개요
쿠버네티스를 사용하는 중요한 이유 중 하나는 오토 스케일링을 간편하게 구현할 수 있기 때문이다.
트래픽이 급격하게 증가할 때는 컨테이너를 여러 개 더 실행해서 부하를 분산해주고, 평상시에는 적은 수의 컨테이너로 운영을 하는 것이 효율적이다.
이번 5주차 EKS 스터디에서는 AWS EKS 를 이용해서 오토 스케일링을 구현하는 방법을 다루었다.
스케일링(Scaling)
쿠버네티스의 오토 스케일링을 알아보기 전에 스케일링의 개념을 먼저 짚고 넘어가자.
스케일링은 크기를 조절한다는 의미이다.
서비스를 운영할 때는 크게 2가지 종류의 스케일링 기법을 사용한다.
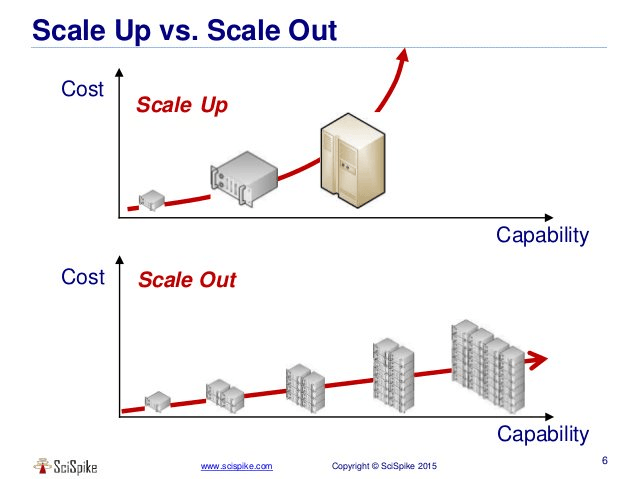
출처: 수직 확장(Scale up) vs 수평 확장(Scale out) [hudi.blog]
1. 스케일 업(Scale up)
스케일 업은 하나의 서버 컴퓨터의 성능을 더 좋은 부품으로 교체하는 것을 의미하며, 수직 확장으로 불린다.
서버 컴퓨터에 32GB 램을 사용하고 있었다면 64GB 램으로 교체하는 것이다.
장점
- 부품만 교체하면 성능을 개선할 수 있다.
- 서버 컴퓨터만 한 대만 관리하면 되기 때문에 여러 서버 컴퓨터를 관리하는 번거로움이 없다.
단점
- 부품의 성능이 높을 수록 지불해야 하는 비용이 높아진다.
- 트래픽이 몰리지 않는 상황에서는 좋은 성능의 부품을 100% 활용하지 못한다.
- 단일 장애점을 갖기 때문에 부품을 교체할 때 서비스를 운영할 수 없는 다운타임이 존재한다.
2. 스케일 아웃(Scale out)
스케일 아웃은 비슷한 성능의 서버 컴퓨터를 추가로 설치하는 것이며, 수평 확장으로 불린다.
즉, 하나의 서버 컴퓨터가 처리하던 일을 여러 서버 컴퓨터가 처리하도록 하는 것이다.
트래픽을 분산하기 위해 설치한 컴퓨터를 더 이상 사용하지 않는다면 제거하면 되는데, 이를 스케일 인(Scale in)이라 한다.
장점
- 수직 확장보다 적은 비용이 든다.
- 수직 확장보다 유연하게 조절이 가능하다.
- 단일 장애점이 없기 때문에 확장을 하거나 줄일 때 다운타임 없이 서비스를 운영할 수 있다.
단점
- 여러 서버를 하나의 서버처럼 사용하기 위한 클러스터링 작업이 필요하다. (로드 밸런서 설치 등)
- 기술적으로나 관리의 난이도가 수직 확장에 비해 높다.
- 여러 서버들이 네트워크로 연결되어 있기 때문에 네트워크 상황에 따라 원하는 성능을 얻지 못할 수도 있다.
쿠버네티스 오토 스케일링
앞서 살펴본 것처럼 스케일링은 사람이 직접 서버 컴퓨터의 부품을 교체하거나(수직 확장), 새로운 컴퓨터를 설치하는(수평 확장) 번거로움이 존재한다.
이러한 번거로움을 없애기 위해 쿠버네티스는 파드를 이용해서 수직 확장과 수평 확장을 알아서 해주는 오토 스케일링 기능을 지원한다.
쿠버네티스에서는 파드마다 CPU, RAM 을 최대로 사용할 수 있는 제한을 걸 수 있다는 특징이 있는데, 이를 이용해서 오토 스케일링을 구현한 것이다.
AWS EKS 에서 사용할 수 있는 오토 스케일링의 종류는 크게 3가지가 있다.

출처: Was ist (Kubernetes) Autoscaling? VPA vs. HPA [kreyman]
1. HPA(Horizontal Pod Autoscaling)
파드 수평 확장(HPA; Horizontal Pod Autoscaling)은 동일한 성능을 가진 파드를 여러 개 실행하는 것이다.
2. VPA(Vertical Pod Autoscaling)
파드 수직 확장(VPA; Vertical Pod Autoscaling)은 기존에 실행하던 파드 대신 성능이 높은 파드를 실행하고, 기존에 실행하던 파드는 종료하는 것이다.
3. CA(Cluster Autoscaling)
클러스터 오토 스케일링은 실행 중인 노드(EC2 인스턴스)를 추가하는 것이다.
HPA, VPA 는 물리 서버 컴퓨터를 추가하지 않고 실행 중이던 파드를 단순히 늘리거나 성능 제한을 높이는 식으로 구현했다면, CA 는 물리 서버 컴퓨터를 추가로 설치하는 것이 특징이다.

출처: Cluster Autoscaler 적용하기 [aws workshop studio]
현재 실행 중인 워커 노드에서 파드를 더 이상 실행할 수 없어서 pending 상태에 있는 파드가 있다면 새로운 워커 노드를 스케일 아웃한다.
AWS EKS 에서 클러스터 오토스케일링은 Auto Scaling Group 을 사용해서 이루어진다.
HPA 실습
1. 쿠버네티스 기본 HPA 실습
파드 배포
HPA 실습을 위해 덧셈 연산을 수행하는 파드를 실행하고자 아래의 yaml 파일을 이용했다.
# php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apacheresources.limits 는 파드에서 CPU 의 최대 500m(밀리코어)를 사용할 수 있다는 것이고, requests.cpu 는 최소 200m 를 요구한다는 것이다.
참고로 500m 는 0.5 CPU 를 의미하는데, 물리 CPU 의 1코어의 절반만 사용한다는 의미이다.
php-apache 이미지에서 실행하는 php 파일의 내용은 아래와 같이 for 문에서 100만번 덧셈을 수행한다.
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>즉, 아파치 웹 서버의 80번 포트로 접속할 때마다 100만번의 연산을 수행하게 되는 것이며, 이를 이용해서 CPU 에 부하를 줄 것이다.
HPA 적용
아래의 명령어를 이용해서 HPA 를 적용했다.
kubectl autoscale deployment php-apache \
--cpu-percent=50 \
--min=1 \
--max=10Deployment 로 배포한 php-apache 의 파드의 CPU 사용률이 50% 를 넘어가면 오토스케일링 한다.
파드는 최소 1개 유지되어야 하며, 최대 10개까지 생성할 수 있다.
즉, 파드에 할당된 최대 CPU 사용률의 50% 이상인 250m 를 넘어가면 자동으로 파드를 늘리는 것이다.
HPA 가 정상적으로 설정되었는지 확인하기 위해 아래의 명령어를 실행했다.
kubectl describe hpa실행 결과는 아래와 같다.
Name: php-apache
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 03 Apr 2024 21:34:45 +0900
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable rangeHPA 설정을 확인하기 위해 아래의 명령어를 사용할 수 있다.
kubectl get hpa php-apache -o yaml | kubectl neat | yh실행 결과는 아래와같다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache부하 발생
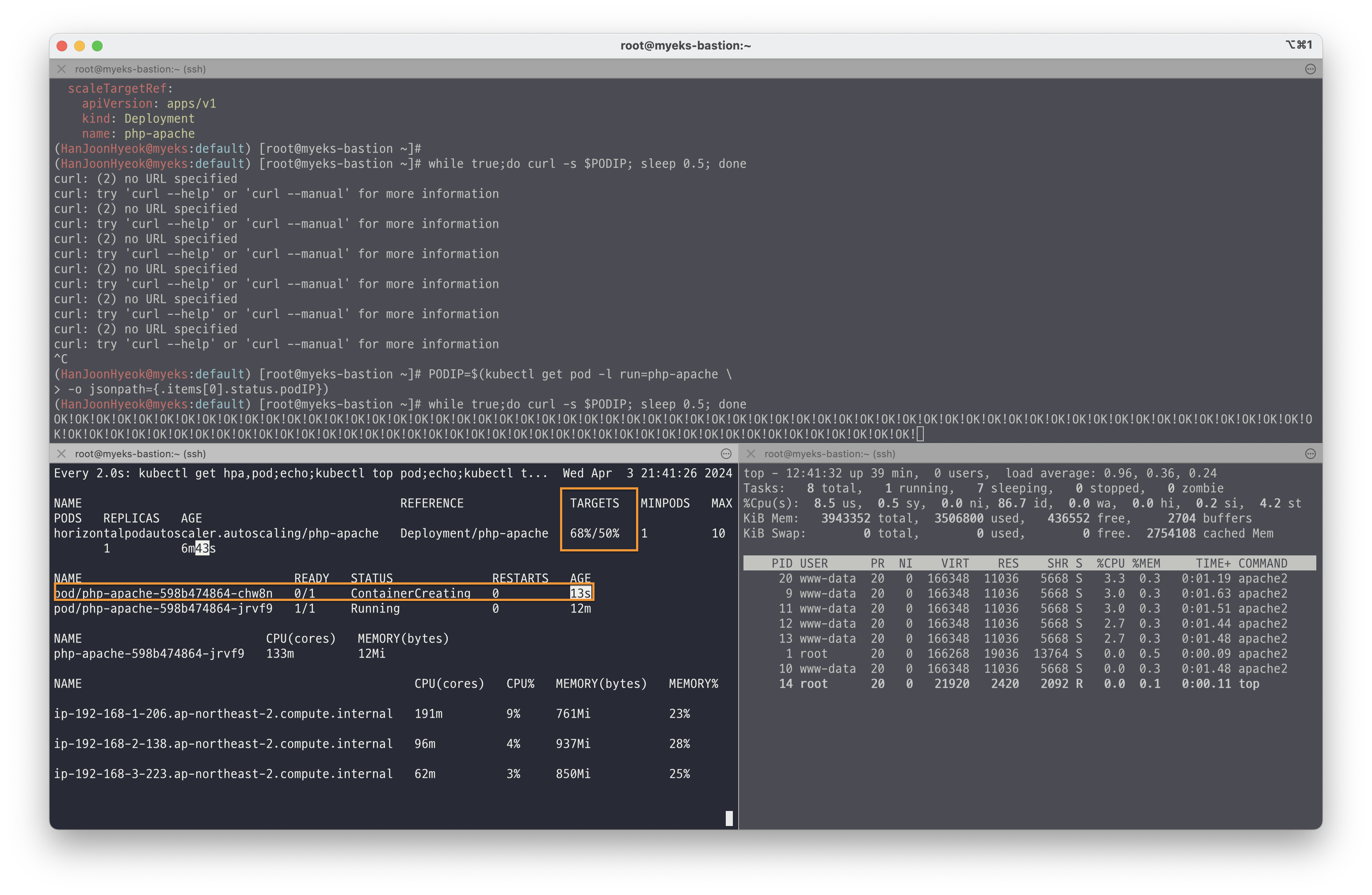
아래의 명령어를 이용해서 파드의 IP 를 알아냈다.
PODIP=$(kubectl get pod -l run=php-apache \
-o jsonpath={.items[0].status.podIP})그 다음 0.5초 간격으로 접속을 시도해서 부하를 주었다.
while true;do curl -s $PODIP; sleep 0.5; done아래의 이미지와 같이 CPU 사용률이 50% 넘어가면 파드가 새롭게 생성되는 것을 확인할 수 있다.
