Tools (stock)
1장 에이전트의 확장: Tools (도구)
1. 도구(Tool)란 무엇인가?
도구는 본질적으로 "LLM이 호출할 수 있는 함수"입니다.
우리가 파이썬 함수를 작성하고, 그 함수를 "언제 써야 하는지", "어떤 값을 넣어야 하는지" 설명서를 붙여주면, LLM은 대화 맥락에 맞춰 스스로 이 함수를 실행(Call)하기로 결정합니다.
이 과정을 시각화하면 다음과 같습니다.
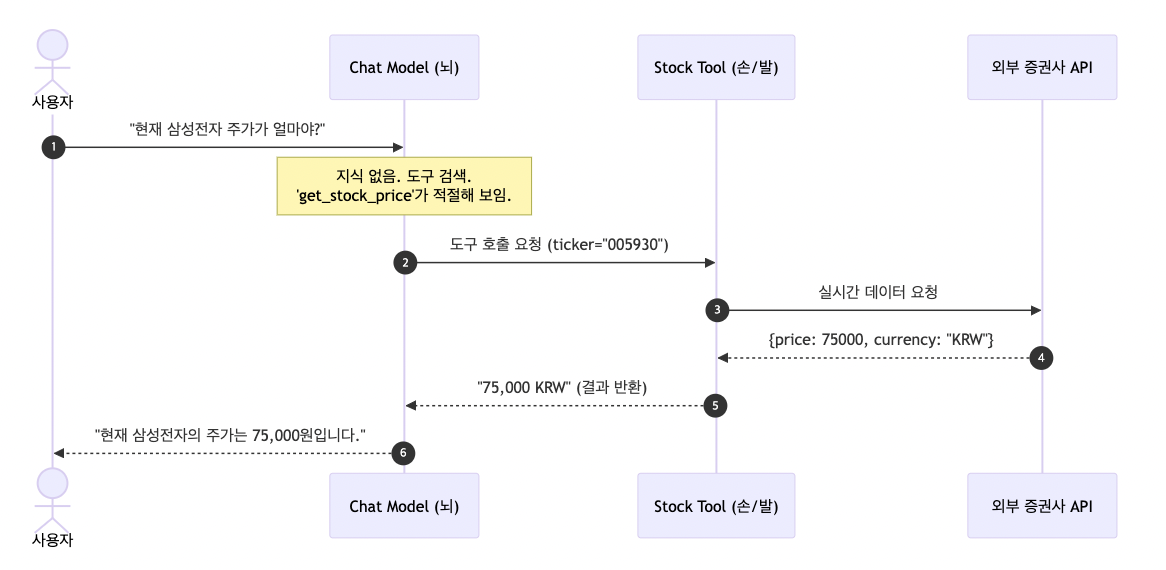
2. 가장 기초적인 도구 만들기: @tool 데코레이터
가장 쉬운 방법은 @tool 데코레이터를 사용하는 것입니다. 여기서 가장 중요한 것은 함수의 이름, 독스트링(Docstring), 그리고 타입 힌트(Type Hint)입니다. LLM은 이 세 가지를 보고 도구의 사용법을 익힙니다.
예제: 단순 주가 조회 도구
주식 종목 코드(Ticker)를 입력받아 현재 가격을 알려주는 간단한 도구를 만들어봅시다.
from langchain.tools import tool
# 1. 데코레이터 선언
@tool
def get_stock_price(ticker: str) -> str:
"""
특정 주식 종목의 현재 가격을 조회합니다.
