LLM 최적화
1.FlashAttention

FlashAttention은 Transformer 모델의 self-attention 메커니즘을 최적화하는 기술입니다. 주요 특징과 장점은 다음과 같습니다:메모리 효율성:기존 self-attention은 모든 데이터를 메모리에 한 번에 로드했지만, FlashAttenti
2.데이터 타입
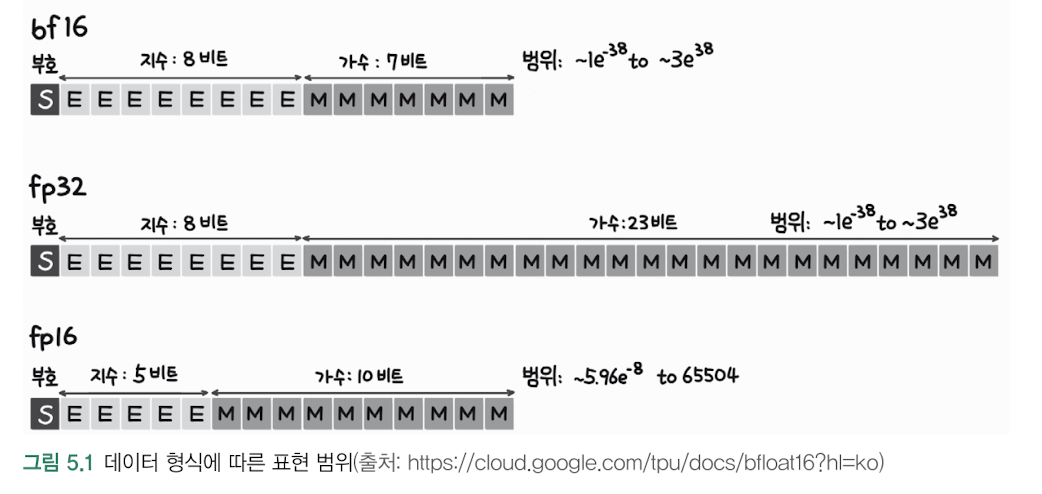
LLM에서는 일반적으로 fp16보다 bf16이 더 선호수치 안정성fp16은 지수부가 5비트로 작아서 표현 범위가 제한적 (±65,504)bf16은 지수부가 8비트라서 fp32와 동일한 범위 표현 가능 (±3.4×10^38)LLM 학습 시 gradient 값들이 매우 작
3.Gradient 누적
그래디언트 누적의 목적제한된 GPU 메모리로 더 큰 배치 크기 효과를 얻기 위해 사용작은 배치로 나눠서 계산하고 그래디언트를 모아서 한 번에 업데이트장점:메모리 효율적: 큰 배치를 직접 처리할 때보다 메모리 사용량이 적음큰 배치 효과: 작은 배치로 나눠 처리해도 큰 배
4.Gradient Checkpointing
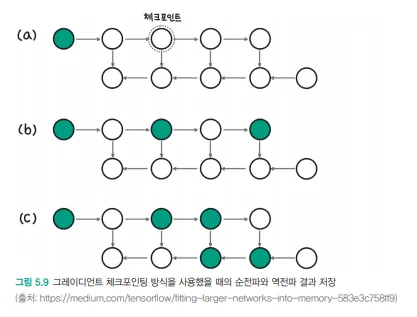
기본 원리:딥러닝 모델 학습 시 모든 중간 활성화값을 메모리에 저장하는 대신 일부만 저장역전파(Backpropagation) 과정에서 필요한 중간값들은 저장된 체크포인트로부터 재계산메모리 사용량과 계산 시간 사이의 트레이드오프를 조절할 수 있음장점:메모리 사용량을 크게