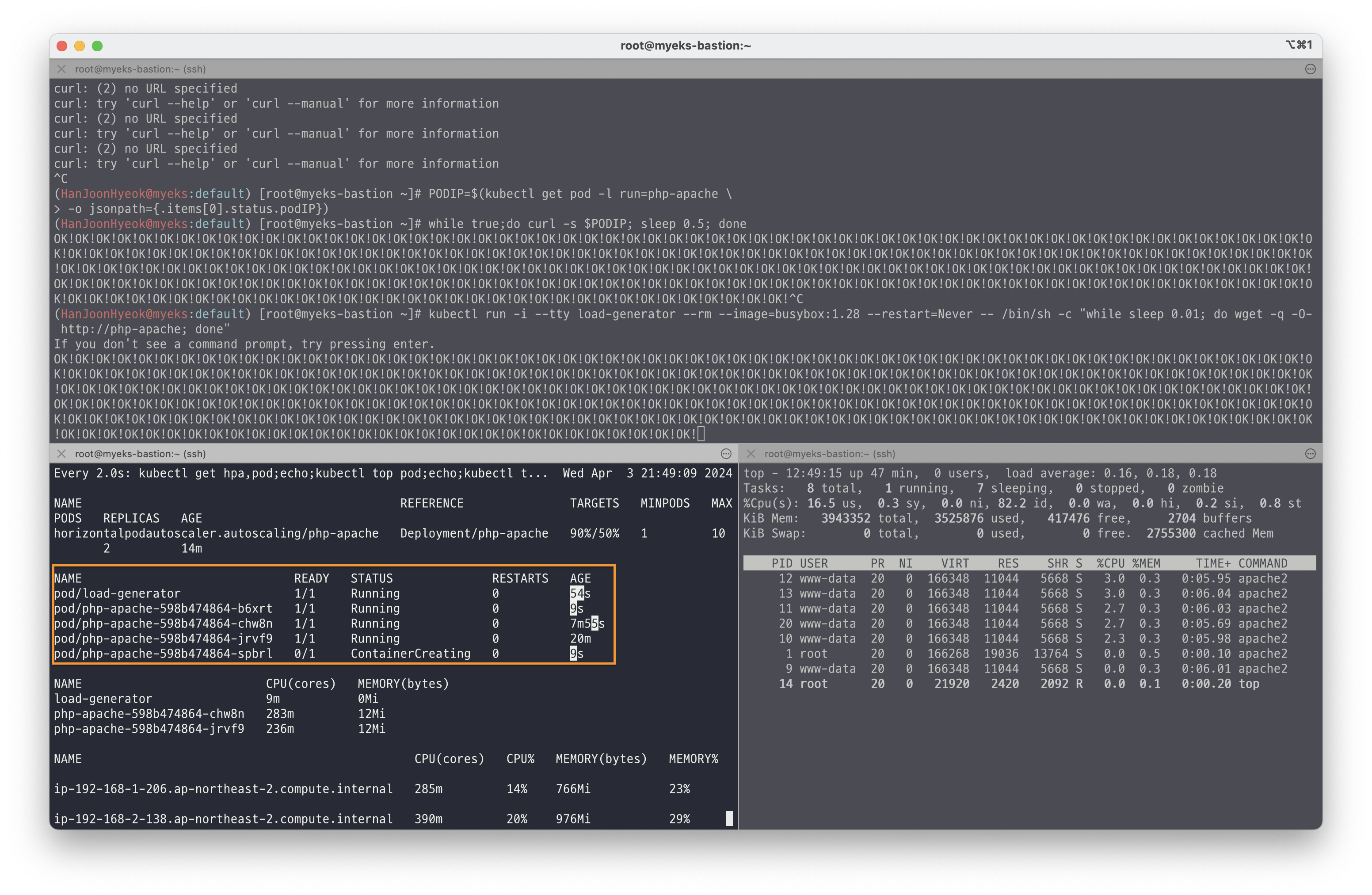
위에서는 파드 1개에 대해서만 부하를 주었지만, 여러 파드에 동시에 부하를 주기 위해 아래의 명령어를 실행했다.
kubectl run -i --tty load-generator \
--rm \
--image=busybox:1.28 \
--restart=Never \
-- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"load-generator 라는 이름을 가진 파드는 busybox 이미지에서 0.01초 간격으로 서비스 도메인명으로 접속한다.
아래의 이미지와 같이 파드가 더욱 많이 생성되는 것을 확인할 수 있다.
HPA 는 스케일 아웃(증가)할 때는 기본 대기 시간이 30초이며, 스케일 인(감소)할 때는 기본 대기 시간이 5분이다. 간격은 조정 가능하다.
그라파나에서도 HPA 로 인한 파드의 변화 개수를 추적할 수 있는데, 아래의 이미지와 같이 파드가 증가했다가 감소하는 그래프의 흐름을 확인할 수 있다.
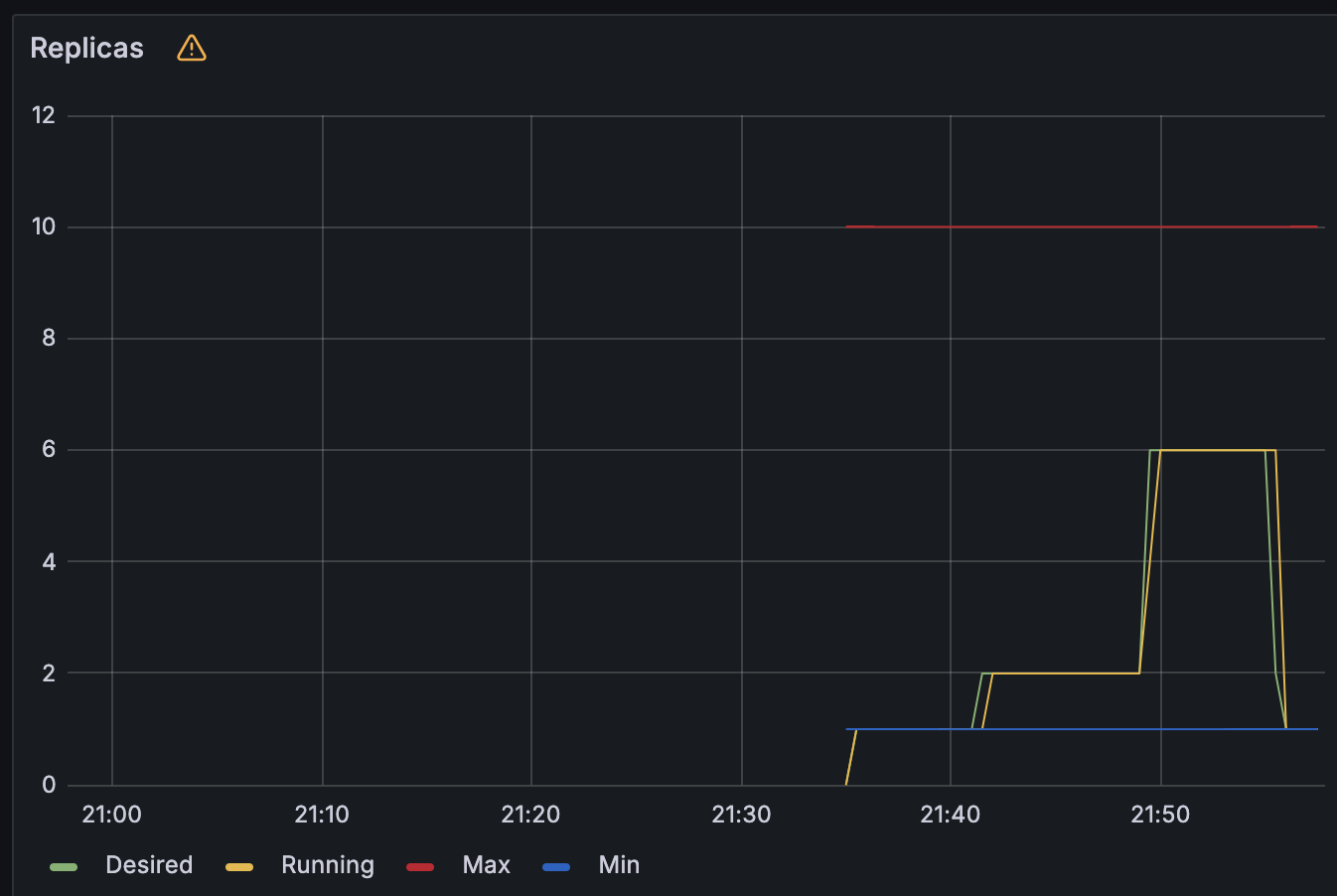
아래의 명령어를 이용해서 실습을 위해 사용한 자원들을 모두 삭제했다.
kubectl delete deploy,svc,hpa,pod --all2. KEDA
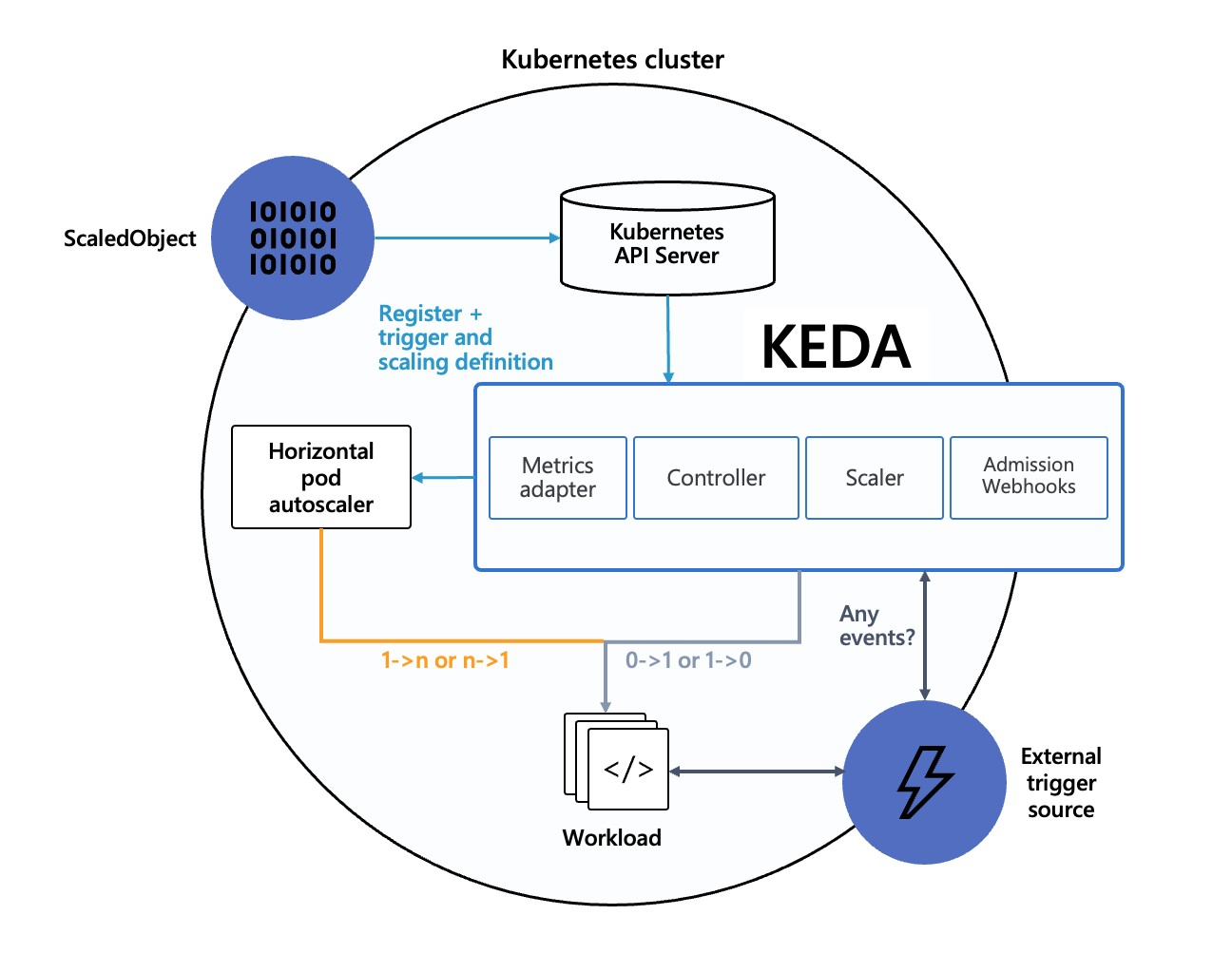
출처: KEDA Concepts [keda]
KEDA(Kubernetes-based Event Driven Autoscaler)는 HPA 의 한계를 보완하기 위해 등장한 컴포넌트다.
쿠버네티스의 기본 HPA 는 CPU, RAM 을 기준으로만 수행하는데, 서비스를 운영하다보면 다양한 메트릭을 기준으로 오토 스케일링을 해야 하는 경우가 생긴다.
그래서 KEDA 는 다른 서비스의 메트릭을 수집해서 HPA 를 수행할 수 있도록 지원한다.
메트릭 수집을 지원하는 서비스로는 Kafka, Redis, MySQL, Prometheus 등 다양하게 지원하고 있다.
KEDA 는 HPA 를 직접 수행하지는 않으며, 아래의 3가지 역할을 수행한다.
- Agent: 이벤트의 유무에 따라 애플리케이션의 Deployment 를 활성화/비활성화 하도록 한다. 이는
keda-operator컨테이너가 수행한다. - Metrics: KEDA 에는 KEDA 전용 metrics server 가 존재한다. 다양한 서비스의 이벤트를 수집해서 HPA 가 메트릭을 수집할 수 있도록 돕는다.
keda-operator-metrics-apiserver컨테이너가 이를 수행한다. - Admission Webhooks: KEDA 관련 자원들을 변경할 때 실수로 발생할 수 있는 오류를 자동으로 검증하는 역할을 수행한다. 예를 들면, 여러 ScaledObject 가 동일한 대상을 오토 스케일링 하지 않도록 방지하는 것이 있다. KEDA 에서는 오토 스케일링을 하고자 하는 대상(Deployment, ReplicaSet 등)을 지정하고, 오토 스케일링을 언제 수행할 지, 얼만큼 파드를 늘리거나 줄일 지 정의하기 위해 ScaledObject 에 정의한다. 만약 여러 ScaledObject 가 동일한 대상(Deployment)을 오토 스케일링 한다면, 여러 기준에 의해 오토 스케일링이 복합적으로 이루어지기 때문에 일관된 기준으로 오토 스케일링을 수행할 수 없게 된다.
KEDA 실습
helm 을 이용해서 설치하기 위해 아래의 yaml 파일을 생성했다.
cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOTkeda 네임스페이스 생성 후 helm 설치를 진행했다.
kubectl create namespace keda
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda --version 2.13.0 --namespace keda -f keda-values.yamlHPA 실습에서 사용했던 php-apache deployment 를 그대로 이용해서 keda 네임스페이스에 배포했다.
kubectl apply -f php-apache.yaml -n kedacron 의 이벤트를 기반으로 오토스케일링을 적용하기 위해 아래의 ScaledObject 를 생성했다.
cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2
pollingInterval: 30
cooldownPeriod: 300
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT이는 매 시간 0분, 15분, 30분, 45분마다 php-apache 를 실행하고, 매 시간 5분, 20분, 35분, 50분마다 php-apache 를 종료한다는 것이다.
즉, 매 시간 0~5분, 15~20분, 30~35분, 45~50분 사이에 php-apache 파드가 desiredReplicas 에 명시된 것처럼 1개만 실행되었다가 종료되는 것이다.
