개요
이번 4주차 스터디에서는 쿠버네티스로 애플리케이션을 배포하고 운영할 때 문제가 발생하면 적절한 조치를 취해주기 위해 애플리케이션의 로그 메세지나 컴퓨터의 물리 자원에 대한 정보를 모니터링 하는 Observability 에 대해 학습했다.
Observability 는 관측 가능성, 가시성을 의미하는 영단어이다. 줄여서 O11y 라고 하며, O 와 y 알파벳 사이에 총 11개의 알파벳 O(bservabilit)y이 있어서 O11y 라고 한다. 쿠버네티스를 K8s 라고 줄여서 부르는 것도 동일한 맥락이다.
애플리케이션을 운영하고 관리하는 입장에서 컴퓨터의 상태나 내부적으로 발생하고 있는 일에 대한 정보를 살펴보는 것은 중요하다.
컴퓨터에서 일어나고 있는 일을 파악할 수 있는 정보의 종류는 크게 2가지가 있다.
- 물리 자원 정보 : 컴퓨터의 전체 CPU 사용률, 메모리 사용량, 네트워크 사용량, 디스크 사용량
- 소프트웨어 정보 : 애플리케이션에서 발생하는 오류, 로그 메세지 등
애플리케이션을 배포했는데 코드 상에서 무한 루프에 빠져 CPU 사용률이 지나치게 높아진다면 적절한 조치를 취해주어야 한다.
마찬가지로 물리 자원에는 문제가 없지만 애플리케이션 단에서 사용자의 요청을 제대로 처리하지 못한다면 애플리케이션에서 발생하는 로그 메세지를 기반으로 문제를 해결해야 한다.
이처럼 서비스의 안정성, 가용성, 성능을 유지하기 위해서는 모니터링이 필수적이며, 데이터를 시각화해서 보는 것은 서버 관리 생산성을 높여준다.
AWS EKS 에서 Observability 를 향상하기 위한 방법을 알아보자.
EKS Logging
EKS 내부적으로 발생하는 일을 알기 위해서는 어떤 대상에서 로그를 수집 해올 것인지 먼저 정해야 한다.
로그를 수집할 수 있는 대상은 크게 컨트롤 플레인, 노드, 애플리케이션 3가지로 정할 수 있다.
여기서 노드 로깅은 클러스터 노드(데이터 플레인) 로깅을 의미하는데, 컨트롤 플레인 로깅을 활성화하면 노드 로깅도 함께 이루어진다.
Control Plane Logging + Node Logging
AWS 에서 관리해주는 컨트롤 플레인에서 발생하는 로그는 AWS CloudWatch 를 이용해서 수집할 수 있다.
컨트롤 플레인 로깅을 사용하면 CloudWatch 를 사용하기 때문에 비용이 발생한다.
2024년 3월 25일 기준, 서울 리전(ap-northeast-2)에서는 데이터 수집 1GB 당 0.76 달러(약 1,017원)가 부과된다.
자세한 요금 정책은 아래의 링크에서 확인 가능하다.
- Amazon CloudWatch 요금 [aws]
컨트롤 플레인에서 수집할 수 있는 데이터의 종류는 아래와 같이 5가지다.
- API 서버: 클러스터 내에서 발생하는 모든 작업에 대한 요청과 응답 기록 제공
- 감사(Audit): 클러스터에 영향을 준 개별 사용자, 관리자, 시스템 구성 요소에 대한 기록 제공
- 인증자(Authenticator): Authenticator 로그는 EKS 에서만 존재하는 개념이다. EKS 가 쿠버네티스의 RBAC 인증을 위해 사용하는 IAM 자격 증명에 대한 정보를 제공한다.
- 컨트롤러 관리자(Controller Manager): 클러스터 내의 여러 시소스를 관리하고 클러스터의 상태를 지속적으로 감시하여 안정성을 유지하는 여러 컨트롤러에 대한 정보를 제공한다. replication 컨트롤러, endpoint 컨트롤러, namespace 컨트롤러 등의 작업을 포함한다. (참고 자료: kube-controller-manager)
- 스케줄러(Scheduler): 클러스터에 언제 어느 노드에 파드를 실행할 지 관리하는 스케줄러에서 발생하는 정보를 제공한다.
컨트롤 플레인 로깅 활성화
배스천 호스트에서 아래의 명령어를 실행해서 EKS 의 앞에서 언급한 5가지 로깅을 활성화했다.
aws eks update-cluster-config \
--region $AWS_DEFAULT_REGION \
--name $CLUSTER_NAME \
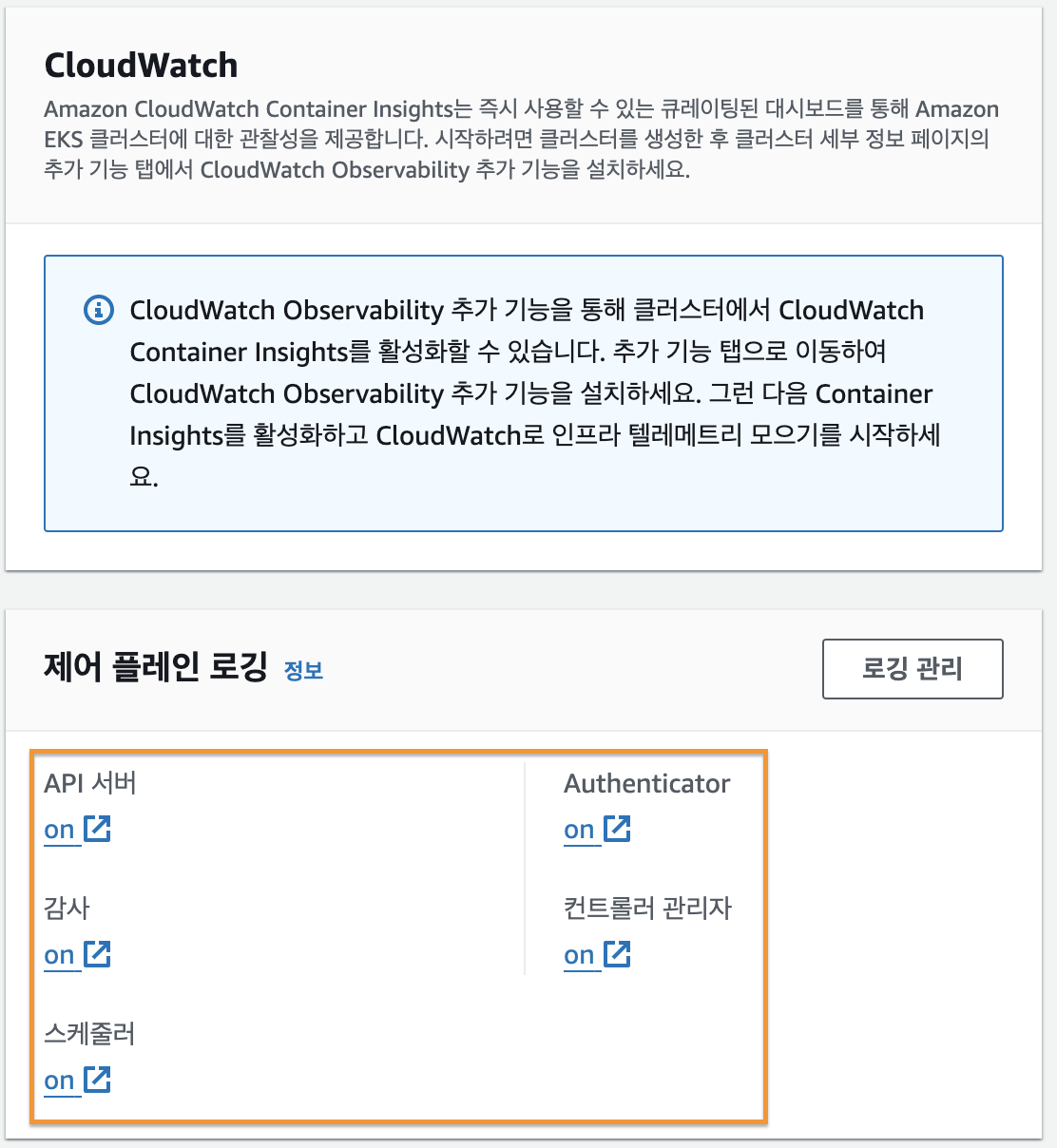
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'[AWS 콘솔] - [EKS] 에서 클러스터의 [관찰성] 탭을 클릭해서 [제어 플레인 로깅] 항목을 확인해보면 모든 항목이 아래의 이미지와 같이 on 으로 되어 있는 것을 확인할 수 있다.
아래의 명령어를 이용해서 kube-controller-manager 에서 실시간으로 쌓이는 로그를 확인해볼 수 있다.
aws logs tail /aws/eks/$CLUSTER_NAME/cluster \
--log-stream-name-prefix kube-controller-manager \
--follow
#...
#2024-03-26T03:33:28.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:33:28.566078 9 shared_informer.go:311] Waiting for caches to sync for garbage collector
#2024-03-26T03:33:28.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:33:28.667199 9 shared_informer.go:318] Caches are synced for garbage collector
#2024-03-26T03:33:28.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:33:28.667255 9 garbagecollector.go:274] "synced garbage collector"실제로 로그가 쌓이는 지 확인하기 위해 coredns 파드를 2개에서 1개로 줄여보았다.
kubectl scale deployment \
-n kube-system coredns \
--replicas=1아래와 같이 Too many replicas 라는 문구와 함께 파드가 2개에서 1개로 줄이는 작업을 수행한 것을 확인할 수 있다.
2024-03-26T03:33:28.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:33:28.566078 9 shared_informer.go:311] Waiting for caches to sync for garbage collector
2024-03-26T03:33:28.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:33:28.667199 9 shared_informer.go:318] Caches are synced for garbage collector
2024-03-26T03:33:28.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:33:28.667255 9 garbagecollector.go:274] "synced garbage collector"
# 위는 기존 내용
# 아래는 새롭게 생성된 내용
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.397739 9 replica_set.go:621] "Too many replicas" replicaSet="kube-system/coredns-55474bf7b9" need=1 deleting=1
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.397789 9 replica_set.go:248] "Found related ReplicaSets" replicaSet="kube-system/coredns-55474bf7b9" relatedReplicaSets=["kube-system/coredns-56dfff779f","kube-system/coredns-55474bf7b9"]
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.397884 9 controller_utils.go:609] "Deleting pod" controller="coredns-55474bf7b9" pod="kube-system/coredns-55474bf7b9-nwm4v"
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.399437 9 event.go:307] "Event occurred" object="kube-system/coredns" fieldPath="" kind="Deployment" apiVersion="apps/v1" type="Normal" reason="ScalingReplicaSet" message="Scaled down replica set coredns-55474bf7b9 to 1 from 2"
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.432664 9 event.go:307] "Event occurred" object="kube-system/coredns-55474bf7b9" fieldPath="" kind="ReplicaSet" apiVersion="apps/v1" type="Normal" reason="SuccessfulDelete" message="Deleted pod: coredns-55474bf7b9-nwm4v"
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.432868 9 deployment_controller.go:503] "Error syncing deployment" deployment="kube-system/coredns" err="Operation cannot be fulfilled on deployments.apps \"coredns\": the object has been modified; please apply your changes to the latest version and try again"
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.448338 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="50.689441ms"
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.463605 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="15.198486ms"
2024-03-26T03:41:53.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:53.464732 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="214.116µs"
2024-03-26T03:41:58.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:58.674441 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="109.109µs"
2024-03-26T03:41:59.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:59.223026 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="97.968µs"
2024-03-26T03:41:59.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:59.259569 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="110.126µs"
2024-03-26T03:41:59.000000+00:00 kube-controller-manager-881456c824365d1fbd4b50dba3ddd7c0 I0326 03:41:59.264681 9 replica_set.go:676] "Finished syncing" kind="ReplicaSet" key="kube-system/coredns-55474bf7b9" duration="307.365µs"CloudWatch Log Insights
EKS 컨트롤 플레인 로깅을 활성화 하면 CloudWatch Log Insights 를 사용할 수 있다.
AWS CloudWatch 에서 [로그] - [Logs Insights] 탭으로 들어오면 로그를 SQL 처럼 가공해서 조회할 수 있다.