Args:
ticker (str): 조회할 주식의 종목 코드 (예: 'AAPL', '005930')
"""
# 실제로는 여기서 yfinance나 증권사 API를 호출합니다.
# 예시를 위해 가상의 데이터를 반환합니다.
mock_data = {
"AAPL": "185.50 USD",
"005930": "75,000 KRW"
}
price = mock_data.get(ticker, "데이터 없음")
return f"{ticker}의 현재 가격: {price}"
# 도구 정보 확인
print(f"이름: {get_stock_price.name}")
print(f"설명: {get_stock_price.description}")
print(f"인자 스키마: {get_stock_price.args}")핵심 포인트
- 타입 힌트(
ticker: str): 필수입니다. LLM에게 "이 함수에는 문자열을 넣어야 해"라고 알려주는 규칙입니다. - 독스트링(Docstring): LLM에게 주는 '프롬프트' 역할을 합니다. "특정 주식 종목의 현재 가격을 조회합니다"라는 문장을 보고 LLM은 사용자가 "가격 알려줘"라고 할 때 이 도구를 선택합니다.
3. 정교한 도구 만들기: Pydantic을 활용한 스키마 정의
단순히 가격만 묻는 것이 아니라, "지난 30일간의 이동평균선(MA)을 계산해줘"와 같이 복잡한 요청을 처리해야 한다면 어떨까요?
이때는 입력 변수가 여러 개가 되고, 각 변수의 제약 조건(기간, 날짜 등)이 중요해집니다. 이를 위해 Pydantic 모델을 사용하여 입력 스키마를 엄격하게 정의해야 합니다.
예제: 주식 기술적 지표(Technical Indicator) 계산 도구
이 도구는 억지스러운 예시가 아니라, 실제 퀀트 투자나 분석 에이전트에서 사용하는 방식입니다.
from langchain.tools import tool
from pydantic import BaseModel, Field
from typing import Literal
# 1. 입력 스키마(설계도) 정의
class TechnicalAnalysisInput(BaseModel):
"""기술적 지표 계산을 위한 입력 파라미터"""
ticker: str = Field(
...,
description="주식 종목 코드 (예: AAPL, TSLA)"
)
indicator_type: Literal["SMA", "EMA", "RSI"] = Field(
...,
description="계산할 보조지표 종류 (SMA: 단순이동평균, EMA: 지수이동평균, RSI: 상대강도지수)"
)
window: int = Field(
default=20,
description="지표 계산 기간 (일 단위). 기본값은 20일."
)
# 2. 도구 정의 (args_schema 적용)
@tool(args_schema=TechnicalAnalysisInput)
def calculate_technical_indicator(ticker: str, indicator_type: str, window: int = 20) -> str:
"""
주식 데이터에 대한 기술적 분석 지표를 계산합니다.
이동평균선이나 모멘텀 지표를 요청받았을 때 사용하세요.
"""
# 실제 로직: pandas 등으로 데이터 분석 수행
# 여기서는 예시 반환
return f"[{ticker}] {window}일 {indicator_type} 계산 결과: 145.20 (상승 추세)"🔍 구조 시각화 (Mermaid Class Diagram)
위 코드가 LLM에게 어떻게 전달되는지 구조적으로 살펴보겠습니다. Pydantic 모델은 LLM이 이해할 수 있는 JSON 스키마로 변환됩니다.
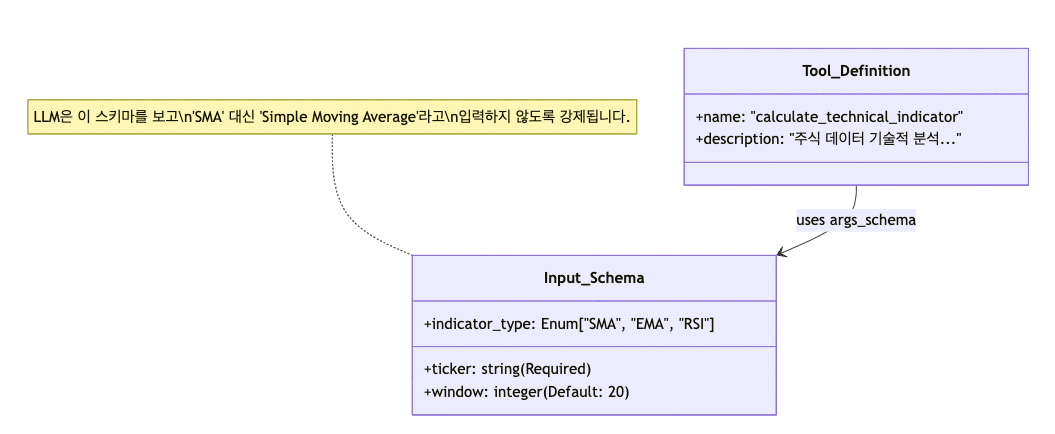
이렇게 Literal과 Field를 사용하면, LLM이 엉뚱한 값(예: 지표 타입에 "Love"를 넣는 등)을 입력하는 환각(Hallucination)을 방지할 수 있습니다.