그 다음 keda 네임스페이스에 ScaledObject 를 배포했다.
kubectl apply -f keda-cron.yaml -n keda그라파나 대시보드를 통해 확인해보면 아래의 이미지와 같이 정해진 시간동안 파드 1개가 실행되었다가 종료되는 것을 확인할 수 있다.
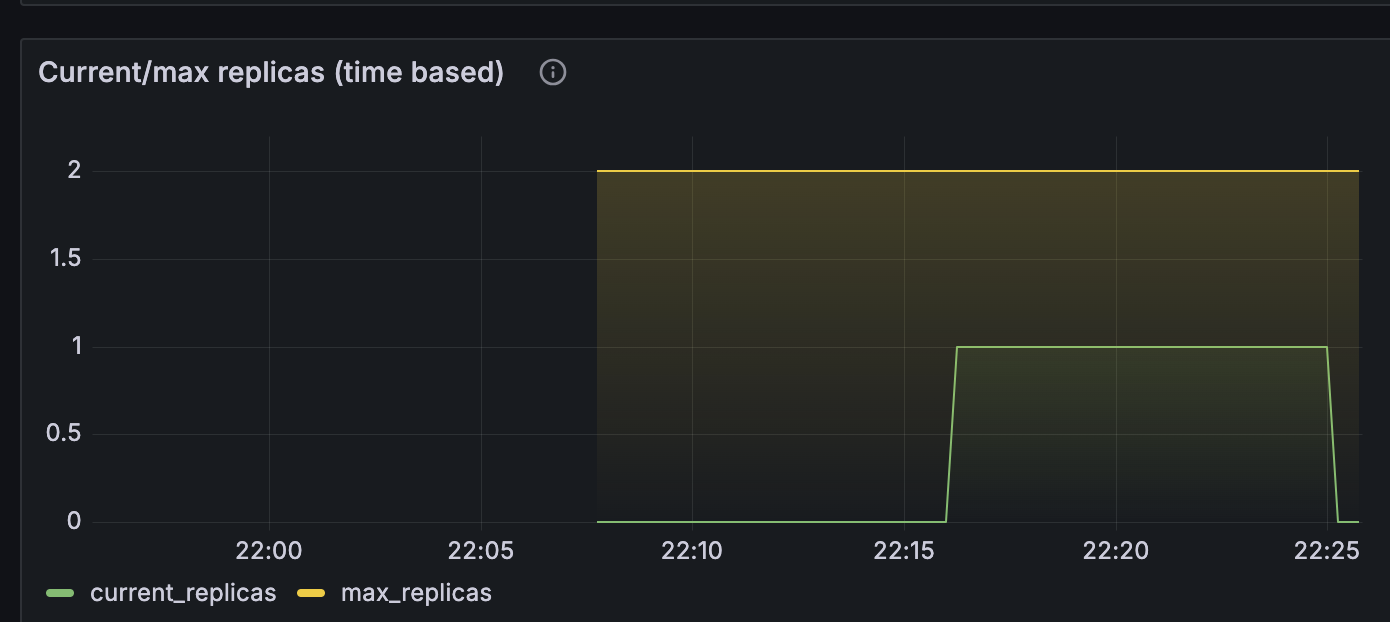
이유는 모르겠지만, 오토스케일링이 cron 에 명시한 시각에 정확히 이루어지지 않았다.
시작은 15분을 조금 넘겨서 바로 이루어졌지만, 종료는 25분이 되어서야 이루어진 모습을 확인할 수 있었다.
실습에서 사용한 자원을 삭제하기 위해 아래의 명령어를 실행했다.
kubectl delete -f keda-cron.yaml -n keda && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda
kubectl delete namespace keda3. CPA(Cluster Proportional Autoscaler)
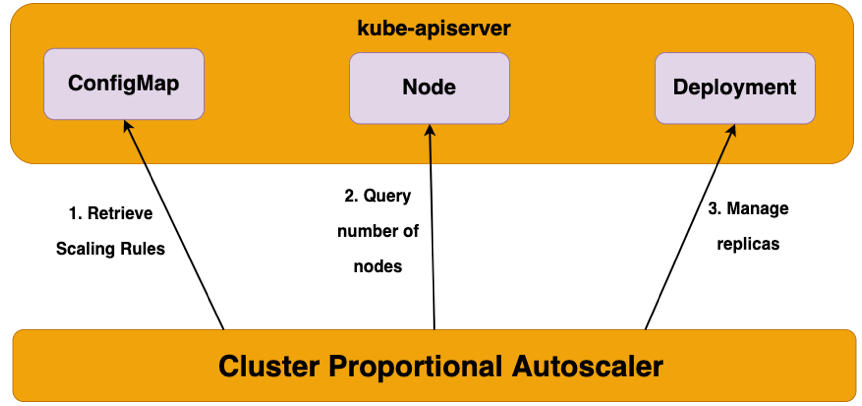
출처: Cluster Proportional Autoscaler [EKS Workshop]
CPA 는 HPA 와 CA 가 합쳐진 형태라고 생각할 수 있다.
클러스터에서 실행 중인 노드의 수에 비례해서 파드를 오토스케일링 한다.
즉, 노드의 수에 따라 특정 파드를 몇 개 실행할 것인지 정할 수 있다.
예를 들면, 노드 개수가 2개일 때는 CoreDNS 파드를 1개를, 노드 개수가 5개일 때는 CoreDNS 파드를 3개 실행하도록 설정할 수 있다.
CPA 는 Metrics server 와 같은 다른 컴포넌트가 아닌 오직 kube-apiserver 만 이용하기 때문에 의존성이 낮다는 특징이 있다.
CPA 실습
helm 을 이용해서 cluster proportional autoscaler 를 설치했다.
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
# CPA규칙을 설정하고 helm차트를 릴리즈 필요
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscalernginx deployment 를 생성하기 위해 아래와 같이 명령어를 실행했다.
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT위에서 생성한 파일을 아래의 명령어를 실행해서 배포했다.
kubectl apply -f cpa-nginx.yamlnginx deployment 를 CPA 로 오토스케일링 하기 위해 아래와 같은 명령어를 실행해서 yaml 파일을 생성했다.
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOFnginx deployment 를 오토스케일링 하는 기준을 config.ladder.nodesToReplicas 속성에 정의해놓은 것을 확인할 수 있다.
노드가 1개일 때는 1개를, 노드가 2개일 때는 2개를, 노드가 3~4개일 때는 3개를, 노드가 5개일 때는 5개를 배포하도록 설정한 것이다.
아래의 명령어를 이용해서 CPA 규칙을 새롭게 적용했다.
helm upgrade --install cluster-proportional-autoscaler \
-f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler오토스케일링이 적용되는지 확인하기 위해 아래의 명령어를 실행해서 노드를 5개로 증가시켰다.
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 5 \
--desired-capacity 5 \
--max-size 5아래의 이미지와 같이 노드가 5개로 증가하면 deployment 도 함께 5개로 증가한 것을 확인할 수 있다.
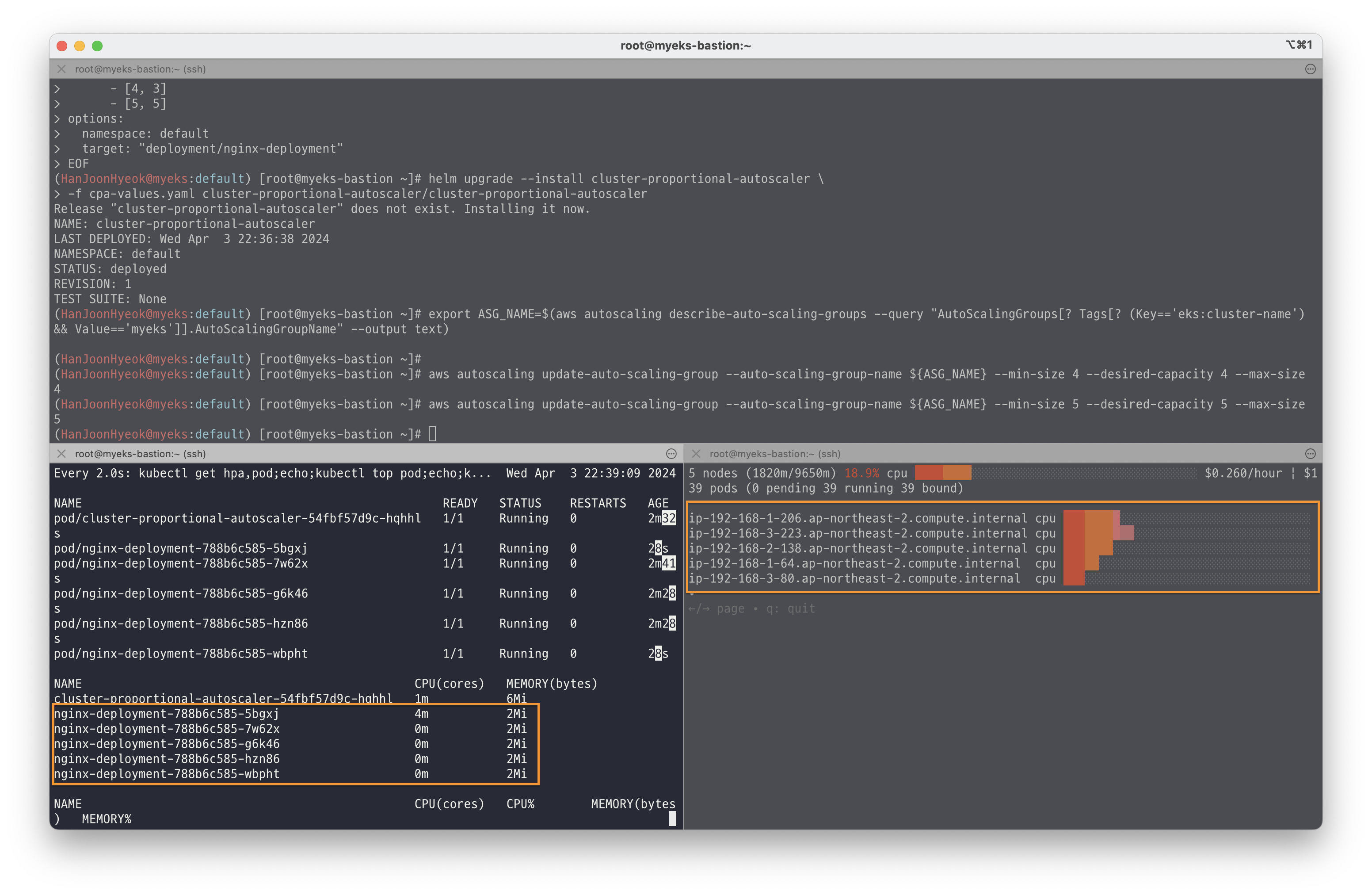
그리고 아래의 명령어를 실행해서 노드를 4개로 줄였다.
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 4 \
--desired-capacity 4 \
--max-size 4아래의 이미지와 같이 노드가 4개로 줄어서 nginx deployment 도 함께 3개로 줄어든 것을 확인할 수 있다.
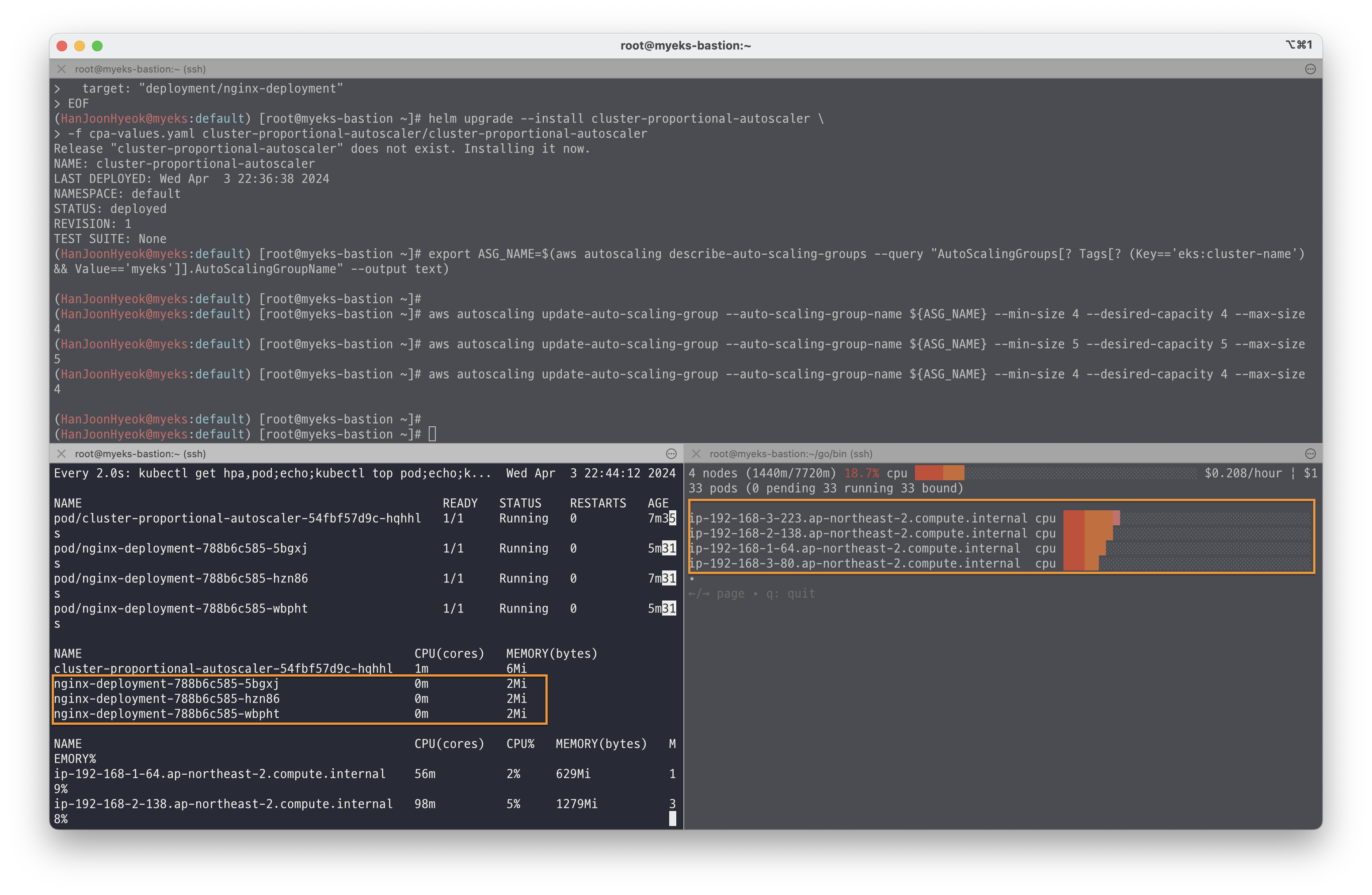
실습에서 사용한 자원을 삭제하기 위해 아래의 명령어를 실행했다.
helm uninstall cluster-proportional-autoscaler \
&& kubectl delete -f cpa-nginx.yamlVPA 실습
VPA 는 쿠버네티스 기본 VPA 를 기준으로 실습을 진행했다.
