로지틱스 회귀
로지틱스 회귀(Logistic Regression)는 데이터가 어떤 범주에 속할 확률을 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 알고리즘이다.
💡 로지틱스 회귀 = 확률 + 분류
💡 z = a × (Weight) + b × (Length) + c × (Diagonal) + d × (Height) + e × (width) + f
➡ a, b, c, d, e는 각 가중치이며, 괄호안에 있는 항목들은 각 특성이 된다.
💡 z는 음수가 될 수 있고 양수가 될 수 있다.
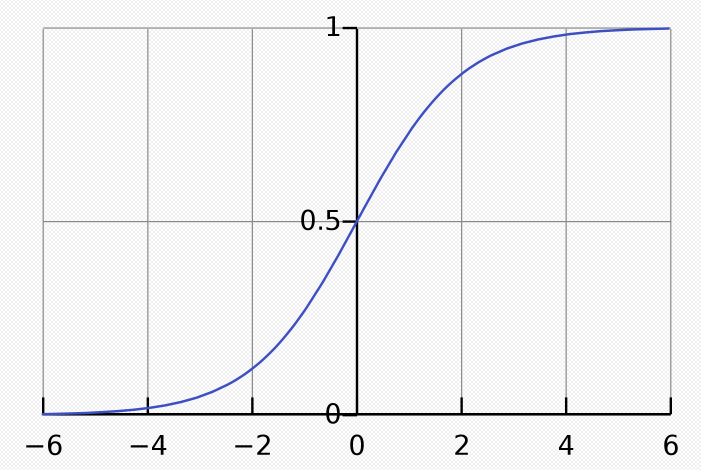
➡ 원하는 값은 확률이기 때문에, 0-1 또는 0-100%으로 변환하기위해 시그모이드함수(로지스틱 함수) 사용한다.
- 시그모이드 그래프
- 코랩으로 시그모이드 그래프 그려보기
🔗 시그모이드 함수
⭕ 먼저 알아야 할 라이브러리
-
pandas: 데이터 조작 및 분석을 위한 JSON, CSV, Excel, SQL 등 다양한 형식에서 데이터를 가져와 데이터프레임 형태로 제공가능한 라이브러리 -
데이터 프레임: 2차원 표 형식의 데이터 구조이며, Numpy로 상호 변환이 쉬움
바로 실습으로 들어가보자.
랜덤한 생선이 들어가있는 럭키백을 고객에게 제공하고자 한다. 고객에게는 제일 높은 확률을 가진 생선을 표시해주고 선택 할 수 있는 정보를 제공하려고한다. 그렇다면 각 럭키백에 어떤 생선이 많이 들어가있는지 통계를 내보고 분류해보자.
1. 데이터 준비하기
🔗 https://bit.ly/fish_csv_data 데이터를 활용하였다.
앞서 알아본 pandas 라이브러리로 데이터를 준비한다.
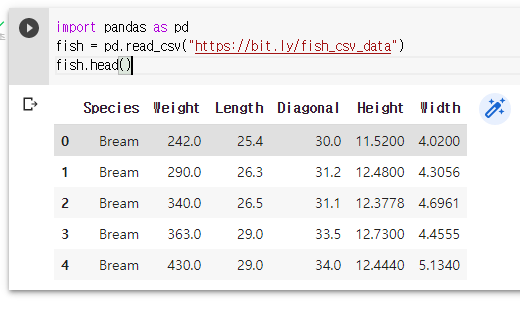
- read_csv("csv파일") ➡ 생선 데이터의 특성들을 담은 csv 파일을 데이터프레임 형태로 변환
- head() ➡ 데이터프레임 내의 처음 n줄을 출력. 기본값은 5행
2. 생선 종류 확인하기
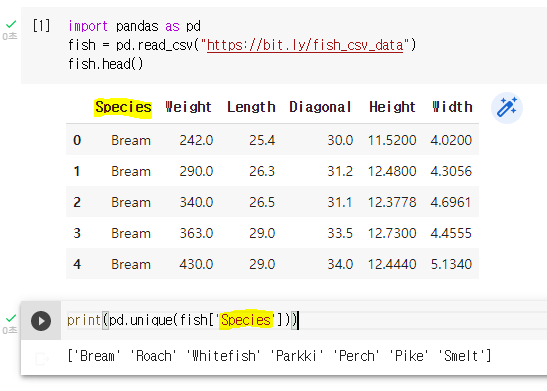
어떤 생선의 종류가 있는지 확인하자.
- unique(열이름) ➡ 특정 열의 중복을 제거한 고유 값 추출하기
3. 타깃데이터와 입력데이터 구분하기
Species 열을 타깃데이터로, 나머지 열을 입력데이터로 사용해보자.
- Weight, Length, Diagonal, Height, Width열을 Numpy형태의
입력데이터로 변환
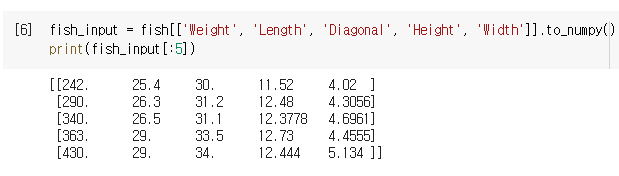
- Species 열을 Numpy형태의
타깃데이터로 변환

4. 훈련세트와 테스트세트 나누기
이전 장에서 배웠던 train_test_split을 통해서 훈련세트와 테스트세트를 나누어준다.