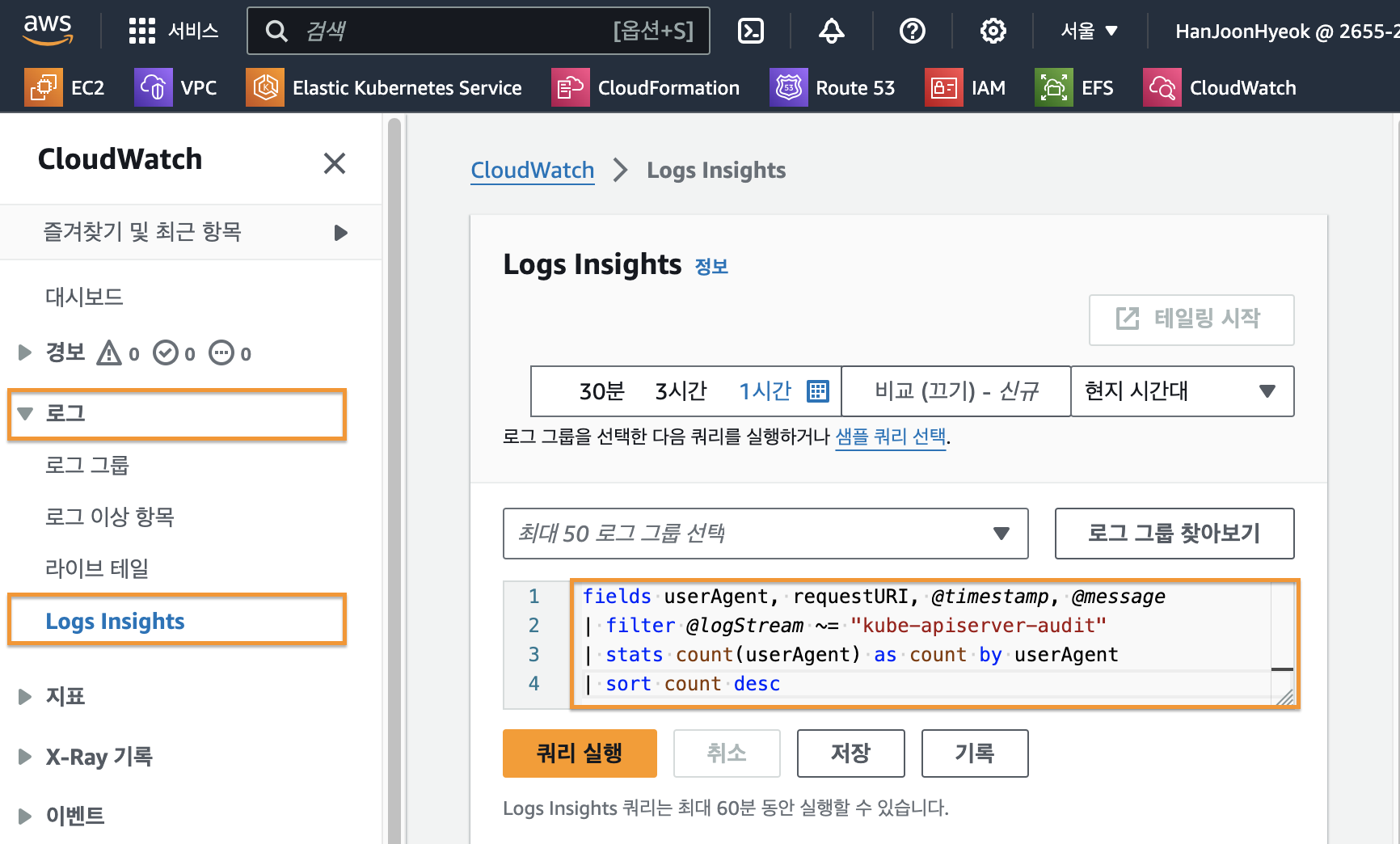
사용하기 위해서는 아래의 이미지와 같이 로그 그룹을 선택해야 한다.
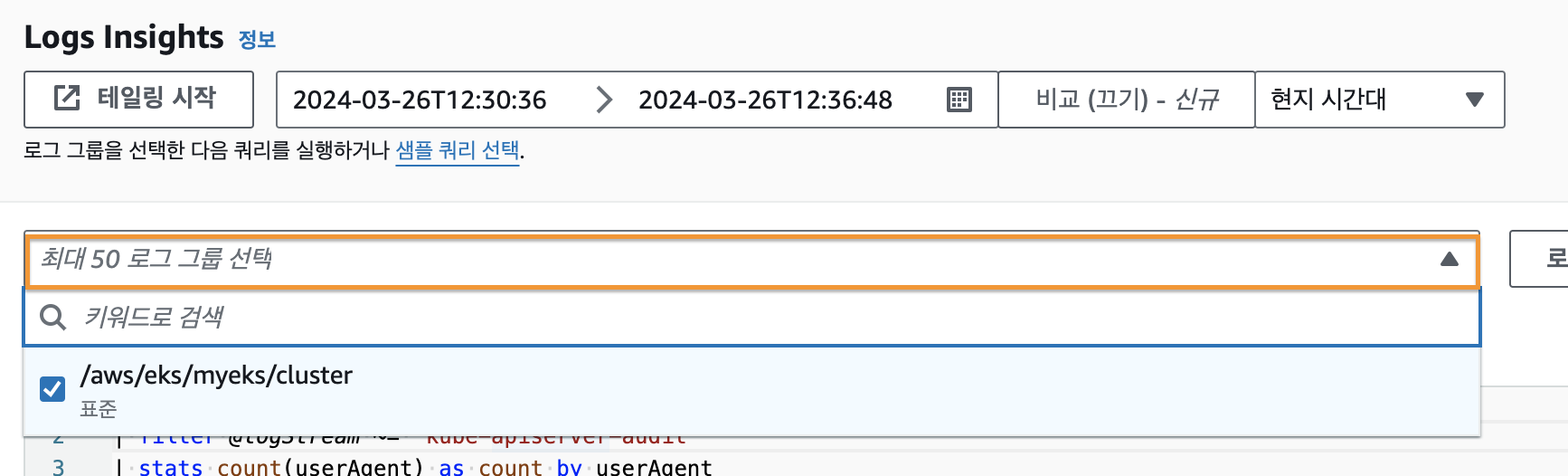
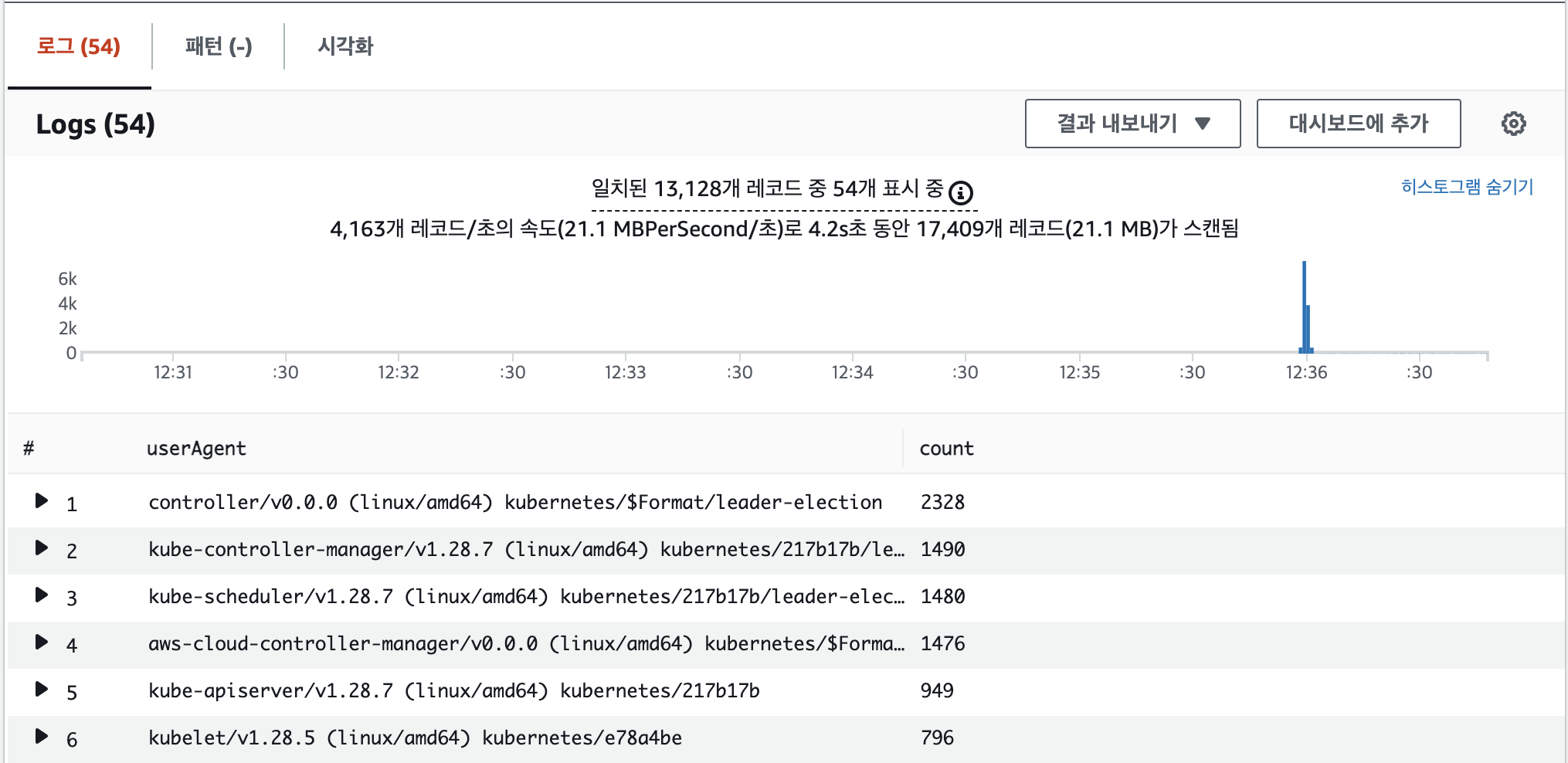
그 다음 아래의 쿼리문을 이용해서 kube-apiserver-audit 로그에서 userAgent 의 수를 기준으로 내림차순으로 정렬하여 userAgent, requestURI, timestamp, message 4가지 필드를 조회했다.
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc아래의 이미지와 같이 userAgent 의 count 를 내림차순으로 정렬한 텍스트 데이터와 시계열 그래프로 시간대 별로 로그가 가장 많이 발생한 시간을 시각화해서 보여주고 있다.
아래와 같이 CLI 환경에서도 쿼리를 작성해서 전송할 수 있다.
aws logs get-query-results --query-id $(aws logs start-query \
--log-group-name '/aws/eks/myeks/cluster' \
--start-time `date -d "-1 hours" +%s` \
--end-time `date +%s` \
--query-string 'fields @timestamp, @message | filter @logStream ~= "kube-scheduler" | sort @timestamp desc' \
| jq --raw-output '.queryId')실행 결과는 아래와 같다.
{
"results": [
[
{
"field": "@timestamp",
"value": "2024-03-26 03:43:54.000"
},
{
"field": "@message",
"value": "I0326 03:43:54.451310 9 schedule_one.go:286] \"Successfully bound pod to node\" pod=\"kube-system/coredns-55474bf7b9-j9ngk\" node=\"ip-192-168-2-110.ap-northeast-2.compute.internal\" evaluatedNodes=3 feasibleNodes=3"
},
{
"field": "@ptr",
"value": "CmgKJwojMjY1NTI0MDc0ODA0Oi9hd3MvZWtzL215ZWtzL2NsdXN0ZXIQBxI5GhgCBl5nSXEAAAAA9j1N1AAGYCRDQAAAAhIgASjF2OrG5zEw+ZfxxucxOMEBQMHLDUiw6QFQlNUBGAAgARBVGAE="
}
]
],
"statistics": {
"recordsMatched": 1.0,
"recordsScanned": 35042.0,
"bytesScanned": 42725415.0
},
"status": "Running"
}컨트롤 플레인 로깅 종료
아래의 명령어를 이용해서 EKS 컨트롤 플레인 로깅을 비활성화 할 수 있다.
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve실행하는 동안 쌓인 로그를 삭제하기 위해 아래의 명령어를 실행해서 로그 그룹도 삭제했다.
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/clusterPod Logging
컨테이너로 배포하는 애플리케이션은 로그를 표준 출력(stdout)과 표준 오류(stderr)로 출력하도록 권장하고 있다.