참고로 VPA 는 HPA 와 함께 사용할 수 없다.
그리고 VPA 를 수행할 때 파드를 최적값으로 수정하기 위해 기존에 실행하던 파드를 종료하고 새로운 파드를 실행한다.
VPA 설치
아래의 명령어를 실행해서 VPA 를 수행하기 위한 코드를 다운 받는다.
git clone https://github.com/kubernetes/autoscaler.gitVPA 는 openssl 1.1.1 이상 버전을 요구한다.
공식문서를 찾아봤지만 명확한 이유는 설명되어 있지 않았다.
다만, openssl 버전을 업데이트 하지 않으면 설치가 정상적으로 이루어지지 않았다.
아래의 명령어를 실행해서 openssl 1.1.1 이상 버전으로 업데이트 했다.
yum install openssl11 -yVPA 실행 스크립트에서 openssl 버전을 수정하기 위해 아래의 명령어를 실행했다.
sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.shVPA 활성화 스크립트를 실행하기 위해 아래의 명령어를 실행했다.
cd ~/autoscaler/vertical-pod-autoscaler/
./hack/vpa-up.sh배포
아래의 명령어를 실행해서 쿠버네티스에서 제공하는 공식 예제를 배포했다.
cd ~/autoscaler/vertical-pod-autoscaler/
cat examples/hamster.yaml | yh
kubectl apply -f examples/hamster.yaml && kubectl get vpa -whamster.yaml 파일은 아래와 같이 작성되어 있다.
# This config creates a deployment with two pods, each requesting 100 millicores
# and trying to utilize slightly above 500 millicores (repeatedly using CPU for
# 0.5s and sleeping 0.5s).
# It also creates a corresponding Vertical Pod Autoscaler that adjusts the
# requests.
# Note that the update mode is left unset, so it defaults to "Auto" mode.
---
apiVersion: "autoscaling.k8s.io/v1"
kind: VerticalPodAutoscaler
metadata:
name: hamster-vpa
spec:
# recommenders field can be unset when using the default recommender.
# When using an alternative recommender, the alternative recommender's name
# can be specified as the following in a list.
# recommenders:
# - name: 'alternative'
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: hamster
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hamster
spec:
selector:
matchLabels:
app: hamster
replicas: 2
template:
metadata:
labels:
app: hamster
spec:
securityContext:
runAsNonRoot: true
runAsUser: 65534 # nobody
containers:
- name: hamster
image: registry.k8s.io/ubuntu-slim:0.1
resources:
requests:
cpu: 100m
memory: 50Mi
command: ["/bin/sh"]
args:
- "-c"
- "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done"0.5초마다 yes 명령어를 실행해서 ‘yes’ 라는 문자열을 출력한 다음, 0.5초 잠시 대기하는 과정을 반복해서 파드에 부하를 준다. (햄스터가 빠르게 쳇바퀴 도는 것을 비유해서 파일 이름도 hamster 로 지은 것 같다.)
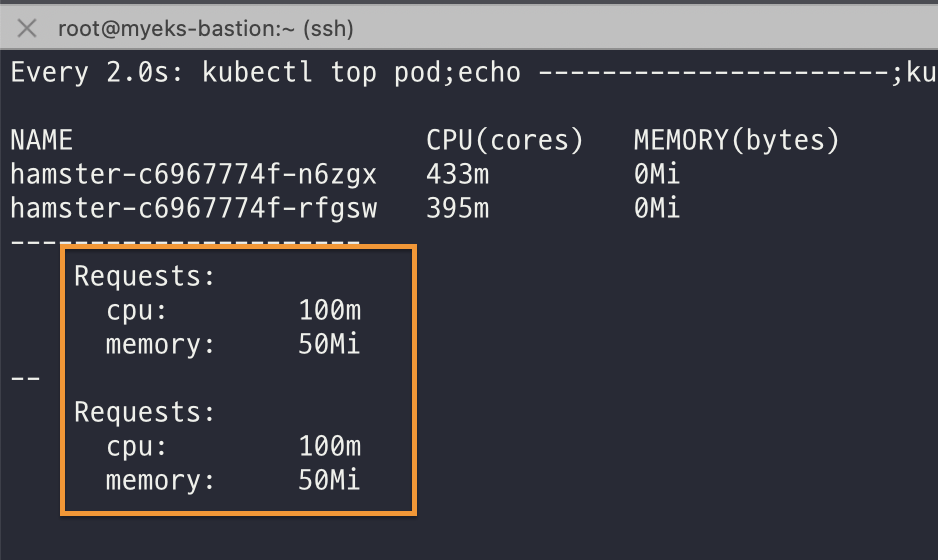
파드는 총 2개를 실행하며, 파드에는 최소 CPU 는 100m, RAM 은 50MB 를 요구한다.
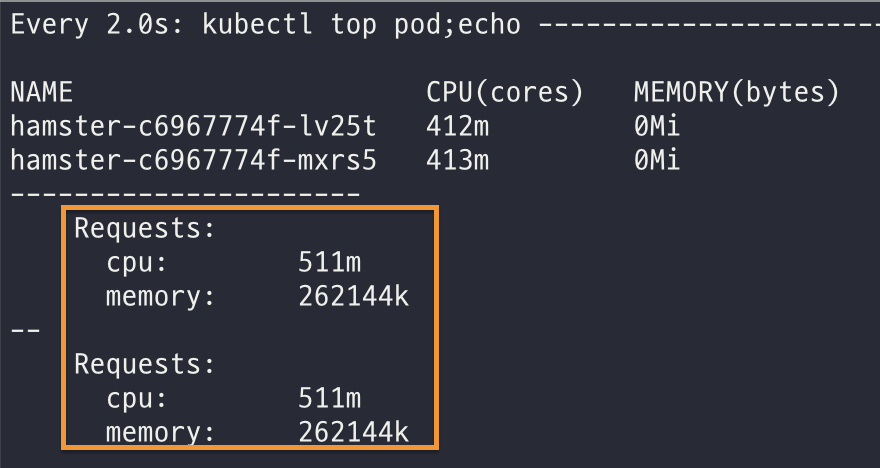
부하가 걸릴 때는 최대 CPU 1코어와 RAM 500MB 까지 사용할 수 있도록 수직 확장을 할 수 있지만, 수직 확장의 결과로 생성되는 파드의 자원 제한은 최적값 계산에 따라 달라질 수 있다.
아마 파드가 최근에 사용한 자원 사용량에서 여유값을 약간 추가해서 자원을 할당해주는 것 같다.
처음 배포하면 아래와 같이 파드의 CPU 제한은 100m, RAM 은 50MB 로 할당된 것을 확인할 수 있다.
시간이 지나 부하가 계속되면 파드 1개씩 수직 확장해서 파드의 CPU 제한이 500m, RAM 은 262MB(262144k) 로 증가하는 것을 확인할 수 있다.

실습에 사용한 자원을 삭제하기 위해 아래의 명령어를 실행했다.
kubectl delete -f examples/hamster.yaml \
&& cd ~/autoscaler/vertical-pod-autoscaler/ \
&& ./hack/vpa-down.shCA 실습
설치
우선 오토스케일링 노드 최대 개수를 6개로 늘려주었다.
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6아래의 명령어를 실행해서 CA 를 클러스터에 배포했다.
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml아래의 명령어를 실행해서 nginx deployment yaml 파일을 생성했다.
cat <<EoF> nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF파드의 CPU, RAM 사용량 최대 제한과 최소 요구치를 다소 높게 설정함으로써 파드가 늘어남에 따라 노드가 함께 늘어날 수 있도록 했다.
아래의 명령어를 실행해서 nginx 를 배포했다.
kubectl apply -f nginx.yaml그 다음 파드를 15개로 늘렸다.
kubectl scale --replicas=15 deployment/nginx-to-scaleout처음에는 파드를 배포할 수 있는 노드가 부족해서 일부 파드는 Pending 상태로 되어있는 것을 확인할 수 있다.
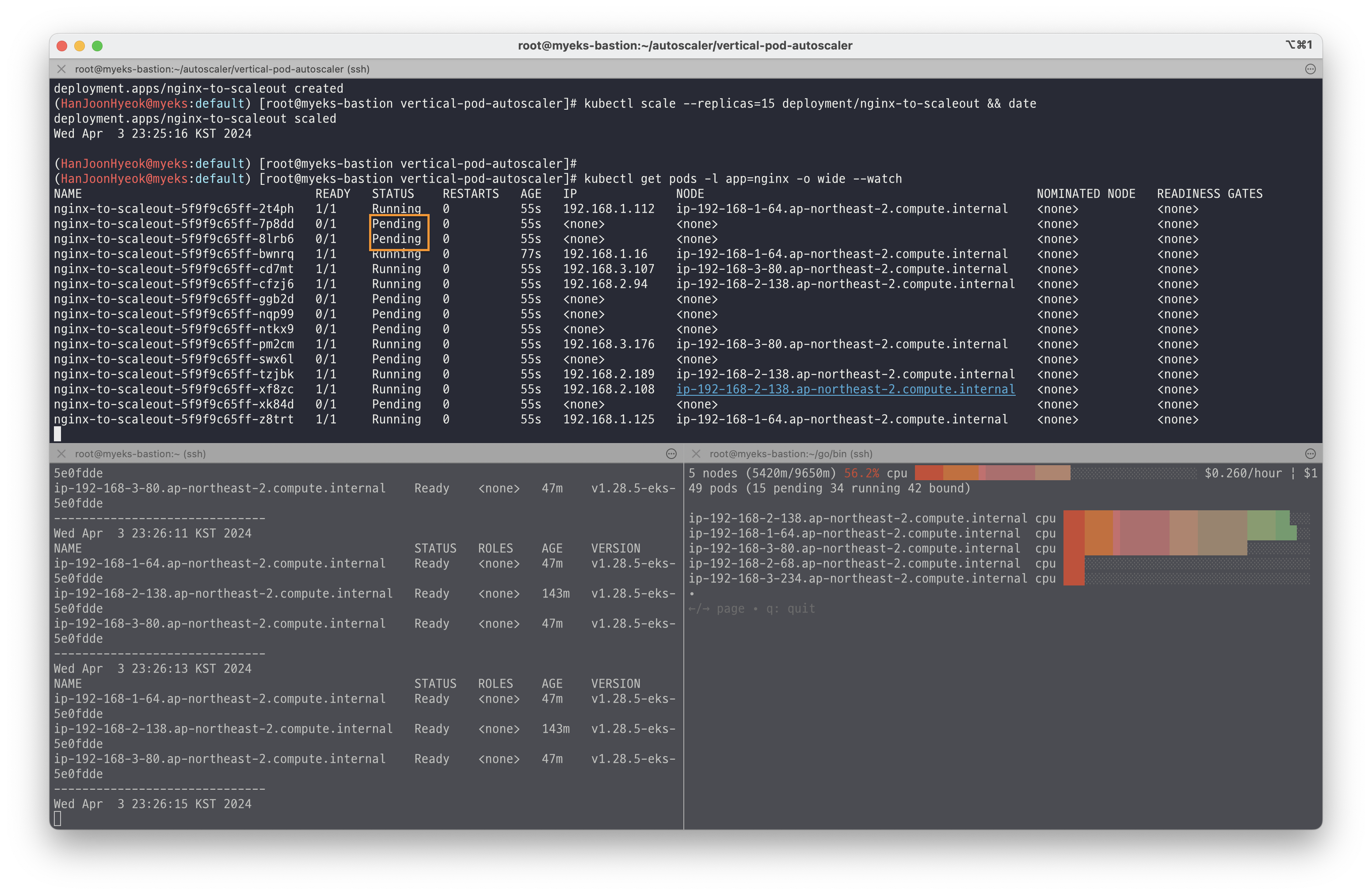
하지만 시간이 지나면서 노드가 총 6개까지 늘어났고, 이에 따라 Pending 상태였던 파드들이 정상적으로 배포되어 Running 상태로 변경된 것을 확인할 수 있다.
