
2024년 10월 26-27일에 광교 수원컨벤션센터에서 진행한 PyCon Korea 2024에 참가했습니다.
이전에 Python과 Django로 백엔드 개발을 진행한 적이 있고, 행사에 참여하는 여러 기업들의 Python 개발 방식이 궁금해 이번 행사에 관심이 생겼습니다. 세션을 진행하시는 분들 중 해당 기업 출신이거나, 재직 중인 분들이 계셔서 세션을 직접 듣고 싶어 행사에 참여하게 되었습니다.
양일 참가 비용은 80,000원입니다. 학생/공무원의 경우 할인 혜택이 있습니다.
행사 위치가 집에서 꽤 멀어서 오전 세션은 참가하지 못했고, 양일 오후 세션 중 흥미가 가는 세션 위주로 참가했습니다. 해당 세션 중 흥미로웠던 몇 가지를 정리하였습니다.
색칠놀이에 파이썬을 입힌다면?

https://tech-diary.tistory.com/m/68
세션 진행자 분의 블로그인 듯 합니다. 세션 내용이 거의 그대로 들어 있습니다.
PIPO Painting이란 물감을 도안에 적힌 숫자에 따라서 색칠하면 완성되는 그림을 말합니다.
해당 세션에서는 그리고 싶은 그림을 Python을 통해 PIPO Painting 도안으로 만들어주는 오픈소스 라이브러리를 만들면서 만난 문제들과 그 해결 방법을 다루었습니다.
pypipo 라이브러리를 개발하면서, 문제를 정의하고 해결 방법을 찾아가는 과정이 논리적이고 인상적이어서 기억에 남았습니다.
어떻게 이미지를 도안으로 만들까?

단순히 이미지를 흑백으로 만드는 방식을 사용하면, 선이 불연속적이고 실종되는 선이 많아 영역을 나누기가 어렵습니다.
그래서 진행자는 영상처리 기법 중 Bilateral Filter 메서드를 사용하여 이미지를 blur 처리하고, K-means 알고리즘을 사용해 이미지에 존재하는 수많은 RGB 색상을 K개의 색상으로 정리하여 영역을 나누는 방식을 사용했습니다.
K-means 알고리즘은 기존에 알고 있던 개념이었는데, RGB 색상값의 유클리드 거리를 이용하여 K-means 알고리즘을 실제 문제 해결에 적용하는 논리적 과정이 인상깊었습니다.
색상 번호는 어느 위치에 매길까?
진행자는 처음에는 영역의 내접원 중심에 번호를 매기면 될 것이라는 생각을 했다고 합니다. 하지만 내접원의 중심이라고 모든 영역에 적용할 수 있는 것은 아니었습니다.
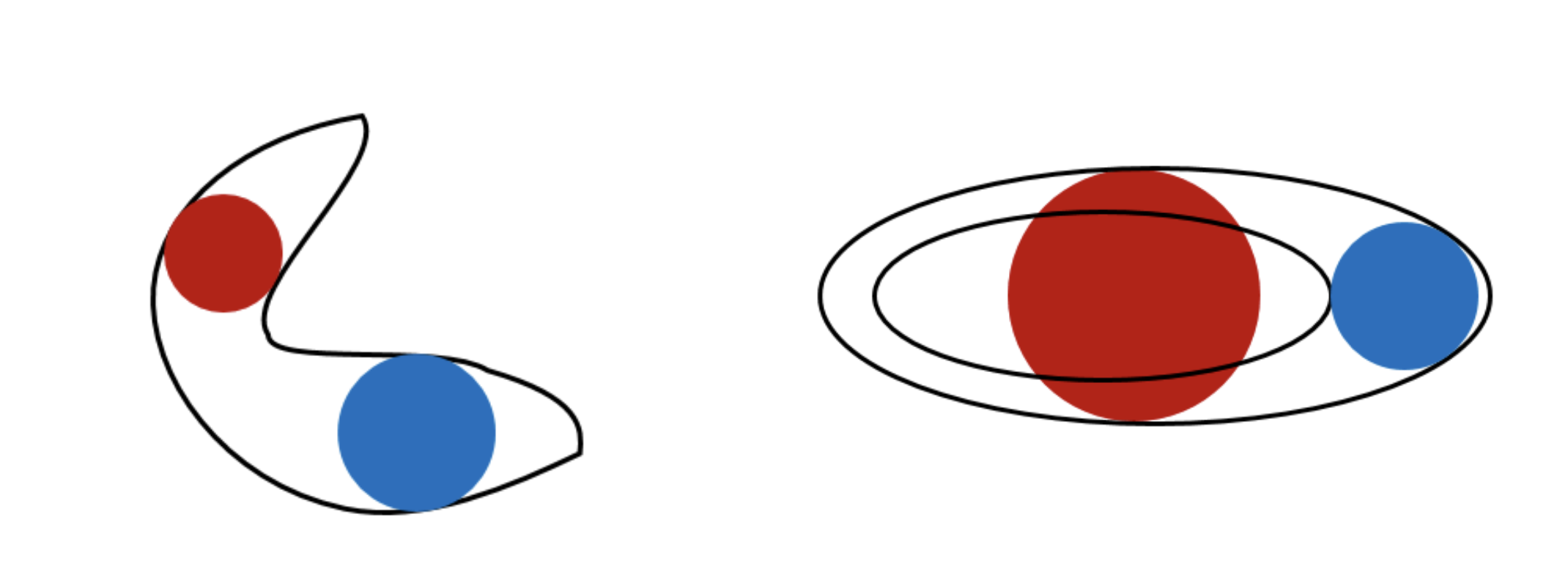
왼쪽 그림처럼 하나의 영역에 내접원이 여러 개 존재하는 경우도 있고, 오른쪽 그림처럼 영역 안에 영역이 있어 내접원의 중심이 해당 영역에 포함되지 않는 경우도 있었습니다.