5.ZeRO (Zero Redundancy Optimizer)
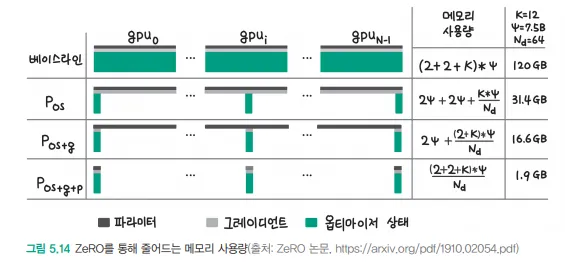
ZeRO (Zero Redundancy Optimizer)는 대규모 딥러닝 모델 학습을 위한 메모리 최적화 기술입니다. 이미지에서 보이는 것처럼 여러 단계의 파티셔닝을 통해 메모리를 효율적으로 사용합니다.ZeRO-1 (Optimizer State Partitioning
6.최적의 배치크기 계산
기본 공식: 배치 크기 = 하드웨어 연산 속도 / (2 × 메모리 대역폭)실제 숫자를 대입한 예:하드웨어 연산 속도 = 312×10¹² (FLOPS)메모리 대역폭 = 1555×10⁹ (bytes/s)계산: (312×10¹²) / (2 × 1555×10⁹) = 102.7
7.Group Query Attention
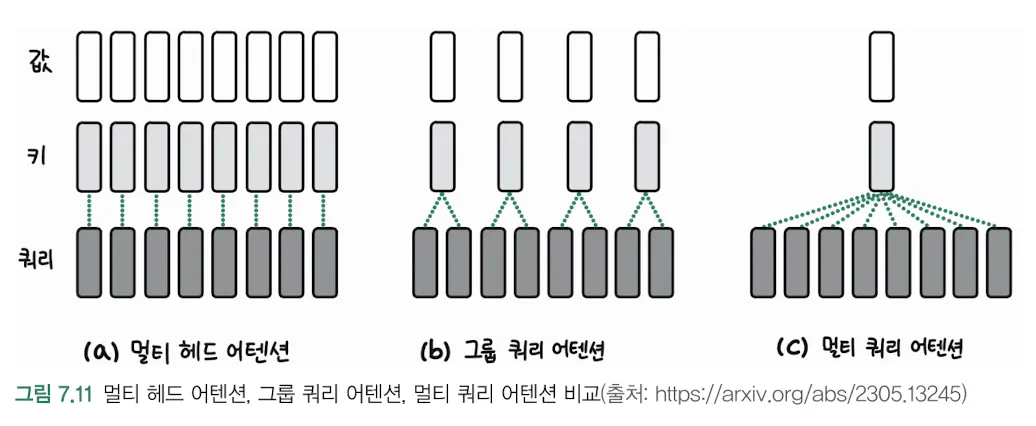
구조적 특징:기존 멀티헤드 어텐션과 달리 쿼리(Q)의 수가 키(K)와 값(V)의 수보다 적습니다중간 단계에서 4개의 쿼리가 8개의 키/값 쌍과 상호작용하는 것을 볼 수 있습니다작동 방식:장점:연산 효율성: 쿼리의 수가 적어 계산량이 줄어듭니다메모리 효율성: 어텐션 맵의
8.flash attention
핵심 내용: 용량이 작고 빠른 GPU의 SRAM에서 계산할 수 있도록 블록처리SRAM (Static Random-Access Memory):특징:GPU 내부에 위치한 고속 캐시 메모리매우 빠른 읽기/쓰기 속도전력 소비가 많고 비용이 높음플래시 어텐션의 블록 단위 계산이