4. 도구의 속성 커스터마이징
때로는 함수 이름이 코드 작성 규칙(snake_case)을 따르다 보니 LLM이 이해하기 어려울 수 있습니다. 혹은 기존 함수를 수정하지 않고 이름만 바꾸고 싶을 때가 있죠.
이름과 설명 덮어쓰기
@tool("stock_screener", description="PER, PBR 등 펀더멘털 지표를 기준으로 저평가된 주식을 검색합니다.")
def search_undervalued_stocks(min_per: float, max_pbr: float) -> str:
"""(이 독스트링은 무시되고 위의 description이 사용됩니다)"""
return f"PER {min_per} 이상, PBR {max_pbr} 이하 종목 검색 결과..."@tool("이름"): 함수명search_undervalued_stocks대신stock_screener라는 이름으로 LLM에게 소개됩니다.
5. 주의사항: 예약된 인자 이름 (Reserved Arguments)
도구를 만들 때 절대 사용하면 안 되는 변수명이 있습니다. LangChain 프레임워크 내부에서 사용하는 변수들이기 때문입니다.
| 금지된 변수명 | 이유 |
|---|---|
config | RunnableConfig (실행 설정)를 전달하기 위해 예약됨 |
runtime | ToolRuntime (상태, 컨텍스트 접근)을 위해 예약됨 |
잘못된 예시:
@tool
def get_financial_report(ticker: str, config: dict): # (X) 에러 발생 가능성 높음!
...만약 실행 시점의 설정이나 메타데이터가 필요하다면, 인자 이름을 config 대신 user_config 등으로 변경하거나, LangChain이 제공하는 ToolRuntime 파라미터 주입 방식을 따라야 합니다.
마무리
도구(Tool)는 LLM을 단순한 '챗봇'에서 '일 잘하는 비서'로 진화시키는 열쇠입니다.
1. @tool로 함수를 감싸고,
2. Type Hint와 Docstring으로 사용법을 명시하고,
3. 복잡한 입력은 Pydantic으로 정의한다.
이 세 가지만 기억하시면, 어떤 주식 데이터 분석 도구도 만드실 수 있습니다.
앞선 장에서 우리는 도구(Tool)를 만드는 법을 배웠습니다. 하지만 지금까지 만든 도구에는 치명적인 단점이 하나 있었습니다. 바로 "기억상실증"입니다.
도구 함수 자체는 독립적으로 실행되기 때문에, 지금 대화하고 있는 사용자가 누구인지(User ID), 이전에 무슨 대화를 나눴는지(History), 사용자의 투자 성향이 무엇인지(Memory) 전혀 알지 못합니다.
이번 장에서는
ToolRuntime이라는 강력한 매개변수를 통해, 도구에게 맥락(Context)과 기억(Memory)을 주입하는 방법을 아주 상세히 알아보겠습니다.
2장. 도구에 지능 더하기: Context와 State 접근
1. ToolRuntime이란 무엇인가?
ToolRuntime은 도구가 실행될 때, 에이전트 시스템(LangGraph 등)이 도구에게 몰래 쥐여주는 '만능 키'와 같습니다.