진행자는 이 문제를 해결하기 위해, 영역에 포함되지 않는 내부 영역은 masking하고, 영역에 존재하는 내접원들 중 최대 넓이의 내접원을 찾는 방식을 사용했습니다. 최대 넓이 내접원을 찾을 때는 BFS (Breadth-First Search) 알고리즘을 사용했습니다.
Next Step
pypipo 라이브러리가 해결해야 할 남은 문제에 대해서도 다루었습니다.
앞서 사용했던 K-means clustering 이 가진 문제에 대한 것이었는데, 색상을 clustering 할 때 시중에서 판매하는 물감의 종류도 고려해야 하며, RGB 색상의 유클리드 거리만을 사용하여 clustering 하게 되면 실제 사람이 인식하는 색상과 차이가 있으므로 명도와 채도도 고려해야 한다는 것이었습니다.
pypipo 오픈소스 라이브러리
https://github.com/AutoPipo/pypipo
해당 세션을 듣는 내내 '어? 저런 문제가 있구나. 어떻게 해결하지?', '아~ 저렇게 해결할 수 있겠구나~' 라는 생각을 반복했던 것 같습니다. 세션 진행자 분의 문제를 발견하고 정의하는 능력이 대단하다고 생각했고, K-means clustering 알고리즘, BFS 알고리즘 등 이미 제가 알고 있는 개념을 실제 문제 해결에 적용하는 과정이 인상깊었습니다.
Django로 구현하는 EAV 모델링와 CQRS
SLASH 24에서 토스 인터널 팀의 No-Code Tool에 대한 세션을 하셨던 문상헌 님이 진행을 해주셨습니다. 이번 세션에서는 EAV 모델링과 CQRS에 대해 다루었는데, 이것 역시 No-Code Tool을 개발하면서 다루었던 내용으로 보였습니다.
EAV 모델링과 CQRS 둘 다 잘 알지 못했던 내용이었는데, 이것이 어떻게 문제 해결에 사용될 수 있는지를 알게 되어 기억에 남았습니다.