9.flash attention
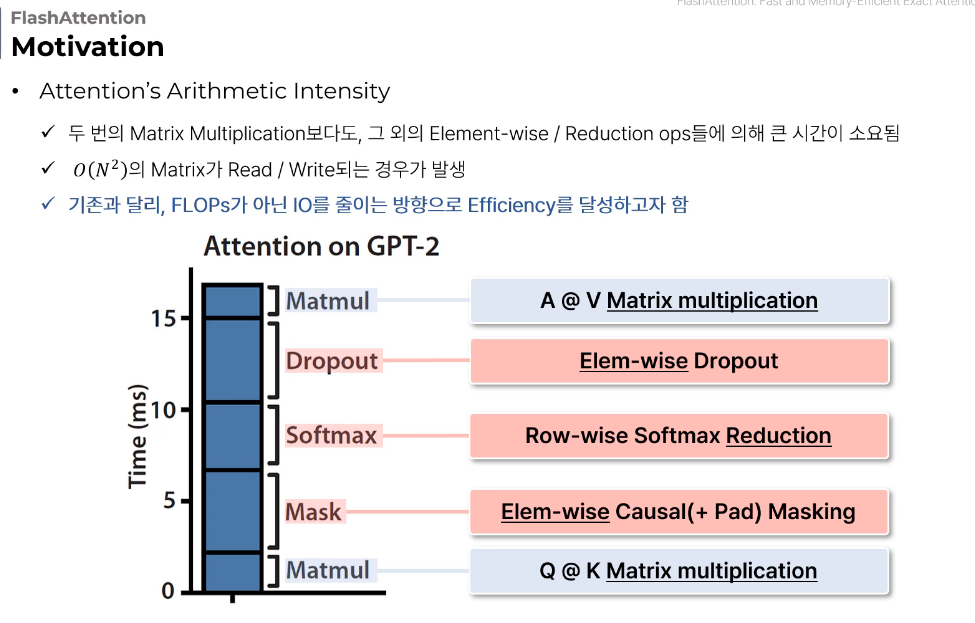
실제 값 예시를 통한 설명:입력값: 24, 12, 18 일반 Softmax (Algorithm 1) 계산과정:Online Safe Softmax (Algorithm 3) 계산과정:Overflow 문제 상세 설명:a) 컴퓨터의 수 표현 한계:일반적인 32비트 float는
10.동적 디코딩(ALiBi)
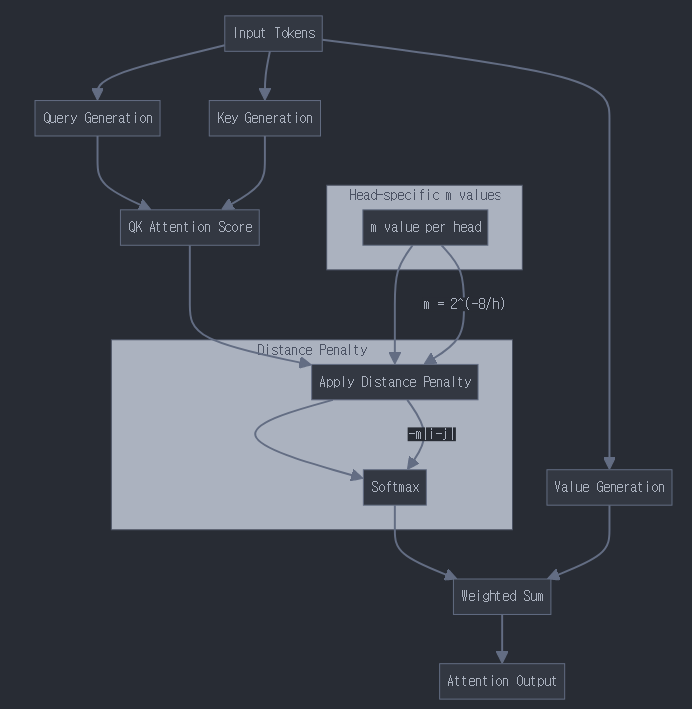
ALiBi의 기본 개념기존 positional encoding을 대체하는 방식attention score에 직접적으로 거리에 비례하는 벌점(페널티)을 부여학습된 position embedding 없이도 위치 정보를 반영핵심 수식기본 attention score 계산:s
11.paged attention vs flash attention
핵심 목적과 접근 방식:플래시 어텐션: GPU 메모리 대역폭 최적화에 중점타일 단위로 행렬 곱셈을 수행HBM과 SRAM 사이의 메모리 이동 최소화페이지 어텐션:GPU 메모리 용량 관리에 중점페이지 단위로 KV 캐시 관리메모리 할당과 재사용에 초점메모리 접근 방식:최적화
12.paged attention
KV캐시의 방식은 max_length의 값을 미리 메모리로 잡아 놓는다.길이가 짧은 요청인 경우 빈값 즉, 공간 낭비가 발생한다.페이지 어텐션의 경우 블록테이블을 관리해서 실제로는 물리적으로 연속된 메모리를 사용하지 않으면서 논리적 메모리에서는 서로 연속적이도록 만들었