실제로 nginx 의 이미지의 Dockerfile 내용을 살펴보면 아래와 같이 표준 출력 (/dev/stdout)을 /var/log/nginx/acess.log 와 표준 오류(/dev/stderr)를 /var/log/nginx/error.log 로 심볼릭 링크를 설정해놓은 것을 확인할 수 있다. (참고자료: docker-nginx [github])
# docker-nginx/stable/alpine-slim/Dockerfile
...
# forward request and error logs to docker log collector
&& ln -sf /dev/stdout /var/log/nginx/access.log \
&& ln -sf /dev/stderr /var/log/nginx/error.log \
...쿠버네티스에서는 각각의 파일 디스크립터(표준 출력, 표준 오류)로 출력되는 로그는 심볼릭 링크를 통해 노드의 /var/log/pods/*.log 경로에 저장한다.
실제로 해당 경로에 로그가 저장되는지 확인하기 위해 아래의 명령어를 이용해서 nginx 를 파드로 실행했다.
kubectl create deployment nginx-demo --image=nginx파드는 아래와 같이 nginx-demo-554db85f85-rfb8b 이름으로 생성되었다.
kubectl get pod
#NAME READY STATUS RESTARTS AGE
#nginx-demo-554db85f85-rfb8b 1/1 Running 0 3m44s그리고 /var/log/pods 디렉토리를 살펴보면 아래와 같이 네임스페이스_파드이름 으로 폴더가 생성된다.
tree /var/log/pods
#/var/log/pods
#├── default_nginx-demo-554db85f85-rfb8b_c0b25fb2-78b1-4f35-a5c8-bc9d08b6b005
#│ └── nginx
#│ └── 0.log
해당 폴더에는 0.log 라는 파일이 있는데 해당 파일을 확인해보면 아래와 같이 표준 출력과 표준 오류가 함께 저장되는 것을 확인할 수 있다.
sudo cat /var/log/pods/default_nginx-demo-554db85f85-rfb8b_c0b25fb2-78b1-4f35-a5c8-bc9d08b6b005/nginx/0.log
#2024-03-25T11:41:59.633035943+09:00 stdout F /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
#2024-03-25T11:41:59.633240006+09:00 stdout F /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
#2024-03-25T11:41:59.654369672+09:00 stdout F /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
#2024-03-25T11:41:59.679301579+09:00 stdout F 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
#2024-03-25T11:41:59.705699617+09:00 stdout F 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
#2024-03-25T11:41:59.707104126+09:00 stdout F /docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
#2024-03-25T11:41:59.708469557+09:00 stdout F /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
#2024-03-25T11:41:59.720243664+09:00 stdout F /docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
#2024-03-25T11:41:59.72523142+09:00 stdout F /docker-entrypoint.sh: Configuration complete; ready for start up
#2024-03-25T11:41:59.795594235+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: using the "epoll" event method
#2024-03-25T11:41:59.795617599+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: nginx/1.25.4
#2024-03-25T11:41:59.79562109+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: built by gcc 12.2.0 (Debian 12.2.0-14)
#2024-03-25T11:41:59.795623356+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: OS: Linux 5.15.0-97-generic
#2024-03-25T11:41:59.795625493+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
#2024-03-25T11:41:59.79574719+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: start worker processes
#2024-03-25T11:41:59.796150421+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: start worker process 29
#2024-03-25T11:41:59.796521757+09:00 stderr F 2024/03/25 02:41:59 [notice] 1#1: start worker process 30
간편하게 로그를 확인하고 싶다면 kubectl logs 명령어를 이용해서 파드의 로그를 출력할 수 있다.
kubectl logs -l app=nginx-demo
#/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
#/docker-entrypoint.sh: Configuration complete; ready for start up
#2024/03/25 02:41:59 [notice] 1#1: using the "epoll" event method
#2024/03/25 02:41:59 [notice] 1#1: nginx/1.25.4
#2024/03/25 02:41:59 [notice] 1#1: built by gcc 12.2.0 (Debian 12.2.0-14)
#2024/03/25 02:41:59 [notice] 1#1: OS: Linux 5.15.0-97-generic
#2024/03/25 02:41:59 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
#2024/03/25 02:41:59 [notice] 1#1: start worker processes
#2024/03/25 02:41:59 [notice] 1#1: start worker process 29
#2024/03/25 02:41:59 [notice] 1#1: start worker process 30파드 로깅은 EKS 설정에서 지원해주지 않기 때문에 사용자가 도구를 선택해서 파드 로그 수집과 저장을 해야 한다.
AWS 에서는 FluentBit 를 이용해서 로그를 수집해서 CloudWatch 로 로그로 전송하는 예시를 제공하고 있다.
FluentBit
FluentBit 는 경량화된 로그 및 메트릭 처리를 담당하는 프로그램이다.
컨테이너 애플리케이션을 로그를 수집해서 CloudWatch 와 같은 중앙 로그 집중 프로그램으로 로그를 전송한다.
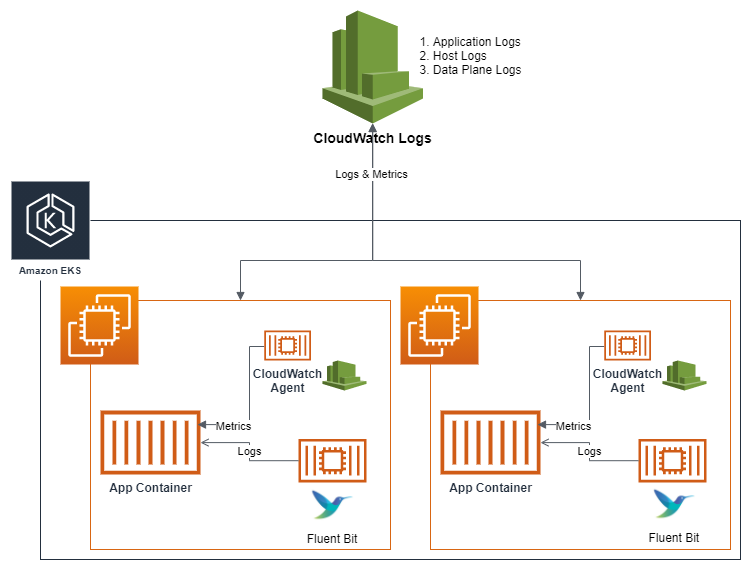
출처: Fluent Bit Integration in CloudWatch Container Insights for EKS [aws]
쿠버네티스에서는 FluentBit 컨테이너를 데몬셋(DaemonSet)으로 작동시키며, 아래의 3가지 종류의 로그를 CloudWatch Logs 에 전송한다.
- 컨테이너/파드 로그
- 노드(호스트) 로그
- 노드에서 발생하는 시스템 수준의 로그를 수집한다.
/var/log/dmesg,/var/log/secure,/var/log/messages경로에서 수집한다.
- 쿠버네티스 데이터 플레인 로그
- 노드가 결국 데이터 플레인이긴 하지만, 조금 더 구체적으로는 쿠버네티스 컴포넌트에 해당하는 kubelet, kube-proxy 와 같은 에이전트의 로그를 수집한다.
/var/log/journal(kubelet, kube-proxy, docker) 경로에서 수집한다.
CloudWatch Logs 에 로그를 저장하고, 로그 그룹마다 로그를 얼마나 보존할 지 기간을 설정하는 것이 가능하다.
또한, CloudWatch 의 Logs Insights 를 이용해서 로그를 분석하고 대시보드로 시각화 하는 것이 가능하다.
FluentBit 로 컨테이너 로그 수집하기
CloudWatch Agent 파드와 FluentBit 파드가 데몬셋으로 실행되어 메트릭과 로그를 수집할 수 있다.
수집한 데이터는 AWS CloudWatch Container Insight 를 이용하면 시각화해서 볼 수 있다.
로그를 수집하기 전에 애플리케이션의 로그가 어디에 위치해있는지 살펴보자.
실행 중인 애플리케이션의 로그는 노드의 /var/log/containers 경로에서 확인할 수 있다.
해당 경로의 있는 파일들의 심볼릭 링크를 확인해보면 위에서 파드의 로그 저장 위치를 살펴보았던 /var/log/pods 에 걸려있는 것을 확인할 수 있다.
# 노드 1번에서 실행
sudo ls -al /var/log/containers
#total 8
#drwxr-xr-x 2 root root 4096 Mar 26 03:33 .
#drwxr-xr-x 10 root root 4096 Mar 26 03:25 ..
#lrwxrwxrwx 1 root root 143 Mar 26 03:33 aws-load-balancer-controller-5f7b66cdd5-qrjkc_kube-system_aws-load-balancer-controller-4f03bc226362e416dbcf76d3f4f3511f01291691b222b2bf7bd8b22fa12fd22d.log -> /var/log/pods/kube-system_aws-load-balancer-controller-5f7b66cdd5-qrjkc_2428c723-4338-4f90-a4cd-a57bba9fed35/aws-load-balancer-controller/0.log
#lrwxrwxrwx 1 root root 101 Mar 26 03:25 aws-node-h29zj_kube-system_aws-eks-nodeagent-e37e5fe0f251cf98f8e1c657300f826084ea4d1c89a5eb3ae8d8d82d64392586.log -> /var/log/pods/kube-system_aws-node-h29zj_1713ae3c-a453-4d53-8960-e1d58860543d/aws-eks-nodeagent/0.log
#...CloudWatch 로 로그를 확인하기 위해 아래의 명령어를 실행해서 Amazon CloudWatch Observability 애드온을 설치한다.
aws eks create-addon \
--cluster-name $CLUSTER_NAME \
--addon-name amazon-cloudwatch-observability애드온을 설치하면 FluentBit 도 함께 설치된다.
아래의 명령어로 FluentBit 의 ConfigMap 을 확인할 수 있다.
kubectl describe cm fluent-bit-config \
-n amazon-cloudwatch출력 결과는 아래와 같다.
Name: fluent-bit-config
Namespace: amazon-cloudwatch
Labels: k8s-app=fluent-bit
Annotations: <none>
Data
====
application-log.conf:
----
[INPUT]
Name tail
Tag application.*
Exclude_Path /var/log/containers/cloudwatch-agent*, /var/log/containers/fluent-bit*, /var/log/containers/aws-node*, /var/log/containers/kube-proxy*
Path /var/log/containers/*.log
multiline.parser docker, cri
DB /var/fluent-bit/state/flb_container.db
Mem_Buf_Limit 50MB
Skip_Long_Lines On
Refresh_Interval 10
Rotate_Wait 30
storage.type filesystem
Read_from_Head ${READ_FROM_HEAD}
...FluentBit 가 각 노드에서 로그를 수집하는 방법은 볼륨을 HostPath 로 연결해서 가져오기 때문에 가능하다.
아래의 명령어를 실행해서 FluentBit 의 데몬셋을 자세히 살펴보자.
kubectl describe -n amazon-cloudwatch ds fluent-bit그 중에서도 Volumes 항목을 확인해보면 아래와 같이 HostPath 로 /var/log , /run/log/journal, /var/log/dmesg 에 연결된 것을 확인할 수 있다.
Volumes:
fluentbitstate:
Type: HostPath (bare host directory volume)
Path: /var/fluent-bit/state
HostPathType:
varlog:
Type: HostPath (bare host directory volume)
Path: /var/log
HostPathType:
varlibdockercontainers:
Type: HostPath (bare host directory volume)
Path: /var/lib/docker/containers
HostPathType:
fluent-bit-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: fluent-bit-config
Optional: false
runlogjournal:
Type: HostPath (bare host directory volume)
Path: /run/log/journal
HostPathType:
dmesg:
Type: HostPath (bare host directory volume)
Path: /var/log/dmesg
HostPathType:AWS 콘솔에서 CloudWatch 에 접속한 후 [로그 그룹]을 확인해보면 아래의 이미지와 같이 애플리케이션 로그 그룹이 생성된 것을 확인할 수 있다.