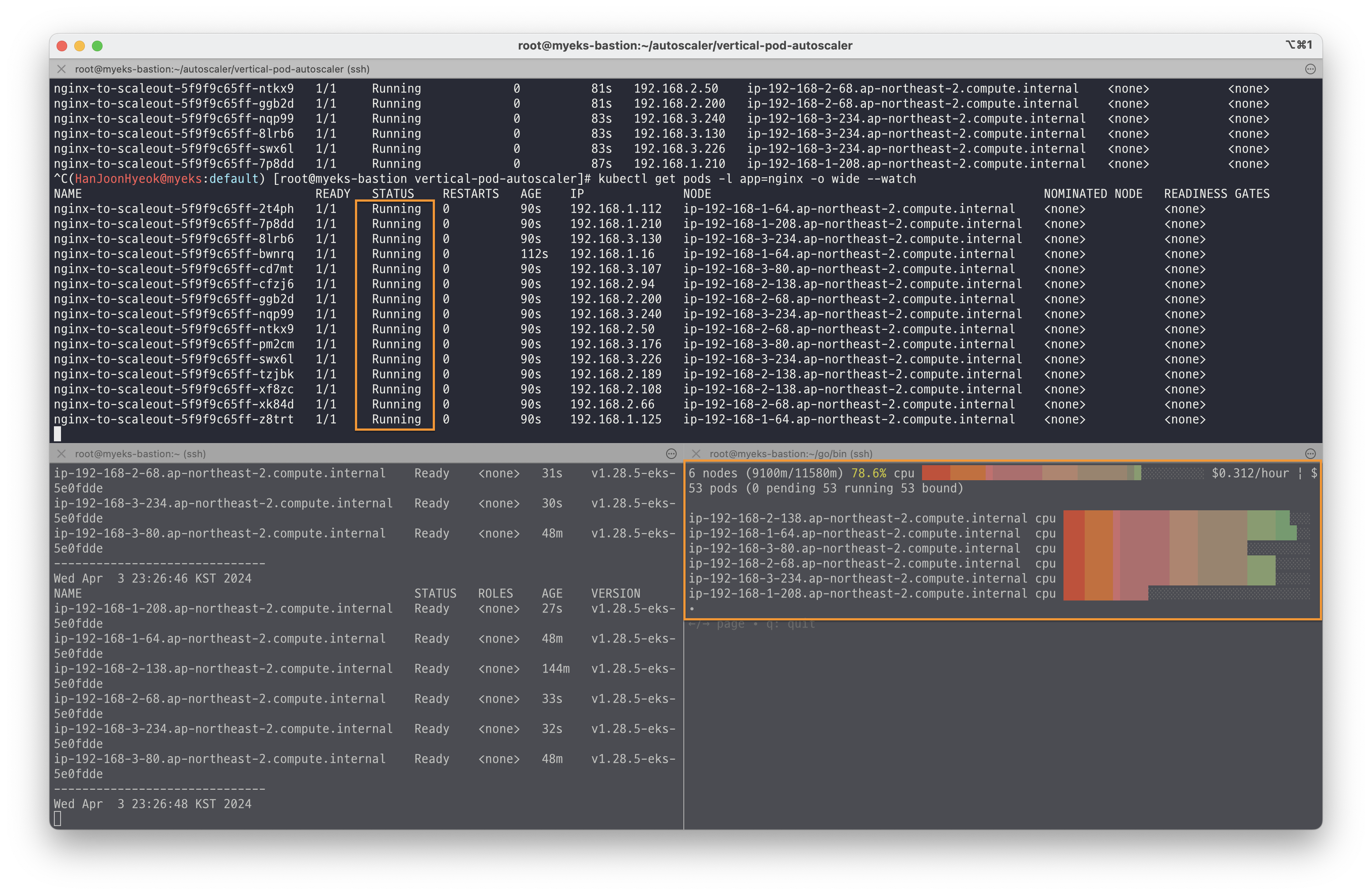
실습에 사용한 자원을 삭제하기 위해 아래의 명령어를 실행했다.
# deployment 삭제
kubectl delete -f nginx.yaml
# size 수정
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 3
# Cluster Autoscaler 삭제
kubectl delete -f cluster-autoscaler-autodiscover.yamlKarpenter
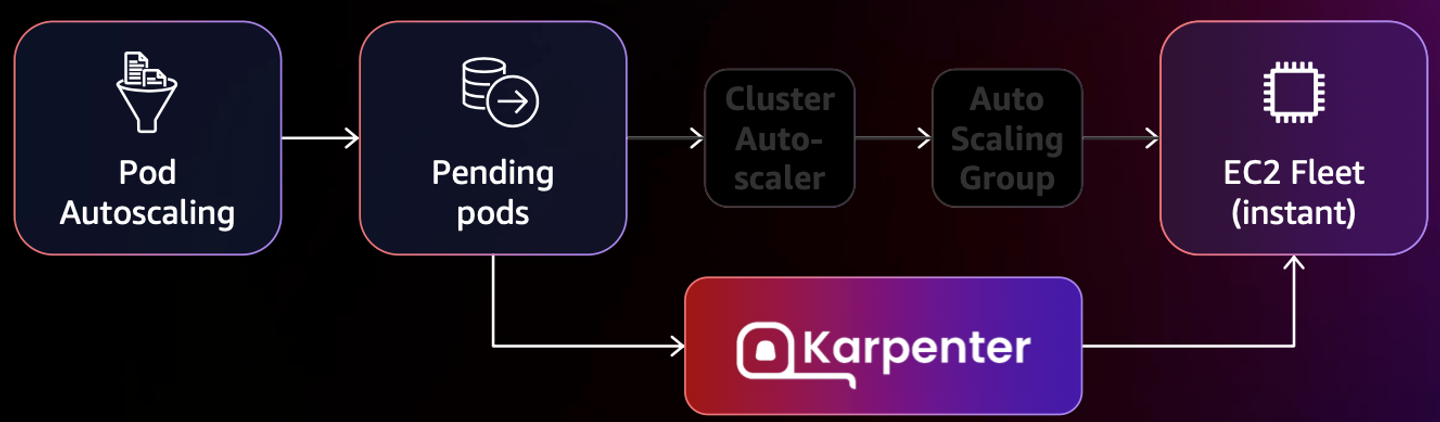
출처: Running efficient Kubernetes clusters on Amazon EC2 with Karpenter [aws summit]
Karpenter 는 AWS EKS 에 최적화해서 만든 오토스케일링 오픈소스 프로젝트다.
앞서 살펴본 CA(Cluster Autoscaler)는 AWS ASG 를 이용하는데, 문제는 AWS ASG 와 AWS EKS 가 노드(인스턴스) 대해 각자의 방식으로 관리하다보니 정보가 동기화 되지 않아 여러 문제가 발생한다.
- 스케일링 속도가 매우 느리다.
- EKS 에서 노드를 삭제해도 ASG 에서는 인스턴스가 삭제되지 않는다.
Karpenter 는 이러한 문제를 해결하기 위해 CA 와 ASG 에 의존하지 않고도 노드를 빠르게 오토스케일링 할 수 있다는 장점이 있다.
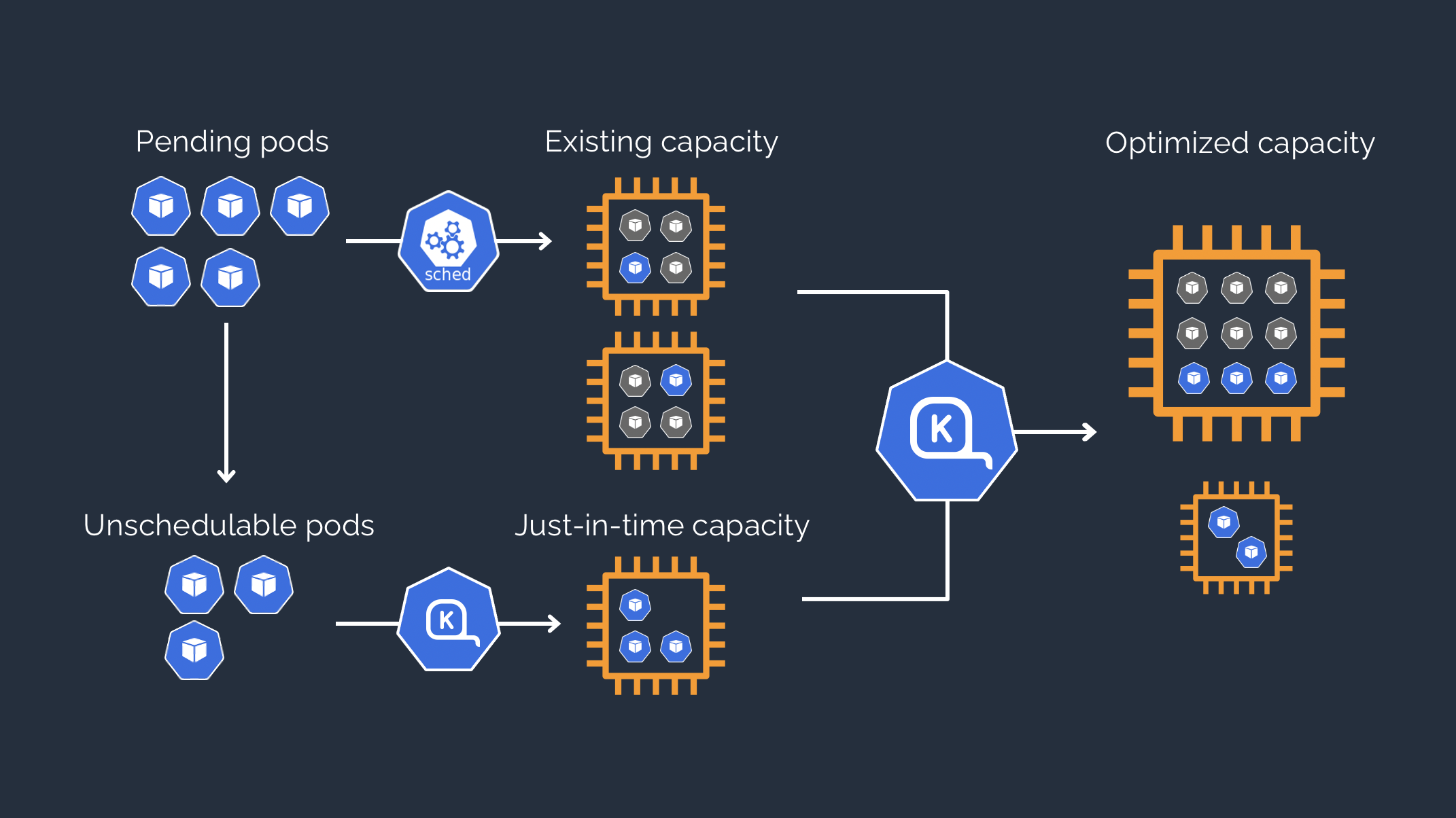
출처: karpenter [karpenter]
또한, 오토스케일링을 할 때 여러 노드를 하나로 합쳐서 사용하는 것이 더 낫다고 판단하면 비용을 최적화 할 수 있도록 돕는 기능이 있다.
아래의 영상을 참고하면 Karpenter 의 전반적인 내용에 대해 파악할 수 있다.
- 참고자료: [데브옵스] 오픈 소스 Karpenter를 활용한 Amazon EKS 확장 운영 전략 | 신재현, 무신사 [youtube]
실습
Karpenter 설치 및 EKS 환경 구성은 생략하고 Karpenter 사용법 위주로 정리했다.
NodePool 정의
Karpenter 는 NodePool 을 이용해서 어떤 종류의 인스턴스를 실행시킬 것인지 정의할 수 있다.
아래의 명령어를 실행해서 NodePool 과 EC2NodeClass 를 정의했다.
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 720h # 30 * 24h = 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2 # Amazon Linux 2
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- id: "${ARM_AMI_ID}"
- id: "${AMD_AMI_ID}"
# - id: "${GPU_AMI_ID}" # <- GPU Optimized AMD AMI
# - name: "amazon-eks-node-${K8S_VERSION}-*" # <- automatically upgrade when a new AL2 EKS Optimized AMI is released. This is unsafe for production workloads. Validate AMIs in lower environments before deploying them to production.
EOF인스턴스 패밀리로 c, m, r 을 선택할 수 있도록 했으며, 인스턴스 종류는 스팟 인스턴스를 사용하도록 설정했다.
배포
아래의 명령어를 실행해서 아무 것도 수행하지 않는 파드를 실행하는 Deployment 를 정의했다.
처음에는 아무 파드를 실행하지 않고, 파드의 수를 점차 올리면서 워커 노드가 어떻게 새롭게 오토스케일링 되는지 살펴볼 것이다.
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
EOF아래의 명령어를 실행해서 파드를 5개로 늘렸다.
kubectl scale deployment inflate --replicas 5스팟 인스턴스가 새롭게 생기면서 Pending 상태에 있던 파드들이 새로운 노드에 배치된다.