이전에는 상태(State)를 얻기 위해 InjectedState, 설정을 위해 RunnableConfig 등을 따로따로 써야 했지만, 이제는 ToolRuntime 하나로 통일되었습니다.
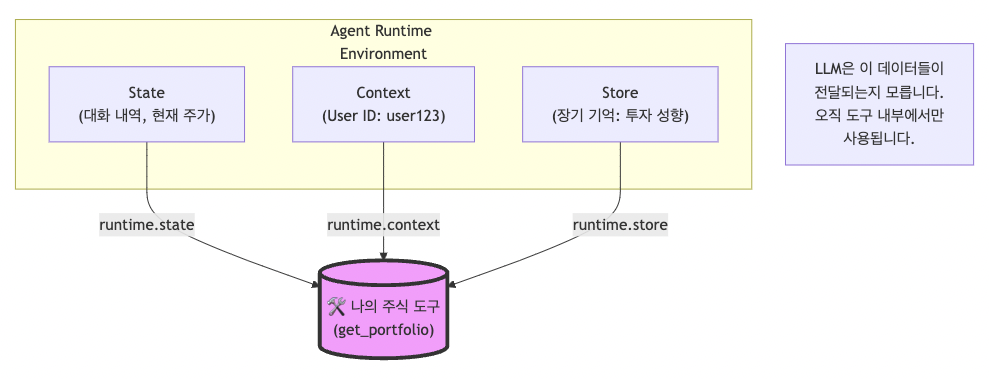
ToolRuntime이 제공하는 5가지 핵심 요소
- State (상태): 현재 대화의 흐름, 주고받은 메시지 내역 (변경 가능)
- Context (컨텍스트): 사용자 ID, 세션 정보 등 고정된 설정값 (변경 불가)
- Store (저장소): 대화가 끝나도 유지되는 장기 기억 (DB와 유사)
- Stream Writer: 도구 실행 중간중간 진행 상황을 사용자에게 알림
- Config: 실행 설정 정보
이 구조를 그림으로 먼저 이해해 봅시다.
2. 실전 예제: 개인화된 주식 포트폴리오 관리
이제부터 '사용자 맞춤형 포트폴리오 조회 도구'를 만들면서 각 기능을 하나씩 적용해 보겠습니다.
시나리오
- 사용자 A는 '공격적 투자자'이고, 사용자 B는 '안정적 투자자'입니다.
- 도구는 사용자 ID를 알아야 누구의 계좌를 조회할지 결정할 수 있습니다. (Context)
- 도구는 사용자가 방금 어떤 종목을 언급했는지 대화 내역에서 찾아야 합니다. (State)
2-1. Context 접근: "당신은 누구십니까?"
도구 함수에 runtime: ToolRuntime을 추가하면 됩니다. 이때 UserContext 같은 데이터 클래스를 정의하여 타입 안전성을 확보합니다.
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
# 1. 컨텍스트 스키마 정의 (사용자 정보)
@dataclass
class UserContext:
user_id: str
access_level: str # 예: 'premium', 'basic'
# 가상의 증권사 데이터베이스
PORTFOLIO_DB = {
"user_A": {"name": "김철수", "holdings": {"AAPL": 10, "TSLA": 5}, "cash": 1000.0},
"user_B": {"name": "이영희", "holdings": {"005930": 100, "035420": 20}, "cash": 500000.0}
}
# 2. 도구 정의 (Context 접근)
@tool
def get_my_portfolio(runtime: ToolRuntime[UserContext]) -> str:
"""
현재 로그인한 사용자의 주식 포트폴리오와 현금 잔고를 조회합니다.