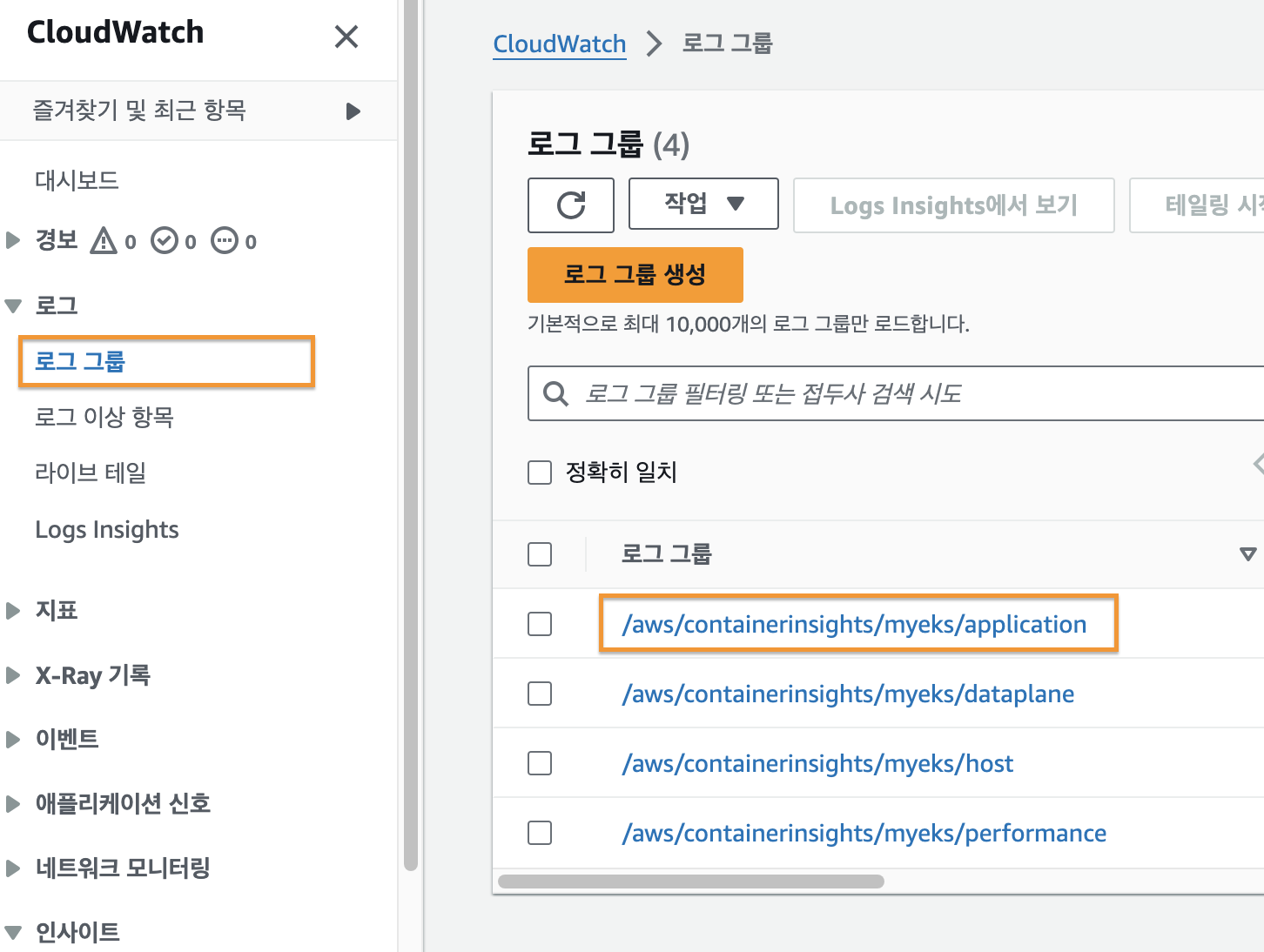
애플리케이션 로그 그룹에는 현재 실행 중인 파드들의 목록이 나타나는 것을 확인할 수 있다.
해당하는 로그 스트림을 클릭하면 로그를 확인할 수 있다.

CloudWatch 의 [인사이트] - [Container Insights] 탭을 확인해보면 아래의 이미지와 같이 메트릭을 시각화해서 컨테이너의 성능을 측정할 수 있다.
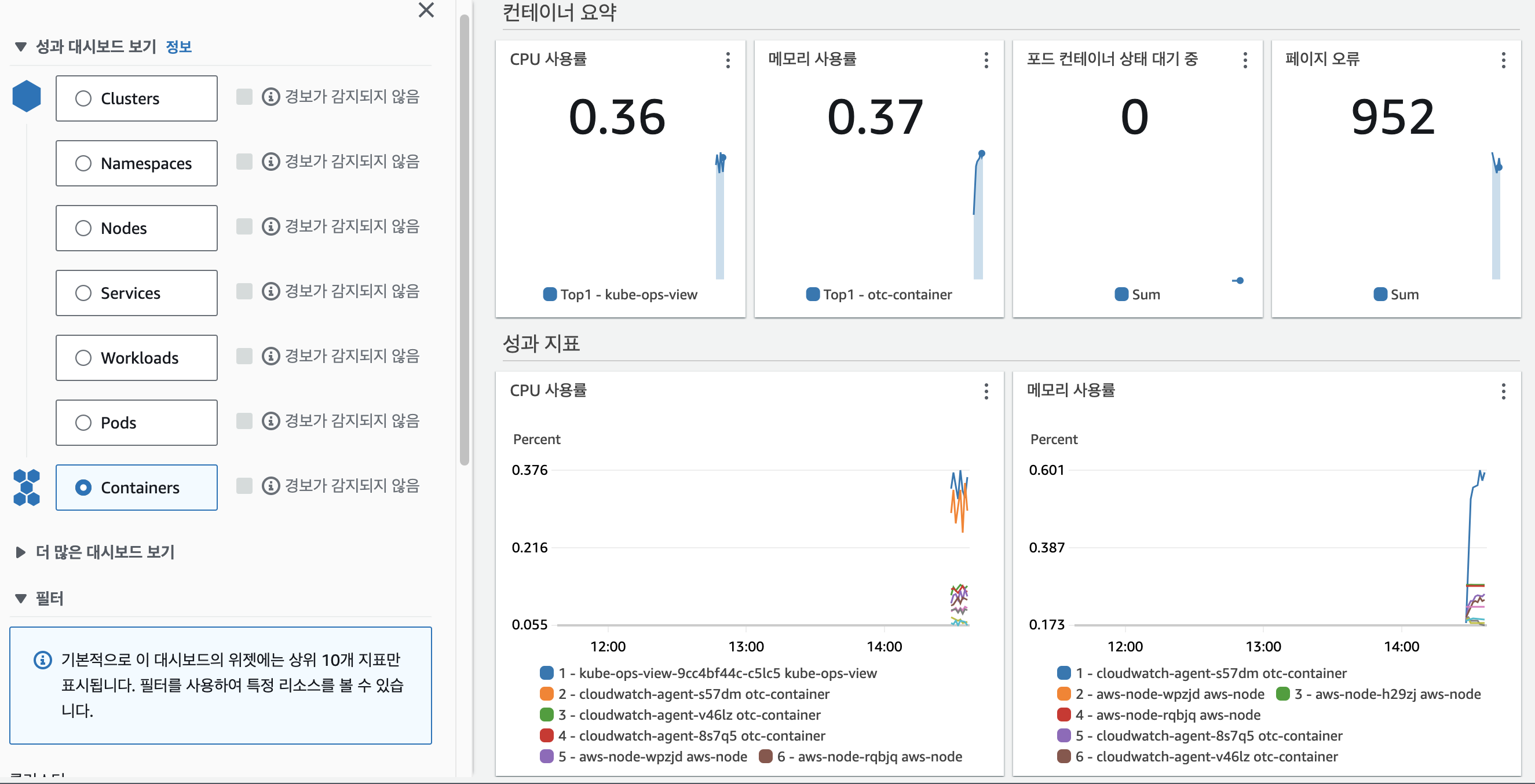
메트릭 수집하기 (1) : metrics-server
메트릭이란 시간이 지나면서 변화하는 데이터다.
CPU 사용률, 메모리 사용률, 하드 디스크 사용률, 네트워크 트래픽 처리량 등 시간의 흐름에 따라 추적할 가치가 있는 데이터를 의미한다.
쿠버네티스에서 메트릭을 수집하기 위한 대표적인 프로그램으로는 metric-servers, prometheus 등이 있다.
메트릭을 수집하기 위한 애드온(addon)으로 metric-servers 를 먼저 사용해볼 것이다.
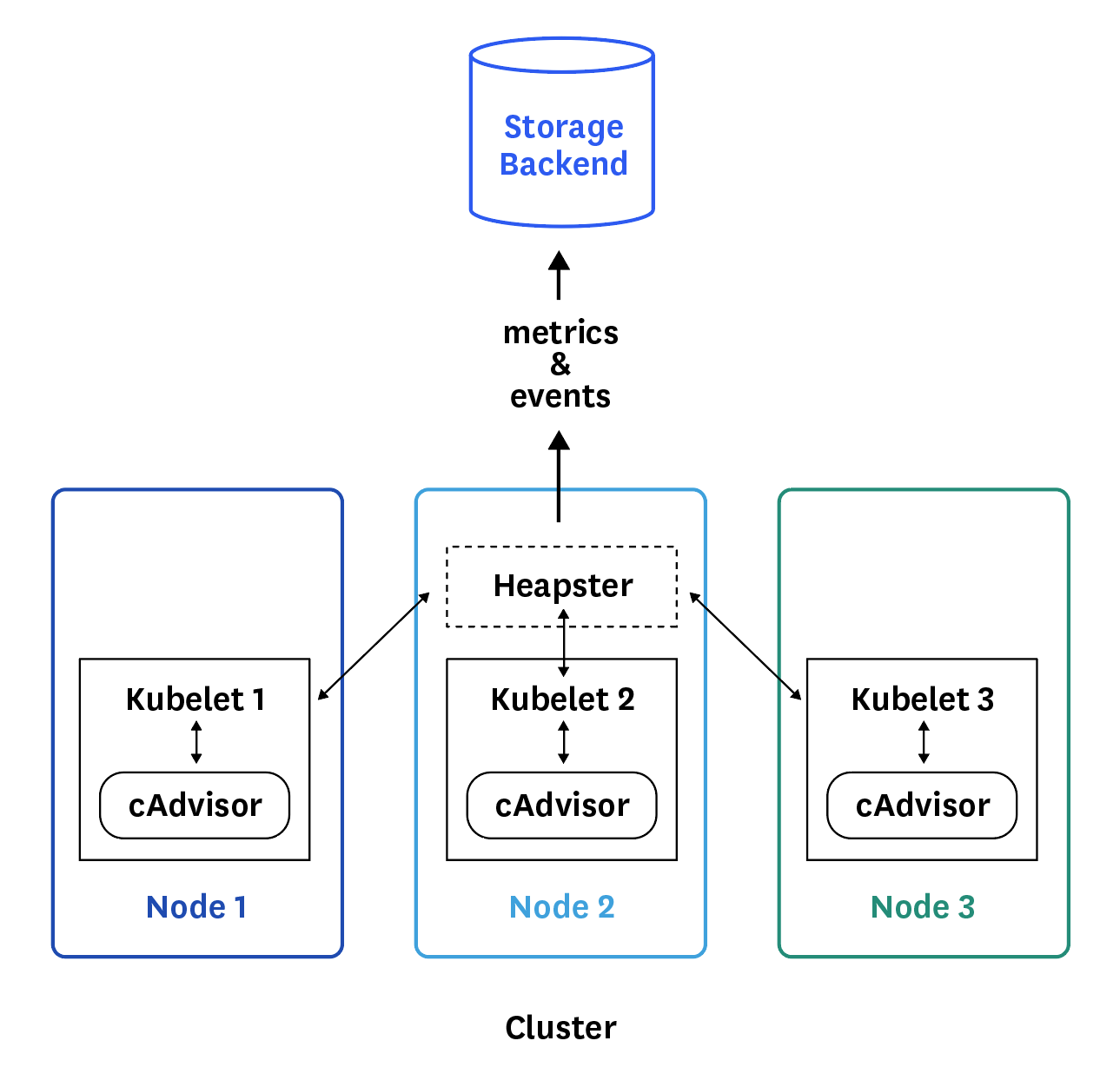
metric-servers 구성도
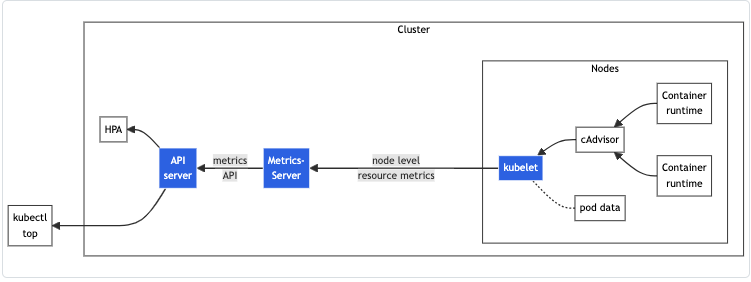
출처: Resource metrics pipeline [kubernetes.io]
metric-servers 는 각 노드마다 실행되는 kubelet 에서 컨테이너로 실행되는 cAdvisor 를 통해 메트릭을 수집한다.
metrics-server 는 kube-system 네임스페이스에 파드로 실행된다.
metrics-server 는 kubelet 내부에서 실행되는 cAdvisor 에서 메트릭을 가져온다. (기본 15초 간격으로 수집)
그리고 metrics-server 는 쿠버네티스 API 서버로 수집한 메트릭을 전송한다.
