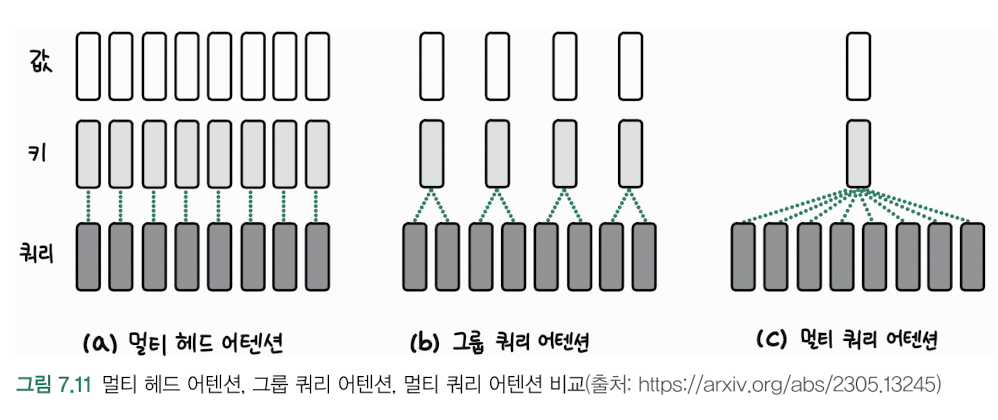
- 멀티 쿼리 어텐션(MQA)
-
특징:
- 하나의 Key/Value 쌍을 여러 Query와 공유
- 메모리 사용량과 계산 비용 감소
- 기존 멀티헤드 어텐션보다 효율적
-
장점:
- 메모리 효율성 향상
- 추론 속도 개선
- 계산 비용 감소
-
단점:
- 성능이 약간 저하될 수 있음
- 표현력이 일부 제한될 수 있음
- 그룹 쿼리 어텐션(GQA)
-
특징:
- MQA와 기존 멀티헤드 어텐션의 중간 형태
- Query를 그룹으로 나누어 Key/Value 쌍 공유
- 각 그룹이 독립적인 Key/Value 쌍 사용
-
장점:
- MQA보다 더 나은 성능
- 메모리 효율성과 성능의 균형
- 유연한 구현 가능
-
단점:
- MQA보다 더 많은 메모리 사용
- 구현이 약간 더 복잡
- 비교
MHA(Multi-Head Attention) > GQA > MQA
- 성능: MHA > GQA > MQA
- 메모리 효율성: MQA > GQA > MHA
- 추론 속도: MQA > GQA > MHA
- 활용
- 대규모 언어 모델
- 트랜스포머 기반 모델
- 효율적인 AI 시스템
- 구현 예시 (의사 코드):
# MQA
def multi_query_attention(query, key, value):
# 하나의 key/value 쌍을 여러 query와 공유
attention_scores = dot_product(query, key)
attention_weights = softmax(attention_scores)
output = dot_product(attention_weights, value)
return output
# GQA
def grouped_query_attention(query, key, value, num_groups):
# query를 그룹으로 나누어 처리
query_groups = split_into_groups(query, num_groups)
outputs = []
for group in query_groups:
attention_scores = dot_product(group, key)
attention_weights = softmax(attention_scores)
output = dot_product(attention_weights, value)
outputs.append(output)
return concatenate(outputs)- 최신 트렌드
- LLM에서 널리 사용
- 효율성 개선 연구 지속
- 하이브리드 접근법 개발
이러한 어텐션 메커니즘들은 모델의 효율성과 성능 사이의 균형을 맞추는 데 중요한 역할을 합니다.
멀티 쿼리 어텐션(MQA)과 그룹 쿼리 어텐션(GQA)은 주로 인퍼런스(추론) 단계에서 사용됩니다.
- 인퍼런스 시 사용 이유
- 메모리 효율성 향상
- 추론 속도 개선
- 계산 비용 감소
- 실시간 응답 필요성
- 학습/파인튜닝 vs 인퍼런스
학습/파인튜닝:
- 일반적으로 표준 멀티헤드 어텐션(MHA) 사용
- 더 높은 표현력 필요
- 성능 최적화 중요
인퍼런스:
- MQA/GQA 사용
- 속도와 효율성 중시
- 리소스 최적화 중요
- 실제 적용 사례
- LLaMA 2: GQA 사용
- PaLM: MQA 사용
- Claude: GQA 변형 사용
- 변환 과정
# 학습된 MHA 모델을 MQA/GQA로 변환
def convert_to_mqa(mha_model):
# Key/Value 헤드 평균화
averaged_kv = average_heads(mha_model.kv_heads)
return MQAModel(
query_heads=mha_model.query_heads,
shared_kv=averaged_kv
)- 주요 고려사항
- 모델 크기
- 하드웨어 제약
- 응답 시간 요구사항
- 메모리 가용성
이러한 어텐션 메커니즘은 실제 서비스 배포 시 효율적인 추론을 위해 중요합니다.
그러나 학습/파인튜닝에도 MQA/GQA를 사용하는 경우가 있습니다.
- 처음부터 MQA/GQA로 학습
- LLaMA 2: 처음부터 GQA로 학습
- PaLM: MQA 구조로 학습
- Falcon: MQA 구조로 학습
- 사용 이유
- 메모리 효율적 학습 가능
- 더 큰 배치 사이즈 사용 가능
- 학습 비용 절감
- 일관된 아키텍처 유지
- 장단점
장점:
- 학습-추론 일관성
- 메모리 효율성
- 비용 효율성
단점:
- 일부 성능 저하 가능성
- 최적화 어려움
- 학습 안정성 이슈
- 선택 기준
- 가용 자원
- 모델 크기
- 성능 요구사항
- 비용 제약
따라서 상황과 요구사항에 따라 학습 단계에서도 MQA/GQA를 선택할 수 있습니다.

시리즈를 기반으로 작성하였습니다.