"""
# runtime.context를 통해 사용자 ID에 접근
user_id = runtime.context.user_id
if user_id not in PORTFOLIO_DB:
return "오류: 사용자 정보를 찾을 수 없습니다."
user_data = PORTFOLIO_DB[user_id]
holdings = ", ".join([f"{k}: {v}주" for k, v in user_data['holdings'].items()])
return f"[{user_data['name']}님의 포트폴리오]\n보유 주식: {holdings}\n현금 잔고: {user_data['cash']}"
# 주의: LLM은 user_id를 입력하지 않습니다. 시스템이 주입합니다.2-2. State 접근: "방금 무슨 얘기 했지?"
이번에는 도구가 현재 대화의 상태(State)를 읽어오는 방법입니다. 예를 들어, 사용자가 "삼성전자 어때?"라고 물어본 뒤 "그거 매수해줘"라고 했을 때, "그거"가 무엇인지 알려면 상태를 봐야 합니다.
@tool
def analyze_mentioned_stock(runtime: ToolRuntime) -> str:
"""
대화 맥락을 분석하여 가장 최근에 언급된 주식 종목을 다시 분석합니다.
"""
# runtime.state를 통해 현재까지의 메시지 목록 접근
messages = runtime.state.get("messages", [])
# (단순화된 로직) 최근 메시지에서 종목 코드가 있는지 역순으로 탐색
# 실제로는 별도의 파싱 로직이 필요합니다.
last_ticker = "알 수 없음"
for msg in reversed(messages):
if "삼성전자" in msg.content:
last_ticker = "005930 (삼성전자)"
break
elif "테슬라" in msg.content:
last_ticker = "TSLA (테슬라)"
break
if last_ticker == "알 수 없음":
return "이전 대화에서 주식 종목을 찾을 수 없습니다."
return f"문맥 파악 완료: 사용자가 언급한 '{last_ticker}'에 대한 심층 분석을 시작합니다..."3. 상태 업데이트 (Updating State)
도구가 단순히 정보를 읽는 것을 넘어, 에이전트의 상태를 변경해야 할 때가 있습니다.
예를 들어, "매수 주문" 도구가 실행되면, 에이전트의 order_status 상태를 '주문 완료'로 바꿔야 합니다.
이때는 Command 객체를 반환합니다.
from langgraph.types import Command
@tool
def place_buy_order(ticker: str, quantity: int) -> Command:
"""
주식 매수 주문을 실행하고, 주문 상태를 업데이트합니다.
"""
# 1. 실제 주문 로직 (API 호출 등)
order_id = "ORD-20240101-001" # 가상의 주문 번호
print(f"[System] {ticker} {quantity}주 매수 주문 전송 완료.")
# 2. Command를 반환하여 에이전트의 상태(State)를 업데이트
return Command(
# 도구의 실행 결과 메시지
update={
# 에이전트의 전역 상태 중 'last_order' 필드를 업데이트
"last_order": {"id": order_id, "ticker": ticker, "status": "SUCCESS"},
# 대화 기록에 시스템 메시지 추가 (선택 사항)
"messages": [f"시스템 알림: {ticker} 매수가 체결되었습니다."]
}
)핵심 포인트: Command vs 일반 반환
- 일반 반환 (
return str): LLM에게 "이런 결과가 나왔어"라고 알려주는 용도입니다. Command반환: 시스템(LangGraph)에게 "이 변수 값을 이렇게 바꿔줘"라고 명령하는 용도입니다.
4. 장기 기억 (Store)과 스트리밍
Store: 세션이 끊겨도 기억하기
사용자가 "나는 바이오주는 싫어해"라고 말했습니다. 내일 다시 접속했을 때도 이걸 기억해야겠죠? 이때 runtime.store를 사용합니다.
@tool
def set_investment_preference(preference: str, runtime: ToolRuntime) -> str:
"""사용자의 투자 선호도(예: '바이오 기피', '배당주 선호')를 저장합니다."""
user_id = runtime.context.user_id # 현재 사용자 ID
store = runtime.store
# ('users', user_id)라는 키로 데이터 저장 (Key-Value Store)
current_prefs = store.get(("users",), user_id) or {}
# 데이터 업데이트
new_data = {"preference": preference}
store.put(("users",), user_id, new_data)
return f"알겠습니다. 앞으로 '{preference}' 성향을 기억하고 투자 조언에 반영하겠습니다."Stream Writer: "계산 중입니다..."