API 서버는 metrics-server 가 보낸 메트릭에 따라 오토 스케일링을 할 수도 있고, 사용자가 kubectl top 명령어를 실행했을 때 메트릭을 표시할 수도 있다.
cAdvisor
출처: Datadog [github]
cAdvisor 는 Container Advisor 를 의미하며, 컨테이너의 리소스 사용량과 성능을 측정하기 위한 데몬 프로그램이다.
그렇기 때문에 쿠버네티스가 아닌 도커만으로 컨테이너를 실행할 때도 사용할 수 있다.
파드 안에서 컨테이너가 실행될 수 있도록 하는 kubelet 에 cAdvisor 가 함께 포함되어 있다.
쿠버네티스에서 cAdvisor 를 사용하는 이유는 오토 스케일링을 수행하기 위해서다. 메트릭의 수치에 따라 파드를 늘리거나 줄이기 위해 필요하다.
metric-servers 사용해보기
metrics-server 를 설치하기 위해 아래의 명령어를 실행했다.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlkube-system 네임스페이스에서 실행 중인 파드를 확인하면 metrics-server 가 실행되고 있는 것을 확인할 수 있다.
kubectl get pod -n kube-system -l k8s-app=metrics-server
#NAME READY STATUS RESTARTS AGE
#metrics-server-6db4d75b97-vfm2v 1/1 Running 0 41s노드의 메트릭을 확인하기 위해서 아래의 명령어를 실행할 수 있다.
kubectl top node
#NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
#ip-192-168-1-22.ap-northeast-2.compute.internal 67m 1% 763Mi 5%
#ip-192-168-2-110.ap-northeast-2.compute.internal 82m 2% 704Mi 4%
#ip-192-168-3-213.ap-northeast-2.compute.internal 64m 1% 794Mi 5%파드의 메트릭도 확인 가능하다.
kubectl top pod
#NAME CPU(cores) MEMORY(bytes)
#nginx-7f7b5d655f-zdmpv 1m 4Mi함께 사용하기 좋은 프로그램
kwatch
kwatch 는 쿠버네티스 클러스터 안에서 발생하는 변경, 오류를 다양한 채널로 알림을 보내주는 프로그램이다.
이번 글에서는 슬랙 웹훅을 이용해서 알림을 보내볼 것이다.
별도의 슬랙 워크스페이스를 생성해서 웹훅을 설치했으며, 설치하는 방법은 아래의 글에 잘 설명되어있으니 이를 참고하자.
- 참고자료: Slack Incoming Webhook 2가지 방법 [velog]
아래의 yaml 파일을 이용해서 ConfigMap 을 설정했다.
# kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/<webhook-url>'
title: joonhan-EKS
#text: Customized text in slack message
pvcMonitor:
enabled: true
interval: 5
threshold: 70아래의 명령어를 실행해서 ConfigMap 을 적용했다.
kubectl apply -f kwatch-config.yaml아래의 명령어를 실행해서 kwatch 를 배포했다.
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml웹훅을 설정한 슬랙 채널에 아래와 같이 정상적으로 kwatch 를 실행했다는 메세지가 전송된다.
kwatch 가 정상적으로 작동하는지 확인하기 위해 의도적으로 파드에 오류를 내볼 것이다.
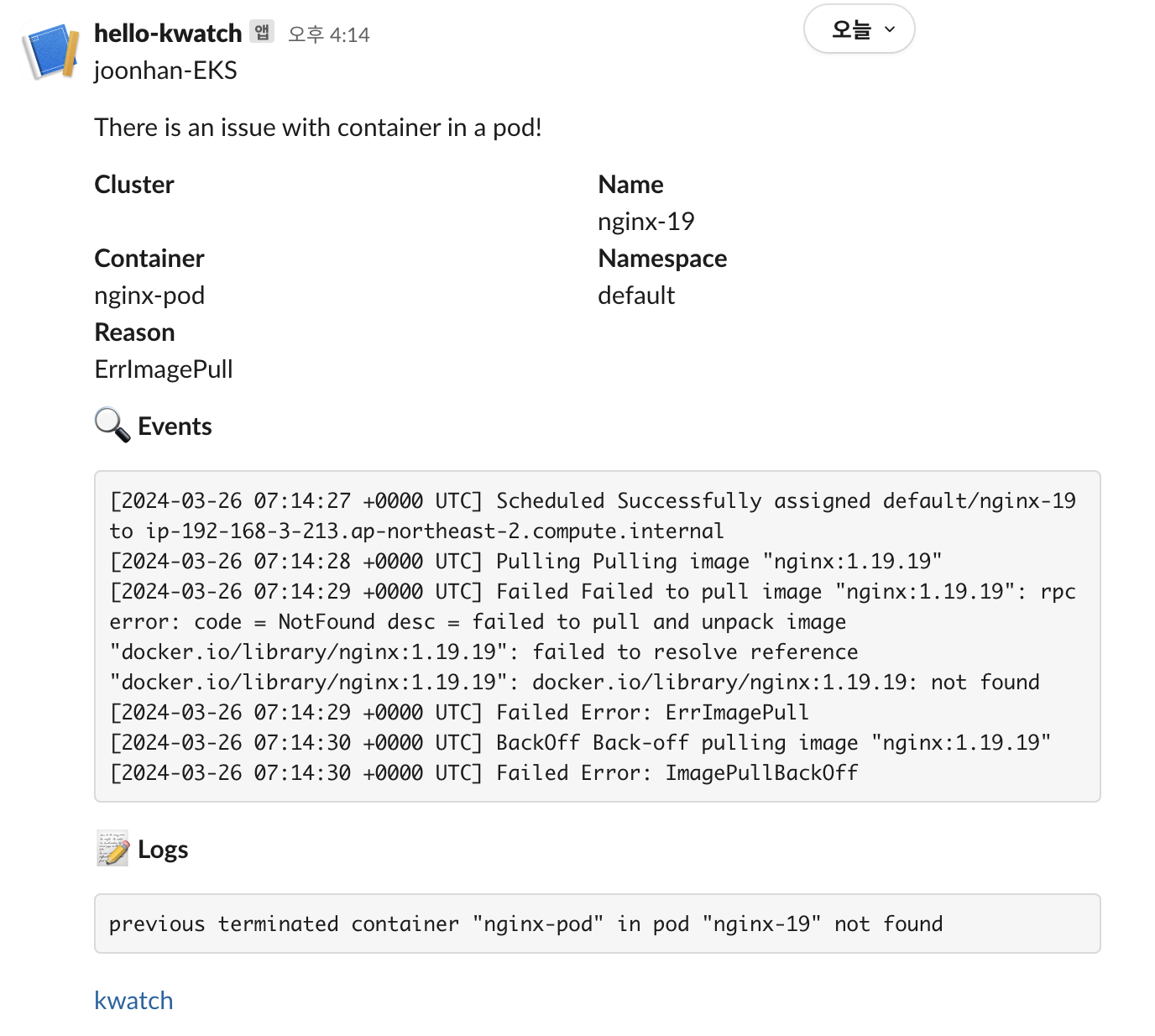
아래의 yaml 파일을 이용해서nginx 의 존재하지 않는 버전을 이미지로 설정해서 파드로 배포했다.
# nginx-error-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-19
spec:
containers:
- name: nginx-pod
image: nginx:1.19.19 # 존재하지 않는 이미지 버전입니다.아래의 명령어를 실행해서 잘못된 파드를 배포했다.
kubectl apply -f nginx-error-pod.yaml슬랙에는 아래의 이미지와 같이 오류 메세지가 전송된 것을 확인할 수 있다.
kwatch 를 삭제하기 위해 아래의 명령어를 실행했다.
kubectl delete -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8./deploy/deploy.yamlbotkube
botkube 는 kwatch 와 유사하게 클러스터에서 발생하는 오류를 수집해서 다양한 채널로 알림을 보내주는 프로그램이다.
kwatch 와 다른 점은 슬랙 채널에서 쿠버네티스 명령어를 실행할 수 있다는 것이다.
예를 들면, 파드 정보를 조회하기 위한 kubectl get pod 를 실행할 수 있다.
마찬가지로 슬랙에 앱을 설치해서 진행했으며, 자세한 설치 방법은 공식 문서에 잘 설명되어있다.
- Socket Slack App [botkube]
위의 설치 방법에 따라 슬랙 봇 토큰과 앱 토큰을 환경변수로 설정한다.
export SLACK_API_BOT_TOKEN='xoxb-YYYY'
export SLACK_API_APP_TOKEN='xapp-YYYXXXXX'helm repo 를 추가한다.
helm repo add botkube https://charts.botkube.io
helm repo update아래의 환경변수를 추가한다.
export ALLOW_KUBECTL=true
export ALLOW_HELM=true
export SLACK_CHANNEL_NAME="슬랙-봇-테스트"알림을 받고 싶은 슬랙 채널에서 botkube 봇을 초대한다.
초대하는 방법은 채널에 @봇이름 을 전송하면 된다.
여기서는 Botkube 로 설정했기 때문에 @Botkube 를 입력해서 초대할 수 있다.
아래의 yaml 파일을 이용해서 botkube 의 슬랙에서 kubectl 을 사용할 수 있도록 설정했다.
#botkube-values.yaml
actions:
'describe-created-resource': # kubectl describe
enabled: true
'show-logs-on-error': # kubectl logs
enabled: true
executors:
k8s-default-tools:
botkube/helm:
enabled: true
botkube/kubectl:
enabled: truebotkube 를 설치하기 위해 아래의 명령어를 실행했다.
helm install --version v1.0.0 botkube --namespace botkube --create-namespace \
--set communications.default-group.socketSlack.enabled=true \
--set communications.default-group.socketSlack.channels.default.name=${SLACK_CHANNEL_NAME} \
--set communications.default-group.socketSlack.appToken=${SLACK_API_APP_TOKEN} \
--set communications.default-group.socketSlack.botToken=${SLACK_API_BOT_TOKEN} \
--set settings.clusterName=${CLUSTER_NAME} \
--set 'executors.k8s-default-tools.botkube/kubectl.enabled'=${ALLOW_KUBECTL} \
--set 'executors.k8s-default-tools.botkube/helm.enabled'=${ALLOW_HELM} \
-f botkube-values.yaml botkube/botkube설치가 완료되면 아래의 이미지와 같이 안내 메세지가 전송된다.
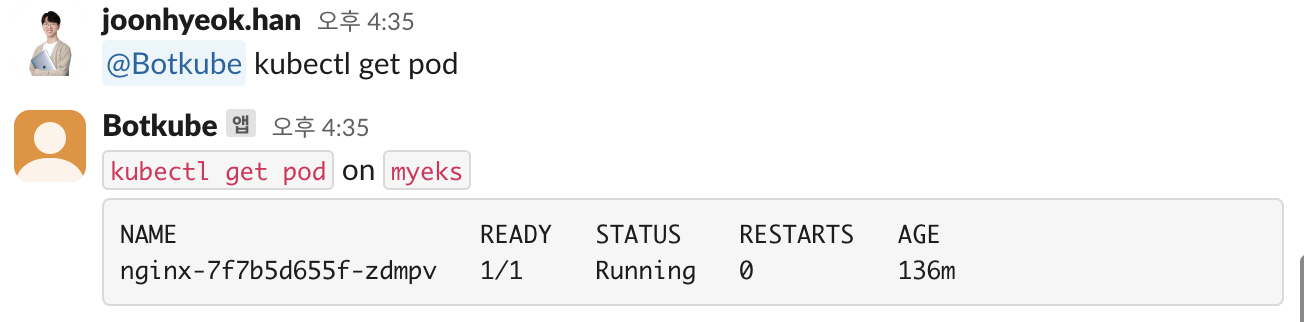
클러스터에서 실행 중인 파드를 조회하기 위해 kubectl get pod 를 실행하면 아래와 같이 응답이 돌아온다.