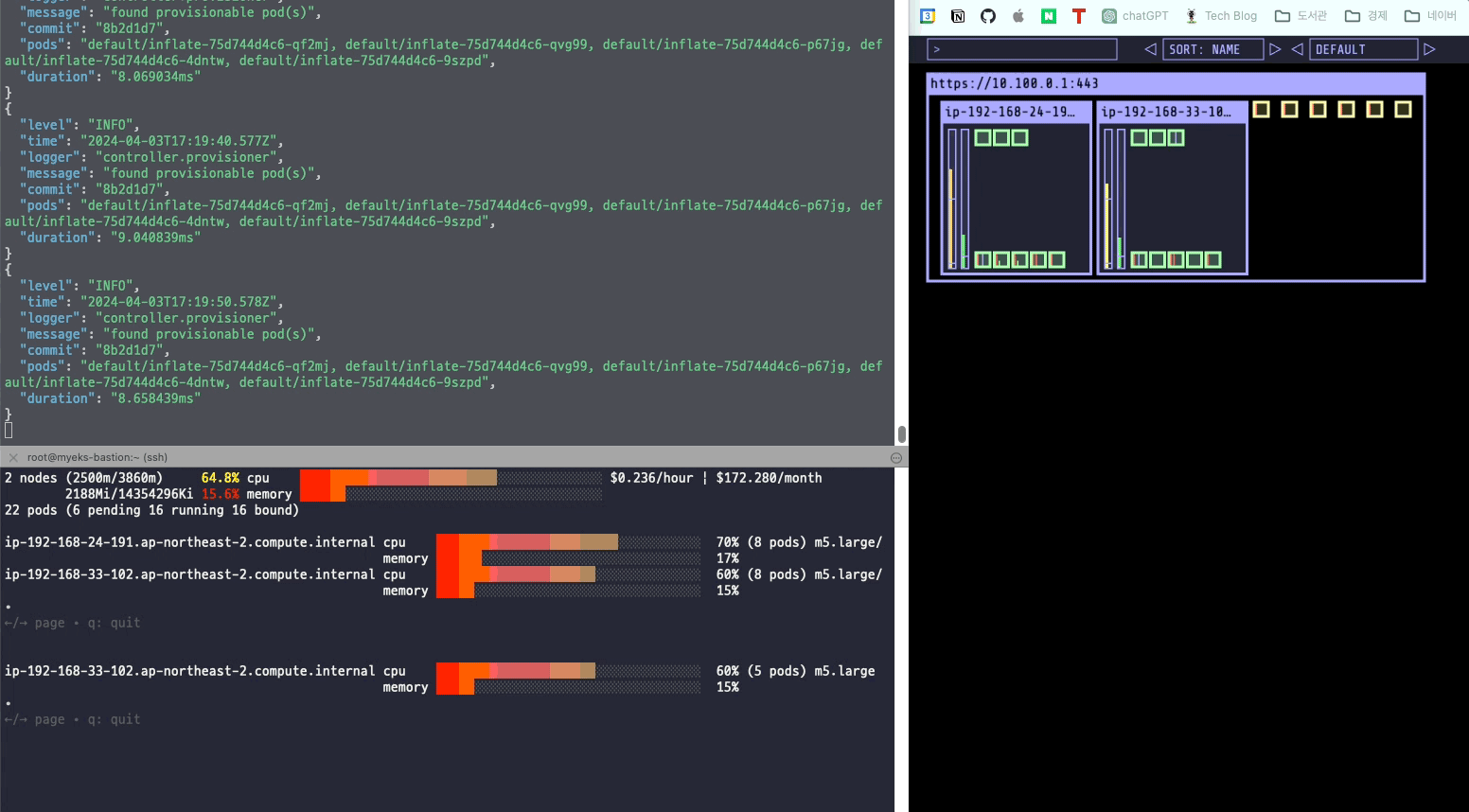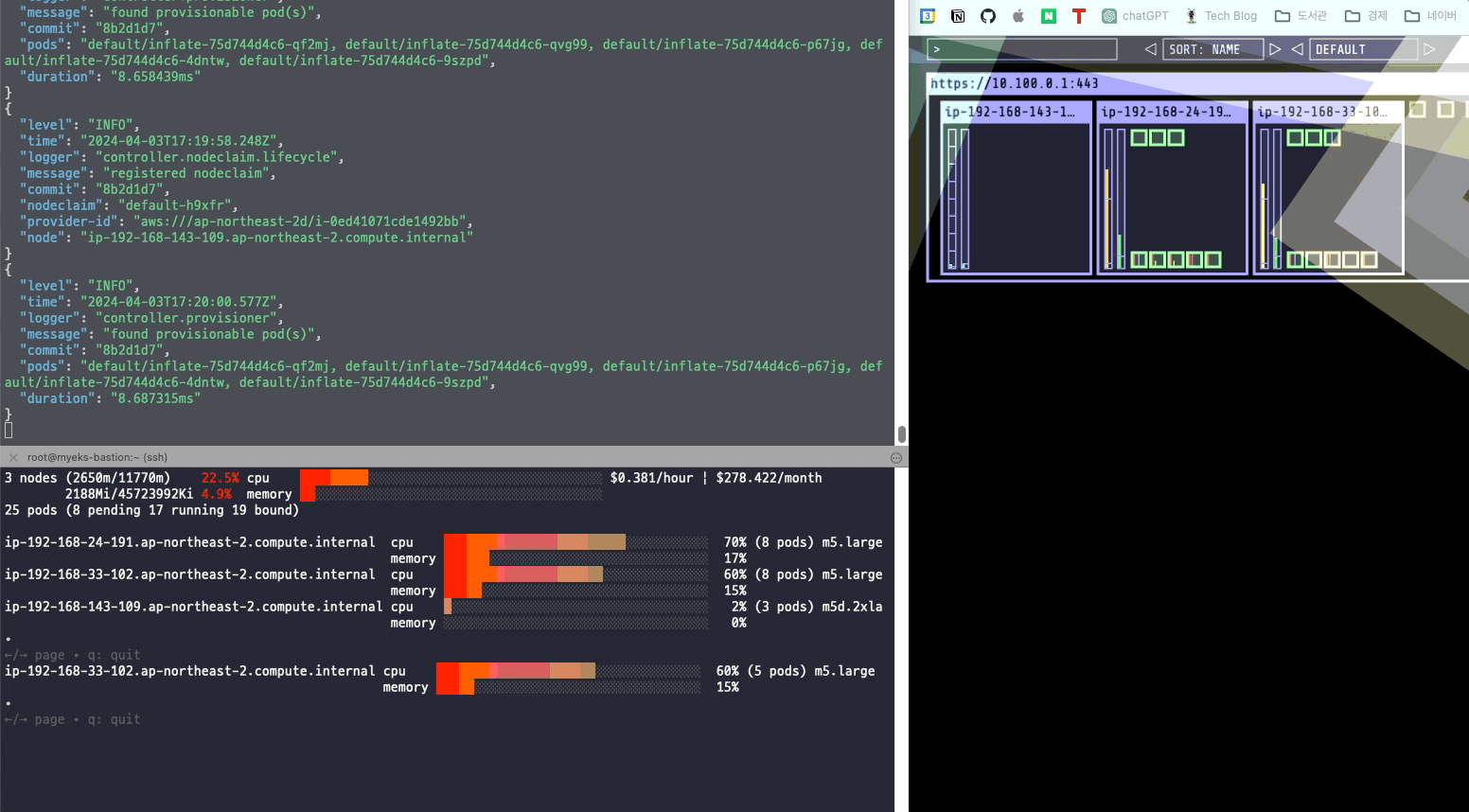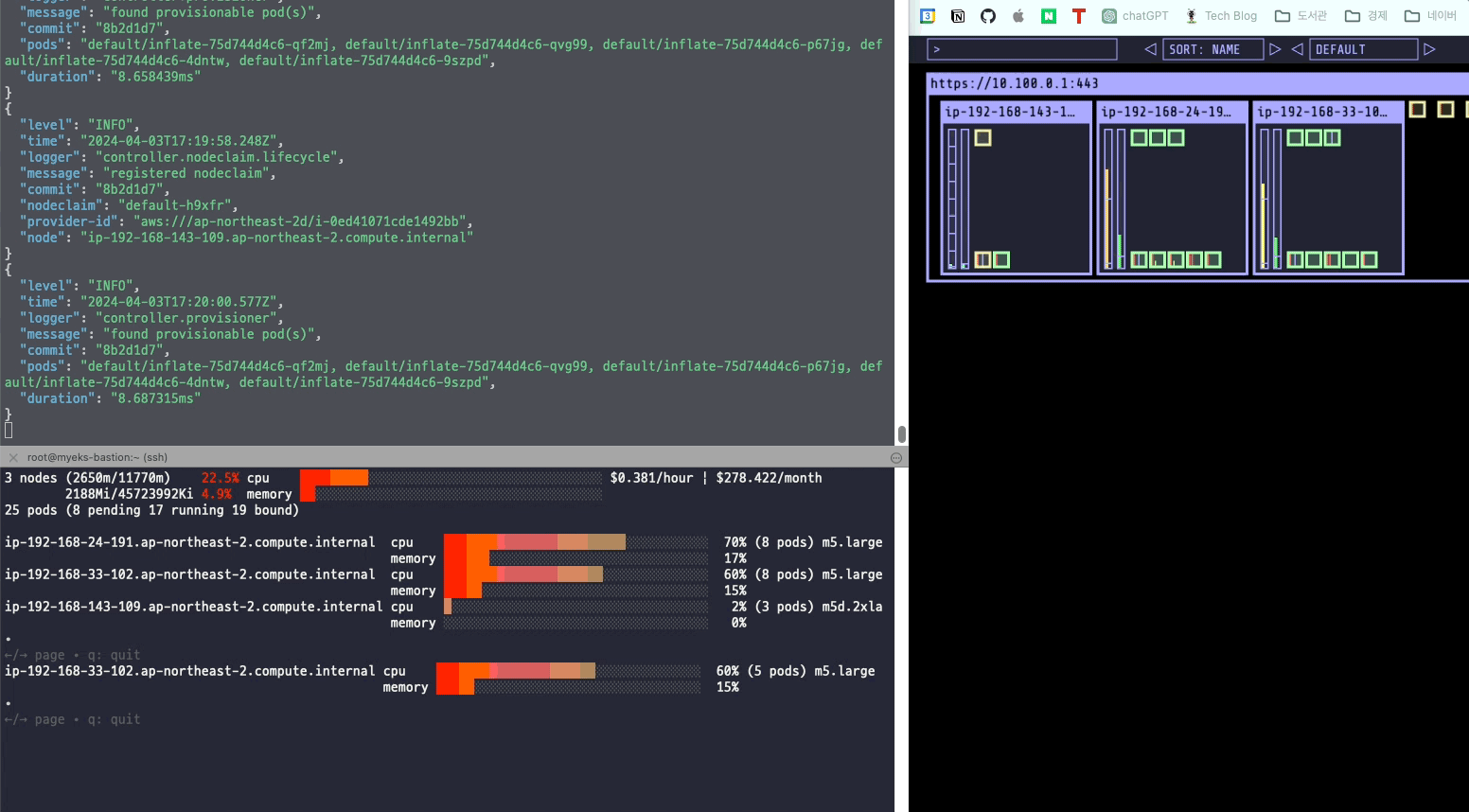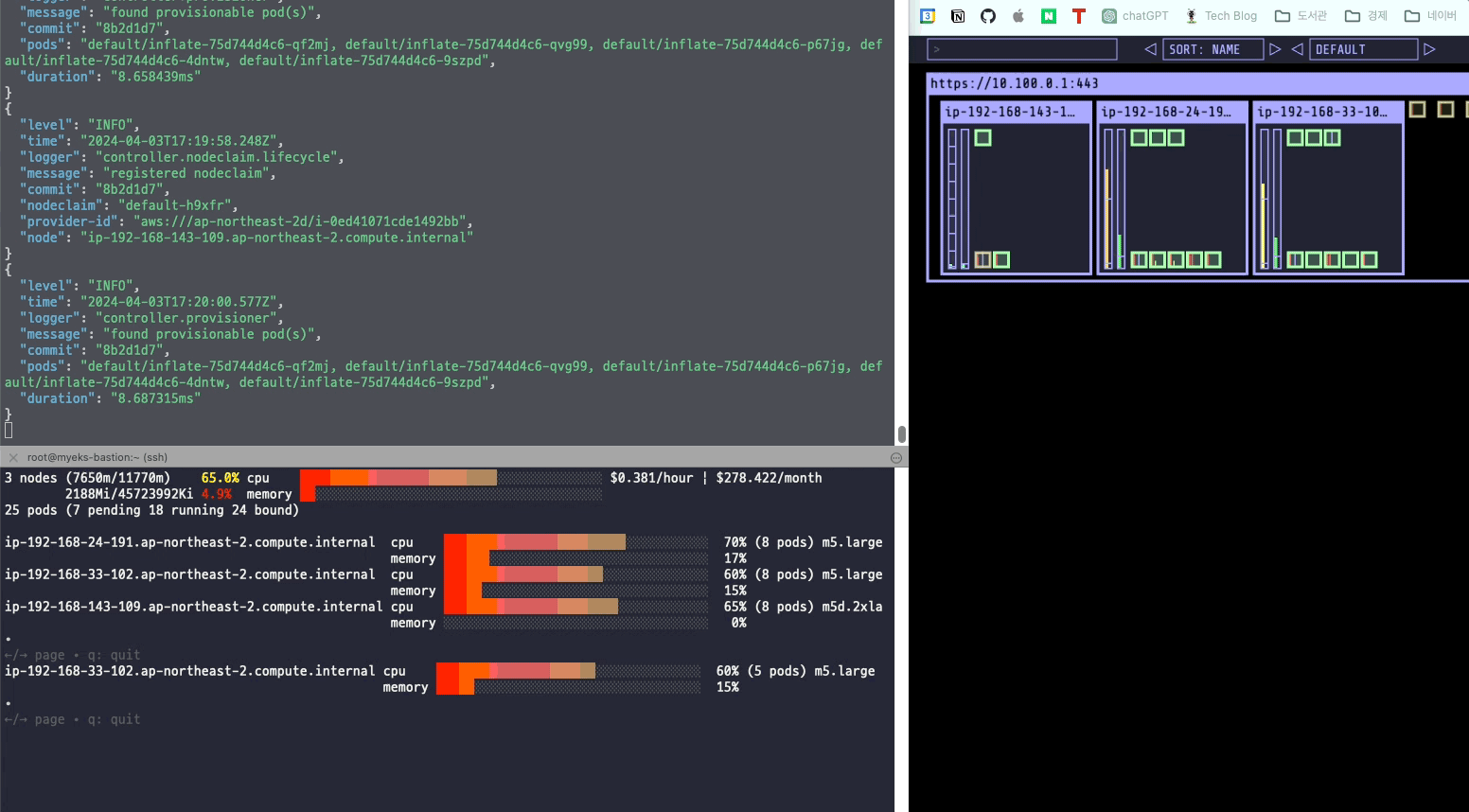
정상적으로 파드가 배치된 것을 확인할 수 있었다.