복잡한 퀀트 분석은 시간이 오래 걸립니다. 사용자가 멈춘 화면을 보지 않도록 stream_writer로 중간 보고를 합니다.
import time
@tool
def calculate_complex_valuation(ticker: str, runtime: ToolRuntime) -> str:
"""복잡한 가치평가 모델(DCF)을 계산합니다."""
writer = runtime.stream_writer
writer(f"1단계: {ticker}의 재무제표를 불러오는 중...")
time.sleep(1) # 가상의 처리 시간
writer("2단계: 미래 현금 흐름(FCF) 추정 중...")
time.sleep(1)
writer("3단계: 적정 주가 산출 중...")
time.sleep(1)
return f"{ticker}의 적정 주가는 $150.00 입니다."5. 전체 구조 시각화 (Python Graph)
우리가 배운 ToolRuntime의 데이터 흐름을 파이썬 코드로 시각화하여 정리해 봅시다.
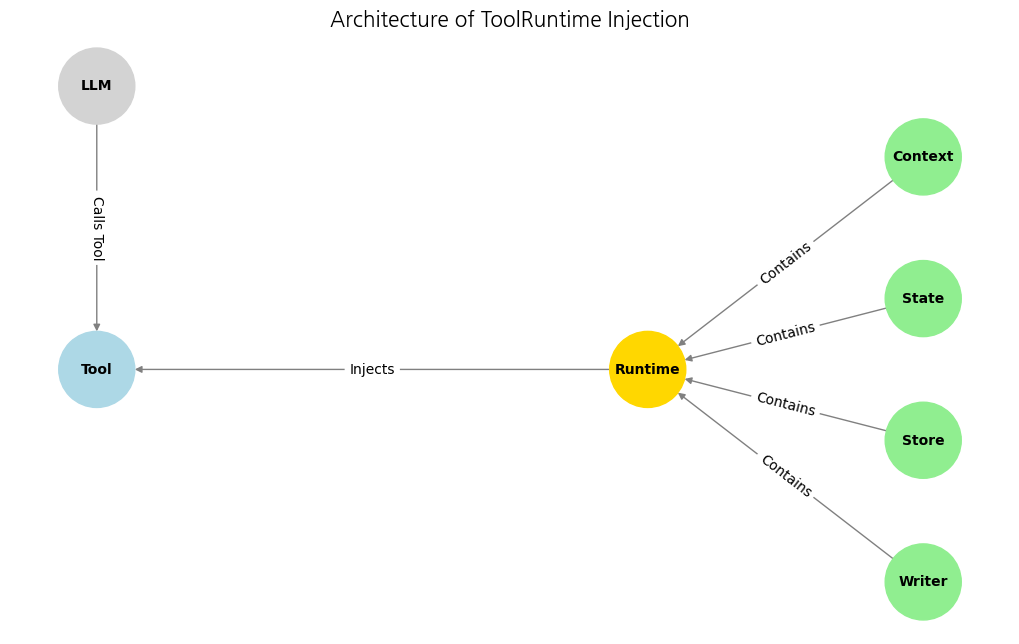
마무리
이번 장의 핵심은 "도구는 혼자가 아니다"라는 것입니다.
ToolRuntime을 사용하면 도구가 에이전트의 뇌(State), 신분증(Context), 수첩(Store)에 접근할 수 있습니다.- 이를 통해 단순히 "주가를 알려줘"가 아니라, "김철수 님(Context), 아까 말씀하신(State) 삼성전자는 공격적인 성향(Store)을 고려할 때 매수를 추천합니다"라고 말하는 똑똑한 에이전트를 만들 수 있습니다.
다음 장에서는 이렇게 만든 도구들을 묶어서 실제로 에이전트를 구동시키는 AgentExecutor와 LangGraph의 워크플로우에 대해 알아보겠습니다.