관리자 입장에서는 컴퓨터가 없더라도 스마트폰만 있다면 슬랙을 통해서 작업을 할 수 있다는 장점이 있는 것 같다.
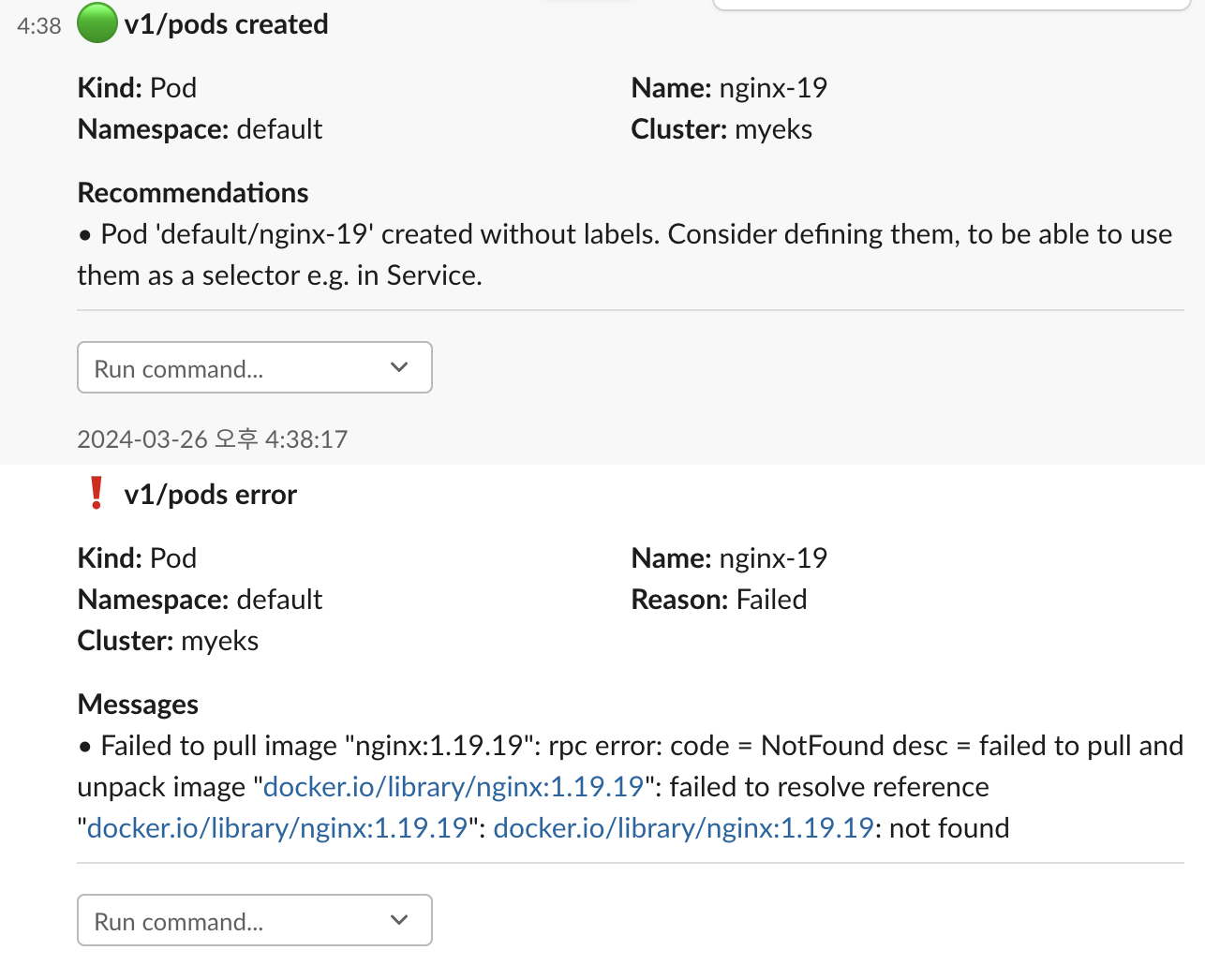
kwatch 와 마찬가지로 파드에 오류가 생기면 아래의 이미지와 같이 알림을 보내준다.
botkube 는 아래의 명령어를 실행해서 삭제할 수 있다.
helm uninstall botkube --namespace botkube메트릭 수집하기 (2) : prometheus
프로메테우스는 앞서 설명한 metrics-server 와 동일하게 메트릭을 수집하지만, 더 많은 기능을 포함하고 있는 오픈 소스 프로그램이다.
메트릭의 이상 수치가 보이면 슬랙이나 이메일로 알림을 보내주는 기능을 포함하고 있다.
PromQL(Prometheus Query Language)을 이용해서 데이터를 SQL 처럼 가공해서 조회하는 것이 가능하다.
또한, 메트릭을 시각화하기 위한 프로그램인 Grafana 와 연동해서 사용할 수 있다.
설치
프로메테우스와 그라파나를 함께 설치할 수 있는 prometheus stack 을 이용해서 설치할 것이다.
프로메테우스와 그라파나에서 제공하는 웹 대시보드를 이용하기 위해 ALB 를 이용했으며, 별도로 구매한 도메인을 이용해서 접근했다.
데이터 저장을 위해 PV 는 EBS 에 연결했고, 아래의 yaml 파일과 같이 gp3 라는 이름의 스토리지 클래스를 사전에 생성했다.
# gp3-sc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp3
allowVolumeExpansion: true
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
allowAutoIOPSPerGBIncrease: 'true'
encrypted: 'true'
fsType: xfs # default value: ext4helm repo 를 추가한다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts모니터링을 위한 네임스페이스를 생성했다.
kubectl create ns monitoring프로메테우스와 그라파나의 설정을 위해 아래와 같은 yaml 파일을 생성했다.
# monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.joonhan.link
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: <your_arn>
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.joonhan.link
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn:
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: falseALB 를 이용하는 경우 아마존에서 HTTPS 통신을 위해 발급하는 Amazon Certificate 가 있어야 한다.
비용은 추가로 발생하지 않으며, Certificate Manager 에서 발급할 수 있다.
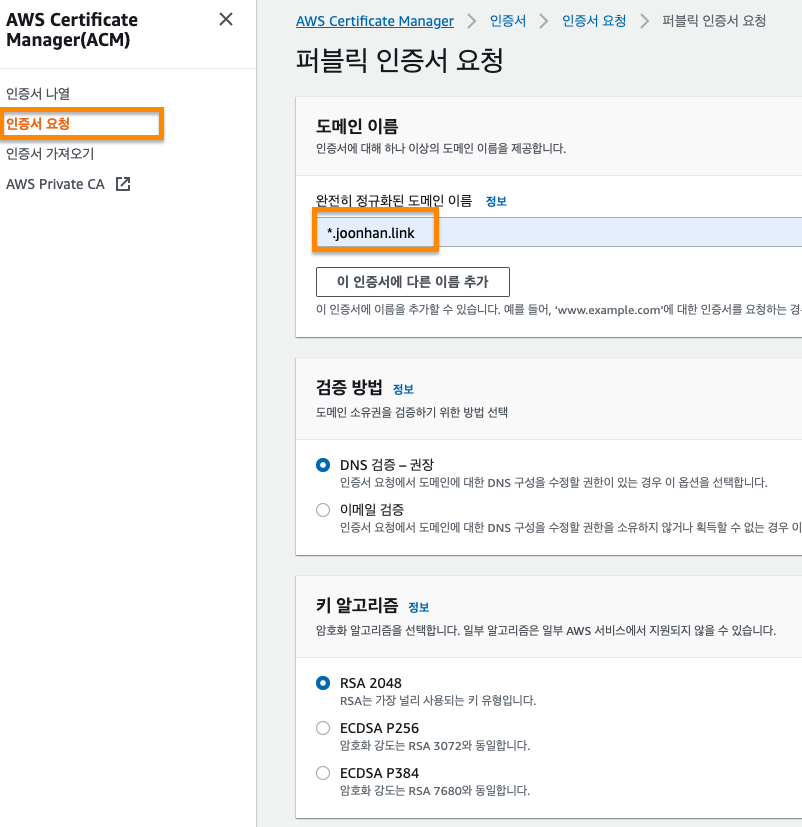
퍼블릭 인증서를 요청하기 위해서는 도메인을 구매해야 한다.
나는 joonhan.link 도메인을 구매했고, 도메인은 서브 도메인들도 모두 사용할 수 있도록 *.joonhan.link 로 설정했다.
아래의 명령어를 실행해서 prometheus stack 을 배포했다.
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version 57.1.0 \
--set prometheus.prometheusSpec.scrapeInterval='15s' \
--set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml \
--namespace monitoring아래의 명령어를 실행해서 monitoring 네임스페이스에 배포된 prometheus 의 상태를 확인할 수 있다.
helm list -n monitoring
#NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
#kube-prometheus-stack monitoring 1 2024-03-27 00:09:24.437334061 +0900 KST deployed kube-prometheus-stack-57.1.0 v0.72.0ALB 를 이용해서 배포한 프로메테우스 웹 링크인 prometheus.joonhan.link 를 접속해보니 정상적으로 배포된 것을 확인할 수 있었다.
프로메테우스 사용하기
모니터링 대상이 되는 서비스는 자체 웹 서버의 /metrics 엔드포인트로 메트릭 정보를 노출한다.
프로메테우스는 해당 경로에 HTTP GET 요청을 전송해서 메트릭 정보를 가져오고, 시계열 데이터베이스 형태로 저장한다.
워커 노드에 직접 접속해서 localhost:9100/metrics 로 GET 요청을 보내면 아래와 같이 다양한 메트릭 정보를 확인할 수 있다.
ssh ec2-user@$N1 curl -s localhost:9100/metrics | tail -n 3
#promhttp_metric_handler_requests_total{code="200"} 25
#promhttp_metric_handler_requests_total{code="500"} 0
#promhttp_metric_handler_requests_total{code="503"} 0서비스 디스커버리
프로메테우스의 특징 중 하나는 엔드포인트를 자동으로 찾아서 메트릭 수집 대상으로 등록하는 서비스 디스커버리가 가능하다는 것이다.
kubenetes api 를 이용해서 실행 중인 모든 서비스와 엔드포인트를 검색할 수 있다.
이를 확인하기 위해 프로메테우스 웹의 [status] - [service discovery] 항목을 비교했다.
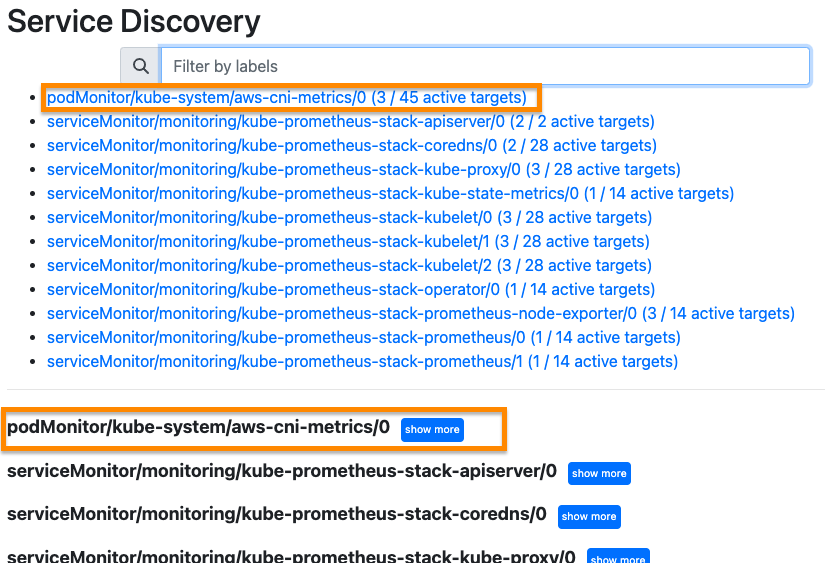
아래의 yaml 파일을 이용해서 AWS CNI Metrics 을 수집하기 위한 PodMonitor 를 배포했다.
# aws-cni-pod-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node아래의 이미지는 PodMonitor 를 배포하기 전의 화면이다.
배포 이후에는 자동으로 podMonitor 가 추가된 것을 확인할 수 있다.