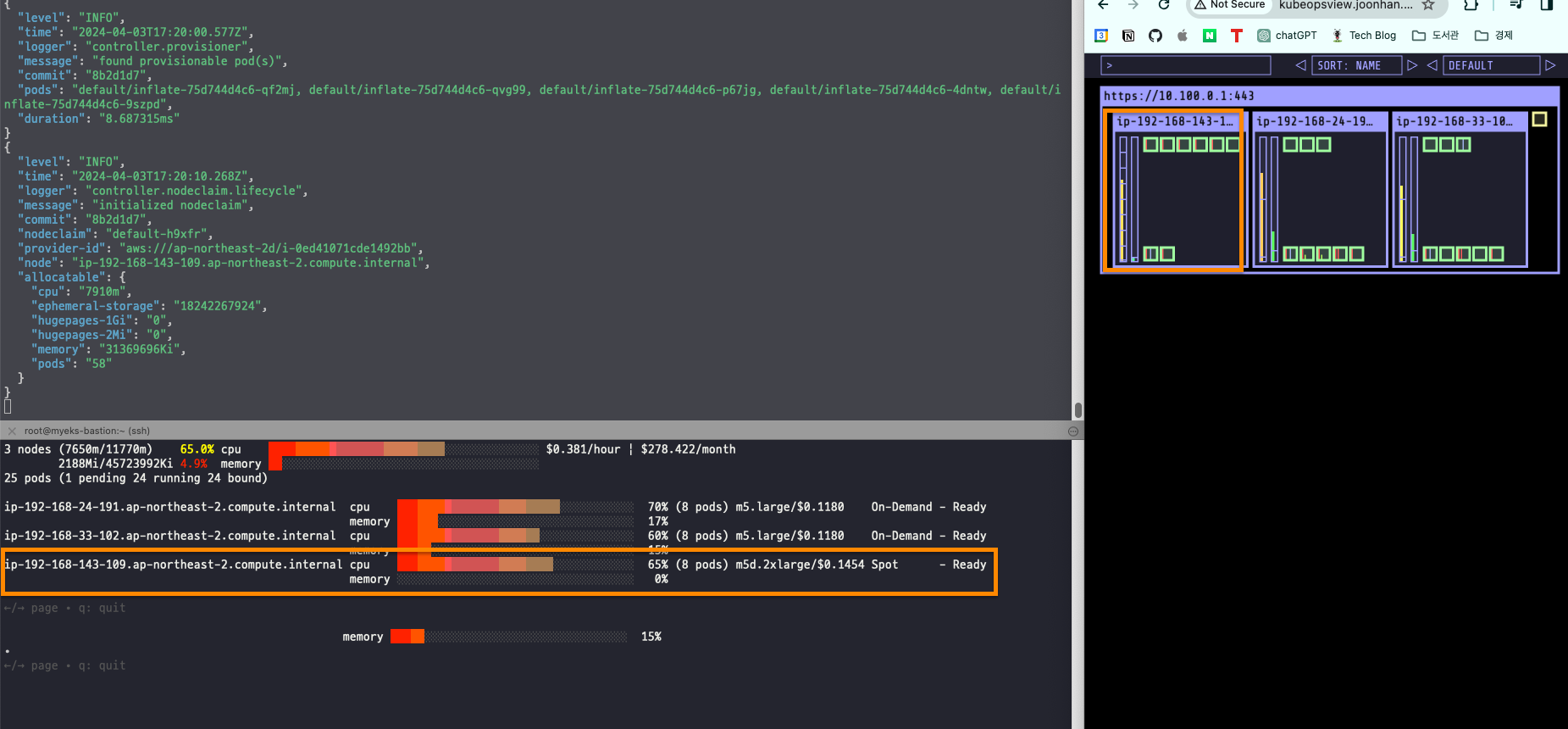
아래의 명령어를 이용해서 파드를 삭제했다.
kubectl delete deployment inflate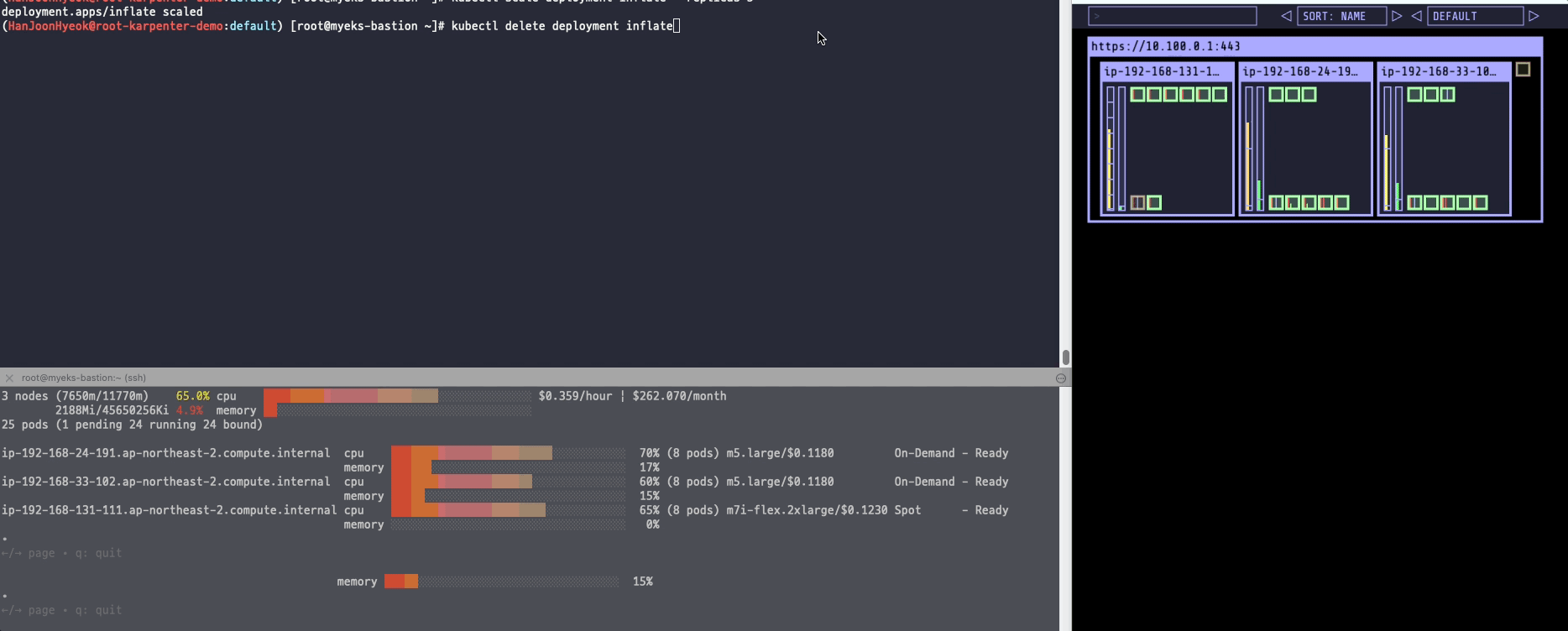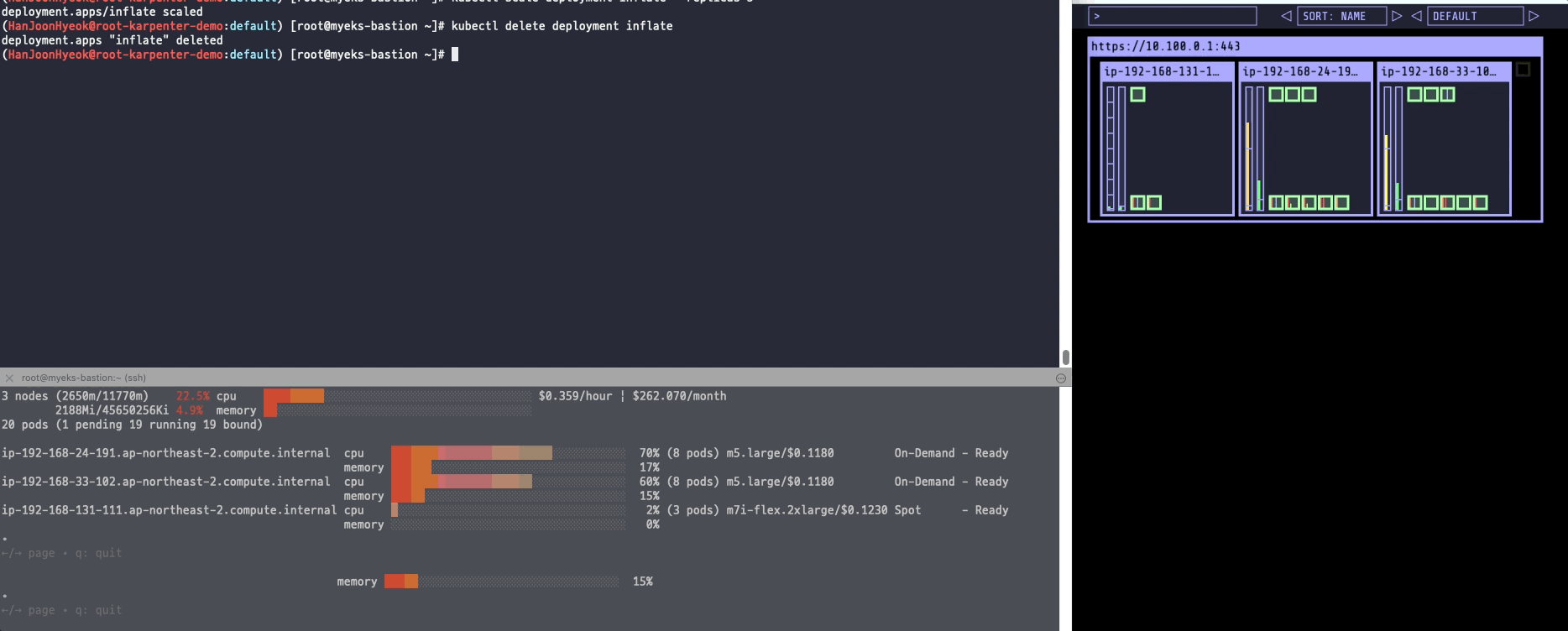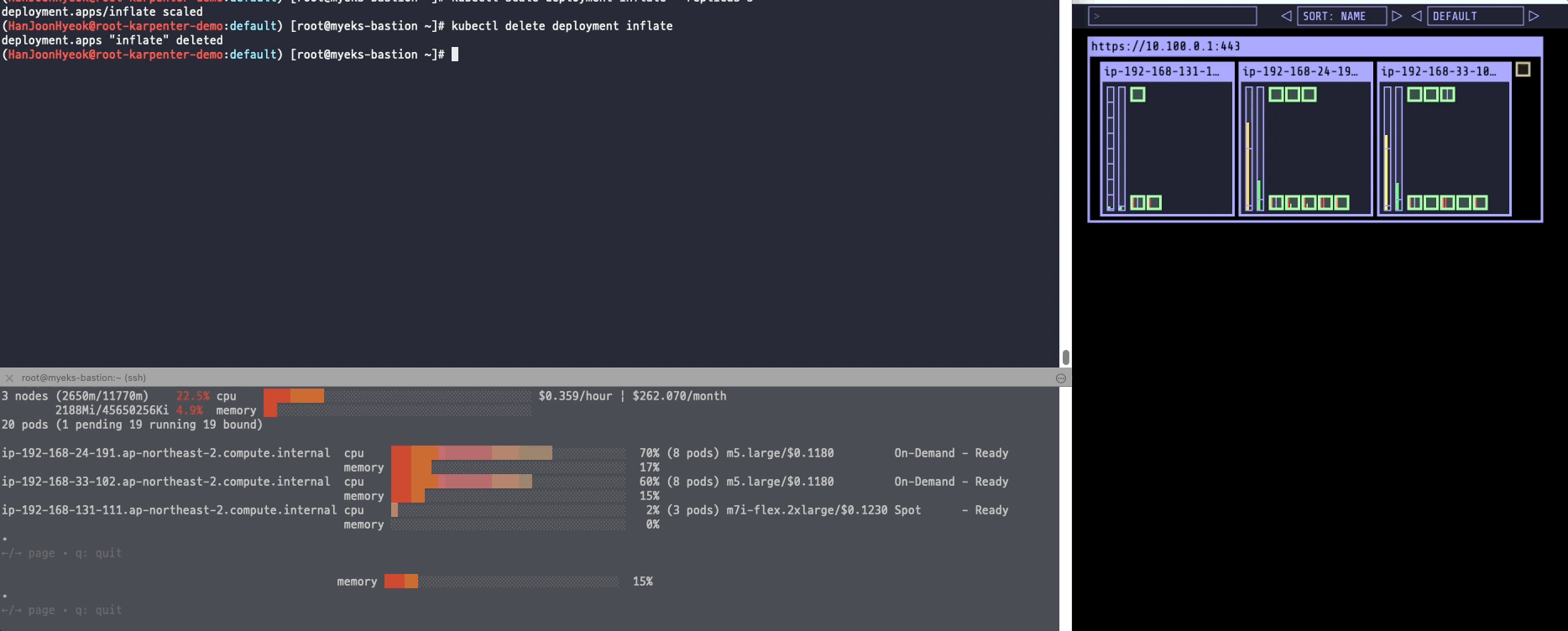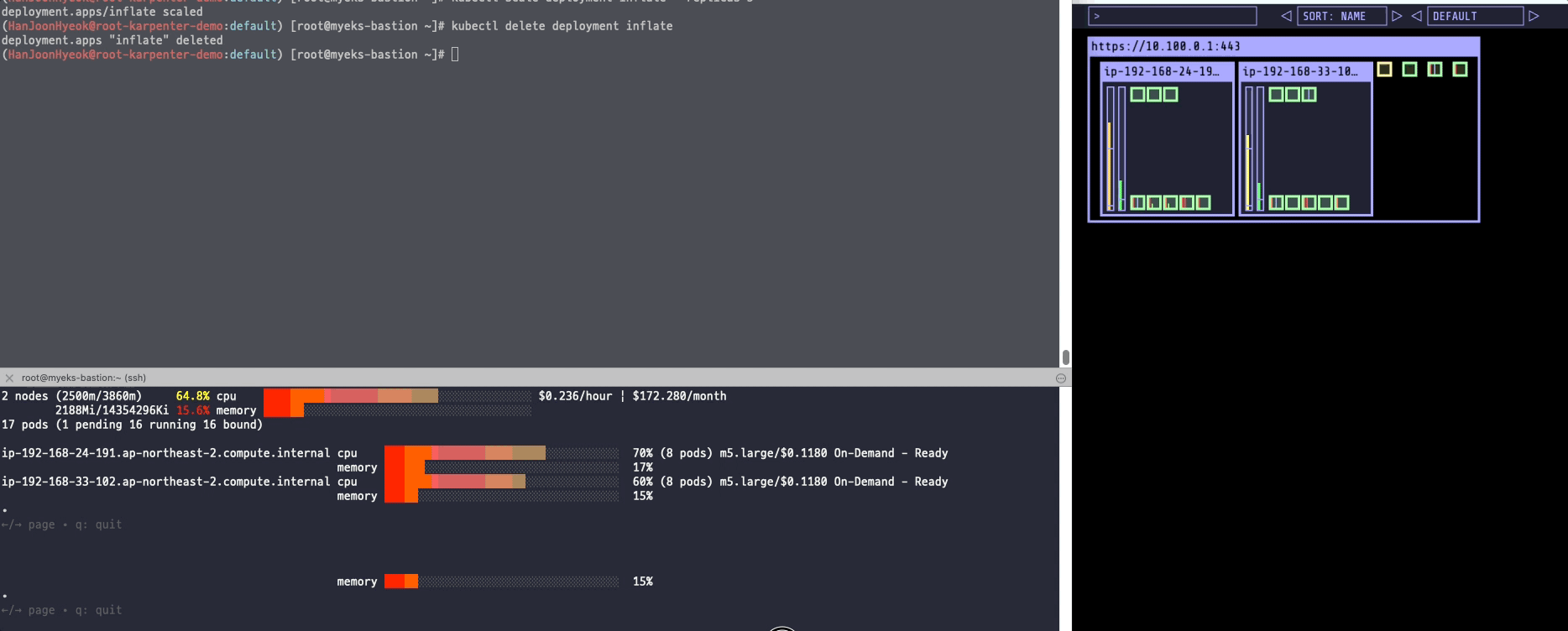
파드들이 먼저 제거되고 나서 새롭게 생성했던 스팟 인스턴스도 제거되었다.
