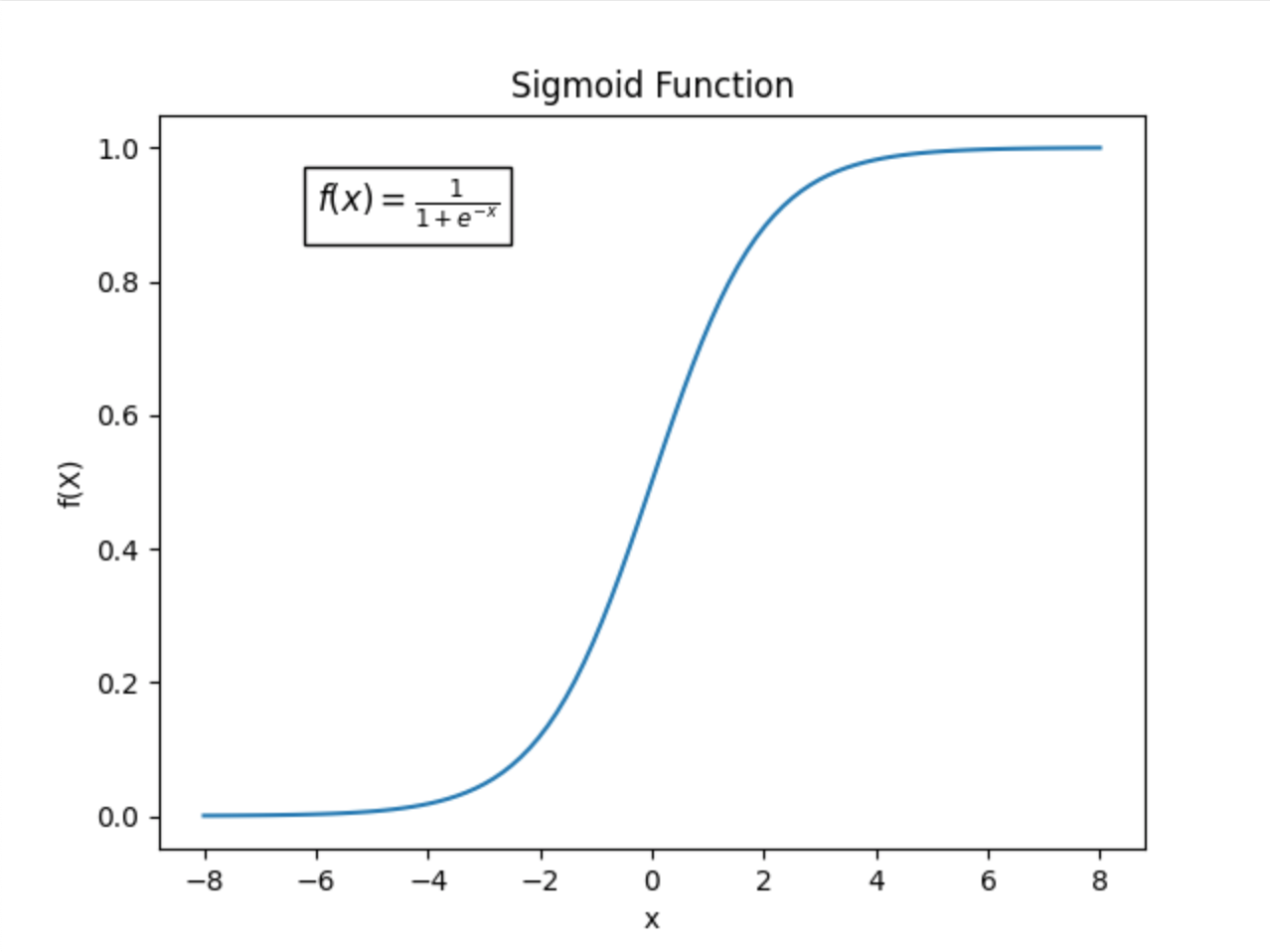
수학적 관점: Sigmoid의 "선형 구간"과 "포화 구간"
Sigmoid 함수 의 그래프 참고.
- 중간 구간 (y축: 0.2 ~ 0.8): 그래프가 직선에 가깝습니다. 입력값()이 조금만 변해도 출력값()이 잘 변합니다. 즉, 학습이 가장 잘 되는 구간입니다.
- 양쪽 끝 구간 (y축: 0 ~ 0.1 or 0.9 ~ 1.0): 그래프가 평평합니다(Saturation). 입력값을 아무리 크게 바꿔도 출력값은 거의 변하지 않습니다. 이를 기울기 소실이라고 합니다.
마진 크기에 따른 시나리오 분석
-
마진이 너무 클 때 (예: 0.5)
- 조건:
- 이를 만족하려면 예를 들어 , 정도가 되어야 합니다.
- 문제점: 이 값을 만들기 위해 모델은 입력값(Logit)을 아주 크게 키우거나 줄여야 합니다. 즉, Sigmoid의 양쪽 끝(포화 구간)으로 데이터를 억지로 밀어넣어야 합니다.
- 결과: 학습 속도가 급격히 느려지거나, 모델이 과도하게 확신(Overconfidence)하는 부작용이 생깁니다.
-
마진이 0.15일 때 (적절함)
- 조건:
- 시나리오: , (중앙 부근에서 약간만 벌려도 만족)
- 장점: 이 값들은 Sigmoid의 가장 기울기가 가파른 구간(중앙)에 위치합니다.
- 결과: 모델이 적은 힘(작은 가중치 변화)으로도 조건을 만족시킬 수 있어 학습이 빠르고 안정적입니다.

시리즈를 기반으로 작성하였습니다.