PromQL
프로메테우스는 메트릭을 가공해서 조회할 수 있도록 자체적인 PromQL(Prometheus Query Language)라는 쿼리 언어를 지원한다.
웹 대시보드에서 [Graph] 탭으로 이동한 후 노드의 cpu 가 idle 상태에 있던 시간의 평균값을 1분 단위로 조회하는 쿼리를 작성했다.
1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m]))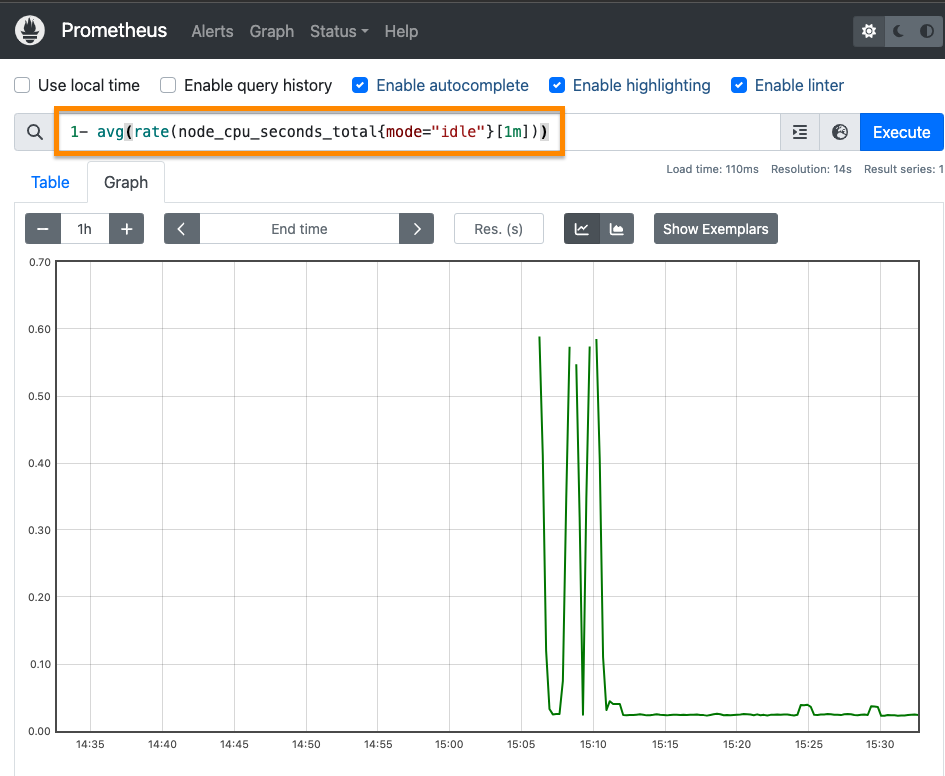
프로메테우스의 메트릭에는 크게 4가지 종류가 있다.
- 게이지(Gauge): 특정 시점의 값을 표현하기 위해 사용하는 메트릭이다. 예를 들면, 현재 시점의 값을 CPU 온도, 메모리 사용량 등이 있다.
- 카운터(Counter): 누적된 값을 표현하기 위해 사용하는 메트릭이다. 예를 들면,요청 처리 횟수나 오류 발생 횟수 등이 있다.
- 히스토그램(Histogram): 관측된 값의 분포를 표현하는 메트릭이다.
- 요약(Summary): 히스토그램과 비슷하지만, 합계와 카운트에 대한 합산 메트릭을 제공한다. 평균, 분산, 분위수와 같은 요약 통계를 계산할 때 사용한다.
PromQL 의 자세한 문법은 공식 문서를 참고하자.
- 참고자료: QUERYING PROMETHEUS [prometheus.io]
PromQL 을 이용해서 Grafana 에서 대시보드를 원하는 대로 구성하는 것이 가능하기 때문에 PromQL 을 잘 다루면 좋다.
메트릭 시각화 : Grafana
그라파나는 메트릭을 시각화하는 프로그램이다.
프로메테우스와 함께 자주 사용하고 있으며, PostgreSQL, Github, Google Sheets 등 다양한 프로그램과 연동이 가능하다.
대시보드 가져오기
대시보드를 직접 만드는 것도 좋지만, 이미 잘 만들어진 대시보드를 가져와서 활용하는 것도 좋은 방법이다.
그리고 잘 만들어진 대시보드에서 원하는 형태로 데이터를 표시하고 있는 요소의 PromQL 만 가져와서 나만의 대시보드를 만드는 것도 좋은 방법이다.
사용자들이 공유하는 대시보드 목록은 아래의 링크에서 확인할 수 있다.
- 참고자료: Grafana Dashboard [grafana]
대시보드마다 고유한 ID 값이 있는데, 이 값을 이용해서 대시보드를 생성할 수 있다.
아래의 이미지는 ArgoCD 공식 대시보드의 정보이다.
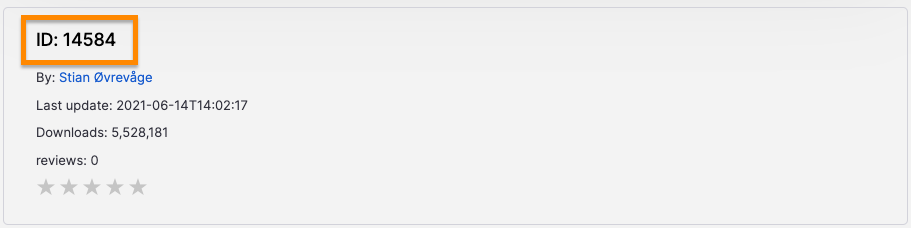
프로메테우스에서 메트릭을 가져와서 대시보드로 시각화해보자.
이미 만들어진 대시보드를 가져오는 방법은 아래와 같다.
-
[Home] - [Dashboards] 탭 클릭
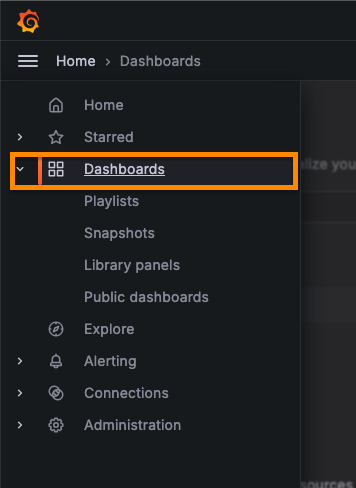
-
[New] - [Import] 선택
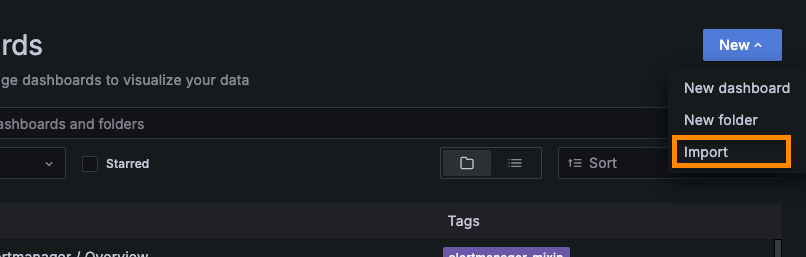
-
가져오고자 하는 대시보드의 ID 입력 후 [Load] 클릭
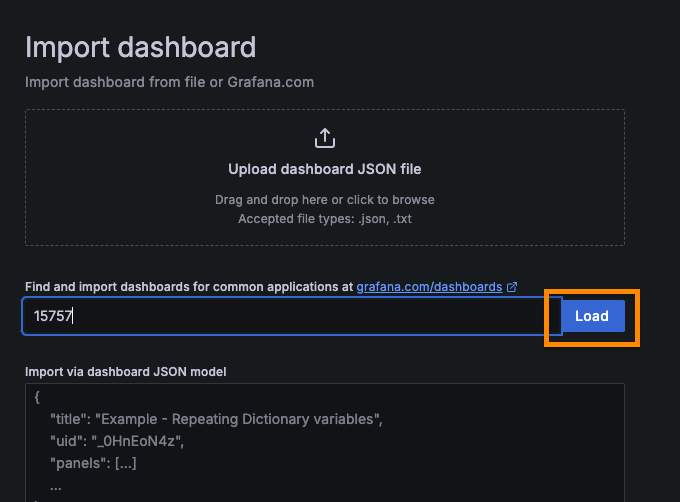
-
data source 는 현재 프로메테우스 밖에 없으므로 프로메테우스를 선택한다.
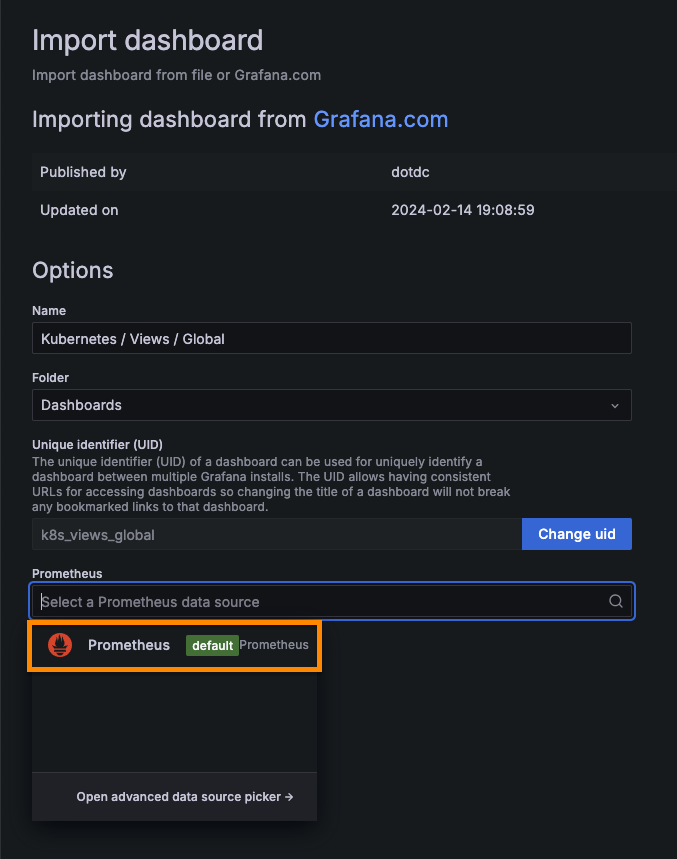
-
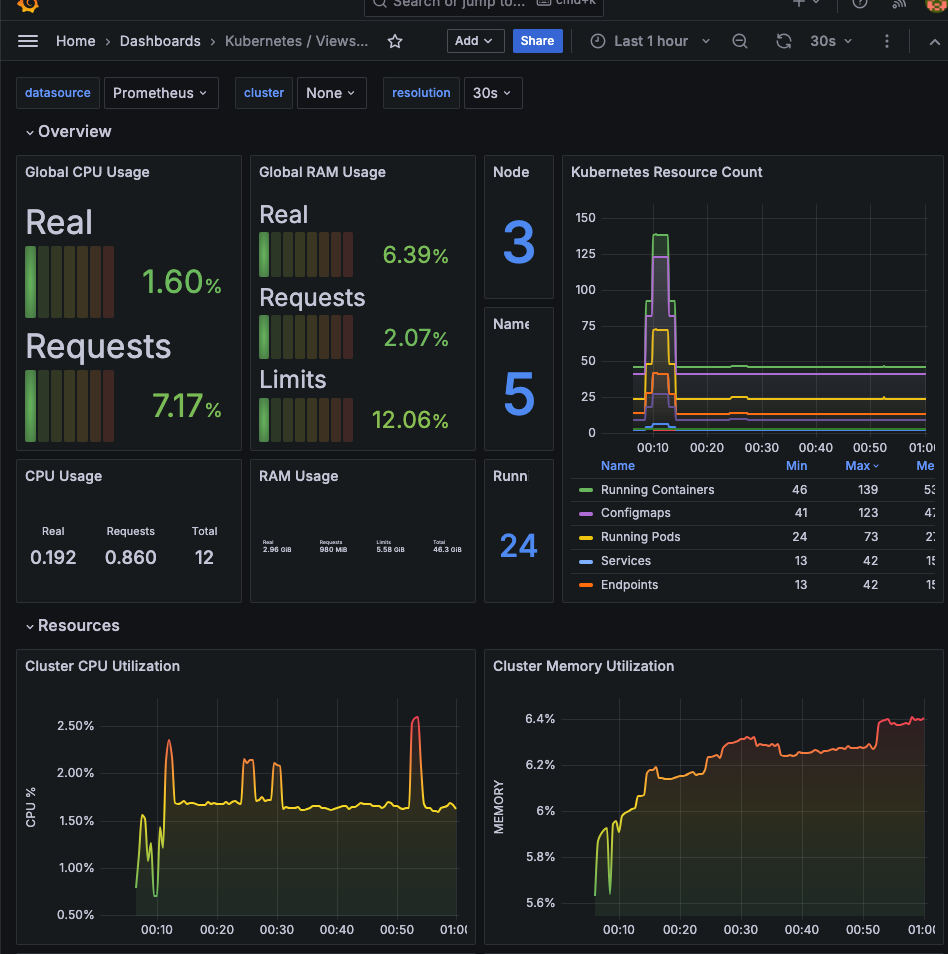
정상적으로 완료되면 아래의 이미지와 같이 메트릭들이 보기 좋게 시각화된다.