CA 에 비하면 굉장히 빠른 속도로 스케일링이 이루어졌다.
명령어 실행 후 약 20초 만에 인스턴스가 제거되었다.
Spot-to-Spot Consolidation
파드의 수를 조절하면서 오버/언더 프로비저닝이 되지 않도록 스팟 인스턴스의 성능도 함께 조절하는 기능이다.
우선 기존에 생성한 NodePool 을 삭제했다.
kubectl delete nodepool,ec2nodeclass defaultsettings.featureGates.spotToSpotConsolidation 옵션을 true 로 설정하면 사용할 수 있다.
helm upgrade karpenter -n kube-system oci://public.ecr.aws/karpenter/karpenter \
--reuse-values --set settings.featureGates.spotToSpotConsolidation=trueNodePool 을 아래와 같이 새롭게 생성했는데, 달라진 점은 인스턴스 세대를 2세대에서 5세대(Nitro)로 변경했다는 점이다.
cat <<EOF > nodepool.yaml
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata:
labels:
intent: apps
spec:
nodeClassRef:
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c","m","r"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: karpenter.k8s.aws/instance-hypervisor
operator: In
values: ["nitro"]
limits:
cpu: 100
memory: 100Gi
disruption:
consolidationPolicy: WhenUnderutilized
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: Bottlerocket
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
tags:
Name: karpenter.sh/nodepool/default
IntentLabel: "apps"
EOF
kubectl apply -f nodepool.yaml그 다음 Deployment 를 이용해서 파드를 5개 배포했다.
cat <<EOF > inflate.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 5
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
nodeSelector:
intent: apps
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.2
resources:
requests:
cpu: 1
memory: 1.5Gi
EOF
kubectl apply -f inflate.yaml새롭게 스팟 인스턴스를 실행하는 건 동일하지만, 파드의 수를 줄이면서 스팟 인스턴스의 성능도 함께 줄어드는지 확인하기 위해 파드의 개수를 줄였다.
kubectl scale --replicas=1 deployment/inflate기존에 실행하던 스팟 인스턴스는 c6g.2xlarge 였는데, 상태가 Cordoned Ready (차단 준비 완료)로 바뀌었다.
그리고 한 단계 낮은 c6g.large 스팟 인스턴스가 새롭게 생성되었다.
즉, 파드가 줄어듬에 따라 성능이 높은 기존에 실행하던 스팟 인스턴스는 제거하고, 성능이 낮은 스팟 인스턴스를 새롭게 생성하고 있는 것이다.
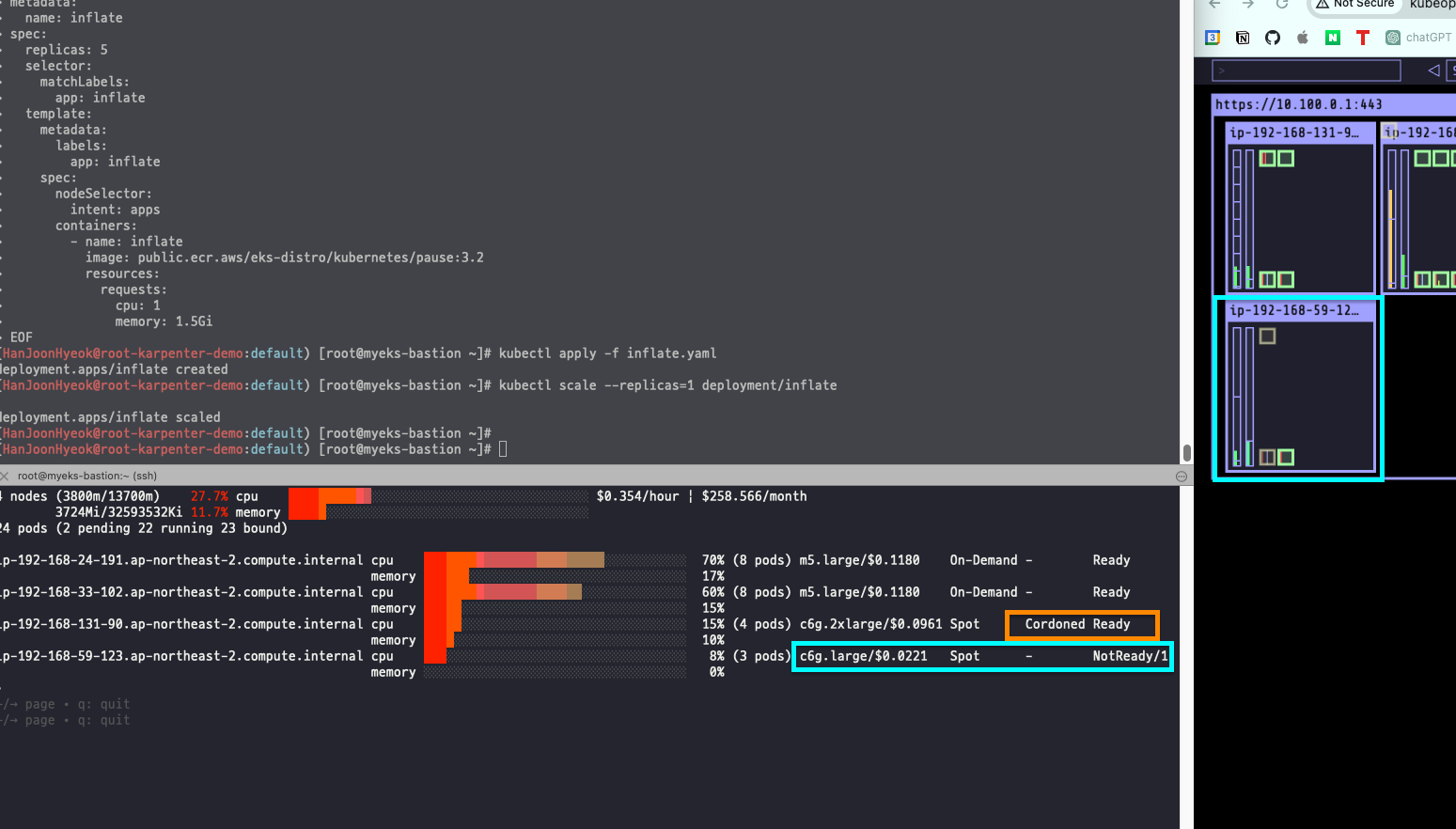
새롭게 실행한 스팟 인스턴스에 파드들이 모두 실행되면 기존에 실행하던 스팟 인스턴스는 종료된다.
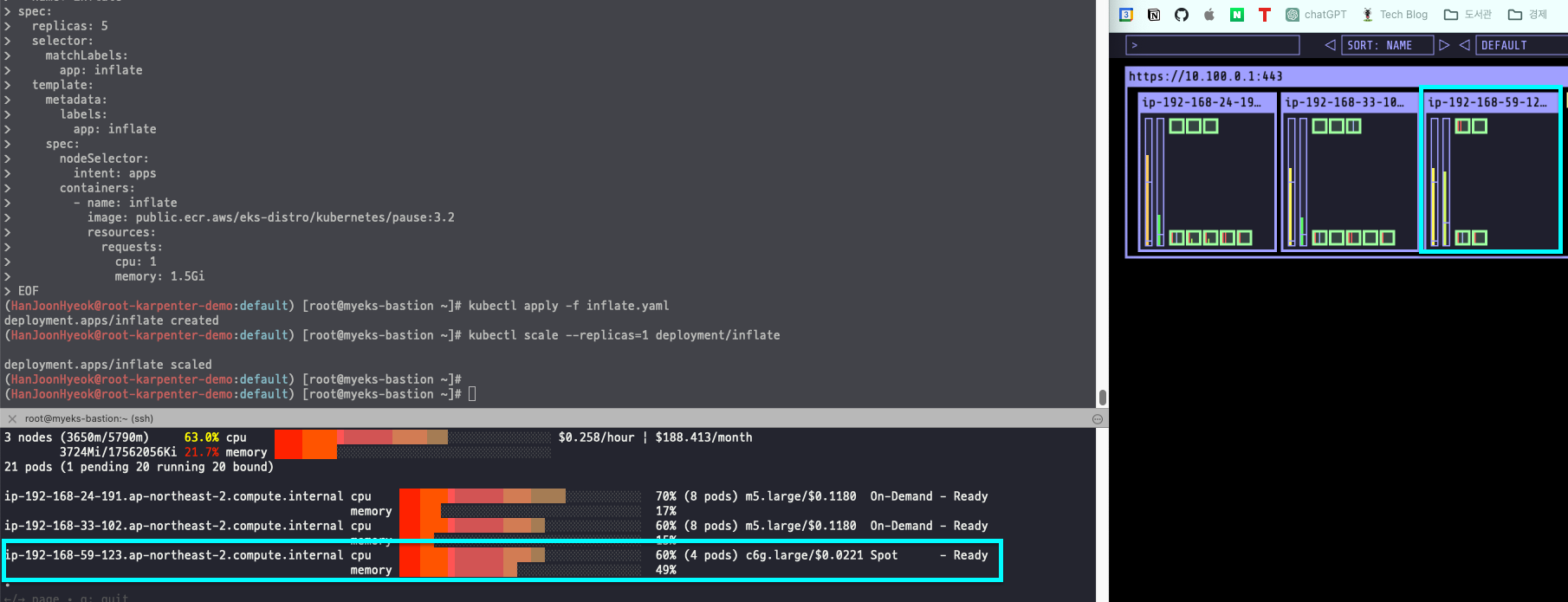
비용 최적화를 생각한다면 스팟 인스턴스를 함께 사용하는 것도 좋은 것 같다.
후기
CPU, RAM 사용량 뿐만 아니라 다양한 메트릭을 기준으로 오토스케일링을 수행할 수 있다는 걸 새롭게 알게 되었다.
서비스를 운영하면서 트래픽이 급격하게 몰리는 경험을 해보지 않았지만, 오토스케일링을 적용하지 않아서 서버가 다운되는 상황은 상상하는 것만으로도 정말 아찔하다.
뉴스에서 심심치 않게 갑자기 트래픽이 몰려서 페이지 접속이 안됐다는 사례를 볼 수 있었는데, 오토스케일링이 잘 되어 있다면 이런 상황에도 튼튼하게 트래픽을 감당할 수 있을 것 같다.
오토스케일링을 적용할 때 가장 어려울 것으로 예상되는 건 파드마다 적절한 CPU, RAM 사용량을 할당해주고, 최대 몇 개까지 늘려줄 것인지 정하는 일인 것 같다.
오토스케일링은 비용과 직결되는 문제이기 때문에 오버 프로비저닝으로 비용이 생각보다 더 많이 나올 수 있을 것 같다.
반대로 언더 프로비저닝으로 트래픽을 감당하지 못하는 상황도 난감할 것 같다.
따라서 서비스를 운영할 때는 시간별 트래픽 변화 추이를 데이터로 반드시 확인해야 높은 가용성을 유지할 수 있을 것이다.
비용 최적화까지 생각한다면 Karpenter 를 적극적으로 사용하면 좋을 것 같다.
참고자료
- 수직 확장(Scale up) vs 수평 확장(Scale out) [hudi.blog]
- 쿠버네티스 KEDA 소개 [devocean]
- EKS 스터디 - 5주차 2편 - CPA [티스토리]
