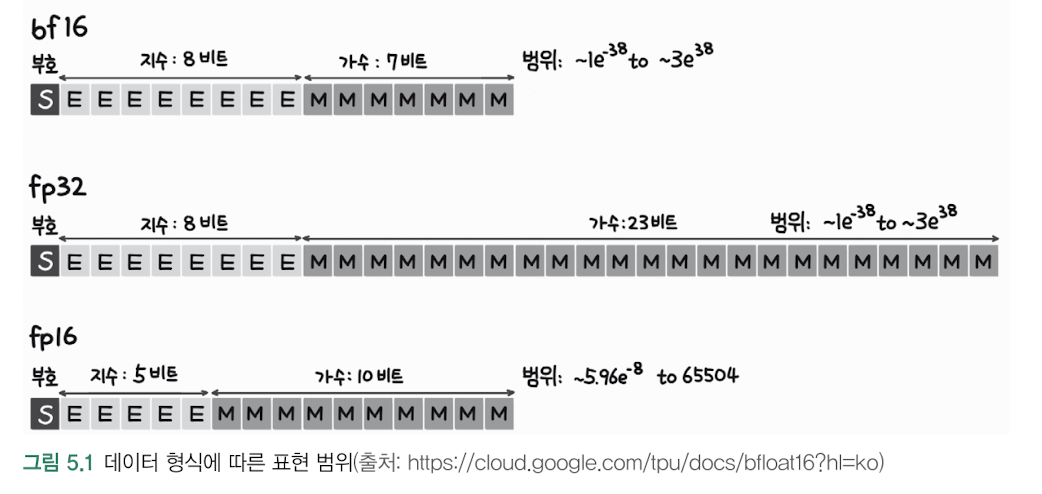
LLM에서는 일반적으로 fp16보다 bf16이 더 선호
- 수치 안정성
- fp16은 지수부가 5비트로 작아서 표현 범위가 제한적 (±65,504)
- bf16은 지수부가 8비트라서 fp32와 동일한 범위 표현 가능 (±3.4×10^38)
- LLM 학습 시 gradient 값들이 매우 작거나 큰 경우가 많은데, bf16이 이런 값들을 더 잘 표현
- 오버플로우/언더플로우 문제
- fp16은 범위가 작아서 학습 중 수치가 범위를 벗어나는 경우가 자주 발생
- 이로 인해 NaN(Not a Number) 또는 Inf(Infinity) 문제가 자주 발생
- bf16은 이런 문제가 훨씬 적게 발생
- 메모리 효율성
- 둘 다 16비트를 사용하므로 fp32 대비 메모리 사용량 50% 감소
- 하지만 bf16이 더 안정적이어서 추가적인 보정 기법(예: loss scaling)이 덜 필요
실제 사용 예시:
# PyTorch에서 bf16 사용 예
model = model.to(torch.bfloat16)
# 학습 시
scaler = torch.cuda.amp.GradScaler() # fp16은 이게 필요
with torch.autocast(device_type='cuda', dtype=torch.bfloat16): # bf16은 단순
loss = model(input)대표적인 사용 사례:
- GPT 모델들의 학습
- BERT, T5 등 대규모 언어 모델
- PaLM, LLaMA 등의 최신 모델들
단, bf16은 가수부가 7비트로 짧아서 정밀도는 낮지만, LLM 학습에서는 이 정도의 정밀도 손실이 성능에 크게 영향을 미치지 않는다고 알려져 있습니다.

시리즈를 기반으로 작성하였습니다.