알림 설정하기
그라파나에서도 메트릭을 기준으로 다양한 채널에 알림을 보내는 것이 가능하다.
테스트를 위해 nginx 에 배포했다.
helm repo add bitnami https://charts.bitnami.com/bitnami
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
~~#alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN~~
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
helm install nginx bitnami/nginx --version 15.14.0 -f nginx-values.yaml다음으로 nginx 에서 발생하는 프로메테우스가 메트릭을 수집할 수 있도록 아래와 같이 serviceMonitor 를 추가했다.
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml그라파나 웹에서 [Alerting] - [Alert rules] 탭으로 이동한다.
[New alert rule] 클릭
아래의 이미지에 표시된 항목들을 수정해준다.
여기서는 1분 간격으로 nginx 에 들어온 request 전체 요청 수가 1 이상이면 알람을 보내도록 설정했다.
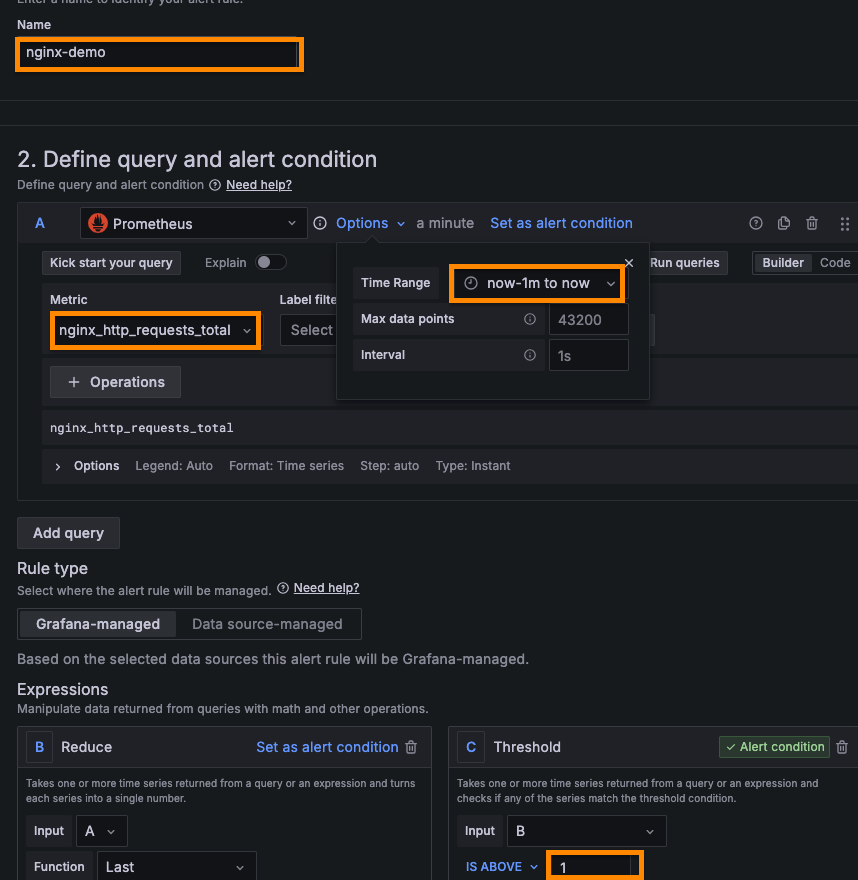
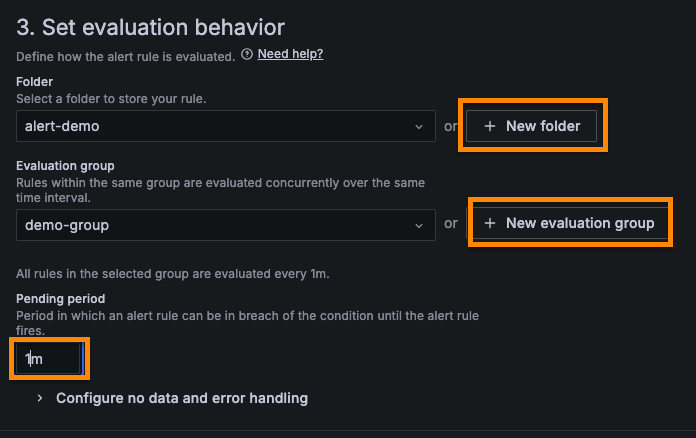
[Folder] 는 새롭게 생성하고, [Evaluation group] 도 [Evaluation Interval] 을 1m 로 설정하고 새로 생성한다.
[Pending period] 는 1m 로 설정한다.
위의 설정대로라면 1분마다 규칙을 검사하고, 알람을 보내기 1분 기다렸다가 보낸다는 것이다.
[Save and exit] 클릭 후 [Alerting] - [Contact points] 탭으로 이동해서 [Add contact point] 클릭
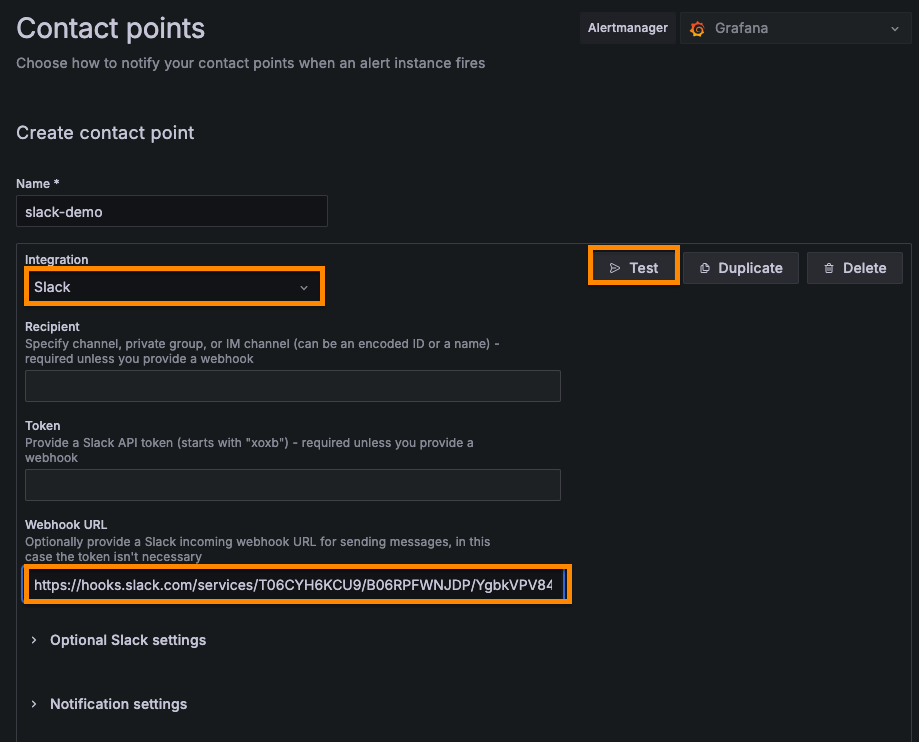
[Integration] 은 슬랙을 선택하고, 웹훅을 이용해서 알람을 보내기 위해 [Webhook URL] 에 웹훅 URL 을 입력한다. 그 다음 [Test] 버튼을 누른다.
[Test] 버튼을 누르면 슬랙에 테스트 알림이 발송되는 것을 확인할 수 있다.
정상적으로 알림이 왔다면 [Save contact point] 클릭해서 저장한다.

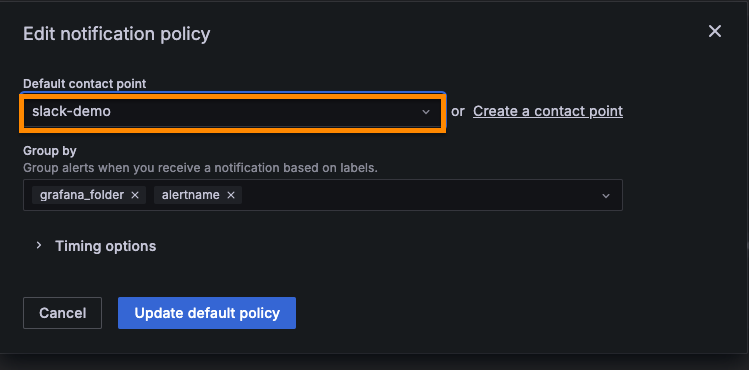
[Alerting] - [Notification policies] 탭으로 이동해서 [Default policy] 를 [edit] 한다.
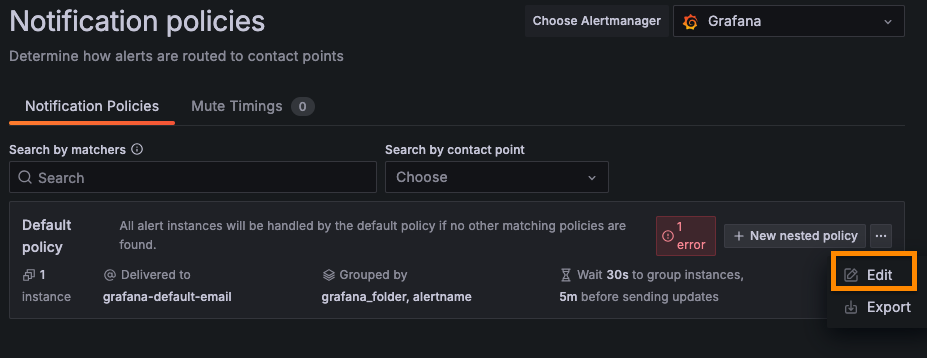
[Default contact point] 를 방금 생성한 slack 으로 설정하고 [Update default policy] 버튼 클릭
아래의 명령어를 실행해서 nginx 에 계속 접속 요청을 보낸다.
http 요청이 1번이라도 발생하면 알림이 오기 때문에 1초 후에 종료했다.
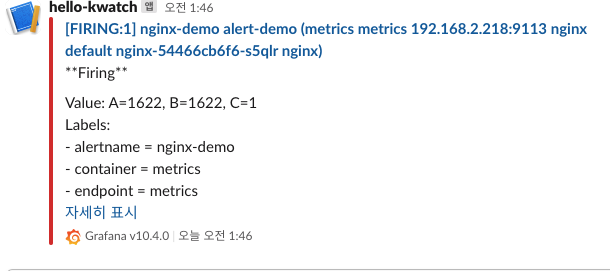
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done아래의 이미지와 같이 알람이 발생하는 것을 확인할 수 있다.
후기
1~3주차의 내용들이 많기도 하고 처음 보는 것도 많아서 어렵기도 했지만, 앞선 3주 동안 차근차근 쌓아올리다보니 이번 주 내용은 조금 쉬어가는 느낌이 들었다.
확실히 처음 스터디를 시작할 때보다 쿠버네티스와 EKS 에 익숙해진 것 같다.
그리고 현재 진행하고 있는 쿠버네티스를 이용한 사이드 프로젝트에 큰 도움이 될 것 같다.
로그를 수집하고 메트릭을 시각화 하는 것을 직접 구현하려면 시간도 많이 걸리고 번거로울텐데, 전 세계의 훌륭한 개발자 분들이 이미 잘 구현해놓은 덕분에 편리하게 Observability 를 높일 수 있다는 점에 감사하다.
벌써 스터디의 절반이나 왔다. 남은 기간도 알차게 학습하고 성장하고 싶다.
참고자료
- AWS EKS 컨트롤 플레인 로깅 [aws docs]
- Kube Controller Manager [velog]
- kubelet이란? [velog]
- Kubernetes Components [kubernetes.io]