EAV 모델링
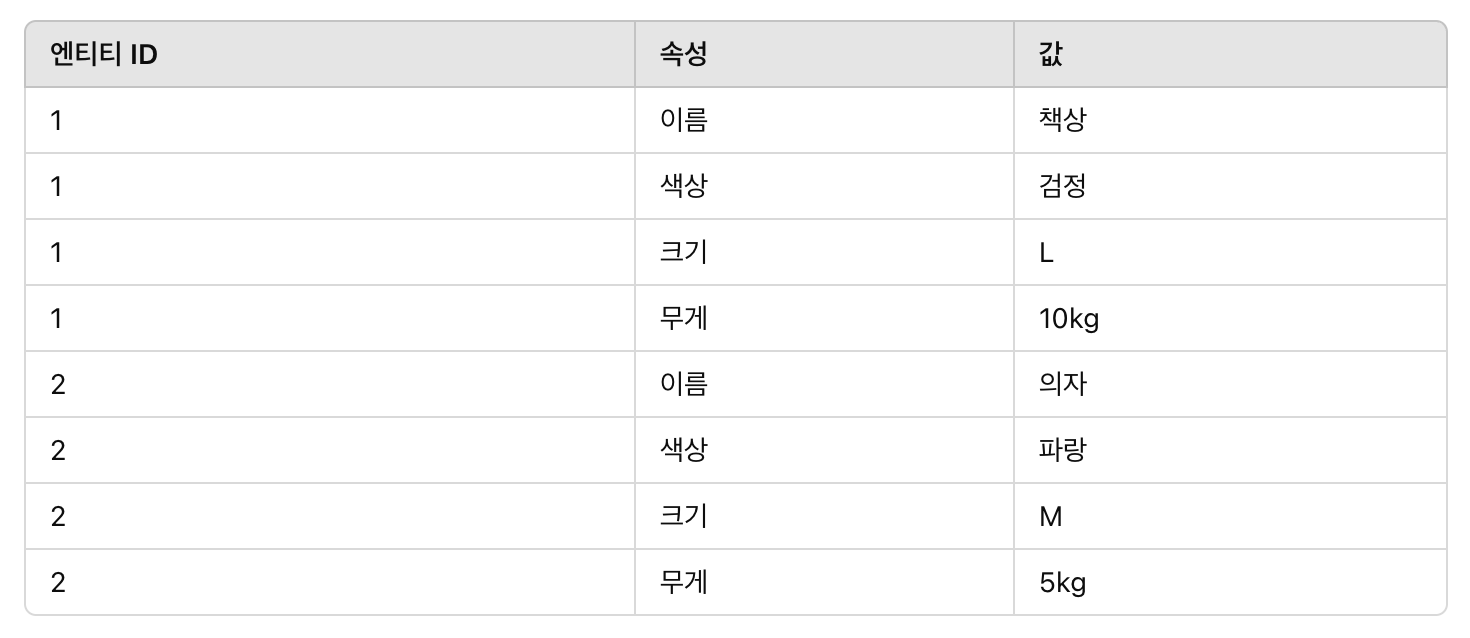

EAV는 Entity-Attribute-Value의 줄임말로, 스키마가 자주 변경되는 데이터를 저장할 때 주로 사용됩니다. No-Code Tool에서는 사용자가 데이터 스키마를 정의해서 사용하므로 EAV 모델링 기법을 사용한 것으로 보입니다.
EAV 모델링의 장점으로는 유연하게 속성을 관리할 수 있고, 확장성이 뛰어나며, 공간복잡도 효율이 좋다는 것을 들 수 있습니다. 단점으로는 서비스 복잡도가 증가하고, 성능적으로 좋지 않다는 점이 있습니다.
일반적인 데이터 모델과 다르게, EAV 모델은 데이터를 조회하거나 정렬, 필터할 때마다 수많은 Join 연산이 발생하고, Index를 적용하기도 어려우므로 매번 Full Scan을 사용하여 성능이 좋지 않습니다.
진행자는 이 성능 문제를 해결하기 위해 CQRS 기법을 사용했습니다.
CQRS
CQRS는 Command Query Responsibility Segregation의 줄임말로, CRUD에서 Command에 해당하는 Create, Update, Delete와 Query에 해당하는 Read를 분리하여 처리하는 방식입니다.
가장 익숙한 CQRS의 방식에는 Replica DB로 Read Only DB와 Read Write DB를 분리하여 성능을 향상하는 방식이 있습니다.
EAV 모델링의 성능 문제는 EAV 테이블을 사용하는 과도한 정규화 때문인데, 진행자는 이를 역정규화 Read Only DB를 구축하는 방식으로 해결했습니다.
Elastic Search를 역정규화 NoSQL DB로 사용하여, 데이터 수정이 발생하면 기존 MySQL 관계형 데이터베이스를 수정하고, 그 데이터를 Elastic Search Read-only DB에 동기화하여 데이터를 조회할 때는 Elastic Search로 빠르게 조회할 수 있도록 설계하였습니다.
데이터를 동기화하는 로직을 추가하고 데이터 정합성을 신경써야 하는 비용이 발생하지만, EAV 모델링의 좋지 않은 성능을 효과적으로 개선할 수 있었겠다는 생각이 들었습니다.
django-eav
https://github.com/sanghunmoon/django-eav
Read-only DB와 Read-write DB를 분리하여 성능을 향상하는 replica DB 방식을 넘어 아예 DB 종류를 다르게 해서 조회 성능을 향상하는 것은 생각지도 못한 방식이었는데, DB와 서버 성능 향상에 대한 시야를 넓히기 위해서 CQRS를 비롯한 다양한 개념의 공부가 필요하겠다고 생각했습니다.
Django의 DB Connection과 Transaction 관리

마찬가지로 토스의 Python 개발자이신 명세교 님이 진행해주셨습니다. Django와 MySQL 간의 DB Connection 이 연결되는 시점과 원리, 그리고 Django의 transaction.atomic의 savepoint 파라미터의 특징을 다루었습니다.
