혼공학습단
1.[혼공학습단8기] 혼자 공부하는 머신러닝+딥러닝 시작🔥

가까운 지인의 권유로 혼공학습단에 지원하게되었다. 신청기간도 길었고 커리큘럼 자체도 탄탄해 지원자가 많을 것 같았다. 당첨되지 않을 것 같았는데 딱! 당첨이 되어버리다니🤟(포토샵을 할 줄 알았으면 저기 '혼공족 당첨 당신의 자리'에 내 전신을 합성했을거다..🤪)도서
2.[혼공학습단8기] Chapter1🌍 나의 첫 머신러닝
인공지능는 컴퓨터 시스템이 사람처럼 학습하고 추론 할 수 있는 기술을 인공지능 기술이라고 부른다. 인공지능에는 크게 능력치에 따라 약인공지능과 강인공지능으로 분류된다. > 약인공지능(Weak AI): 인간에게 유용한 기능을 제공 하도록 설계된 인공지능 > 예시) 음
3.[혼공학습단8기] Chapter2🌍 데이터 다루기- 1. 훈련세트와 테스트세트
실습하기 앞서, 머신러닝에는 지도학습과 비지도학습 그리고 강화학습이 있다. 앞서 배운 k-최근접 이웃 알고리즘의 경우
4.[혼공학습단8기] Chapter2🌍 데이터 다루기- 2. 데이터 전처리
앞서 배운 것은 샘플링 편향을 막고자 numpy index를 통한 랜덤한 순서로 배치시켜 훈련세트와 테스트 세트를 나누어 훈련했다.해당 모델에서 타겟 기준의 중간 지점에 있는 데이터들은 이웃의 거리와 상관 없이 단순 인덱스만 보고 예측을 하기 시작했다.그래서 인접한
5.[혼공학습단8기] Chapter3🌍 회귀 알고리즘과 모델 규제- 1. k-최근접 이웃 회귀
실습하기 앞서,
6.[혼공학습단8기] Chapter3🌍 회귀 알고리즘과 모델 규제- 2. 선형 회귀
실습하기 앞서, k-최근접 이웃 알고리즘의 한계 🤦 k-최근접 이웃 회귀 알고리즘으로 훈련된 모델을 통해 길이가 긴 농어의 무게를 예측해보았다. 1) k-최근접 이웃 회귀 알고리즘으로 농어 무게 예측하기 > 길이가 50cm인 농어의 무게를 1,033g으로 예측하
7.[혼공학습단8기] Chapter4🌍 다양한 분류 알고리즘- 1. 로지스틱 회귀
로지틱스 회귀 로지틱스 회귀(Logistic Regression)는 데이터가 어떤 범주에 속할 확률을 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 알고리즘이다. 💡 로지틱스 회귀 = 확률 + 분류 💡 z = a × (Weight)
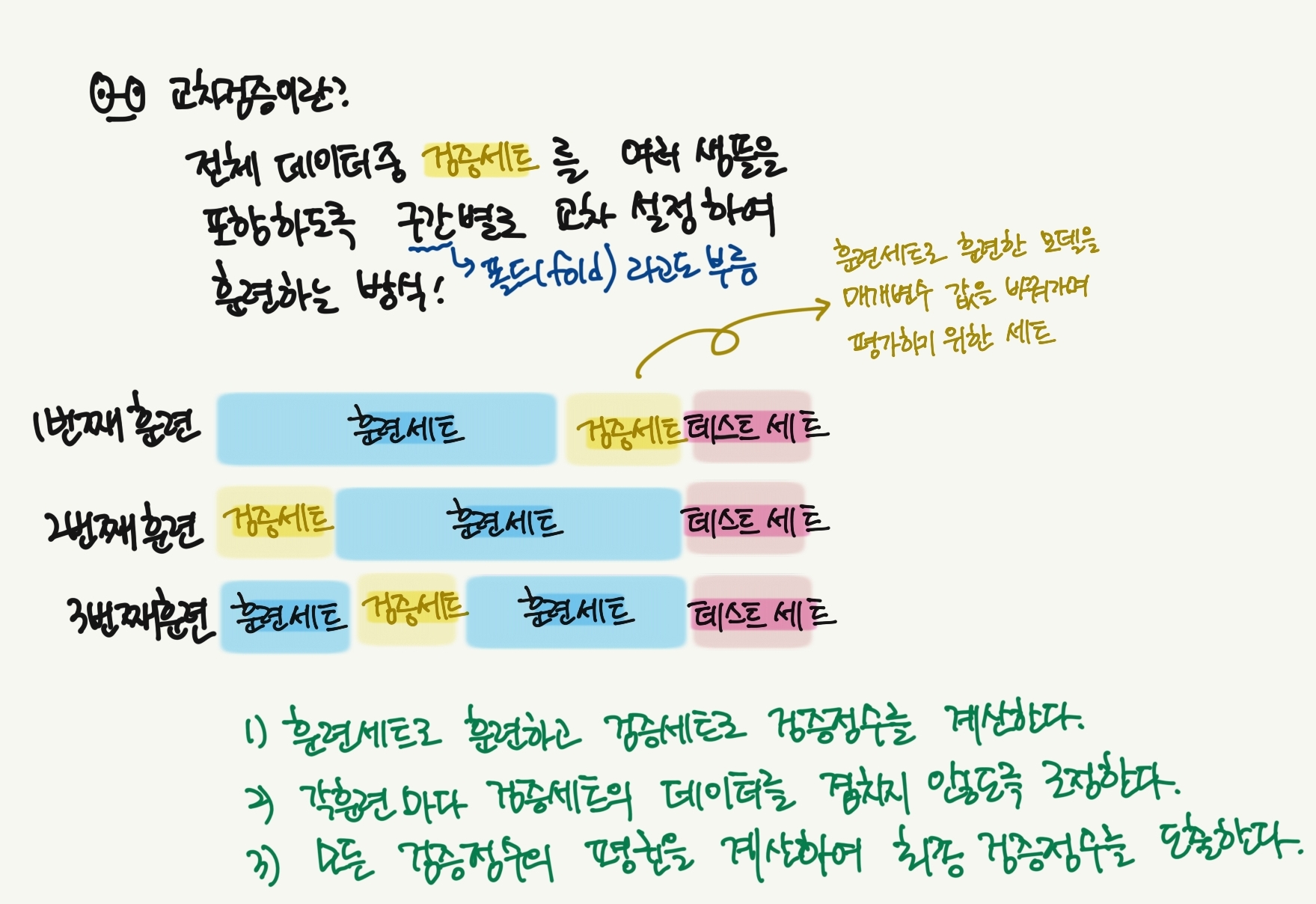
8.[혼공학습단8기] Chapter5🌍 [참고] 교차검증
9.[혼공학습단8기] Chapter6🌍 비지도학습- 2. k-평균
Chapter2에서 잠깐 언급하였지만 비지도학습은 입력데이터만을 통한 학습을 말한다.당연히 비지도학습인 k-평균(k-means) 알고리즘도 입력데이터만 존재하는 것을 예측 할 수 있다.그럼 k-평균 알고리즘에 대해서 자세히 알아보기위해,책에서 예시로 들은 과일을 분류하
10.[혼공학습단8기] Chapter7🌍 딥러닝- 1. 인공신경망 <확인문제>
딥러닝에 대해서 책을 읽고 정리하려다 보니 양이 너무 많아 확인문제 미션부터 수행해야겠다. 🤧어떤 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터 개수는 몇개인가요?① 1,000개② 1,001개 ☞ ③ 1,010개