13.vLLM
일반 배치와 vLLM에서 사용하는 시퀀스의 차이점.vLLM은 페이지 어텐션을 사용이해를 위한 극단적 예시 (블록사이즈 상관안함)일반적인 Batch 처리의 경우:VLLM Sequence 처리의 경우:처리 방식의 차이:메모리 사용 패턴:이처럼 VLLM의 시퀀스 처리는 각
14.Self-Attention과 KV 캐시
"나는 학교에 간다"라는 문장을 처리한다고 가정토큰화 과정각 토큰은 고유한 임베딩 벡터로 변환됩니다. 간단한 예시를 위해 2차원 벡터로 표현해보겠습니다:KV 캐시 작동 방식첫 번째 단어 "나는"을 처리할 때:Key: 0.2, 0.8Value: 0.15, 0.75이 값들
15.KV캐쉬 최적화
kv캐쉬를 hbm에 얼마나 차지하게 할지에 따라 배치 크기가 정해지고배치 크기가 적당해야 sram의 연산 속도를 맞출 수 있다.전체 시스템의 균형을 맞추는 것이 핵심HBM (40GB) 공간 분배:균형점 찾기:KV 캐시가 너무 크면:배치 크기가 작아짐SRAM이 제 성능을
16.멀티 쿼리 어텐션(MQA), 그룹 쿼리 어텐션(GQA)
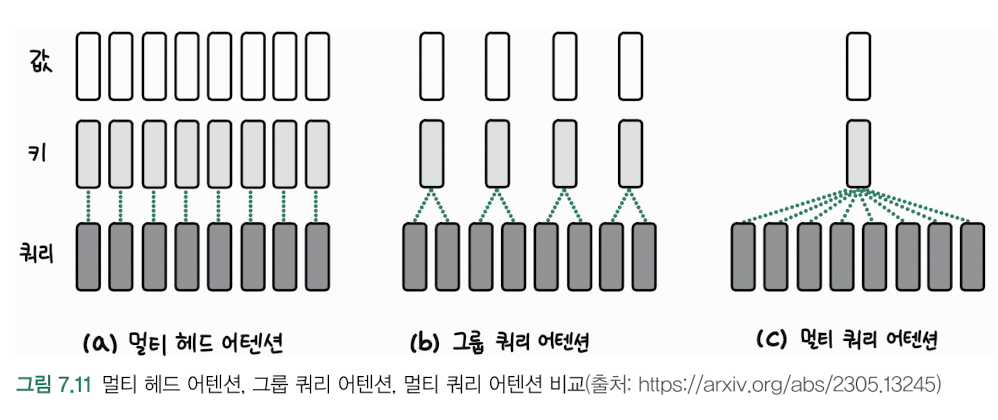
멀티 쿼리 어텐션(MQA)특징:하나의 Key/Value 쌍을 여러 Query와 공유메모리 사용량과 계산 비용 감소기존 멀티헤드 어텐션보다 효율적장점:메모리 효율성 향상추론 속도 개선계산 비용 감소단점:성능이 약간 저하될 수 있음표현력이 일부 제한될 수 있음그룹 쿼리 어