DB Connection의 원리에 대해서 잘 알지 못했었고, transaction.atomic은 연결할 DB의 alias를 설정하는 정도로만 파라미터를 설정했었는데, 해당 개념들을 깊게 파고드는 세션을 듣게 되어 유익했습니다.
Django의 DB Connection 관리
참고하면 좋은 Django Database Documentation
https://docs.djangoproject.com/en/5.1/ref/databases/
Django의 DB Connection은 CONN_MAX_AGE 값에 따라 그 유지 시간이 결정됩니다. 60으로 설정하면 60초 동안 해당 Connection을 재사용할 수 있으며, None으로 설정하면 Connection이 영구적으로 유지됩니다. 0으로 설정하면 요청이 끝나자마자 Connection이 종료됩니다. 기본값은 0입니다.
close_if_unusable_or_obsolete 메서드를 사용하면 유효하지 않은 connection을 종료할 수 있습니다.
Django의 DB Connection 관리 유의점
MySQL은 wait_timeout 파라미터를 가지고 있는데, wait_timeout보다 connection에서 요청이 들어오지 않은 시간이 길어지면 connection을 종료합니다. 그러므로 CONN_MAX_AGE 값이 wait_timeout 보다 짧아야 종료된 connection에 요청을 보내지 않을 수 있습니다.
하지만 CONN_MAX_AGE 값에 의해 connection이 종료되는 시점은 요청이 시작할 때와 끝날 때입니다. 요청이 아닌 batch, consumer, worker 등에서 query가 발생하는 경우나, CONN_MAX_AGE 보다 요청이 오래 걸리는 경우에는 문제가 발생할 수 있습니다.
이때 CONN_HEALTH_CHECKS 값을 True로 설정하면 query를 DB에 보내기 전에 DB에 ping을 먼저 날려 응답이 없을 경우 다시 connection을 맺을 수 있습니다. 하지만 이 경우 CONN_MAX_AGE 값과 별개로 매번 DB에 ping을 날리는 오버헤드가 발생하는데, health check를 하기 전에 close_if_unusable_or_obsolete 메서드를 먼저 호출한다면 해당 connection이 CONN_MAX_AGE 를 넘었는지 먼저 확인할 수 있습니다.
DB Connecton을 직접적으로 관리해본 적이 없어서, 개념을 찾아보면서 다시 정리해 보았는데, 이 부분은 따로 실습을 해봐야 할 것 같습니다.
Django의 Transaction 관리 방법
Django의 트랜잭션을 담당하는 transaction.atomic은 3가지 파라미터를 가지고 있습니다.
using(기본값None)- 연결할 DB의 이름, alias를 지정해줄 수 있습니다.
savepoint(기본값True)True일 경우 transaction block이 중첩될 경우 savepoint를 생성합니다.
durable(기본값False)True일 경우 transaction block이 중첩되면 RuntimeError를 발생시켜, 해당 트랜잭션이 가장 외부에 있음을 보장합니다.
진행자는 이 중 savepoint를 기본적으로 False 로 설정할 것을 추천했습니다. savepoint를 기본값인 True로 설정한 상태에서, 내부 트랜잭션의 에러를 직접 제어하지 않을 경우 문제가 외부 트랜잭션으로 전파될 수 있기 때문이라고 이유를 설명했습니다.
일반적으로 함수나 메서드를 사용할 때 파라미터는 기본값으로 설정된 걸 건드리지 않는 경우가 많은데, 기본값으로 설정하지 않는 것을 추천한 것이 인상깊었습니다. 해당 내용을 다시 듣고 정리해보고 싶은데, PyCon 공식 유튜브에 아직 영상이 올라오지 않아서..
참고하면 좋은 Django Transaction Documentation
https://docs.djangoproject.com/en/5.1/topics/db/transactions/
깊게 생각해보지 않았던 Django와 DB 간의 Connection에 관련된 내용에 대해 들으면서 DB Connection에 대해서도 더 알아봐야겠다는 생각이 들었습니다. transaction.atomic 을 사용할 때도 using 파라미터를 replica db 로 설정하는 정도로만 사용했었는데, 다른 파라미터들에 대해서도 좀 더 이해가 필요하겠다는 생각이 들었습니다.
개발 컨퍼런스에 오랜만에 참여해서 세션을 들으면서 Python을 사용하는 분야가 정말 다양하다는 생각이 들었고, Django 백엔드 관련 내용 뿐 아니라 여러 방면으로 시야를 넓힐 수 있는 계기가 되었습니다. 한국의 Python 생태계가 계속해서 확장되었으면 좋겠다는 생각이 들었습니다.