5. 데이터 전처리하기
StandardScaler➡ 훈련세트와 테스트세트를 표준화 전처리

6. k-최근접 이웃 알고리즘을 통한 분류
- 최근접 이웃 개수를 3으로 지정하여 훈련 및 결정계수 확인

잠깐!
우리가 2번에서 생선종류를 확인했는데 7개의 종류가 나왔었다.
클래스가 7개라고 볼 수 있으니, 2개 이상 클래스가 포함된 문제를다중 분류(multiclass classification)이라고 한다.
- 타깃값 출력
- 테스트 세트의 타깃값 예측
➡ 어떻게 예측했는지 클래스 별 확률 값을 확인 할 필요가 있다.
- 테스트세트의 확률값 확인하기
- 훈련세트의 4번째 샘플의 최근접 이웃 확인하기

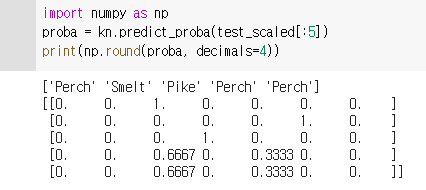
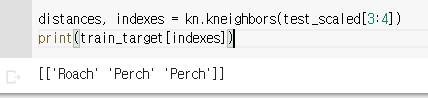
🔥 최근접 이웃 개수를 3개로 설정하였기 때문에 나올 수 있는 경우의 수는 0/3, 1/3, 2/3, 3/3 일텐데, 지금 클래스가 다양한데 더 논리적인 통계 값을 위해 로지스틱 회귀를 사용해보자.
[참고] 로지스틱 회귀로 이진분류 수행
다중분류를 해보기 전에 로지스틱 회귀로 이진분류를 수행해보자.
도미와 빙어를 True, 나머지를 False로 두기
1. 도미와 빙어 데이터 골라 학습하기

2. 예측 확률 확인하기

3. 양성클래스와 음성클래스 확인하기

알파벳순으로 정렬하여 사용함. 따라서 Smelt 양성클래스임
4. 로지스틱 계수 확인하기

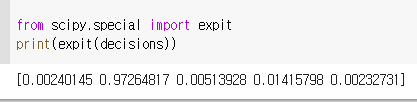
샘플 5개의 z의 값을 확인해보면 아래와 같다.

z의 값을 시그모이드 함수값으로 변경하면 각 값의 확률값으로 변환된다.
😛 실전으로 들어가기: 로지스틱 회귀로 다중 분류 수행하기
1. 훈련데이터로 훈련하기
- 훈련 반복횟수가 1,000번이고 규제 완화를 위해 C의 값을 20으로 설정하여 훈련하기

C의 값은 LogisticRegression에서 규제를 제어하는 변수이며, 기본값은 1임
2. 샘플에 대한 예측값 출력하기

3. 예측 확률값 출력하기
- 타켓값들에 대한 예측 확률을 5개 샘플만 출력하기
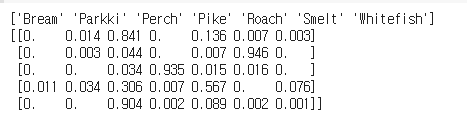
첫번째 샘플은 Perch에 대한 확률이 높았기 때문에 예측값이 Perch인 것을 확인 할 수 있다.
각 샘플들의 예측 확률을 확인하여 예측값을 도출한다.
4. z값 출력하기

5. 소프트맥스 함수를 통해 확률로 변환하기

🔔 소프트맥스 함수를 통해 계산된 확률 값이 앞서 본 로지스틱 회귀를 통한 샘플의 에측 확률값과 동일한 것을 볼 수 있다.
확인문제
- 2개보다 많은 클래스가 있는 분류 문제를 무엇이라 부르나요?
① 이진 분류
☞ ② 다중 분류
③ 단변량 회귀
④ 다변량 회귀
- 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 함수는 무엇인가요?
☞ ① 시그모이드 함수
② 소프트맥스 함수
③ 로그 함수
④ 지수 함수
🧬 2번 문제 추가 해석 🧬
- 확률의 값은 0-1 또는 0-100%의 값으로 변환해주기 위해 선형방정식의 출력을 0부터 1까지의 값으로 압축 할 수 있는 시그모이드 함수를 사용한다.
- decision_function() 메서드의 출력이 0일 때 시그모이드 함수의 값은 얼마인가요?
① 0
② 0.25
☞ ③ 0.5
④ 1
